
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Весной 2021 года во французском Страсбурге случилось яркое событие: полностью сгорел дата-центр одного из крупнейших европейских хостинг-провайдеров (OVH). Всего за несколько часов пожар отрубил доступ к миллиону популярных сайтов и онлайн-сервисов во всём мире. Одна из вероятных причин — человеческий фактор. В результате под угрозой существования оказался не только сам ЦОД, но и весь бизнес провайдера. К слову, и в России ЦОДы тоже горят. К сожалению, пожар — не единственная проблема больших данных. Не менее опасно — highload системы. Это когда, например, приложение перестаёт справляться с моментальной нагрузкой, а вся инфраструктура работает на пределе возможностей, и запаса для роста у неё нет. Забегая вперед, скажу, что решение есть у каждой из перечисленных проблем. Но, обо всём по порядку.

Что делать, если объёмы и нагрузка на СУБД продолжают расти, а мы уже исчерпали все возможности?
Совсем недавно в своей статье «Big Data с «кремом» от LinkedIn: инструкция о том, как правильно строить архитектуру системы» я затронул очень важный аспект: проектирование и эксплуатация высоконагруженных информационных систем — речь шла об узких местах в архитектуре подобных программных решений. Рекомендую прочитать эту «вступительную» часть, чтобы лучше погрузиться в суть разбираемых вопросов в этой статье.
Дело в том, что традиционно, самым узким местом в архитектуре любой системы является система управления базами данных (СУБД). Можно сколько угодно оптимизировать прикладное программное обеспечение (ПО), но всё равно вы упрётесь в ограничения в части производительности запросов к СУБД. Мы уже говорили о том, что можно отказаться от традиционных СУБД в пользу NoSQL, пожертвовав строгой консистентностью, но при этом нашли компромиссный вариант — eventual consistency. Но что делать, если объёмы и нагрузка на СУБД продолжают расти, а мы уже исчерпали все возможности вертикального масштабирования?
Пожалуй, оптимальное решение — шардирование (англ. sharding). Это подход, предполагающий разделение баз данных, отдельных её объектов на независимые сегменты, каждый из которых управляется отдельным экземпляром сервера базы данных, размещаемым, как правило, на отдельном вычислительном узле.
В отличие от секционирования (партиционирования), предполагающего раздельное хранение частей объектов базы данных под управлением единого экземпляра СУБД, сегментирование позволяет задействовать технику распределённых вычислений. Однако, при этом более сложно в реализации, поскольку требует обеспечения координации множества экземпляров — причём взаимодействие должно вестись со всей совокупностью сегментов, как с единой базой данных.
Техника сегментирования широко используется в NoSQL-СУБД (таких, как Cassandra, Couchbase, MongoDB), аналитических СУБД (Teradata Database, Netezza, Greenplum), поисковых системах (Elasticsearch, Solr). Также техника реализована в некоторых традиционных реляционных СУБД (опция Sharding в Oracle Database). Для СУБД, не поддерживающих сегментирование, организуется маршрутизация запросов к нескольким экземплярам СУБД со стороны приложения.
Чтобы было понятнее, давайте рассмотрим архитектуру с использованием шардированной СУБД на примере MongoDb:
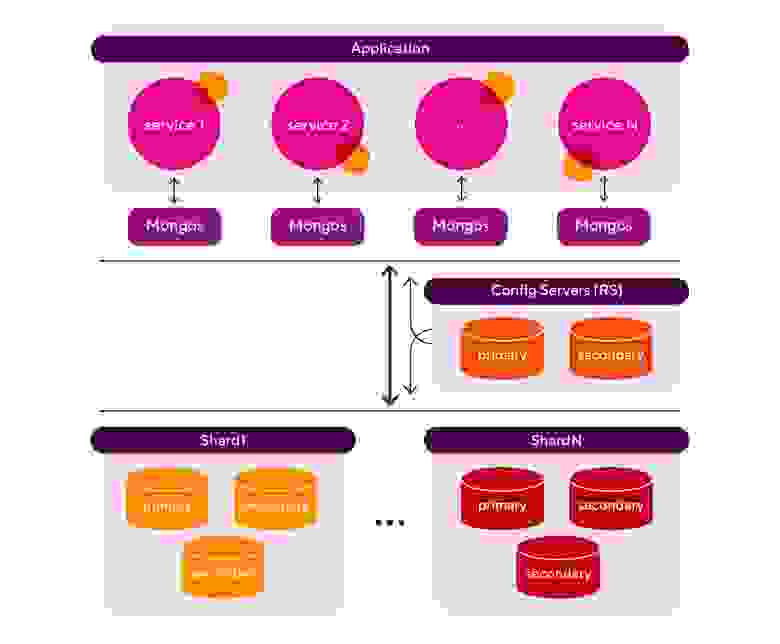
Разберём отдельно каждый элемент архитектуры:
Application — это наше приложение. Для простоты я нарисовал типовое микросервисное приложение, но мы не рассматриваем его архитектуру в рамках данной статьи. Для нас важно, что приложение работает с СУБД;
Mongos — маршрутизатор запросов от приложения к конкретному узлу СУБД. Количество маршрутизаторов может быть любым и зависит от профиля нагрузки и особенностей самого приложения;
Config Servers — сервер конфигурации (кластер) самой СУБД. Отвечает за хранение метаданных шардированного кластера СУБД. Представляет собой типовой кластер MongoDb в конфигурации ReplicaSet;
Shard — шард. Кластер СУБД, отвечающий за хранение сегмента данных. Представляет собой типовой кластер MongoDb в конфигурации ReplicaSet. Количество шардов может быть любым и зависит от профиля нагрузки, объёмов данных и требований в части производительности и отказоустойчивости. По сути, каждый шард — это отдельный экземпляр СУБД.
Как выбрать ключ шардирования?
Горизонтальное масштабирование подразумевает распределение набора данных и нагрузки по нескольким узлам СУБД. Но как это работает? Для этого используется так называемый ключ шардирования. Как это устроено: сущности, связанные одинаковым значением ключа шардирования, группируются в набор данных по заданному ключу. Этот набор данных хранится в пределах одного физического шарда, что существенно облегчает обработку данных.
Таким образом, если известен ключ шардирования некоторого объекта, то всегда можно ответить на вопросы:
- Где следует сохранить данные?
- Где найти запрошенные данные?
Возникает резонный вопрос — как выбрать ключ шардирования? Отмечу, что у хорошего ключа есть несколько признаков: высокий (cardinality) и неизменяемость (immutable), и второй повсеместно используется в частых запросах.
Естественный выбор ключа шардирования — это идентификатор сущности. Если у вас он есть — используйте его! Лучше всего если данный идентификатор из семейства UUID (от англ. universally unique identifier — универсальный уникальный идентификатор).
По сути, UUID — это стандарт идентификации, используемый в создании программного обеспечения.
Основное назначение UUID — позволять распределённым системам уникально идентифицировать информацию без центра координации. Таким образом, любой может создать UUID и использовать его для идентификации чего-либо с приемлемым уровнем уверенности, что данный идентификатор непреднамеренно никогда не будет использован для чего-то ещё.
Что ещё важно — правильный выбор ключа шардирования обеспечит равномерное распределение кусков данных (chunks) по шардам кластера, а значит, и высокую производительность при чтении. Плюс, чем равномернее распределены данные по шардам, тем меньше нагрузка на балансировщик, который как раз и занимается их выравниванием. И я надеюсь, что все прекрасно помнят, что процесс балансировки chunks далеко не бесплатный!
СУБД MongoDb «из коробки» предлагает два типа ключей:
- Ranged — разделение данных на непрерывные диапазоны;
- Hashed — разделение данных на основе hash функции.
Выбор за вами, но в большинстве случаев я бы рекомендовал использовать хешированное распределение (hashed shard key). Причина проста — hash-функция позволяет даже плохой ключ, с точки зрения формальных признаков, превратить в хороший. Если ещё проще, то задача hash-функции — равномерно распределить сущности по шардам. Я мог бы углубиться в суровую математику и рассказать про критерий Пирсона и другие интересные вещи, но в этом нет необходимости, поскольку инженеры компании MongoDb Corporation уже за нас все продумали и выбрали хорошую hash-функцию для задачи шардирования. Поэтому нам осталось просто этим всем пользоваться и наслаждаться.
«Игры» разума: как избежать «паразитного» трафика в ЦОДе?
С ключами разобрались, а теперь переходим к «воспламеняющимся» терминам: георезервирование и катастрофоустойчивость.
Под катастрофоустойчивостью обычно понимают систему георезервирования, когда инфраструктура информационной системы расположена в нескольких центрах обработки данных (NOC). Катастрофоустойчивость обеспечивает непрерывность выполнения бизнес-процессов, реализованных в информационной системе, при выходе из строя ЦОДа целиком. В это сложно поверить, но даже сейчас бывают масштабные аварии на сетях электроснабжения, причём на длительное время. И даже полное выгорание ЦОДа (ссылка с фотографиями на статью выше)
Катастрофоустойчивые решения для ЦОДов можно разделить на 2 класса: активно-пассивная конфигурация, когда нагрузка выполняется на одной площадке и метро-кластер конфигурация, когда нагрузка выполняется одновременно на обеих площадках.
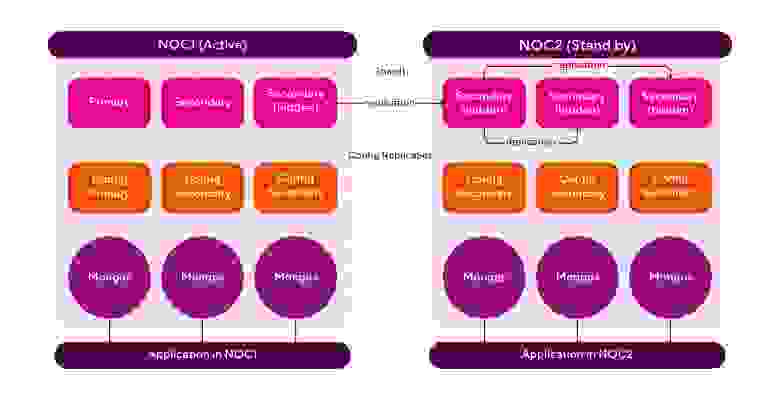
Рассмотрим пример катастрофоустойчивого решения на базе СУБД MongoDb в активно-пассивной конфигурации. На диаграмме ниже представлена топология СУБД, распределённой по двум ЦОД (NOC). Давайте разбираться, как это работает!
Фактически, мы делим каждый шард на две части — одна часть работает в NOC1, вторая в NOC2. В активном ЦОДе расположен PRIMARY узел шарда СУБД и половина secondary узлов. С одного из secondary узлов СУБД в активном ЦОД (NOC1), не с PRIMARY как мы привыкли, идёт репликация данных в сторону NOC2. Причем можно заметить, что этот узел БД помечен на «скрытый» (hidden). От кого он скрывается? Конечно же, от нашего приложения, иначе, на данный узел падала бы дополнительная нагрузка на чтение.
В самом ЦОД настроена каскадная репликация. Зачем? Все дело в том, что между NOC1 и NOC2 есть канал связи и так как они географически разнесены, то канал имеет задержку в несколько десятков миллисекунд. Если бы репликация шла с основного (PRIMARY) узла активного шарда в NOC1, то мы бы замедлили работу кластера СУБД на этом ЦОД. Дело в том, что при записи PRIMARY узел ждёт подтверждения от кворума реплик (SECONDARY) о том, что они завершили запись, а поскольку у нас есть задержка на канале, то и подтверждение от реплик, расположенных в NOC2, приходило бы с задержкой. Помимо этого, мы попросту забили бы канал связи между ЦОДами «паразитным» трафиком от репликации. Поэтому репликация в NOC2 идёт с выделенного узла в этом же ЦОД, который, в свою очередь, реплицируется с источника, расположенного в NOC1. Ух, наверное, всех запутал… Для осознания происходящего советую перечитать данный абзац несколько раз.
Итак, с репликацией шарда мы разобрались. С config server всё ещё проще — это единый распределённый ReplicaSet для двух ЦОД. Никакой репликации тут нет, поэтому ничего накручивать не нужно.
Далее маршрутизаторы запросов — Mongos. С ними тоже все просто. Они, как и само приложение (application), просто продублированы в двух ЦОД. Никакого взаимодействия между этими компонентами нет. Они работают абсолютно независимо друг от друга.
Что же произойдёт при наступлении катастрофы в NOC1, когда он внезапно превратится в пепел или «тыкву»? Алгоритм тут следующий:
- Исключаем узлы, расположенные в NOC1 из replica set для shard и config servers
- Меняем роль основного узла – источника репликации в NOC2 на PRIMARY
- Меняем роль одной из secondary в config server replica set в NOC2 на PRIMARY
- Снимаем hidden со всех узлов в NOC2
- Всё работает, данные сохранены. Хотя, конечно, потребовалось вмешательство инженера, который после такой суматошной беготни, наверняка потребует день отдыха за счёт компании.
Даже у шардирования есть недостатки
Безусловно, у любой самой замечательной вещи на свете, в том числе и у шардированной СУБД, есть и недостатки, о которых не стоит забывать:
- Во-первых, шардированный кластер — это дорого! Согласитесь, что иметь кластер из 3-х физических серверов дешевле, чем кластер из 30 узлов. Давайте посчитаем: обычный (нешардированный) кластер СУБД, т.е. типовой ReplicaSet — это primary + пара secondaries. Итого: 3 узла. А шардированный кластер — это уже минимум 2 шарда, обычно больше (в каждом по три узла) + replica set под config servers + серверы под mongos.
- Во-вторых, в шардированных коллекциях не всегда работает операция count. Она может возвращать большее количество документов, чем в действительности. Причина — балансировщик, который в фоне «переливает» документы с одного шарда на другой. В какой-то момент времени возникает ситуация, когда документы уже записались на целевой шард, а на исходном ещё не удалились — count посчитает их дважды.
- В-третьих, шардированный кластер сложнее в администрировании. Дело в том, что есть необходимость обеспечить надёжную сетевую связность между всеми узлами СУБД, поставить под мониторинг и настроить алертинг для всех хостов СУБД, а также обеспечить регулярные бэкапы каждого шарда и высокую отказоустойчивость кластера и прочее. Все эти моменты можно возвести в степень в части повышения сложности эксплуатации и администрирования СУБД и информационной системы как целого по сравнению с обычной кластерной конфигурацией СУБД (single replica set).
Стоит ли «отметать» шардирование за его дороговизну и сложность в администрировании? Вопрос, пожалуй, риторический, ведь на кону не столько деньги и время, сколько репутация и развитие вашей компании.




