Всем привет! Меня зовут Александра Зенченко, я Lead Software Engineer в ЕРАМ. Занимаюсь разработкой решений, которые помогают нашим клиентам повышать эффективность работы и, в основном, включают в себя часть машинного обучения. В последнем проекте я работала над построением рекомендательной системы в сфере логистики. Хочу поделиться своим опытом и рассказать, как при помощи алгоритмов помочь довезти груз из Мюнхена в Женеву.

Наверняка, с ними встречался каждый и не раз. Рекомендательные системы — это программы и сервисы, которые пытаются предсказать, что может быть интересно/нужно/полезно конкретному пользователю, и показывают им это. «Понравились эти беговые кроссовки? Возможно, Вам также понадобятся ветровка, пульсометр и еще 15 товаров для спорта». В последние годы бренды очень активно внедряют рекомендательные системы в свою работу, так как от этого решения «выигрывают» и продавец, и покупатель. Потребители получают инструмент, который помогает им за короткий срок сделать выбор в бесконечном множестве товаров и услуг, а у бизнеса растут продажи и аудитория.
Я работала на проекте для крупной мировой компании, которая предоставляет своим клиентам SaaS-решение обмена грузами или freight exchange платформу.
Звучит непонятно, а как происходит на деле: с одной стороны, на платформе зарегистрированы пользователи, у которых есть грузы и которым нужно их куда-то отправить. Они размещают заявку по типу «Есть партия декоративной косметики, ее нужно отвезти завтра из Амстердама в Антверпен» и ждут ответ. С другой стороны, у нас есть люди или компании с грузовиками — грузоперевозчики. Допустим, они уже совершили свой стандартный еженедельный рейс, доставив йогурты из Парижа в Брюссель. Им нужно возвращаться и, чтобы не ехать с пустым грузовиком, найти какой-то груз для перевозки по дороге назад. Для этого грузоперевозчики заходят на платформу моего заказчика и выполняют серчи (от англ. search), указывая направление и, возможно, тип груза (или фрейта, от англ. freight), походящий грузовику. Система собирает заявки от грузоотправителей и показывает их грузоперевозчикам.
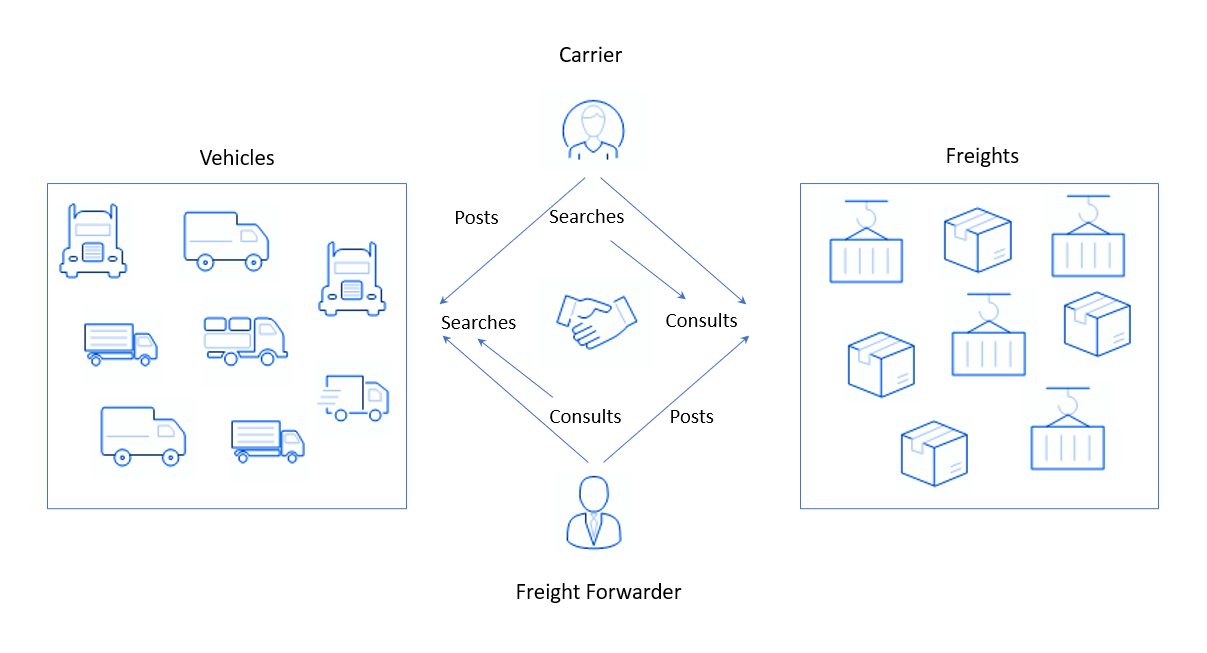
В подобных платформах важен баланс спроса и предложения. Тут спросом пользуются грузы у грузоперевозчиков и грузовики у грузоотправителей, а в качестве предложения все наоборот: машины у перевозчиков и товар от компаний. Баланс достаточно сложно поддерживать по ряду причин, например:
Компания хотела улучшить функционал своей freight exchange платформы и повысить user experience пользователей, чтобы они видели все возможности системы и широкий диапазон грузов, а также не теряли лояльность. Это могло бы удержать целевую аудиторию от перехода на конкурентный сервис и показать грузоперевозчикам, что подходящие заказы можно найти не только у компаний, с которыми они привыкли работать.
С учетом всех пожеланий передо мной стояла задача: разработать рекомендательную систему, которая сразу на входе в платформу будет показывать перевозчикам доступные в настоящее время релевантные грузы и угадывать, что они хотят перевезти и куда. Эта система должна была интегрироваться в уже существующую freight exchange платформу.
Наша рекомендательная система, как и другие, работает на анализе данных о пользователях. И есть несколько источников, которыми можно оперировать:
В приложении, куда решили внедрять рекомендательную систему, уже был механизм поиска грузов по предыдущим запросам. Поэтому мы решили сконцентрироваться на выявлении схем или паттернов, по которым пользователь ищет товары для перевозки. То есть мы не рекомендуем груз, а подбираем направление, наиболее подходящее этому пользователю сегодня. А грузы уже будем находить при помощи стандартного поискового механизма.
Вообще популярные поиски основываются на географической информации и дополнительных параметрах, например, типе грузовика или перевозимого товара. Это достаточно легко отслеживается, потому что такие предпочтения практически не меняются. Ниже я привела данные запросов одного из пользователей за 3 дня. Порядок заполнения таков: 1 колонка — страна отправления, 2 — страна назначения, 3 — регион отправления, 4 — регион назначения.

Видно, что у этого пользователя есть конкретные предпочтения в странах и провинциях. Но так не у всех и не всегда. Очень часто перевозчик указывает только страну назначения или не обозначает регион отправления, к примеру, он находится в Бельгии и может приехать в любую провинцию, чтобы забрать груз. В общем, типы запросов бывают разные: «страна-страна», «страна-регион», «регион-страна» либо «регион-регион» (самый лучший вариант).
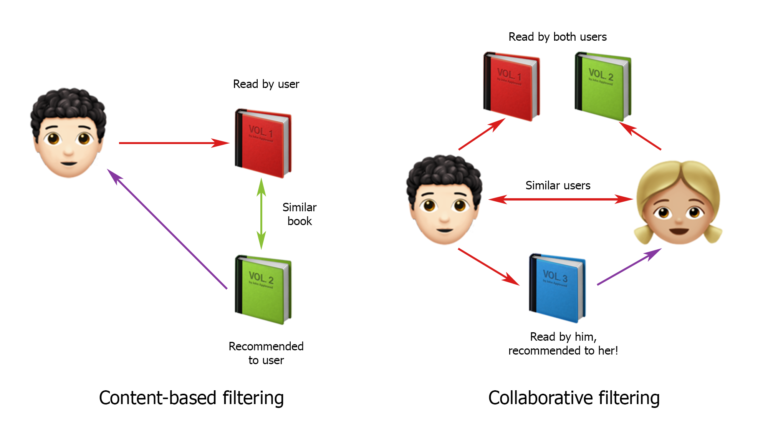
Как известно, стратегии создания рекомендательных систем, в основном, делят по фильтрации на основе содержания (сontent-based) и коллаборативной фильтрации (сollaborative filtering). На этой классификации я и стала строить варианты решений.
Картинку взяла с hub.forklog.com
Во многих источниках говорится, что сollaborative filtering система работает лучше. Все просто: мы пытаемся найти пользователей, похожих на нашего, с подобными паттернами поведения, и рекомендуем нашему пользователю такие же запросы, как у них. В общем-то, это решение было первым вариантом, которые я представила заказчикам. Но они с ним не согласились и сказали, что это не будет работать. Ведь все очень сильно зависит от того, где сейчас находится грузовик, куда он отвез груз, где он живет и куда ему удобнее ехать. Обо всем этом мы не знаем, поэтому так тяжело опираться на поведение других пользователей, пусть даже они, на первый взгляд, подобны.
Теперь о сontent-based системах. Они работают так: сначала определяется и создается профиль пользователя, а после на основании его характеристик делается подборка рекомендаций. Вполне хороший вариант, но в нашем случае есть пара нюансов. Во-первых, за одним пользователем может скрываться целая группа людей, которые ищут грузы для многих грузовиков и заходят с различных IP. Во-вторых, из точных данных у нас есть только страна перевозчика, а информация о количестве грузовиков и их типах примерно «проявляется» только в запросах, которые делает пользователь. То есть, чтобы построить сontent-based систему для нашего проекта, нужно смотреть на запросы каждого пользователя и пытаться найти среди них самые популярные.
Наша первая рекомендательная система не использовала сложные алгоритмы. Мы попытались присвоить запросам ранг (ranк) и найти серчи с наиболее высоким, чтобы их рекомендовать. Для проверки концепции наша команда поработала с реальными пользователями: рассылала им рекомендации, а потом собирала фидбек. В принципе, перевозчикам результат понравился. После я сравнила наши рекомендации с тем, что в эти же дни искали перевозчики, и увидела, что система очень хорошо работала для пользователей с устойчивыми паттернами поведения. Но, к сожалению для тех, кто делал более широкий диапазон запросов, точность рекомендаций была не очень высокая — система нуждалась в доработке.
Я продолжила разбираться, с чем же мы тут имеем дело. Фактически, это скрытая марковская модель, где за каждым пользователем может стоять группа людей. Причем пользователи могут находиться в различных скрытых состояниях: нет данных, где сейчас у них грузовик, сколько человек на одном аккаунте и когда в следующий раз им нужно будет куда-то ехать. На тот момент я не знала готовых решений продукционализации скрытой марковской модели, поэтому решила найти что-то более простое.
Так я обратила внимание на алгоритм PageRank, созданный когда-то основателями Google Сергеем Брином и Ларри Пейджем, который по сей день используется этой поисковой системой для рекомендаций сайтов пользователям. PageRank представляет все интернет-пространство в виде графа, где каждая веб-страничка является его узлом. С его помощью можно рассчитать «важность» (или rank) для каждого узла. PageRank принципиально отличается от алгоритмов поиска, существовавших до него, так как основывается не на содержании страниц, а на ссылках, которые находятся внутри них. То есть rank каждой страницы зависит от количества и качества ссылок, указывающих на нее. Брин и Пейдж доказали сходимость этого алгоритма, а значит мы всегда можем рассчитать rank любого узла направленного графа и придем к значениям, которые не будут меняться.
Посмотрим на его формулу:
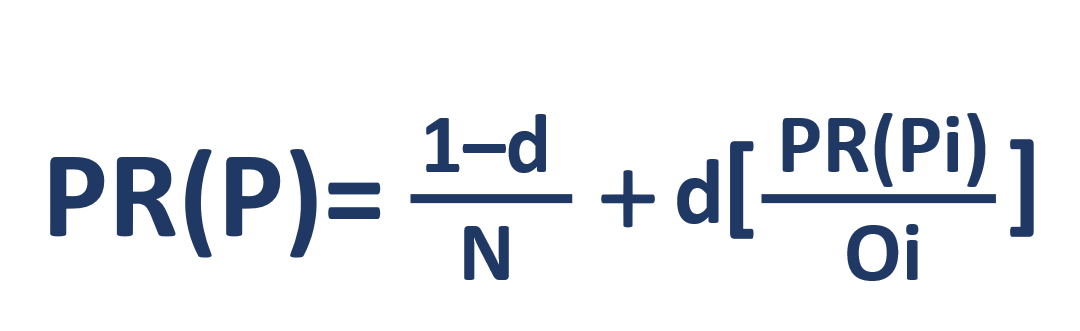
А теперь простой пример расчета PageRank для простого графа, состоящего из трех узлов. Важно помнить, что в начале всем узлам дается одинаковый вес, равный 1/количество узлов.
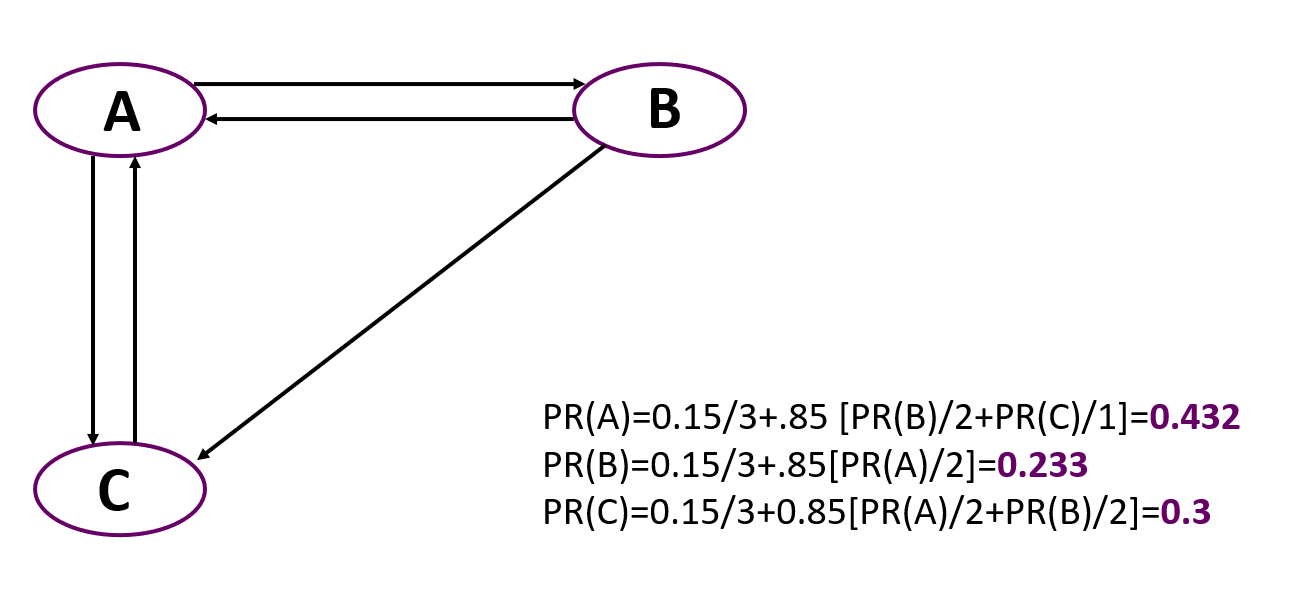
Можно увидеть, что самым важным здесь стал узел А вопреки тому, что на него, как и на С, указывают всего лишь два узла. Но rank узлов, указывающих на А, больше, чем у узлов, ведущих к С.
Итак, PageRank описывает марковский процесс без скрытых состояний. Используя его, мы всегда найдем окончательный вес каждого узла, но не сможем отслеживать изменения в графе. Алгоритм действительно хороший, нам удалось его адаптировать и повысить точность результатов. Для этого мы взяли модификацию PageRank — алгоритм Personalized PageRank, который отличается от базового тем, что переход всегда осуществляется на какое-то ограниченное число узлов. То есть, когда пользователь устает “ходить” по ссылкам, то переключается не на случайный узел, а на один из заданного множества.
Узлами графа в нашем случае будут запросы пользователя. Так как наш алгоритм должен давать рекомендации на предстоящий день, я разбила все запросы каждого перевозчика по дням. Теперь строим граф: узел А соединяется с узлом В, если поиск вида В следует за поиском вида А, то есть поиск вида А осуществлялся пользователем перед днем, когда искали маршрут В. Например: «Париж — Брюссель» во вторник (А), а в среду «Брюссель — Кёльн» (B). А некоторые пользователи делают много запросов за день, поэтому сразу несколько узлов соединяются друг с другом, и в результате мы получаем довольно сложные графы.
Чтобы добавить информацию о важности перехода от одного серча к другому, мы добавили веса ребер графа. Вес ребра А-В — это число случаев, когда пользователь осуществил поиск B после поиска А. Еще очень важно учитывать давность запросов, ведь пользователь меняет свой шаблон: он может переехать или реорганизовать основной вид перевозок, после которого не захочет ехать с пустым грузовиком. Поэтому нужно следить за историей маршрутов — мы добавляем переменную reсency, которая также будет влиять на вес узла.
Стоит учитывать сезонность: мы можем знать, что, например, в сентябре перевозчик чаще ездит во Францию, а в октябре — в Германию. Соответственно, больший вес можно предавать серчам, «популярным» в определенный месяц. Кроме того, мы опираемся на информацию о том, что пользователь искал в последний раз. Это помогает косвенным образом предположить, где может находиться грузовик.
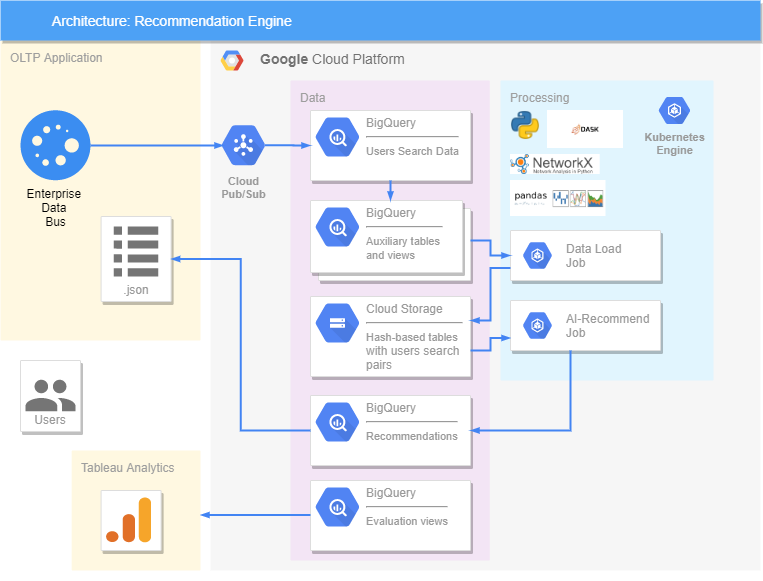
Все реализовано на платформе Google. У нас есть OLTP-приложение, откуда идут данные о запросах и поступают в BigQuery, где формируются дополнительные представления и таблицы, содержащие уже обработанную информацию. Для ускорения и параллелизации обработки больших объемов данных использовалась библиотека DASK. В нашем решении все данные переносятся в Cloud Storage, потому что DASK работает только со ним и не взаимодействует с BigQuery. В Kubernetes были созданы две Job, одна из которых переносит данные из BigQuery в Cloud Storage, а вторая делает рекомендации. Это происходит так: Job берет данные о парах серчей из Cloud Storage, обрабатывает, формирует рекомендации на предстоящий день и отправляет их назад в BigQuery. Оттуда, уже в формате .json, мы можем передавать рекомендации на OLTP-приложение, где их будут видеть пользователи. Точность рекомендаций оценивается в Tableau, где сравниваются наши рекомендации и то, что потом реально искал пользователь, а еще его реакция (понравилось или нет).
Конечно же, хочется поделиться результатами. Вот, например, пользователь, который ежедневно делает по 14 серчей «страна-страна». Такое же количество мы ему и порекомендовали:
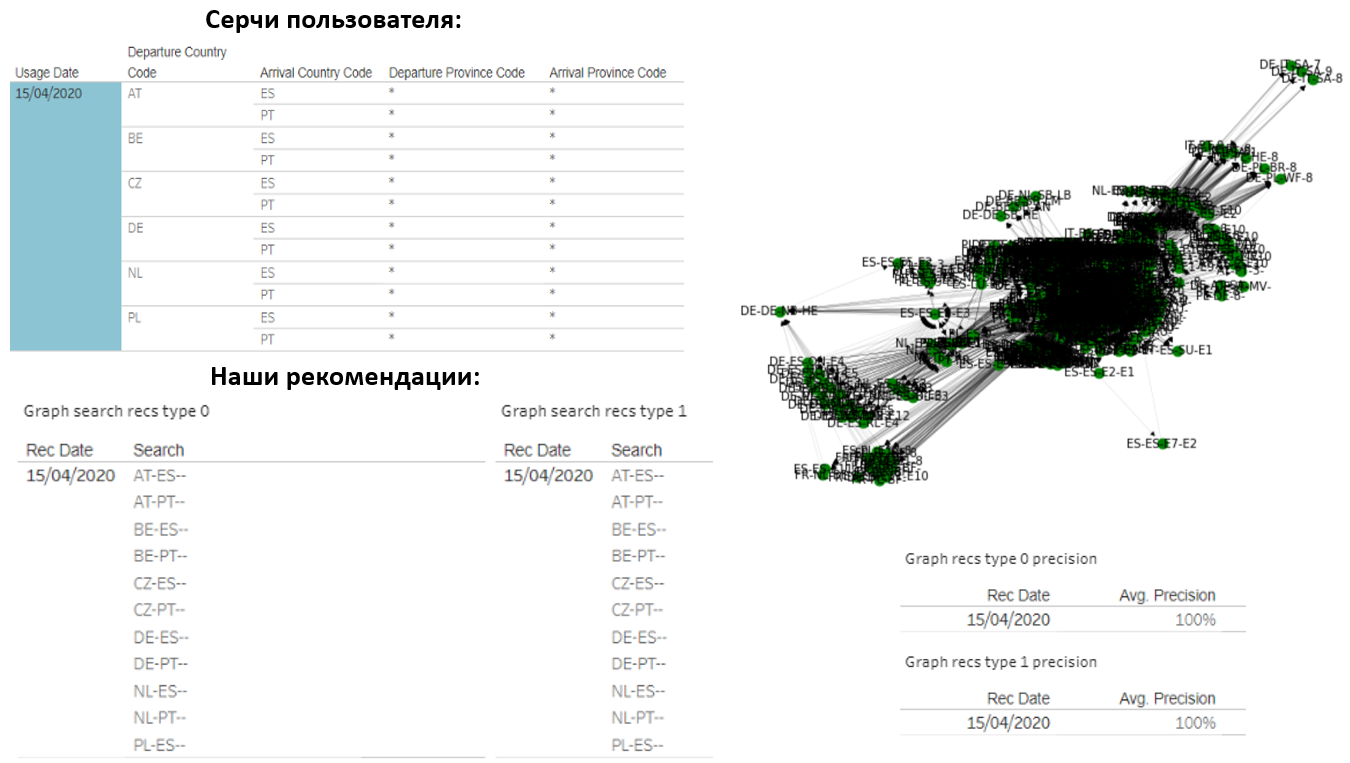
Оказалось, наши варианты полностью совпали с тем, что он искал. Граф этого пользователя состоит из около 1000 различных запросов, но нам удалось очень точно угадать, что его заинтересует.
Второй пользователь в среднем делает 8 различных запросов каждые 2 дня, причем ищет и как формате «страна-страна», так и с указанием конкретного региона отправления. Кроме того, страны отправления и доставки совершенно разные. Поэтому, мы не смогли «угадать» все и точность результатов получилась ниже:

Замечу, что у пользователя 2 графа с разными весами. В одном точность достигала 38%, а значит где-то 3 из 8 вариантов, рекомендованных нами, оказались релевантными. И, возможно, если мы найдем грузы на этих направлениях, то пользователь их и выберет.
Последний и самый простой пример. Человек каждый день делает примерно 2 поиска. У него очень устойчивые паттерны, не слишком много предпочтений и простой граф. Точность наших предсказаний в результате — 100%.

Performance в фактах:
Могу сказать, что наши поиски и эксперименты дали очень хорошие результаты. Представление поведения пользователей freight exchange платформы в виде графа и применение PageRank позволяет с высокой точностью угадывать их будущие предпочтения и, таким образом, строить эффективные рекомендательные системы.
Пару слов о рекомендательных системах
Наверняка, с ними встречался каждый и не раз. Рекомендательные системы — это программы и сервисы, которые пытаются предсказать, что может быть интересно/нужно/полезно конкретному пользователю, и показывают им это. «Понравились эти беговые кроссовки? Возможно, Вам также понадобятся ветровка, пульсометр и еще 15 товаров для спорта». В последние годы бренды очень активно внедряют рекомендательные системы в свою работу, так как от этого решения «выигрывают» и продавец, и покупатель. Потребители получают инструмент, который помогает им за короткий срок сделать выбор в бесконечном множестве товаров и услуг, а у бизнеса растут продажи и аудитория.
Что нам дано?
Я работала на проекте для крупной мировой компании, которая предоставляет своим клиентам SaaS-решение обмена грузами или freight exchange платформу.
Звучит непонятно, а как происходит на деле: с одной стороны, на платформе зарегистрированы пользователи, у которых есть грузы и которым нужно их куда-то отправить. Они размещают заявку по типу «Есть партия декоративной косметики, ее нужно отвезти завтра из Амстердама в Антверпен» и ждут ответ. С другой стороны, у нас есть люди или компании с грузовиками — грузоперевозчики. Допустим, они уже совершили свой стандартный еженедельный рейс, доставив йогурты из Парижа в Брюссель. Им нужно возвращаться и, чтобы не ехать с пустым грузовиком, найти какой-то груз для перевозки по дороге назад. Для этого грузоперевозчики заходят на платформу моего заказчика и выполняют серчи (от англ. search), указывая направление и, возможно, тип груза (или фрейта, от англ. freight), походящий грузовику. Система собирает заявки от грузоотправителей и показывает их грузоперевозчикам.
В подобных платформах важен баланс спроса и предложения. Тут спросом пользуются грузы у грузоперевозчиков и грузовики у грузоотправителей, а в качестве предложения все наоборот: машины у перевозчиков и товар от компаний. Баланс достаточно сложно поддерживать по ряду причин, например:
- Замкнутые связи грузоперевозчика и клиента. Когда водитель часто работает только с определенным заказчиком, это не очень хорошо сказывается на платформе. Если грузоотправитель уйдет с рынка, то сервис может потерять и грузоперевозчика, потому что он станет клиентом другой логистической компании.
- Наличие грузов, которые никто не хочет перевозить. Так случается, когда мелкие компании размещают заявки на перевозку, а потом их не обновляют и, соответственно, быстро выходят из числа активных.
Компания хотела улучшить функционал своей freight exchange платформы и повысить user experience пользователей, чтобы они видели все возможности системы и широкий диапазон грузов, а также не теряли лояльность. Это могло бы удержать целевую аудиторию от перехода на конкурентный сервис и показать грузоперевозчикам, что подходящие заказы можно найти не только у компаний, с которыми они привыкли работать.
С учетом всех пожеланий передо мной стояла задача: разработать рекомендательную систему, которая сразу на входе в платформу будет показывать перевозчикам доступные в настоящее время релевантные грузы и угадывать, что они хотят перевезти и куда. Эта система должна была интегрироваться в уже существующую freight exchange платформу.
Как «гадать» будем?
Наша рекомендательная система, как и другие, работает на анализе данных о пользователях. И есть несколько источников, которыми можно оперировать:
- Во-первых, открытая информация о заявках на перевозку грузов.
- Во-вторых, платформа предоставляет данные о перевозчике. Когда пользователь заключает договор с нашими клиентами, он может указать, сколько у него есть грузовиков и какого типа. Но, к сожалению, после эти данные не обновляются. И единственное, на что мы можем опираться, — это страна грузоперевозчика, так как она, скорее всего, не изменится.
- В-третьих, система сохраняет историю поисков пользователей за несколько лет: как самые последние запросы, так и годовой давности.
В приложении, куда решили внедрять рекомендательную систему, уже был механизм поиска грузов по предыдущим запросам. Поэтому мы решили сконцентрироваться на выявлении схем или паттернов, по которым пользователь ищет товары для перевозки. То есть мы не рекомендуем груз, а подбираем направление, наиболее подходящее этому пользователю сегодня. А грузы уже будем находить при помощи стандартного поискового механизма.
Вообще популярные поиски основываются на географической информации и дополнительных параметрах, например, типе грузовика или перевозимого товара. Это достаточно легко отслеживается, потому что такие предпочтения практически не меняются. Ниже я привела данные запросов одного из пользователей за 3 дня. Порядок заполнения таков: 1 колонка — страна отправления, 2 — страна назначения, 3 — регион отправления, 4 — регион назначения.
Видно, что у этого пользователя есть конкретные предпочтения в странах и провинциях. Но так не у всех и не всегда. Очень часто перевозчик указывает только страну назначения или не обозначает регион отправления, к примеру, он находится в Бельгии и может приехать в любую провинцию, чтобы забрать груз. В общем, типы запросов бывают разные: «страна-страна», «страна-регион», «регион-страна» либо «регион-регион» (самый лучший вариант).
Пробы алгоритмов
Как известно, стратегии создания рекомендательных систем, в основном, делят по фильтрации на основе содержания (сontent-based) и коллаборативной фильтрации (сollaborative filtering). На этой классификации я и стала строить варианты решений.
Картинку взяла с hub.forklog.com
Во многих источниках говорится, что сollaborative filtering система работает лучше. Все просто: мы пытаемся найти пользователей, похожих на нашего, с подобными паттернами поведения, и рекомендуем нашему пользователю такие же запросы, как у них. В общем-то, это решение было первым вариантом, которые я представила заказчикам. Но они с ним не согласились и сказали, что это не будет работать. Ведь все очень сильно зависит от того, где сейчас находится грузовик, куда он отвез груз, где он живет и куда ему удобнее ехать. Обо всем этом мы не знаем, поэтому так тяжело опираться на поведение других пользователей, пусть даже они, на первый взгляд, подобны.
Теперь о сontent-based системах. Они работают так: сначала определяется и создается профиль пользователя, а после на основании его характеристик делается подборка рекомендаций. Вполне хороший вариант, но в нашем случае есть пара нюансов. Во-первых, за одним пользователем может скрываться целая группа людей, которые ищут грузы для многих грузовиков и заходят с различных IP. Во-вторых, из точных данных у нас есть только страна перевозчика, а информация о количестве грузовиков и их типах примерно «проявляется» только в запросах, которые делает пользователь. То есть, чтобы построить сontent-based систему для нашего проекта, нужно смотреть на запросы каждого пользователя и пытаться найти среди них самые популярные.
Наша первая рекомендательная система не использовала сложные алгоритмы. Мы попытались присвоить запросам ранг (ranк) и найти серчи с наиболее высоким, чтобы их рекомендовать. Для проверки концепции наша команда поработала с реальными пользователями: рассылала им рекомендации, а потом собирала фидбек. В принципе, перевозчикам результат понравился. После я сравнила наши рекомендации с тем, что в эти же дни искали перевозчики, и увидела, что система очень хорошо работала для пользователей с устойчивыми паттернами поведения. Но, к сожалению для тех, кто делал более широкий диапазон запросов, точность рекомендаций была не очень высокая — система нуждалась в доработке.
Я продолжила разбираться, с чем же мы тут имеем дело. Фактически, это скрытая марковская модель, где за каждым пользователем может стоять группа людей. Причем пользователи могут находиться в различных скрытых состояниях: нет данных, где сейчас у них грузовик, сколько человек на одном аккаунте и когда в следующий раз им нужно будет куда-то ехать. На тот момент я не знала готовых решений продукционализации скрытой марковской модели, поэтому решила найти что-то более простое.
Знакомьтесь, PageRank
Так я обратила внимание на алгоритм PageRank, созданный когда-то основателями Google Сергеем Брином и Ларри Пейджем, который по сей день используется этой поисковой системой для рекомендаций сайтов пользователям. PageRank представляет все интернет-пространство в виде графа, где каждая веб-страничка является его узлом. С его помощью можно рассчитать «важность» (или rank) для каждого узла. PageRank принципиально отличается от алгоритмов поиска, существовавших до него, так как основывается не на содержании страниц, а на ссылках, которые находятся внутри них. То есть rank каждой страницы зависит от количества и качества ссылок, указывающих на нее. Брин и Пейдж доказали сходимость этого алгоритма, а значит мы всегда можем рассчитать rank любого узла направленного графа и придем к значениям, которые не будут меняться.
Посмотрим на его формулу:
- PR(P) – rank конкретной страницы
- N – количество страниц
- i – остальные страницы
- O – количество исходящих ссылок
- d – понижающий фактор. Когда пользователь ищет что-то, в определенный момент он останавливается, перестает переходить по ссылкам со страницы на страницу и начинает поиск чего-то другого. Понижающий фактор говорит нам о том моменте, когда произойдет переход к новому поиску. 0 ≤ d ≤ 1 – обычно d равен 0,85. В нашей модели я сохранила это значение.
А теперь простой пример расчета PageRank для простого графа, состоящего из трех узлов. Важно помнить, что в начале всем узлам дается одинаковый вес, равный 1/количество узлов.
Можно увидеть, что самым важным здесь стал узел А вопреки тому, что на него, как и на С, указывают всего лишь два узла. Но rank узлов, указывающих на А, больше, чем у узлов, ведущих к С.
Предположения и решение
Итак, PageRank описывает марковский процесс без скрытых состояний. Используя его, мы всегда найдем окончательный вес каждого узла, но не сможем отслеживать изменения в графе. Алгоритм действительно хороший, нам удалось его адаптировать и повысить точность результатов. Для этого мы взяли модификацию PageRank — алгоритм Personalized PageRank, который отличается от базового тем, что переход всегда осуществляется на какое-то ограниченное число узлов. То есть, когда пользователь устает “ходить” по ссылкам, то переключается не на случайный узел, а на один из заданного множества.
Узлами графа в нашем случае будут запросы пользователя. Так как наш алгоритм должен давать рекомендации на предстоящий день, я разбила все запросы каждого перевозчика по дням. Теперь строим граф: узел А соединяется с узлом В, если поиск вида В следует за поиском вида А, то есть поиск вида А осуществлялся пользователем перед днем, когда искали маршрут В. Например: «Париж — Брюссель» во вторник (А), а в среду «Брюссель — Кёльн» (B). А некоторые пользователи делают много запросов за день, поэтому сразу несколько узлов соединяются друг с другом, и в результате мы получаем довольно сложные графы.
Чтобы добавить информацию о важности перехода от одного серча к другому, мы добавили веса ребер графа. Вес ребра А-В — это число случаев, когда пользователь осуществил поиск B после поиска А. Еще очень важно учитывать давность запросов, ведь пользователь меняет свой шаблон: он может переехать или реорганизовать основной вид перевозок, после которого не захочет ехать с пустым грузовиком. Поэтому нужно следить за историей маршрутов — мы добавляем переменную reсency, которая также будет влиять на вес узла.
Стоит учитывать сезонность: мы можем знать, что, например, в сентябре перевозчик чаще ездит во Францию, а в октябре — в Германию. Соответственно, больший вес можно предавать серчам, «популярным» в определенный месяц. Кроме того, мы опираемся на информацию о том, что пользователь искал в последний раз. Это помогает косвенным образом предположить, где может находиться грузовик.
Результат
Все реализовано на платформе Google. У нас есть OLTP-приложение, откуда идут данные о запросах и поступают в BigQuery, где формируются дополнительные представления и таблицы, содержащие уже обработанную информацию. Для ускорения и параллелизации обработки больших объемов данных использовалась библиотека DASK. В нашем решении все данные переносятся в Cloud Storage, потому что DASK работает только со ним и не взаимодействует с BigQuery. В Kubernetes были созданы две Job, одна из которых переносит данные из BigQuery в Cloud Storage, а вторая делает рекомендации. Это происходит так: Job берет данные о парах серчей из Cloud Storage, обрабатывает, формирует рекомендации на предстоящий день и отправляет их назад в BigQuery. Оттуда, уже в формате .json, мы можем передавать рекомендации на OLTP-приложение, где их будут видеть пользователи. Точность рекомендаций оценивается в Tableau, где сравниваются наши рекомендации и то, что потом реально искал пользователь, а еще его реакция (понравилось или нет).
Конечно же, хочется поделиться результатами. Вот, например, пользователь, который ежедневно делает по 14 серчей «страна-страна». Такое же количество мы ему и порекомендовали:
Оказалось, наши варианты полностью совпали с тем, что он искал. Граф этого пользователя состоит из около 1000 различных запросов, но нам удалось очень точно угадать, что его заинтересует.
Второй пользователь в среднем делает 8 различных запросов каждые 2 дня, причем ищет и как формате «страна-страна», так и с указанием конкретного региона отправления. Кроме того, страны отправления и доставки совершенно разные. Поэтому, мы не смогли «угадать» все и точность результатов получилась ниже:
Замечу, что у пользователя 2 графа с разными весами. В одном точность достигала 38%, а значит где-то 3 из 8 вариантов, рекомендованных нами, оказались релевантными. И, возможно, если мы найдем грузы на этих направлениях, то пользователь их и выберет.
Последний и самый простой пример. Человек каждый день делает примерно 2 поиска. У него очень устойчивые паттерны, не слишком много предпочтений и простой граф. Точность наших предсказаний в результате — 100%.
Performance в фактах:
- Наши алгоритмы работают на 4 стандартных CPU и 10 GB памяти.
- Объемы данных составляет до 1 миллиарда записей.
- Создание рекомендаций для всех пользователей, которых около 20 000, занимает 18 минут.
- Библиотека DASK используется для параллелизации, а библиотека NetworkX — для алгоритма PageRank.
Могу сказать, что наши поиски и эксперименты дали очень хорошие результаты. Представление поведения пользователей freight exchange платформы в виде графа и применение PageRank позволяет с высокой точностью угадывать их будущие предпочтения и, таким образом, строить эффективные рекомендательные системы.



