

Данная статья, является продолжением, описания хода учебного исследовательского проекта по разработке рекомендательной системы.
В первой части мы остановились на том, что модель, полученная с использованием библиотеки LightFM, не оправдала моих ожиданий, можно ли сделать что-то лучше?
Может что-то у нас не так с данными?
Из столбцов датасета которые у нас есть

я использовал только две ключевые сущности id пользователя и товара и одно производное, рассчитанный ранг товара для пары Покупатель - Товар. Там все без обмана.
Может быть ошибка в выборе целевой переменной?
Но... мне представляется, что она по всем параметрам похожа на рейтинг со звездочками, тоже как голосование, только рублем.
А вот то, что для построения модели я использовал только 1/5 данных, это заставляет задуматься. И к этому мы вернемся позже, когда определимся с концептуальными вопросами исследования.
О смысле разработки рекомендательной системы
Цель модели, которая создается в исследовании, в своей идеальной реализации, заключается в формировании ранжированного перечня товаров, которые предпочтет покупатель. Предпочтет, это значит купит то, что ему рекомендуют - и тогда рекомендация успешна или не купит, тогда рекомендательная система работает не очень хорошо.
Посмотрим где мы находимся сейчас: обладаем ли мы знаниями о реакции покупателя на рекомендацию - нет, поскольку имеем на текущий момент информацию только о том, что он купил, а не о том, как он отреагировал на рекомендацию.
Значит ли то, что раз мы не обладаем этой информацией мы строим не рекомендательную систему?
Полагаю, что у каждого на это есть свой ответ. Я же отвечаю так - для того, чтобы войти в реку, нужно до нее дойти, т.е. пока мы не представим рекомендацию, мы не сможем получить на нее реакцию. Кстати, "воспитанию" агента правильной реакции на изменения во внешней среде, посвящено целое направление "обучение с подкреплением" - Reinforcement learning, которое я также изучил в курсе Otus и это то направление о котором я также думал, при выборе темы для учебного проекта.
Резюмируя, считаю сам и предлагаю согласиться с этим читателю, что до конца этой статьи и исследования о котором в ней говорится, мы разрабатываем модель, которая сможет предлагать покупателю 10 товаров, специфичные для него и которые он должен захотеть купить.
Возможно вас полностью устроила предыдущая фраза, но у меня она у меня вызвала еще один вопрос: это будут покупки вместе или вместо?
Готов ли будет покупатель, после ознакомления с нашей рекомендации, удалить свою традиционную корзину и положит туда предложенный список или ему должно понравиться что-то, что стоит "добавить", например к коле ром, к пюрешке грудку?
Я склоняюсь к тому, что более интересным, с точки зрения бизнеса, было бы второе - увеличение чека, на одну-две позиции.
О путях движения к цели
Вопросы
Анализируя подходы, закладываемые в функционирование существующих рекомендательных системы, можно видеть, что предлагаемые ими решения направлены на максимальное использования чрезвычайно скудной информации о выборе покупателем товара. В своей предельной форме, то, что мы имеем - это факт покупки, идентификатор покупателя, идентификатор товара/услуги и рейтинг. Именно такими данными я воспользовался в первой части при построении модели с помощью LightFM. Мощнейший алгоритм многофакторного ранжирования, по данным матрицы, в которую помещаются данные, формирует ранг товара в иерархии предпочтений покупателя в зависимости от его связи с другими покупателями - завораживающая математика, а получаемый результат это лучший вариант из имеющейся информации.
Что может измениться, если "подлить" информации в наши данные, если наряду c минимально необходимыми, у нас появятся дополнительные "фичи"?
Что они могут значить, и на что повлиять?
Первое и очевидное: новые данные могут нести информацию (конечно не всегда полную) о причинах и условиях осуществления покупателем покупки. Это важно, поскольку теперь это не просто "рейтинг" / "звездочки мишлена", но и то, как они возникли.
Позволит это знание приблизиться к получению рекомендаций?
Думаю да, поскольку если мы будем знать, что зажигает звезды влияет на принятие решения о покупке или приоритетности одной покупки над другой, мы получим ключ, как войти в эту дверь принятия решений, как бы пафосно это не звучало.
Методы
Решение о связи рейтинга фичей покупателя и товара, может быть получено методами классификации и/или регрессии. При успешном результате классификации мы получим "потребительскую модель" конкретного покупателя, как открытую книгу для рекомендаций ему.
Дотошный читатель, несомненно задастся вопросом, хорошо, допустим с помощью классификации мы научимся прогнозировать рейтинг в пространстве обитания одного покупателя(а оно конечно замкнутое и иерархия достаточна устойчива), как же мы можем на нее повлиять и сможем ли?
Ответ на вопрос "сможем или нет" и с какой вероятностью лучше всего получить в рекомендательной системе с элементами RL, а ответ на вопрос "как взламывать будем", конечно с привлечением покупательский опыт других покупателей, но об этом и кое-чем другом поговорим по дороге, далее.
Идеальная модель
Представляя модель идеал, работать должно так:
ввел в нее ФИО id покупателя и получить для него рекомендацию что-то такое, голодным не смотреть.
пример ответа системы
user_1006
Покупки
['Натс']
['Чудо обыкновенное классическое']
['Мармелад Haribo']
Рекомендации
['Блинчики с творогом и сметаной, 210 грамм']
['Сникерс']
['Куриные шашлычки с картофелем Айдахо, 330 грамм']
['Филе куриное отварное с гречкой и черри, 270 грамм']
['Оладушки тыквенные, 140 грамм']
user_101
Покупки
['Зразы картофельные с грибами, 200 грамм']
Рекомендации
['Морковь с сыром и чесноком, 250 грамм']
['Салат Коул-Слоу постный, 200 грамм']
['Леденцы "Холс" оригинальные']
['Лобио из красной фасоли с орехами, 190 грамм']
['Сэндвич с курицей и маринованными огурцами, 180 грамм']
В качестве факультатива, не могу не обратить внимание на интересный сравнительный анализ классификации и ранжирования, в применении к рекомендациям.
Ну а я продолжу. - если мы хотим воспользоваться классификацией/регрессией, стоит опять стоит посмотреть на данные.
EDA 2.0
Итак, что у нас есть:
re_work=pd.read_csv('/content/drive/MyDrive/re_work.csv',sep=',')
re_work.head()
может быть, никакая классификация не нужна и выбор покупателя однозначен - первый в рейтинге всегда один, а второй ? Проверим это:
user_rang_count=re_merg.groupby(['user_str','rank'])['weight'].sum().reset_index()
user_rang_count.columns=['user_str', 'rank', 'count']
user_rang_count[user_rang_count['rank']<11].plot.scatter('rank','count')")
Из данного графика видно, что для большого числа пользователей

ситуация когда приоритет выбора товара не является однозначным, широко распространена - покупатели разнообразят свой рацион, выбирая разное в различных условиях. А наша задача "хакнуть" их логику.
Не вдаваясь в объяснение логики выбора, для решения задачи классификации, для этого решил воспользоваться библиотекой LightGBM, не буду возражать, если кто-то из читателей имеет другие предпочтения и готов привести в комментариях основания для своего выбора, но у меня, извините LightGBM.
подготовка данных для классификации

Как видим, данные в таком виде нельзя использовать для классификации. В данных присутствуют текстовые значения: для категорий товаров и и идентификаторов. Несмотря на то, что для переменной shop использованы цифровые значения, вероятнее всего это идентификатор в каком-то отчетном списке и его порядковый номер может вводить модель в заблуждение, ну и конечно артефакты в виде даты, года и вспомогательной переменной, тоже излишни.
")
Необходима ревизия данных. Почему бы не произвести энкодинг переменных, а заодно и Feature Engineering (кстати, этим двум темам были также проведены живые вебинары курса OTUS, а помимо этого, разбирали и пробовали на вкус AutoML, ну это к слову).
Для энкодинга, можно написать что-то такое
X=re_work_FM['Month']
ce_bin = ce.BinaryEncoder(cols = ['Month'])
mon_id_df=ce_bin.fit_transform(X)
.....
re_work_FM=pd.concat((re_work_FM,cat_id_df, shop_id_df,mon_id_df,hour_id_df,Minute_id_df,week_day_id_df),axis=1)
re_work_FM.drop(['cat_id','shop','Month','Hour','Minute','week_day'],axis=1,inplace=True)
и получить

так конечно можно....
Но мы так делать не будем.
Я предлагаю свернуть в нашем исследовании, на 42 градуса, и обратиться к одной чудесной штуковине.
Это сладкое слово "эмбеддинг"
Кто в ML не бредил эмбеддингами... тот, кто их никогда не видал.
У меня в институте была хорошая математика, но инженерная, инженер работает на "земле", в простом двух, максимум трехмерном мире. Красота же математики эмбеддинга, состоит в том, что объект с помощью доброго слова и кода, помещается в N-мерное пространство скрытых переменных,( допустим предложение можно "погрузить в пространство слов"), а полученный вектор, начнет обладать чудесными свойствами, ну вы знаете...
Я тоже, для нашей задачи, решил поиграть в эмбеддинги. И что у нас есть для этого?
У нас есть две сущности - покупатель и товар. Эти сущности, должны быть закодированы, для помещения в модель обучения классификации. Что у нас есть еще? Если присмотреться к исходным данным, то их можно четко разделить между этими двумя сущностями как специфицирующие фичи:
Month, Hour, Minute, Week_day - эти фичи, при оценке поведения покупателя, определяют условия в каких он принимает решение о покупке. Допустим кто-то покупает только в 17 минут часа, а по средам, предпочитает что-то особенное. Месяц, точно несет информацию о сезонности покупок.
Тогда свою очередь:
Shop, Cat_id, Price - однозначно атрибуты товара как место продажи, его категория и цена товара.
Эмбеддинги так эмбеддинги, допустим можно воспользоваться word2vec так или вот так. Но это же мой сон мое исследование и тут я решил по своему, потому что еще одна штука зацепила меня в курсе от OTUS.
Его высочество граф
В силу своей давней увлеченности системным подходом и общей теорией систем, я уверен, что вся сила системы в связях (это конечно не имеет прямого отношения к данному исследованию), я не мог пройти мимо такого объекта, квинтэссенцией которого являются связи - графы.
Почти сразу же, после начала работы над этим проектом, я представил себе покупки в корзине покупателя, как граф, где узлами являлись товары, а ребрами вероятности положить следующий товар в корзину, многообещающее начало.
Но на данной стадии исследования, я решил использовать графу несколько иным образом. Я задался задаче получить эмбеддинги для ключевых сущностей, через графы. Для этого, я использовал такую разновидность графов, как двудольный граф.
Особенность этого математического объекта, представлена на рисунке ниже. В таком графе присутствуют узлы двух типов "красные" и синие". Логика построение графа такова, что ребра связывают только узлы разных типов, это наглядно видно на рисунку слева.

Получается презанятнейшая конструкция.
Для работы с графами в Python я использовал библиотеку NetworkX сейчас осваиваю StellarGraph.
Подготовим данные, поскольку фичей для каждой сущности у нас более одной, создаю отдельные переменные 'user_feachers' и 'prod_feachers' как объединение соответствующих фичей для покупателя: месяца, дня недели и "половины дня" (0 - покупки до 13.00 1 - после), аналогично и с фичами для товара.
re_user_prod_sorted_lite['user_feachers']=re_user_prod_sorted_lite['Month'].apply(str)+'_'+re_user_prod_sorted_lite['week_day'].apply(str)+'_'+re_user_prod_sorted_lite['Day_half'].apply(str)
re_user_prod_sorted_lite['prod_feachers']=re_user_prod_sorted_lite['shop'].apply(str)+'_'+re_user_prod_sorted_lite['cat_id']Ниже показано, как получаются данные для создания узлов и ребер графов. Для работы с графами в Python я использовал библиотеку NetworkX сейчас осваиваю StellarGraph.
В результате, для покупателей получен двудольный граф B_ud

а для товаров граф B_ps.
Визуализацию этих графов я сделал в прекрасном инструменте Gephi

Полученные графы. Слева граф для покупателей, справа для товаров. Очевидна их различная структура. На графе товаров явно выделяется кластеризация, по точкам продаж (содержащаяся в переменной shop). Можно долго играться этими графами, извлекая из них все более и более ценные смыслы.

Эмбеддинги на графах Node2vec
Как я уже говорил выше, получению эмбеддингов посвящена много хороших статей, есть своя история и для эмбеддингов на графах. Говоря упрощенно, поскольку граф это, грубо говоря сочетание домиков (узел - node) и тропинок между ними (ребра - edges), по которым можно ходить, то любой узел может быть охарактеризован через узлы, в которые можно из него попасть, пропорционально ширине тропинки, заключенной в ее свойстве weight. Алгоритм Node2vec в числе прочих умеет это делать и я воспользовался им. И продолжаем помнить, что в двудольном графе из узла характеризующего товар, можно попадать только в узлы его фичей.
В рамках текущего исследования я не проводил оценку влияния гиперпараметров на результат, поскольку работу вел в домашних условиях, то ограничился тем, что подобрал значения так, чтобы скорость формирования эмбеддингов в Google Colab составила не более 15 минут.

Получили 16 мерные векторы эмбеддингов и товаров.

Наконец-то все готово запуску.
Модель
Инициализируем модель LightGBM для обучения на подготовленных данных.
def models(X_train, X_test, y_train, y_test,class_num,path,file_name, rounds):
train_dataset = lgb.Dataset(X_train, y_train)
test_dataset = lgb.Dataset(X_test, y_test)
booster = lgb.train({"objective": "multiclass", "num_class":class_num, "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=rounds)
train_preds = booster.predict(X_train)
train_preds = np.argmax(train_preds, axis=1)
test_preds = booster.predict(X_test)
test_preds = np.argmax(test_preds, axis=1)
path='/content/drive/MyDrive/'
file_model=path+file_name
booster.save_model(file_model, num_iteration=booster.best_iteration)
return test_preds,y_test,train_preds,y_train,file_modelПолучаем долгожданный результат.

Мы видим, не плохие цифры классификации в целом и в частности по классам. Значимая для нас метрика ранжирования nDCG@10 получается равной 0.92, выходит модель, достаточно хорошо, "разобралась" в данных.
На рисунке ниже, представлена оценка важности фичей, которые модель в себя включила.

видно, что, что чуть большую значимость имеют значение вектора эмбеддинга покупателей.
Так же, за компанию, я получил и регрессионные модели

Теперь мы приближаемся к ключевому пункту исследования: получится ли у меня достичь предсказание рангов товаров для рекомендаций, с лучшим или хотя бы сопоставимыми с результатами, полученными в первой части.
Проверка модели на отложенных данных
Присоединяем к датасету тестовых данных (re_valid) справочники эмбеддингов покупателей и товаров (prod_embed_df, user_embed_df)
valid_nodes_user=node_merge(re_valid,'inner','prod_id','id','inner','user_str','user_id',prod_embed_df,user_embed_df)
valid_nodes_user.to_csv('/content/drive/MyDrive/valid_nodes_user.csv',index=False)
И вот что мы получаем

вспомним как это было в первой части

Признаюсь, для полученный результат выглядит более обнадеживающим.
nDCG@10 = 0.69 , это заметно больше чем 0.4.
Но посмотрим, что у нас с MAP@10.

MAP@10= 0.59 в сравнении с 0.18, несомненный прогресс. Хорошо...
Товарищи! Тиграм не докладывают мяса.
Боюсь таким, или почти таким был бы призыв очень внимательного читателя, который обратил внимание, на использование в коде
valid_nodes_user=node_merge(re_valid,'inner','prod_id','id','inner','user_str','user_id',prod_embed_df,user_embed_df)для merge способа связывания "inner". Его использование объясняется тем, что поскольку данные на которых обучалась модель и данные на которых мы ее проверяем не пересекаются во времени, то в динамически изменяемом мире торговли, в будущих данных может не быть либо товаров, либо покупателей, которые появятся позже, уже после того как "сняты" данные для модели. Масштаб бедствия мы можем увидеть ниже.

В train массиве мы видим 1880 покупателей и 571 товар, в test соответственно 942 и 329, и это может быть не критично, если данных просто меньше мы учимся на 1880 покупателях, а проверяем, на 942, но ситуация сложнее.
При сравнении состава покупателей и товаров, для train и test общих оказывается всего 713 покупателя и 255 товара - выходит что в тестовом периоде появилось абсолютно новых 229 покупателя и 74 товара.... и по ним мы ничего не можем сказать, или можем? И забившие тревогу бдительные товарищи правы - нужно с этим что-то делать.
Но, наверное, мы можем по ним что-то сказать? Или можем?
Ведь не даром у нас эмбеддинги.
"Синтезируем" эмбеддинги новых покупателей и товаров, как средние от покупателей и товаров такими же значениями фичей. Думаю помимо среднего можно использовать и другую агрегирующую функцию, но пока так.
user_feachers=re_work.groupby(['user_str','user_feachers'])['prod_id'].count().reset_index()
prod_feachers=re_work.groupby(['prod_id','prod_feachers'])['user_str'].count().reset_index()
fe_all=[]
for fe in fe_user_list['user_feachers'][:].values:
# print(fe)
fe_add=[]
users_line=user_feachers[user_feachers['user_feachers']==fe]['user_str'].values
# print(users_line)
for user in users_line:
# print(user)
embed_user=[]
a=user_embed_df[user_embed_df['user_id']==user].values[0][1:]
# print(a)
embed_user.append(a)
# print(embed_user)
new_emb=np.mean(embed_user,axis=0)
fe_add.append(fe)
for i in range(len(new_emb)):
fe_add.append(new_emb[i])
fe_all.append(fe_add)
#fe_all
fe_user_df=pd.DataFrame(fe_all)
fe_user_df.columns=['user_feachers','user0','user1','user2','user3','user4','user5','user6','user7','user8','user9','user10','user11','user12','user13','user14','user15']
fe_user_df.head()В результате выполнения кода выше у нас возникли в справочники "синтетических" пользователей и товаров.
add_prod_mean=add_prod.groupby(['id'])['prod0','prod1','prod2','prod3','prod4','prod5','prod6','prod7','prod8','prod9','prod10','prod11','prod12','prod13','prod14','prod15'].mean().reset_index()
add_user_mean=add_user.groupby(['user_id'])['user0','user1','user2','user3','user4','user5','user6','user7','user8','user9','user10','user11','user12','user13','user14','user15'].mean().reset_index()
user_embed_full=pd.concat([user_embed_df,add_user_mean])
prod_embed_full=pd.concat([prod_embed_df,add_prod_mean])Для того чтобы было нагляднее, представим все на картинке
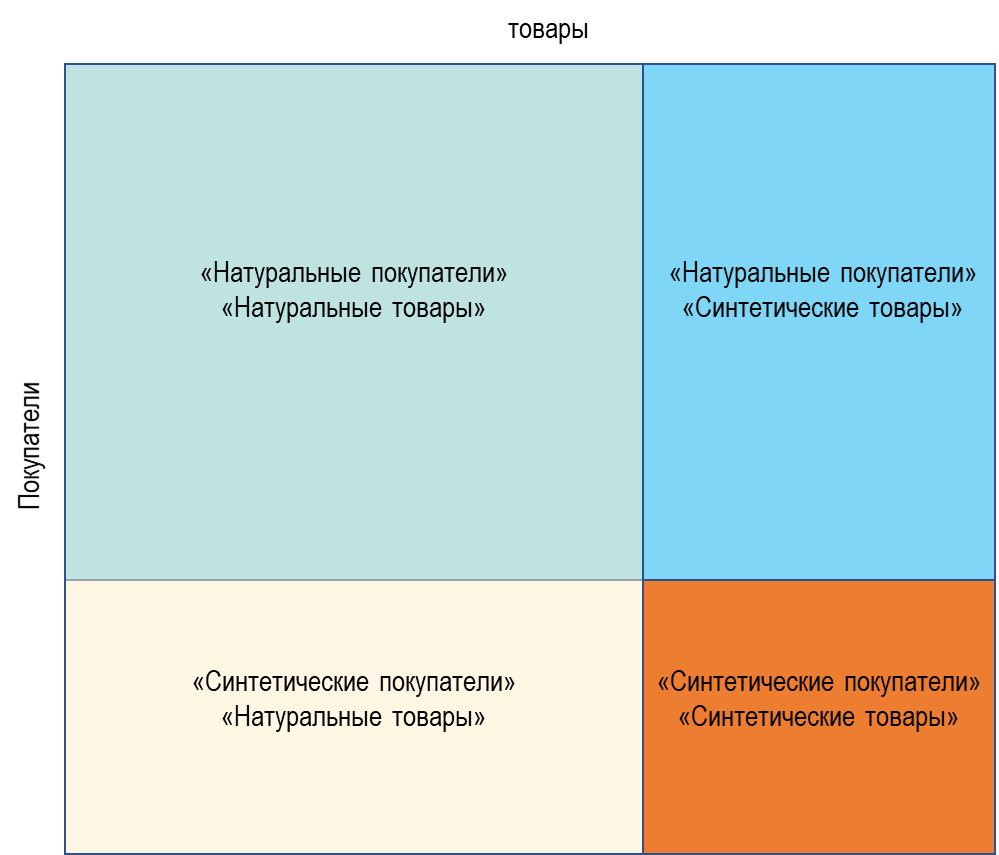
То что мы уже проверили, это верхний левый квадрант. Но у нас появились еще возможности, для проверки модели.
Объединенные данные (натуральное плюс синтетическое в одном флаконе)
Запускаем модель с объединенными справочниками эмбеддингов (user_embed_full,prod_embed_full).
В результате выполения получаем:

Видим, что добавленные данные улучшают nDCG@10, до 0.79.
Для MAP@10, значение несколько ухудшилось

Теперь, пользуясь случаем, проверим модель и на других сочетания данных.

"Синететические покупатели", "натуральные товары"

Не берусь оценить полученные результаты, по этим трем сочетаниям, надо подумать.
А сейчас на повестке вопрос - можно ли улучшить полученные результаты.
Ищем резервы для улучшения
В процессе работы над проектом, меня всегда сопровождало, не проявленное беспокойство, о том что данные для train мы получили условно за 2020 год, а модель проверяем в 2022, нет ли здесь риска "устаревания данных", чувствую что есть, но как его измерить.
И вот я кажется придумал.
Если добавить дисконтирование ценности покупки, т. е. большие раки из вчера, выглядят очень маленькими сегодня.
Но чтобы это сделать, нужна дисконтирующая функция, от показателя, связанного с временем от даты покупки, до наших дней. Для этого добавим даты первой и последней (на момент обработки данных) покупки, а также период в днях между этими датами.
re_all_lite=re_date_lite.loc[re_date_lite['shop'].isin(shop_lite)]
user_date=re_all_lite.groupby(['user_str'])['Date'].apply(set).reset_index()
user_date.columns=['user_name','Date_set']
user_date['set_len']=user_date['Date_set'].apply(len)
users_data=[]
for data in user_date.values:
datas=[]
datas.append(data[0])
datas.append(min(list(data[1])))
datas.append(max(list(data[1])))
datas.append(data[2])
users_data.append(datas)
users_date_df=pd.DataFrame(users_data,columns=['user_str','first_data','last_data','day_in_shop'])
users_date_df.head() получим следующее

Переменная day_in_shop отражает на сколько дней от первой покупки покупателя, отстоит текущая его покупка.
Применим к ней дисконтирующую функцию, пока предлагаю использовать такую


Посмотрим, как это повлияет на результат.
Обучение модели с дисконтированными данными

Результат для отложенных данных следующие:

видно, что данные стали лучше.

Итоги, что же у нас получилось
Нам удалось повысить качество модели формирования списка рекомендаций, "взломав" логику покупки. Теперь это может быть использовано для формирования рекомендаций.
В рамках текущей статьи, алгоритм формирования рекомендаций представлен не будет, но для вдумчивого читателя, не составит труда его восстановить, с опорой на эмбеддинги и графы, конечно же.
Но рекомендации будут, вот здесь можно получить пример файл рекомендаций, получаемого по данным.
Что еще впереди
В ближайшее время, я надеюсь, будет проведена MVP демонстрация работы по формированию рекомендаций, в Компании, которая предоставила свой датасет для проекта.
Следом, я смогу приступить ко второму этапу - адаптации алгоритма рекомендаций с учетом реакции покупателей на рекомендацию, с трансформацией RL в систему рекомендаций.
И это будет совсем другая история.
Большое спасибо всем, кто дочитал до конца, надеюсь было интересно. И пожелайте мне удачи на склоне просветления.
P.S. Хотел бы реабилитировать в глазах читателей библиотеку LightFM, с использованием механизма добавления в модель user_features, item_features можно получить не столь неутешительны результаты, которые были получены в первой части.
Читать первую часть
Также хочу напомнить о том, что 10 февраля в OTUS пройдет бесплатное занятие на котором расскажут про несколько классических подходов к построению рекомендательных систем и научат реализовывать один из них своими руками. Также преподаватели расскажут о готовых инструментах, которые позволяют создать рекомендашку всего в пару строк кода. Регистрация на бесплатный урок доступна вот по этой ссылке.


")