Предлагаю ознакомиться с расшифровкой доклада начала 2019 года Андрея Бородина "Резервные копии с WAL-G. Что там в 2019?"

Всем привет! Меня зовут Андрей Бородин. Я разработчик в Яндексе. Я интересуюсь PostgreSQL с 2016-го года, после того, как я поговорил с разработчиками, и они сказали, что тут все просто – ты берешь исходный код и собираешь, и все получится. И с тех пор не могу остановиться – пишу всякие разные штуки.
 Одна из штук, которой я занимаюсь, это система резервного копирования WAL-G. Вообще, в Яндексе мы занимаемся системами резервного копирования в PostgreSQL очень давно. И можно найти в интернете серию из шести докладов о том, как мы делаем системы резервного копирования. И с каждым годом они немного эволюционируют, немного развиваются, становятся более надежными.
Одна из штук, которой я занимаюсь, это система резервного копирования WAL-G. Вообще, в Яндексе мы занимаемся системами резервного копирования в PostgreSQL очень давно. И можно найти в интернете серию из шести докладов о том, как мы делаем системы резервного копирования. И с каждым годом они немного эволюционируют, немного развиваются, становятся более надежными.
Но сегодня доклад посвящен не только тому, что мы сделали, но и о том, как все просто и о том, что есть. Кто из вас уже смотрел мои доклады про WAL-G? Это хорошо, что довольно много людей не смотрели, потому что я начну с самой простой вещи.

Если вдруг у вас есть кластер PostgreSQL, а я думаю у каждого он есть по парочке с собой, и вдруг еще нет системы резервного копирования, то нужно получить любое S3 хранилище или Google Cloud совместимое хранилище.

Например, вы можете подойти к нам на стенд и взять промокод на Yandex Object Storage, который S3 совместим.
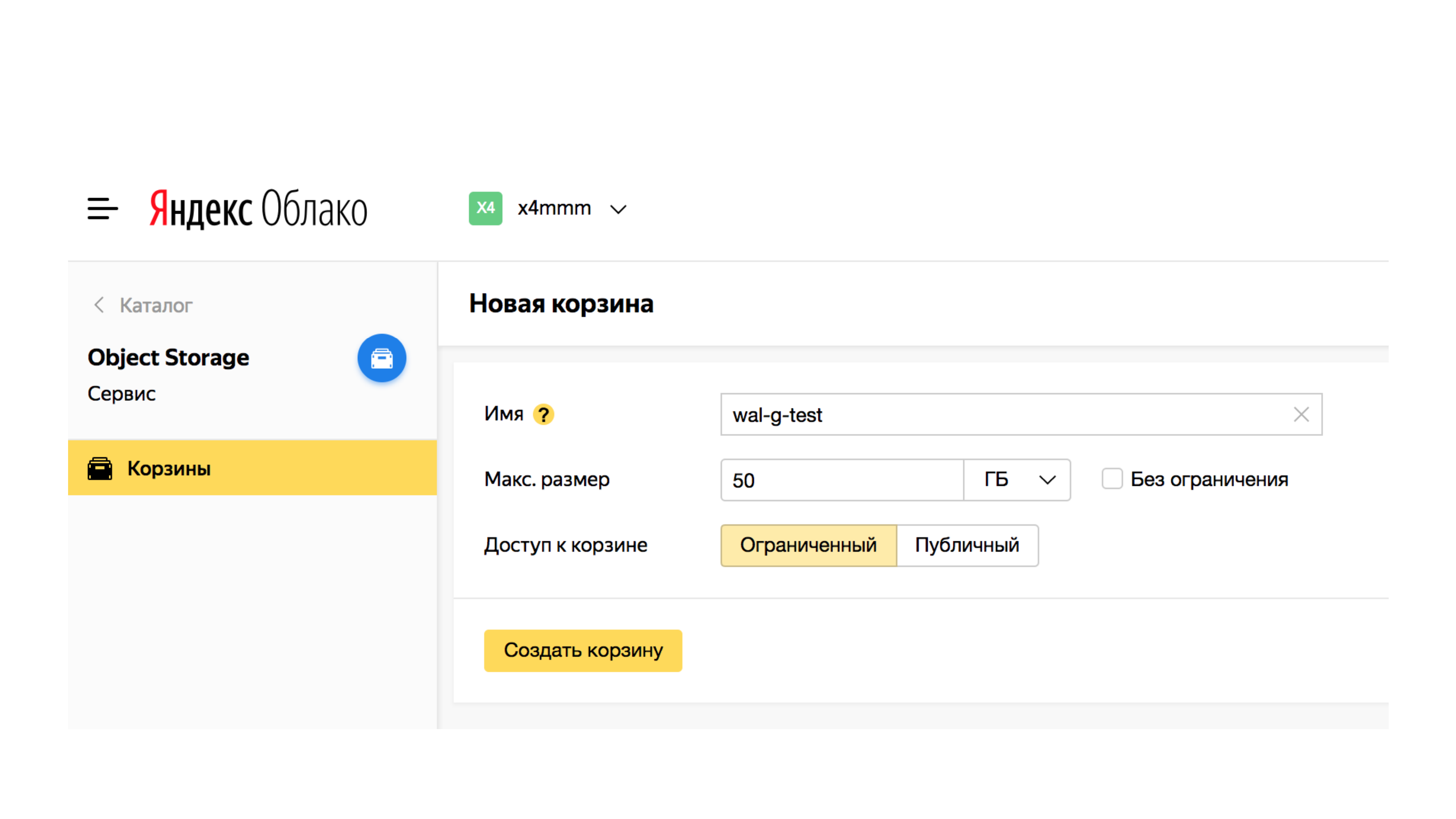
После чего создать Bucket. Это просто контейнер для информации.

Создать сервисного пользователя.
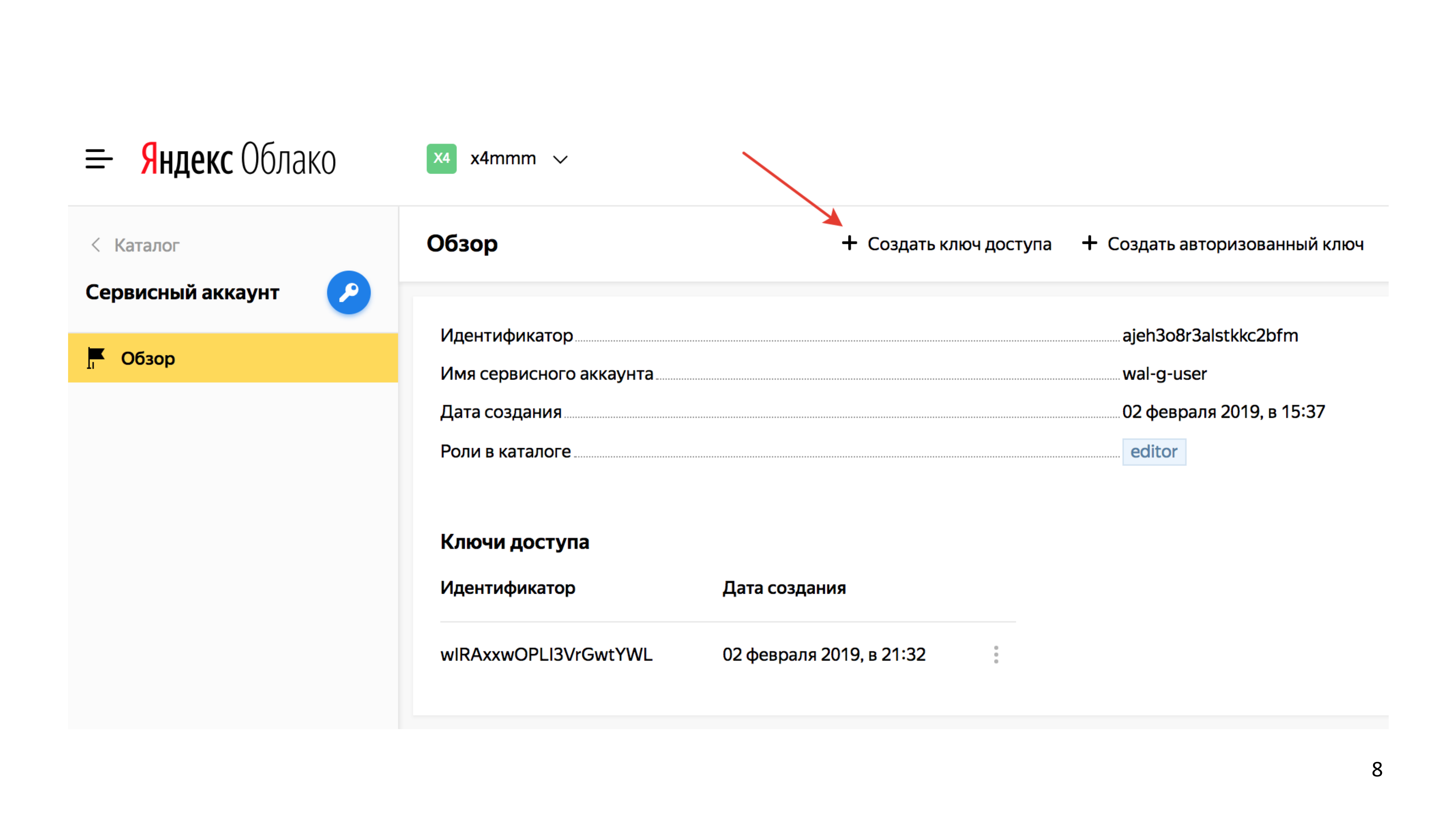
Cоздать сервисному пользователю ключ доступа aws-s3-key.

Скачать последний стабильный релиз WAL-G.
Чем отличаются наши предрелизы от релизов? Меня часто просят сделать релиз пораньше. И если в версии не находится бага достаточное время, например, месяц, то я выпускаю релиз. Вот этот релиз от ноября. И это означает, что каждый месяц мы находили какой-то баг, обычно в не критичной функциональности, но до сих пор релиз мы не выпустили. Предыдущая версия только ноябрьская. В ней нет известных нам багов, т. е. баги добавлялись по ходу развития проекта.
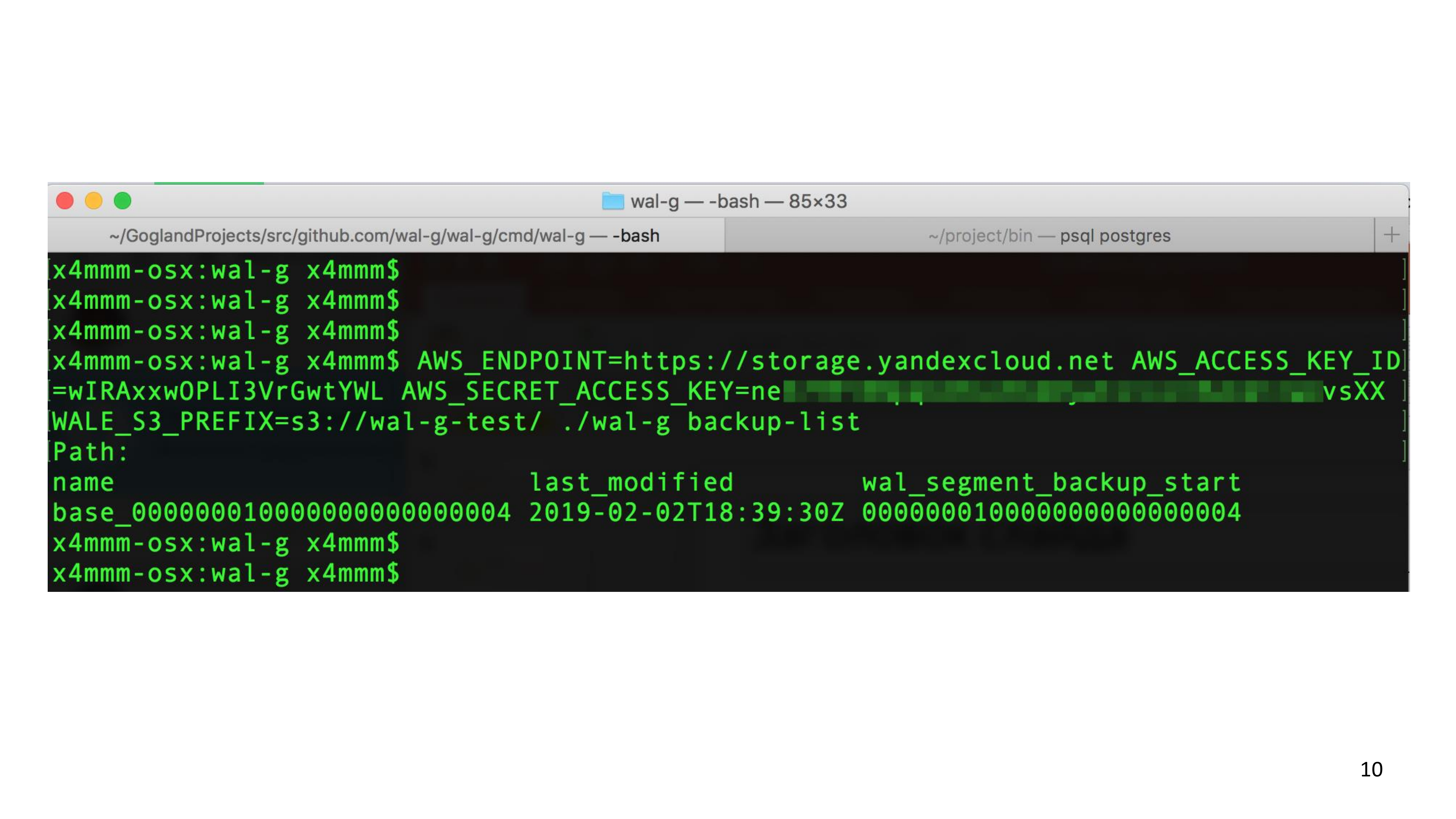
После того, как вы скачали WAL-G, вы можете выполнить нехитрую команду «backup list», передав переменные окружения. И она соединится с Object Storage, и сообщит, какие бэкапы у вас есть. По началу у вас, конечно, бэкапов не должно быть. Смысл этого слайда показать, что все довольно просто. Это консольная команда, которая принимает переменные окружения и выполняет подкоманды.
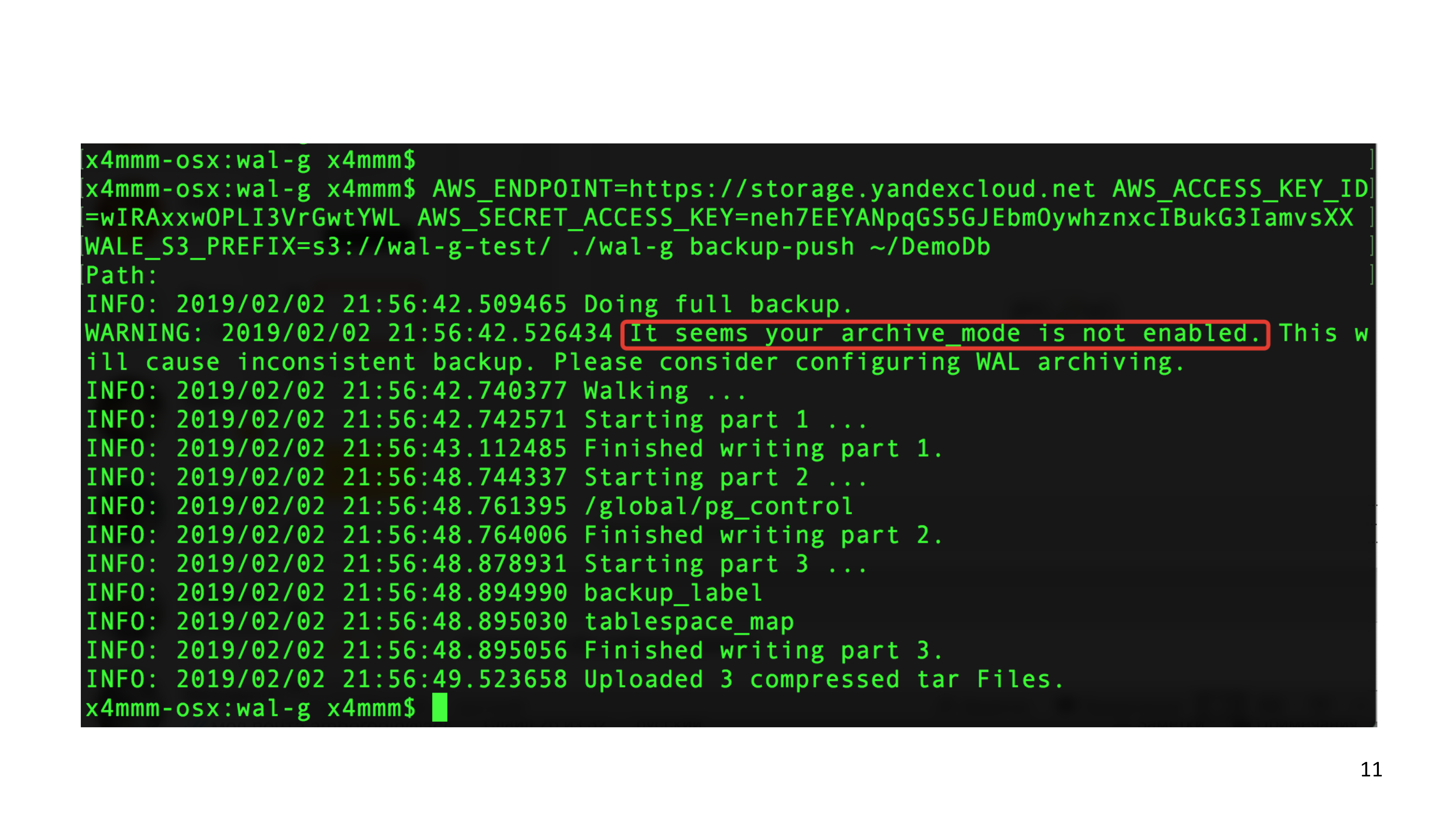
После этого вы можете сделать свой первый бэкап. Сказать в WAL-G «backup-push» и указать в WAL-G расположение pgdata вашего кластера. И, скорее всего, PostgreSQL вам скажет, если у вас нет еще системы резервного копирования, что вам нужно включить «archive-mode».

Это означает, что нужно пойти в настройки и включить «archive_mode = on» и добавить «archive_command», который точно также является подкомандой в WAL-G. Но в эту тему люди часто почему-то используют бар-скрипты и делают обвязку вокруг WAL-G. Пожалуйста, не делайте так. Используйте функциональность, которая есть в WAL-G. Если вам чего-то не хватает, то пишите в GitHub. WAL-G предполагает, что он единственная программа, которая запускается в archive_command.

Мы используем WAL-G в основном для создания High Availability кластера в Яндекс Database management.
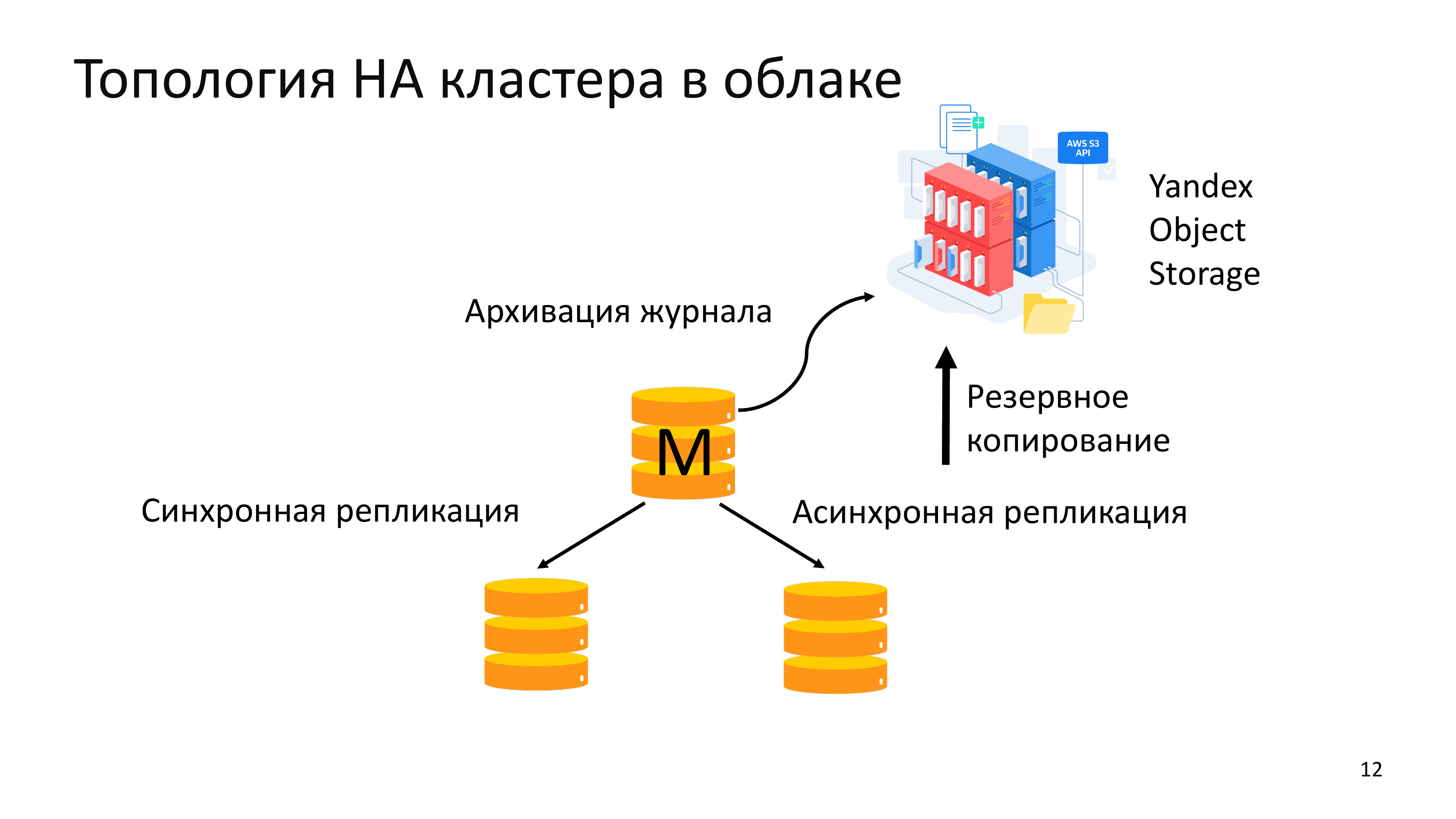
И он используется обычно в топологии из одного Мастера и нескольких репликаций. При этом делает резервную копию в Yandex Object Storage.
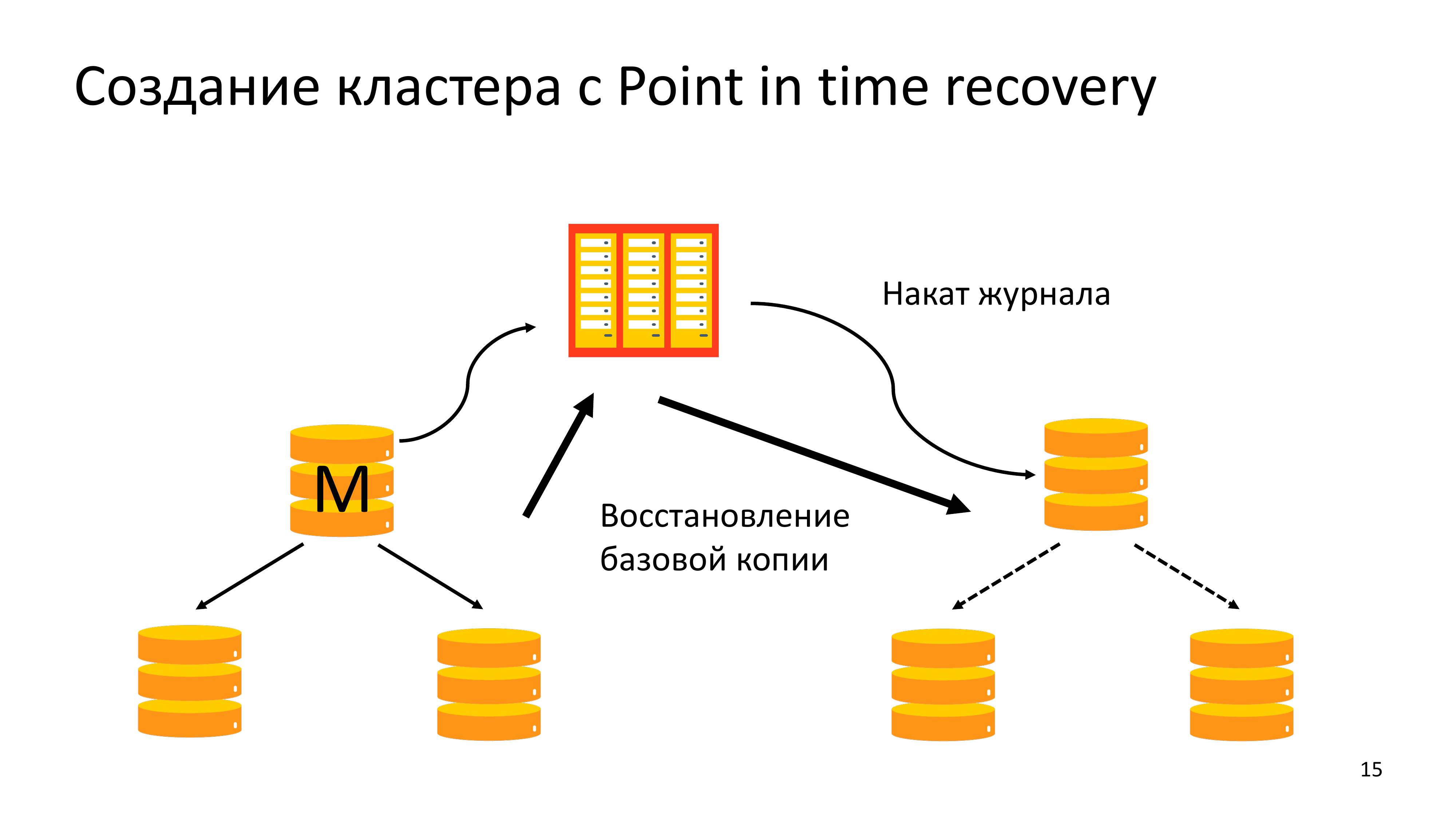
Самые частые сценарии – это создание копий кластера с использованием Point in time recovery. Но в этом случае для нас не так важна производительность системы резервного копирования. Нам просто нужно налить новый кластер из бэкапа.
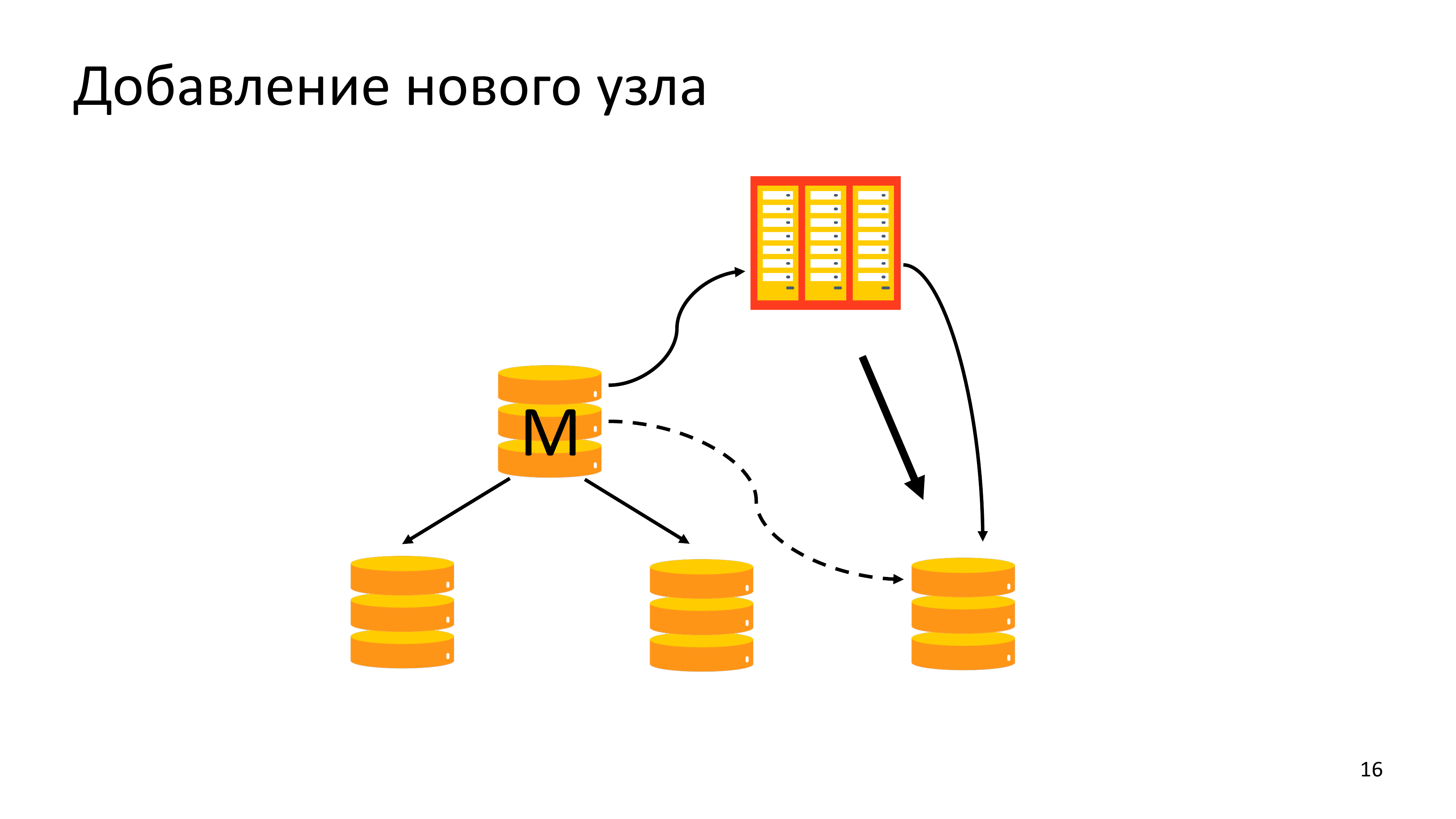
Обычно производительность системы резервного копирования нам нужна при добавлении нового узла. Почему это важно? Обычно люди добавляют новый узел в кластер, потому что существующий кластер не справляется с читающей нагрузкой. Им нужно добавить новую реплику. Если добавим нагрузку от pg_basebackup на Мастер, то Мастер может сложиться. Поэтому нам очень важно было, чтобы мы могли быстро налить новый узел из архива, создавая минимальную нагрузку на Мастере.
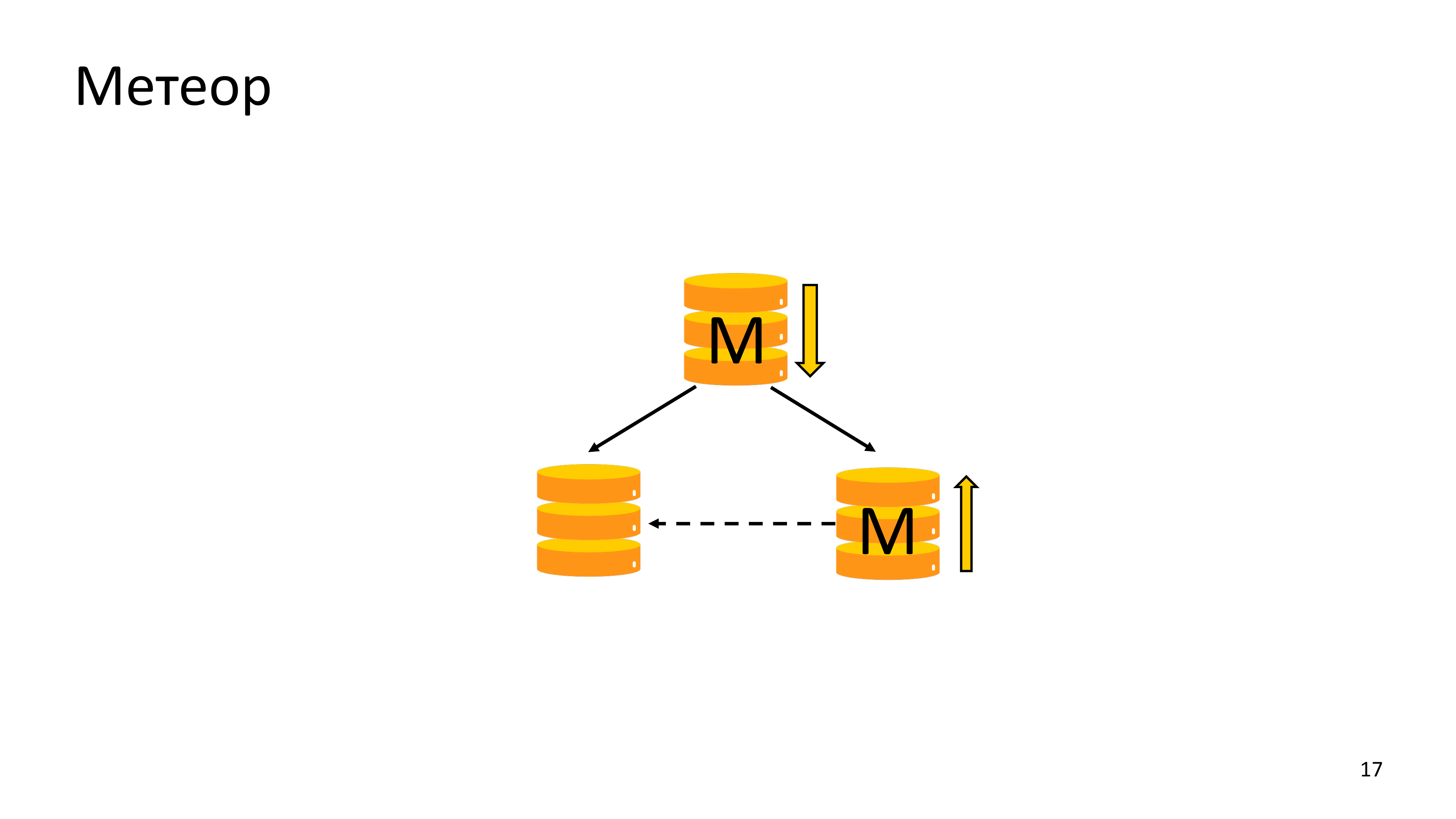
И другая схожая ситуация. Это необходимость переналивки старого Мастера после переключения Мастера кластера из Дата-центра, с которым была потеряна связность.

- В итоге формулируя требования к системе копирования, мы поняли, что pg_basebackup нам не подходит при эксплуатации в облаке.
- Мы хотели иметь возможность сжимать наши данные. Но сжатие данных предоставит почти любая система резервного копирования, кроме того, что есть в коробке.
- Мы хотели параллелизовать все, потому что пользователь в облаке покупает большое количество процессорных ядер. Но если у нас нет параллелизмов в какой-то операции, то большое количество ядер становится бесполезным.
- Нам необходимо шифрование, потому что зачастую это не наши данные и нельзя их хранить в открытом виде. Кстати, именно с шифрования начался наш contribution в WAL-G. Мы дописали шифрование в WAL-G, после чего нас спросили: «Может быть, кто-то из нас займется развитием проекта?». И с тех пор год с лишним я работаю с WAL-G.
- Также нам необходим был троттлинг ресурсов, потому что со временем эксплуатации облака мы выяснили, что иногда у людей бывает важная продуктовая нагрузка ночью и этой нагрузке нельзя мешать. Поэтому мы дописали троттлинг ресурсов.
- А также листинг и управление.
- И верификация.

Мы рассмотрели много различных инструментов. К счастью, у нас огромный выбор в PostgreSQL. И везде нам чего-то не хватало, какой-то одной небольшой функции, какой-то одной небольшой особенности.

И рассмотрев существующие системы мы пришли к том, что будем развивать WAL-G. Он тогда был новым проектом. Довольно легко было повлиять на развитие в сторону именно облачной инфраструктуры системы резервного копирования.

Основная идеология, которой мы придерживаемся – это то, что WAL-G должен быть простым как балалайка.

В WAL-G 4 команды. Это:
WAL-PUSH – заархивировать вал.
WAL-FETCH – получить вал.
BACKUP-PUSH – сделать бэкап.
BACKUP-FETCH – получить бэкап из системы резервного копирования.

На самом деле, в WAL-G есть и менеджмент этих бэкапов, т. е. listing и удаление валов и бэкапов в истории, которые на данный момент уже не нужны.
Одна из важных для нас функция – это функция создания дельта-копий.
Дельта-копии означают, что у нас создается не полный бэкап всего кластера, а вносятся только измененные страницы измененных файлов в кластере. Казалось бы, что функционально это очень похоже на возможность восстановиться используя WAL. Но WAL-однопоточный, дельта-бэкап мы можем накатить параллельно. Соответственно, когда у нас есть базовый бэкап, сделанный в субботу, дельта-бекапы ежедневные и в четверг у нас происходит fail, то нам необходимо накатить 4 дельта-бекапа и 10 часов WAL. Это займет примерно одно и то же время, потому что дельта-бекапы катятся параллельно.
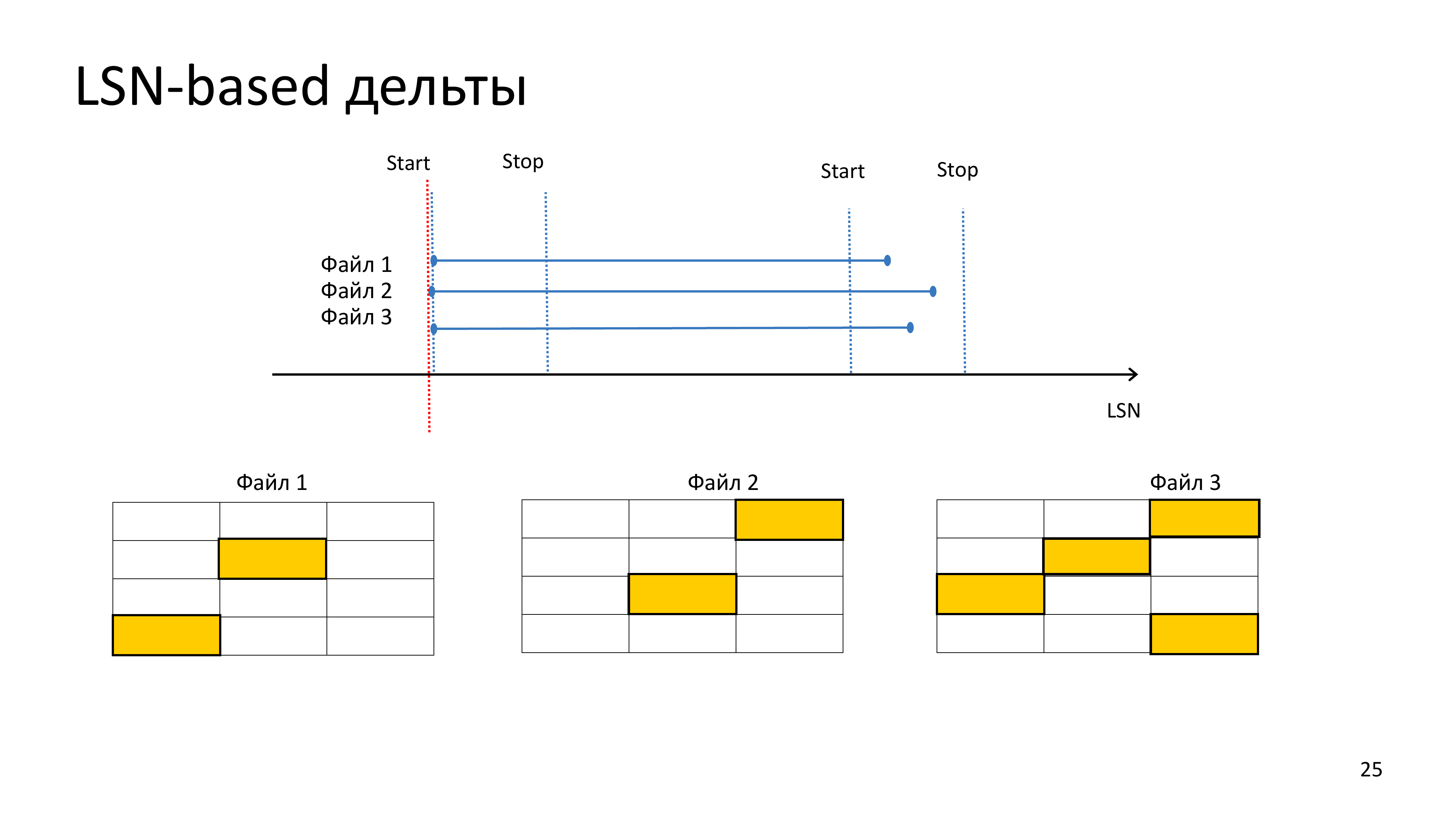
LSN-based дельты – это означает, что при создании резервной копии, нам необходимо будет сочетать каждую страницу и сверить ее LSN с LSN предыдущего бэкапа для того, чтобы понять, что она изменилась. Любая страница, которая потенциально может содержать измененные данные, должна присутствовать в дельта-бэкапе.

Как я говорил, довольно много внимания было уделено параллелизму.

Но API архива в PostgreSQL последовательная. PostgreSQL архивирует один WAL-файл и при восстановлении он запрашивает один WAL-файл. Но когда база данных запросила один WAL-файл при помощи команды «WAL-FETCH», мы вызываем команду «WAL-PREFETCH», которая подготавливает 8 следующих валов для того, чтобы параллельно качать данные из объектного хранилища.
 А когда база данных просит нас заархивировать один вал, мы заглядываем в archive_status и смотрим нет ли других WAL-файлов. И пытаемся закачивать WAL тоже параллельно. Это дает существенный выигрыш по производительности, существенно сокращает расстояние в количестве незаархивированных WAL. Многие разработчики систем резервного копирования считают, что это такая рискованная система, потому что мы опираемся на наши знания внутренностей кода, который не является API PostgreSQL. PostgreSQL не гарантирует наличие нам папки archive_status и не гарантирует семантику, наличие там сигналов готовности у WAL-файлов. Тем не менее мы изучаем исходный код, видим, что это так и стараемся это эксплуатировать. И контролируем в каком направлении развивается PostgreSQL, если вдруг этот механизм будет нарушен, то мы прекратим его использовать.
А когда база данных просит нас заархивировать один вал, мы заглядываем в archive_status и смотрим нет ли других WAL-файлов. И пытаемся закачивать WAL тоже параллельно. Это дает существенный выигрыш по производительности, существенно сокращает расстояние в количестве незаархивированных WAL. Многие разработчики систем резервного копирования считают, что это такая рискованная система, потому что мы опираемся на наши знания внутренностей кода, который не является API PostgreSQL. PostgreSQL не гарантирует наличие нам папки archive_status и не гарантирует семантику, наличие там сигналов готовности у WAL-файлов. Тем не менее мы изучаем исходный код, видим, что это так и стараемся это эксплуатировать. И контролируем в каком направлении развивается PostgreSQL, если вдруг этот механизм будет нарушен, то мы прекратим его использовать.

В чистом виде LSN-based WAL-дельта требует считывать любого файла кластера, у которого mode-time в файловой системе изменился с предыдущего бэкапа. Мы долго с этим жили, почти год. И в итоге пришли к тому, что у нас есть WAL-дельты.
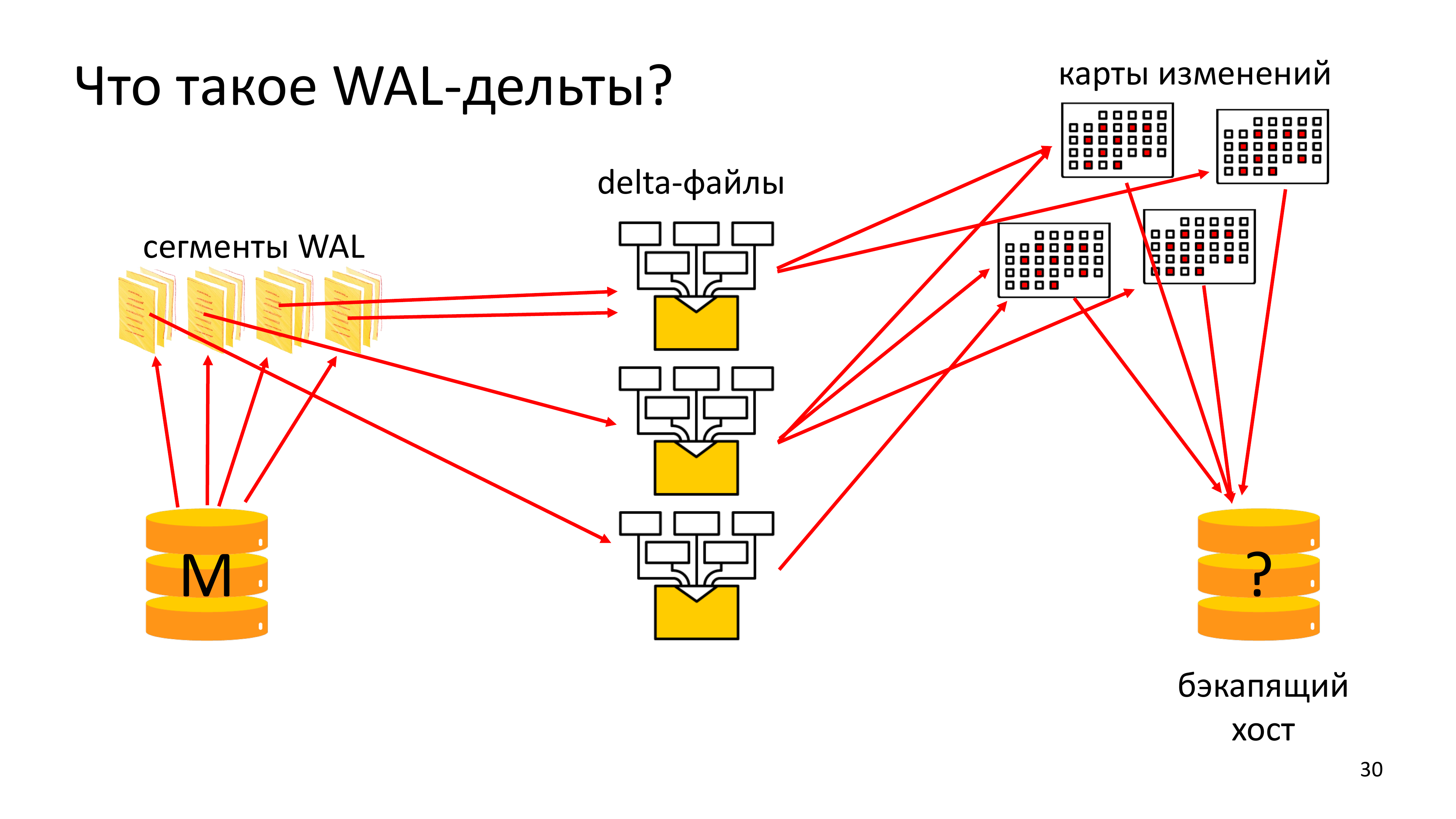 Это означает, что каждый раз при архивировании WAL на Мастере, мы не только его сжимаем, шифруем и отправляем в сеть, но мы его еще и читаем при этом. Анализируем, читаем в нем рекорды. Понимаем, какие блоки изменились и собираем delta-файлы.
Это означает, что каждый раз при архивировании WAL на Мастере, мы не только его сжимаем, шифруем и отправляем в сеть, но мы его еще и читаем при этом. Анализируем, читаем в нем рекорды. Понимаем, какие блоки изменились и собираем delta-файлы.
Delta-файл описывает некоторый диапазон WAL-файлов, описывает информацию о том, какие блоки были изменены в этом диапазоне WAL. И затем эти delta-файлы тоже архивируются.
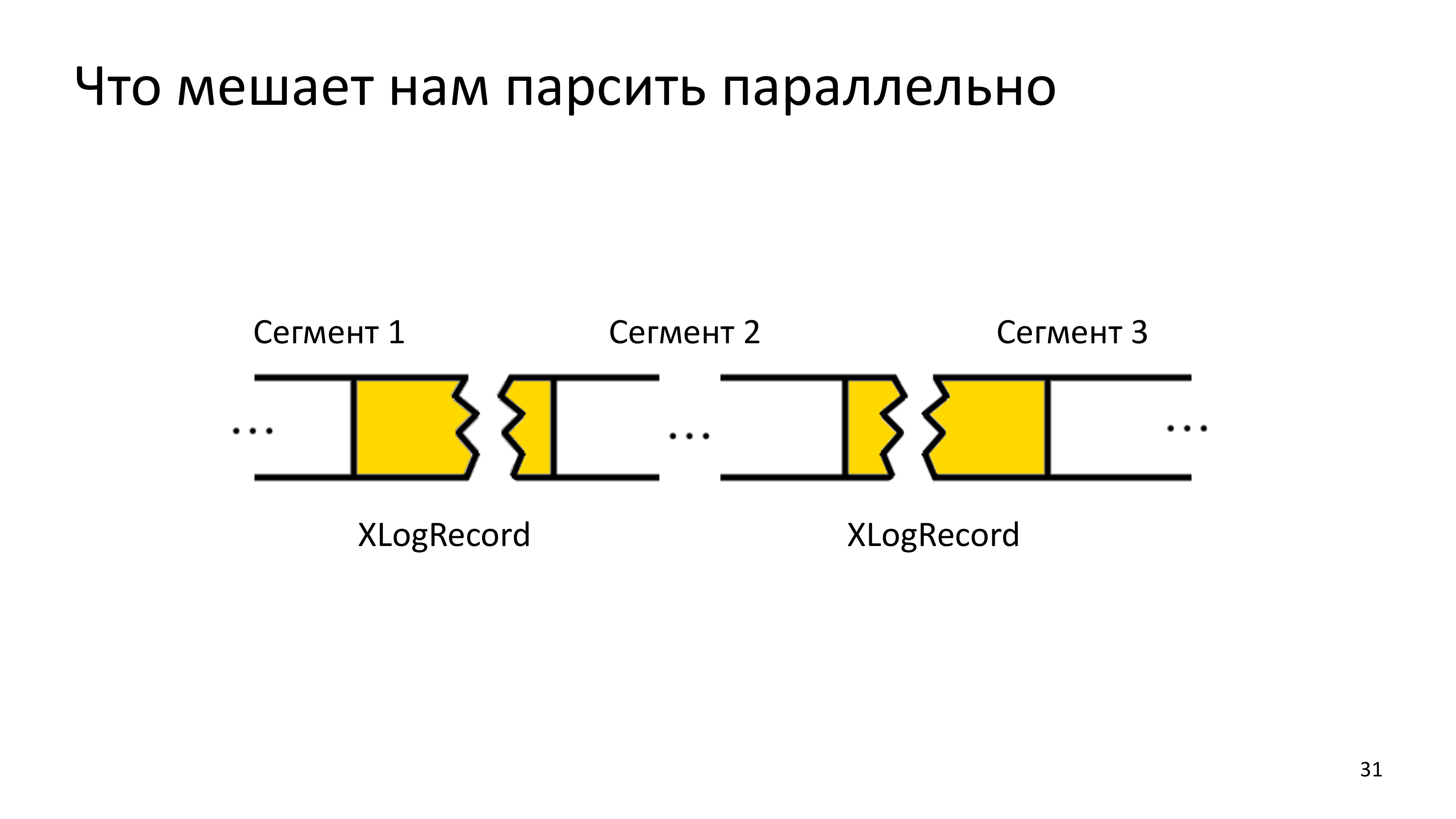
Тут мы столкнулись с тем, что мы достаточно все быстро распараллелили, но нельзя параллельно читать последовательную историю, потому что в определенном сегменте, нам может встретиться конец предыдущего рекорда WAL, который пока нам не с чем состыковать, потому что параллельное чтение привело к тому, что мы сначала анализируем будущее, у которого нет еще прошлого.
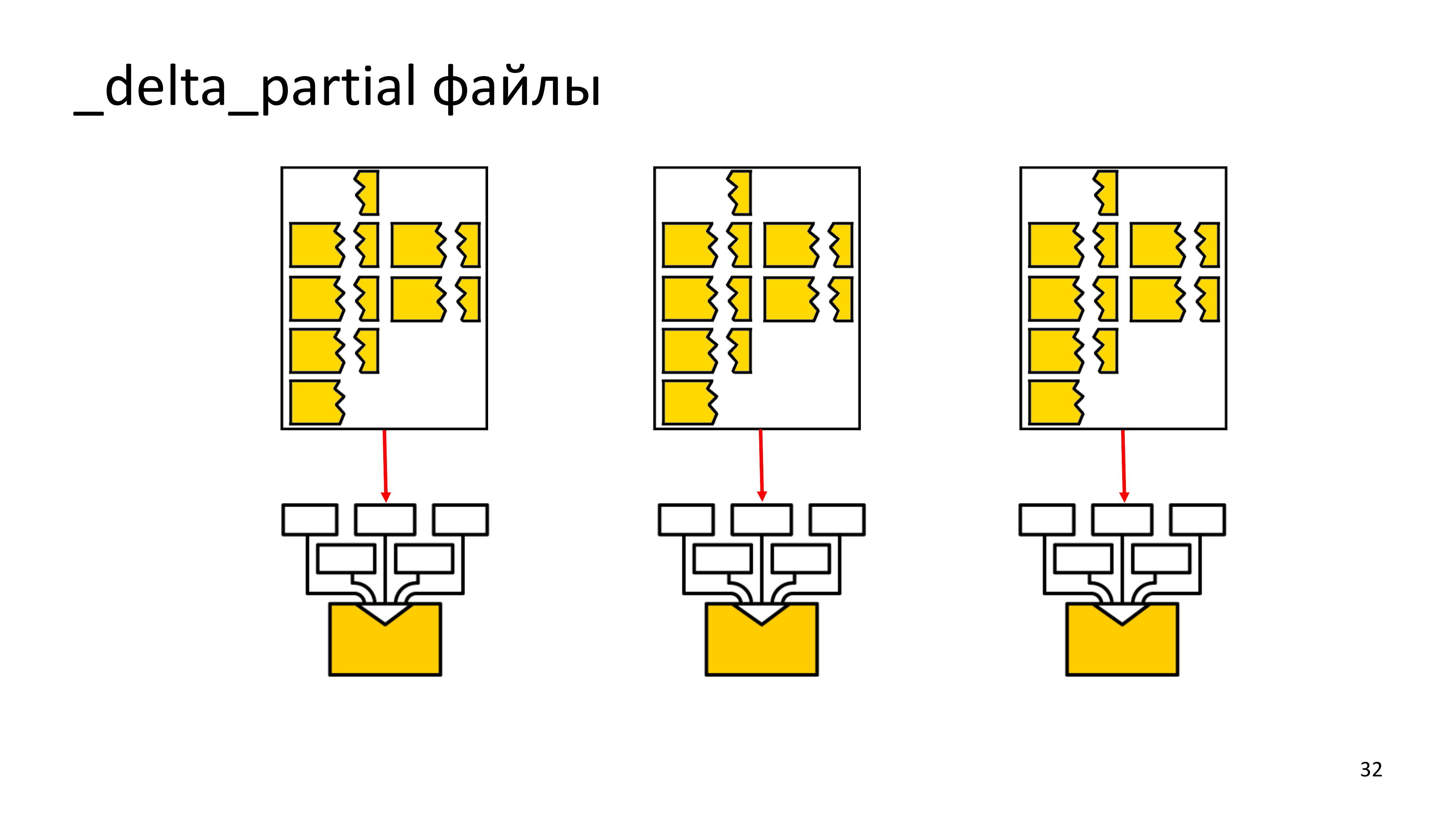
В итоге нам пришлось непонятные куски складывать в _delta_partial файлы. В итоге, когда мы вернемся к прошлому, мы склеим куски WAL рекорда в один, после этого его распарсим и поймем, что в нем менялось.
Если в истории нашего парсинга вала образуется хотя бы одна точка, где мы не понимаем, что происходило, то, соответственно, при следующем бэкапе мы вынуждены будем снова прочитать весь кластер, так же, как мы это сделали при обычной LSN-based дельте.
В итоге все наши страдания привели к тому, что мы заопенсорсили библиотеку для парсинга WAL-G. Насколько мне известно, пока ее никто не использует, но, если кто-нибудь хочет – пишите и используйте, она в открытом доступе. (Обновленная ссылка https://github.com/wal-g/wal-g/tree/master/internal/walparser)
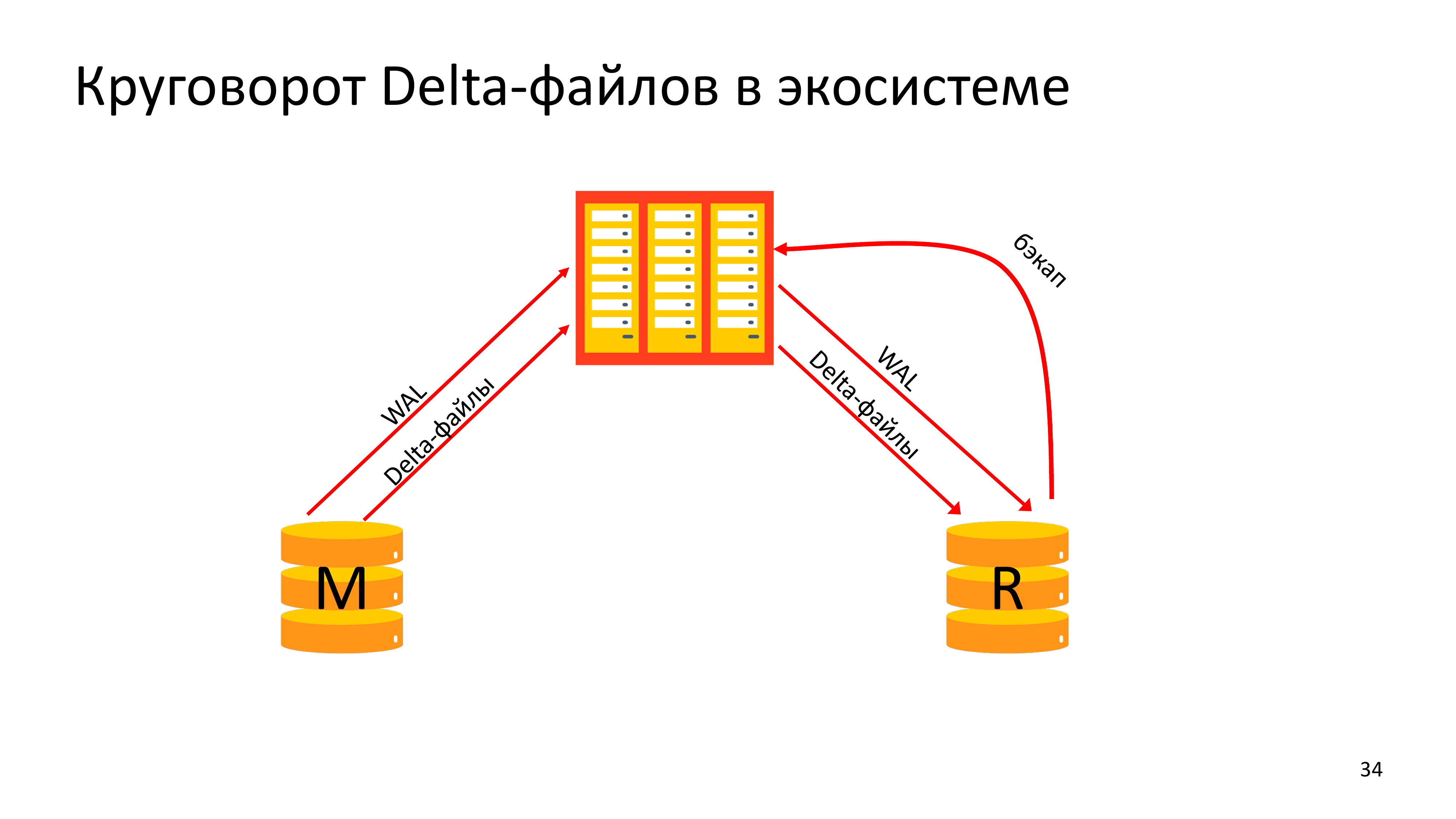
В итоге все информационные потоки выглядят довольно сложно. У нас Мастер архивирует вал и архивирует delta-файлы. А реплика, которая делает резервную копию, она должна получить delta-файлы за то время, которое прошло между бэкапами. Части истории при этом надо будет дополучить валом и его допарсить, потому что в крупные сегменты не вся история укладывается. И только после этого реплика может заархивировать полноценный delta-бэкап.
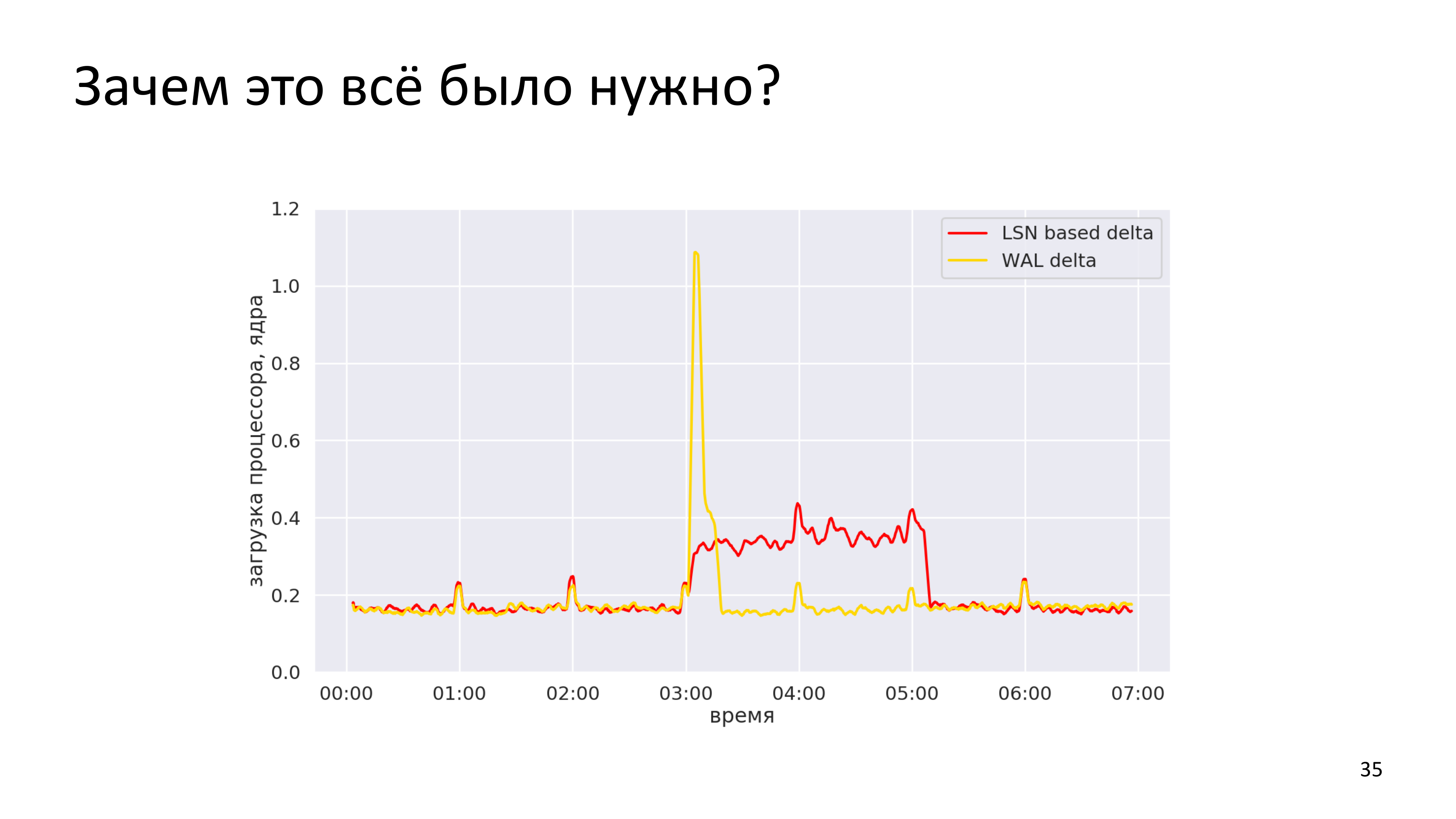
На графиках все выглядит значительно проще. Это загрузка с одного из наших реальных кластеров. У нас есть LSN-based, сделанная в один день. И мы видим, что LSN-based delta-бэкап шел с трех часов ночи до пяти ночи. Это загрузка в количестве процессорных ядер. WAL-delta у нас тут заняла примерно минут 20. Т. е. она сделалась существенно быстрее, но при этом более интенсивный обмен по сети был.

Поскольку у нас есть информация о том, какие блоки менялись и в какое время в истории базы, мы пошли дальше и решили интегрировать функциональность – расширение PostgreSQL, которое называется «pg_prefaulter»

Это означает, что, когда база на Stand-by выполняет restore command, она говорит WAL-G принести следующий WAL-файл. Мы понимаем примерно, к каким блокам данных в ближайшее время процесс восстановления WAL будет обращаться и инициируем операцию чтения на эти блоки. Сделано это для того, чтобы повысить производительность SSD контроллеров. Потому что накат WAL дойдет до страницы, которую нужно поменять. Эта страница находится на диске и отсутствует в page-кэше. И он синхронно будет ждать, когда эта страница приедет. Но рядом стоит WAL-G, который знает о том, что в ближайшее несколько сотен мегабайт WAL нам понадобятся определенные страницы и параллельно начинает их прогревать. Инициирует множество обращений к диску для того, чтобы они выполнялись параллельно. Это хорошо работает на SSD-дисках, но, к сожалению, это абсолютно не применимо для жесткого диска, потому что мы ему только мешаем своими подсказками.
Это то, что есть в коде сейчас.

Есть фичи, которые мы бы хотели дописать.
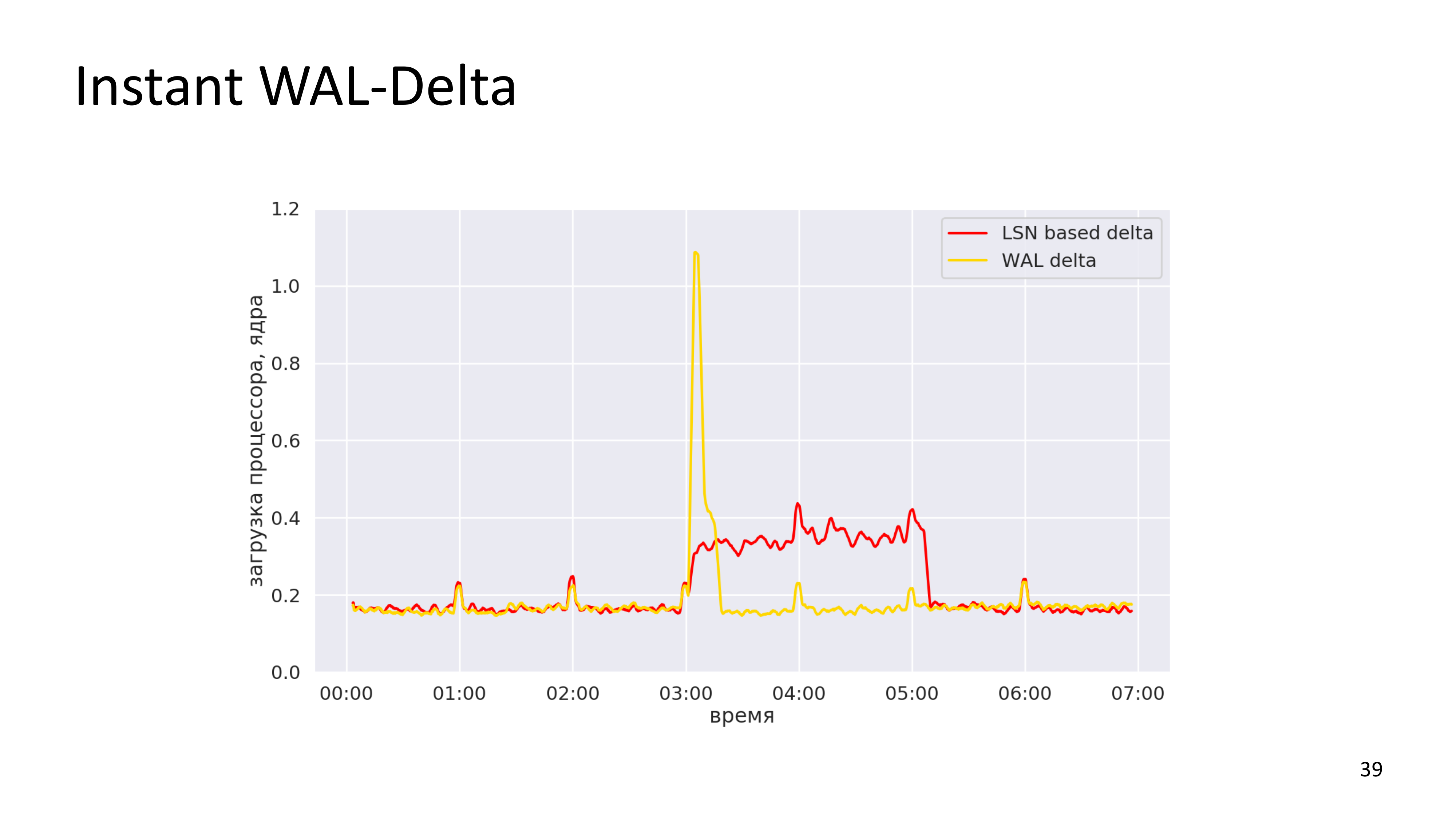
На этой картинке видно, что WAL-delta занимает относительно короткое время. И это чтение тех изменений, которые произошли в базе за сутки. Мы могли бы делать WAL-delta не только ночью, потому что она не является уже существенным источником нагрузки. Мы можем считывать WAL-delta каждую минуту, потому что это дешево. За одну минуту мы можем просканировать все изменения, которые произошли с кластером. И это можно было бы называть «instant WAL-delta».
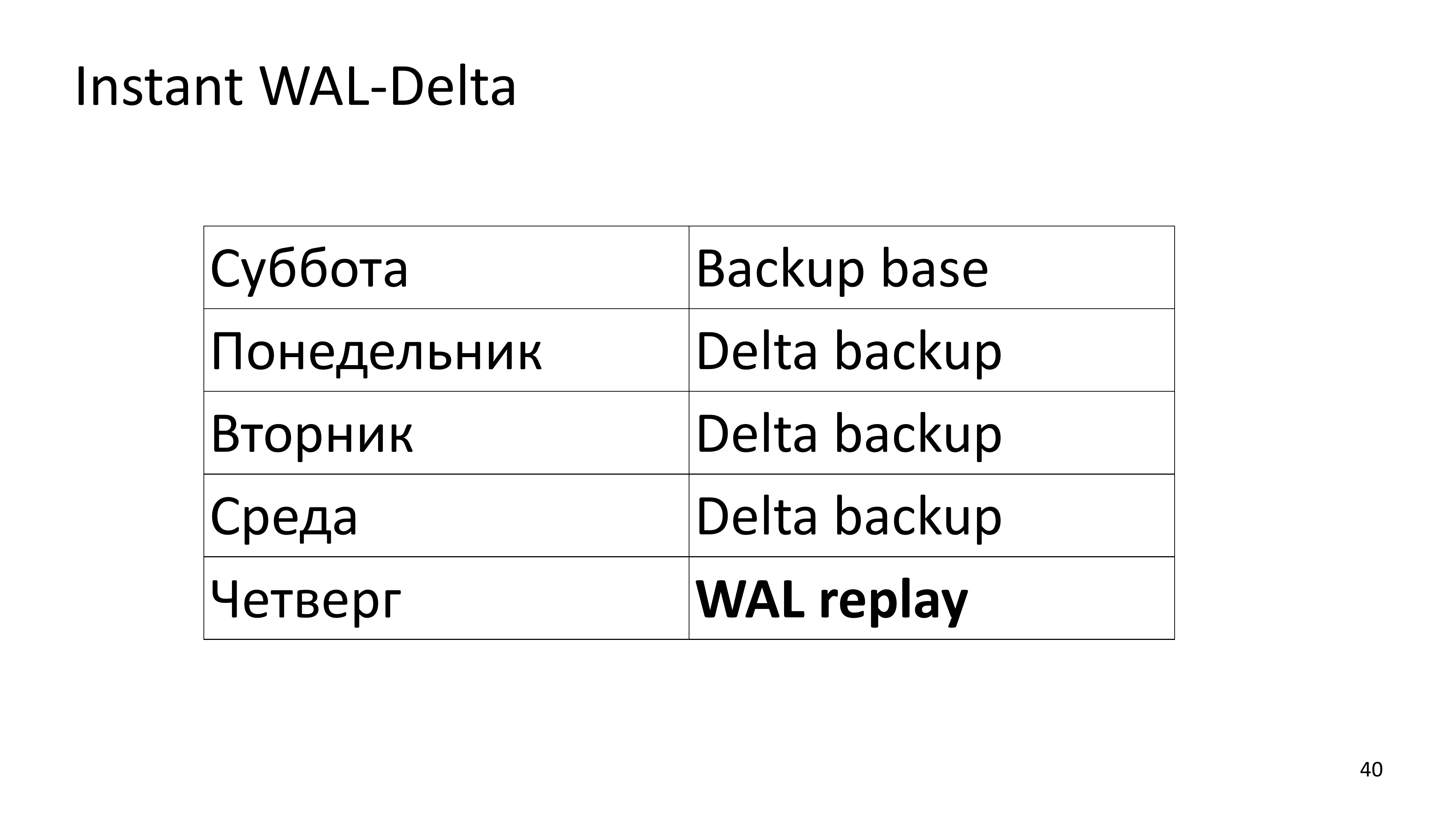
Суть в том, чтобы, когда мы восстанавливаем кластер, уменьшить количество историй, которые нам придется накатить последовательно. Т. е. количество WAL, которое накатывается PostgreSQL должно быть сокращено, потому что это занимает существенное время.
Но это не все. Если мы знаем, что какой-то блок будет изменен до точки консистентности бэкапа, мы можем его не менять в прошлом. Т. е. сейчас у нас пофайловая оптимизация наката WAL-delta. Это означает, что если, например, во вторник какая-то таблица была целиком удалена или какие-то файлы были удалены целиком из таблицы, то при накате delta в понедельник и восстановления субботнего pg_basebackup, мы эти данные даже создавать не будем.
Мы хотим эту технологию распространить на страничный уровень. Т. е. если какая-то часть файла меняется в понедельник, но при этом будет перезаписана в среду, то при восстановлении на точку в четверг, нам не нужно первые несколько версий страниц записывать на диск.
Но это пока идея, которая активно обсуждается у нас внутри, но до кода пока еще не дошло.

Еще одну фичу мы хотим сделать в WAL-G. Мы хотим сделать расширяемость, потому что нам нужно поддерживать разные базы данных и хотелось бы иметь возможность одинаково подходить к управлению бэкапами. Но проблема в том, что API MySQL отличаются радикально. У MySQL PITR основан не на физическом WAL-логе, а на binlog. И у нас нет системы архивации в MySQL, которая бы сказала какой-то внешней системе, что вот этот binlog закончен и нужно его заархивировать. Нам нужно где-то в cron стоять с базой и проверять – а нет ли чего-то готового?
И точно также во время восстановления MySQL там нет restore command, который мог бы сказать системе, что мне нужны файлы такие-то и такие-то. До того, как ты начал восстановление кластера, тебе нужно знать, какие файлы тебе понадобятся. Тебе самому нужно догадаться, какие файлы тебе понадобятся. Но эти проблемы, возможно, можно будет как-нибудь обойти. (Уточнение: MySQL уже поддерживается)

В докладе я еще хотел сказать о тех случаях, когда WAL-G вам не подходит.

Если у вас нет синхронной реплики, WAL-G не гарантирует вам сохранность последнего сегмента. И если архивация отстает от последних нескольких сегментов истории, что является риском. В случае отсутствия синхронной реплики, я бы не рекомендовал пользоваться WAL-G. Все-таки в основном он проектируется для облачной инсталляции, которая подразумевает High Availability решения с синхронной репликой, которая отвечает за сохранность закоммиченных последних байт.

Я часто вижу людей, которые пытаются одновременно эксплуатировать и WAL-G и WAL-E. Мы поддерживаем обратную совместимость в том плане, что WAL-G может восстановить вал из WAL-E и может восстановить бэкап, сделанный в WAL-E. Но поскольку обе эти системы используют параллельный wal-push, они начинают красть друг у друга файлы. Если в WAL-G мы это починим, то в WAL-E это все равно останется. В WAL-E смотрит archive-status, видит готовые файлы и архивирует их, при этом другие системы, просто не узнают о том, что этот WAL-файл существовал, потому что PostgreSQL не будет пытаться заархивировать его во второй раз.
Что мы тут починим со стороны WAL-G? Мы не будем сообщать PostgreSQL о том, что этот файл был унесен параллельно, а когда PostgreSQL нас попросит его заархивировать, мы уже будем знать, что такой файл с таким mode-time и с таким md5 уже был заархивирован и просто скажем PostgreSQL – OK, все готово, по сути, ничего не делая.
Но на стороне WAL-E вряд ли эта проблема будет чиниться, поэтому сделать archive command, который заархивирует файл и в WAL-G, и в WAL-E сейчас невозможно.
Кроме того, есть случаи, когда WAL-G вам не подходит сейчас, но мы обязательно будем это чинить.
 Во-первых, у нас сейчас нет встроенной верификации бэкапа. У нас нет верификации ни во время бэкапа, ни при восстановлении. Конечно, в облаке это реализуется. Но это реализуется просто предпроверкой, просто восстановлением кластера. Хотелось бы дать такую функциональность пользователям. Но под верификацией я предполагаю, что в WAL-G будет возможность восстановить кластер и запустить его, и прогнать smoke-тесты: pg_dumpall в /dev/null и amcheck верификацию индексов.
Во-первых, у нас сейчас нет встроенной верификации бэкапа. У нас нет верификации ни во время бэкапа, ни при восстановлении. Конечно, в облаке это реализуется. Но это реализуется просто предпроверкой, просто восстановлением кластера. Хотелось бы дать такую функциональность пользователям. Но под верификацией я предполагаю, что в WAL-G будет возможность восстановить кластер и запустить его, и прогнать smoke-тесты: pg_dumpall в /dev/null и amcheck верификацию индексов.

Сейчас в WAL-G нет возможности отложить один бэкап с WAL. Т. е. мы поддерживаем некоторое окно. Например, хранение последних семи дней, хранение последних десяти бэкапов, хранение последних трех полных бэкапов. Довольно часто люди приходят и говорят: «Нам нужен бэкап того, что было в Новый год и мы хотим хранить это вечно». WAL-G пока этого не умеет. (Примечание — Это уже починено. Подробнее — Опция backup-mark в https://github.com/wal-g/wal-g/blob/master/PostgreSQL.md)

И у нас нет проверки контрольных сумм страниц и проверки целостности всех сегментов вала при валидации PITR.

Из всего этого я составил проект для Google Summer of Code. Если вы знаете толковых студентов, которые хотели бы пописать что-либо на Go и получить несколько тысяч долларов от одной компании на букву «G», то порекомендуйте им наш проект. Я выступлю ментором этого проекта, они смогут это сделать. Если студентов не найдется, то я возьму и сделаю это сам летом.

И у нас есть других много мелких проблем, над которыми мы постепенно работаем. И встречаются довольно странные вещи.
Например, если в WAL-G дать пустой бэкап, то он просто упадет. Например, если сказать ему, что надо забэкапить пустую папку. Там не будет лежать pg_control файла. И он подумает, что он чего-то не понимает. По идее в данном случае нужно написать нормальное сообщение пользователю, чтобы объяснить ему, как пользоваться инструментом. Но это даже фича не программирования, а фича хорошего доходчивого языка.
Мы не умеем делать offline-бэкап. Если база лежит, мы не можем ее забэкапить. Но тут очень все просто. Мы называем бэкапы по LSN, когда он начался. LSN у лежащей базы нужно считывать из control файла. И это такая нереализованная фича. Многие системы резервного копирования умеют делать бэкап лежащей базы. И это удобно.
У нас сейчас не обрабатывается нормально недостаток места для бэкапа. Потому что мы обычно работаем с большими бэкапами у себя. И руки до этого не дошли. Но если кто-то хочет программировать на Go прямо сейчас, добавьте обработку ошибки недостатка места в bucket. Я обязательно посмотрю pull request.
И самое главная вещь, которая нас беспокоит, мы хотим, как можно больше докерных интеграционных тестов, которые проверяют различные сценарии. Сейчас у нас проверяются только базовые сценарии. На каждом коммите, но мы хотим покоммитно проверять всю функциональность, которую мы поддерживаем. В частности, например, нам нахватает поддержки PostgreSQL 9.4-9.5. Мы поддерживаем их, потому что сообщество поддерживает PostgreSQL, но покоммитно не проверяем, что все еще не сломалось. И, мне кажется, что это довольно серьезный риск.

WAL-G у нас работает на более, чем тысяча кластеров в Яндекс Database management. И ежедневно бэкапит несколько сотен терабайт данных.
В коде у нас очень много TODO. Если вам хочется программировать, приходите, ждем pull request, ждем вопросов.

Вопросы
Добрый вечер! Спасибо! Я так полагаю, что если вы используете WAL-delta, то, наверное, вы сильно опираетесь на full-page writes. И если да, то проводили ли вы тесты? Вы показывали красивый график. Насколько он не красивее становится, если FPW выключить?
Full-page writes у нас включен, мы не пробовали его выключать. Т. е. я, как разработчик, не пробовал его выключать. Системные администраторы, которые исследовали, наверное, исследовали этот вопрос. Но нам FPW необходим. Его практически никто не отключает, потому что иначе невозможно взять бэкап с реплики.
Спасибо за доклад! У меня два вопроса. Первый вопрос – что будет с табличными пространствами?
Мы ждем pull request. Наши базы живут на SSD и NMVE дисках и нам эта фича не очень нужна. Я прямо сейчас не готов потратить серьезное время на то, чтобы ее сделать хорошо. Я всеми руками за то, чтобы мы это поддержали. Есть люди, которые это поддержали, но поддержали в том виде, как это подходит для них. Сделали форк, но не делают pull request. (Добавлено в версии 0.2.13)
И второй вопрос. Ты в самом начале сказал, что WAL-G предполагает, что он работает один и обертки не нужны. Я сам использую обертки. А почему их не следует использовать?
Мы хотим, чтобы он был простым, как балалайка. Это означает, что тебе вообще ничего, кроме балалайки не надо. Мы хотим, чтобы система была простой. Если у тебя есть функциональность, которую тебе необходимо сделать в скрипте, то приходи и рассказывай – сделаем ее на Go.
Добрый вечер! Спасибо за доклад! У нас не получилось заставить работать WAL-G с GPG дешифрованием. Шифрует нормально, дешифровать не хочет. Это у нас что-то не сложилось? Ситуация удручающая.
Создавайте вопрос на GitHub, давайте разбираться.
Т. е. не сталкивались с таким?
Там есть особенность репорта ошибок, что когда WAL-G не понимает, что это за файл, он спрашивает: «Может быть, он зашифрован?». Возможно, проблема совсем не в шифровании. Я хочу поправить логирование на эту тему. Расшифровать он должен. На эту тему мы сейчас работаем в том плане, что не очень нравится, как организована система получения публичных и приватных ключей. Потому что мы вызываем внешний GPG для того, чтобы он нам отдал свои ключи. А потом мы эти ключи берем и передаем внутреннему GPG, который open PGP, который к нам компилирован вовнутрь WAL-G, и там вызываем шифрование. В этом плане мы хотим систему улучшить и хотим поддержать шифрование Libsodium (Добавлено в версии 0.2.15). Конечно, расшифрование должно работать, давайте разбираться – больше симптомом нужно, чем пара слов. Можно как-нибудь собраться в комнате докладчика и посмотреть на систему. (PGP encryption without external GPG — v0.2.9)
Привет! Спасибо за доклад! У меня два вопроса. У меня есть странное желание для того, чтобы делать pg_basebackup и WAL log в два провайдера, т. е. я хочу в одно облако и в другое. Есть ли какой-то способ сделать это?
Сейчас этого нет, но идея интересная.
Просто я одному провайдеру не доверяю, мне хочется в другом на всякий случай иметь тоже.
Идея интересная. Технически это реализовать совсем не сложно. Чтобы идея не потерялась, можно попросить сделать issue на GitHub?
Да, конечно.
И тогда, когда придут студенты на Google Summer of Code, мы добавим им в проект, чтобы больше было работы, чтобы больше получить от них.
И второй вопрос. Есть issue на GitHub. Он, по-моему, уже закрыт. Есть паника при restore. И чтобы ее победить, ты делал отдельную сборку. Она лежит прямо в issues. И есть вариант, что переменное окружение в один поток делать. И очень медленно поэтому работает. И мы сталкивались с этой проблемой, и пока это не починилось.
Проблема в том, что почему-то хранилище (CEPH) сбрасывает соединение, когда мы к нему приходим с большим параллелизмом. Что с этим можно сделать? Логика retry выглядит следующим образом. Мы пытаемся загрузить файл заново. За один проход у нас сколько-то файлов не загрузилось, мы сделаем второй для всех тех, кто не зашел. И пока хотя бы один файл за итерацию загружается, мы повторяем и повторяем, и повторяем. Мы дорабатывали логику retry — exponential backoff. Но не совсем понятно, что делать с тем, что соединение просто обрывается со стороны системы хранения. Т. е. когда мы закачиваем в один поток, она эти соединения не обрывает. Что мы тут можем улучшить? У нас сетевой троттлинг у нас есть, мы можем каждое соединение ограничить по количеству байт, которое оно отправляет. В остальном, как бороться с тем, что объектное хранилище не дает нам параллельно закачивать или из него выкачивать, я не знаю.
Нет никакого SLA? Не написано у них, как они позволяют себя мучить?
Суть в том, что люди, которые приходят с этим вопросом, обычно имеют свое хранилище. Т. е. с Amazon или с Google Cloud, или с Yandex Object Storage никто не приходит.
Может вопрос уже не к вам?
Вопрос тут в данном случае неважно к кому. Если есть какие-то идеи, как с этим бороться, давайте мы это сделаем в WAL-G. Но пока у меня хороших идей, как с этим бороться нет. Есть некоторые Object Storage, которые по-другому поддерживают listing бэкапов. Ты их просишь перечислить объекты, а они туда добавляют еще folder. WAL-G при этом пугается – тут есть какая-то штука, которая не файл, я не могу его восстановить, значит, бэкап не восстановился. Т. е. на самом деле у тебя лежит полностью восстановленный кластер, но он тебе возвращает ошибочный статус, потому что Object Storage вернул какую-то странную информацию, которую он не до конца понял.
Это в облаке Mail возникает такая штука.
Если можно построить reproduce…
Оно стабильно вопроизводится…
Если есть reproduce, то, я думаю, что мы поэкспериментируем со стратегиями retry и придумаем, как ретраить и понимать, что от нас требует облако. Может быть, оно нам стабильно на трех соединениях не будет рвать соединение, тогда мы будем аккуратненько доходить до трех. Потому что сейчас мы соединение бросаем очень быстро, т. е. если запустил восстановление в 16 потоков, то после первого же retry там будет 8 потоков, 4 потоков, 2 потоков и один. И дальше он будет по файлику тянуть в один поток. Если есть какие-то магические значения типа 7,5 потоков лучше всего качается, то мы будем на них задерживаться и пробовать еще по 7,5 потоков делать. Вот такая идея есть.
Спасибо за доклад! Как выглядит полный workflow работы с WAL-G? Например, в дурацком случае, когда дельты по страницам нет. И мы берем и снимаем начальный бэкап, потом архивируем вал до посинения. Здесь, как я понимаю, есть разбивка. В какой-то момент нужно сделать delta-бэкап страниц, т. е. какой-то внешний процесс это драйвит или как это случается?
API delta-бэкапов довольно простое. Там есть число – max delta steps, вроде так называется. Он по дефолту в нуле. Это означает, что каждый раз, когда ты делаешь backup-push, он закачивает полный бэкап. Если ты его меняешь на любое положительное число, например, на 3, то, когда ты в следующий раз делаешь backup-push, он смотрит историю предыдущих бэкапов. Видит, что ты не превышаешь цепочку в 3 дельты и делает дельту.
Т. е. каждый раз, когда мы запускаем WAL-G, он пытается сделать полный бэкап?
Нет, мы запускаем WAL-G, и он пытается сделать дельту, если разрешено это твоими политиками.
Грубо говоря, если каждый раз запускать его с нулем, то он будет себя вести как pg_basebackup?
Нет, он все равно будет работать быстрее, потому что он использует сжатие и параллелизм. Pg_basebackup тебе рядом положит вал. WAL-G рассчитывает на то, что у тебя настроена архивация. И будет выдавать warning, если она не настроена.
Pg_basebackup можно запустить без валов.
Да, тогда они будут вести себя почти одинаково. Pg_basebackup копирует на файловую систему. У нас есть, кстати, нова фича, о которой я забыл сказать. Мы теперь можем из pg_basebackup на файловую систему бэкапиться. Не знаю, зачем это надо, но это есть.
Например, на CephFS. Не все хотят Object Storage конфигурировать.
Да, наверное, поэтому и задавали вопрос про эту фичу, чтобы мы ее сделали. И мы ее сделали.
Спасибо за доклад! Есть как раз вопрос по поводу копирования на файловую систему. Из коробки вы сейчас поддерживаете копирование на remote storage, например, если какая-то полка в ЦОД или еще что-нибудь?
В такой формулировке – это сложный вопрос. Да, мы поддерживаем, но эта функциональность еще не включена ни в один релиз. Т. е. все предрелизы это поддерживают, но в релизных версиях этого нет. Эта функциональность добавлена в версию 0.2. Она обязательна скоро окажется в релизе, как только мы починим все известные баги. Но прямо сейчас это можно сделать только в предрелизе. В предрелизе есть два бага. Проблема с восстановлением WAL-E, это мы не починили. И в последнем предрелизе добавлен баг про delta-backup. Поэтому мы всем рекомендуем пользоваться релизными версиями. Как только в предрелизе перестанут находиться баги, можно будет сказать, что мы поддерживаем Google Cloud, S3-совместимые вещи и файловый storage.
Привет, спасибо за доклад. Как я понял, WAL-G – это не централизованная какая-то система как barmen? Планируете ли в этом направлении двигаться?
Проблема в том, что мы ушли от этого направления. WAL-G живет на хосте базы, на хосте кластера, причем на всех хостах кластера. Когда мы перешли в несколько тысяч кластеров, у нас было много инсталляций бармена. И каждый раз, когда в них что-то разваливается, это большая проблема. Потому что их нужно чинить, нужно понять, какие кластера теперь не имеют бэкапов. В направлении физического железа под системы резервного копирования я развивать WAL-G не планирую. Если сообщество захочет какую-то функциональность здесь, я ничуть не против.
У нас есть команды, которые отвечают за storage. И нам так хорошо, что это не мы, что есть специальные люди, которые кладут наши файлики туда, где файликам безопасно. Они делают там всякие хитрые кодирования так, чтобы выдерживать потери какого-то количества файлов. Они отвечают за пропускную способность сети. Когда у тебя есть бармен, у тебя неожиданно может выясниться, что в один и тот же сервер съехались маленькие базы с большим трафиком. У тебя вроде бы на нем куча места, но почему-то не влезает все через сеть. Может оказаться наоборот. Сети много там, процессорные ядра есть, но диски здесь кончились. И эта необходимость жонглировать чем-то нам надоела, и мы перешли к тому, что хранение данных – это отдельный сервис, за который отвечает отдельные специальные люди.
P.S Вышла новая версия 0.2.15, в которой можно использовать файл конфигурации .walg.json, который по умолчанию находится в домашней директории postgres. Можно отказаться от bash скриптов. Пример .walg.json находится в этом issue https://github.com/wal-g/wal-g/issues/545
Видео:




