
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Любая компания рано или поздно сталкивается с вопросом обработки большого объема входящей документации. В первую очередь это может быть, например, бухгалтерия со своими первичными документами: счетами, актами, накладными, либо HR-отдел с больничными и заявлениями на отпуск. Когда определенные задачи выполняются систематически, с постоянной четкой логикой, и при этом фигурируют в большом количестве бизнес-процессов, становится экономически выгодной их роботизация. UiPath предлагает использовать программных роботов для автоматизации процесса обработки входящих документов — Document Understanding.
Как выяснилось в последнее время, наши заказчики не всегда в курсе того, что UiPath может справляться с задачами, связанными с обработкой бумажных документов. Так вот: UiPath не просто отображает документы, роботы могут их распознавать, извлекать данные и передавать их в любую нужную вам систему.
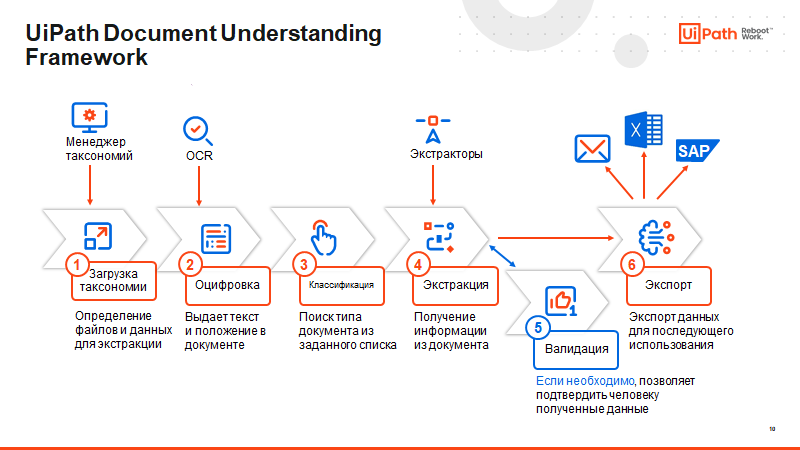
Фреймворк Document Understanding
В начале года мы уже рассказывали о том, что такое Document Understanding или интеллектуальная обработка документов в целом. Это многосоставной процесс, который включает сканирование, распознавание документа средствами OCR, классификацию документа и извлечение требуемых полей.
Уже на этапе OCR может возникать ряд проблем. Например, необходимо распознать миллион страниц документов. Представим, что из них 900 тысяч — простые, а 100 тысяч — сложные для распознавания. Если покупать лицензии у одного поставщика средств OCR на весь этот миллион документов, то платить придется одинаково и за простые, и за сложные страницы. Обработка простых документов оказывается дорогостоящим делом.
Вдобавок классические системы распознавания сами по себе не дают возможности сразу же передавать данные в ваши системы: 1С, SAP и т.д. А именно это и требуется после распознавания.
UiPath Document Understanding — это фреймворк, который закрывает весь процесс обработки документа. Документы могут поступать абсолютно из любого источника, при этом фреймворк независим от вендора OCR. В систему уже интегрированы несколько движков, в том числе ABBYY, Omnipage, Microsoft OCR, Google Tesseract OCR и других. Может использоваться также и собственная система распознавания текста UiPath OCR. Какой именно движок использовать — решает сам заказчик, отталкиваясь от своих задач.
Процедура обработки документа включает набор активностей, шаблон процесса для использования этих активностей, станции классификации и валидации. Станция валидации — это опциональный модуль, который не обязательно присутствует в проекте.
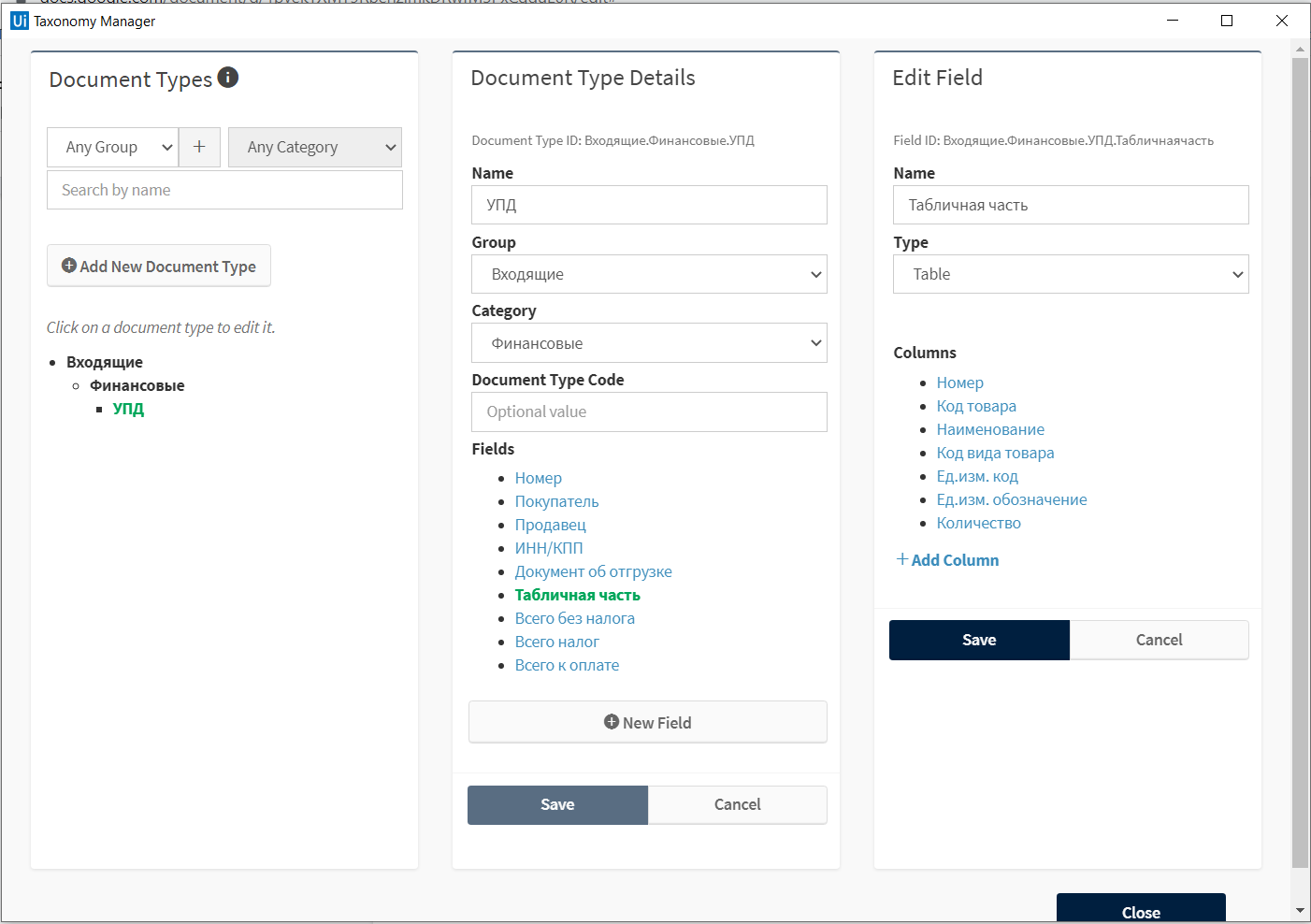
Таксономия и OCR
Распознавание начинается с определения таксономии. Для ее создания нужно указать используемые типы документов: например, счет-фактура, акт, товарная накладная. Дальше для каждого типа документов указываются те поля, данные из которых будет извлекать робот. Информация о типах документов и полях сохраняется в формате JSON.. После того как таксономия определена, мы можем начинать обработку.

OCR — это оптическое распознавание графических изображений и преображение их в машиночитаемые символы. В разработках UiPath используются наиболее популярные движки как платные, так и бесплатные. Существует возможность использовать сразу несколько движков распознавания. Например, отправлять часть наиболее сложных документов на платные движки — ABBYY или Google Cloud, а остальные – на бесплатные, например, на OmniPage.
Есть 3 разных варианта распределения документов на разные OCR-движки:
Первый вариант – создавать разные проекты для разных типов документов. Это применимо в том случае, когда мы знаем, например, что все акты сверки у нас хорошего качества, а счета-фактуры — плохого. В таком случае нет смысла отправлять акты сверки на платный движок, тут можно сэкономить. На продвинутые движки направляются только счета-фактуры.
Второй вариант – отправить сразу все документы на бесплатный движок распознавания. На выходе каждый движок показывает степень уверенности, с которой он распознал документ. В проекте можно задать фильтр, определяющий, куда дальше документ направляется. Если степень уверенности распознавания оказывается меньше 80-90%, то такие документы передаются уже на более продвинутый платный движок.
Есть и третий вариант. Можно прогнать всё через бесплатный движок и посмотреть, как распознались, к примеру, названия контрагентов. Например, в счетах значится «Ромашка Inc.» Отправляем данные в ERP-систему и смотрим, есть ли у нас такой поставщик. Если есть, значит всё распозналось хорошо. Если вместо «Ромашки» всплывает что-то вроде «Ормашок», и он не значится в базе, то мы делаем вывод, что что-то распозналось некорректно, и документ отправляется на повторное распознавание — уже на платный движок.
Классификация документов
После того, как робот распознал документ, нужно определить его тип. За это отвечают классификаторы. Подробнее о классификаторах читайте в нашей предыдущей статье.
Извлечение данных и якоря
После определения типа документа робот обращается к таксономии за списком необходимых полей и начинает этап извлечения текстовых данных. Для этого этапа у нас есть пять стандартных экстракторов:
Form Extractor — экстрактор форм с поддержкой назначаемых якорей;
Intelligent Form Extractor — экстрактор форм, который умеет работать с рукописным текстом, правда, пока только с английским, и подписями;
Regex Extractor — экстрактор на базе регулярных выражений;
Machine Learning Extractor, который использует модели машинного обучения;
FlexiCapture Extractor, который использует шаблоны ABBYY FlexiLayout.
Экстрактор форм хорошо работает со структурированными данными: больничными, счетами-фактурами, УПД, товарными накладными и т.п. Тут очень кстати оказываются якоря, с помощью которых мы указываем роботу, в какой части документа размещаются определенные данные. Якорей может быть сколь угодно много, всё зависит от документа.
Якоря в экстракторе форм — недавно добавленная функция, которая значительно расширила его возможности. Теперь можно извлекать данные из гораздо большего объёма документов, чем раньше.
Часто используется и Regex Extractor, поскольку он бесплатный и позволяет закрывать большую часть задач. Это мощное решение, позволяющее извлекать большое количество данных с учётом множества факторов — например, неожиданных переносов строк и т.д. Он также позволяет работать с полностью неструктурированными данными — массивами документов, написанных в произвольной форме. Их вполне успешно можно обрабатывать с помощью Regex при условии правильной настройки регулярных выражений. Для этой цели может служить собственный конструктор таких выражений в UiPath Studio – или популярный сайт regex101.com.
Как и в случае с движками распознавания, можно использовать параллельно сразу несколько экстракторов; более того, назначать свой экстрактор возможно для каждого поля. Например, Intelligent Form Extractor — для номера документа, для номера заказа — Regex, для даты — FlexiCapture. Разные экстракторы могут быть задействованы в зависимости от степени уверенности, которую экстрактор выдаёт на выходе. Если один экстрактор не отработал как ожидалось, за дело берётся другой, по порядку их расположения.
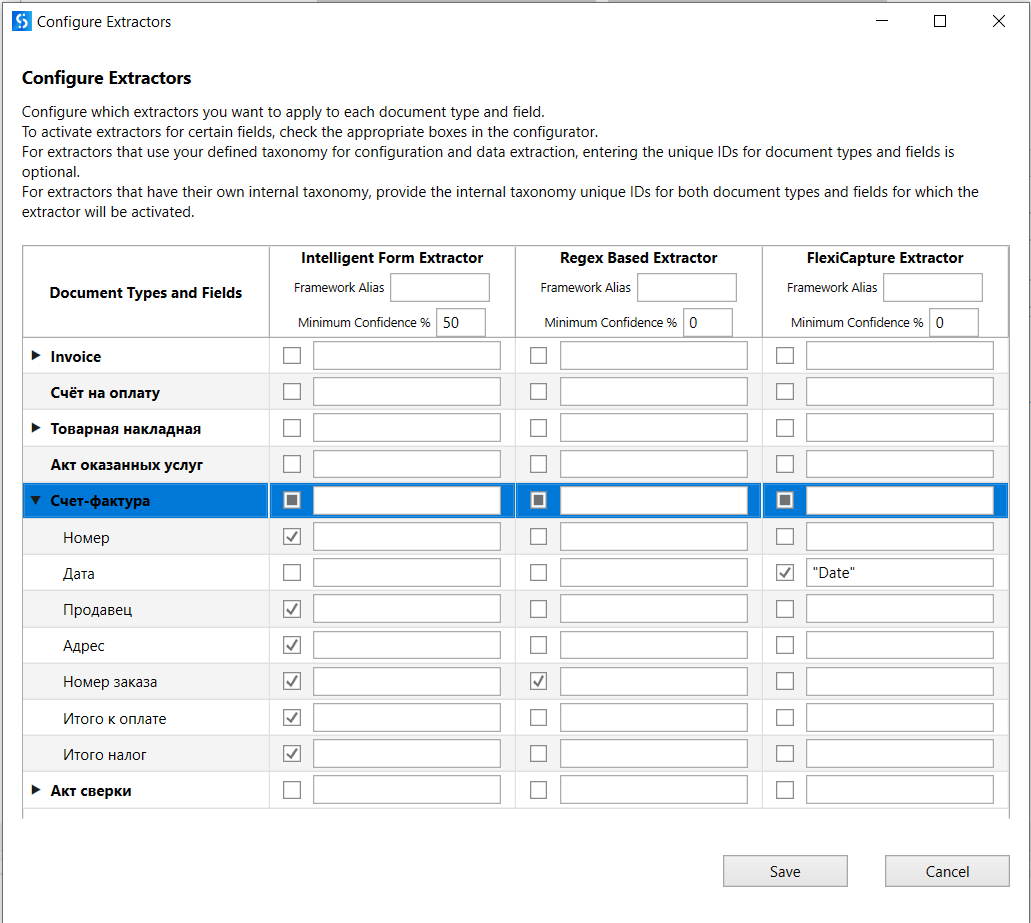
Стоит отметить, что для встроенных экстракторов UiPath Studio не понадобится прописывать никакие поля, а вот для сторонних, например, FlexiCapture, потребуется указать, какие поля в экстракторе (в шаблоне) соответствуют какому полю в вашей таксономии.
Извлекать можно не только текстовые данные, но и информацию о печати и подписях. Для этого можно использовать OpenCV; это достаточно долго и сложно, поскольку требует соответствующих компетенций, но зато бесплатно. Также можно использовать ML-модель для обнаружения подписей и печатей, например, Microsoft Custom Vision или UiPath AICenter. Это быстро, просто, но стоит денег. Наконец, для нахождения подписей можно использовать Intelligent Form Extractor.
Настройка шаблона и работа с таблицами
Инструментарий UiPath Studio позволяет распознавать многостраничные таблицы и извлекать из них информацию. Как это делается, покажем на примере УПД.
В UiPath Studio при создании таксономии создаем поле с типом «таблица». В этом поле описываем наши колонки. В нашем примере таксономия выглядит следующим образом (мы оставили 7 колонок):
В активности Form Extractor переходим в Manage Templates. Создаём новый шаблон, определяем тип документа (УПД) и выбираем цифровой документ, на основе которого будет строиться шаблон. В идеале это должен быть чистый PDF (не скан). Если это скан, желательно, чтобы он был хорошего качества и правильно ориентирован; функция автоматического поворота работает при распознавании, но для создания шаблона необходимо, чтобы документ уже был повёрнут правильно.
В нашем примере мы будем работать со сканом: нажимаем Manage Templates, а затем Create Template.


После того, как документ оцифровывается, появляется форма, где справа сам документ — отсканированный двухстраничный УПД, а слева — сформированные в нашей таксономии поля.
Далее начинается процесс разметки документа для робота. Вариантов тут несколько. Можно указать точную область, где находится нужное нам поле. Например, номер документа будет всегда находиться на одном и том же месте. Это хорошо работает для анкет и других жестко фиксированных документов, однако, мало применимо для полуструктурированных документов. Лучше использовать уже упомянутые якоря. С их помощью отмечаем, где какие элементы располагаются.
К примеру, указываем место, где расположен номер документа, а в качестве якоря используем слова «Счет-фактура» и «от».

Для данного поля мы указали 2 якоря: основной «счет фактура» и дополнительный «от».
В сущности, якорей может быть неограниченное количество и находиться они могут где угодно. Кстати, например, для поля ИНН/КПП мы рекомендуем использовать регулярные выражения.
Переходим к таблицам. Довольно часто приходится иметь дело с ситуацией, когда в примерно одинаковых документах таблицы могут значительно отличаться друг от друга по количеству страниц. В таком случае для шаблона необходимо выбрать документ с максимальным количеством страниц (например, 100) и разметить его целиком. При обработке документов робот будет извлекать данные из всего диапазона, с первой до сотой страницы включительно. То есть для документа с 99 страницами обработка пройдет успешно, а для 101-страничного документа — уже нет.
Разделители таблицы формируются автоматически, но если где-то они не начертились, их можно выставить вручную (и удалить лишние). Для каждой колонки необходимо выставить её название в соответствии с названиями колонок в таксономии. Стоит отметить, что ширина колонок на всех документах должна быть одинакова.
Процесс разметки таблицы выглядит следующим образом:
Посмотрим, как отработает наш шаблон с другим УПД. В нем таблица будет на одну страницу, вместо двух. Результаты извлечения видны на скриншоте ниже.

С этой таблицей есть нюансы. Первые строки извлечены корректно. Но так как в шаблоне у таблицы были две страницы, а не одна, робот не смог понять, где заканчивается таблица на одностраничном документе. Поэтому всё, что следует в документе за таблицей, он также посчитал её частью. Такие таблицы будут нуждаться в пост-обработке.
Суммируя вышесказанное
Мы рассмотрели общую структуру функционирования фреймворка Document Understanding в UiPath Studio. Она довольно проста и её использование не требует особо продвинутых компетенций и больших усилий, особенно, если иметь в виду, с какими объемами документации помогут в итоге справиться роботы.
Также вкратце продемонстрирован процесс работы с многостраничными таблицами и извлечение данных из них.
Задачей фреймворка является максимальная рационализация и автоматизация процесса обработки входящих документов, вне зависимости от их качества или ориентации. При распознавании происходит автоматическая корректировка расположения текста на странице и структуры данных. Долгое время машинам было не под силу справляться с подобными задачами, но сейчас роботы вполне этому научились, а значит, есть смысл перепоручить это занятие им.



