
Посмотрим, что происходит, когда вы выполняете git rebase и почему нужно быть внимательным.
Это вторая и третья части гайда по Git из блога Pierre de Wulf в переводе команды Mail.ru Cloud Solutions. Первую часть можно почитать тут.
Как именно происходит rebase:
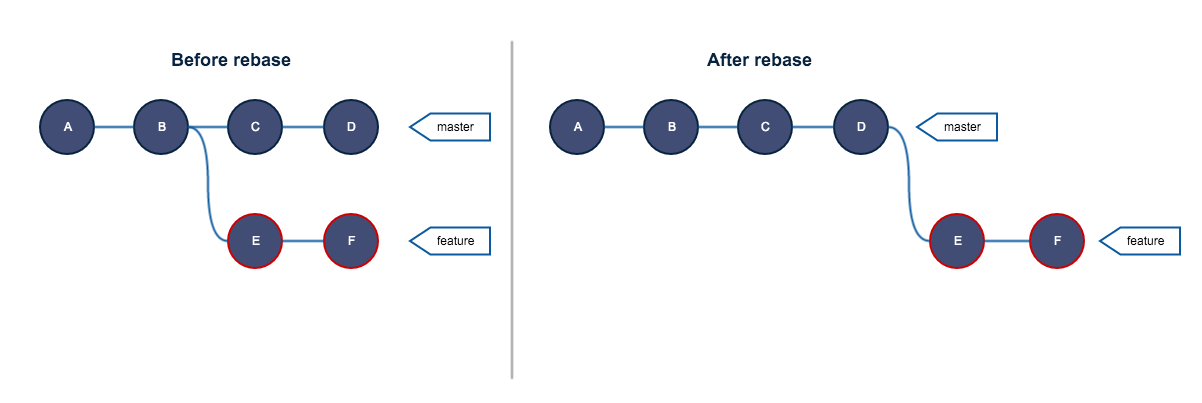
Можно сказать, что rebase — это открепить ветку (branch), которую вы хотите переместить, и подключить ее к другой ветке. Такое определение соответствует действительности, но попробуем заглянуть чуть глубже. Если вы посмотрите документацию, вот что там написано относительно rebase: «Применить коммиты к другой ветке (Reapply commits on top of another base tip)».
Главное слово здесь — применить, потому что rebase — это не просто копипаст ветки в другую ветку. Rebase последовательно берет все коммиты из выбранной ветки и заново применяет их к новой ветке.
Такое поведение приводит к двум моментам:
Вот более правильная интерпретация того, что происходит при rebase:

Как видите, ветка feature содержит абсолютно новые коммиты. Как было сказано ранее, тот же самый набор изменений, но абсолютно новые объекты с точки зрения Git.
Это также означает, что старые коммиты не уничтожаются. Они становятся просто недоступными напрямую. Если вы помните, ветка — всего лишь ссылка на коммит. Таким образом, если ни ветка, ни тег не ссылаются на коммит, к нему невозможно получить доступ средствами Git, хотя на диске он продолжает присутствовать.
Теперь давайте обсудим «Золотое правило».
Золотое правило rebase звучит так — «НИКОГДА не выполняйте rebase расшаренной ветки!». Под расшаренной веткой понимается ветка, которая существует в сетевом репозитории и с которой могут работать другие люди, кроме вас.
Часто это правило применяют без должного понимания, поэтому разберем, почему оно появилось, тем более что это поможет лучше понять работу Git.
Давайте рассмотрим ситуацию, когда разработчик нарушает золотое правило, и что происходит в этом случае.
Предположим, Боб и Анна вместе работают над проектом. Ниже представлено, как выглядят репозитории Боба и Анны и исходный репозиторий на GitHub:

У всех пользователей репозитории синхронизируются с GitHub.
Теперь Боб, нарушая золотое правило, выполняет rebase, и в это же время Анна, работая в ветке feature, создает новый коммит:
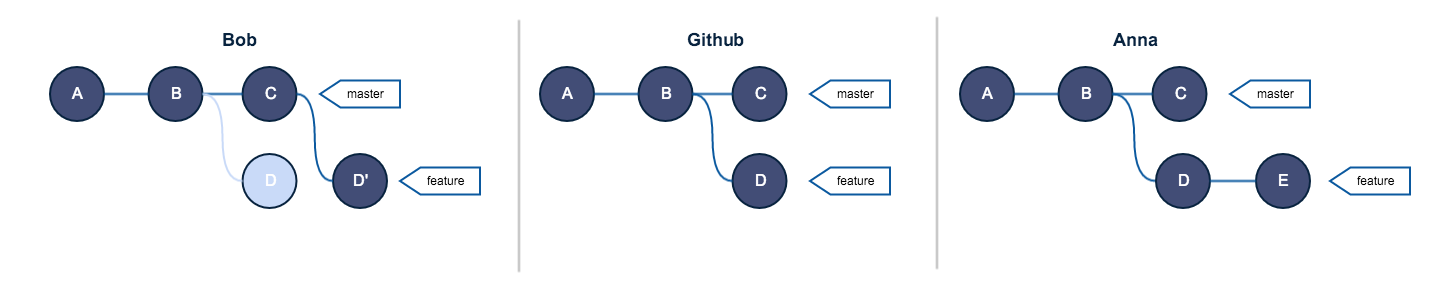
Вы видите, что произойдет?
Боб пытается выполнить пуш коммита, ему приходит отказ примерно такого содержания:

Выполнение Git не было успешным, потому что Git не знает, как объединить feature ветку Боба с feature веткой GitHub.
Единственным решением, позволяющим Бобу выполнить push, станет использование ключа force, который говорит GitHub-репозиторию удалить у себя ветку feature и принять за эту ветку ту, которая пушится Бобом. После этого мы получим следующую ситуацию:

Теперь Анна хочет запушить свои изменения, и вот что будет:

Это нормально, Git сказал Анне, что у нее нет синхронизированной версии ветки feature, то есть ее версия ветки и версия ветки в GitHub — разные. Анна должна выполнить pull. Точно таким же образом, как Git сливает локальную ветку с веткой в репозитории, когда вы выполняете push, Git пытается слить ветку в репозитории с локальной веткой, когда вы выполняете pull.
Перед выполнением pull коммиты в локальной и GitHub-ветках выглядят так:
Когда вы выполняете pull, Git выполняет слияние для устранения разности репозиториев. И вот, к чему это приводит:

Коммит M — это коммит слияния (merge commit). Наконец, ветки feature Анны и GitHub полностью объединены. Анна вздохнула с облегчением, все конфликты устранены, она может выполнить push.
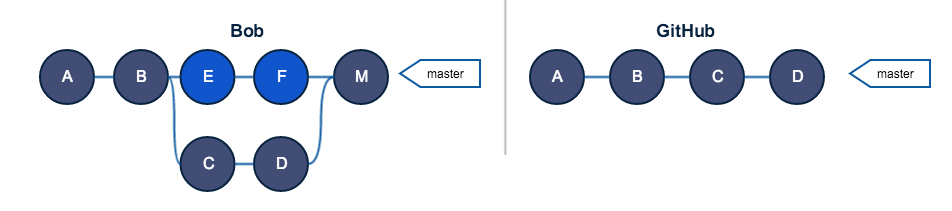
Боб выполняет pull, теперь все синхронизированы:

Глядя на получившийся беспорядок, вы должны были убедиться в важности золотого правила. Также учтите, что подобный беспорядок был создан всего одним разработчиком и на ветке, которая расшарена всего между двумя людьми. Представьте, что будет в команде из десяти человек.
Одним из многочисленных достоинств Git является то, что можно без проблем откатиться на любое время назад. Но чем больше допущено ошибок, подобных описанной, тем сложнее это сделать.
Также учтите, что появляются дубликаты коммитов в сетевом репозитории. В нашем случае — D и D’, содержащие одни и те же данные. По сути, количество дублированных коммитов может быть таким же большим, как и количество коммитов в вашей rebased ветке.
Если вы все еще не убеждены, давайте представим Эмму — третью разработчицу. Она работает в ветке feature перед тем, как Боб совершает свою ошибку, и в настоящий момент хочет выполнить push. Предположим, что к моменту ее push наш маленький предыдущий сценарий уже завершился. Вот что выйдет:
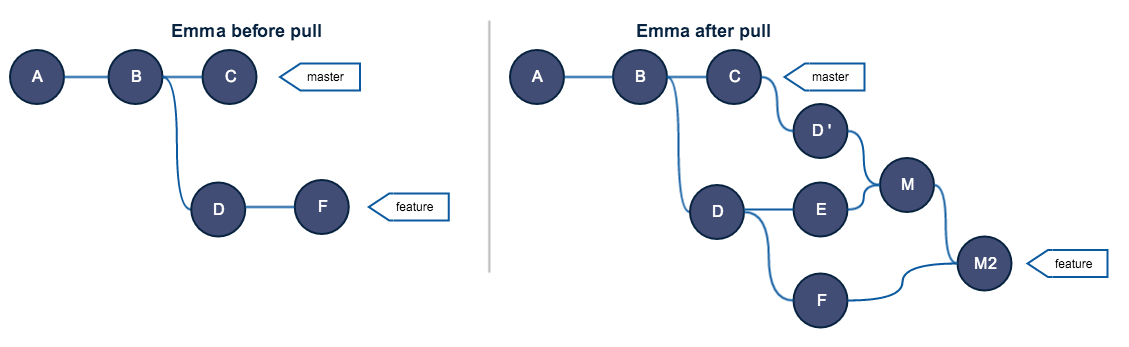
Ох уж этот Боб!!!!
Этот текст мог заставить вас подумать, что rebase используют только для перемещения одной ветки на верхушку другой ветки. Это необязательно — вы можете выполнять rebase и на одной ветке.
Как вы видели выше, проблем Анны можно было избежать, если бы она использовала pull rebase. Рассмотрим этот вопрос подробнее.
Допустим, Боб работает в ветке, отходящей от мастера, тогда его история может выглядеть вот так:

Боб решает, что настало время выполнить pull, что, как вы уже поняли, приведет к некоторым неясностям. Поскольку репозиторий Боба отходил от GitHub, Git спросит делать ли объединение, и результат будет таким:
Это решение подходит и работает нормально, однако, вам может быть полезно знать, что есть другие варианты решения проблемы. Одним из них является pull-rebase.
Когда вы делаете pull-rebase, Git пытается выяснить, какие коммиты есть только в вашей ветке, а какие — в сетевом репозитории. Затем Git объединяет коммиты из сетевого репозитория с самым свежим коммитом, присутствующим и в локальном, и в сетевом репозитории. После чего выполняет rebase ваших локальных коммитов в конец ветки.
Звучит сложно, поэтому проиллюстрируем:

Как вы помните, при rebase Git применяет коммиты один за одним, то есть в данном случаем применяет в конец ветки master коммит E, потом F. Получился rebase сам в себя. Выглядит неплохо, но возникает вопрос — зачем так делать?
По моему мнению, самая большая проблема с объединением веток в том, что загрязняется история коммитов. Поэтому pull-rebase — более элегантное решение. Я бы даже пошел дальше и сказал, что когда нужно скачать последние изменения в вашу ветку, вы всегда должны использовать pull-rebase. Но нужно помнить: поскольку rebase применяет все коммиты по очереди, то когда вы делаете rebase 20 коммитов, вам, возможно, придется решать один за другим 20 конфликтов.
Как правило, можно использовать следующий подход: одно большое изменение, сделанное давно — merge, два маленьких изменения, сделанных недавно — pull-rebase.
Предположим, история ваших коммитов выглядит так:
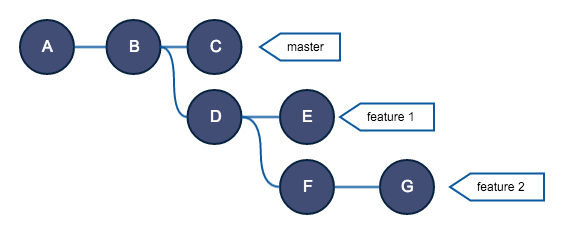
Итак, вы хотите выполнить rebase ветки feature 2 в ветку master. Если вы выполните обычный rebase в ветку master, получите это:
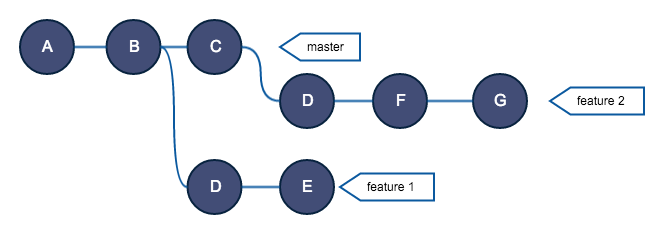
Нелогично выглядит то, что коммит D существует в обоих ветках: в feature 1 и feature 2. Если вы переместите ветку feature 1 в конец ветки мастер, получится, что коммит D будет применен два раза.
Предположим, что вам нужно получить другой результат:
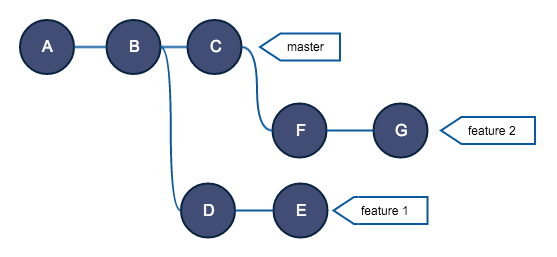
Для реализации подобного сценария как раз и предназначен git rebase onto.
Сначала прочтем документацию:
Нас интересует вот это:
С помощью этой опции указывается, в какой точке создавать новые коммиты.
Если эта опция не указана, то стартовой точкой станет upstream.
Для понимания приведу еще один рисунок:
То есть ветка master — это newbase, а ветка feature 1 — upstream.
Таким образом, если вы хотите получить результат как на последнем рисунке, необходимо выполнить в ветке feature2 git rebase --onto master feature1.
Удачи!
Переведено при поддержке Mail.ru Cloud Solutions.
Что еще почитать по теме:
Это вторая и третья части гайда по Git из блога Pierre de Wulf в переводе команды Mail.ru Cloud Solutions. Первую часть можно почитать тут.
Суть rebase
Как именно происходит rebase:
Можно сказать, что rebase — это открепить ветку (branch), которую вы хотите переместить, и подключить ее к другой ветке. Такое определение соответствует действительности, но попробуем заглянуть чуть глубже. Если вы посмотрите документацию, вот что там написано относительно rebase: «Применить коммиты к другой ветке (Reapply commits on top of another base tip)».
Главное слово здесь — применить, потому что rebase — это не просто копипаст ветки в другую ветку. Rebase последовательно берет все коммиты из выбранной ветки и заново применяет их к новой ветке.
Такое поведение приводит к двум моментам:
- Переприменяя коммиты, Git создает новые коммиты. Даже если они содержат те же изменения, то рассматриваются Git как новые и независимые коммиты.
- Git rebase переприменяет коммиты и не удаляет старые. Это значит, что после выполнения rebase ваши старые коммиты продолжат храниться в подпапке /оbjects папки .git. Если вы не до конца понимаете, как Git хранит и учитывает коммиты, почитайте первую часть этой статьи.
Вот более правильная интерпретация того, что происходит при rebase:
Как видите, ветка feature содержит абсолютно новые коммиты. Как было сказано ранее, тот же самый набор изменений, но абсолютно новые объекты с точки зрения Git.
Это также означает, что старые коммиты не уничтожаются. Они становятся просто недоступными напрямую. Если вы помните, ветка — всего лишь ссылка на коммит. Таким образом, если ни ветка, ни тег не ссылаются на коммит, к нему невозможно получить доступ средствами Git, хотя на диске он продолжает присутствовать.
Теперь давайте обсудим «Золотое правило».
Золотое правило rebase
Золотое правило rebase звучит так — «НИКОГДА не выполняйте rebase расшаренной ветки!». Под расшаренной веткой понимается ветка, которая существует в сетевом репозитории и с которой могут работать другие люди, кроме вас.
Часто это правило применяют без должного понимания, поэтому разберем, почему оно появилось, тем более что это поможет лучше понять работу Git.
Давайте рассмотрим ситуацию, когда разработчик нарушает золотое правило, и что происходит в этом случае.
Предположим, Боб и Анна вместе работают над проектом. Ниже представлено, как выглядят репозитории Боба и Анны и исходный репозиторий на GitHub:
У всех пользователей репозитории синхронизируются с GitHub.
Теперь Боб, нарушая золотое правило, выполняет rebase, и в это же время Анна, работая в ветке feature, создает новый коммит:
Вы видите, что произойдет?
Боб пытается выполнить пуш коммита, ему приходит отказ примерно такого содержания:
Выполнение Git не было успешным, потому что Git не знает, как объединить feature ветку Боба с feature веткой GitHub.
Единственным решением, позволяющим Бобу выполнить push, станет использование ключа force, который говорит GitHub-репозиторию удалить у себя ветку feature и принять за эту ветку ту, которая пушится Бобом. После этого мы получим следующую ситуацию:
Теперь Анна хочет запушить свои изменения, и вот что будет:
Это нормально, Git сказал Анне, что у нее нет синхронизированной версии ветки feature, то есть ее версия ветки и версия ветки в GitHub — разные. Анна должна выполнить pull. Точно таким же образом, как Git сливает локальную ветку с веткой в репозитории, когда вы выполняете push, Git пытается слить ветку в репозитории с локальной веткой, когда вы выполняете pull.
Перед выполнением pull коммиты в локальной и GitHub-ветках выглядят так:
A--B--C--D' origin/feature // GitHub
A--B--D--E feature // AnnaКогда вы выполняете pull, Git выполняет слияние для устранения разности репозиториев. И вот, к чему это приводит:
Коммит M — это коммит слияния (merge commit). Наконец, ветки feature Анны и GitHub полностью объединены. Анна вздохнула с облегчением, все конфликты устранены, она может выполнить push.
Боб выполняет pull, теперь все синхронизированы:
Глядя на получившийся беспорядок, вы должны были убедиться в важности золотого правила. Также учтите, что подобный беспорядок был создан всего одним разработчиком и на ветке, которая расшарена всего между двумя людьми. Представьте, что будет в команде из десяти человек.
Одним из многочисленных достоинств Git является то, что можно без проблем откатиться на любое время назад. Но чем больше допущено ошибок, подобных описанной, тем сложнее это сделать.
Также учтите, что появляются дубликаты коммитов в сетевом репозитории. В нашем случае — D и D’, содержащие одни и те же данные. По сути, количество дублированных коммитов может быть таким же большим, как и количество коммитов в вашей rebased ветке.
Если вы все еще не убеждены, давайте представим Эмму — третью разработчицу. Она работает в ветке feature перед тем, как Боб совершает свою ошибку, и в настоящий момент хочет выполнить push. Предположим, что к моменту ее push наш маленький предыдущий сценарий уже завершился. Вот что выйдет:
Ох уж этот Боб!!!!
Этот текст мог заставить вас подумать, что rebase используют только для перемещения одной ветки на верхушку другой ветки. Это необязательно — вы можете выполнять rebase и на одной ветке.
Красота pull rebase
Как вы видели выше, проблем Анны можно было избежать, если бы она использовала pull rebase. Рассмотрим этот вопрос подробнее.
Допустим, Боб работает в ветке, отходящей от мастера, тогда его история может выглядеть вот так:
Боб решает, что настало время выполнить pull, что, как вы уже поняли, приведет к некоторым неясностям. Поскольку репозиторий Боба отходил от GitHub, Git спросит делать ли объединение, и результат будет таким:
Это решение подходит и работает нормально, однако, вам может быть полезно знать, что есть другие варианты решения проблемы. Одним из них является pull-rebase.
Когда вы делаете pull-rebase, Git пытается выяснить, какие коммиты есть только в вашей ветке, а какие — в сетевом репозитории. Затем Git объединяет коммиты из сетевого репозитория с самым свежим коммитом, присутствующим и в локальном, и в сетевом репозитории. После чего выполняет rebase ваших локальных коммитов в конец ветки.
Звучит сложно, поэтому проиллюстрируем:
- Git обращает внимание только на коммиты, которые есть и в вашем, и в сетевом репозитории:

Это выглядит как локальный клон репозитория GitHub. - Git выполняет rebase локальных коммитов:
Как вы помните, при rebase Git применяет коммиты один за одним, то есть в данном случаем применяет в конец ветки master коммит E, потом F. Получился rebase сам в себя. Выглядит неплохо, но возникает вопрос — зачем так делать?
По моему мнению, самая большая проблема с объединением веток в том, что загрязняется история коммитов. Поэтому pull-rebase — более элегантное решение. Я бы даже пошел дальше и сказал, что когда нужно скачать последние изменения в вашу ветку, вы всегда должны использовать pull-rebase. Но нужно помнить: поскольку rebase применяет все коммиты по очереди, то когда вы делаете rebase 20 коммитов, вам, возможно, придется решать один за другим 20 конфликтов.
Как правило, можно использовать следующий подход: одно большое изменение, сделанное давно — merge, два маленьких изменения, сделанных недавно — pull-rebase.
Сила rebase onto
Предположим, история ваших коммитов выглядит так:
Итак, вы хотите выполнить rebase ветки feature 2 в ветку master. Если вы выполните обычный rebase в ветку master, получите это:
Нелогично выглядит то, что коммит D существует в обоих ветках: в feature 1 и feature 2. Если вы переместите ветку feature 1 в конец ветки мастер, получится, что коммит D будет применен два раза.
Предположим, что вам нужно получить другой результат:
Для реализации подобного сценария как раз и предназначен git rebase onto.
Сначала прочтем документацию:
SYNOPSIS
git rebase [-i | --interactive] [<options>] [--exec <cmd>]
[--onto <newbase> | --keep-base] [<upstream> [<branch>]]
git rebase [-i | --interactive] [<options>] [--exec <cmd>]
[--onto <newbase>]
--root [<branch>]
git rebase (--continue | --skip | --abort | --quit | --edit-todo
| --show-current-patch)
Нас интересует вот это:
OPTIONS
--onto <newbase>
Starting point at which to create the new commits. If the
--onto option is not specified, the starting point is <upstream>. May be
any valid commit, and not just an existing branch name.
С помощью этой опции указывается, в какой точке создавать новые коммиты.
Если эта опция не указана, то стартовой точкой станет upstream.
Для понимания приведу еще один рисунок:
A--B--C master
\
D--E feature1
\
F--G feature2
Here we want to rebase feature2 to master beginning from feature1
| |
newbase upstream
То есть ветка master — это newbase, а ветка feature 1 — upstream.
Таким образом, если вы хотите получить результат как на последнем рисунке, необходимо выполнить в ветке feature2 git rebase --onto master feature1.
Удачи!
Переведено при поддержке Mail.ru Cloud Solutions.
- Первая часть гайда про Git.
- Мой второй год в качестве независимого разработчика.
- Как технический долг убивает ваши проекты.




