

Фото Ricardo Gomez Angel, Unsplash.com
Используем метрики для отправки уведомлений через Slack
В предыдущей статье мы задеплоили оператор Prometheus с помощью helm-чарта и на примере набора сервисов увидели, как можно собирать метрики через prom-client и экспортеры. Как вы помните, цель observability (наблюдаемости) — узнать статус системы, поэтому нужные люди должны получать уведомления, когда значения метрик выходят за установленные пределы. Для этого надо настроить алерты.
Система алертов в Prometheus состоит из двух частей. В самом Prometheus мы создаем правила алертов, которые определяют условие для срабатывания алертов. Когда алерты срабатывают, Prometheus отправляет их в AlertManager, который может их подавлять, объединять или отправлять на разные платформы.
В этой статье мы создадим несколько правил алертов и отправим уведомления на их основе через Slack. Все ресурсы, которые мы используем в этой статье, можно скачать из репозитория.
Правила алертов
Чтобы создать правило алертов с помощью оператора Prometheus, используем кастомный ресурс PrometheusRule. В PrometheusRule нужно указать следующее:
Groups: коллекция алертов, которые оцениваются последовательно.
Rules: имя, условие срабатывания, период ожидания, метки и аннотации с дополнительной информацией.
Условное выражение алерта основано на выражениях Prometheus. Можно использовать Prometheus expression builder, чтобы проверить условие, прежде чем создавать его. В следующем примере у нас есть группа правил database.rules с одним правилом, которое срабатывает, когда метрика mysql_up отсутствует минимум 1 минуту.
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
creationTimestamp: null
namespace: observability
labels:
prometheus: example
role: alert-rules
release: prometheus
app: kube-prometheus-stack
name: prometheus-example-rules
spec:
groups:
- name: database.rules
rules:
- alert: "MysqlDown"
expr: (absent(mysql_up)) == 1
for: 1m
labels:
severity: critical
namespace: observability
annotations:
description: MySQL has been down for more than a minuteСоздаем ресурс командой kubectl apply -f alertrules.yml и переходим на страницу Alerts в Prometheus.

Алерт Prometheus MysqlDown
Чтобы протестировать это правило, уменьшаем количество реплик деплоя MySQL:
kubectl scale deployment/mysql --replicas=0 -n applicationsГде-то через минуту сработает алерт:
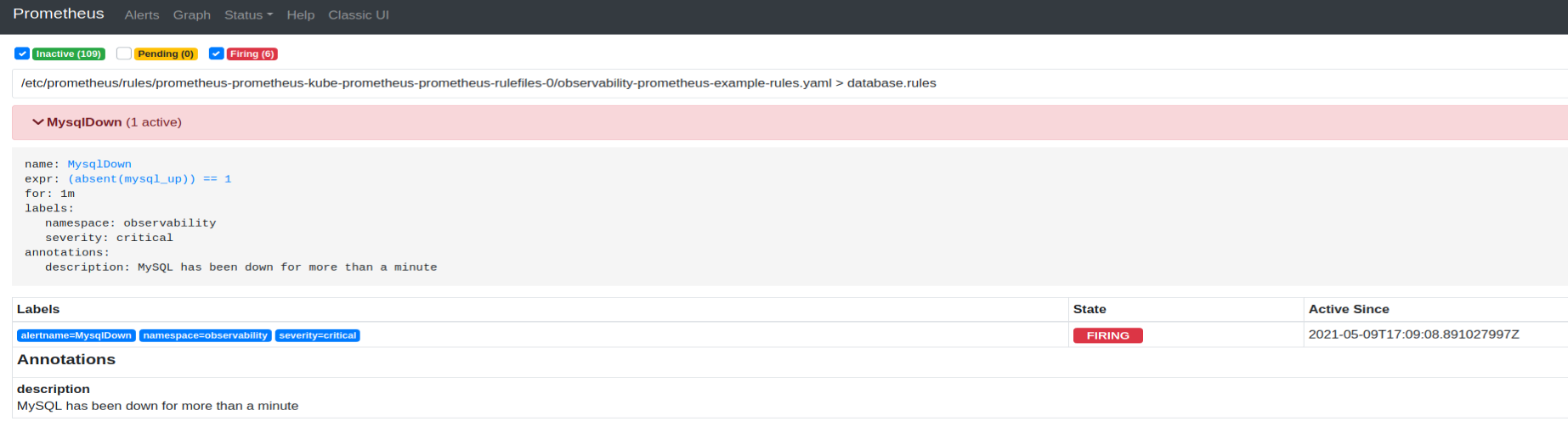
Сработавший алерт Prometheus MysqlDown
Нам не придется создавать все самим — в helm-чарте Kube Prometheus уже есть много полезных алертов для метрик Kubernetes. На основе этих алертов можно создавать собственные.

Что происходит, когда в системе возникает серьезный сбой? Приложения отказывают одно за другим, а команда получает вал уведомлений. Чтобы этого избежать, можно использовать AlertManager, который группирует похожие алерты в одно уведомление.
Посмотрим, как это работает, создав простой алерт, который срабатывает, если у деплоя остается меньше двух реплик контейнера. Но сначала настроим Slack.
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
creationTimestamp: null
namespace: observability
labels:
prometheus: example
role: alert-rules
release: prometheus
app: kube-prometheus-stack
name: prometheus-example-rules-services
spec:
groups:
- name: services.rules
rules:
- alert: "NotEnoughContainerReplicas"
expr: count by (namespace,container,job) (up{container=~".*-service"}) < 2
for: 30s
labels:
severity: warning
namespace: observability
annotations:
description: "{{ $labels.job }}: {{ $labels.container }} container doesn't have enough replicas for more than 30 seconds."Подготовка Slack
Давайте подготовимся к тому, чтобы отправлять все алерты в Slack. Для начала создадим канал Slack.
Окно создания канала в Slack
Создаем приложение в рабочем пространстве. Включаем Incoming Webhooks (входящие вебхуки) для приложения и добавляем новый вебхук в рабочее пространство. Скопируем URL вебхука — он понадобится позже.
Включение входящих вебхуков в Slack
Настройка AlertManager
Чтобы настроить AlertManager, нужно создать кастомный ресурс с именем AlertmanagerConfig. Для этого мы должны настроить хотя бы один receiver (платформу, которая будет принимать сообщения) и маршрут ко всем receiver-ам.
Для маршрута нужно указать несколько параметров группирования:
- groupBy содержит метки, которые AlertManager использует для объединения алертов в одно уведомление.
- groupWait указывает время ожидания до отправки первого уведомления.
- groupInterval указывает время ожидания до отправки обновленного уведомления.
- repeatInterval указывает время ожидания до повторной отправки последнего уведомления.
У Receiver-а Slack есть несколько параметров (см. здесь).
- Для конфигурации Slack нужен URL вебхука в качестве секрета. На этот секрет будет ссылаться параметр apiURL.
- channel — канал Slack, который будет использоваться для приема уведомлений.
- SendResolved указывает AlertManager, что нужно отправить уведомление, когда условие алерта уже не выполняется.
- Title и Text позволяют изменить формат сообщения Slack. Оба параметра могут включать ссылку на существующий шаблон.
В следующем коде все алерты с одинаковым именем, сработавшие за 30 секунд, будут объединены в одно уведомление Slack.
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: slack-alertmanager
labels:
alertmanagerConfig: slack
namespace: observability
spec:
route:
groupBy: ['alertname']
groupWait: 30s
groupInterval: 5m
repeatInterval: 12h
receiver: 'slack'
receivers:
- name: 'slack'
slackConfigs:
- sendResolved: true
apiURL:
name: slack-secret
key: url
channel: '#alerts'
title: '{{ template "alert_title" . }}'
text: '{{ template "alert_description" . }}'Пример AlertmanagerConfig
Создадим конфигурацию командой kubectl apply -f alertmanagerconfig.yml.
Переходим на страницу статуса AlertManager и видим все настроенные маршруты. Маршрут, который мы настроили, изменился — у него появилось другое имя и параметр match. Параметр match указывает метки, которые нужны алерту, чтобы его можно было отправить в receiver. По умолчанию каждый настроенный маршрут будет изменен — в него будет добавлена метка неймспейса в параметре match, даже если мы включили другие метки.
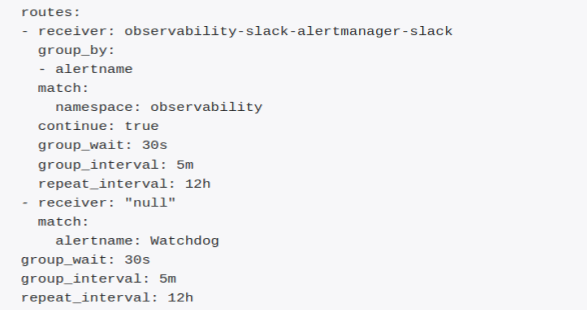
Чтобы проверить, что алерт будет направлен в нужный receiver, используем routing tree editor. Скопируем конфигурацию AlertManager со страницы статуса и протестируем метки алертов.
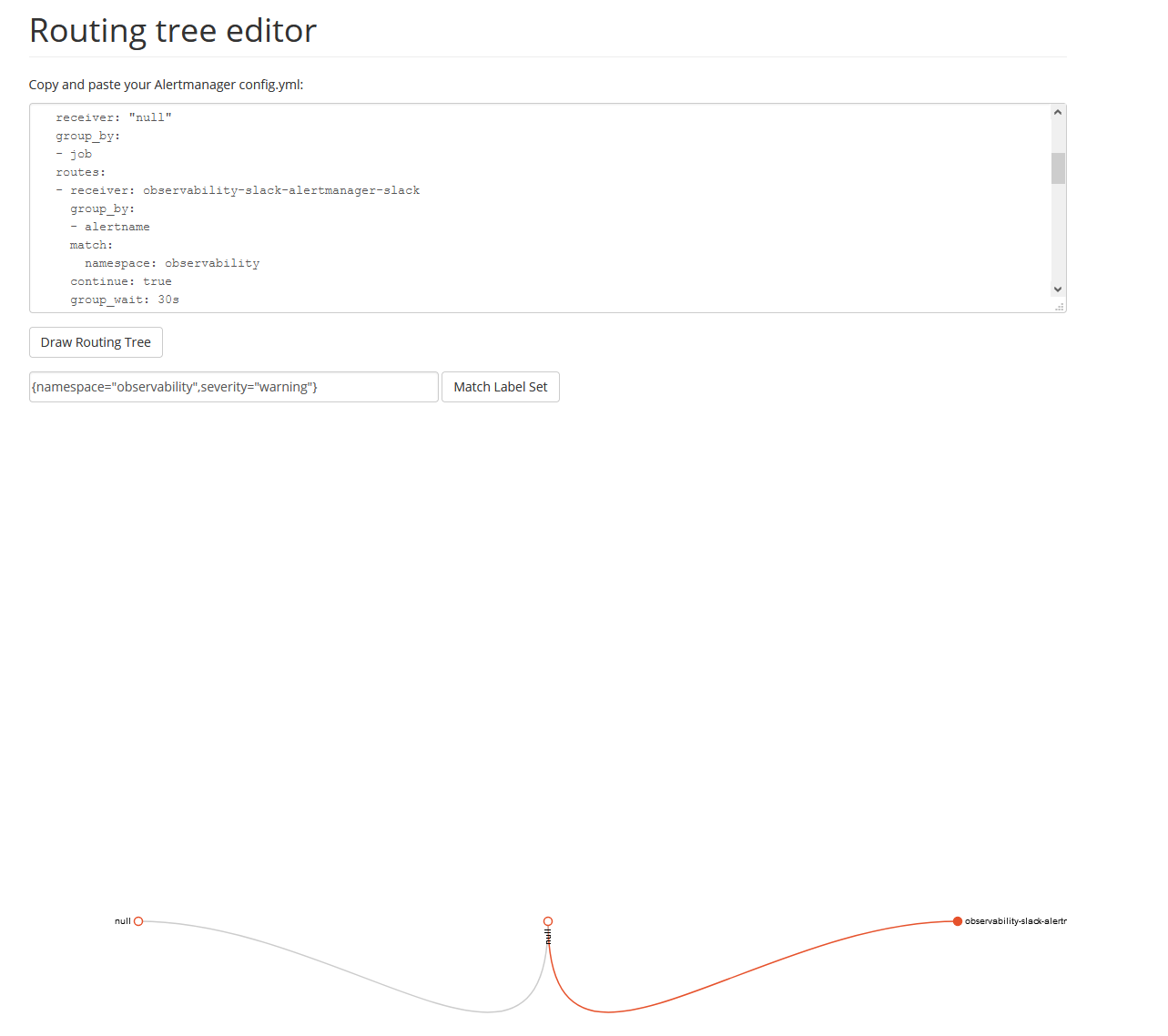
Routing Tree Editor
Шаблоны
Prometheus поддерживает определение шаблонов для уведомлений. С помощью шаблонов мы можем стандартизировать текст уведомлений для всех алертов.
Пример шаблона:
{{ define "__title" }}{{ range .Alerts.Firing }}{{ .Labels.alertname }}{{ end }}{{ range .Alerts.Resolved }}{{ .Labels.alertname }}{{ end }}{{ end }}
{{ define "alert_title" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ if or (and (eq (len .Alerts.Firing) 1) (eq (len .Alerts.Resolved) 0)) (and (eq (len .Alerts.Firing) 0) (eq (len .Alerts.Resolved) 1)) }}{{ template "__title" . }}{{ end }}{{ end }}
{{ define "alert_description"}}
{{ if or (and (eq (len .Alerts.Firing) 1) (eq (len .Alerts.Resolved) 0)) (and (eq (len .Alerts.Firing) 0) (eq (len .Alerts.Resolved) 1)) }}
{{ range .Alerts.Firing }}{{ .Annotations.description }} *{{ .Labels.severity | toUpper }}* :chart_with_upwards_trend: *<{{ .GeneratorURL }}|Graph>*{{ end }}
{{ range .Alerts.Resolved }}{{ .Annotations.description }} :chart_with_upwards_trend: *<{{ .GeneratorURL }}|Graph>*{{ end }}
{{ else }}
{{ if gt (len .Alerts.Firing) 0 }}*Alerts Firing:*
{{ range .Alerts.Firing }}- {{ .Annotations.description }} | *{{ .Labels.severity | toUpper }}* :chart_with_upwards_trend: *<{{ .GeneratorURL }}|Graph>*
{{ end }}{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}
*Resolved:*
{{ range .Alerts.Resolved }}- {{ .Annotations.description }} :chart_with_upwards_trend: *<{{ .GeneratorURL }}|Graph>*
{{ end }}{{ end }}
{{ end }}
{{ end }}Пример шаблона Prometheus
Ключевое слово define обозначает многоразовый фрагмент кода. В коде три многоразовых фрагмента: __title, alert_title и alert_description.
__title — просматривает сработавшие и разрешенные алерты и выводит имя алерта.
alert_title — выводит статус в верхнем регистре в квадратных скобках, а также число сработавших алертов. Также включает содержимое __title, если сработавший или разрешенный алерт всего один.
alert_description — если алерт всего один, выводит описание и уровень серьезности алерта, а еще ссылку на URL графика в Prometheus. Если алертов несколько, выводит их список.
Чтобы включить файл шаблона в Prometheus с оператором, нужно обновить кастомный ресурс AlertManager. Для этого можно передать кастомные значения в helm-чарт. Раз нам нужно изменить только файлы шаблонов, следующего файла будет достаточно.
alertmanager:
templateFiles:
template_1.tmpl: |-
{{ define "__title" }}{{ range .Alerts.Firing }}{{ .Labels.alertname }}{{ end }}{{ range .Alerts.Resolved }}{{ .Labels.alertname }}{{ end }}{{ end }}
{{ define "alert_title" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ if or (and (eq (len .Alerts.Firing) 1) (eq (len .Alerts.Resolved) 0)) (and (eq (len .Alerts.Firing) 0) (eq (len .Alerts.Resolved) 1)) }}{{ template "__title" . }}{{ end }}{{ end }}
{{ define "alert_description"}}
{{ if or (and (eq (len .Alerts.Firing) 1) (eq (len .Alerts.Resolved) 0)) (and (eq (len .Alerts.Firing) 0) (eq (len .Alerts.Resolved) 1)) }}
{{ range .Alerts.Firing }}{{ .Annotations.description }} *{{ .Labels.severity | toUpper }}* :chart_with_upwards_trend: *<{{ .GeneratorURL }}|Graph>*{{ end }}
{{ range .Alerts.Resolved }}{{ .Annotations.description }} :chart_with_upwards_trend: *<{{ .GeneratorURL }}|Graph>*{{ end }}
{{ else }}
{{ if gt (len .Alerts.Firing) 0 }}*Alerts Firing:*
{{ range .Alerts.Firing }}- {{ .Annotations.description }} | *{{ .Labels.severity | toUpper }}* :chart_with_upwards_trend: *<{{ .GeneratorURL }}|Graph>*
{{ end }}{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}
*Resolved:*
{{ range .Alerts.Resolved }}- {{ .Annotations.description }} :chart_with_upwards_trend: *<{{ .GeneratorURL }}|Graph>*
{{ end }}{{ end }}
{{ end }}
{{ end }}Можно обновить деплоймент helm следующей командой:
helm upgrade --reuse-values prometheus prometheus-community/kube-prometheus-stack -n observability -f values.ymlТестирование уведомлений
Чтобы получить уведомление Slack, нам нужен алерт. Давайте уменьшим количество реплик MySQL, чтобы получить уведомление по одному алерту:
Уменьшим количество реплик MySQL: kubectl scale deployment/mysql --replicas=0 -n applications
Через пару минут увеличим: kubectl scale deployment/mysql --replicas=1 -n applications
Переходим в канал Slack, чтобы посмотреть уведомление.

Уведомления Prometheus в Slack
Наконец, нужно протестировать объединение алертов в одно уведомление.
Уменьшим количество реплик Node.js:
kubectl scale deployment/format-service-depl --replicas=1 -n applications
kubectl scale deployment/hello-service-depl --replicas=1 -n applications
kubectl scale deployment/people-service-depl --replicas=1 -n applicationsЧерез пару минут увеличим:
kubectl scale deployment/format-service-depl --replicas=2 -n applications
kubectl scale deployment/hello-service-depl --replicas=2 -n applications
kubectl scale deployment/people-service-depl --replicas=2 -n applications Возвращаемся в Slack и сравниваем результаты.
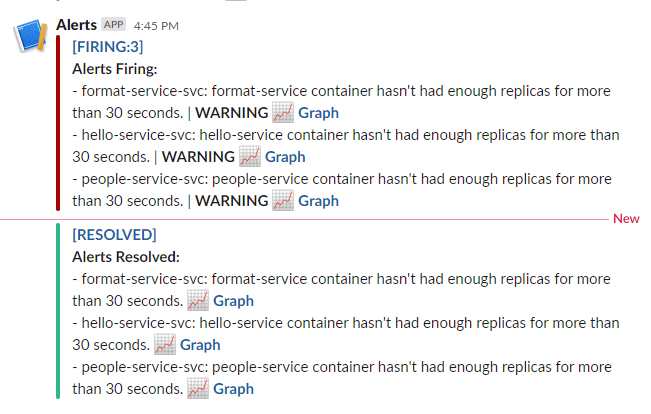
Объединенные алерты Prometheus в Slack
Как видите, алерты объединены в одно уведомление. В этом случае они входят в одну группу, потому что у них одинаковое имя. Конфигурацию группы можно изменить, добавив дополнительные метки.
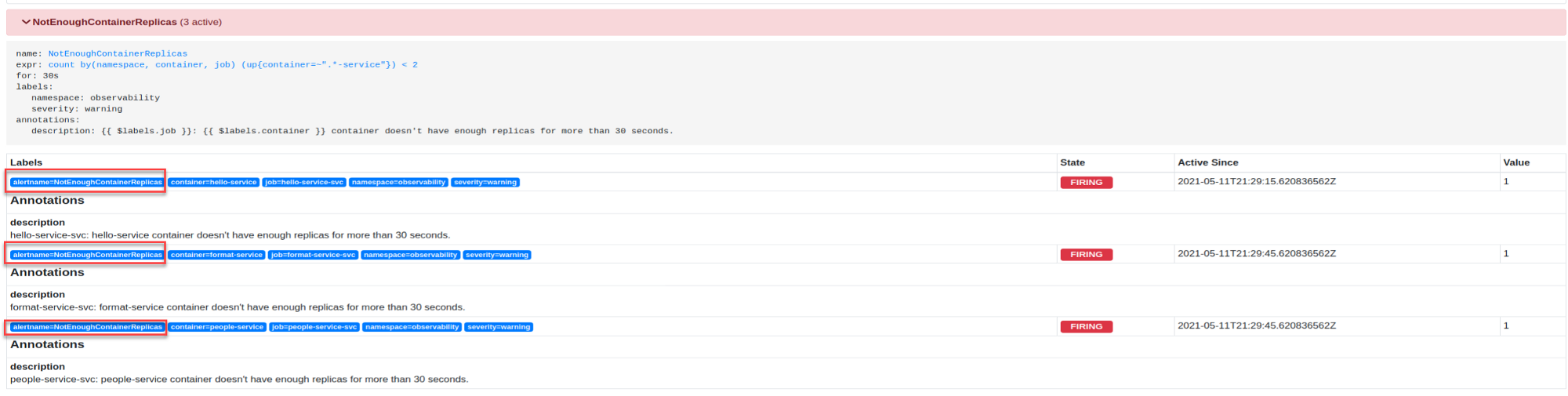
Алерты с одинаковым именем
Заключение
Уведомления — это удобный способ сообщить команде о том, что происходит в системе. Используйте шаблоны, чтобы повысить точность сообщений — это позволит быстрее решать проблемы. Не забывайте объединять алерты, чтобы не устать от уведомлений.


