
Когда вы сталкиваетесь с новой уязвимостью, какая мысль приходит первой? Конечно, отреагировать как можно быстрее. Однако, скорость — всего лишь одно из условий эффективной борьбы с ИБ-угрозами. Когда речь идет о корпоративной безопасности, не менее важно безошибочно определять, на что стоит реагировать в первую очередь. Недооцененная угроза может стать причиной серьезных убытков или потери деловой репутации. Но если число уязвимостей постоянно растет, как быстро оценить их значимость и не упустить важные детали?

Динамика числа уязвимостей по группам CVSS (источник — vulners.com)
Для ранжирования уязвимостей по различным критериям традиционно применяется шкала CVSS Score (Common Vulnerability Scoring System), ранжирующая уязвимости по различным критериям, от сложности эксплуатации до наносимого вреда и других параметров.
Казалось бы, зачем придумывать что-то еще — но у CVSS Score есть одно слабое место — она строится на экспертных оценках, не подкрепленных реальной статистикой. Гораздо эффективнее было бы предлагать экспертам уже отобранные по определенным количественным критериям кейсы и принимать решения на основании проверенных данных — но где взять эти данные и что с ними делать дальше? Звучит как необычная и интересная задача для датасаентиста – и именно этот вызов вдохновил меня и команду Vulners на новую концепцию оценки и классификацию уязвимостей на основе графа связанной информации.
Почему графы? В случае социальных сетей и СМИ графовые методы давно и успешно применяются для различных целей: от анализа распространения контента в новостном потоке, до заметок о влиянии ТОПовых авторов на мнение читателей и кластеризации социальной сети по интересам. Любая уязвимость может быть представлена как граф, содержащий данные — новости об изменениях в software или hardware и вызванных ими эффектах.
Мне не пришлось вручную собирать новости о каждом обновлении, все необходимые тексты нашлись в открытой базе уязвимостей vulners.com. Визуально данные выглядят следующим образом:
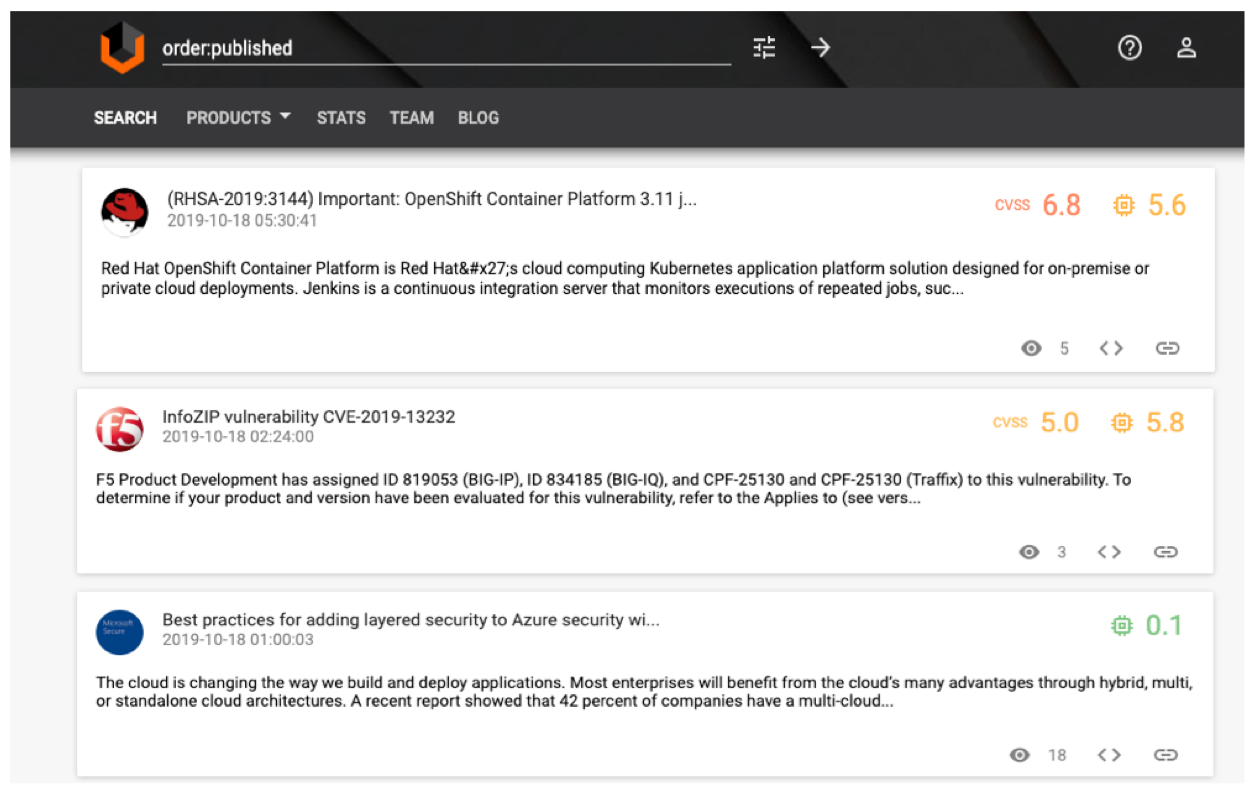
Каждая уязвимость, помимо названия, даты публикации и описания, имеет уже присвоенный ей тип (cve, nessus и пр.) семейство (NVD, scanner, exploit и пр.), оценку CVSS (здесь и далее используется CVSS v2), а также ссылки на связанные новости.
Если представить эти связи схематично в виде графа, то одна уязвимость будет выглядеть следующим образом: оранжевый кружок обозначает исходную или родительскую публикацию, черные кружки – новости, на которые можно кликнуть, находясь на родительской страничке, а серые кружки – связанные новости, добраться до которых можно только пройдя по всем публикациям, обозначенным черными кружками. Каждый цвет кружков – это новый уровень графа связанной информации, от нулевого – исходной уязвимости, до первого, второго и так далее.

Конечно, при просмотре одной новости нам известны только нулевой и первый уровень, поэтому для получения всех данных был использован метод обхода графа в глубину, позволяющий распутать клубок новостей от начала до самых последних связанных узлов (далее — нод графа). На этом этапе вылезли проблемы оптимизации — сборка графа за длительный период занимала большое время и пришлось поколдовать как со скриптом, так и структурой данных. Кстати, итоговые данные я решила упаковать в parquet для последующей работы с ними при помощи spark sql, что очень облегчило первичный анализ.
Как же выглядят графовые данные? Лучше всего понять их природу нам поможет визуализация. На рисунке 4 представлен граф известной, но не очень опасной уязвимости Heartbleed (всего 5 из 10 баллов по шкале cvss).
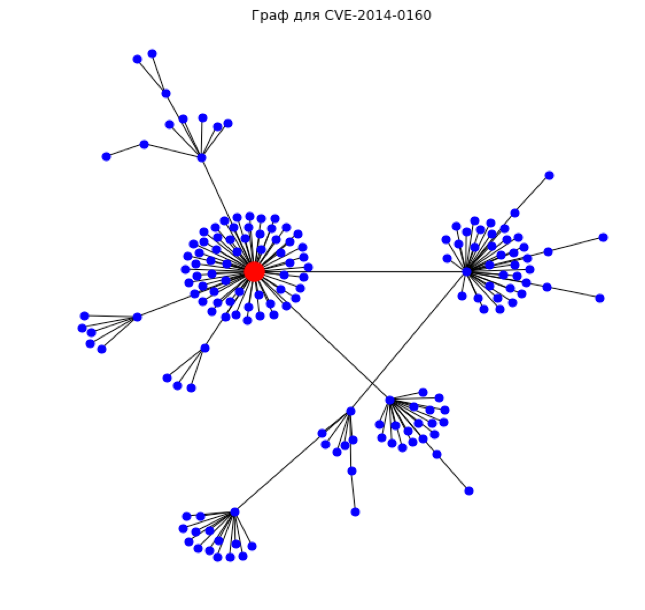
Глядя на этот пышный «букет» из связанных новостей и эксплойтов, где красная точка – исходная уязвимость, мы понимаем, что Heartbleed был существенно недооценен.
На этом примере можно сделать вывод о том, что системность, продолжительность и другие параметры уязвимости неплохо оцениваются при помощи графовых метрик. Ниже пару примеров метрик из исследования, которые послужили базой для альтернативной классификации:
Конечно, это не все метрики, под капотом исследования сейчас порядка 30 показателей, дополняющих базовый набор CVSS критериев, в том числе средний прирост между уровнями новостного графа уязвимости, доля эксплойтов на первом уровне графа и многое другое.
А теперь немного data science и статистики — ведь гипотезы нужно подтверждать на данных, не так ли?
Для эксперимента с альтернативной шкалой и новыми метриками были отобраны новости, опубликованные в январе 2019 года. Это 2403 бюллетеня и около 150 тысяч строк в графе новостей. Все исходные уязвимости были разделены на три группы по CVSS Score:
Для начала посмотрим, как CVSS-балл коррелирует с числом связанных новостей в графе, числом типов новостей и числом эксплойтов:
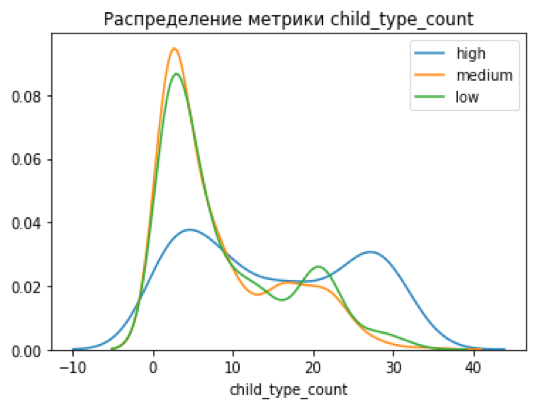
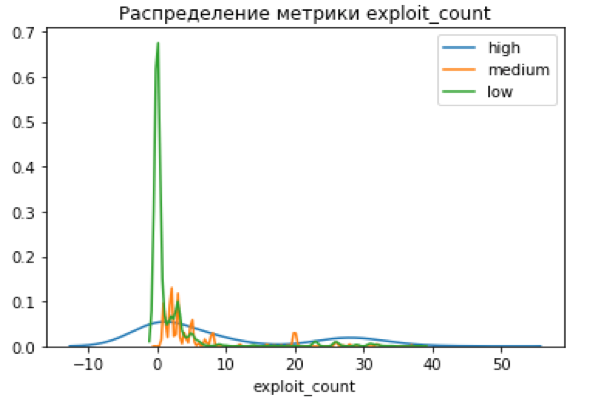
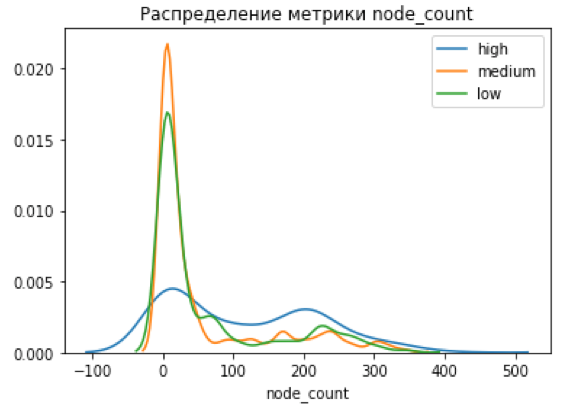
В идеальной картинке мы должны были увидеть четкое разделение метрик на три кластера, однако этого не произошло, что указало на возможное наличие серой зоны, которую CVSS Score не определяет – это и есть наша цель.
Следующим логичным шагом стала кластеризация уязвимостей в однородные группы и построение новой шкалы.
Для первой итерации был выбран простой метрический классификатор и k-means и получена новая матрица оценок: по оси У находятся исходные баллы (Medium, Low, High), по X, где 2 — максимально крупные по новым метрикам уязвимости, 1 — новые уязвимости, 0 — самые маленькие.

Зона, помеченная овалом (класс уязвимостей 2 с первоначальной оценкой low & medium) —потенциально недооцененные уязвимости. Разделение на новые классы тоже выглядит уже более четким, чего мы и добивались:
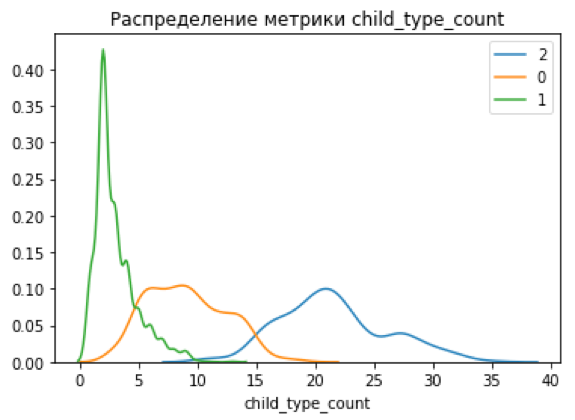
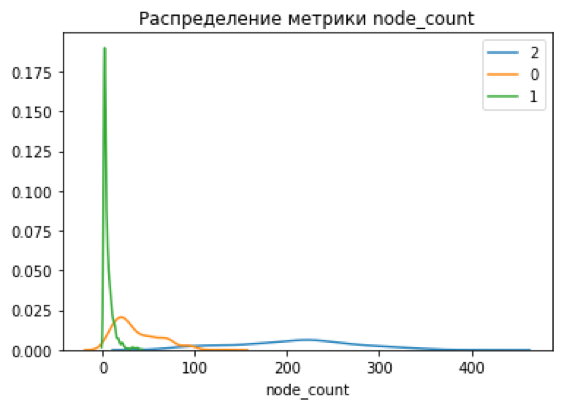
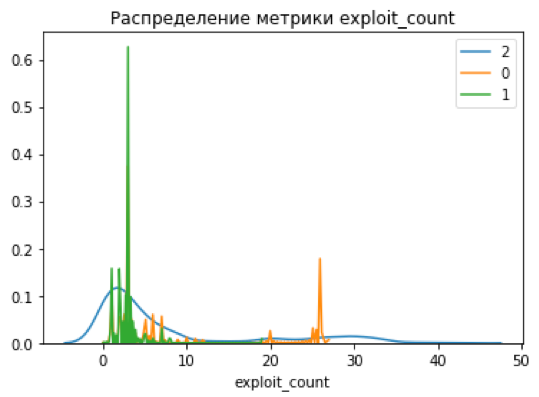
Однако, просто доверять модели — плохая идея, особенно, если речь идет об unsupervised кластеризации, где правильный ответ в принципе не известен, и полагаться можно лишь на метрики разделения полученных классов.
И именно тут нам потребуется знание эксперта — ведь для хорошей проверки и интерпретации результатов необходимо знание предметной области. Поэтому желательно точечно проверить модель, например, вытащив пару уязвимостей для детального анализа.
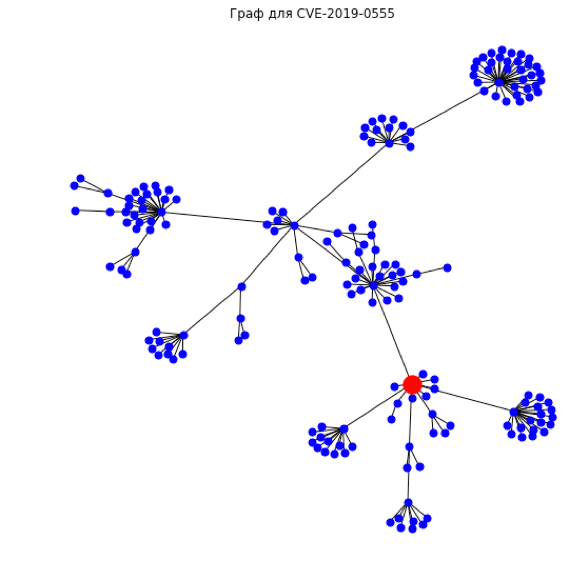
Ниже приведены несколько ярких образцов из серой зоны, имеющих низкий балл CVSS, но высокий графовый балл – а значит, потенциально требующих другого приоритета работы с ними. Вот как они выглядят в графовом представлении:
CVE-2019-0555 (CVSS балл 4.4, графовый класс 2 — high)

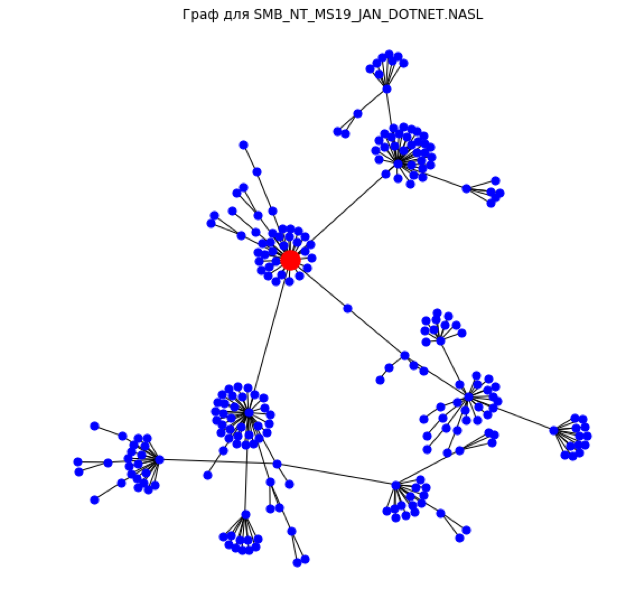
SMB_NT_MS19_JAN_DOTNET.NASL (CVSS балл 5.0, графовый класс 2 — high)

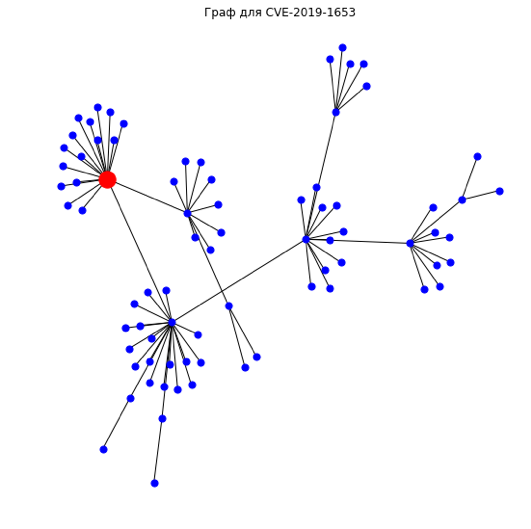
CVE-2019-1653 (CVSS балл 5.0, графовый класс 2 — high)

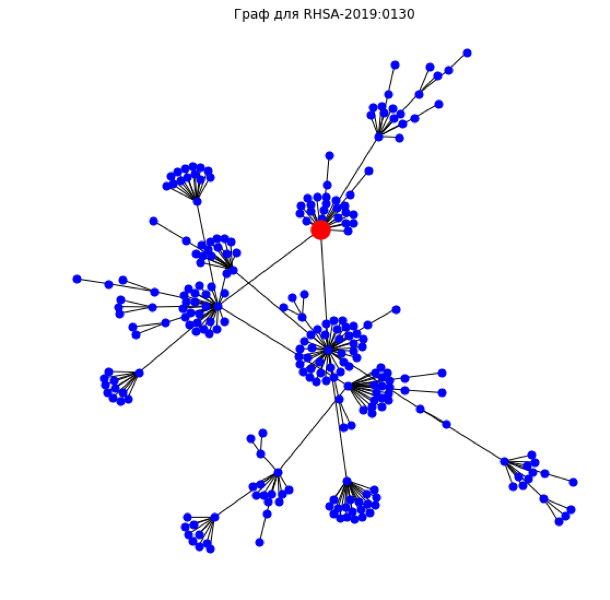
RHSA-2019:0130 (CVSS балл 5.0, графовый класс 2 — high)

Похоже, что концепция подтвердилась статистикой и точечной проверкой, поэтому в ближайшем будущем мы хотим доработать и автоматизировать сбор графовых метрик, и — возможно — сам классификатор. Конечно, предстоит еще очень много работы – от сбора огромного числа новых графов по неохваченным в исследовании месяцам, но это лишь добавляет энтузиазма, как и сама суть задачи. Как датасаентист могу сказать, что работа над этим исследованием была невероятно вдохновляющим опытом, как с точки зрения темы, так и сложности — даже подготовительная инженерная работа со слабо структурированными данными была очень интересна.
Как сделать шаг от экспертных оценок к реальным цифрам и оценить неоценимое?
После исследования стало ясно, что первую очередь, необходим критичный подход не только к любой метрике или данным, но и к процессу в целом, ведь мир слишком динамичен и меняется быстрее, чем методологии и документация. Всегда оценивали одним способом — почему бы и не попробовать сместить угол зрения? Как показывает наш пример, даже самые необычные гипотезы могут подтвердиться.
Немаловажную роль играет и доступность данных для датасаентистов – она позволяет быстро проверить самые смелые гипотезы и лучше понять суть вашей предметной области во всех ее проявлениях. Поэтому если вы еще не собираете или удаляете «ненужные» данные — подумайте, возможно там таится немало открытий. Этот кейс подсказывает, что data driven и information security отлично дополняют друг друга.
Динамика числа уязвимостей по группам CVSS (источник — vulners.com)
Для ранжирования уязвимостей по различным критериям традиционно применяется шкала CVSS Score (Common Vulnerability Scoring System), ранжирующая уязвимости по различным критериям, от сложности эксплуатации до наносимого вреда и других параметров.
Казалось бы, зачем придумывать что-то еще — но у CVSS Score есть одно слабое место — она строится на экспертных оценках, не подкрепленных реальной статистикой. Гораздо эффективнее было бы предлагать экспертам уже отобранные по определенным количественным критериям кейсы и принимать решения на основании проверенных данных — но где взять эти данные и что с ними делать дальше? Звучит как необычная и интересная задача для датасаентиста – и именно этот вызов вдохновил меня и команду Vulners на новую концепцию оценки и классификацию уязвимостей на основе графа связанной информации.
Почему графы? В случае социальных сетей и СМИ графовые методы давно и успешно применяются для различных целей: от анализа распространения контента в новостном потоке, до заметок о влиянии ТОПовых авторов на мнение читателей и кластеризации социальной сети по интересам. Любая уязвимость может быть представлена как граф, содержащий данные — новости об изменениях в software или hardware и вызванных ими эффектах.
О данных
Мне не пришлось вручную собирать новости о каждом обновлении, все необходимые тексты нашлись в открытой базе уязвимостей vulners.com. Визуально данные выглядят следующим образом:
Каждая уязвимость, помимо названия, даты публикации и описания, имеет уже присвоенный ей тип (cve, nessus и пр.) семейство (NVD, scanner, exploit и пр.), оценку CVSS (здесь и далее используется CVSS v2), а также ссылки на связанные новости.
Если представить эти связи схематично в виде графа, то одна уязвимость будет выглядеть следующим образом: оранжевый кружок обозначает исходную или родительскую публикацию, черные кружки – новости, на которые можно кликнуть, находясь на родительской страничке, а серые кружки – связанные новости, добраться до которых можно только пройдя по всем публикациям, обозначенным черными кружками. Каждый цвет кружков – это новый уровень графа связанной информации, от нулевого – исходной уязвимости, до первого, второго и так далее.
Конечно, при просмотре одной новости нам известны только нулевой и первый уровень, поэтому для получения всех данных был использован метод обхода графа в глубину, позволяющий распутать клубок новостей от начала до самых последних связанных узлов (далее — нод графа). На этом этапе вылезли проблемы оптимизации — сборка графа за длительный период занимала большое время и пришлось поколдовать как со скриптом, так и структурой данных. Кстати, итоговые данные я решила упаковать в parquet для последующей работы с ними при помощи spark sql, что очень облегчило первичный анализ.
Как же выглядят графовые данные? Лучше всего понять их природу нам поможет визуализация. На рисунке 4 представлен граф известной, но не очень опасной уязвимости Heartbleed (всего 5 из 10 баллов по шкале cvss).
Глядя на этот пышный «букет» из связанных новостей и эксплойтов, где красная точка – исходная уязвимость, мы понимаем, что Heartbleed был существенно недооценен.
На этом примере можно сделать вывод о том, что системность, продолжительность и другие параметры уязвимости неплохо оцениваются при помощи графовых метрик. Ниже пару примеров метрик из исследования, которые послужили базой для альтернативной классификации:
- число нод в графе — отвечает за «широту» уязвимости, насколько большой след она оставила в различных системах,
- число подграфов (крупных скоплений новостей) — отвечает за гранулярность проблемы или наличие крупных проблемных зон внутри уязвимости,
- число связанных эксплойтов и патчей — говорит о взрывоопасности новости и сколько раз ее приходилось «лечить»,
- количество уникальных типов и семейств новостей в графе — о системности, то есть числе подсистем, затронутых влиянием уязвимости,
- длительность от первой публикации до первого эксплойта, время от первой публикации до последней связанной новости — о темпоральной природе уязвимости, тянется ли он с большим «хвостом» последствий или быстро развивается и затухает.
Конечно, это не все метрики, под капотом исследования сейчас порядка 30 показателей, дополняющих базовый набор CVSS критериев, в том числе средний прирост между уровнями новостного графа уязвимости, доля эксплойтов на первом уровне графа и многое другое.
Открываем серую зону
А теперь немного data science и статистики — ведь гипотезы нужно подтверждать на данных, не так ли?
Для эксперимента с альтернативной шкалой и новыми метриками были отобраны новости, опубликованные в январе 2019 года. Это 2403 бюллетеня и около 150 тысяч строк в графе новостей. Все исходные уязвимости были разделены на три группы по CVSS Score:
- High — от 8 баллов включительно.
- Medium — от 6 включительно до 8 баллов.
- Low — менее 6 баллов.
Для начала посмотрим, как CVSS-балл коррелирует с числом связанных новостей в графе, числом типов новостей и числом эксплойтов:
В идеальной картинке мы должны были увидеть четкое разделение метрик на три кластера, однако этого не произошло, что указало на возможное наличие серой зоны, которую CVSS Score не определяет – это и есть наша цель.
Следующим логичным шагом стала кластеризация уязвимостей в однородные группы и построение новой шкалы.
Для первой итерации был выбран простой метрический классификатор и k-means и получена новая матрица оценок: по оси У находятся исходные баллы (Medium, Low, High), по X, где 2 — максимально крупные по новым метрикам уязвимости, 1 — новые уязвимости, 0 — самые маленькие.
Зона, помеченная овалом (класс уязвимостей 2 с первоначальной оценкой low & medium) —потенциально недооцененные уязвимости. Разделение на новые классы тоже выглядит уже более четким, чего мы и добивались:
Однако, просто доверять модели — плохая идея, особенно, если речь идет об unsupervised кластеризации, где правильный ответ в принципе не известен, и полагаться можно лишь на метрики разделения полученных классов.
И именно тут нам потребуется знание эксперта — ведь для хорошей проверки и интерпретации результатов необходимо знание предметной области. Поэтому желательно точечно проверить модель, например, вытащив пару уязвимостей для детального анализа.
Ниже приведены несколько ярких образцов из серой зоны, имеющих низкий балл CVSS, но высокий графовый балл – а значит, потенциально требующих другого приоритета работы с ними. Вот как они выглядят в графовом представлении:
CVE-2019-0555 (CVSS балл 4.4, графовый класс 2 — high)
SMB_NT_MS19_JAN_DOTNET.NASL (CVSS балл 5.0, графовый класс 2 — high)
CVE-2019-1653 (CVSS балл 5.0, графовый класс 2 — high)
RHSA-2019:0130 (CVSS балл 5.0, графовый класс 2 — high)
Похоже, что концепция подтвердилась статистикой и точечной проверкой, поэтому в ближайшем будущем мы хотим доработать и автоматизировать сбор графовых метрик, и — возможно — сам классификатор. Конечно, предстоит еще очень много работы – от сбора огромного числа новых графов по неохваченным в исследовании месяцам, но это лишь добавляет энтузиазма, как и сама суть задачи. Как датасаентист могу сказать, что работа над этим исследованием была невероятно вдохновляющим опытом, как с точки зрения темы, так и сложности — даже подготовительная инженерная работа со слабо структурированными данными была очень интересна.
В заключение
Как сделать шаг от экспертных оценок к реальным цифрам и оценить неоценимое?
После исследования стало ясно, что первую очередь, необходим критичный подход не только к любой метрике или данным, но и к процессу в целом, ведь мир слишком динамичен и меняется быстрее, чем методологии и документация. Всегда оценивали одним способом — почему бы и не попробовать сместить угол зрения? Как показывает наш пример, даже самые необычные гипотезы могут подтвердиться.
Немаловажную роль играет и доступность данных для датасаентистов – она позволяет быстро проверить самые смелые гипотезы и лучше понять суть вашей предметной области во всех ее проявлениях. Поэтому если вы еще не собираете или удаляете «ненужные» данные — подумайте, возможно там таится немало открытий. Этот кейс подсказывает, что data driven и information security отлично дополняют друг друга.
")


