
Перед вами четвёртый материал о разработке REST-серверов на Go. Здесь мы поговорим о том, как можно воспользоваться OpenAPI и Swagger для реализации стандартизированного подхода к описанию REST API, и о том, как генерировать Go-код на основе спецификации OpenAPI.
Перевод предыдущих частей:
❒ Разработка REST-серверов на Go. Часть 1: стандартная библиотека.
❒ Разработка REST-серверов на Go. Часть 2: применение маршрутизатора gorilla/mux
❒ Разработка REST-серверов на Go. Часть 3: использование веб-фреймворка Gin

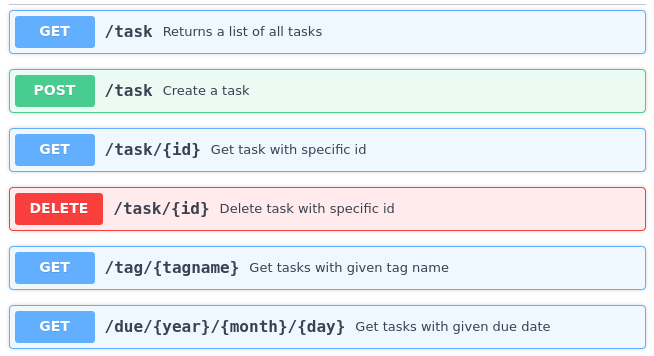
В первой части этой серии материалов, когда мы описывали REST API, я говорил о том, что описание этого API создано специально для нашего примера. Это описание представляет собой просто список методов (путей) с комментариями:
Было бы неплохо, если бы существовал стандартный способ описания API. «Стандартным» я называю такое описание, которое могло бы играть роль контракта между серверами и клиентами. Более того, стандартное описание API выглядело бы совершенно понятным для тех разработчиков, которые не знакомы с особенностями конкретного проекта. Такое описание, кроме того, могло бы быть понятным не только людям, но и машинам, что привело бы к возможности автоматизации различных задач, связанных с API.
Проект Swagger появился в 2011 году как IDL (Interface Description Language, язык описания интерфейсов) для описания REST API.

Причиной появления Swagger было стремление к созданию системы автоматического генерирования документации для REST API, а так же — желание автоматизации испытаний API. Вспомните скрипт manual.sh из репозитория к первому материалу этой серии. Этот скрипт содержит набор команд
В 2014 году вышла версия Swagger 2.0, а в 2016 множество крупных IT-компаний объединили усилия в деле создании спецификация OpenAPI, жёстко стандартизированного варианта Swagger 3.0.
Официальный сайт Swagger и OpenAPI, https://swagger.io, поддерживает Компания SmartBear Software.
Во всех этих хитросплетениях технологий можно и запутаться. Легче всего разложить сведения о них в голове можно, если помнить о том, что OpenAPI — это современное название спецификации, а словом «Swagger» обычно называют инструменты, построенные на основе этой спецификации (правда, можно ещё столкнуться и с таким понятием, как «спецификация Swagger», особенно — если речь идёт о версиях Swagger, вышедших раньше, чем версия 3.0).
Начнём с повторения нашего любимого упражнения — с переписывания сервиса приложения для управления задачами. В этот раз мы воспользуемся OpenAPI и Swagger.
Для того чтобы это сделать, я почитал документацию OpenAPI 3.0 и воспользовался редактором Swagger для ввода спецификации в формате YAML. Это заняло некоторое время. В результате в моём распоряжении оказался этот файл.
Например, следующий фрагмент кода представляет собой описание запроса
Здесь
Это — описание схемы данных. Обратите внимание на то, что мы можем указывать типы для полей данных, что (как минимум — в теории) может пригодиться при автоматическом генерировании кода для валидации этих данных.
Вся эта работа принесла плоды сразу же после её завершения. А именно — она дала мне приятно выглядящую, цветную документацию для API.
Фрагмент документации из редактора Swagger
Это — всего лишь скриншот. В настоящей документации можно щёлкать по её элементам, их можно раскрывать, можно видеть чёткие описания параметров запросов, ответов, JSON-схем и прочего подобного.
Но это, правда, далеко не всё. Исходя из предположения о том, что сервер, поддерживающий наш API, общедоступен, взаимодействовать с этим сервером можно прямо из редактора Swagger. Это похоже на то, как мы пользовались для той же цели командами
Представьте себе, что занимаетесь разработкой API в рамках приложения, предназначенного для управления задачами. На определённом этапе работы принято решение о том, что этот API можно опубликовать для того чтобы к нему можно было бы обращаться с клиентских систем различных видов (это могут быть веб-клиенты, мобильные клиенты и так далее). Если ваш API описан с использованием OpenAPI/Swagger, это значит, что у вас имеется автоматически созданная документация и интерфейс для клиентов, позволяющий им экспериментировать с API. Это вдвойне важно в том случае, если среди пользователей вашего API есть люди, не являющиеся программистами. Например, это могут быть UX-дизайнеры, технические писатели, продакт-менеджеры, которым нужно разобраться в API, но которые не особенно привыкли к самостоятельному написанию скриптов.
Более того, OpenAPI стандартизирует и такие вещи, как авторизация, что тоже может оказаться очень кстати. Наш подход из первой статьи, когда мы пользовались произвольным описанием API, ни в какое сравнение не идёт с тем, что даёт нам OpenAPI.
После того, как подготовлена спецификация API, можно взглянуть на дополнительные инструменты, имеющиеся в экосистеме Swagger. Например — это Swagger UI и Swagger Inspector. Спецификацию API можно даже использовать в роли вспомогательного инструмента при интеграции REST-сервера в инфраструктуру облачного провайдера. Например, в GCP имеется система управления API Cloud Endpoints, поддерживающая спецификацию OpenAPI. Она, кроме прочего, позволяет настраивать мониторинг и анализ опубликованных API. Описание API предоставляется этой системе с использованием OpenAPI.
Возможности, которые обещают нам OpenAPI/Swagger, выходят далеко за пределы автоматического создания документации. На основе соответствующих спецификаций можно автоматически генерировать код клиентов и серверов.
Я, следуя официальной инструкции проекта Swagger-Codegen, сгенерировал «скелет» кода Go-сервера. Затем я дописал код обработчиков для реализации функционала нашего сервера. Код проекта можно найти здесь. Последовательность действий, выполненная мной при подготовке этого кода, описана в файле
В коде, сгенерированном автоматически, для маршрутизации используется gorilla/mux (это похоже подход к маршрутизации из второй статьи). Там, в файле
В процессе работы я сделал некоторые выводы относительно ограничений такого подхода:
В целом же могу сказать, что преимущества автоматически сгенерированного кода кажутся мне сомнительными. Эта возможность позволяет сэкономить относительно немного времени, учитывая то, что мне, всё равно, пришлось переписывать немало кода. Более того, так как я не использовал автоматически сгенерированный базовый код в его исходном виде, экономия времени относится только к созданию этого базового кода. Если я поменяю OpenAPI-описание, я не могу просто предложить генератору кода обновить существующий код сервера, так как в этот код уже внесены серьёзные изменения.
Инструмент swagger-codegen умеет ещё и создавать код клиентов, в том числе и на Go. Иногда это может оказаться очень кстати, но с моей точки зрения подобный код выглядит несколько запутанным. Он, как и в случае с серверным кодом, возможно, может сыграть роль хорошей отправной точки в деле написания собственного клиента, но механизм его автоматического создания вряд ли может стать частью некоего CI/CD-процесса.
Спецификации OpenAPI представлены в виде YAML (или JSON), их формат хорошо документирован. В результате неудивительно то, что существует далеко не один инструмент, позволяющий генерировать на основе этих спецификаций серверный код. В предыдущем разделе мы рассмотрели «официальный» генератор кода Swagger, но есть и другие подобные инструменты.
В случае с Go популярным инструментом такого рода является go-swagger. В
Чем этот генератор отличается от генератора из swagger-codegen?
tl;dr В настоящий момент его главное отличие заключается в том, что он реально работает.
Проект swagger-codegen генерирует рабочий Go-код лишь для клиента, и даже тут он поддерживает лишь плоские модели. А код Go-сервера, сгенерированный swagger-codegen — это, в основном, нечто вроде кода-заглушки.
Я попробовал сгенерировать код сервера с помощью go-swagger. Так как код, сгенерированный этим средством, достаточно велик, я не привожу тут ссылку на него. Тут я лишь поделюсь впечатлениями от работы с go-swagger.
В первую очередь отмечу, что go-swagger поддерживает лишь спецификацию Swagger 2.0, а не более новую версию OpenAPI 3.0. Это довольно-таки печально, но я нашёл один онлайновый инструмент, который умеет конвертировать описания API, выполненные с использованием спецификации OpenAPI 3.0 в описания формата OpenAPI 2.0 (Swagger). Описание нашего API в формате Swagger 2.0 тоже имеются в репозитории проекта.
В серверном коде, сгенерированном go-swagger, определённо, реализовано больше возможностей, чем в коде, сгенерированном swagger-codegen. Но за всё надо платить. Дополнительные возможности означают привязку к особому фреймворку, разработанному создателями go-swagger. Сгенерированный код имеет множество зависимостей от пакетов из репозиториев go-openapi, в нём код из этих пакетов широко используется для обеспечения работы сервера. Там есть даже код для разбора флагов. Собственно, почему бы ему там не быть?
Если вам нравится фреймворк, используемый в коде, генерируемом go-swagger, то вам вполне может подойти этот код. Но если у вас на этот счёт есть свои идеи — вроде использования Gin или собственного маршрутизатора, то решения разработчиков go-swagger, отразившиеся на готовом коде, могут вас не устроить.
С помощью go-swagger можно сгенерировать и код клиента, который, как и код сервера, отличается хорошим функционалом и отражает точку зрения разработчиков go-swagger на то, каким должен быть такой код. Правда, если нужно всего лишь быстро создать такой код для целей тестирования, то, что он отражает мнение других людей, не будет выглядеть серьёзной проблемой.
После публикации этого материала мне посоветовали попробовать ещё один инструмент для генерирования кода — oapi-codegen. Код нашего сервера, созданный с помощью этого инструмента, можно найти здесь.
Я должен признать, что результаты работы oapi-codegen понравились мне гораздо больше, чем код, созданный другими опробованными мной инструментами. Это — простой и чистый код, при работе с которым легко отделить то, что сгенерировано автоматически, от того, что написано самостоятельно. Средство oapi-codegen даже понимает спецификации OpenAPI 3! Единственное, к чему я могу придраться, это то, что тут используется зависимость от пакета стороннего разработчика лишь для того, чтобы реализовать привязку параметров запроса. Лучше было бы, если бы это можно было как-то настраивать. Например — чтобы имелся бы некий параметр, позволяющий выбрать между использованием кода, входящего в состав сервера, и кода, получаемого из стороннего пакета.
Что если у вас уже имеется реализация REST-сервера, но вам очень понравилась идея его описания с помощью OpenAPI? Можно ли сгенерировать это описание на основе кода сервера?
Да — можно! Сгенерировать OpenAPI-описание сервера (правда, это снова будет описание в формате спецификации 2.0) можно с помощью специальных комментариев-аннотаций и инструментов наподобие swaggo/swag. Затем с полученным описанием можно поработать, используя различные Swagger-инструменты и, например, создать на его основе документацию.
На самом деле, это выглядит как весьма привлекательная возможность для тех, кто привык писать REST-серверы по-своему и не хочет переходить к новой схеме работы только ради того, чтобы пользоваться Swagger.
Представьте, что у вас имеется приложение, которому необходимо работать с REST API, и при этом вам приходится выбирать между двумя сервисами.
Исходя из предположения о том, что в остальном эти сервисы абсолютно одинаковы, подумайте о том, какой из них вы решите опробовать первым? По моему скромному мнению выбор очевиден. Это, конечно, сервис №2 — благодаря возможностям OpenAPI в плане генерирования документации и благодаря наличию стандартизированных контрактов между REST-серверами и клиентами. Менее очевиден ответ на вопрос о том, насколько глубоко стоит внедрять в проекты инструменты из экосистемы Swagger.
Я с удовольствием опишу мой API в формате OpenAPI и воспользуюсь инструментом для создания документации. А вот в деле автоматического генерирования кода я буду действовать уже более осторожно. Лично я предпочитаю достаточно сильно контролировать мой серверный код. В частности, речь идёт об используемых в нём зависимостях и о его структуре. Я вижу смысл в автоматическом создании серверного кода для целей быстрого прототипирования или для каких-то экспериментов, но я не использовал бы автоматически сгенерированный серверный код как базу для собственного проекта. Конечно, я иначе бы смотрел на этот вопрос, если бы мне надо было бы еженедельно выпускать новую версию REST-сервера. В поисках баланса между использованием чужого кода и кода своего, стоит помнить о том, что преимущества от использования зависимостей обратно пропорциональны усилиям, потраченным на программный проект.
На самом деле, инструменты вроде swaggo/swag могут предложить разработчикам отличный баланс между зависимостями и собственными усилиями. Серверный код пишут с использованием самостоятельно выбранного подхода или фреймворка и оснащают его особыми комментариями, описывающими REST API. После этого соответствующий инструмент генерирует на основе этих комментариев спецификацию OpenAPI. Эту спецификацию можно использовать для создания документации к проекту или чего угодно другого, что можно создать на её основе. При таком подходе у нас появляется дополнительная полезная возможность — наличие единственного источника истины в виде комментариев. Этот источник расположен в максимальной близости к исходному коду, реализующему механизмы, описываемые в комментариях. А такой подход, кстати, всегда полезен в деле разработки программного обеспечения.
Пользуетесь ли вы спецификациями OpenAPI при создании REST-серверов?
Перевод предыдущих частей:
❒ Разработка REST-серверов на Go. Часть 1: стандартная библиотека.
❒ Разработка REST-серверов на Go. Часть 2: применение маршрутизатора gorilla/mux
❒ Разработка REST-серверов на Go. Часть 3: использование веб-фреймворка Gin
Зачем это всё?
В первой части этой серии материалов, когда мы описывали REST API, я говорил о том, что описание этого API создано специально для нашего примера. Это описание представляет собой просто список методов (путей) с комментариями:
POST /task/ : создаёт задачу и возвращает её ID
GET /task/<taskid> : возвращает одну задачу по её ID
GET /task/ : возвращает все задачи
DELETE /task/<taskid> : удаляет задачу по ID
GET /tag/<tagname> : возвращает список задач с заданным тегом
GET /due/<yy>/<mm>/<dd> : возвращает список задач, запланированных на указанную дату
Было бы неплохо, если бы существовал стандартный способ описания API. «Стандартным» я называю такое описание, которое могло бы играть роль контракта между серверами и клиентами. Более того, стандартное описание API выглядело бы совершенно понятным для тех разработчиков, которые не знакомы с особенностями конкретного проекта. Такое описание, кроме того, могло бы быть понятным не только людям, но и машинам, что привело бы к возможности автоматизации различных задач, связанных с API.
Swagger и OpenAPI
Проект Swagger появился в 2011 году как IDL (Interface Description Language, язык описания интерфейсов) для описания REST API.
Причиной появления Swagger было стремление к созданию системы автоматического генерирования документации для REST API, а так же — желание автоматизации испытаний API. Вспомните скрипт manual.sh из репозитория к первому материалу этой серии. Этот скрипт содержит набор команд
curl, предназначенных для взаимодействия с сервером. Ясно, что подобные команды могут быть сгенерированы автоматически на основе стандартизированного описания REST API. Это способно сэкономить много времени.В 2014 году вышла версия Swagger 2.0, а в 2016 множество крупных IT-компаний объединили усилия в деле создании спецификация OpenAPI, жёстко стандартизированного варианта Swagger 3.0.
Официальный сайт Swagger и OpenAPI, https://swagger.io, поддерживает Компания SmartBear Software.
Во всех этих хитросплетениях технологий можно и запутаться. Легче всего разложить сведения о них в голове можно, если помнить о том, что OpenAPI — это современное название спецификации, а словом «Swagger» обычно называют инструменты, построенные на основе этой спецификации (правда, можно ещё столкнуться и с таким понятием, как «спецификация Swagger», особенно — если речь идёт о версиях Swagger, вышедших раньше, чем версия 3.0).
Создание сервиса системы управления задачами с применением OpenAPI
Начнём с повторения нашего любимого упражнения — с переписывания сервиса приложения для управления задачами. В этот раз мы воспользуемся OpenAPI и Swagger.
Для того чтобы это сделать, я почитал документацию OpenAPI 3.0 и воспользовался редактором Swagger для ввода спецификации в формате YAML. Это заняло некоторое время. В результате в моём распоряжении оказался этот файл.
Например, следующий фрагмент кода представляет собой описание запроса
GET /task/, который должен возвращать список всех задач. В спецификации OpenAPI можно описать произвольное количество путей, с каждым из которых сопоставлены различные методы (GET, POST и так далее). В описаниях путей имеются сведения об их параметрах и об ответах, а так же о JSON-схемах./task:
get:
summary: Returns a list of all tasks
responses:
'200':
description: A JSON array of task IDs
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/Task'
Здесь
components/schemas/Task представляет собой ссылку на модель Task:components:
schemas:
Task:
type: object
properties:
id:
type: integer
text:
type: string
tags:
type: array
items:
type: string
due:
type: string
format: date-time
Это — описание схемы данных. Обратите внимание на то, что мы можем указывать типы для полей данных, что (как минимум — в теории) может пригодиться при автоматическом генерировании кода для валидации этих данных.
Вся эта работа принесла плоды сразу же после её завершения. А именно — она дала мне приятно выглядящую, цветную документацию для API.
Фрагмент документации из редактора Swagger
Это — всего лишь скриншот. В настоящей документации можно щёлкать по её элементам, их можно раскрывать, можно видеть чёткие описания параметров запросов, ответов, JSON-схем и прочего подобного.
Но это, правда, далеко не всё. Исходя из предположения о том, что сервер, поддерживающий наш API, общедоступен, взаимодействовать с этим сервером можно прямо из редактора Swagger. Это похоже на то, как мы пользовались для той же цели командами
curl, но теперь речь идёт об использовании механизма, в основе которого лежит автоматическое генерирование кода, и который учитывает особенности схемы данных API.Представьте себе, что занимаетесь разработкой API в рамках приложения, предназначенного для управления задачами. На определённом этапе работы принято решение о том, что этот API можно опубликовать для того чтобы к нему можно было бы обращаться с клиентских систем различных видов (это могут быть веб-клиенты, мобильные клиенты и так далее). Если ваш API описан с использованием OpenAPI/Swagger, это значит, что у вас имеется автоматически созданная документация и интерфейс для клиентов, позволяющий им экспериментировать с API. Это вдвойне важно в том случае, если среди пользователей вашего API есть люди, не являющиеся программистами. Например, это могут быть UX-дизайнеры, технические писатели, продакт-менеджеры, которым нужно разобраться в API, но которые не особенно привыкли к самостоятельному написанию скриптов.
Более того, OpenAPI стандартизирует и такие вещи, как авторизация, что тоже может оказаться очень кстати. Наш подход из первой статьи, когда мы пользовались произвольным описанием API, ни в какое сравнение не идёт с тем, что даёт нам OpenAPI.
После того, как подготовлена спецификация API, можно взглянуть на дополнительные инструменты, имеющиеся в экосистеме Swagger. Например — это Swagger UI и Swagger Inspector. Спецификацию API можно даже использовать в роли вспомогательного инструмента при интеграции REST-сервера в инфраструктуру облачного провайдера. Например, в GCP имеется система управления API Cloud Endpoints, поддерживающая спецификацию OpenAPI. Она, кроме прочего, позволяет настраивать мониторинг и анализ опубликованных API. Описание API предоставляется этой системе с использованием OpenAPI.
Автоматическое генерирование базового кода для Go-сервера
Возможности, которые обещают нам OpenAPI/Swagger, выходят далеко за пределы автоматического создания документации. На основе соответствующих спецификаций можно автоматически генерировать код клиентов и серверов.
Я, следуя официальной инструкции проекта Swagger-Codegen, сгенерировал «скелет» кода Go-сервера. Затем я дописал код обработчиков для реализации функционала нашего сервера. Код проекта можно найти здесь. Последовательность действий, выполненная мной при подготовке этого кода, описана в файле
README. Сервер проходит все автоматизированные тесты.В коде, сгенерированном автоматически, для маршрутизации используется gorilla/mux (это похоже подход к маршрутизации из второй статьи). Там, в файле
api_default.go, создаются заготовки для обработчиков. В эти обработчики я поместил уже знакомый вам по предыдущим материалам код. Например:func TaskIdDelete(w http.ResponseWriter, r *http.Request) {
id, err := strconv.Atoi(mux.Vars(r)["id"])
if err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
err = store.DeleteTask(id)
if err != nil {
http.Error(w, err.Error(), http.StatusNotFound)
}
}
В процессе работы я сделал некоторые выводы относительно ограничений такого подхода:
- Именование пакетов и команды импорта в сгенерированном коде пришлось переделать, так как в исходном виде они не позволяют нормально работать, по крайней мере — при использовании модулей Go. Мне пришлось всё немного реструктурировать.
- Форматирование кода в некоторых из сгенерированных файлов по какой-то причине не соответствует стилю, который устраивает утилиту
gofmt. - В коде используются глобальные сущности, а ранее мы всегда пользовались структурами данных Go, методы которых регистрировали в роли обработчиков запросов (и, в итоге, поля экземпляра структуры играли роль общедоступного хранилища данных). А в серверном коде, сгенерированном Swagger, обработчики являются функциями верхнего уровня.
- Несмотря на то, что в описании API, сделанном средствами OpenAPI, есть схема данных, прямо указывающая на использование целочисленных значений для некоторых из параметров путей (например — это день, месяц и год в пути
due/), в автоматически сгенерированном коде сервера нет системы валидации значений таких параметров. Более того, хотя gorilla/mux поддерживает использование регулярных выражений при настройке параметров путей, в сгенерированном коде эта возможность не используется. В результате мне пришлось снова вручную написать код для валидации параметров.
В целом же могу сказать, что преимущества автоматически сгенерированного кода кажутся мне сомнительными. Эта возможность позволяет сэкономить относительно немного времени, учитывая то, что мне, всё равно, пришлось переписывать немало кода. Более того, так как я не использовал автоматически сгенерированный базовый код в его исходном виде, экономия времени относится только к созданию этого базового кода. Если я поменяю OpenAPI-описание, я не могу просто предложить генератору кода обновить существующий код сервера, так как в этот код уже внесены серьёзные изменения.
Инструмент swagger-codegen умеет ещё и создавать код клиентов, в том числе и на Go. Иногда это может оказаться очень кстати, но с моей точки зрения подобный код выглядит несколько запутанным. Он, как и в случае с серверным кодом, возможно, может сыграть роль хорошей отправной точки в деле написания собственного клиента, но механизм его автоматического создания вряд ли может стать частью некоего CI/CD-процесса.
Испытание альтернативных генераторов кода
Спецификации OpenAPI представлены в виде YAML (или JSON), их формат хорошо документирован. В результате неудивительно то, что существует далеко не один инструмент, позволяющий генерировать на основе этих спецификаций серверный код. В предыдущем разделе мы рассмотрели «официальный» генератор кода Swagger, но есть и другие подобные инструменты.
В случае с Go популярным инструментом такого рода является go-swagger. В
README этого проекта есть следующий раздел:Чем этот генератор отличается от генератора из swagger-codegen?
tl;dr В настоящий момент его главное отличие заключается в том, что он реально работает.
Проект swagger-codegen генерирует рабочий Go-код лишь для клиента, и даже тут он поддерживает лишь плоские модели. А код Go-сервера, сгенерированный swagger-codegen — это, в основном, нечто вроде кода-заглушки.
Я попробовал сгенерировать код сервера с помощью go-swagger. Так как код, сгенерированный этим средством, достаточно велик, я не привожу тут ссылку на него. Тут я лишь поделюсь впечатлениями от работы с go-swagger.
В первую очередь отмечу, что go-swagger поддерживает лишь спецификацию Swagger 2.0, а не более новую версию OpenAPI 3.0. Это довольно-таки печально, но я нашёл один онлайновый инструмент, который умеет конвертировать описания API, выполненные с использованием спецификации OpenAPI 3.0 в описания формата OpenAPI 2.0 (Swagger). Описание нашего API в формате Swagger 2.0 тоже имеются в репозитории проекта.
В серверном коде, сгенерированном go-swagger, определённо, реализовано больше возможностей, чем в коде, сгенерированном swagger-codegen. Но за всё надо платить. Дополнительные возможности означают привязку к особому фреймворку, разработанному создателями go-swagger. Сгенерированный код имеет множество зависимостей от пакетов из репозиториев go-openapi, в нём код из этих пакетов широко используется для обеспечения работы сервера. Там есть даже код для разбора флагов. Собственно, почему бы ему там не быть?
Если вам нравится фреймворк, используемый в коде, генерируемом go-swagger, то вам вполне может подойти этот код. Но если у вас на этот счёт есть свои идеи — вроде использования Gin или собственного маршрутизатора, то решения разработчиков go-swagger, отразившиеся на готовом коде, могут вас не устроить.
С помощью go-swagger можно сгенерировать и код клиента, который, как и код сервера, отличается хорошим функционалом и отражает точку зрения разработчиков go-swagger на то, каким должен быть такой код. Правда, если нужно всего лишь быстро создать такой код для целей тестирования, то, что он отражает мнение других людей, не будет выглядеть серьёзной проблемой.
После публикации этого материала мне посоветовали попробовать ещё один инструмент для генерирования кода — oapi-codegen. Код нашего сервера, созданный с помощью этого инструмента, можно найти здесь.
Я должен признать, что результаты работы oapi-codegen понравились мне гораздо больше, чем код, созданный другими опробованными мной инструментами. Это — простой и чистый код, при работе с которым легко отделить то, что сгенерировано автоматически, от того, что написано самостоятельно. Средство oapi-codegen даже понимает спецификации OpenAPI 3! Единственное, к чему я могу придраться, это то, что тут используется зависимость от пакета стороннего разработчика лишь для того, чтобы реализовать привязку параметров запроса. Лучше было бы, если бы это можно было как-то настраивать. Например — чтобы имелся бы некий параметр, позволяющий выбрать между использованием кода, входящего в состав сервера, и кода, получаемого из стороннего пакета.
Генерирование спецификаций на основе кода
Что если у вас уже имеется реализация REST-сервера, но вам очень понравилась идея его описания с помощью OpenAPI? Можно ли сгенерировать это описание на основе кода сервера?
Да — можно! Сгенерировать OpenAPI-описание сервера (правда, это снова будет описание в формате спецификации 2.0) можно с помощью специальных комментариев-аннотаций и инструментов наподобие swaggo/swag. Затем с полученным описанием можно поработать, используя различные Swagger-инструменты и, например, создать на его основе документацию.
На самом деле, это выглядит как весьма привлекательная возможность для тех, кто привык писать REST-серверы по-своему и не хочет переходить к новой схеме работы только ради того, чтобы пользоваться Swagger.
Итоги?
Представьте, что у вас имеется приложение, которому необходимо работать с REST API, и при этом вам приходится выбирать между двумя сервисами.
- У сервиса №1 имеется описание API, выполненное в произвольном формате, в текстовом файле, с примерами взаимодействия с сервером, основанными на
curl. - API сервиса №2 описано с использованием спецификации OpenAPI. К нему подготовлена аккуратная стандартная документация, имеются онлайн-инструменты, которые позволяют опробовать этот сервис без необходимости открывать терминал.
Исходя из предположения о том, что в остальном эти сервисы абсолютно одинаковы, подумайте о том, какой из них вы решите опробовать первым? По моему скромному мнению выбор очевиден. Это, конечно, сервис №2 — благодаря возможностям OpenAPI в плане генерирования документации и благодаря наличию стандартизированных контрактов между REST-серверами и клиентами. Менее очевиден ответ на вопрос о том, насколько глубоко стоит внедрять в проекты инструменты из экосистемы Swagger.
Я с удовольствием опишу мой API в формате OpenAPI и воспользуюсь инструментом для создания документации. А вот в деле автоматического генерирования кода я буду действовать уже более осторожно. Лично я предпочитаю достаточно сильно контролировать мой серверный код. В частности, речь идёт об используемых в нём зависимостях и о его структуре. Я вижу смысл в автоматическом создании серверного кода для целей быстрого прототипирования или для каких-то экспериментов, но я не использовал бы автоматически сгенерированный серверный код как базу для собственного проекта. Конечно, я иначе бы смотрел на этот вопрос, если бы мне надо было бы еженедельно выпускать новую версию REST-сервера. В поисках баланса между использованием чужого кода и кода своего, стоит помнить о том, что преимущества от использования зависимостей обратно пропорциональны усилиям, потраченным на программный проект.
На самом деле, инструменты вроде swaggo/swag могут предложить разработчикам отличный баланс между зависимостями и собственными усилиями. Серверный код пишут с использованием самостоятельно выбранного подхода или фреймворка и оснащают его особыми комментариями, описывающими REST API. После этого соответствующий инструмент генерирует на основе этих комментариев спецификацию OpenAPI. Эту спецификацию можно использовать для создания документации к проекту или чего угодно другого, что можно создать на её основе. При таком подходе у нас появляется дополнительная полезная возможность — наличие единственного источника истины в виде комментариев. Этот источник расположен в максимальной близости к исходному коду, реализующему механизмы, описываемые в комментариях. А такой подход, кстати, всегда полезен в деле разработки программного обеспечения.
Пользуетесь ли вы спецификациями OpenAPI при создании REST-серверов?


