
Михаил Коновалов, руководитель направления отдела сопровождения интеграционных проектов ИТ-дирекции МКБ
День добрый, хабровчане!
Систематизированный подход к управлению загрузками. Мы хотим рассказать, как упорядочить и автоматизировать наполнение хранилища информацией, и при этом не запутаться в потоках из различных источников.
В корпоративной базе данных любой компании рано или поздно наступает такой момент, когда она разрастается до размеров, что глаз архитектора перестает улавливать неопределенность (хаос) системы, и превращается в неуправляемую массу всевозможных загрузок из различных источников.
Вам повезло, если ваша система разрабатывалась с нуля (с первой таблицы) и велась одним архитектором, одной командой разработчиков и аналитиков. И к тому же этот архитектор грамотно вел модель хранилища данных. Но жизнь многогранна, в большинстве случаев DWH вырастает спонтанно, сначала было 30 таблиц, потом по мере необходимости добавили еще чуть-чуть, а потом «нам понравилось» и мы стали добавлять по каждому удобному случаю, и теперь у нас больше пяти тысяч, да еще появились слои, стейджинги и витрины. И все это «счастье» на нас свалилось в результате одного, но очень удобного процесса, представляющего собой жесткую причинно-следственную связь:
Но, как правило, последний пункт в реальности не существует. А появляется только в определенный момент в больших компаниях, которые доросли до своего DWH, где аккуратный архитектор грамотно управляет целостностью информации в базе данных. Такие хранилища представляют собой review предыдущей структуры, которое было заново задокументировано, а чаще заново построено с оглядкой на предыдущую (не документированную) версию.
Итак, кратенькое резюме:
Если вы являетесь счастливым обладателем «правильной» DWH, или входите в команду этого счастливого обладателя, вам эта статья «в теории», возможно, покажется интересной. А если вам только предстоит пройти review, или (упаси вас) rebuild, то эта статья, сможет сильно облегчить жизнь.
Так как источников информации может быть невообразимое количество, то и потоков загрузки и перегрузки разных объектов, минимум, столько же, а зачастую гораздо больше, так как каждый объект БД может проходить не одну трансформацию, прежде чем его данные могут быть использованы конечным пользователем для построения бизнес-отчетов. А ведь именно для него, для бизнеса, а не ради собственного удовольствия построена вся эта экосистема по «переливанию из сосуда в сосуд».
В качестве БД нашего хранилища используется Oracle. Когда-то, на стадии создания, центральное ядро нашей БД состояло из пары сотен таблиц. Мы и не думали о стейджингах и витринах. Но, как говорится, «все течет, все меняется», и теперь мы выросли! Бизнес диктует новые требования, и уже появилась интеграция с различными базами MS SQL, SyBASE, Vertica, Access. Откуда только не стекается к нам информация, даже появилась такая экзотика как XML и JSON-обмен со сторонними системами, и уж совсем анахронизм XLS-файл как источник информации.
Жизнь заставила нас пройти review и актуализировать модель данных, вести ее и поддерживать. Вот так выглядит одна из частей основного ядра:
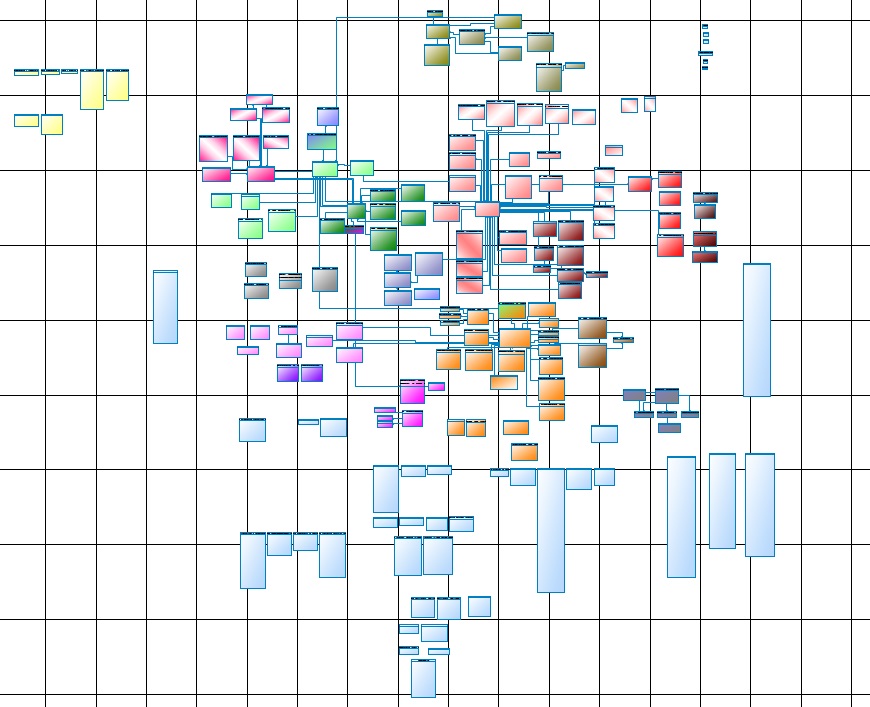
Рис. 1
Кому как, а по мне – это читаемо только на ватмане, причем A0 будет маловат, лучше 4A0, на экране это – ни глазу, ни воображению не поддается.
Теперь вспомним, что это только ядро (Core Data Layer), точнее его основная часть, полное ядро состоит из нескольких подсистем, которые не сильно уступают основной. Еще к этому добавляется Primary Data Layer и Data Mart Layer. Дальше – больше, первичный слой получает свою информацию из источников данных, а это, как уже говорилось выше, различные БД и файлы. С другой стороны, к слою витрин, потребителем стыкуются различные системы отчетности.
На первых порах, когда таблиц БД было немного и алгоритмы загрузки были реализованы на PL/SQL, особых сложностей в понимании обновления данных не вызывало. Но с ростом DWH, стратегически важным решением стало покупка Informatica PowerCenter. При всем удобстве этого инструмента, как в смысле надежности загрузки, так и визуализации разработки, этот инструмент имеет ряд недостатков. На рисунке ниже, представлена модель последовательности запуска загрузки DWH.
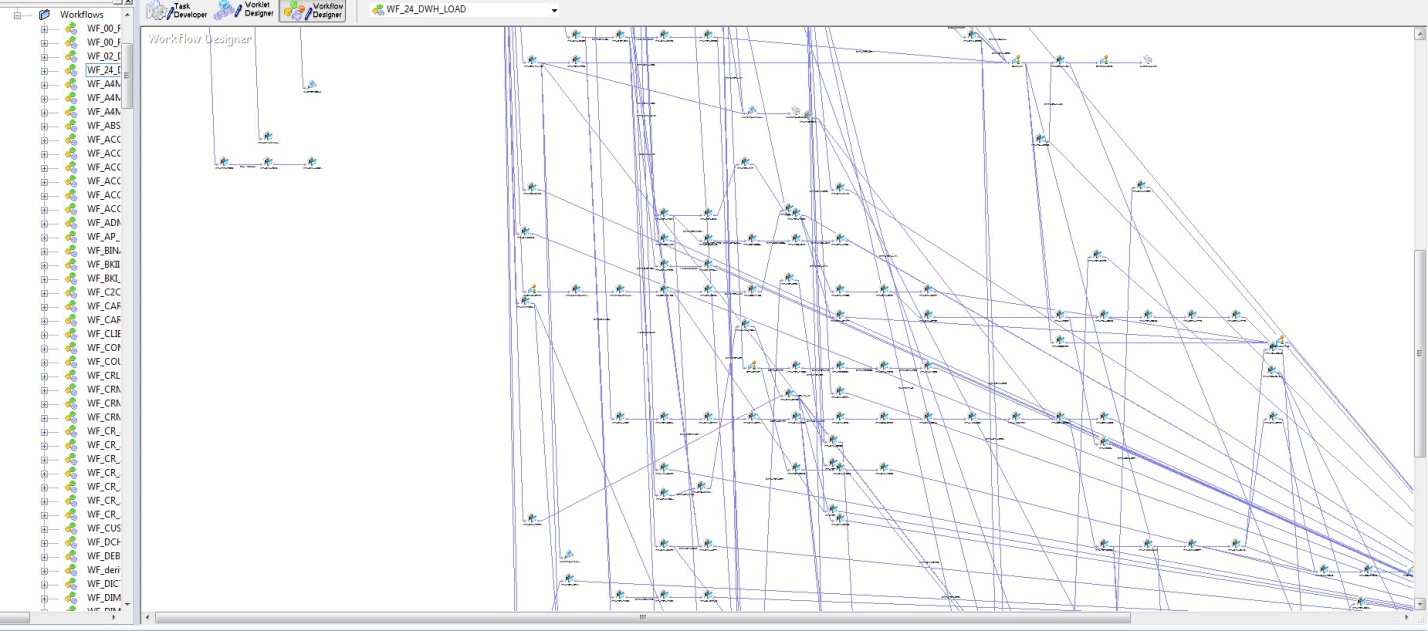
Рис. 2
Самый главный недостаток – это субъективность, точнее только архитектор может дать гарантию, что проводки не грузятся раньше счетов. К сожалению, с ростом DWH растет и энтропия информации. С учетом физической модели данных (рис. 1) и логикой загрузки этих данных (рис. 2) конструкция получается та еще.
Что делать и как этим рулить, спросите вы. Естественно: иметь гениального архитектора, который способен разобраться во всех связях этих хитросплетений. Который будет следить за всеми потоками, согласовывать новые потоки, и не допускать, чтобы таблица проводок грузилась раньше таблицы счетов. Конечно, все это вшивается в алгоритмы и регулируется в процесс отсечками загрузок, но изначально только архитектор может понять и задать загрузкам строгую последовательность, а при такой разветвленности вероятность ошибиться весьма высока.
Теперь я постараюсь изложить основные мысли словаря модели данных, а так же какие задачи он решает.
Так как данные в хранилище находятся в таблицах, а источниками данных являются частично таблицы, а частично представления, последние сами представляют собой таблицы. То отсюда вытекает простая идея – создать структуру зависимостей TABLE–TABLE. Форма 3NF как нельзя лучше для этого подходит.
Во-первых, наполнение данными сущности DWH, называем их (target), в самом общем случае можно представить в виде select из разных таблиц. Будут ли это таблицы Oracle, SyBase, MSSQL, xls-файлы или еще что-нибудь, не так уж и важно, все это, называем их источники (source). То есть у нас есть source, который перетекает в target.
Во-вторых, у каждой сущности DWH есть зависимости между собой references.
В-третьих, есть хронология старта загрузок различных сущностей DWH.
Осталось дело за малым, реализовать – как? Казалось бы, очень просто, с основания вашего DWH, архитектор при появлении очередной таблицы сущности (target) должен посмотреть и занести в словарь сущность приемник и все сущности, которые служат источниками. Далее, во второй таблице словаря задать связки между этими сущностями источниками в select, а также все подчиненные таблицы который связаны references. Далее можно загрузку этой сущности встроить в цепочку загрузок хранилища. Всего две таблицы – и возможность учета в алгоритме последовательности наполнения хранилища данными решена.
Словарь модели данных позволит решить следующие задачи:
В теории всегда все просто и красиво, на практике дела обстоят несколько иначе. То что написано в предыдущем разделе, есть идеальная ситуация, когда DWH развивалось с нуля, когда при ней неотлучно находился архитектор. Если вам не повезло, все это вы «благополучно» миновали, архитектора нет, а есть гигантский набор таблиц, то все равно, выход есть.
Теперь, собственно, расскажу, как мы сумели наверстать упущенное и сделать review и rebuild достаточно дешево. Наше DWH начало развиваться с решения руководства о ого (DWH) назревшей необходимости. В качестве инструмента сначала использовался PL/SQL. Немного позже переключились на Informatica. Естественно, в приоритете были сроки создания. Модель данных в PowerDesigner появилась спустя некоторое время, к тому моменту, когда четко сформировалась уверенность, что уже никто четко не представляет себе полной и ясной картины DWH. С моделью на стене мы прожили еще какое-то время, когда стало ясно, что мы не справляемся с управлением всей этой системы, стали искать решение, которое вкратце постараюсь здесь описать.
Сам словарь модели данных прост как палка. Но заполнить его – это проблема. N-месяцев кропотливого, а самое главное, внимательного учета трех вышеизложенных частей:
К счастью нам в помощь Oracle и Informatica, а так же очень удачно оказалось, что репозиторий Informatica находится в базе Oracle. Взяв за основу, что один Informatica Session – это атом загрузки какой-либо сущности DWH, покопавшись немного в репозитории, мы нашил все source и target. То есть в рамках одного Session, для всех его target (как правило, он один) источниками являются все его source. Тем самым мы может заполнить первое условие задачи. Но не спешите радоваться, source может быть представлен в виде очень навороченного select, таким образом, пришлось писать парсер, который вытаскивает все таблицы указанные в select, – это было вовсе не сложно. Но и это еще не все, сами эти таблицы могут быть на самом деле представлениями. С помощью DBA_VIEWS (либо через DBA_DEPENDENCIES) этот вопрос был тоже решен. Второе условие этой трилогии мы вытащили из модели данных (рис. 1) и DBA_CONSTRAINTS. Третье условие мы также получили из репозитория Informatica исходя из (рис. 2).
Что же из всего этого получилось?
Возможно, у вас найдется еще масса способов применения словаря модели данных.
Всем спасибо!
День добрый, хабровчане!
Цель
Систематизированный подход к управлению загрузками. Мы хотим рассказать, как упорядочить и автоматизировать наполнение хранилища информацией, и при этом не запутаться в потоках из различных источников.
Преамбула
В корпоративной базе данных любой компании рано или поздно наступает такой момент, когда она разрастается до размеров, что глаз архитектора перестает улавливать неопределенность (хаос) системы, и превращается в неуправляемую массу всевозможных загрузок из различных источников.
Вам повезло, если ваша система разрабатывалась с нуля (с первой таблицы) и велась одним архитектором, одной командой разработчиков и аналитиков. И к тому же этот архитектор грамотно вел модель хранилища данных. Но жизнь многогранна, в большинстве случаев DWH вырастает спонтанно, сначала было 30 таблиц, потом по мере необходимости добавили еще чуть-чуть, а потом «нам понравилось» и мы стали добавлять по каждому удобному случаю, и теперь у нас больше пяти тысяч, да еще появились слои, стейджинги и витрины. И все это «счастье» на нас свалилось в результате одного, но очень удобного процесса, представляющего собой жесткую причинно-следственную связь:
- бизнес говорит: «У нас есть потребность вот в таких-то данных. Нужен новый отчет»
- аналитик ищет
- разработчик реализует
- архитектор согласовывает и вносит в модель данных
Но, как правило, последний пункт в реальности не существует. А появляется только в определенный момент в больших компаниях, которые доросли до своего DWH, где аккуратный архитектор грамотно управляет целостностью информации в базе данных. Такие хранилища представляют собой review предыдущей структуры, которое было заново задокументировано, а чаще заново построено с оглядкой на предыдущую (не документированную) версию.
Итак, кратенькое резюме:
- не существует DWH, которое родилось сразу и ранее не представляло собой обычную БД с набором таблиц;
- все, что существует сейчас, и представляет собой четко алгоритмизированную и документированную структуру, получено в результате «горького опыта» предыдущих наработок.
Если вы являетесь счастливым обладателем «правильной» DWH, или входите в команду этого счастливого обладателя, вам эта статья «в теории», возможно, покажется интересной. А если вам только предстоит пройти review, или (упаси вас) rebuild, то эта статья, сможет сильно облегчить жизнь.
Так как источников информации может быть невообразимое количество, то и потоков загрузки и перегрузки разных объектов, минимум, столько же, а зачастую гораздо больше, так как каждый объект БД может проходить не одну трансформацию, прежде чем его данные могут быть использованы конечным пользователем для построения бизнес-отчетов. А ведь именно для него, для бизнеса, а не ради собственного удовольствия построена вся эта экосистема по «переливанию из сосуда в сосуд».
В качестве БД нашего хранилища используется Oracle. Когда-то, на стадии создания, центральное ядро нашей БД состояло из пары сотен таблиц. Мы и не думали о стейджингах и витринах. Но, как говорится, «все течет, все меняется», и теперь мы выросли! Бизнес диктует новые требования, и уже появилась интеграция с различными базами MS SQL, SyBASE, Vertica, Access. Откуда только не стекается к нам информация, даже появилась такая экзотика как XML и JSON-обмен со сторонними системами, и уж совсем анахронизм XLS-файл как источник информации.
Жизнь заставила нас пройти review и актуализировать модель данных, вести ее и поддерживать. Вот так выглядит одна из частей основного ядра:
Рис. 1
Кому как, а по мне – это читаемо только на ватмане, причем A0 будет маловат, лучше 4A0, на экране это – ни глазу, ни воображению не поддается.
Теперь вспомним, что это только ядро (Core Data Layer), точнее его основная часть, полное ядро состоит из нескольких подсистем, которые не сильно уступают основной. Еще к этому добавляется Primary Data Layer и Data Mart Layer. Дальше – больше, первичный слой получает свою информацию из источников данных, а это, как уже говорилось выше, различные БД и файлы. С другой стороны, к слою витрин, потребителем стыкуются различные системы отчетности.
На первых порах, когда таблиц БД было немного и алгоритмы загрузки были реализованы на PL/SQL, особых сложностей в понимании обновления данных не вызывало. Но с ростом DWH, стратегически важным решением стало покупка Informatica PowerCenter. При всем удобстве этого инструмента, как в смысле надежности загрузки, так и визуализации разработки, этот инструмент имеет ряд недостатков. На рисунке ниже, представлена модель последовательности запуска загрузки DWH.
Рис. 2
Самый главный недостаток – это субъективность, точнее только архитектор может дать гарантию, что проводки не грузятся раньше счетов. К сожалению, с ростом DWH растет и энтропия информации. С учетом физической модели данных (рис. 1) и логикой загрузки этих данных (рис. 2) конструкция получается та еще.
Что делать и как этим рулить, спросите вы. Естественно: иметь гениального архитектора, который способен разобраться во всех связях этих хитросплетений. Который будет следить за всеми потоками, согласовывать новые потоки, и не допускать, чтобы таблица проводок грузилась раньше таблицы счетов. Конечно, все это вшивается в алгоритмы и регулируется в процесс отсечками загрузок, но изначально только архитектор может понять и задать загрузкам строгую последовательность, а при такой разветвленности вероятность ошибиться весьма высока.
Теория
Теперь я постараюсь изложить основные мысли словаря модели данных, а так же какие задачи он решает.
Так как данные в хранилище находятся в таблицах, а источниками данных являются частично таблицы, а частично представления, последние сами представляют собой таблицы. То отсюда вытекает простая идея – создать структуру зависимостей TABLE–TABLE. Форма 3NF как нельзя лучше для этого подходит.
Во-первых, наполнение данными сущности DWH, называем их (target), в самом общем случае можно представить в виде select из разных таблиц. Будут ли это таблицы Oracle, SyBase, MSSQL, xls-файлы или еще что-нибудь, не так уж и важно, все это, называем их источники (source). То есть у нас есть source, который перетекает в target.
Во-вторых, у каждой сущности DWH есть зависимости между собой references.
В-третьих, есть хронология старта загрузок различных сущностей DWH.
Осталось дело за малым, реализовать – как? Казалось бы, очень просто, с основания вашего DWH, архитектор при появлении очередной таблицы сущности (target) должен посмотреть и занести в словарь сущность приемник и все сущности, которые служат источниками. Далее, во второй таблице словаря задать связки между этими сущностями источниками в select, а также все подчиненные таблицы который связаны references. Далее можно загрузку этой сущности встроить в цепочку загрузок хранилища. Всего две таблицы – и возможность учета в алгоритме последовательности наполнения хранилища данными решена.
Словарь модели данных позволит решить следующие задачи:
- Просмотр зависимостей. Можно смотреть какие данные, откуда тянутся. Это удобно для аналитиков, которые вечно мучаются вопросами: «где, что лежит и откуда все берется». Представить это в приложении в виде дерева, причем как от source к target, так и наоборот: от target к source.
- Разрыв петель. При встраивании очередной загрузки в уже работающий общий поток, не имея словаря модели данных вполне можно ошибиться и назначить время старта загрузки очередного target впереди одного из его source. При этом возникает петля. Словарь модели данных легко позволит избежать этого.
- Можно написать алгоритм наполнения хранилища с учетом словаря модели. В этом случае вообще пропадает необходимость встраивать куда-либо очередную загрузку, достаточно ее отразить в словаре и алгоритм сам определит ему место. Останется нажать на вожделенную кнопку «Сделать ВСЕ». Загрузчик лавинообразно будет запускать загрузки всех сущностей хранилища – от простых (независимых) к сложным (зависимым).
Реализация
В теории всегда все просто и красиво, на практике дела обстоят несколько иначе. То что написано в предыдущем разделе, есть идеальная ситуация, когда DWH развивалось с нуля, когда при ней неотлучно находился архитектор. Если вам не повезло, все это вы «благополучно» миновали, архитектора нет, а есть гигантский набор таблиц, то все равно, выход есть.
Теперь, собственно, расскажу, как мы сумели наверстать упущенное и сделать review и rebuild достаточно дешево. Наше DWH начало развиваться с решения руководства о ого (DWH) назревшей необходимости. В качестве инструмента сначала использовался PL/SQL. Немного позже переключились на Informatica. Естественно, в приоритете были сроки создания. Модель данных в PowerDesigner появилась спустя некоторое время, к тому моменту, когда четко сформировалась уверенность, что уже никто четко не представляет себе полной и ясной картины DWH. С моделью на стене мы прожили еще какое-то время, когда стало ясно, что мы не справляемся с управлением всей этой системы, стали искать решение, которое вкратце постараюсь здесь описать.
Сам словарь модели данных прост как палка. Но заполнить его – это проблема. N-месяцев кропотливого, а самое главное, внимательного учета трех вышеизложенных частей:
- из каких источников (source) состоит каждая сущность хранилища (target);
- какие взаимоотношения между объектами хранилища (references);
- хронология старта загрузок и наполнения хранилища.
К счастью нам в помощь Oracle и Informatica, а так же очень удачно оказалось, что репозиторий Informatica находится в базе Oracle. Взяв за основу, что один Informatica Session – это атом загрузки какой-либо сущности DWH, покопавшись немного в репозитории, мы нашил все source и target. То есть в рамках одного Session, для всех его target (как правило, он один) источниками являются все его source. Тем самым мы может заполнить первое условие задачи. Но не спешите радоваться, source может быть представлен в виде очень навороченного select, таким образом, пришлось писать парсер, который вытаскивает все таблицы указанные в select, – это было вовсе не сложно. Но и это еще не все, сами эти таблицы могут быть на самом деле представлениями. С помощью DBA_VIEWS (либо через DBA_DEPENDENCIES) этот вопрос был тоже решен. Второе условие этой трилогии мы вытащили из модели данных (рис. 1) и DBA_CONSTRAINTS. Третье условие мы также получили из репозитория Informatica исходя из (рис. 2).
Что же из всего этого получилось?
- Во-первых, мы распутали все петли, которые сумели накрутить в процессе эволюции нашего DWH.
- Во-вторых, получили замечательное дерево для аналитиков:

Рис. 3 - В-третьих, наш суперзагрузчик, представленный на рис. 2 превратился в элегантный (простите, коллеги, но размытость картинки – намеренная, так как это рабочие данные):
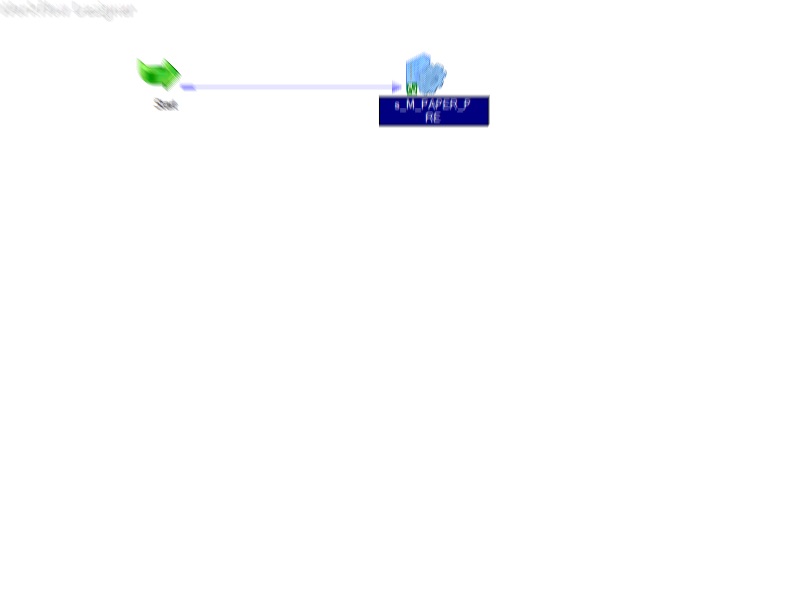
Рис. 4
Возможно, у вас найдется еще масса способов применения словаря модели данных.
Всем спасибо!




