
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Перед вами полноценный гайд по запуску приложений с высокой доступностью (HA) в Kubernetes. В его основу лёг мой многолетний опыт работы с этой системой, приправленный лучшими практиками из официальной документации OpenShift и Kubernetes.
Вступление
При выполнении приложений в Kubernetes можно быстро принять как должное прекрасную функциональность высокой доступности, которая реализована здесь по умолчанию. В случае падения одного узла, выполняющиеся на нём поды автоматически приписываются к другому доступному узлу, и разработчику ничего для этого специально делать не нужно.
Для многих приложений этого будет более чем достаточно, но только пока ваш проект не достигнет определённой степени сложности. Здесь в контексте может возникнуть соглашение об уровне оказания услуг (SLA), обязывающее вас обеспечить отказоустойчивость сервисов.
Это руководство написано на примере платформы OpenShift, но вполне будет применимо к большинству дистрибутивов Kubernetes.
В случаях, когда предоставленных примеров окажется недостаточно, обратитесь к документации, на которую в каждом разделе даётся ссылка.
Реплики
Первая рекомендация будет самой простой: запускать несколько копий (реплик) приложения.
Если ваше приложение это поддерживает, то вам нужно обеспечить одновременную работу не менее двух его реплик. Точное их число нужно выбирать на основе количества доступных узлов. К примеру, масштабировать систему до 100 реплик, имея лишь один доступный узел, будет бессмысленным.
В
Deployment это можно настроить в поле .spec.replicas:apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginxinc/nginx-unprivileged:1.20
ports:
- containerPort: 8080Теперь Kubernetes обеспечит, чтобы у нас всегда было запущено 3 реплики пода
nginx, хотя при этом их доступность он учитывать не будет. В следующем разделе мы рассмотрим, как это можно решить.Ссылки
- kubernetes.io/docs/concepts/workloads/controllers/deployment/#replicas
Бюджет отказов подов
PodDisruptionBudget (pdb) защищает ваши поды от необходимых перебоев в работе, которые могут происходить в случае отключения узлов для обслуживания или во время апгрейдов.Как и предполагает имя, для этого создаётся так называемый «бюджет отказов». По сути, вы сообщаете Kubernetes, утрата какого количества подов окажется для вас допустима.
Создать
pdb можно так:apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: nginxЭтот
pdb обеспечит, чтобы всегда было доступно 2 пода, соответствующих метке app=nginx.В нашем примере это будет касаться следующих подов:
$ oc get pods -l app=nginx -o wide
NAME READY STATUS
nginx-deployment-94795dbf6-thjws 1/1 Running
nginx-deployment-94795dbf6-xhvn6 1/1 Running
nginx-deployment-94795dbf6-z2xt9 1/1 RunningЕсли два из этих подов окажутся назначены одному узлу, который уйдёт на обслуживание, то планировщик Kubernetes обеспечит, чтобы после исключения одного из подов, другой оставался в строю, пока первый не вернётся в работу. Таким образом, всегда будут доступны 2 пода.
Проверка состояния
pdb:$ oc get pdb
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
pdb 2 N/A 1 31m
$ oc describe pdb pdb
Name: pdb
Namespace: pdb-testing
Min available: 2
Selector: app=nginx
Status:
Allowed disruptions: 1
Current: 3
Desired: 2
Total: 3Доступность указывается с помощью
.spec.minAvailable или .spec.maxUnavailable.Для
.spec.maxUnavailable значение можно указать целым числом или в процентах, а для .spec.minAvailable только целым числом.Pdb работает со следующими ресурсами:DeploymentReplicationControllerReplicaSetStatefulSet
Примечание: если вы установите
minAvailable: 100%, это будет означать то же, что maxUnavailable: 0%. На практике так делать нельзя, поскольку это приведёт к невозможности планировщика исключать поды, усложнив жизнь вашему администратору.Иными словами:
disruptionsAllowed не может быть 0. Произойдёт это, к примеру, если установить minAvailable на 2 при выполнении всего двух реплик приложения.Задача
pdb сообщать планировщику, что определённое число подов можно вывести из строя, не навредив существенным образом приложению. Это своеобразный компромисс между разработчиком и администратором.Ссылки
- https://kubernetes.io/docs/tasks/run-application/configure-pdb
- https://innablr.com.au/blog/what-is-pod-disruption-budget-in-k8s-and-why-to-use-it
- https://cloud.google.com/blog/products/management-tools/sre-error-budgets-and-maintenance-windows
- https://sre.google/workbook/alerting-on-slos/#low-traffic-services-and-error-budget-alerting
Anti-affinity подов
По умолчанию Kubernetes будет стараться распределить поды по узлам на основе использования ресурсов. Это можно настроить с помощью профиля планирования, но здесь мы об этом говорить не будем.
Устанавливая требование сближенности (affinity) подов, вы обеспечиваете выполнение определённых подов в одном узле (узлах).
Здесь можно использовать два варианта:
requiredDuringSchedulingIgnoredDuringExecution: означает обязательную близость, то есть в случае невозможности выполнить это требование поды разным узлам назначаться не будут.preferredDuringSchedulingIgnoredDuringExecution: означает желательную близость, то есть планировщик постарается соблюсти требование, и если ему это не удастся, распределит поды по разным узлам.
Использовать можно как один, так и оба варианта. Вот пример из документации Kubernetes, в котором для пода установлен параметр близости:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0Хотя нам по факту нужно обеспечить разброс подов по разным узлам с целью повышения их доступности, не полагаясь при этом на предустановленное поведение планировщика. Для этого мы настроим требование раздельности (anti-affinity).
Раздельность определяется в спецификации
Pod:apiVersion: v1
kind: Pod
metadata:
name: with-pod-antiaffinity
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostnameПоскольку поды редко развёртываются по-отдельности, этот фрагмент мы добавим в
Deployment из предыдущего раздела:apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginxinc/nginx-unprivileged:1.20
ports:
- containerPort: 8080
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostnameТеперь посмотрим, как всё это будет выглядеть на практике. В данной среде нам доступно 3 узла:
$ kubectl get node
NAME STATUS ROLES AGE VERSION
node-1 Ready worker 15d v1.23.3+e419edf
node-2 Ready worker 15d v1.23.3+e419edf
node-3 Ready worker 15d v1.23.3+e419edfТак как в конфигурации раздельности подов мы используем
topologyKey=kubernetes.io/hostname, можно ожидать, что они будут распределены так:$ kubectl get node -l kubernetes.io/hostname=node-1
NAME STATUS ROLES AGE VERSION
node-1 Ready worker 15d v1.23.3+e419edf
$ kubectl get node -l kubernetes.io/hostname=node-2
NAME STATUS ROLES AGE VERSION
node-2 Ready worker 15d v1.23.3+e419edf
$ kubectl get node -l kubernetes.io/hostname=node-3
NAME STATUS ROLES AGE VERSION
node-3 Ready worker 15d v1.23.3+e419edfПроверяя поды после развёртывания, мы в этом убеждаемся:
$ kubectl get pods -o wide
NAME READY NODE
nginx-deployment-7dffdbff88-2z5vb 1/1 node-1
nginx-deployment-7dffdbff88-64fwd 1/1 node-2
nginx-deployment-7dffdbff88-7zr7z 1/1 node-3
Даже после удваивания количества реплик поды распределяются поровну:
$ kubectl scale --replicas=6 deployment/nginx-deployment
deployment.apps/nginx-deployment scaled
$ kubectl get pods -o wide
NAME READY STATUS NODE
nginx-deployment-7dffdbff88-2z5vb 1/1 Running node-1
nginx-deployment-7dffdbff88-64fwd 1/1 Running node-2
nginx-deployment-7dffdbff88-7zr7z 1/1 Running node-3
nginx-deployment-7dffdbff88-j8x2r 0/1 ContainerCreating node-1
nginx-deployment-7dffdbff88-8jxw7 0/1 ContainerCreating node-2
nginx-deployment-7dffdbff88-vd8dn 0/1 ContainerCreating node-3Если ваши узлы отмечены доступной зоной/датацентром, можете также использовать это для распределения подов. Для этого обычно используется строка
topology.kubernetes.io/zone.Ссылки
- kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node
- kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#inter-pod-affinity-and-anti-affinity
- docs.openshift.com/container-platform/4.10/nodes/scheduling/nodes-scheduler-pod-affinity.html
- docs.openshift.com/container-platform/4.10/nodes/scheduling/nodes-scheduler-profiles.html
- kubernetes.io/docs/reference/scheduling/config
Топология узлов
Узлы должны быть распределены по нескольким датацентрам (или зонам), чтобы исключить возможный даунтайм в случае инфраструктурного сбоя в одном из этих центров.
Отражается топология внутри Kubernetes с помощью ранее упомянутой строки
topology.kubernetes.io/zone.Технический анализ
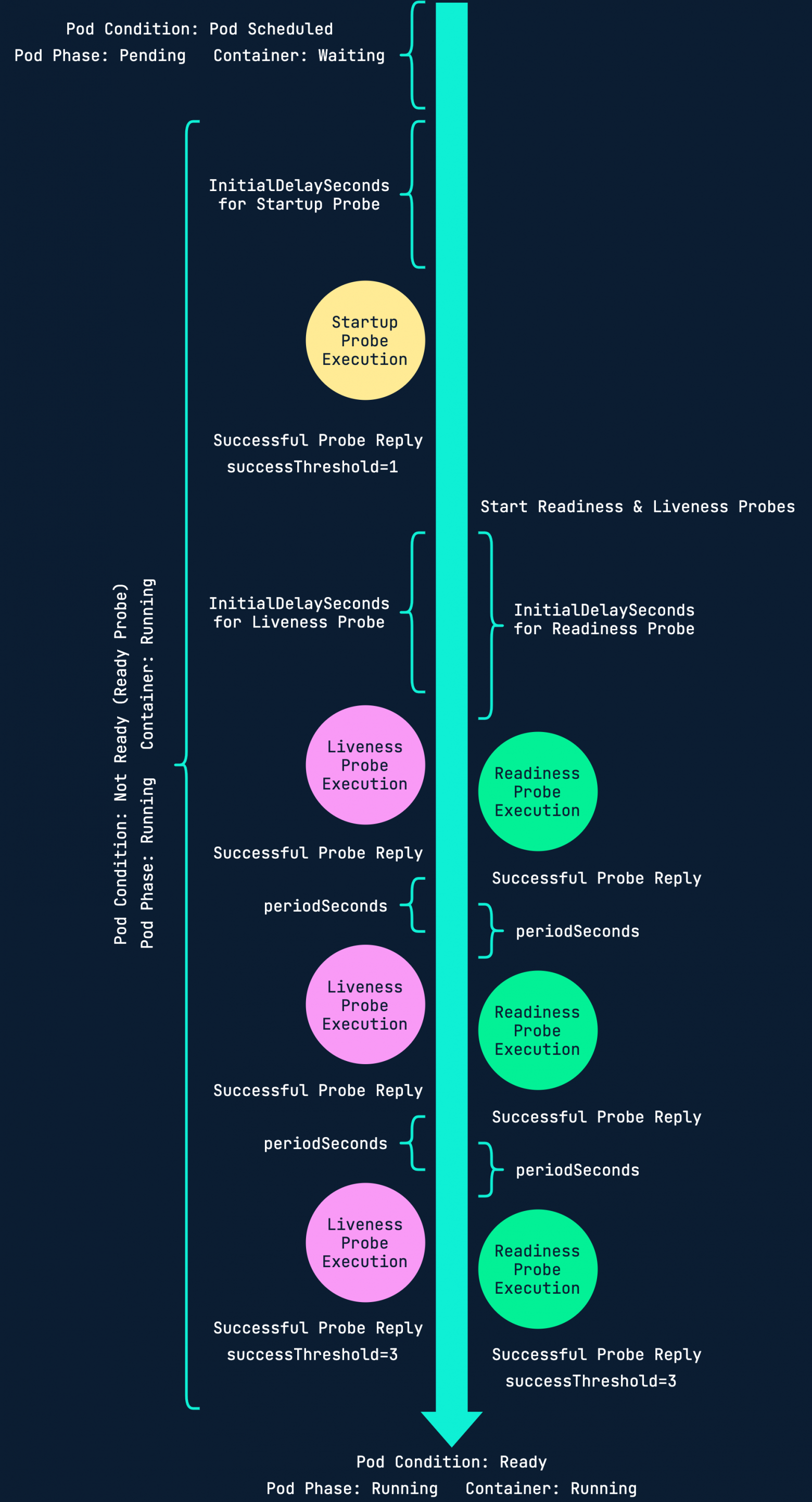
Технический анализ позволяет Kubernetes понять состояние вашего приложения. Без него система узнает о сбое приложения, только если оно выбросит ошибку с кодом 1.
Всего существует три вида проверки: запуска (startup), готовности (readiness) и жизнеспособности (liveness).
В зависимости от приложения вам может потребоваться использовать все проверки, некоторые из них, или вообще ни одну. Здесь уже решать вам.
- Проверка запуска. Выполняется только при запуске.
- Проверка готовности. Выполняется в течение всей жизни пода. Предположим, у вас есть три реплики, и одной из них требуется перезапуск. Без проверки готовности сервис, расположенный перед этими подами, может отправить траффик на перезапущенный под до того, как содержащееся в нём приложение окажется готово к приёму этого траффика.
- Проверка жизнеспособности. Также выполняется в течение всей жизни пода. С помощью проверок живучести kubelet определяет, когда контейнер нужно перезапустить. Например, такая проверка может перехватить взаимную блокировку, когда приложение выполняется, но прогресса не происходит. В подобном состоянии перезапуск контейнера помогает повысить доступность приложения в случае возникновения ошибок.
Вот полезная схема, наглядно демонстрирующая эти три вида проверки:
Эти проверки дополнительно можно настроить на использование различных тестов:
- HTTP GET. Проверка состояния пода на основе ответа от конечной точки HTTP в контейнере (например,
/health). - Выполнение команды в контейнере. Выполнить команду оболочки внутри контейнера для выяснения его состояния.
- TCP-сокет. Проверить статус контейнера, попытавшись открыть в нём TCP-порт.
Ссылки
- docs.openshift.com/container-platform/4.10/applications/application-health.html
- kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes
- kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle
- loft.sh/blog/kubernetes-probes-startup-liveness-readiness
Восстановление после сбоя
Возможность быстрого восстановления после инцидента является ключевой.
Обычно в случае инфраструктурного сбоя Kubernetes производит автоматическое восстановление сразу после исправления проблемы.
Однако в редких случаях, когда нужно пересоздавать кластер или выполнять с него перенос, есть несколько решений, который позволят сэкономить время.
GitOps
Один из лучших способов быстрого восстановления в Kubernetes – это использование GitOps/Infrastructure-as-Code.
При определении ресурсов и даже всего кластера в Git (будь то с помощью Helm, Kustomize или просто файлов YAML) у вас всегда будет модель размещения вашего приложения на случай необходимости развернуть его где-либо.
В качестве хороших примеров открытых проектов для реализации GitOps-стратегии в Kubernetes могу порекомендовать Argo CD и Flux.
- https://argo-cd.readthedocs.io
- https://fluxcd.io
- https://gitops.tech
Резервное копирование
Если все ваши ресурсы будут располагаться в Git, это уже можно будет рассматривать как своего рода бэкап.
Если же ваша база данных работает в Kubernetes, то одного только этого будет недостаточно, и если вы цените свои данные, то вам нужно будет обеспечить создание резервных копий. То же касается случаев, когда у вас есть важные данные в постоянных томах.
Это можно сделать разными способами, вот один из вариантов:
- Запустить задачу CronJob, которая создаст дамп базы данных.
- Загрузить этот дамп на сервер NFS/CIFS или в Object Storage.
Также можете использовать инструменты вроде Velero, чтобы сделать бэкап всех ресурсов кластера Kubernetes, включая тома.
Ссылки
- https://velero.io
Ресурсы и планирование
В системах с повышенной доступностью очень важно не перегружать узлы, на которых выполняются поды. Если не предпринять превентивных мер, то, к примеру, утечка памяти в одном из ваших приложений может обрушить всю продакшн-среду.
Далее мы разберём, как работает запрос ресурсов и планирование, и как можно зарезервировать ЦПУ и память для рабочих нагрузок.
В документации планирование описывается так:
В Kubernetes планирование – это обеспечение сопоставления подов с узлами, чтобы Kubelet мог их выполнять.
Планировщик следит за создаваемыми подами, которые ещё не к узлам не присвоены. Его задача в том, чтобы для каждого такого пода найти наиболее подходящий узел.
Поскольку планировщик не может узнать, сколько ресурсов ваше приложение собирается использовать, пока он его не разместит, вам нужно предоставить эту информацию заранее. Если этого не сделать, ничто не помешает поду использовать все доступные ресурсы узла.
В отношении ЦПУ и памяти необходимо предоставлять два элемента информации:
- Запрос ресурсов. Минимальный объём, который нужно зарезервировать для пода. Этот объём нужно устанавливать согласно потреблению ресурсов приложением под стандартной нагрузкой.
- Лимит ресурсов. Максимальный объём, который под может использовать. При достижении этого лимита — он будет завершён.
Память указывается в байтах. Можно использовать целые числа или один из их суффиксов: E, P, T, G, M, k. Согласно документации, также можно применять эквивалент суффиксов степени числа два: Ei, Pi, Ti, Gi, Mi, Ki.
При выборе суффиксов нужно быть внимательным, на что указывается в документации:
Если запросить 400m памяти, то это будет означать 0.4 байта. Однако вводящий этот запрос человек, вероятно, имеет ввиду 400 мебибайт (400Mi) или 400 мегабайт (400M).
Ресурсы ЦПУ определяются в ядрах, которые можно указать так:
1.0, 0.5, 100m. Суффикс m означает миллиядро (или миллицпу), то есть одну тысячную ядра.Ещё раз процитирую документацию:
В Kubernetes 1 единица ЦПУ эквивалентна 1 физическому ядру ЦПУ, или 1 виртуальному ядру, что зависит от того, является ли узел физическим хостом или же виртуальной машиной, запущенной на физической.
На узле с 4 ЦПУ у нас есть 4 ядра, или 4000 миллиядер.
В спецификации
Pod запросы и лимиты устанавливаются в поле .spec.containers[].resources:apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"Взглянем поближе:
requests:
memory: "64Mi"
cpu: "250m"Это запрос к планировщику зарезервировать для пода
frontend не менее 64 мебибайт памяти и 250 миллиядер.LimitRange
Если вы хотите избежать установки запросов и лимитов для каждого развёртывания по-отдельности, создайте
LimitRange для всего пространства имён.Так вы добавите лимиты и/или запросы ко всем подам этого пространства, их не имеющим.
Вот простой пример
LimitRange:apiVersion: v1
kind: LimitRange
metadata:
name: limit-range
spec:
limits:
- defaultRequest: # Предустановленный REQUEST
memory: 256Mi
cpu: 250m
default: # Предустановленный LIMIT
memory: 512Mi
cpu: 500m
type: ContainerПроясню используемое здесь именование:
.spec.limits.defaultRequestустанавливает запрос ресурсов по умолчанию;.spec.limits.defaultустанавливает предустановленный лимит ресурсов.
Ссылки
- https://kubernetes.io/docs/concepts/configuration/manage-resources-containers
- https://kubernetes.io/docs/tasks/administer-cluster/manage-resources/memory-default-namespace
- https://kubernetes.io/docs/concepts/scheduling-eviction/kube-scheduler
- https://physics.nist.gov/cuu/Units/binary.html
Канареечные обновления
Примечание: применимо только к OpenShift.
Для узлов с чрезвычайными потребностями в высокой доступности (>=99.9% SLA) можно рассмотреть вариант их настройки на канареечные обновления.
Это позволит администратору производить обновления для определённого набора узлов в рамках установленного окна обслуживания. Это также даст возможность извлекать поды из узлов для контролируемого обновления.
Ссылки
- https://docs.openshift.com/container-platform/4.10/updating/update-using-custom-machine-config-pools.html
Дальнейшие шаги
Если вы хотите пойти дальше в плане повышения доступности системы, то это наверняка будет подразумевать некое гибридное облачное решение, когда несколько кластеров Kubernetes выполняются в разных облаках, возможно, даже соединённые с помощью сервисной сетки.




