
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Это история о том, как уход вендора чуть не лишил бизнес голосовой аналитики, как наша сервисная команда занималась реверс-инжинирингом на проекте с SLA 4-часа, искала и исправляла ошибки в коде базы данных с огромным числом зависимостей, обнаружила за собой слежку, избавилась от нее и сохранила отношения с клиентом.
Пятница, утро. Через неделю должен начаться мой долгожданный отпуск, на душе мир и покой. Но когда ты сотрудник сервисной поддержки, ты как спасатель должен быть готов в любую минуту оказаться в совершенно других жизненных обстоятельствах.
В 8:38 на почту клиентской поддержки пришло письмо, которое начиналось стандартно “Коллеги, доброе утро”, а заканчивалось тревожно – “Ситуация критична для работы нескольких подразделений”.
Клиент - крупный бизнес с больших числом клиентов, который использует зарубежное решение голосовой аналитики. Один из его блоков индексирует транскрибированный текст по ряду параметров в том числе, позволяя оценить массив по содержанию и эмоциональному окрасу. На входе аналитики выставляют сложные фильтры, а на выходе получают файлы со звонками по конкретным запросам, в которых уже подсвечены важные для оценки места. Внутри нейронные сети и ищут ключевые слова, необходимые для оценки телефонных сессий и по ряду созависимых параметров мэтчит запросы со звонками.
Это позволяет аналитикам контролировать работу специалистов колл-центра, оценивать результаты маркетинговых активностей, разбирать спорные ситуации. Данной работой ежедневно занимается несколько команд аналитиков в разных городах. В пятницу утром аналитики привычно выставили фильтры, запустили алгоритм, а на выходе получили ноль.

Вендор тихо ушел из России практически сразу после начала февральских событий, оставив без какой либо поддержки закупленные ранее лицензии. Он не отвечал на вопросы и видимо боялся даже контактировать с российскими клиентами, считая такое общение токсичным и рискованным. Оставалось только надеяться на свои силы и самостоятельно искать причину сбоя. Понимая что у данного кейса самый высокий приоритет, мы подключили своих лучших специалистов и начали вбуриваться в проблему.
Начали мы, как и всегда, со штатных действий: вставили вилку в розетку, посмотрели логи, перезагрузили сервера, сервис целиком и его отдельные компоненты, еще раз посмотрели логи, сопоставили взаимодействие компонентов. Единственное, что нам удалось выяснить, что один из тасков сервиса Background Worker, который оперирует всеми SQL джобами постоянно отбивался ошибкой. Возникала она в процессе выполнения пула Core Update, джобы ETL, которая отвечает за отображение, собранных и обработанных данных операционной БД в системе, путём их публикации в БД долгосрочного хранения. Именно в последнюю БД приложение смотрит при манипуляции с данными.
Мы поняли, что джоба перестала работать еще в четверг – она зависла при выполнении одного из шагов. Мы её принудительно завершили и перезапустили через Management Console. Для отработки джобой накопленного массива необходимо было примерно час-два времени. По прошествии этого времени нас снова ждала неудача. Джоба отрабатывала до какого-то определенного момента и снова выдавала ошибку. Мы попробовали перезагрузку сервера базы данных, но и это не принесло результатов.
Время идет, кейс первого приоритета с SLA в 4 часа все еще не решен. У заказчика остановилась работа аналитиков нескольких департаментов, потому что они не могут получить материал для своей работы. Остроту ситуации немного сглаживало приближение выходных, когда аналитики не работают и влияние на сервис не столь критично. Но у нас контракт на поддержку 24/7, поэтому работа не останавливалась в субботу и воскресенье. Все выходные команда поддержки продолжала нон-стопом искать решение и проверять все приходящие в голову варианты. Вечером в воскресенье становится понятно, что гипотез больше нет, а проблема не решена.
Утром в понедельник усиливаем команду - подключаем двух инженеров внедрения, двух аналитиков, которые принимали участие во внедрении этой системы, и начинаем этой командой брейнштормить и проверять новые гипотезы. Мы либо чиним систему, либо будем больше заказчику не нужны – поддерживать больше нечего.
В какой-то момент становится понятно, что проблема в базе данных, и чтобы до нее добраться, придется повозиться.
Джобы здесь находятся глубоко в недрах очень мутной архитектуры. Внутри джоб – целая куча хранимых процедур и все это вызывается не SQL сервер-агентом, а Background Worker сервисом, который ещё и крутится на винде. Чтобы понять устройство процедуры и внутренние зависимости, нам нужно было провести реверс-инжиниринг кода. Потому что уже на втором уровне базы Warehouse – это целый вагон хранимых процедур, которые выполняют функцию DTL, перекладывают свои данные из одной базы в другую и их очень сложно отследить. Потому что вендор сделал так, что сломанный механизм после отработки откатывается и удаляет все логи. Мы по сути не знаем, что конкретно этот механизм не может переварить.
Мы поняли, что нам необходимо написать свою программу-логгер на уровне БД, которая будет собирать все, что делает база. А для этого нужен человек, который лучше знаком с синтаксисом, занимается написанием запросов на SQL, анализом баз данных и поможет нам с написанием логгера. И такой человек быстро нашелся (мы же в КРОК). Мы взяли вендорскую хранимую процедуру, чуть-чуть переписали ее и добавили дополнительных табличек, чтобы собирать данные.
В таблицу:
create table dyn_sql_logger (
start_time datetime2,
dyn_sql nvarchar(max));
Была добавлена в процедура:
dbo.cspGetMediaWithHitsQuerySQL
dbo.cspGetSavedStateForTargetMediaSet
dbo.cspKeyListToIdentityList
TargetMediaSet.cspGetMediaWithHitsQuerySQL
dbo.cspGetFilteredMedia
Также добавлены вызовы перед выполнением динамического SQL:
insert into dbo.dyn_sql_logger values(sysdatetime(), <переменная с текстом запроса>);
Нашему специалисту по БД потребовалось какое-то время, чтобы финализировать логгер, потому что первые версии не позволяли нам заглянуть достаточно глубоко. Мы раскручивали код как клубок. Каждый раз узнавали что-то новое, допиливали программу и заново запускали процесс. Слой за слоем мы погружались внутрь разработки вендора. В ходе выполнения следующих запусков это позволило нам непосредственно следить за тем, какие шаги выполняют сломанные процедуры. И вот что мы обнаружили.
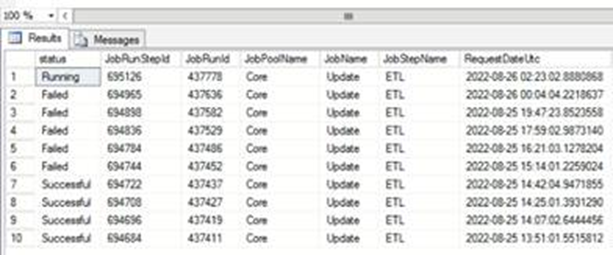
Сами джобы, запускающиеся сервисом, находятся непосредственно в операционной БД. Статус их запуска установить можно следующим запросом: в первую очередь здесь нам важно было видеть время запуска

Однако в самой операционной базе данная ошибка не происходила, необходимо было коррелировать запуск джобы с ETL батчем который выполнялся в БД долгосрочного хранения. Именно в нем система попадала на исключение с указанной выше ошибкой синтаксиса. Сами шаги относящиеся к Core Update джобе можно было увидеть в логе внутри базы:

Но именно шаги выполняемые внутри шагов можно видеть в таблице ниже. Причем в данной таблице мы видим только выполнение текущего задания. Нам конечно же нужно было отслеживать ETL и его компоненты.

После завершения шага джобы данные сразу перебрасываются в таблицу cfgETLSQLlogHistory. По данным из этих таблиц был получен ключ некорректного TMS (так называется множество аналитических данных, которые используются, например, в отчётности)со стороны БД а также выявлены процедуры которые непосредственно ведут обработку.

Некорректный ключ на котором наблюдалась ошибка заполнялся в таблицу с TMS и первичным ключом TargetMediaSetKey ровно соответствующим выводу выше с последующей ошибкой.

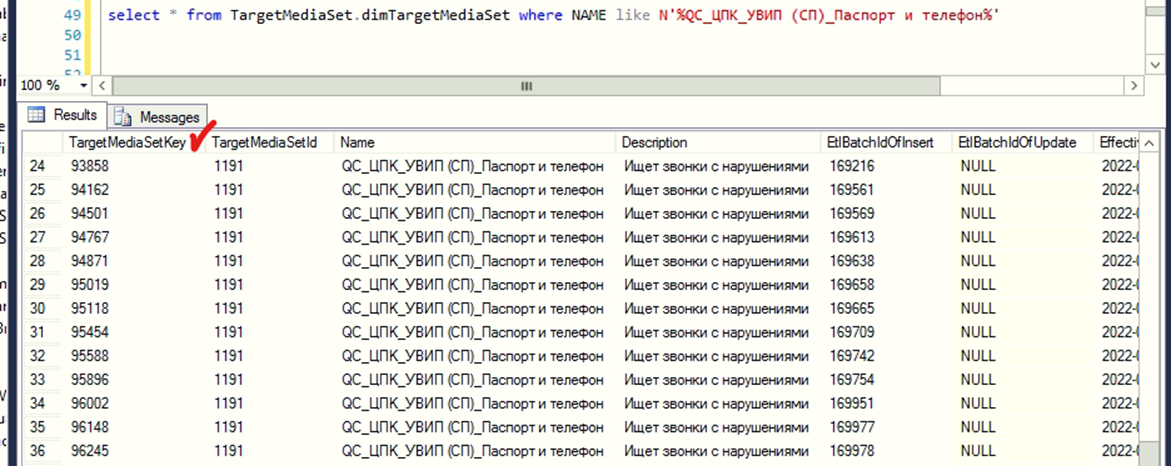
Стоить отметить, что система работает транзакциями, и откатывает их в случае неудачи, в связи с этим следить за шагами приходилось в режиме реального времени, чтобы успеть проверить соответствие ключа. На проверку гипотезы уходило сначала 2 часа, а затем 7 часов – к середине недели система накопила приличный бэклог (более 60+ млн. строк данных).
Далее мы проверили веб интерфейс и данный TMS – попытка открытия приводила к ошибке в интерфейсе и он перезапускался. Что послужило вторым доказательством что TMS некорректный. Удалить в интерфейсе его было невозможно, следовательно это необходимо было сделать в БД. Было проведено тестирование в нашей лаборатории с определением всех связей, после чего аналогичную операцию выполнили на проде.
Сама проверка:

Непосредственно удаление и проверка после, плюс бекапы:

После чего запуск джобы был отменен, т.к. она все равно уже собрала некорректные данные через процедуру:

Помимо того, выполнение динамического SQL было обернуто в блоки обработки ошибок с добавлением потенциально проблемных запросов в ErrorMessage в следующих процедурах:
dbo.cspReportGetValidChainingKeys
dbo.MediaFile_GetDistributedCounts
dbo.cspGetMediaWithHitsQuerySQL
dbo.cspGetSavedStateForTargetMediaSet
dbo.cspIdentityListToKeyList
dbo.cspKeyListToIdentityList
TargetMediaSet.cspGetMediaWithHitsQuerySQL
dbo.cspGetFilteredMedia
dbo.cspIngestSessionIdentityListToLiveKeyList
dbo.getTagAssignedMedia
Снова запускаем процедуру, в полной уверенности, что мы попали в точку и проблемная джоба исправлена. Ждем 7 часов и…утром сервис аварийно завершился с новой ошибкой.

Она ссылается на новый объект в системе, созданный недавно техническими специалистами заказчика. База BD_TEMP, не учитывающая полностью дизайн сервиса, не только логгировала наши действия, но и крашила всю программу.
Тут важно отметить, поскольку это кейс первого приоритета, в течение всего времени проведения сервисных работ мы дважды в день информировали представителей заказчика о наших действиях. Практически в режиме реального времени мы транслировали что происходит, с какими проблемами столкнулись, какие решения предлагаем, какие могут быть сроки. Представитель заказчика был полностью синхронизирован с нами и на всех уровнях понимал, что происходит.
И вот когда я уже собирался сообщить о решении проблемы, мне нужно писать заказчику, что все зафейлилось, потому что его технические специалисты решили последить за нами. В этой ситуации нам было важным сохранить лицо перед бизнесом и отношения с его айтишниками. В общую переписку было несколько абстрактно написано, что создан некий новый объект, на котором все споткнулось. Параллельно мы договорились с айтишниками клиента, что они удалят из БД свой объект. Казалось, что мы уже у финишной цели.
Снова тестовый запуск, 7 часов ожидания и снова мы получаем ошибку, которой быть не должно. Ошибка ссылается на тот же самый объект, созданный недавно. В ходе повторной синхронизации с коллегами нас заверили, что больше этот объект влияния на работу сервиса не окажет. Это происходит вечером в пятницу, мой последний день перед отпуском. Я очень рассчитывал не передавать эту историю еще кому-то на время отпуска, но на всякий случай уже добавил в чатик с командой и почтовый тред с заказчиком своего коллегу, который был готов подхватить проблему на время моего отпуска.
И вот в субботу утром, мы видим, что звонки в системе появились – после отката изменений BD_TEMP джоб успешно отработал.

Ранее остановленная сессия была перезапущена и отработала корректно, данные в TMS наполнились:

Система и джоба ETL Core Update работают корректно.
Пишу клиенту долгожданное письмо, что все починили и со спокойной душой ухожу в отпуск. Happy end.
Несколько выводов по итогам истории:
1. Если вы используете систему вендора, ушедшего с российского рынка, прямо сейчас подумайте о сервисной поддержке. Кто вам ее окажет и сколько потребуется на это времени?
2. Пока вендоры не вернутся на российский рынок или пока бизнес не перейдет на альтернативные решения, в коде критических приложений будут периодически всплывать ошибки. И единственный путь устранить их – это исправлять своими силами.
3. Доверяйте своим технологическим партнерам. Двойной контроль это хорошо, но иногда приводит к обратным результатам. Если вы делегировали задачу профессионалам, дайте им время и возможность с ней разобраться.
****
18 мая в 11:00 на площадке Digital Leader состоится онлайн митап “Есть контакт! Будущее контакт-центров на зарубежных платформах. Стоит ли переходить на российские альтернативы?”. Специалисты компаний КРОК и К2Тех поделятся трендами на рынке контакт-центров, расскажут как в текущих условиях наладить сервисную поддержку и бесшовно перейти на альтернативных решения.
Чтобы стать участников митапа, зарегистрируетесь по ссылке.
")


