
Этот пост является продолжением предыдущей публикации Разделение кода и текста: мысли вслух. На этот раз мы пойдем чуть-чуть дальше и представим возможный API, а также сравним рабочий процесс до и после. В качестве примера использованы язык PHP и фреймворк Laravel, но это почти не имеет значения.
Тезис
В этом посте мы пытаемся разобраться, можно ли заметно улучшить процесс работы с текстом в современных приложениях. Под текстом подразумеваются любые элементы интерфейса, коммуникаций с пользователями и так далее – то, что не является частью бизнес-логики в исходном коде. Говоря проще, это файлы с шаблонами, переменные и параметры типа string и так далее.
Текущий метод #1
Для начала рассмотрим самый примитивный способ работы с текстами. Этот способ вполне себе подходит для маленьких приложений и сайтов. Текст передается как параметр внутри контроллера:

Текст являются частью шаблона:

Плюсы данного метода:
Программисту не надо тратить дополнительное время
Очень легко вставлять в текст значения из переменных
Минусы:
Тексты разбросаны по репозиторию – что-то находится в классах, что-то в шаблонах. Иногда нужно время, чтобы найти конкретный текст и исправить в нем ошибку
Нет возможности перевода на другие языки
Текущий метод #2
Этот метод из документации Laravel, и большинство современных фреймворков, написанных на самых разных языках, имеют что-то подобное. Это примерная копия технологии 1970-1980 годов под названием i18n.
Имеем отдельную папку с набором файлов, в которых хранятся все наши тексты. В коде, вместо того, чтобы писать текст напрямую, ссылаемся на эти файлы, на какой-то идентификатор конкретного текста:
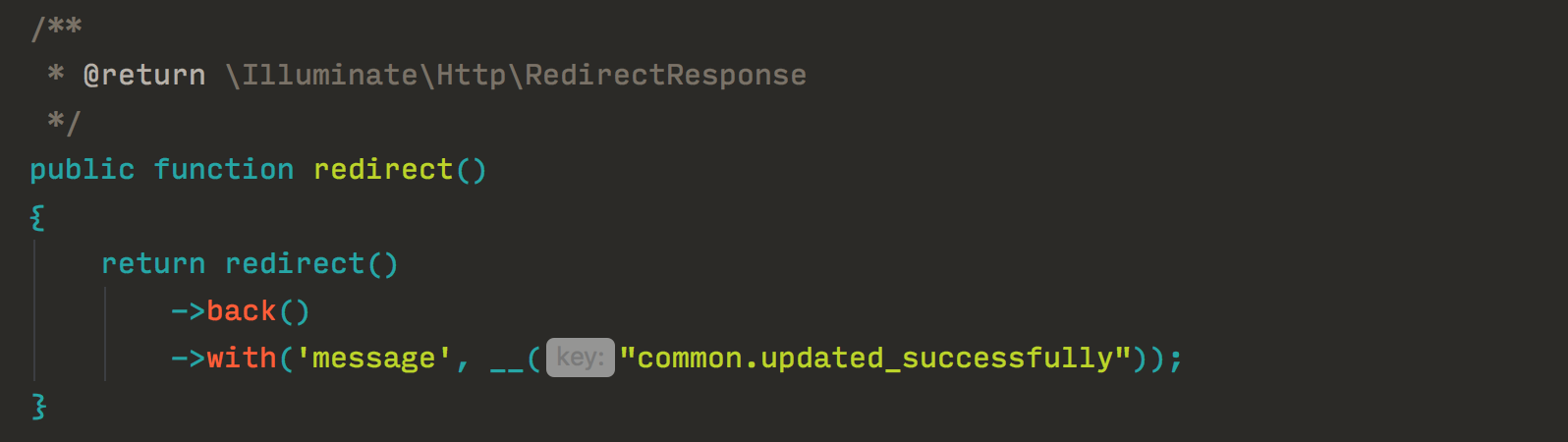

Плюсы метода:
Теперь можно переводить тексты при необходимости, достаточно перевести файлы, в которых хранятся тексты
Тексты вынесены в отдельную папку, что позволяет оптимизировать рабочий процесс (допустим, сделать их отдельным пакетом или репозиторием, чтобы копирайтеры и переводчики могли там делать изменения сами)
Минусы метода:
Дополнительная, замедляющая работа для разработчика, причем с ростом приложения она сильно увеличивается. Часто возникает дилемма - использовать существующий текст или создать новый? А вдруг в этом новом месте чуть-чуть другой контекст?
Вставлять переменные в текст не так удобно, как в варианте #1
Опечатка в идентификаторе текста "поломает" его
Работая с текстами копирайтеры и переводчики могут не до конца понимать, в каком месте конкретно он используется, "влезет" ли он в интерфейс и так далее
Текущий метод #3
Этот метод является модификацией предыдущего. Вместо использования идентификаторов, в целях ускорения работы сразу подставляется текст на языке по-умолчанию (например, на языке разработчика):
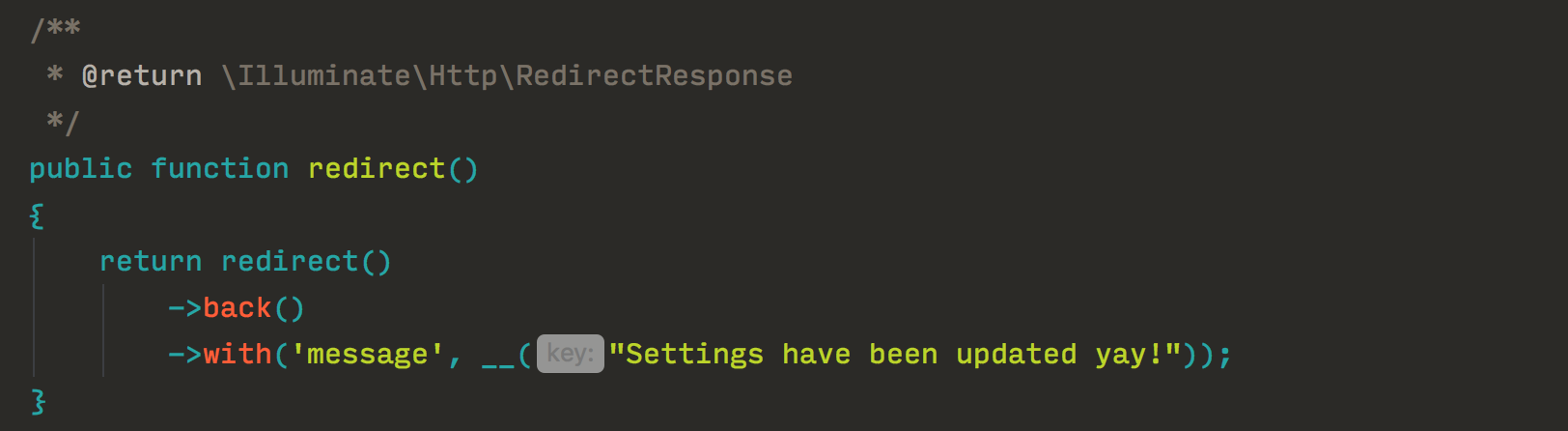

Плюсы метода:
Программист не тратит лишнего времени, как и в варианте #1
Можно комфортно переводить продукт на другие языки или локали
Минусы метода:
Переменные снова не так удобно вставлять внутрь текста
Если программист сделал опечатку или просто написал плоховато, то копирайтеру надо идти в код, чтобы исправить
Тексты теперь разнесены по 2 местам – переводы находятся в папке с текстовыми файлами, а тексты на основном языке находятся прямо в коде
Все еще не до конца понятно где находится в продукте конкретный текст. Копирайтер или переводчик может выбрать неудачный или неподходящий (по тону, по длине) текст
Невозможность иметь разные переводы для одного и того же исходного текста, так как сам текст является уникальным идентификатором
Предлагаемый метод
А теперь рассмотрим предлагаемый данной статьей метод, в котором мы попытаемся объединить плюсы каждого из вышеперечисленных. Предлагается использовать супер-короткую глобальную функцию (наподобие __()) в коде и директиву в файлах шаблонов (допустим, @p):
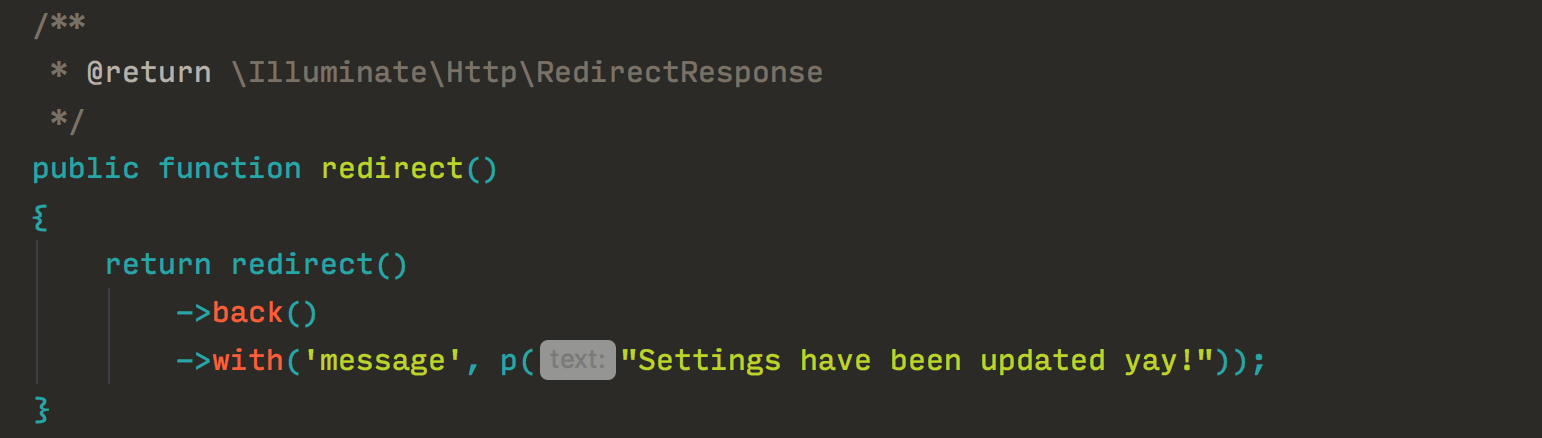

Или даже вот так:

Это смесь всех вышеуказанных методов. С одной стороны, мы работаем с текстом по привычному – мы можем взять и вставить переменную внутри, где ходим. С другой стороны, у нас есть специальный класс, который умеет переводить тексты.
Что же делает глобальная функция или директива p:
Подобно функции
__()она проверяет в специальных файлах наличие альтернативного текста, которым может быть как перевод на другой язык, так и просто поправленная версия на этом же языкеВсе отсутствующие тексты записываются в специальной лог, для дальнейшего экспорта
Функция использует трассировку языка и статический анализ, чтобы понять откуда был вызов – с какой страницы, какого шаблона и так далее
Таким образом, предполагается, что где-то в процессе CI/CD будет происходить синхронизация – мы будем извещать внешний API о новых текстах, которые нуждаются в переводе или поправках, включая их точное местоположение, а также загружать в локальные файлы существующие тексты.
Это создает целый ряд плюсов. Рассмотрим их детально.
Преимущество #1
Как известно, многие программисты говорят даже на своих родных языках заметно слабее Шекспира или Пушкина. Тем не менее, с этим подходом разработчики могут не терять лишнее время, а просто писать черновые версии текста:

Вот соответствующее всплывающее сообщение на сайте:

Вроде бы и неплохо, но как-то слишком лаконично и сухо, кто-то даже может обидеться. Копирайтер (ну или какой-то product manager) вскоре увидит в своем интерфейсе, что появился новый текст на сайте и правит его на что-то более дружелюбное или соответствующее брэнду:
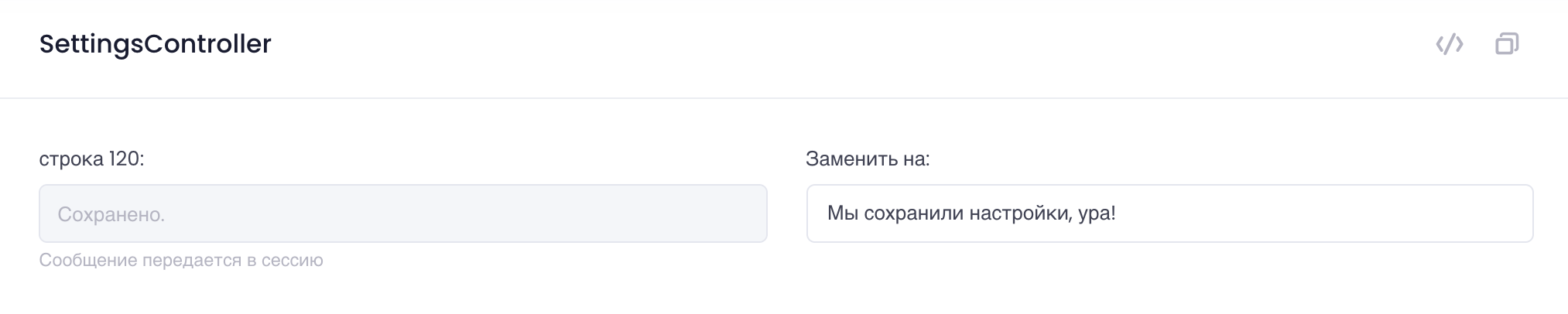
Что после следующей синхронизации попадает в интерфейс продукта:

Программист при этом не трогал код, да и не будет трогать эту часть кода никогда. Ведь это не часть бизнес-логики. Тексты целиком и полностью управляются из удобной админки. Нет никаких коммитов в репозиторий, чтобы поправить опечатку или улучшить текст.
То есть первое преимущество – это снятие с плечей разработчиков забот о качественных текстах. Программисты делают свою работу, а копирайтеры делают свою.
Преимущество #2
Удобный общий контроль всех текстов в продукте – языка, на котором мы говорим с клиентами. Можно в любую секунду посмотреть как сейчас мы говорим на странице X или в письме Y, влазит ли тайский перевод в кнопку, достаточно ли эмпатии в письме про отмену транзакции:

Если раньше коллеги спрашивали: "а что мы сейчас говорим на такой-то странице?", а мы отвечали: "непомню, вроде вот это", то теперь любой сотрудник может посмотреть любой шаг и предложить поправки или улучшения в пару кликов. Тексты, разбросанные по сотням или тысячам файлов теперь собраны в одном месте и разложены аккуратно по полочкам, с полноценным предпросмотром:
")
Преимущество #3
Такой фичи, во всяком случае публично, пока нигде нет, но появляется интересная возможность создавать что-то вроде диалектов – тексты, адаптированные по тону и лексикону под конкретного пользователя, точнее группу пользователей. Пользователи младше 30 лет получают сообщения в более веселом тоне, с модными словечками, а люди старше 50 – нейтральные, уважительные тексты. В теории это поднимет конверсии за счет повышения рапорта с пользователем, и логично предположить, что полезно это будет в основном продуктам с разными сегментами пользователей.
То есть, имеем локаль ru_RU – русский язык в Российской его версии, и на его основе создаем ru_RU-молодежный .
Преимущество #4
Появляется сильно упрощенная возможность проведения тестов A/B. Как многим давно известно, текст напрямую влияет на уровень конверсий на странице – исправив одно слово, можно замотивировать большую группу пользователей что-то сделать, или наоборот перестать что-то делать. Сейчас на рынке нет прямо уж очень простых способов делать такие тесты. Как правило, разработчики делают что-то вроде:

Имеем два шаблона home.blade.php и home__treatment.blade.php, в первом у нас так называемая control-версия теста, его старый вид, а во втором файле treatment-версия – версия, эффективность которой мы тестируем. Пользователям при посещении страницы выставляется кука или флаг в сессии, которая будет определять какую версию в дальнейшем они будут видеть. Кроме того, аналитика (допустим, Google Analytics) будет также получать этот флаг, чтобы в дальнейшем можно было делать сравнительный анализ.
Представим, что в нашей гипотетический админке появилась еще кнопка "A/B-тест":

Нажали на кнопочку и предоставили вторую версию текста:

А наш сервис аналитики (скажем, Google Analytics) берет правильную метку (control или treatment) либо из нашего приложения, либо из этого сервиса по работе с текстами. Добавили вторую версию текста и через неделю посмотрели как изменился Bounce Rate или количество кликов на странице, оставили одну – ту, что эффективнее. Тривиально.
Преимущество #5
Подключать сервисы переводов (вроде Gengo) или сервисы исправления грамматических ошибок настолько тривиально, что даже не стоит подробно об этом писать ;)
Послесловие
Конечно, тут бы имела место быть какая-то цена миграции – время и силы, затраченные на то, чтобы обернуть все тексты в коде в эти функцию и директиву, но этот момент присутствует и в существующих в индустрии вариантах #2 и #3. Хочется добавить, чтобы преимуществ от подобного сервиса достаточно много даже для моно-языковых продуктов.
Контроллировать практику обертки текстов можно через простой webhook, тогда все pull-реквесты будут автоматически проверятся:

Несмотря на то, что я немного поигрался с кодом и проверил, что все вышеизложенное возможно, эта статья обсуждает гипотетический продукт или утилиту. Цель статьи – собрать мнения, ваши мнения.
Пользовались бы Вы такой вещью?



