
Cloud Logging —отличный сервис для просмотра логов. Но у него есть ограничение —время хранения. Сейчас сервис находится в стадии превью, поэтому логи хранятся три дня. После выхода в General Availability это время, скорее всего, увеличится, но ненамного. И это будет небесплатно.
Но что делать, если вам хочется посмотреть историческую информацию или необходимо (например, по юридическим или регуляторным причинам) хранить логи дольше года. А еще бы делать это максимально просто и дешево.
Решение есть! А самое прекрасное, что вам почти не понадобится ничего дополнительно делать, если вы уже настроили поставку логов через Fluentbit, как я рассказывал в двух предыдущих постах про поставку логов из контейнера и systemd.
Чтобы проще всего настроить долгосрочное хранение логов, необходимо поставлять их через Yandex Data Streams при помощи протокола AWS Kinesis Data Streams, а затем складывать их в Yandex Object Storage, используя Yandex Data Transfer.
Теперь давайте разберем этот способ подробнее по шагам.
Шаг 0. Логи
В этот раз я не буду подробно останавливаться на генерации логов. Если вам необходим пример, обратитесь к одному из вышеупомянутых туториалов.
Я буду считать, что необходимый Input для сбора логов у вас уже настроен.
Шаг 1. Настройка секретов
В этот раз нам даже не понадобится плагин. Для поставки воспользуемся одним из стандартных Output’ов Fluentbit — Amazon Kinesis Data Streams.
К сожалению, в отличие от плагина от Yandex мы не сможем воспользоваться авторизацией при помощи IAM-токена, который можно получить привязав сервисный аккаунт к ВМ. Нам придется каким-то образом доставить на ВМ статические ключи авторизации в формате AWS (access и secret key). Например, как я предлагал в туториале про доставку секретов зашифрованных KMS.
Важно: убедитесь заранее, что сервисный аккаунт, от имени которого выписаны ключи, имеет необходимые права на запись в YDS — минимум yds.writer. YDS кэширует ACL, поэтому, если вы сделаете первую неудачную запись и затем назначите права, применение новых ролей для этого сервиса может затянуться.
systemd
Если вы запустили Fluentbit как systemd unit, то вам нужно отредактировать файл с настройками unit’а, добавив в секцию Service строки с переменными окружения:
[Service]
Environment=AWS_CONFIG_FILE=...
Environment=AWS_SHARED_CREDENTIALS_FILE=...Переменные AWS_CONFIG_FILE и AWS_SHARED_CREDENTIALS_FILE должны содержать пути до файлов .aws/config и .aws/credentials соответственно.
Пример содержимого этих файлов:
.aws/credentials
[default]
aws_access_key_id = 5Yd7F94k-BMWIPWIMpj4
aws_secret_access_key = eRSQ7f0o8Itn1vZXY-Xcu1Zt_UHLNv4vhI6fROPp.aws/config
[default]
region = ru-central1Контейнер
Вам нужно замаунтить файл с секретами внутрь контейнера. Добавьте маппинг путей в секцию volumes в docker-compose.yml. Укажите путь до него в переменной окружения, тоже в docker-compose.yml, но в секции environment.
Шаг 2. Конфигурация Fluentbit и YDS
Нужно создать стрим, в который мы будем поставлять логи. В туториале я создам минимально возможный стрим. Для продакшена вам стоит оценить поток ваших логов и конфигурировать стрим, исходя из ваших параметров.
Если у вас еще нет базы YDB, то при создании потока нужно будет сделать ее. Если же у вас есть базы, вы можете выбрать одну из существующих.


Теперь нужно добавить в конфиги Fluentbit еще одну секцию [OUTPUT] и в ней описать настройки Amazon Kinesis Data Streams плагина.
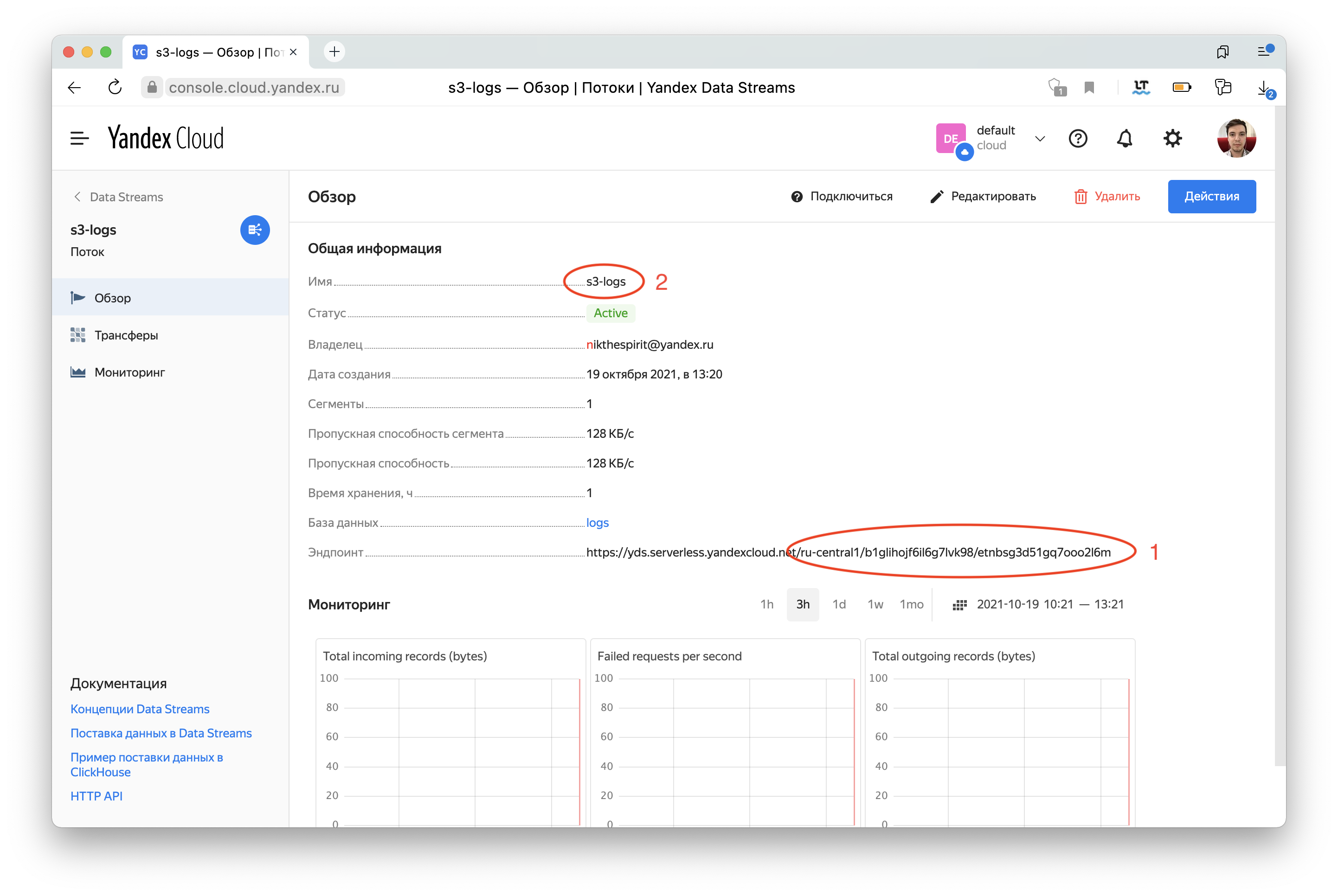
Значение stream нужно собрать из двух частей, обозначенных на скриншоте выше.
[OUTPUT]
Name kinesis_streams
Match *
region ru-central-1
stream /ru-central1/b1glihojf6il6g7lvk98/etnbsg3d51gq7ooo2l6m/s3-logs
workers 1
endpoint https://yds.serverless.yandexcloud.netШаг 3. Data Transfer
Теперь можно перейти на вкладку Трансферы и приступить к созданию Data Transfer.
Создайте два эндпоинта: источник и приемник.
Источник будет типа Yandex Data Stream. В него мы подключим только что созданный стрим.

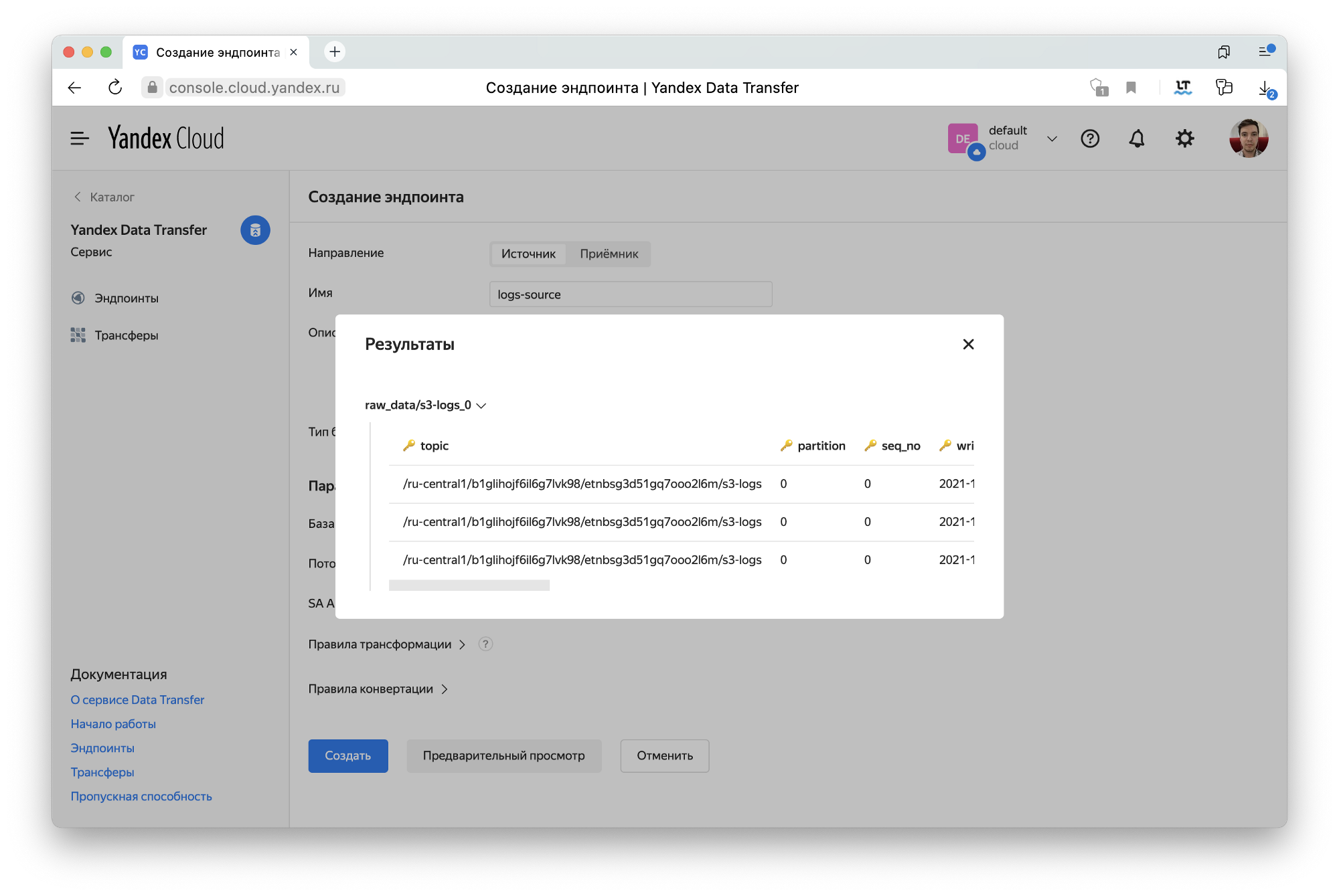
Если вы к тому моменту уже запустили поставку логов, нажмите на кнопку Предварительный просмотр. Так вы сможете убедиться, что всё настроено корректно. Откроется попап с примерами записей из источника. У меня это выглядело так.
Далее перейдем к созданию приемника. Выберем для него тип Object Storage. Нужно заполнить бакет для поставки. Остальные поля можно оставить со значениями по умолчанию. Подробнее про эти настройки можно узнать в документации.

Теперь можно создать трансфер, указав свежесозданные эндпоинты в соответствующих полях формы.

Остается лишь активировать наш трансфер, чтобы он начал переносить данные.

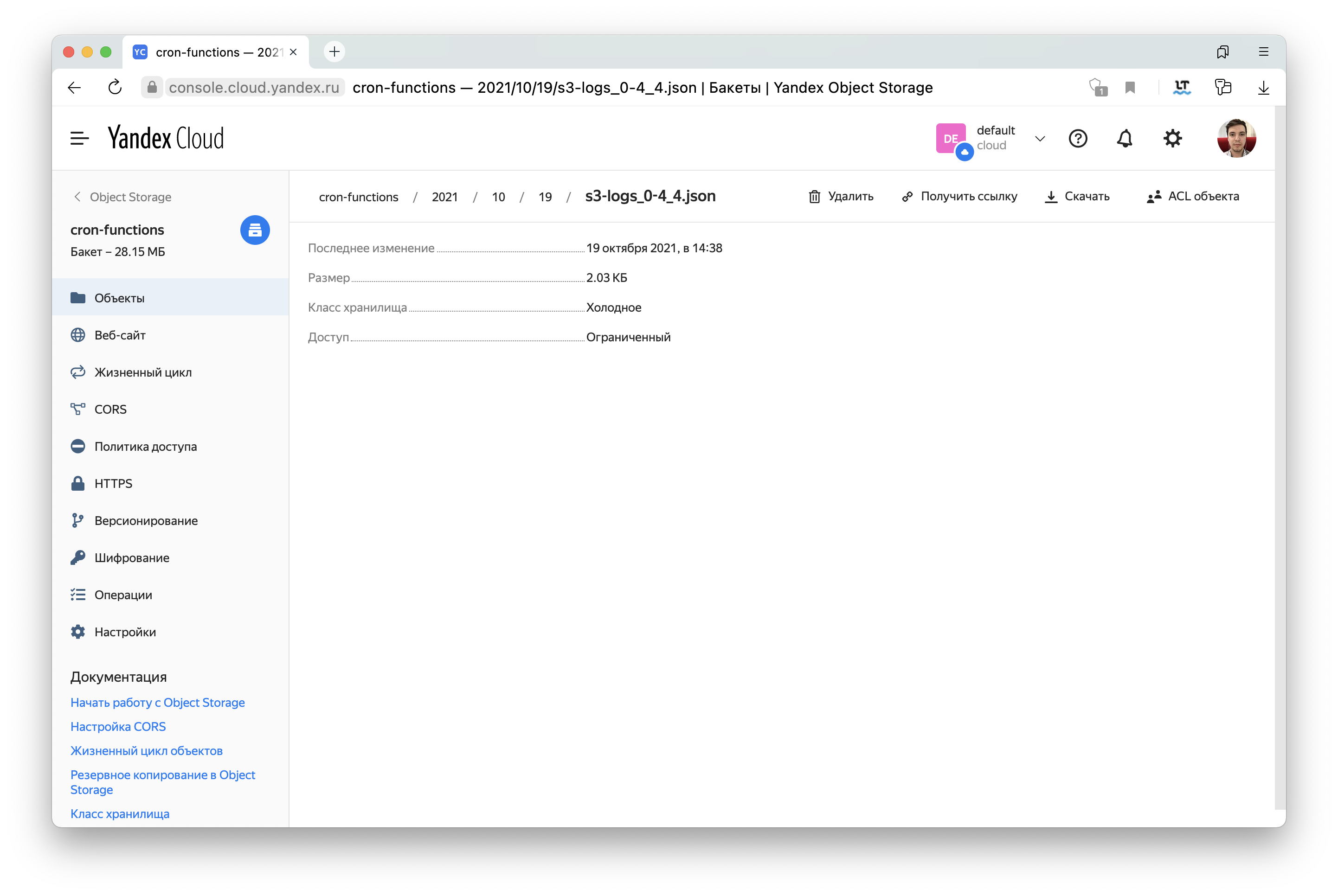
Готово. Можно убедиться, что в Object Storage появились логи в формате JSON.
Таким образом можно настроить приемники других типов, например ClickHouse. Там вы сможете делать аналитические запросы к данным из ваших логов.
P. S. Yandex Data Streams — это serverless-сервис в Yandex.Cloud. Если вам интересна экосистема Serverless-сервисов и все, что с этим связано, заходите в сообщество в Telegram, где можно обсудить serverless в целом.



