Существует большое разнообразие методов сегментарного анализа в маркетинге. Во-первых, сегментация — это стратегия, используемая для концентрации ресурсов на целевом рынке/объекте и оптимизации их использования. Во-вторых, сегментация — это алгоритм анализа рынка для лучшего учёта его особенностей.
Эффективно проведённая сегментация упрощает и удешевляет маркетинговую политику, позволяет отказаться от многих затратных методов продвижения. Объяснение очень простое - покупатель приходит к продавцу не за рекламой и скидками, а за удовлетворением своих потребностей. Поэтому продавцы, предлагающие товары или услуги, лучше удовлетворяющие потребности покупателей (по свойствам, качеству, цене и т. д.), могут добиться большего эффекта, а также свести к минимуму затраты на рекламу и скидки.
Рассмотрим частотно-монетарный метод сегментации применительно к e-commerce сфере. Частотно-монетарный анализ (RFM анализ) - анализ, в основе которого лежат поведенческие факторы групп или сегментов клиентов, позволяющий сегментировать клиентов по частоте и сумме покупок и выявлять тех, которые приносят больше денег. Данный метод позволяет получить ценные инсайты по построению маркетинговых стратегий в компании. Также RFM-сегментация помогает применять особый комуникативный подход к каждой группе клиентов.
RFM-анализ частично перекликается с принципом Парето, полагающим, что 80% результатов происходят благодаря 20% усилий. Если данный принцип рассматривать в общем ключе маркетинга - 80% всех ваших продаж исходят от 20% наиболее лояльных и постоянных клиентов. Постоянные клиенты всегда буду иметь высокое влияние на выручку, а значит – возвращаемость этих клиентов крайне важна для показателей дохода.
Аббревиатура RFM расшифровывается:
Recency — давность (как давно клиенты приобретали товар или услуги). Высокий показатель давности означает, что у клиентов уже сложилось достаточно хорошее впечатление о вашем бренде, поэтому они недавно совершили покупку. Давность в срезе клиентской базы можно посмотреть, если отсортировать клиентов по дате последней покупки.
Frequency — частота (как часто клиенты у вас покупают). Высокий показатель частоты говорит о том, что клиентам нравится ваш бренд, товары или услуги, поэтому он часто к вам возвращается. Для расчета частоты посещения нужно общее кол-во покупок/визитов разделить на кол-во дней/месяцев/годов и т.д.
Monetary — деньги (общая сумма трат). Высокий уровень этого показателя означает, что клиентам нравится тратить именно у вас.
Для наиболее точного RFM-анализа, каждый из этих показателей необходимо условно разделить на N сегментов (чаще всего рекомендуется разбивать на 5 групп) – от наименьшего к наибольшему. В рамках этой статьи можно ограничиться 3 ступенями в каждом из показателей.
По этим признакам можно разделить всех клиентов на группы, понять, кто покупает у вас часто и много, кто — часто, но мало, а кто вообще давно ничего не покупал.
Данный метод помогает разделить ваших клиентов на группы разных размеров, чтобы вам было легче понять, кто из них лучше всего реагирует на текущие рекламные кампании и на будущие активности.
Как правило, небольшой процент пользователей реагирует на общие рекламные предложения (холодные рассылки по всей клиентской базе). RFM анализ используется для исследования поведения покупателей, чтобы определить, как работать с каждой группой клиентов.
Критерии сегментации клиентов
Чтобы провести RFM-анализ, необходимо собрать данные обо всех покупках, совершённых всеми клиентами и суммы всех этих покупок, и распределить клиентов на сегменты с учётом времени с момента последнего приобретения (Recency), частоты покупок (Frequency) и суммы потраченных средств (Monetary). Каждому из клиентов ставится по три оценки, соответствующие каждому из этих параметров. Например, по трёхбалльной системе (где 1 — хорошо, 2 — нормально и 3 — плохо).
В итоге должно получится 27 сегментов с числовыми значениями распределёнными определённым образом в интервале от 111 до 333 включительно, где первая цифра - показатель “давности”/”свежести” покупок (1 - покупал на днях, 2 - покупал относительно недавно, 3 - покупал довольно давно), вторая - показатель “частоты” (1 - покупал часто, 2 - покупал не часто, 3 - покупал редко), а третья - показатель “монетарности”/”доходности” (1 - принёс очень много денег[попадает под правило Парето], 2 - принес много денег, 3 - принёс мало денег). Для удобства и упрощения восприятия некоторые сегменты можно объединять в группы:
Значение | Определение сегмента | Определение группы |
|---|---|---|
111 | Недавно покупавшие частые с высоким чеком | VIP |
112 | Недавно покупавшие частые со средним чеком | Выгодные |
113 | Недавно покупавшие частые с низким чеком | Выгодные |
121 | Недавно покупавшие редкие с высоким чеком | Потенциально выгодные |
122 | Недавно покупавшие редкие со средним чеком | Потенциально выгодные |
123 | Недавно покупавшие редкие с низким чеком | Новенькие |
131 | Недавно покупавшие разовые с высоким чеком |
|
132 | Недавно покупавшие разовые со средним чеком | Новенькие |
133 | Недавно покупавшие разовые с низким чеком | Новенькие |
211 | Спящие частые с высоким чеком | Спящие выгодные |
212 | Спящие частые со средним чеком | Спящие выгодные |
213 | Спящие частые с низким чеком | Спящие выгодные |
221 | Спящие редкие с высоким чеком | Спящие выгодные |
222 | Спящие редкие со средним чеком | Спящие выгодные |
223 | Спящие редкие с низким чеком | Спящие |
231 | Спящие разовые с высоким чеком | Спящие |
232 | Спящие разовые со средним чеком | Спящие |
233 | Спящие разовые с низким чеком | Спящие |
311 | Давние частые с высоким чеком | Уходящие выгодные |
312 | Давние частые со средним чеком | Уходящие выгодные |
313 | Давние частые с низким чеком | Уходящие |
321 | Давние редкие с высоким чеком | Уходящие |
322 | Давние редкие со средним чеком | Уходящие |
323 | Давние редкие с низким чеком | Потерянные |
331 | Давние разовые с высоким чеком | Потерянные |
332 | Давние разовые со средним чеком | Потерянные |
333 | Давние разовые с низким чеком | Потерянные |
Сегменты могут получиться неравномерными (в один сегмент могут попасть 90% всех клиентов, в другой — 1%). Поэтому слишком широкие группы целесообразно разбивать на несколько дополнительных, а узкие — объединять. Также можно выделять больше уровней сегментации. Однако это усложнит дальнейшую работу с сегментами, так как их получится еще больше. Если уровней будет N — получится N^3 сегментов.
Основная сложность — определить границы сегментов, потому что универсальных рекомендаций по этому поводу нет. Важно ориентироваться на нишу, жизненный цикл продукта и покупателя, и другие факторы. Диапазон для каждого показателя у разных компаний будет свой.
Иногда для построения сегментов достаточно учитывать только 2 параметра, а иногда приходится обогащать данные дополнительными сведениями для выведения новых критериев и групп сегментации.
Преимущества и недостатки RFM-анализа
Как и любой инструмент RFM-анализ имеет свои сильные и слабые стороны.
Преимущества:
Простота и сочетаемость с другими маркетинговыми инструментами.
Благодаря точному таргетированию аудитории позволяет снизить затраты на рекламные кампании и привлечение новых клиентов.
Низкие временные затраты на анализ.
Недостатки:
Высокая зависимость от объёма исходных данных, плохо работает на малом количестве клиентов.
Не подходит для компаний с разовыми продажами.
RFM-анализ средствами PowerBI
Предварительная обработка данных
В данной статье мы будем работать в программном обеспечении PowerBI. Рассмотрим данные о продажах е-commerce проекта "Рога и Копыта". Загрузим их в программу:
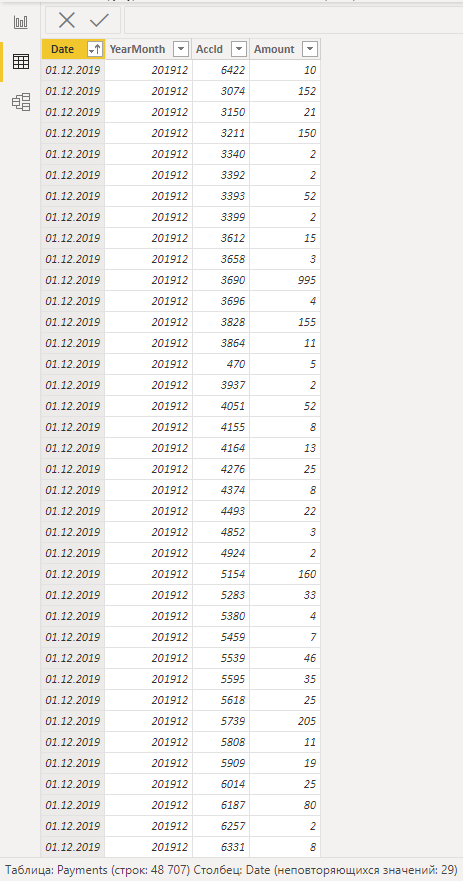
Данные представляют из себя агрегированные покупки клиентов по дням.
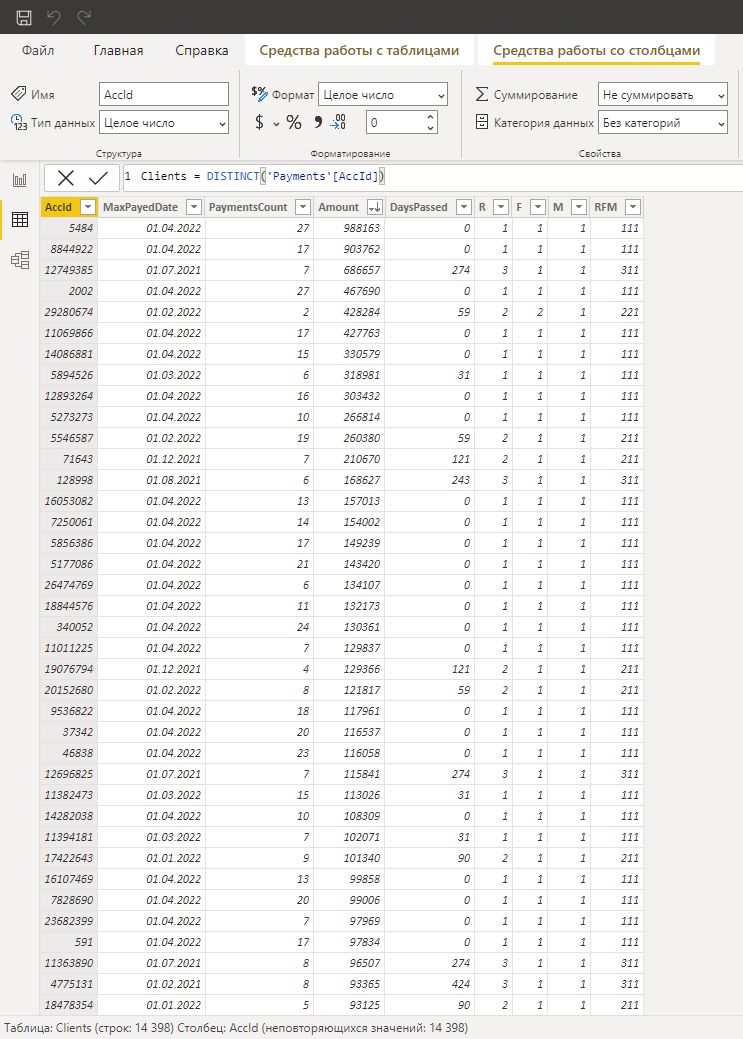
Для анализа клиентов создадим отдельную таблицу уникальных клиентов. Для этого необходимо перейти на вкладку “Средства работы с таблицами“ и использовать кнопку “Создать таблицу”. Далее в открывшейся строке запроса/формул ввести название будущей таблицы и необходимую формулу (Clients = DISTINCT('Payments'[AccId])), для формирования списка уникальных клиентов:
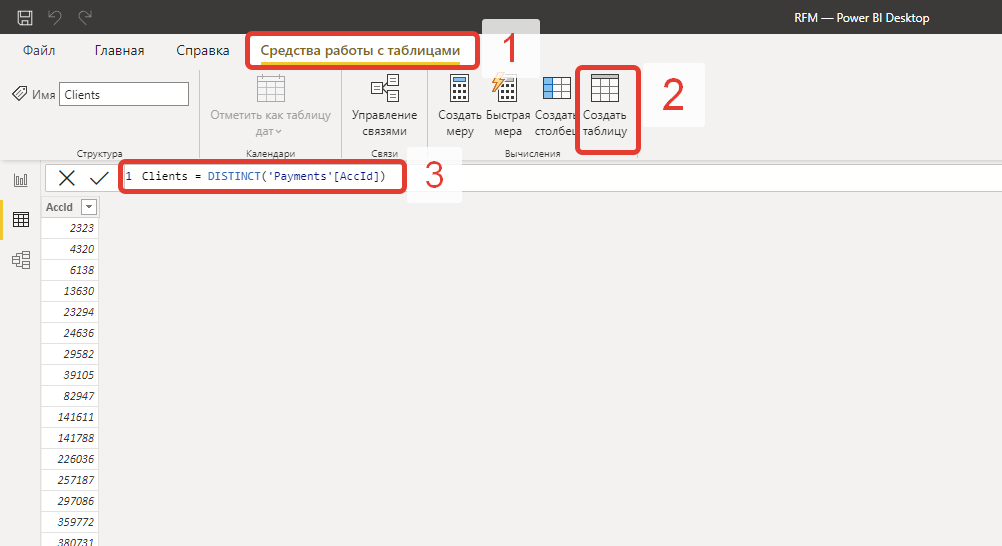
Таким образом будет получен список уникальных клиентов, когда-либо совершивших покупки в компании "Рога и Копыта". Далее необходимо обогатить данные датой последней покупки, суммарной выручкой и частотой покупок. Для этого необходимо создать 3 дополнительных столбца при помощи инструмента “создать столбец“.
Если решать задачу “в лоб” - программа вернёт последнюю дату из датасета.
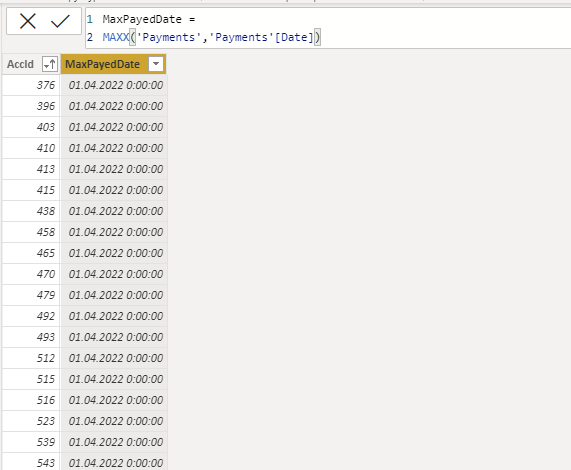
Прибегнем к неочевидному методу группировки. Опционально (не обязательно) можно создать связь “один ко многим“ в модели данных, для этого нужно перейти во вкладку “модель“, которая находится на левой панели инструментов, и перетянуть совпадающие поля таблиц:
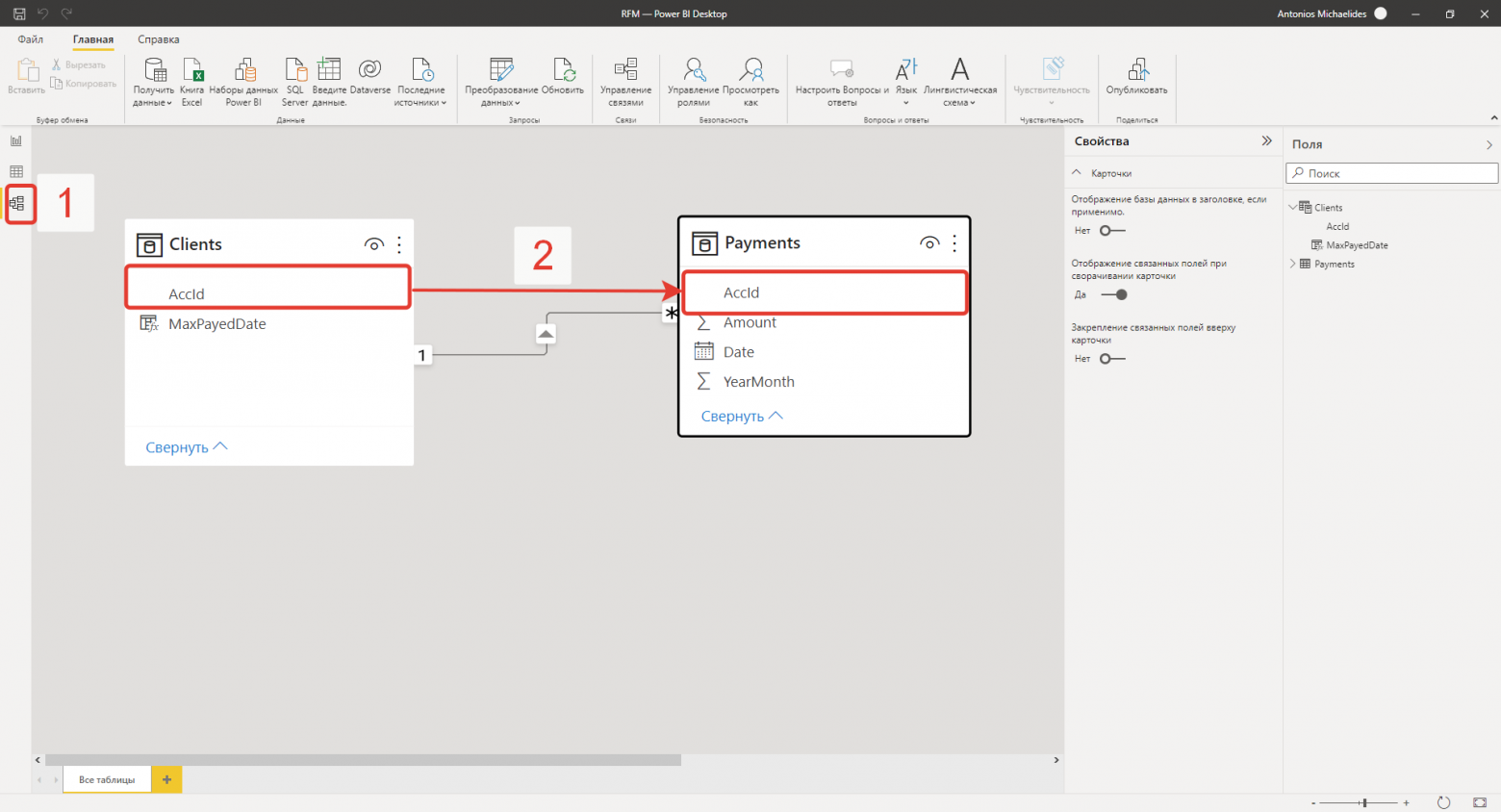
Далее необходимо вернуться на вкладку работы с данными и заменить формулу.
В итоге должно появиться 3 столбца с формулами:
Для даты последней покупки:
MaxPayedDate =
VAR Client = 'Clients'[AccId]
VAR RESULT =
MAXX(
FILTER(
'Payments',
'Payments'[AccId] = Client
),
'Payments'[date]
)
RETURN RESULTДля частоты покупок:
PaymentsCount =
VAR Client = 'Clients'[AccId]
VAR RESULT =
COUNTAX(
FILTER(
'Payments',
'Payments'[AccId] = Client
),
'Payments'[AccId]
)
RETURN RESULTДля суммарной выручки:
Amount =
VAR Client = 'Clients'[AccId]
VAR RESULT =
SUMX(
FILTER(
'Payments',
'Payments'[AccId] = Client
),
'Payments'[Amount]
)
RETURN RESULTТак же для расчёта “давности” покупки добавим столбец вычисляющий число прошедших дней с момента последней покупки клиента до самой свежей/максимальной даты в датасете.
DaysPassed = DATEDIFF('Clients'[MaxPayedDate], MAX('Payments'[Date]),DAY)Расчёт “давности“ до максимальной даты в датасете удобнее чем до текущей даты, так как данные могут устаревать, если отчёт обновляется, например, 1 раз в месяц или реже. На итоговый расчёт данная разница никак не повлияет.
Промежуточная таблица с данными для анализа будет выглядеть так:
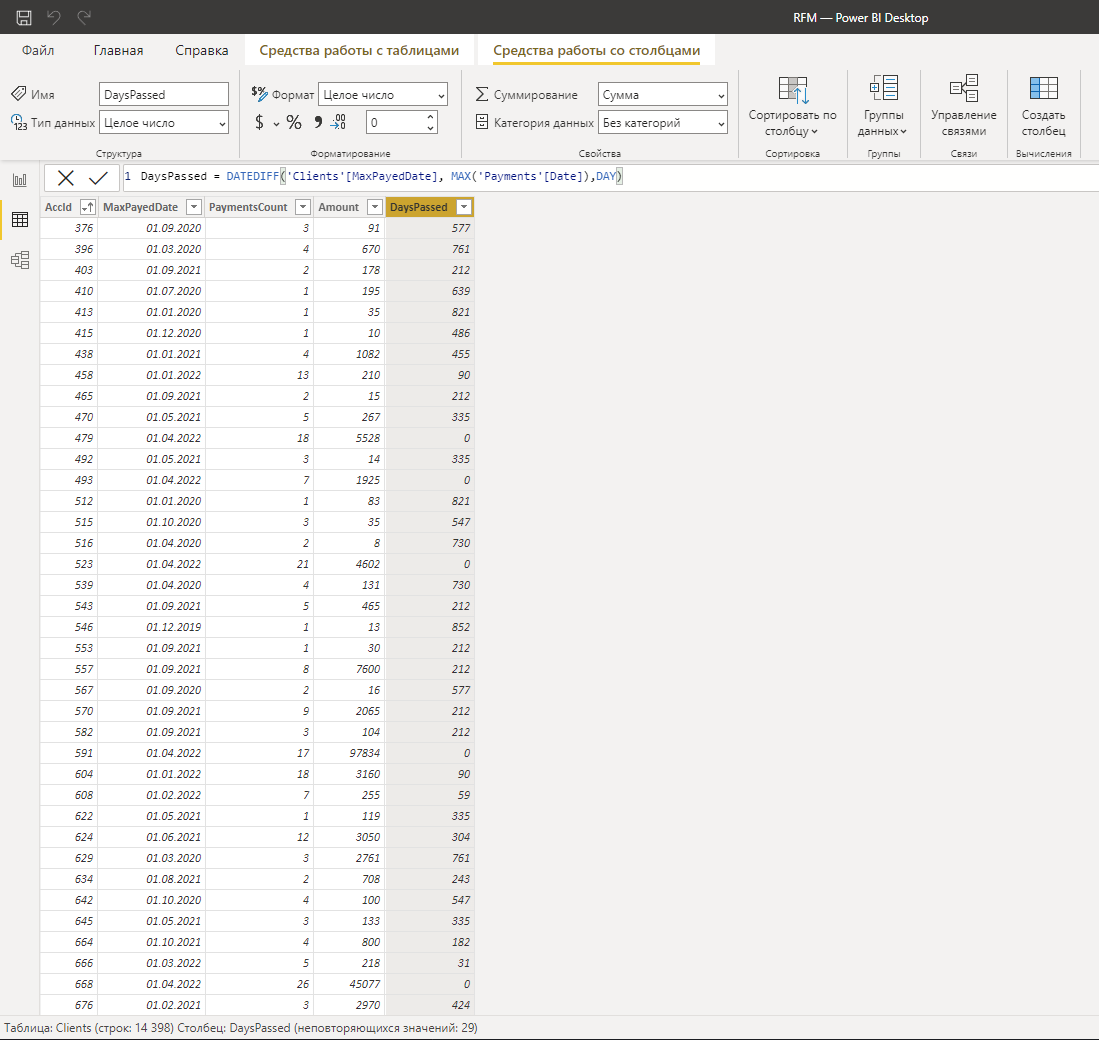
Так же есть ещё 2 метода получения подобной промежуточной таблицы: GROUPBY и SUMMARIZE.
Код для создания таблиц будет выглядеть примерно так:
Clients_GROUPBY =
GROUPBY(
'Payments',
'Payments'[AccId],
"MaxPayedDate", MAXX(CURRENTGROUP(), 'Payments'[Date]),
"PaymentsCount", COUNTAX(CURRENTGROUP(), 'Payments'[AccId]),
"Amount", SUMX(CURRENTGROUP(), 'Payments'[Amount])
)и
Clients_SUMMARIZE =
SUMMARIZE(
'Payments',
'Payments'[AccId],
"MaxPayedDate", MAX('Payments'[Date]),
"PaymentsCount", COUNT('Payments'[AccId]),
"Amount", SUM('Payments'[Amount]),
"DaysPassed", DATEDIFF(MAX('Payments'[Date]), CALCULATE(MAX('Payments'[Date]), ALL('Payments')),DAY)
)соответственно.
Как можно видеть - в вычислении через SUMMARIZE добавлен дополнительный столбец, вычисляющий количество дней прошедших с момента последней покупки. В вычислении через GROUPBY такой столбец не вычисляется, так как скалярные выражения должны быть статистическими функциями в в пределах выбранной группы.
Выбор, какой метод применить, остаётся за разработчиком. От себя могу добавить, что в рассматриваемом примере наилучшим образом себя показал метод с группировкой через GROUPBY.
Исследование поведения пользователей
Для определения правильных границ сегментации по каждому из критериев можно прибегнуть к средствам визуального анализа PowerBI. Для этого надо перейти на вкладку “отчёт“ на левой панели инструментов и создать гистограмму с накоплением. На ось Х нужно перетащить столбец “DaysPassed“ таблицы клиентов, на ось Y - столбец “DaysPassed“ таблицы клиентов. Изначально для оси Y будет рассчитана сумма значений “DaysPassed“ для каждого значения по оси X. Для определения плотности распределения (количества повторяющихся значений) требуется перейти в настройки агрегации оси Y (стрелочка вниз возле наименования оси) и выбрать пункт “количество“.
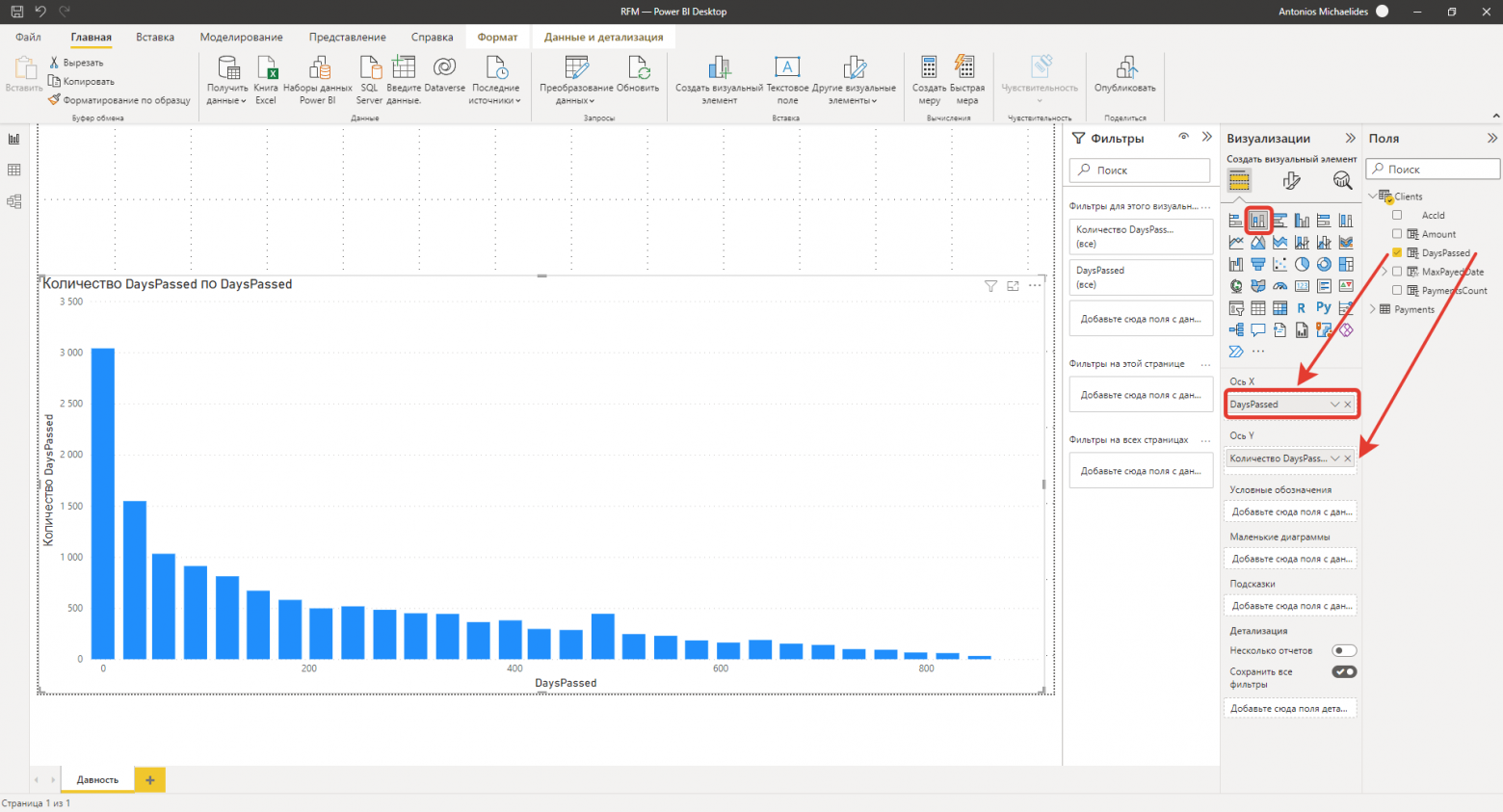
Данный визуальный элемент показывает какое количество клиентов (высота столбца) какое количество дней назад(ось Х) совершили последнюю покупку.
Чаще всего в активно развивающихся компаниях такая гистограмма плохо информативна. Что бы получить более полную картину распределения клиентов по давности покупки добавим на лист отчёта минимальное значение, максимальное значение, медианное значение и среднее арифметическое (наименее информативный показатель при распределении отличном от нормального или равномерного).
Для этого можно воспользоваться визуальным элементом “карточка“. Все карточки можно настроить так же как и ось Y гистограммы, не прибегая к созданию собственных вычислений/мер.
Итоговая страница отчёта будет выглядеть примерно вот так:

На данной странице отчёта дополнительно выведено общее число строк анализируемой таблицы.
Для оставшихся параметров доходности и частоты покупок необходимо создать ещё 2 страницы отчёта. Описывать подробно процесс создания нет необходимости, действия такие же как при создании страницы “Давность”.

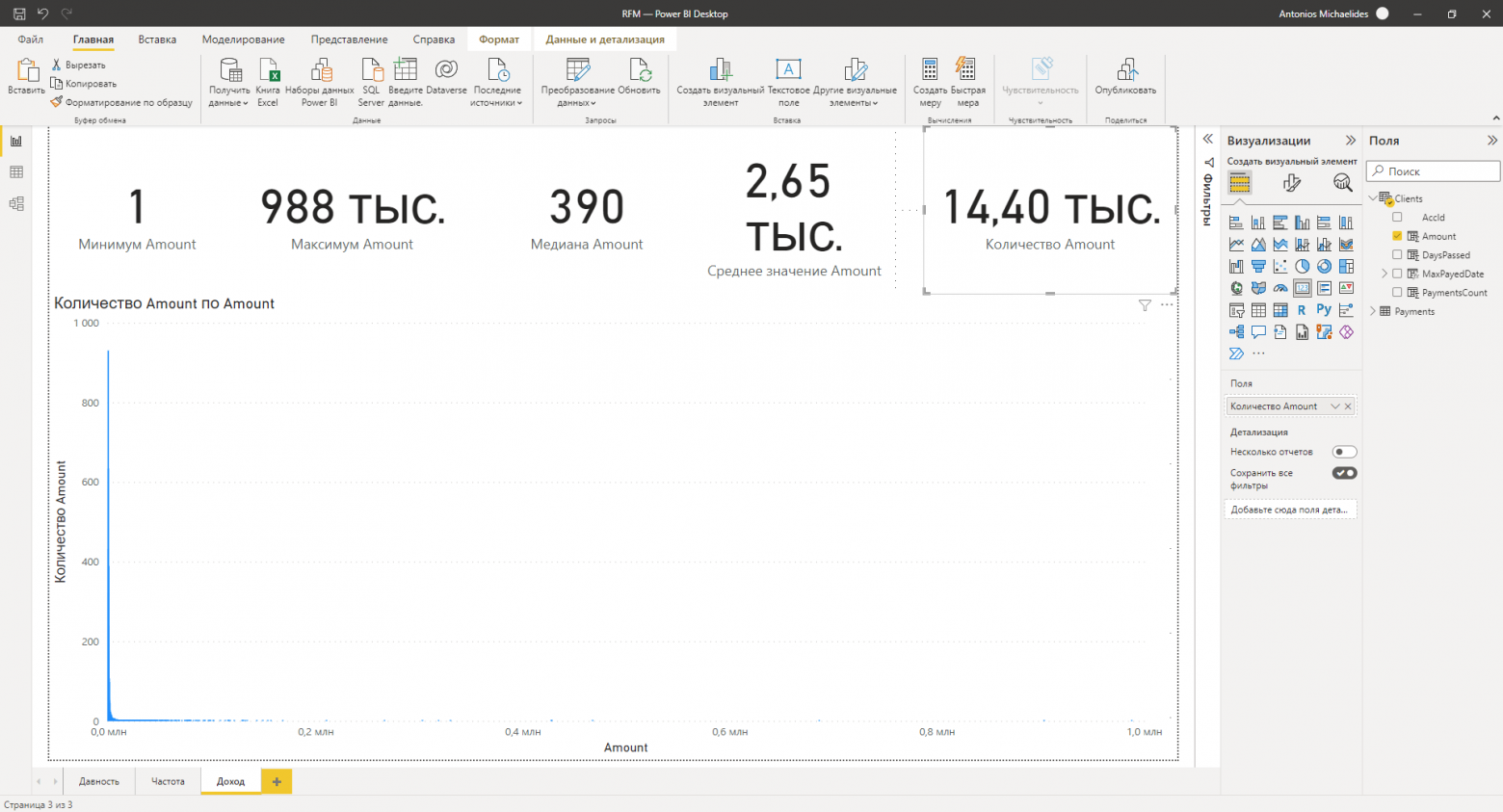
На странице отчёта “Доход“ отчётливо видно, что большинство клиентов сконцентрировано в самом начале гистограммы. Чтобы детальнее рассмотреть область максимальной плотности можно сменить тип оси X гистограммы на “категориальный“.
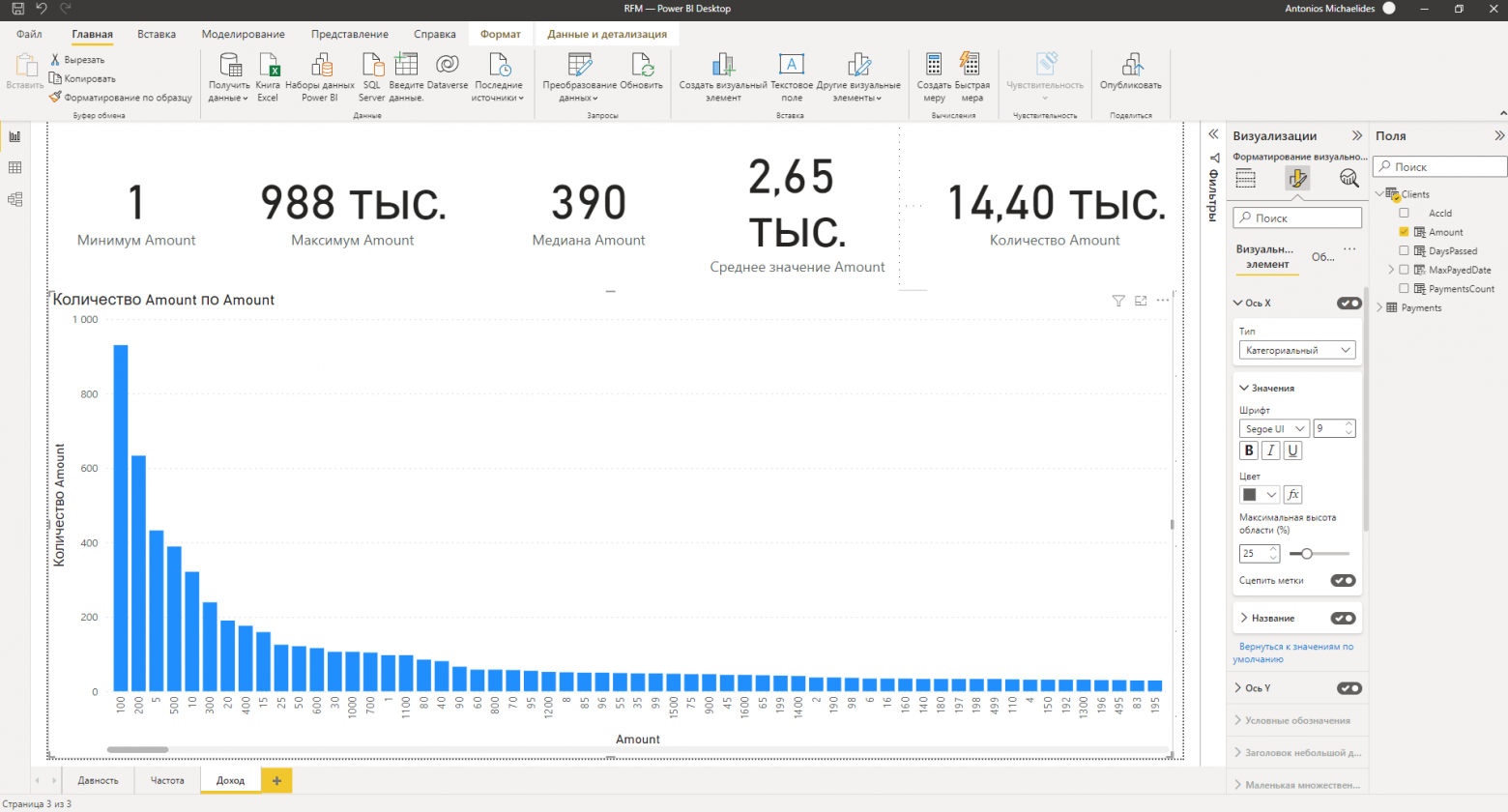
Если обратить внимание - значения по оси X расположены не по порядку. Это связано с сортировкой значений по оси Y по убыванию. Тем не менее такое распределение наиболее информативно описывает поведение клиентов.
Определение групп пользователей
После определения обобщённого поведения клиентов необходимо выбрать границы сегментов по каждому из параметров. Так как в данной статье рассматривается 3х сегментный подход можно обойтись медианным методом сегментации. Если проще - надо определить 25й, 50й и 75й процентиль и использовать в определении сегментов, для этого необходимо вернуться в режим работы с данными и создать в таблице клиентов “Clients“ 4 столбца - 3 столбца определения сегментов основных параметров и сводный столбец итоговых сегментов.
Для сегментации по давности:
R =
//чем меньше времени прошло тем лучше - поэтому считается 25й процентиль
VAR Recency_Good = PERCENTILE.INC('Clients'[DaysPassed], 0.25)
VAR Recency_Bad = PERCENTILE.INC('Clients'[DaysPassed], 0.5)
VAR result = SWITCH( TRUE(),
'Clients'[DaysPassed] <= Recency_Good, 1,
'Clients'[DaysPassed] <= Recency_Bad, 2,
3
)
RETURN resultДля сегментации по частоте:
F =
//чем чаще покупают тем лучше - поэтому считается 75й процентиль
VAR Frequency_Good = PERCENTILE.INC(Clients[PaymentsCount], 0.75)
VAR Frequency_Bad = PERCENTILE.INC(Clients[PaymentsCount], 0.5)
VAR result = SWITCH( TRUE(),
'Clients'[PaymentsCount] >= Frequency_Good, 1,
'Clients'[PaymentsCount] >= Frequency_Bad, 2,
3
)
RETURN resultДля сегментации по доходу:
M =
//чем больше денег оставлено тем лучше - поэтому считается 75й процентиль
VAR Monetary_Good = PERCENTILE.INC(Clients[Amount], 0.75)
VAR Monetary_Bad = PERCENTILE.INC(Clients[Amount], 0.5)
VAR result = SWITCH( TRUE(),
'Clients'[Amount] >= Monetary_Good, 1,
'Clients'[Amount] >= Monetary_Bad, 2,
3
)
RETURN resultДля сводного параметра есть 2 способа:
//Текстовый, главное не забыть поменять тип данных в столбце
RFM = 'Clients'[R]&'Clients'[F]&'Clients'[M]
//Числовой. Немного длиннее для записи, но не требует иных действий
RFM = 100*'Clients'[R] + 10*'Clients'[F] + 'Clients'[M]Как итог - имеем на руках готовый список клиентов, сегментированный на 27 групп и можно сказать, что на этом основная работа закончена.
Как можно видеть - по табличным данным довольно сложно получить общее представление о ситуации в компании. Для быстрого визуального анализа можно воспользоваться визуальным элементом(наиболее популярным при таком виде анализа) “Диаграмма дерева“. Для этого надо перейти в режим создания отчёта, создать новую страницу отчёта и выбрать нужный визуальный элемент. В поле категория перетащить столбец “RFM“ таблицы “Clients“, а в поле значения - “AccId“.
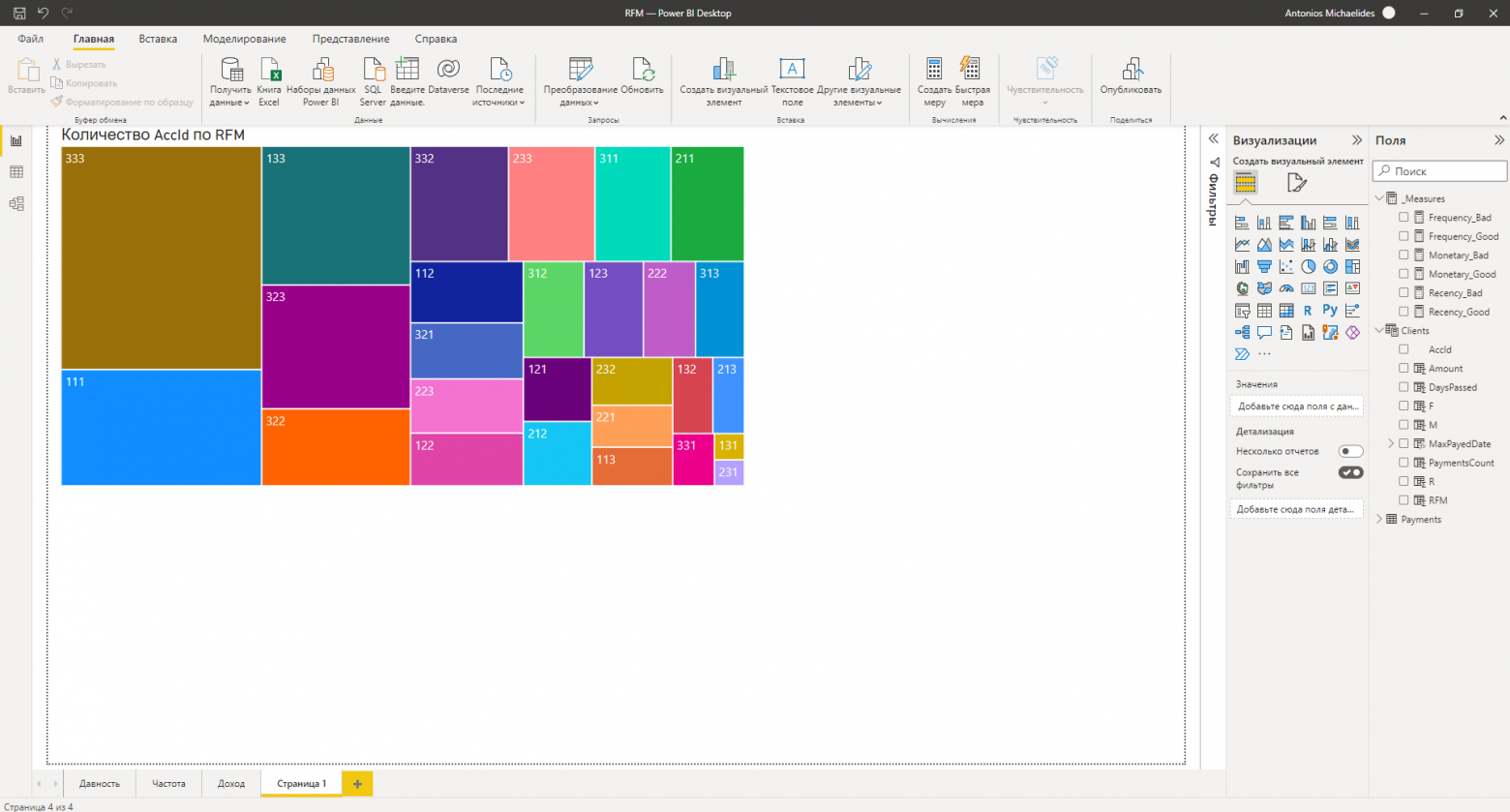
Выбранный визуальный элемент позволяет оценить долю каждого сегмента в общей массе клиентов, но всё равно ещё малопонятен.
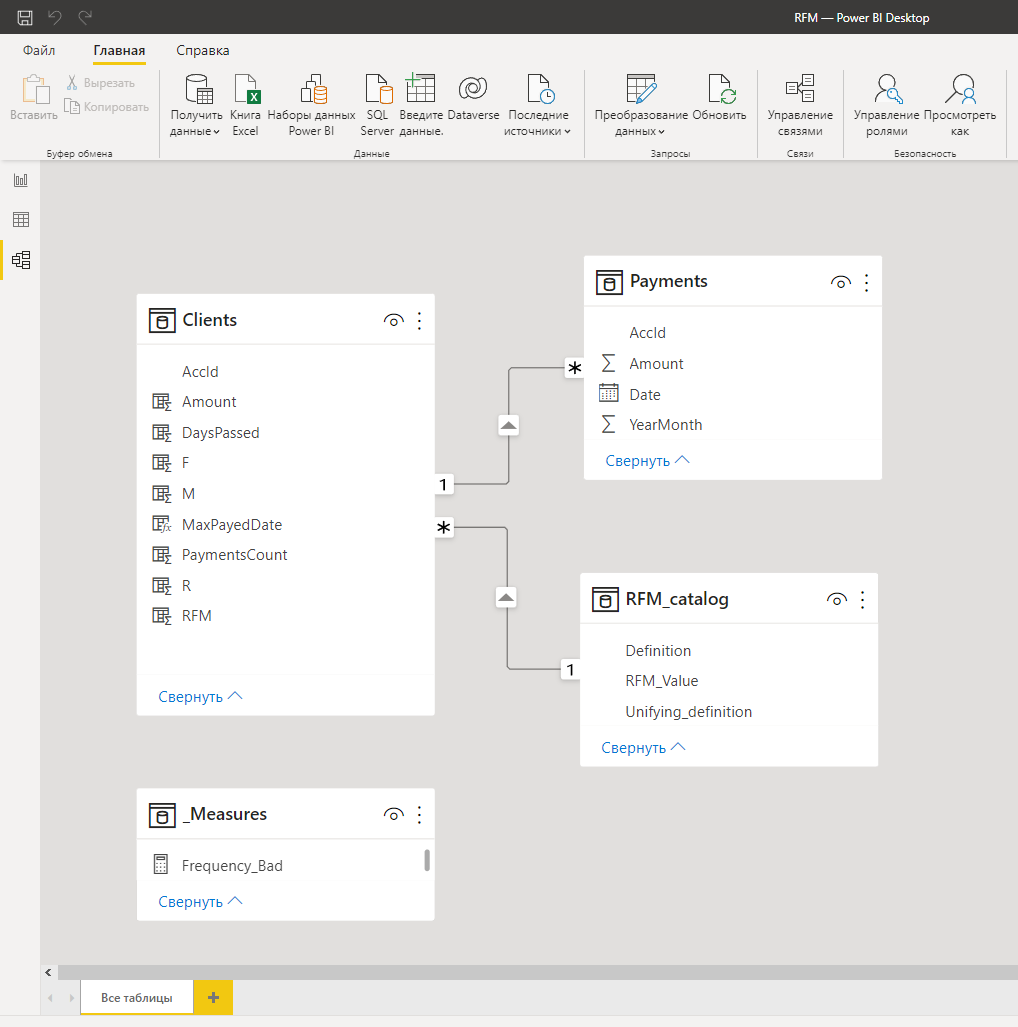
Для упрощения восприятия наши сегменты можно объединить в более крупные сегменты объединённые общим смыслом. Для этого необходимо создать справочную таблицу.

Затем в режиме редактирования модели данных надо установить связь “один ко многим“ между только что созданной таблицей и таблицей клиентов.
Всё готово. Остаётся только “навести красоту“. Для этого стоит вернуться в режим создания отчётов, выбрать визуальный элемент с деревом категорий и заменить в поле “категория“ текущее значение столбцом с описанием укрупнённых сегментов - “Unifying_definition“.
Теперь отчёт приобретает более осмысленный вид, но всё равно не хватает информативности - нельзя быстро понять сколько клиентов в какие группы попали. Чтобы добавить информативности можно добавить визуальный элемент “матрица” и в поле “строки“ перетащить сначала столбец “Unifying_definition“ из справочной таблицы, а затем столбец “AccId“ из таблицы “Clients“ (это создаст вложенную структуру и всегда будет известно, кто конкретно попал в целевую группу), а в поле “Значения“ ещё раз перетащить столбец “AccId“ из таблицы “Clients“.
Для понимания общей картины можно рассчитать несколько показателей:
Показатель | Мера/набор мер |
|---|---|
Общий доход от продаж |
|
Общее количество покупателей |
|
Средний чек |
|
Доля клиентов с пометкой “Выгодный“ в клиентской базе |
|
Доля клиентов с пометкой “Выгодный“ в объёме прибыли |
|
Доля клиентов с пометкой “VIP“ в клиентской базе |
|
Доля клиентов с пометкой “Выгодный“ в объёме прибыли |
|
Размещать числовые показатели на странице отчёта лучше всего при помощи визуального элемента “Карточка“. Карточка имеет всего одно поле для переноса данных - с ней трудностей не возникнет.
При помощи правой кнопки мыши можно скрыть вспомогательные страницы отчёта и вот теперь отчёт готов к публикации.

Вывод
Kомпания “Рога и Копыта“ плохо справляется с удержанием клиентов. Большинство клиентов предпочитает совершать мелкие покупки один-два раза и больше не возвращаться. Однако, в такой негативной тенденции оттока клиентов есть довольно большая группа лояльных постоянных клиентов.
Как можно видеть, даже такой простой отчёт позволит маркетологам проработать стратегию по возврату спящих и уходящих клиентов, подтолкнуть клиента к переходу между сегментами или поощрить самых выгодных клиентов, не напрягая никого из них бесполезными и неинтересными предложениями, что в свою очередь если и не повысит лояльность клиента, то как минимум не опустит её.

")

