
Перевод руководства по рекуррентным нейросетям с сайта Tensorflow.org. В материале рассматриваются как встроенные возможности Keras/Tensorflow 2.0 по быстрому построению сеток, так и возможности кастомизации слоев и ячеек. Также рассматриваются случаи и ограничения использования ядра CuDNN позволяющего ускорить процесс обучения нейросети.
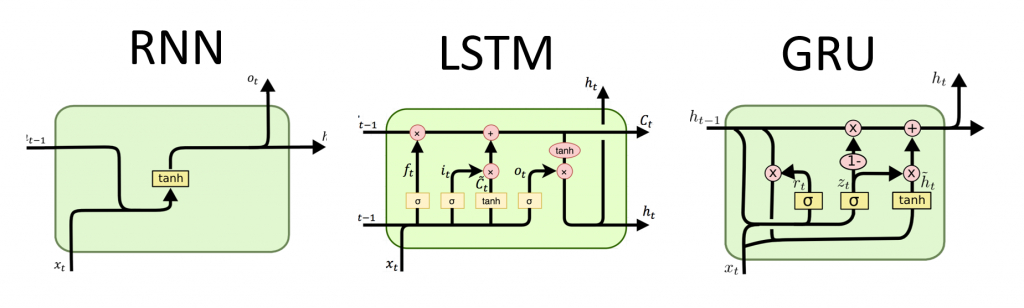
Рекуррентные нейронные сети (RNN) — это класс нейронных сетей, которые хороши для моделирования последовательных данных, таких как временные ряды или естественный язык.
Если схематично, слой RNN использует цикл
Keras RNN API разработан с фокусом на:
Простоту использования: встроенные слои
Простота кастомизации: Вы можете также задать собственный слой ячеек RNN (внутреннюю часть цикла
В Keras есть три встроенных слоя RNN:
В начале 2015, у Keras появились первые переиспользуемые реализации LSTM и GRU на Python с открытым исходным кодом.
Ниже приводится пример
По умолчанию выход слоя RNN содержит один вектор на элемент. Этот вектор является выходом последней ячейки RNN, содержащей информацию обо всей входной последовательности. Размерность этого выхода
Слой RNN может также возвращать всю последовательность выходных данных для каждого элемента (по одному вектору на каждый шаг), если вы укажете
Кроме того, слой RNN может вернуть свое конечное внутреннее состояние (состояния).
Возвращенные состояния можно использовать позже для возобновления выполнения RNN или для инициализации другой RNN. Эта настройка обычно используется в модели энкодер-декодер, последовательность к последовательности, где итоговое состояние энкодера используется для начального состояния декодера.
Для того чтобы слой RNN возвращал свое внутреннего состояния, установите параметр
Чтобы настроить начальное состояние слоя, просто вызовите слой с дополнительным аргументом
Заметьте что размерность должна совпадать с размерностью элемента слоя, как в следующем примере.
RNN API в дополнение к встроенным слоям RNN, также предоставляет API на уровне ячейки. В отличие от слоев RNN, которые обрабатывают целые пакеты входных последовательностей, ячейка RNN обрабатывает только один временной шаг.
Ячейка находится внутри цикла
Математически,
Существует три встроенных ячейки RNN, каждая из которых соответствует своему слою RNN.
Абстракция ячейки вместе с общим классом
При обработке длинных последовательностей (возможно бесконечных), вы можете захотеть использовать паттерн кросс-пакетное сохранение состояния (cross-batch statefulness).
Обычно, внутреннее состояние слоя RNN сбрасывается при каждом новом пакете данных (т.е. каждый пример который видит слой предполагается независимым от прошлого). Слой будет поддерживать состояние только на время обработки данного элемента.
Однако, если у вас очень длинные последовательности, полезно разбить их на более короткие и по очереди передавать их в слой RNN без сброса состояния слоя. Таким образом, слой может сохранять информацию обо всей последовательности, хотя он будет видеть только одну подпоследовательность за раз.
Вы можете сделать это установив в конструкторе `stateful=True`.
Если у вас есть последовательность `s = [t0, t1,… t1546, t1547]`, вы можете разбить ее например на:
Потом вы можете обработать ее с помощью:
Когда вы захотите почистить состояние, используйте
Для последовательностей отличных от временных рядов (напр. текстов), часто бывает так, что модель RNN работает лучше, если она обрабатывает последовательность не только от начала до конца, но и наоборот. Например, чтобы предсказать следующее слово в предложении, часто полезно знать контекст вокруг слова, а не только слова идущие перед ним.
Keras предоставляет простой API для создания таких двунаправленных сетей RNN: обертку
Под капотом,
На выходе`
В TensorFlow 2.0, встроенные слои LSTM и GRU пригодны для использования ядер CuDNN по умолчанию, если доступен графический процессор. С этим изменением предыдущие слои
Поскольку ядро CuDNN построено с некоторыми допущениями, это значит, что слой не сможет использовать слой CuDNN kernel если вы измените параметры по умолчанию встроенных слоев LSTM или GRU. Напр:
Мы выбрали
Как вы можете видеть, модель построенная с CuDNN намного быстрее для обучения чем модель использующая обычное ядро TensorFlow.
Ту же модель с поддержкой CuDNN можно использовать при выводе в однопроцессорной среде. Аннотация
Вам просто не нужно беспокоиться о железе на котором вы работаете. Разве это не круто?
Вложенные структуры позволяют включать больше информации в один временного шага. Например, видеофрейм может содержать аудио и видео на входе одновременно. Размерность данных в этом случае может быть:
В другом примере, у рукописных данных могут быть обе координаты x и y для текущей позиции ручки, так же как и информация о давлении. Так что данные могут быть представлены так:
В следующем коде построен пример кастомной ячейки RNN которая работает с такими структурированными входными данными.
Давайте построим модель Keras которая использует слой
Поскольку у нас нет хорошего датасета для этой модели, мы используем для демонстрации случайные данные, сгенерированные библиотекой Numpy.
Со слоем
После проверки перевод появится также на сайте Tensorflow.org. Если вы хотите поучаствовать в переводе документации сайта Tensorflow.org на русский, обращайтесь в личку или комментарии. Любые исправления и замечания приветствуются.
Рекуррентные нейронные сети (RNN) — это класс нейронных сетей, которые хороши для моделирования последовательных данных, таких как временные ряды или естественный язык.
Если схематично, слой RNN использует цикл
for для итерации по упорядоченной по времени последовательности, храня при этом во внутреннем состоянии, закодированную информацию о шагах, которые он уже видел.Keras RNN API разработан с фокусом на:
Простоту использования: встроенные слои
tf.keras.layers.RNN, tf.keras.layers.LSTM, tf.keras.layers.GRU позволяют вам быстро построить рекуррентные модели без необходимости делать сложные конфигурационные настройки.Простота кастомизации: Вы можете также задать собственный слой ячеек RNN (внутреннюю часть цикла
for) с кастомным поведением и использовать его с общим слоем `tf.keras.layers.RNN` (сам цикл `for`). Это позволит вам быстро прототипировать различные исследовательские идеи в гибкой манере, с минимумом кода.Установка
from __future__ import absolute_import, division, print_function, unicode_literals
import collections
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras import layersПостроение простой модели
В Keras есть три встроенных слоя RNN:
tf.keras.layers.SimpleRNN, полносвязная RNN в которой выход предыдущего временного шага должен быть передан в следующий шаг.tf.keras.layers.GRU, впервые предложен в статье Изучение представлений фраз с использованием кодера-декодера RNN для статистического машинного переводаtf.keras.layers.LSTM, впервые предложен в статье Долгая краткосрочная память
В начале 2015, у Keras появились первые переиспользуемые реализации LSTM и GRU на Python с открытым исходным кодом.
Ниже приводится пример
Sequential модели которая обрабатывает последовательности целых чисел, вкладывая каждое целое число в 64-мерный вектор, затем обрабатывая последовательности векторов с использованием слоя LSTM.model = tf.keras.Sequential()
# Добавим слой Embedding ожидая на входе словарь размера 1000, и
# на выходе вложение размерностью 64.
model.add(layers.Embedding(input_dim=1000, output_dim=64))
# Добавим слой LSTM с 128 внутренними узлами.
model.add(layers.LSTM(128))
# Добавим слой Dense с 10 узлами и активацией softmax.
model.add(layers.Dense(10))
model.summary()Выходы и состояния
По умолчанию выход слоя RNN содержит один вектор на элемент. Этот вектор является выходом последней ячейки RNN, содержащей информацию обо всей входной последовательности. Размерность этого выхода
(batch_size, units), где units соответствует аргументу units передаваемому конструктору слоя.Слой RNN может также возвращать всю последовательность выходных данных для каждого элемента (по одному вектору на каждый шаг), если вы укажете
return_sequences=True. Размерность этих выходных данных равна (batch_size, timesteps, units).model = tf.keras.Sequential()
model.add(layers.Embedding(input_dim=1000, output_dim=64))
# Выходом GRU будет 3D тензор размера (batch_size, timesteps, 256)
model.add(layers.GRU(256, return_sequences=True))
# Выходом SimpleRNN будет 2D тензор размера (batch_size, 128)
model.add(layers.SimpleRNN(128))
model.add(layers.Dense(10))
model.summary()Кроме того, слой RNN может вернуть свое конечное внутреннее состояние (состояния).
Возвращенные состояния можно использовать позже для возобновления выполнения RNN или для инициализации другой RNN. Эта настройка обычно используется в модели энкодер-декодер, последовательность к последовательности, где итоговое состояние энкодера используется для начального состояния декодера.
Для того чтобы слой RNN возвращал свое внутреннего состояния, установите параметр
return_state в значение True при создании слоя. Обратите внимание, что у LSTM 2 тензора состояния, а у GRU только один.Чтобы настроить начальное состояние слоя, просто вызовите слой с дополнительным аргументом
initial_state.Заметьте что размерность должна совпадать с размерностью элемента слоя, как в следующем примере.
encoder_vocab = 1000
decoder_vocab = 2000
encoder_input = layers.Input(shape=(None, ))
encoder_embedded = layers.Embedding(input_dim=encoder_vocab, output_dim=64)(encoder_input)
# Возвращает состояния в добавление к выходным данным
output, state_h, state_c = layers.LSTM(
64, return_state=True, name='encoder')(encoder_embedded)
encoder_state = [state_h, state_c]
decoder_input = layers.Input(shape=(None, ))
decoder_embedded = layers.Embedding(input_dim=decoder_vocab, output_dim=64)(decoder_input)
# Передает 2 состояния в новый слой LSTM в качестве начального состояния
decoder_output = layers.LSTM(
64, name='decoder')(decoder_embedded, initial_state=encoder_state)
output = layers.Dense(10)(decoder_output)
model = tf.keras.Model([encoder_input, decoder_input], output)
model.summary()
RNN слои и RNN ячейки
RNN API в дополнение к встроенным слоям RNN, также предоставляет API на уровне ячейки. В отличие от слоев RNN, которые обрабатывают целые пакеты входных последовательностей, ячейка RNN обрабатывает только один временной шаг.
Ячейка находится внутри цикла
for слоя RNN. Оборачивание ячейки слоем tf.keras.layers.RNN дает вам слой способный обрабатывать пакеты последовательностей, напр. RNN(LSTMCell(10)).Математически,
RNN(LSTMCell(10)) дает тот же результат, что и LSTM(10). Фактически, реализацией этого слоя внутри TF v1.x было лишь создание соответствующей RNN ячейки и оборачивание ее в слой RNN. Однако использование встроенных слоев GRU и LSTM позволяет использовать CuDNN что может дать лучшую производительность.Существует три встроенных ячейки RNN, каждая из которых соответствует своему слою RNN.
tf.keras.layers.SimpleRNNCellсоответствует слоюSimpleRNN.tf.keras.layers.GRUCellсоответствует слоюGRU.tf.keras.layers.LSTMCellсоответствует слоюLSTM.
Абстракция ячейки вместе с общим классом
tf.keras.layers.RNN, позволяет очень легко реализовать кастомные RNN архитектуры для ваших исследований.Кросс-пакетное сохранение состояния
При обработке длинных последовательностей (возможно бесконечных), вы можете захотеть использовать паттерн кросс-пакетное сохранение состояния (cross-batch statefulness).
Обычно, внутреннее состояние слоя RNN сбрасывается при каждом новом пакете данных (т.е. каждый пример который видит слой предполагается независимым от прошлого). Слой будет поддерживать состояние только на время обработки данного элемента.
Однако, если у вас очень длинные последовательности, полезно разбить их на более короткие и по очереди передавать их в слой RNN без сброса состояния слоя. Таким образом, слой может сохранять информацию обо всей последовательности, хотя он будет видеть только одну подпоследовательность за раз.
Вы можете сделать это установив в конструкторе `stateful=True`.
Если у вас есть последовательность `s = [t0, t1,… t1546, t1547]`, вы можете разбить ее например на:
s1 = [t0, t1, ... t100]
s2 = [t101, ... t201]
...
s16 = [t1501, ... t1547]Потом вы можете обработать ее с помощью:
lstm_layer = layers.LSTM(64, stateful=True)
for s in sub_sequences:
output = lstm_layer(s)Когда вы захотите почистить состояние, используйте
layer.reset_states().Примечание: В этом случае, предполагается что примерПриведем полный пример:iв данном пакете является продолжением примераiпредыдущего пакета. Это значит, что все пакеты содержат одинаковое количество элементов (размер пакета). Например, если пакет содержит[sequence_A_from_t0_to_t100, sequence_B_from_t0_to_t100], следующий пакет должен содержать[sequence_A_from_t101_to_t200, sequence_B_from_t101_to_t200].
paragraph1 = np.random.random((20, 10, 50)).astype(np.float32)
paragraph2 = np.random.random((20, 10, 50)).astype(np.float32)
paragraph3 = np.random.random((20, 10, 50)).astype(np.float32)
lstm_layer = layers.LSTM(64, stateful=True)
output = lstm_layer(paragraph1)
output = lstm_layer(paragraph2)
output = lstm_layer(paragraph3)
# reset_states() сбосит кешированное состояние до изначального initial_state.
# Если initial_state не было задано, по умолчанию будут использованы нулевые состояния.
lstm_layer.reset_states()Двунаправленные RNN
Для последовательностей отличных от временных рядов (напр. текстов), часто бывает так, что модель RNN работает лучше, если она обрабатывает последовательность не только от начала до конца, но и наоборот. Например, чтобы предсказать следующее слово в предложении, часто полезно знать контекст вокруг слова, а не только слова идущие перед ним.
Keras предоставляет простой API для создания таких двунаправленных сетей RNN: обертку
tf.keras.layers.Bidirectional.model = tf.keras.Sequential()
model.add(layers.Bidirectional(layers.LSTM(64, return_sequences=True),
input_shape=(5, 10)))
model.add(layers.Bidirectional(layers.LSTM(32)))
model.add(layers.Dense(10))
model.summary()Под капотом,
Bidirectional скопирует переданный слой RNN layer, и перевернет поле go_backwards вновь скопированного слоя, и таким образом входные данные будут обработаны в обратном порядке.На выходе`
Bidirectional RNN по умолчанию будет сумма вывода прямого слоя и вывода обратного слоя. Если вам нужно другое поведение слияния, напр. конкатенация, поменяйте параметр `merge_mode` в конструкторе обертки `Bidirectional`.Оптимизация производительности и ядра CuDNN в TensorFlow 2.0
В TensorFlow 2.0, встроенные слои LSTM и GRU пригодны для использования ядер CuDNN по умолчанию, если доступен графический процессор. С этим изменением предыдущие слои
keras.layers.CuDNNLSTM/CuDNNGRU устарели, и вы можете построить свою модель, не беспокоясь об оборудовании, на котором она будет работать.Поскольку ядро CuDNN построено с некоторыми допущениями, это значит, что слой не сможет использовать слой CuDNN kernel если вы измените параметры по умолчанию встроенных слоев LSTM или GRU. Напр:
- Изменение функции
activationсtanhна что-то другое. - Изменение функции
recurrent_activationсsigmoidна что-то другое. - Использование
recurrent_dropout> 0. - Установка
unrollравным True, что заставляет LSTM/GRU декомпозировать внутреннийtf.while_loopв развернутый циклfor. - Установка
use_biasравным False. - Использование масок, когда входные данные не выровнены строго справа (если маска соответствует строго выровненным справа данным, CuDNN может быть все еще использовано. Это наиболее распространенный случай).
Когда это возможно используйте ядра CuDNN
batch_size = 64
# Каждый пакет изображений MNIST это тензор размерностью (batch_size, 28, 28).
# Каждая входная последовательность размера (28, 28) (высота рассматривается как время).
input_dim = 28
units = 64
output_size = 10 # метки от 0 до 9
# Построим RNN модель
def build_model(allow_cudnn_kernel=True):
# CuDNN доступен только на уровне слоя, а не на уровне ячейки.
# Это значит `LSTM(units)` будет использовать ядро CuDNN,
# тогда как RNN(LSTMCell(units)) будет использовать non-CuDNN ядро.
if allow_cudnn_kernel:
# Слой LSTM с параметрами по умолчанию использует CuDNN.
lstm_layer = tf.keras.layers.LSTM(units, input_shape=(None, input_dim))
else:
# Обертка LSTMCell слоем RNN не будет использовать CuDNN.
lstm_layer = tf.keras.layers.RNN(
tf.keras.layers.LSTMCell(units),
input_shape=(None, input_dim))
model = tf.keras.models.Sequential([
lstm_layer,
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(output_size)]
)
return model
Загрузка датасета MNIST
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
sample, sample_label = x_train[0], y_train[0]Создайте экземпляр модели и скомпилируйте его
Мы выбрали
sparse_categorical_crossentropy в качестве функции потерь. Выходные данные модели имеют размерность [batch_size, 10]. Ответом модели является целочисленный вектор, каждое из чисел находится в диапазоне от 0 до 9.model = build_model(allow_cudnn_kernel=True)
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='sgd',
metrics=['accuracy'])
model.fit(x_train, y_train,
validation_data=(x_test, y_test),
batch_size=batch_size,
epochs=5)Постройте новую модель без ядра CuDNN
slow_model = build_model(allow_cudnn_kernel=False)
slow_model.set_weights(model.get_weights())
slow_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='sgd',
metrics=['accuracy'])
slow_model.fit(x_train, y_train,
validation_data=(x_test, y_test),
batch_size=batch_size,
epochs=1) # Обучим только за одну эпоху потому что она медленная.Как вы можете видеть, модель построенная с CuDNN намного быстрее для обучения чем модель использующая обычное ядро TensorFlow.
Ту же модель с поддержкой CuDNN можно использовать при выводе в однопроцессорной среде. Аннотация
tf.device просто указывает используемое устройство. Модель выполнится по умолчанию на CPU если не будет доступно GPU.Вам просто не нужно беспокоиться о железе на котором вы работаете. Разве это не круто?
with tf.device('CPU:0'):
cpu_model = build_model(allow_cudnn_kernel=True)
cpu_model.set_weights(model.get_weights())
result = tf.argmax(cpu_model.predict_on_batch(tf.expand_dims(sample, 0)), axis=1)
print('Predicted result is: %s, target result is: %s' % (result.numpy(), sample_label))
plt.imshow(sample, cmap=plt.get_cmap('gray'))
RNN с входными данными вида список/словарь, или вложенными входными данными
Вложенные структуры позволяют включать больше информации в один временного шага. Например, видеофрейм может содержать аудио и видео на входе одновременно. Размерность данных в этом случае может быть:
[batch, timestep, {\"video\": [height, width, channel], \"audio\": [frequency]}]В другом примере, у рукописных данных могут быть обе координаты x и y для текущей позиции ручки, так же как и информация о давлении. Так что данные могут быть представлены так:
[batch, timestep, {\"location\": [x, y], \"pressure\": [force]}]В следующем коде построен пример кастомной ячейки RNN которая работает с такими структурированными входными данными.
Определите пользовательскую ячейку поддерживающую вложенный вход/выход
NestedInput = collections.namedtuple('NestedInput', ['feature1', 'feature2'])
NestedState = collections.namedtuple('NestedState', ['state1', 'state2'])
class NestedCell(tf.keras.layers.Layer):
def __init__(self, unit_1, unit_2, unit_3, **kwargs):
self.unit_1 = unit_1
self.unit_2 = unit_2
self.unit_3 = unit_3
self.state_size = NestedState(state1=unit_1,
state2=tf.TensorShape([unit_2, unit_3]))
self.output_size = (unit_1, tf.TensorShape([unit_2, unit_3]))
super(NestedCell, self).__init__(**kwargs)
def build(self, input_shapes):
# # ожидает input_shape содержащий 2 элемента, [(batch, i1), (batch, i2, i3)]
input_1 = input_shapes.feature1[1]
input_2, input_3 = input_shapes.feature2[1:]
self.kernel_1 = self.add_weight(
shape=(input_1, self.unit_1), initializer='uniform', name='kernel_1')
self.kernel_2_3 = self.add_weight(
shape=(input_2, input_3, self.unit_2, self.unit_3),
initializer='uniform',
name='kernel_2_3')
def call(self, inputs, states):
# входы должны быть в [(batch, input_1), (batch, input_2, input_3)]
# состояние должно быть размерностью [(batch, unit_1), (batch, unit_2, unit_3)]
input_1, input_2 = tf.nest.flatten(inputs)
s1, s2 = states
output_1 = tf.matmul(input_1, self.kernel_1)
output_2_3 = tf.einsum('bij,ijkl->bkl', input_2, self.kernel_2_3)
state_1 = s1 + output_1
state_2_3 = s2 + output_2_3
output = [output_1, output_2_3]
new_states = NestedState(state1=state_1, state2=state_2_3)
return output, new_states
Постройте модель RNN с вложенными входом/выходом
Давайте построим модель Keras которая использует слой
tf.keras.layers.RNN и кастомную ячейку которую мы только определили.unit_1 = 10
unit_2 = 20
unit_3 = 30
input_1 = 32
input_2 = 64
input_3 = 32
batch_size = 64
num_batch = 100
timestep = 50
cell = NestedCell(unit_1, unit_2, unit_3)
rnn = tf.keras.layers.RNN(cell)
inp_1 = tf.keras.Input((None, input_1))
inp_2 = tf.keras.Input((None, input_2, input_3))
outputs = rnn(NestedInput(feature1=inp_1, feature2=inp_2))
model = tf.keras.models.Model([inp_1, inp_2], outputs)
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])unit_1 = 10
unit_2 = 20
unit_3 = 30
input_1 = 32
input_2 = 64
input_3 = 32
batch_size = 64
num_batch = 100
timestep = 50
cell = NestedCell(unit_1, unit_2, unit_3)
rnn = tf.keras.layers.RNN(cell)
inp_1 = tf.keras.Input((None, input_1))
inp_2 = tf.keras.Input((None, input_2, input_3))
outputs = rnn(NestedInput(feature1=inp_1, feature2=inp_2))
model = tf.keras.models.Model([inp_1, inp_2], outputs)
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
Обучите модель на случайно сгенерированных данных
Поскольку у нас нет хорошего датасета для этой модели, мы используем для демонстрации случайные данные, сгенерированные библиотекой Numpy.
input_1_data = np.random.random((batch_size * num_batch, timestep, input_1))
input_2_data = np.random.random((batch_size * num_batch, timestep, input_2, input_3))
target_1_data = np.random.random((batch_size * num_batch, unit_1))
target_2_data = np.random.random((batch_size * num_batch, unit_2, unit_3))
input_data = [input_1_data, input_2_data]
target_data = [target_1_data, target_2_data]
model.fit(input_data, target_data, batch_size=batch_size)
Со слоем
tf.keras.layers.RNN от вас требуется только определить математическую логику отдельного шага внутри последовательности, а слой tf.keras.layers.RNN будет обрабатывать для вас итерацию последовательности. Это невероятно сильный способ быстрого прототипирования новых видов RNN (напр. вариант LSTM).После проверки перевод появится также на сайте Tensorflow.org. Если вы хотите поучаствовать в переводе документации сайта Tensorflow.org на русский, обращайтесь в личку или комментарии. Любые исправления и замечания приветствуются.



")
