
Многие разработчики считают скрапинг сложной, медленной и неудобной для масштабирования задачей, особенно при работе с headless-браузерами. По моему опыту, можно заниматься скрапингом современных веб-сайтов даже не пользуясь безголовыми браузерами. Это очень простой, быстрый и хорошо масштабируемый процесс.
Для его демонстрации вместо Selenium, Puppeteer или любого другого решения на основе безголовых браузеров мы просто используем запросы на Python. Я объясню, как можно скрапить информацию из публичных API, которые потребляет на фронтэнде большинство современных веб-сайтов.
На традиционных веб-страницах наша задача заключается в парсинге HTML и извлечении нужной информации. На современных веб-сайтах фронтэнд скорее всего не будет содержать особо много HTML, потому что данные получаются асинхронно после первого запроса. Поэтому большинство людей использует безголовые браузеры — они способны выполнять JavaScript, делать дальнейшие запросы, после чего можно распарсить всю страницу целиком.
Но существует и другой способ, которым можно довольно часто пользоваться.
Скрапинг публичных API
Давайте разберёмся, как можно использовать API, которые веб-сайты применяют для загрузки данных. Я буду скрапить обзоры продукта на Amazon и покажу, как вам сделать то же самое. Если вы повторите описанный мной процесс, то удивитесь, насколько просто его подготовить.
Наша задача — извлечь все обзоры конкретного продукта. Чтобы повторять за туториалом, нажмите сюда или найдите любой другой продукт.
Скриншот продукта.
Наша задача — извлечь как можно больше информации. Помните, когда занимаетесь скрапингом данных, жадность наказуема. Если не извлечь какую-то информацию, то придётся выполнять весь процесс заново, просто чтобы добавить ещё немного данных. И поскольку самой тяжёлой частью скрапинга являются HTTP-запросы, обработка не должна занимать много времени, однако необходимо постараться минимизировать количество запросов.
Перейдя на страницу продукта и нажав на «ratings», а затем выбрав «See all reviews», мы увидим следующее:
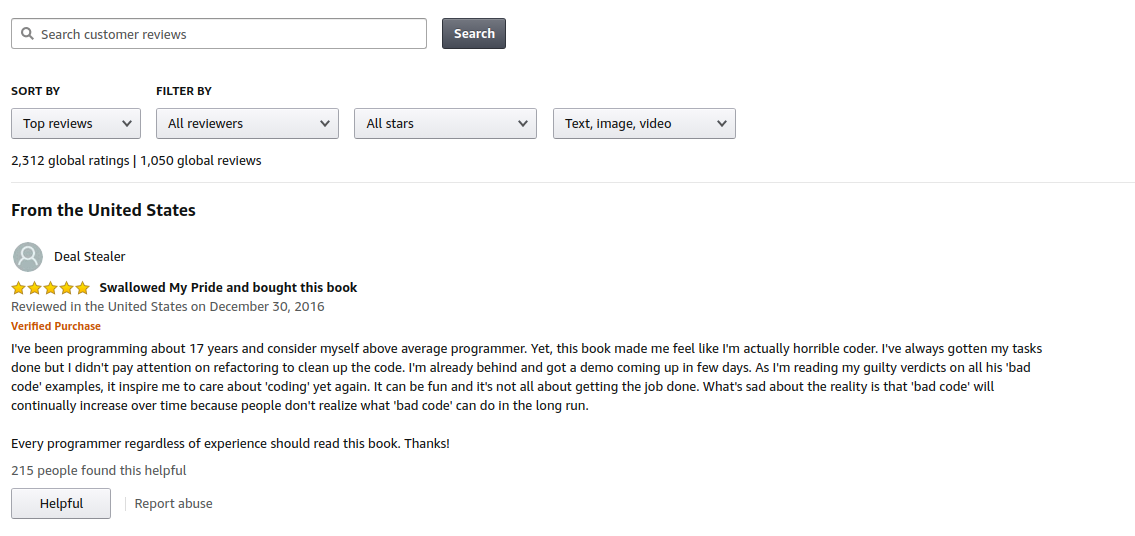
Страница обзоров продукта
Это отдельные обзоры. Наша задача — извлечь информацию с этой страницы без использования безголового браузера для рендеринга страницы.
Процесс прост для него потребуются браузерные инструменты разработчика. Нужно заставить сайт обновить обзоры, чтобы найти возвращающий их запрос. Большинство браузеров после открытия инструментов разработчика отслеживает сетевые запросы, поэтому откройте их перед выполнением обновления.
В данном случае я изменил сортировку с «Top Reviews» на «Most Recent». Взглянув на вкладку Network, я вижу только один новый запрос, то есть обзоры получаются из этого запроса.
Поскольку на страницах выполняется отслеживание и аналитика, иногда при каждом нажатии мышью будет создаваться несколько событий, но если просмотреть их, то вы сможете найти запрос, получающий нужную информацию.
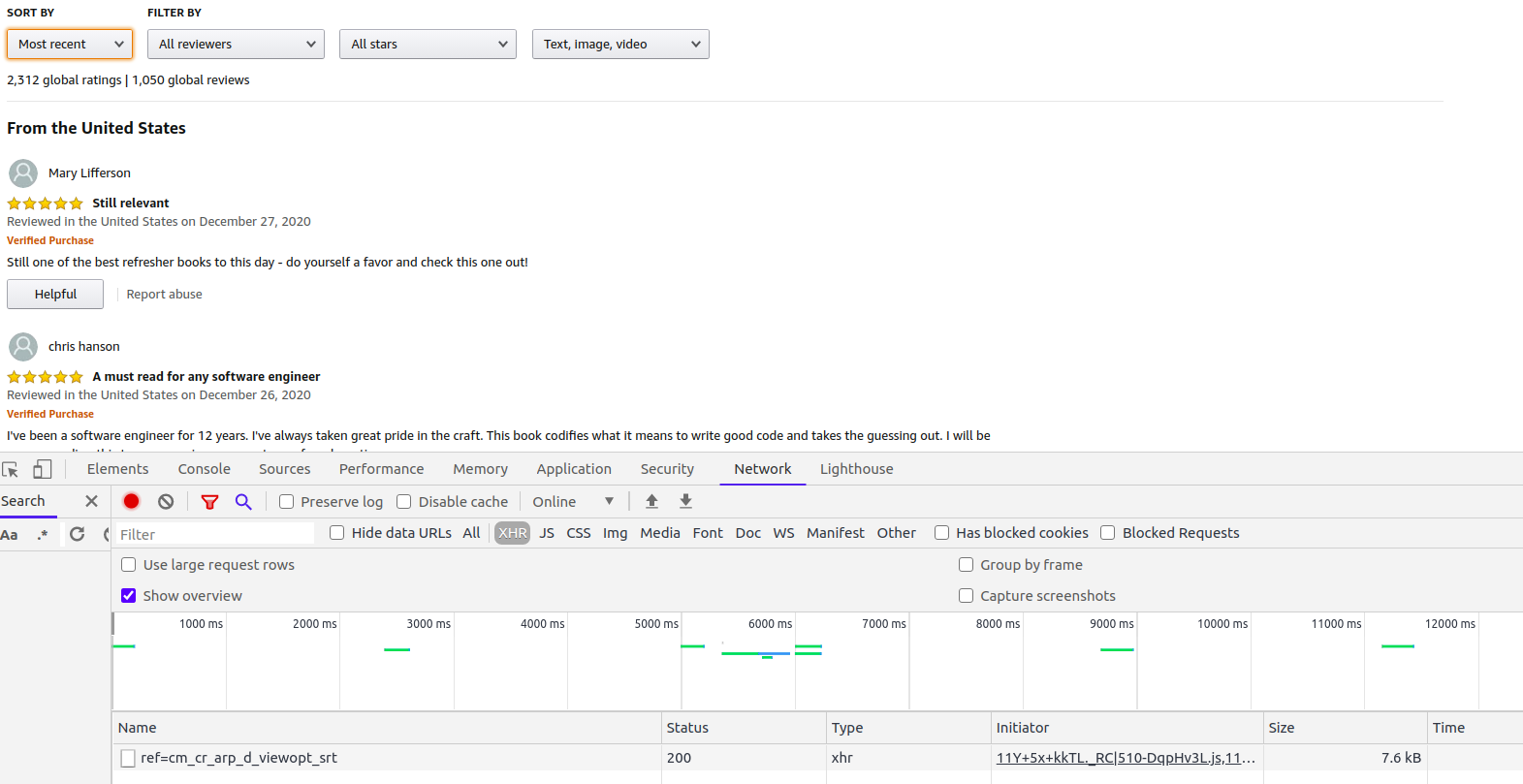
Следующим шагом будет переход на вкладку Response, чтобы понять, в каком формате принимаются обзоры.
Часто запросы бывают в читаемом формате JSON, который можно легко преобразовывать и хранить.
В других случаях, например, в нашем, всё чуть сложнее, но задача всё равно решаема.
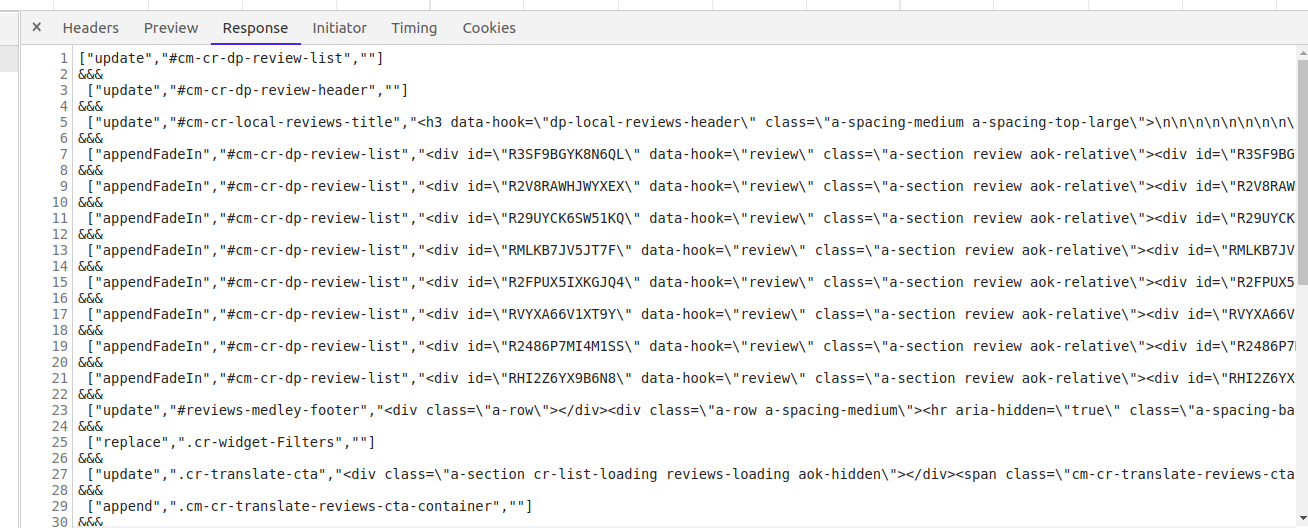
Этот формат непохож на HTML, JavaScript или JSON, но обладает очень понятным шаблоном. Позже я покажу, как мы можем использовать код на Python для его парсинга, несмотря на странность этого формата.
После первоначальной подготовки настала пора перейти к коду. Вы можете запросто писать код для запросов на любимом языке программирования.
Для экономии времени я люблю использовать удобный конвертер cURL. Сначала я копирую запрос как cURL, дважды щёлкнув на него и выбрав «Copy as cURL» (см. скриншот выше). Затем я вставляю его в конвертер, чтобы получить код на Python.
Примечание 1: Существует множество способов выполнения этого процесса, я просто считаю данный способ наиболее простым. Если вы просто создаёте запрос с использованными заголовками и атрибутами, то это вполне нормально.
Примечание 2: Когда я хочу поэкспериментировать с запросами, я импортирую команду cURL внутрь Postman, чтобы можно было поиграться с запросами и понять, как работает конечная точка. Но в этом руководстве я буду выполнять всё в коде.
import requests
import json
from bs4 import BeautifulSoup as Soup
import time
headers = {
'authority': 'www.amazon.com',
'dnt': '1',
'rtt': '250',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'content-type': 'application/x-www-form-urlencoded;charset=UTF-8',
'accept': 'text/html,*/*',
'x-requested-with': 'XMLHttpRequest',
'downlink': '6.45',
'ect': '4g',
'origin': 'https://www.amazon.com',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/product-reviews/0132350882/ref=cm_cr_arp_d_viewopt_srt?ie=UTF8&reviewerType=all_reviews&sortBy=recent&pageNumber=1',
}
post_data = {
'sortBy': 'recent',
'reviewerType': 'all_reviews',
'formatType': '',
'mediaType': '',
'filterByStar': '',
'pageNumber': '1',
'filterByLanguage': '',
'filterByKeyword': '',
'shouldAppend': 'undefined',
'deviceType': 'desktop',
'canShowIntHeader': 'undefined',
'reftag': 'cm_cr_getr_d_paging_btm_next_2',
'pageSize': '10',
'asin': '0132350882',
'scope': 'reviewsAjax1'
}
response = requests.post('https://www.amazon.com/hz/reviews-render/ajax/reviews/get/ref=cm_cr_arp_d_paging_btm_next_2',
headers=headers, data=post_data)Давайте разберём, что здесь происходит. Я взял заголовки и тело post из запроса в браузере. Удалил ненужные заголовки и сохранил те, благодаря которым запрос выглядит реальным. Самый важный заголовок, о котором никогда нельзя забывать — это
User-Agent. Без User-Agent ожидайте частого блокирования.В данных, передаваемых в запросе post, мы передаём язык, ID продукта, предпочтительную сортировку и пару других параметров, которые я на буду здесь объяснять. Легко понять, какой способ сортировки нужно передать, поиграв с фильтрами на странице продукта и изучив, как изменяется запрос. Пагинация проста, она задаёт
pageSize и pageNumber, назначение которых понятно из названий. Если пагинация непонятна, то можно поэкспериментировать со страницей и посмотреть, как меняются запросы.В данных post мы передаём большинство параметров в неизменном виде. Вот одни из самых важных параметров:
pageNumber: номер текущей страницыpageSize: количество результатов на страницуasin: ID продуктаsortBy: активный тип сортировки
Названия параметров
pageNumber и pageSize говорят сами за себя. Мы разберёмся, как работает сортировка, меняя её тип на реальной странице и наблюдая за изменениями запросов на вкладке Network. ID продукта (asin) можно найти в ссылке на страницу, он выделен жирным:https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882/#customerReviews
Чтобы понять, что делает каждый параметр в недокументированном API, нужно вызвать обновления страницы и понаблюдать за изменениями каждого из параметров.
Важное примечание о
pageSize: этот параметр позволяет нам снизить количество запросов, необходимых для получения нужной информации. Однако обычно никакой API не позволяет вводить произвольный размер страницы. Поэтому я начал с 10 и добрался до 20, после чего количество результатов перестало увеличиваться. То есть максимальный размер страницы равен 20, его мы и используем.Примечание: При использовании нестандартных размеров страниц вы упрощаете веб-сайту задачу вашей блокировки, поэтому будьте аккуратнее.
Следующий шаг — понять, как работает пагинация и циклическая передача запросов. Существует три основных способа обработки пагинации:
- Номер страницы: при таком способе в каждом запросе передаётся номер страницы,
1— первая страница,2— вторая, и т.д. - Смещение: смещения тоже часто используют. Если каждая страница содержит по десять результатов, то вторая страница будет иметь смещение на десять, а третья — смещение на двадцать, пока вы не достигнете конца результатов.
- Курсор: ещё один распространённый способ обработки пагинации — использование курсоров. У первой страницы его нет, но ответ на первый запрос даёт нам курсор для следующего запроса, пока мы не достигнем конца.
В нашем случае для прохождения по страницам до конца API использует номер страницы. Нам нужно понять, что сообщает о конце запросов, чтобы использовать эту информацию в своём цикле.
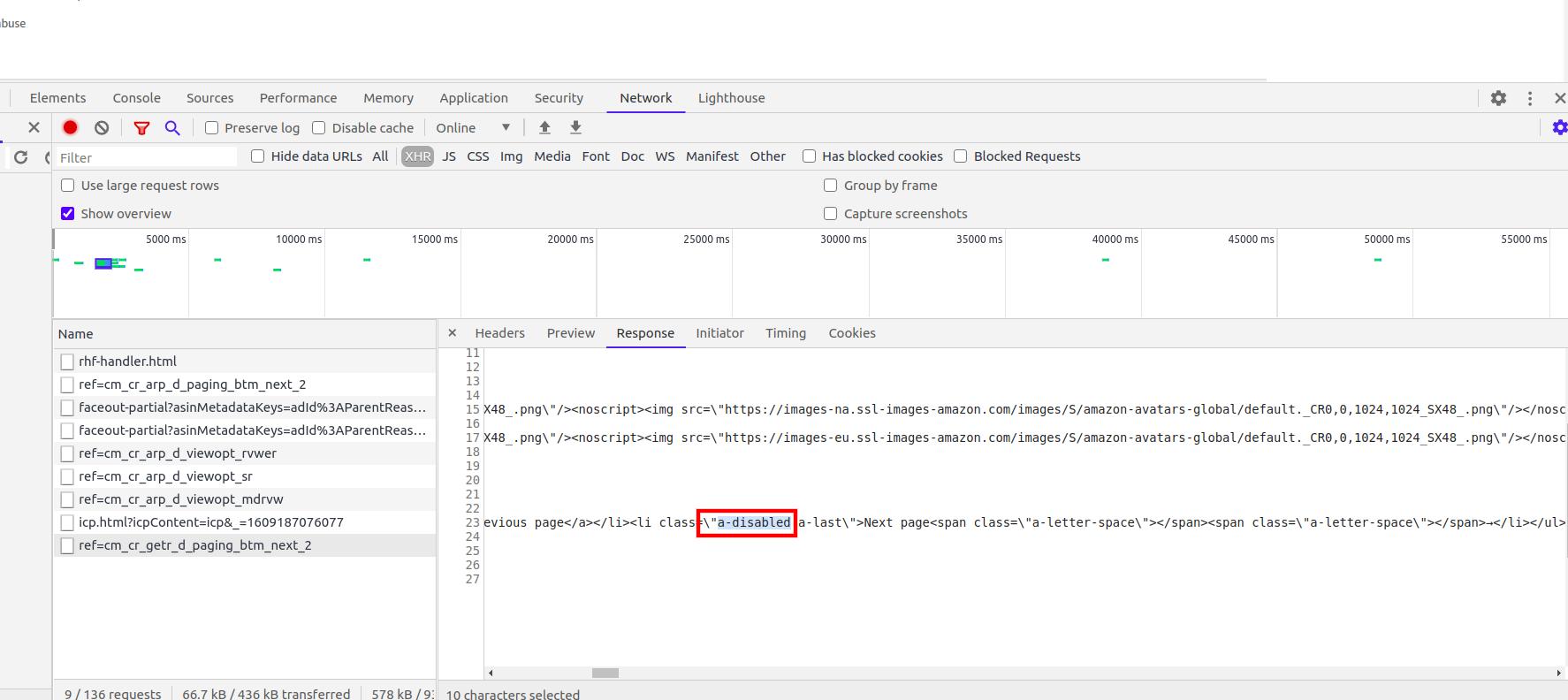
Для этого нам нужно добраться до последней страницы и посмотреть, что произойдёт. В нашем случае простым индикатором последней страницы является отключенная кнопка «Next Page», как видно на показанном ниже скриншоте. Мы запомним это, чтобы прерывать цикл при написании кода.
Теперь давайте пройдём по всем страницам и соберём информацию. Кроме того, я покажу, как парсить фрагменты HTML при помощи Beautiful Soup 4.
page = 1
reviews = []
while True:
post_data['pageNumber'] = page
response = requests.post('https://www.amazon.com/hz/reviews-render/ajax/reviews/get/ref=cm_cr_arp_d_paging_btm_next_2',
headers=headers, data=post_data)
data = response.content.decode('utf-8')
for line in data.splitlines():
try:
payload = json.loads(line)
html = Soup(payload[2], features="lxml")
# Stop scraping once we reach the last page
if html.select_one('.a-disabled.a-last'):
break
review = html.select_one('.a-section.review')
if not review:
# Skip unrelated sections
continue
reviews.append({
'stars': float(review.select_one('.review-rating').text.split(' out of ')[0]),
'text': review.select_one('.review-text.review-text-content').text.replace("\n\n", "").strip(),
'date': review.select_one('.review-date').text.split(' on ')[1],
'profile_name': review.select_one('.a-profile-name').text
})
except Exception as e:
pass
print(str(len(reviews)) + ' reviews have been fetched so far on page ' + str(page))
page += 1
time.sleep(2)Давайте разобьём этот код на части и посмотрим, что он делает:
# Мы каждый раз задаём новую страницу
post_data['pageNumber'] = page
# ...
# А в конце цикла увеличиваем счётчик страниц
page += 1Итак, нам нужно разделить строки, чтобы можно было их парсить. Изучив ответ API, можно понять, что каждая строка — это или массив, или строка, содержащая
&&&. Я решил воспользоваться принципом «лучше просить прощения, чем разрешения» и обернул каждый json.loads в блок try/except. Мы будем игнорировать строки &&& и сосредоточимся на тех, которые являются массивами JSON.Затем мы одну за другой обработаем каждую строку. Некоторые строки относятся к верхней и нижней частям страницы и не содержат обзоров, поэтому можно их спокойно пропустить. В конце нам нужно извлечь нужную информацию из самих обзоров:
# Загружаем строку как JSON
payload = json.loads(line)
# Парсим HTML с помощью Beautiful Soup
html = Soup(payload[2], features="lxml")
# Прекращаем скрапить, когда достигнем последней страницы
if html.select_one('.a-disabled.a-last'):
break
review = html.select_one('.a-section.review')
# Если раздел обзоров не найден, мы переходим к следующей строке
if not review:
continueТеперь настало время объяснить, как можно парсить тексты из HTML, для чего потребуется знание селекторов CSS и простейшей обработки.
reviews.append({
# Для получения количества звёзд мы разделяем текст, в котором, например, написано "1.0 out of 5" и просто сохраняем первое число
'stars': float(review.select_one('.review-rating').text.split(' out of ')[0]),
# Текст извлекается легко, но нам нужно избавиться от окружающих его новых строк и пробелов
'text': review.select_one('.review-text.review-text-content').text.replace("\n\n", "").strip(),
# Для получения даты нужно провести такое же простое разделение
'date': review.select_one('.review-date').text.split(' on ')[1],
# А имя профиля - это простой селектор
'profile_name': review.select_one('.a-profile-name').text
})Я не буду вдаваться в подробности, моя задача — объяснить процесс, а не конкретную реализацию с Beautiful Soup или Python. Этот процесс можно повторить на любом языке программирования.
Текущая версия кода обходит страницы и извлекает звёзды, имя профиля, дату и комментарий из каждого обзора. Каждый обзор хранится в списке, который можно сохранить или подвергнуть дальнейшей обработке. Поскольку скрапинг запросто в любой момент может прерваться, важно часто сохранять данные и обеспечить удобный перезапуск скраперов с места, где произошёл сбой.
Если бы это был реальный пример для работы, то нужно было бы добавить довольно много других аспектов:
- Использовать более надёжное решение для скрапинга (например, scrapy), поддерживающее паралелльные запросы, прокси, конвейеры обработки и сохранения данных, а также многое другое.
- Парсить даты, чтобы иметь стандартный формат.
- Извлекать все возможные элементы данных.
- Создать систему для запуска обновлений страниц и обновления данных.
Безголовые браузеры превосходно справляются с извлечением информации с веб-сайтов, но они очень тяжелы. Они более надёжны и с меньшей вероятностью сломаются, чем доступ к недокументированным API, однако иногда работа с этими публичными API намного быстрее и удобнее, например, в таких ситуациях:
- API меняется не слишком часто
- Вам нужны данные только один раз
- Скорость очень важна
- API предоставляет больше информации, чем сама страница
Существует множество веских причин применения API для веб-скрапинга. Можно даже сказать, что этот способ более уважителен к серверу, поскольку требует меньшего количества запросов и не обязывает загружать статические ресурсы.
Не забывайте скрапить с уважением — добавляйте задержки между запросами и минимально используйте параллельные запросы к одному домену. Цель веб-скрапинга — доступ к информации и её анализ, чтобы создать на её основе что-то полезное, а не вызвать проблемы и торможение серверов.
На правах рекламы
Серверы для парсинга или любых других задач на базе новейших процессоров AMD EPYC. Создавайте собственную конфигурацию виртуального сервера в пару кликов.




