
Привет. Я Марат Сибгатулин — сетевик в Яндексе, ведущий подкаста linkmeup, автор серии книг «Сети для самых маленьких» и спикер курса Слёрм Сети для DevOps, который мы сделали совместно с linkmeup.
Сегодняшний рассказ будет про несколько органических проблем современных сетевых технологий.
В жизни любого инженера бывают периоды как долгой кропотливой проработки архитектуры, так и долгих кропотливых расследований инцидентов или проблем. Нет, бывают, конечно, и озарения, стремительные лёгкие открытия, но обычно слова «кропотливый» и «методичный» — неизменные спутники нашей работы. И увы — не всегда этот процесс завершается яркой кульминацией и впрыском дофамина.
Ведь именно ради этого, и только обладая должным терпением и перфекционизмом, мы идём в профессию.
То, что мы наделали при проектировании, всегда приводит к проблемам при эксплуатации. Отличаются лишь детали: количество таких проблем, сила их влияния, нам их разгребать или кому-то другому, фундаментальные они и требуют масштабных изменений, или декоративные и компенсируются сравнительно небольшими доработками.
И сфера в общем-то не важна — сетевые технологии, разработка ПО, строительство домов, мостов или самолётов.
Есть кирпичи, которые научились изготавливать давно и хорошо, есть инструменты проектирования, упрощающие жизнь, есть шаблоны архитектур, которые берёшь и модифицируешь под свои задачи. Конечный результат получается в среднем хороший, в среднем — как у всех.
Отрасль ИТ от других отличает то, что в ней, обычно, от качества результата не зависит жизнь человека. Во всяком случае, напрямую. Поэтому плохие шаблоны могут вымываться очень долго, а ошибки переходить из одного проекта в другой раз за разом.
Иногда разбираться приходится с плодами своих же талантов архитектора, но чаще — с чужими. Свои или знаешь заранее, или быстро привыкаешь и вырабатываешь мышечную память к их употреблению. Чужие — каждый раз как в первый: садишься, долго разбираешься, находишь уникальное решение-снежинку, но и тут со временем начинаешь прослеживать те самые ошибки-гастролёры.
Я работаю с сетями, я их искренне люблю всем сердцем. Потому что они — фундамент, они основа, на которой всё строится и держится. Они с нами навсегда во всех своих проявлениях — медная витая пара, соединяющая сервер с коммутатором, оптический - трансокеанский кабель, WiFi до ноутбука и 4G до телефона.
Вокруг будут сменяться эпохи и технологии, мир будет бороться за экологию и экологичность, за равенство первых и первенство вторых, мы будем строить базы на Марсе и добывать минералы в поясе Астероидов, но незыблемыми останутся сети.
Сколько нужно сетевых инженеров, чтобы остановить шторм?
Помните тот анекдот про серийного убийцу?
Плохой программист Джон сделал ошибку в коде, из-за которой каждый пользователь программы был вынужден потратить в среднем 15 минут времени на поиск обхода возникшей проблемы. Пользователей было 10 миллионов. Всего впустую потрачено 150 миллионов минут = 2.5 миллиона часов. Если человек спит 8 часов в сутки, то на сознательную деятельность у него остается 16 часов. То есть Джон уничтожил 156250 человеко-дней ≈ 427.8 человеко-лет. Средний мужчина живет 64 года, значит Джон убил примерно 6 целых 68 сотых человека.
Так вот есть такая технология, как Ethernet. По задумке изобретателей в IEEE (читается как ай-трипл-и) она должна была принести благо и обеспечить работу нескольких узлов внутри одной локальной сети.
Под локальной сетью понималась сначала общая металлическая шина на коаксиальном кабеле. Это была разделяемая среда, и в конкретный момент времени в ней мог передавать данные только один узел.Даже всякие слова ругательные придумали, вроде CSMA/CD, которые позволяли коллизии разруливать.
Все узлы получали все данные.
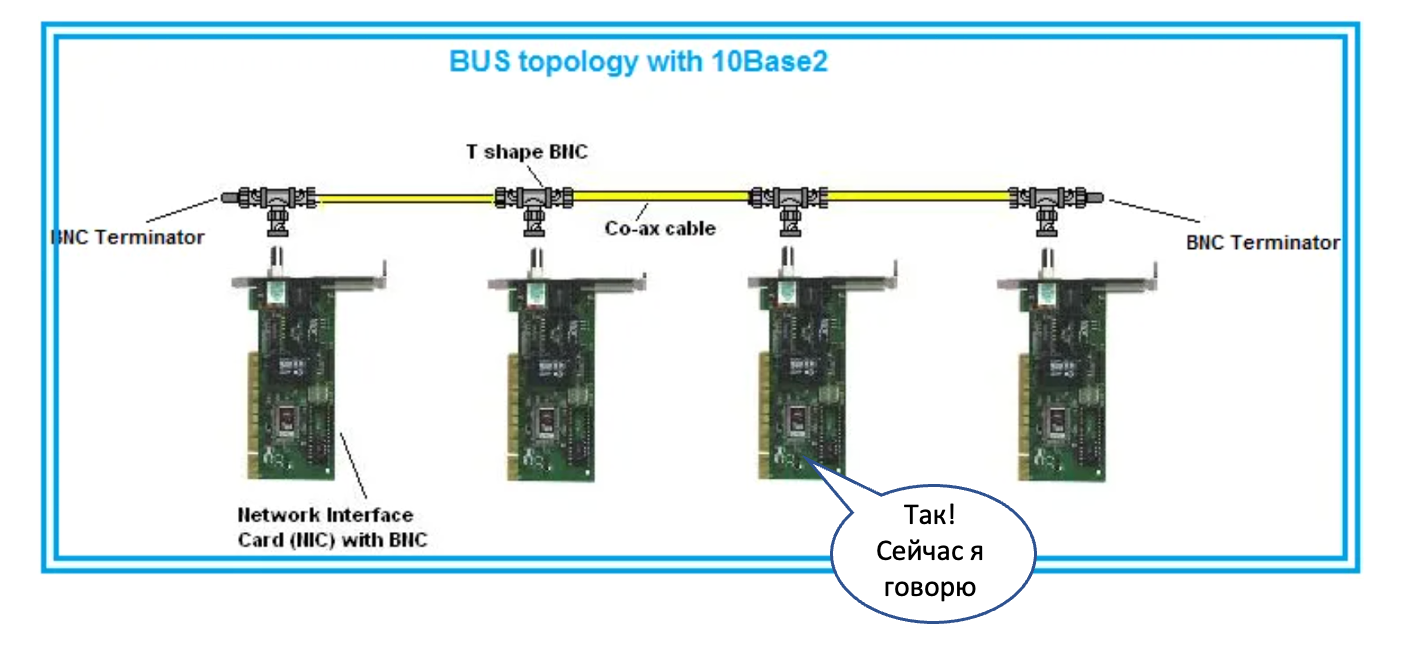

Повторюсь, что технология предполагалась быть ограниченной только небольшим сегментом на несколько узлов. Скорость передачи данных для отдельного узла экспоненциально уменьшается с добавлением каждого нового узла.
Чтобы адресовать узлы, в такой сети используются MAC-адреса — концепция второго уровня модели OSI (Layer 2 или L2). Всё, что подключено к одной такой шине, называется единым L2-доменом, поскольку все коммуникации в пределах него ограничены именно технологиями L2.
В скором одножильную шину заменили на многожильную витую пару, для соединения друг с другом узлов стали ставить хабы, а чтобы в один L2-домен можно было включить побольше узлов, стали сегментировать локальную сеть бриджами. Хабы по сути делали физическую коммутацию между кабелями, а бриджи были поумнее и перекидывали между своими портами не просто электрический сигнал, а уже Ethernet-кадры, зная, какой куда нужно передавать.



Домен коллизий уменьшился, и так стало возможным подключать больше узлов, не сильно жертвуя скоростью.
Ещё чуть позже всё-таки захотелось ещё больше скорости — чтобы каждый узел мог передавать и получать данные с максимальной мощью, предоставляемой сетевой картой - ведь странно, если у тебя 10мегабитный NIC, использовать из него только сотню килобит из-за болтливых соседей?
Так появились коммутаторы — очень (по тем временам) умные коробки, которые сами умеют определять, где какой узел находится и выстраивать коммуникацию с ними индивидуально на основе изучения MAC-адресов и поддержания их таблицы внутри чипов. Домен коллизий вообще исчез, потому что на одном проводе оказались только два устройства, у которых ещё и Rx с Tx на разных парах — шли сколько хочешь в обоих направлениях.
С ними мы шагнули в настоящее, где каждый узел получил возможность подключаться на скорости 1Гб/с


И так в результате больших и маленьких последовательных оптимизаций мир получил возможность в один L2-домен засовывать практически неограниченное количество узлов и неизлечимую болезнь, подпортившую много жизней. Именно с коммутаторов началась мировая история широковещательных штормов: сложно даже прикинуть, сколько миллионов часов человечество провело в их отладке.
Прекрасное и отвратительное в том, что Ethernet превосходно решает порученные ему задачи, имея в самом ядре своём механизм auto-discovery. Узел, отправляющий данные, не знает изначально, сколько и каких соседей с ним есть в сети. Не знает он и то, где расположен его шлюз: он просто шлёт данные. А сеть сама сможет понять, куда их доставить.

Механизм этот называется широковещание или broadcasting. Не знаешь, что делать? Рассылай во всех доступных направлениях — там разберутся.
Ну а поскольку первые топологии локальных сетей были звёздами и не предполагали наличия петель, никто и не думал о том, что жизнь кадра должна быть конечной и скоротечной.
Однако если петля есть и кадр в неё попал, он будет бегать по ней без конца и края. А сделать петлю — как два байта отослать: просто вставить кабель одновременно в два порта коммутатора. Я вам не говорил, но это распространённая проказа в домовых сетях.
Хуже того: такой трафик может мультиплицироваться и за считанные минуты забить любой доступный канал и интерфейс. Характерной чертой штормов является 100% утилизация интерфейсов и истеричная гирлянда светодиодов на портах коммутатора. От этого страдает транзитный пользовательский трафик: для него не остаётся места.
А ещё такие кадры в большинстве своём должны быть обработаны на CPU-коммутатора, вдруг это ему предназначается, поэтому к 100% на интерфейсах добавляется 100% утилизации CPU, а это в свою очередь вырубает Control Plane коробки — она становится неотзывчивой, рвёт установленные сессии, перестают работать протоколы, не отвечает на запросы системы мониторинга или даже SSH.
Но всё ещё нет проблемы, пока мы Ethernet используем в домашней или офисной сети, где упало что-то: да и бог бы с ним,один пользователь пострадал. Мы можем не строить там сети с петлями административно и запрещать их появление по злому умыслу или незнанию технически. А в сетях операторов связи и датацентрах должны существовать свои другие отказоустойчивые топологии и протоколы.
И такое использование разных технологий для организации локальных сетей возможно, потому что общим объединяющим протоколом является IP, работающий на третьем уровне модели OSI (L3). А на разных сегментах от отправителя до получателя на канальном и физическом уровне может быть абсолютно что угодно.
Но почему-то возможность была воспринята как необходимость. И Ethernet начали со страшной силой пихать куда ни попадя. Провайдеры стали делать на нём домовые сети и пихать его в ядро. Сети предприятий распробовав дешевизну оборудования Ethernet и стали строить на нём свои кампусные сети. В датацентрах подешевевшие из-за массовости Ethernet-чипы тоже снискали популярность.
А всем этим ребятам нужна отказоустойчивость, потому что отказ одного линка или устройства — это сотни и тысячи пострадавших пользователей, недополученных денег и испорченная репутация.
И как только стали появляется кольцевые L2-топологии, начались и чудовищные штормы так называемого BUM-трафика. Очень звучное и говорящее название, кстати. Broadcast, Unknown Unicast и Multicast — все эти виды трафика однажды попав в петлю, остаются в ней до тех пор, пока её не разорвать. И все они плоть от плоти L2 — неотъемлемая часть Ethernet, и они присутствуют в сети всегда.
Как решение этой проблемы появились 50 оттенков STP — протокола, отрезающего лишние линки, чтобы не было петель. Вместе с ними плодились и проприетарные реализации протоколов защиты в кольцевых топологиях а-ля ERPS.
И вот представьте себе: строите вы сеть, покупаете гору оборудования, кабелей между ними, трансиверов, а потом половину чик — и отрезаете, лишая себя купленной пропускной полосы. Обидно.
И все эти протоколы рано или поздно дают сбои. Я в своей жизни ещё не встречал отказоустойчивых L2-сетей, в которых бы не было шторма. И это всегда болезненно, это всегда критический инцидент с большим влиянием.
Я видел сети городских провайдеров, ядро которых построено на L2 и отказоустойчивость обеспечивается STP или его аналогом. Их штормило по несколько раз в месяц — весь город оставался без связи от этого провайдера.
Я видел сети операторов связи, у которых по городам и весям на сотни километров были раскинуты гроздья радиорелеек, собранные в L2-кольцо с STP. И от штормов в них иные деревни совсем оставались без связи.
Я видел федеральных операторов, чья физическая сеть построена на L3 и не имеет вышеуказанных проблем. Но поверх неё создавалась так называемая оверлейная или наложенная сервисная сеть, действующая по принципам L2. Да-да, и такое бывает. И в одном L2-домене оказывался целый регион, а то и несколько. Раз в несколько месяцев оно вспыхивало синим пламенем и полыхало по несколько часов, вместе с десятком-другим инженеров, пытающихся понять, что происходит и где рвать петлю.
Я сам запускал шторм в сети датацентра, когда в сеть Клоза ставил недонастроенное оборудование и пара сотен 100гигабитных линков уходили в полку по утилизации.
И вот этот порочный шаблон повторяется из одного проекта в другой многие годы. Раз за разом. А решение очень простое — оставить L2 там, где ему место — в небольших локальных сетях не больше чем на сотню конечных хостов.
Да, мы никуда не денемся от Ethernet как от нижележащего протокола: он теперь повсеместный. Мы ничего не можем сделать с механизмом широковещания: уже поздно добавлять поле TTL в Ethernet-заголовок, чтобы старые пакеты погибали — никто не сможет с этим работать.
Но клянусь, в наших силах сохранить широковещательный домен очень маленьким. И каждый раз, когда к сетевому инженеру приходят с предложением натянуть L2, он должен подозрительно сощурить глаза, взглянув на вопрошающего, и дать тому затрещину. Есть только одна причина, растягивать L2: вам чересчур спокойно живётся и хорошо спится и руководство разделяет вашу тоску.
Вообще мы тут рекламируем наш курс про сети, поэтому если хочется погрузиться в описанные вещи поглубже, то вам туда прямая дорога. Разбираемся с моделью OSI и её уровнями, смотрим, как работает broadcasting, настраиваем бриджинг и STP, ну и вообще всячески делаем так, чтобы эти грозные слова вас не пугали.
Я тебя вычислю по IP
Мне кажется, в топ-3 причин нёх на сети входит именно описанная ниже ситуация.
«Тут ходит — тут не ходит», «то болит — то не болит», «у меня постоянно рвутся коннекты», «у меня через раз устанавливаются коннекты», «поретраю — и работает», «трафик пошёл не туда, куда я сказал», «постоянно разваливается OSPF».
Эти и другие увлекательные истории можно услышать, когда вы (или вам) устроили конфликт IP-адресов, то есть в двух местах настроили один и тот же IP-адрес. Это может быть интерфейс конечного узла, может быть интерфейс маршрутизатора или любой другой сетевой сущности.
А дело всё в том, что пакетик такой бежит-бежит по сети. Радостно оглядываясь на таблицу маршрутизации, спешит он к своему получателю. И вот он его уже видит, запрыгивает на сетевой стек машинки с адресом назначения, а оттуда netlink в него из револьвера — бах! Вас тут не ждали! А настоящий получатель так и не получил свой пакет.
Так могут не устанавливаться новые TCP-сессии: потому что на порту никто не слушает;
Так могут подвисать и рваться старые, если поток трафика перенаправился в другое место, и там, на порту, никто не слушает;
Так могут пинги бежать то к одному получателю, то к другому. И с виду всё хорошо, но почему-то задержки в 7 раз различаются и в tcpdump половину запросов не видно.
Так может OSPF не сходиться или постоянно перестраиваться из-за совпавших router-id.
В общем, если видимые симптомы вы можете охарактеризовать словом «дичь» (но не потому что вы вообще в сетях не шарите), то первым под подозрение поставьте задвоившиеся IP-адреса — поверьте моему опыта (я в сетях немного шарю).
Отлаживать это муторно, но не очень сложно: просто шаг за шагом смотрите на таблицы маршрутизации, местонахождение адреса назначения, его MAC-адреса, за каким портом он изучен. И рано или поздно докопаетесь.
Наверняка вы знаете: один из хостов всё-таки фиксируете проблему. Можно просто выключить его или перенастроить адрес — тогда у вас выровняется ping и по traceroute вы сможете найти путь к хосту-поганцу с таким же IP (а потом найти и инженера-поганца, допустившего это).
Обычно такие проблемы случаются, когда выделение и назначение адресов происходит вручную. Просто человеческая ошибка — бывает. Поэтому для IPv4 придумали DHCP. Вам всего лишь нужно в каждом L2-домене поднять один сервер, настроить на нём пулы, шлюз, адрес DNS-сервера и следить за тем, что такое сервер действительно один. Ну, возможно, покопаться с настройками DHCP-Relay и всяких разных DHCP Options. Не беда.
Главное — что централизованное управление IP-адресами — это благо: оно позволяет снизить вероятность IP-конфликта.
Это всё касалось IPv4. Не в малой степени он склонен к конфликтам из-за ограниченного адресного пространства (всего 32 бита) и отсутствия вообще каких-либо проверок на такие коллизии.

В IPv6 проведена масштабная работа в этом направлении (как и любом другом, на самом деле — они там в IETF вообще большие молодцы, ну если не считать, что из-за них когда-то пришлось придумывать NAT).
Адрес IPv6 — 128-битный. Поэтому, во-первых, выделить одинаковые адреса чуть посложнее, во-вторых, ручное управление адресами вообще проблематично. И как ответ на «во-вторых»для IPv6 придумали автоконфигурацию IP-адреса на основе префикса сети и MAC-адреса хоста. Акцент на вторую часть — MAC-адрес хоста. Именно он делает в 99,9999% случаев IPv6-адрес уникальным.
А автоконфигурация избавляет инженера от необходимости поддерживать DHCP-инфраструктуру. Оно просто работает и нагенерит вам с высочайшей долей вероятности неконфликтный, воспитанный IP-адрес.
А кроме того у IPv6 из коробки есть DAD — Duplicate Address Detection. После назначения адреса на интерфейс он не использует его сразу, а сначала убеждается, что в локальной сети он один такой неповторимый и неотразимый. У меня в практике были десятки случаев конфликтов IPv4 адресов и ни одного IPv6.
IPv6 большее благо, чем IPv4 DHCP. Любите IPv6, переходите на IPv6, рассказывайте всем про IPv6. А если не понимаете за что любить и почему от 4 сразу перешли к 6 — мы вас научим. Как настроить их на Linux, как поднять DHCP-сервер, что за автоконфигурация в IPv6 и чем вообще IPv6 отличается от IPv4 (спойлер — не только числом битов). И вместе с вами подиагностируем разные проблемы связности.
Кортеж пятерых
А вот следующая штука не факт, что входит в какой-то топ среднестатистического сетевого инженера. И каждый день такое ловить не приходится, и коли уж поймали, то непонятно совершенно, что с этим делать.
Однако многие хоть раз да сталкивались с потерей пакетов в сети и неустанавливающиеся соединения. Не факт, что эти проблемы входит в какой-то топ среднестатистического сетевого инженера. И каждый день такое ловить не приходится, и, коли уж поймали, то непонятно совершенно, что с этим делать.
Жили вы обычной жизнью сетевого инженера, BGP-шку там настраивали, новые офисы компании запускали, строили трансокеанский канал между офисами для HFT, чтобы сэкономить 5 миллисекунд по сравнению с конкурентом.И вдруг телеграм начал разрываться, а ваш дежурный пинг в консоли начал показывать 7% потерь.
Допустим, по плану эвакуации уже побегали, пользователям скорейшее выздоровление пообещали, что делаем дальше?
Тут, конечно, наберётся материала на серию статей с абсолютно произвольной глубиной погружения.
На самом деле дальнейшие действия зависят от характера потерь и симптомов: достаём из арсенала ping'и такие и сякие, traceroute/mtr, telnet/nc/curl, в конце концов tcpdump, и начинаем анализировать.
Только ли проблема с ICMP? Есть ли какой-то специфический шаблон в потерях? Большие пакеты проходят? TCP и UDP одинаково себя ведут? Можно ли сказать, что только у конкретных TCP-сессий есть проблема, в то время как у других всё чётко и стабильно? Показывает ли mtr накопительные проблемы по пути? А если mtr-T? Увеличиваются ли задержки? А проблемы наблюдаются до одного конкретного адреса? Или можно локализовать хотя бы направление? Или вообще куда угодно?
А если рубануть одного провайдера? А другого? А попробовать попинговать из другого места? А из-за пределов собственной сети вообще? А в обратную сторону — в сторону нашей сети извне —как дела? А маршруты нашей сети нормально вообще по миру распространяются?
В зависимости от наисследованного дальше причины можно классифицировать следующим образом:
Где-то плохое качество линии, а пакеты портятся/теряются на лету — скорее всего, бессистемные потери без увеличения задержек.
Где-то перегрузка на линии или в очередях маршрутизатора — скорее всего, бессистемные потери, сопровождающиеся отрастанием задержек.
Один из нескольких равнозначных путей испытывает проблемы выше — скорее всего, бессистемные потери с симптомом «то болит, то не болит». Но на трассировке по TCP или UDP будет видно, что только по конкретному пути проблемы.
Что-то стряслось с MTU: раньше большие пакеты проходили нормально, а теперь нет — скорее всего, ping маленькими пакетами (1400 байтов) будет ходить нормально, а большими (1500) будет таймаутить. Скорее всего, можно попробовать в TCP-порт тыркнуться через telnet или nc, а вот curl'ануть уже может не получиться — слишком много данных.
Ну и моё любимое — что-то где-то случилось так неловко, что конкретные TCP-flow (или UDP-датаграммы) не доходят до получателя. При этом другие доходят, а ICMP вообще проблем не фиксирует.
Запомни, инженер! Если ты не видишь потерь в ping %server_address%, это ещё не значит, что у тебя всё в порядке!
Знаете, первые четыре причины имеют под собой очень увлекательную фундаментальную базу и написано про это много книг и снято видосов (даже моими силами), и там, правда интересно, но позвольте мне проявить слабость и рассказать как раз о последнем.
Это действительно нечастая ситуация. В пинге вы можете увидеть её как более или менее регулярные потери с характерным шаблоном или нерегулярные бессистемные потери, но примерно одного и того же % запросов, а можете не увидеть совсем.
Если вы будете делать попытки установить TCP-сессии с помощью telnet или nc, то, на первый взгляд, тоже не будет никакой системы — иногда получается, иногда нет (на что пользователи, собственно, вам и жалуются).
Кстати, в цикле пробовать ставить сессии можно так
while :; do nc -zvw 1 linkmeup.ru 443; done
Connection to linkmeup.ru 443 port [tcp/https] succeeded!
Connection to linkmeup.ru 443 port [tcp/https] succeeded!
Connection to linkmeup.ru 443 port [tcp/https] succeeded!Немного косметики:
while :; do
nc -zw 1 linkmeup.ru 80 &> /dev/null && echo -n '!' || echo -n '.';
sleep 0.1;
doneКартина становится более наглядной.
Но стоит зафиксировать src port, как картина начинает проясняться.
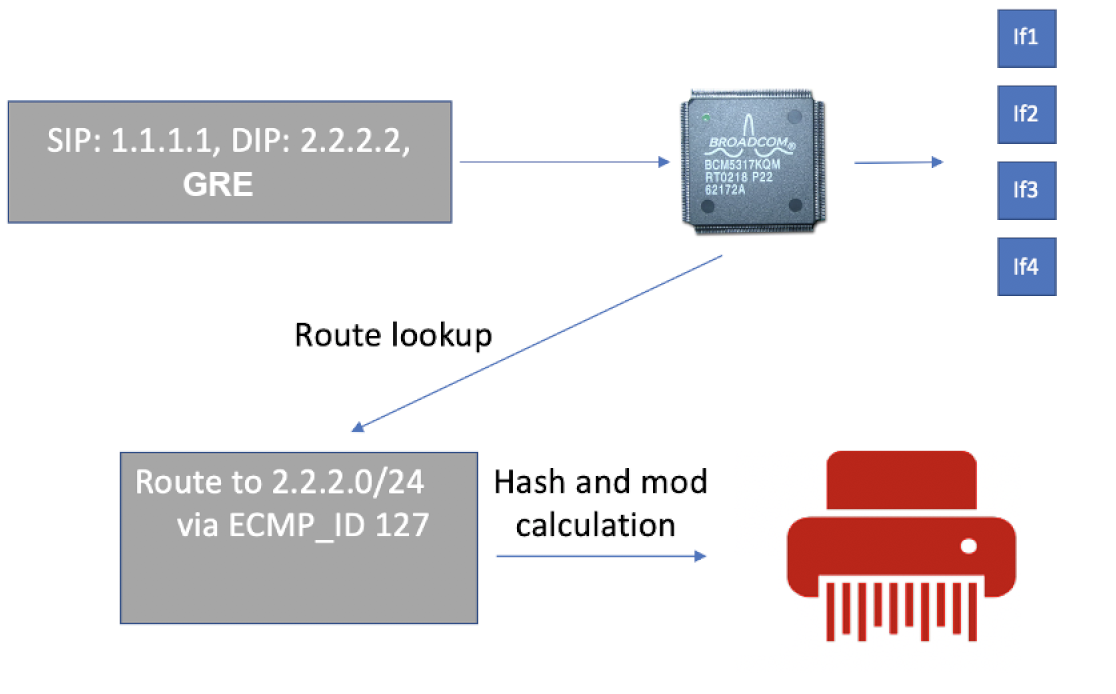
Дело в том, что при установке TCP-сессии у нас зафиксированы четыре параметра: dst IP, src IP, протокол TCP, dst port. И один параметризируемый — src port. Для каждой новой сессии клиенты (браузеры, почтовики, SSH, FTP) выбирают новый эфемерный src port из диапазона 1024-6535. Не выбирать совсем нельзя вообще, меньше 1024 нельзя — всё уже занято, а меняется он для того, чтобы в этом так называемом 5-tuple (src-ip, dst-ip, proto, src-port, dst-port) была энтропия и при наличии нескольких различных путей на основе этого 5-tuple можно считать хэш и раскладывать по разным путям.

Хэш от одного и того же 5-tuple будет всегда получаться один и тот же, а следовательно, для него всегда будет выбираться один и тот же путь.
Так вот, если один из этих путей корёжит пакеты, то всё, что в него отправляется, будет теряться, а всё, что в него не попадает, будет работать нормально.

Именно поэтому просто установка соединения будет то успешной, то нет, а если мы фиксируем src port, то эта хэш-неопределённость разрешается, и мы получаем стабильную картину — или каждый раз успешен, или каждый раз провален.
Вот как можно зафиксировать порт:
nc -zv -p 34437 linkmeup.ru 443Вот как можно перебирать порты в цикле
for i in {10000..50000} ; do
echo -n "$i:";
nc -w 1 -p $i -z linkmeup.ru 443 &> /dev/null && echo " OK" || echo " FAIL" ;
sleep 0.1;
doneТеперь mtr вам, скорее всего, поможет понять, на каком хопе проблема (но может и не помочь).
И осталось разобраться в чём проблема и исправить её - всего-то.
> mtr -T linkmeup.ru -P 443
Host Loss% Snt Last Avg Best Wrst StDev
1. (waiting for reply)
2. 100.64.0.101 0.0% 15 0.2 0.2 0.2 0.3 0.0
100.64.0.33
100.64.0.103
100.64.0.34
100.64.0.74
100.64.0.72
100.64.0.75
100.64.0.39
3. (waiting for reply)
4. msk-ix-2.servers.ru 0.0% 14 4.1 5.9 3.8 18.3 4.7
5. se-mo01-s1.servers.ru 0.0% 14 3.7 3.9 3.7 4.2 0.2
6. se-mo1-s3.servers.ru 0.0% 14 3.9 3.8 3.5 4.0 0.1
7. se-mo01-l25-r1.servers.ru 0.0% 14 4.5 5.1 4.1 7.5 0.9
8. proxy03.linkmeup.ru 0.0% 14 3.4 3.4 3.1 3.5 0.1А тут… ну тоже серия статей с произвольной глубиной погружения.
Однако это почти всегда история про баги ПО — где-то что-то недопрограммировалось в чипы или структуры памяти, записалось не то, что было нужно или уже записанное было повреждено.
Основные причины:
Баг операционной системы сетевого устройства — на уровне работы с протоколами и формирования верхнеуровневых структур. Грубо говоря, программа неправильно посчитала таблицу маршрутизации и испортила один 5-tuple.
Баг SDK чипа. Чип коммутации предоставляет API для управления его внутренней памятью и правилами обработки пакетов. SDK для доступа к API — та же программа. И она тоже содержит баги.
И вы в него можете передать всё правильно, а он запрограммирует в чип с ошибкой. И пакеты с конкретными хэшами будут теряться.
Небольшое расширение вышеприведённых сценариев — залипания на фаерволах, когда в iptables спустились неверные правила.
Такие же сюрпризы может подкинуть и ECMP — Equal Cost Multipath, когда один из путей сломан так, что он продолжает выглядеть рабочим (например, анонсирует маршруты, через себя), но с точки зрения передачи транзитных данных поломался. Тогда всё, что раскладывается в него согласно 5-tuple будет теряться. Стоит вывести из под нагрузки этот путь — и всё начинает работать.
И очень изощрённый случай — аппаратные повреждения.
Был в моей практике такой случай. Приходит заказчик в техподдержку (ко мне) и говорит, что у него теряется часть трафика — лечится ретраями: ну прям как я выше описал симптомы.
Дальнейшая диагностика как раз позволила понять, что проблемы с прохождением определённых 5-tuple.
По трассировке мы увидели, что потери наблюдаются за пределами сети заказчика — в другом провайдере. А он по счастливой случайности тоже оказался нашим заказчиком, поэтому мы уже с ним продолжили диагностику. На сети этого провайдера стоял так называемый холодильник — шассийная коробка размером со шкаф, в которую напиханы дюжина плат и под полсотни разных сложных чипов. И вот мы посмотрели таблицу коммутации на чипе входной карты, посмотрели в какие пины задней шины шасси раскладываются пакеты, проверили живость этих путей и обнаружили, что через часть из них не проходят данные — мы не можем отловить их на выходном чипе.

Попросили инженера клиента извлечь интерфейсную плату и сфотографировать её. И что бы вы думали? На задней общей шине оказались загнуты контакты — и всё, что по балансировке внутри этого холодильника раскладывалось на эти пины, терялось.
Как только увели трафик с этого пути,всё заработало.

Последняя проблема тоже органическая часть современных протоколов, не говоря уж о потерях пакетов как таковых. И даже новые протоколы, такие как QUIK, и всеобщее применение QoS (какая небылица) решить их фундаментально не позволят. Есть разной степени изящности решения, позволяющие обходить проблемные места, но всё это уже предмет архитектурных изысканий мощных сетевых инженеров.
Однако если вам хочется разобраться с маршрутизацией, работой протоколов TCP и UDP, использованием ping, traceroute, mtr, tcpdump, понять как выбираются пути и какие протоколы в этом помогают — мы тоже сможем помочь.
Мир сетевых технологий удивителен — в нём прогрессивные вещи, вроде SDN и прямой программируемостью структур в чипах коммутации сочетаются с чудовищным legacy времён рассвета информационных технологий. И если вы когда-либо страдали от необходимости поддержки обратной совместимости, просто подойдите к своему сетевому инженеру и попросите его рассказать, как трафик с вашего ноутбука добирается до серверов Яндекса или Amazon. У вас точно будет повод порадоваться тому, как хорошо вам живётся с вашими фреймворками и удивиться, как вообще что-то сегодня работает, учитывая снежный ком технологий для организации связи.
Любите IPv6!



