Эта статья – дистиллят моих разведочных исследований о смещении в датасетах. В ней я расскажу, что такое смещение и как оно влияет на работу модели. А еще – о том, как мы воспринимаем результаты работы модели и какие есть подходы для борьбы со смещением. Детальнее расскажу о двух способах избавления от него.
Смещение в датасетах (артефакты) – нежелательные взаимосвязи между входными и выходными данными, в частности, между признаками и метками, которые могут эксплуатироваться моделями машинного обучения в качестве опоры при предсказании. Часто они возникают там, где совсем не ожидаешь.
Простой пример смещения можно представить следующим образом: нам нужно определить оскорбительные посты в социальной сети. Высока вероятность, что оскорбительные посты будут содержать нецензурные слова и модель будет опираться на них при принятии решения. Некоторые пользователи могут использовать нецензурные слова и в обычных, нейтральных постах. Те же нецензурные слова могут быть использованы и для выражения позитивных эмоций. В результате, модель, обученная на датасете, в котором мало других примеров: нейтральных или позитивных, будет считать пост оскорбительным, когда в нем есть нецензурные слова. Если тестирование модели провести на похожей тестовой выборке, где нецензурные слова представлены только в оскорбительных постах, то тест подтвердит высокое качество модели. При реальном использовании эта модель будет давать ложно положительные срабатывания. Из-за смещения складывается ложное чувство, что модель работает хорошо, но это происходит ровно до того, как она начинает использоваться в реальности.
Можно посмотреть на эту проблему с другого ракурса. Всем бы хотелось иметь натренированную на определенном количестве данных модель, которую можно было бы использовать везде с высоким качеством работы. При составлении датасета все возможные случаи учесть невозможно, поэтому мы опираемся на способность моделей к генерализации – обобщению опыта, – чтобы делать предсказания на неизвестных данных.
Области, ограниченные какой-то особенностью, называют доменами. Например, медицинским доменом назовут датасет, который содержит медицинские тексты. Использование модели внутри домена называется in-domain, а за его пределами – out-of-domain. Часто получается, что модели хорошо работают внутри домена, но плохо вне его. Это происходит из-за смещения модели в сторону домена, на котором она обучалась, относительно теоретического общего домена, который покрывал бы все возможные варианты.
Пример: модель обучили на комментариях пользователей в социальных сетях, она не учитывает лингвистические особенности языка как глубокие признаки и опирается на словарь. Такая модель будет работать плохо для задачи по классификации научных статей. Минимизация смещения позволяет добиться качественной работы модели при ее обучении на конкретном датасете и, как следствие, лучшей ее генерализации.
В теории сейчас нет строгой классификации факторов, влияющих на появление смещения. На мой взгляд, есть несколько причин появления смещения в данных:
Разметчики – при разметке люди могут руководствоваться внутренними шаблонами, пропуская важные отличительные детали в данных. Часто люди сами склонны формировать предвзятые, то есть смещенные, мнения [11].
Отсутствие баланса – если в датасете примеров одного класса значительно больше, чем другого, то модель, скорее всего, выучится именно на мажорном классе, не принимая во внимание признаки минорного.
Нерепрезентативность – ситуация, когда в датасете слабо представлены разные случаи. Яркий пример, представленный выше, – с нецензурными словами. Это означает, что в датасете появляется перекос в сторону какого-то класса по определенному признаку.
Неправильный режим обучения – косвенный фактор, при котором смещение проявляется, когда модель недообучается.
Отсутствие негативного множества - частный случай нерепрезентативности, при котором в датасете слабо представлено то, чем классифицированное явление не является.
Есть один показательный пример того, как запросы людей "смещают" поисковую выдачу Гугла, но он 18+, поэтому можете сами поочередно ввести в Гугле две фразы, лежащие под спойлером, и сравнить выдачу.
18+
mother teaches daughter
мать учит дочь
Существует несколько способов борьбы со смещением, они отличаются по вектору направления:
удаление части примеров, которые отражают смещение;
ручная или автоматическая идентификация смещения и построение модели с его учетом;
создание датасетов с механизмами подавления смещений [3], [4];
исправление датасетов путем добавления примеров, уменьшающих влияние смещения [1], [2].
В процессе исследований я рассмотрел детально первый и обзорно второй способы, про них и расскажу. Чтобы познакомиться с оставшимися методами, рекомендую прочитать статьи по ссылкам.
Удаление части примеров, которые отражают смещение
В эту категорию попадает алгоритм AFLite (Adversarial Filtering), предложенный в работе исследователей из AI2 [5]. Алгоритм отбирает примеры, среди которых может быть высокий процент разнообразия. Это уменьшает вероятность нахождения признака, по которому легко можно было бы «решить» эти данные. Ниже – иллюстрация из статьи, хорошо отражающая эту идею.

Слева расположены примеры, которые были выбраны алгоритмом из датасета ImageNet, а справа – те, которые были отброшены. Под серией из пяти картинок, принадлежащих одному классу, представлена тепловая карта косинусной близости по признакам из модели EfficientNet-B7. Слева картинки имеют низкую взаимную похожесть, поэтому здесь можно говорить о большем разнообразии, чем справа.
Задача алгоритма AFLite – найти такое подмножество датасета, обучаясь на котором не должно получиться так, что по какому-то одному признаку или очень маленькому их множеству, игнорируя остальное, модель выучится давать верные предсказания.
Для лучшего понимания проблемы, представьте, что в большинстве датасетов есть область в пространстве признаков, для которой существует очень много примеров, и есть области для которых примеров существенно меньше. Представить это можно в виде Гаусовского колокола. В таком датасете получается серьезный перекос в сторону «головы» распределения, в то время как «хвостовые» примеры остаются не у дел. Модель учится в первую очередь использовать те признаки, где распределение примеров больше. Более того, при тестировании выборка, взятая из того же датасета, может унаследовать это свойство, создав ложное впечатление, что модель хорошо обучилась. AFLite сглаживает колокол, позволяя подтянуть хвосты и приспустить голову. Стоит отметить, что алгоритм является универсальным - его можно применять к любым типам данных, которые можно представить в виде матрицы признаков.
Ключевая идея AFLite заключается в следующей процедуре:
Разбить исходный датасет несколько раз на train/test.
На каждом разбиении натренировать модель (линейная регрессия, SVM, и др.), а результат тестирования – верно был классифицирован пример или нет – занести в память для каждого примера из тестовой выборки.
После того, как проделали это несколько раз, посчитать так называемую оценку предсказуемости (predictability score) для каждого примера. Она считается как отношение числа раз, когда пример был предсказан верно, к общему числу предсказаний.
После этого нужно выбрать k таких примеров, чей результат выше заданного порога, и выбросить их из датасета. Если столько примеров не набралось, то остановить процесс, если набралось – начать сначала. Описание алгоритма в виде псевдокода доступно в оригинальной статье.
Оценка предсказуместь является ключевой точкой в этом алгоритме. Интуиция здесь такая - раз пример можно постоянно верно предсказать, обучаясь на разных подвыборках, значит он является довольно общим для всего датасета и его можно удалить, не теряя репрезентативности.
Код алгоритма представлен ниже
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from collections import defaultdict
from tqdm.auto import tqdm
import numpy as np
def aflite(features: np.array, labels: np.array, n_partitions=20, upper_bound=5000, train_size=0.7, slice_num=200, predictability_treshold=0.8):
while features.shape[0] > upper_bound:
acc = defaultdict(list)
for _ in tqdm(range(n_partitions)):
x_tr, x_ts, y_tr, y_ts = train_test_split(features, labels, train_size=train_size)
lr = LogisticRegression()
lr.fit(x_tr, y_tr)
predicts = lr.predict(x_ts)
for i, pred, true in zip(range(y_ts.shape[0]), predicts, y_ts):
acc[i].append(1 if pred == true else 0)
removing_list = []
for idx, predictions in acc.items():
predictability_score = sum(predictions)/len(predictions)
if predictability_score > predictability_treshold:
removing_list.append((predictability_score, idx))
removing_list.sort(key=lambda x: x[0], )
removing_list = [x[1] for x in removing_list]
if len(removing_list) > slice_num:
removing_list = removing_list[:slice_num]
else:
print("Removing instances are not enough")
break
mask = np.ones(features.shape[0], dtype=bool)
mask[removing_list] = False
features = features[mask]
labels = labels[mask]
print("Dataset size remainig {}/{}".format(features.shape[0], upper_bound))
if features.shape[0] < train_size:
print("Dataset is less then required training size")
break
return features, labelsгде
features - матрица признаков, например, эмбеддинги бертоподобной модели, word2vec, TfIdf матрица и т.д.
labels - вектор меток размерности

n_partitions - количество раундов разбиения
upper_bound - сколько примеров должно остаться
train_size - пропорция (если значение меньше единицы) или количество (если больше единицы) тренировочных данных в раунде
slice_num - сколько примеров выбрасывать за проход
predictability_trashold - порог оценки предсказуемости
По окончанию работы, алгоритм выдаст фильтрованную матрицу признаков и соответствующий вектор меток.
Алгоритм был протестирован в соответствии с протоколом эксперимента на синтетических данных, предоставленных авторами. На картинке ниже вы можете видеть, как выглядит один из искусственных датасетов

К этому датасету были добавлены два признака, в каждом признаке 75 процентов значений были семплированы из разных нормальных распределений, а остальные семплированы из равномерного распределения. Таким обзорам получалось, что каждый признак ассоциируется с конкретным классом. Детально это можно посмотреть на парном графике ниже.
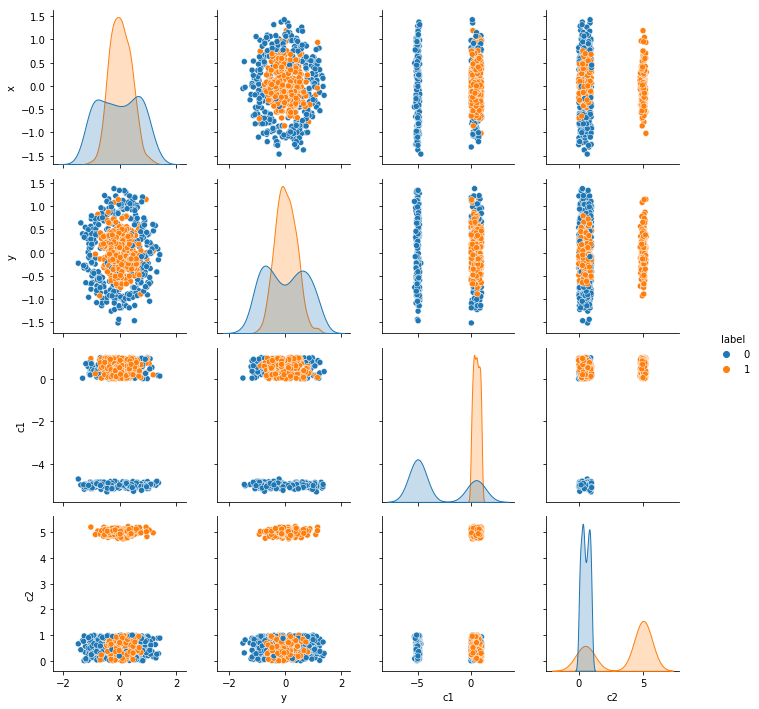
После применения AFLite датасет выглядит следующим образом. Здесь хорошо видно, что по сути AFLite прореживает данные.
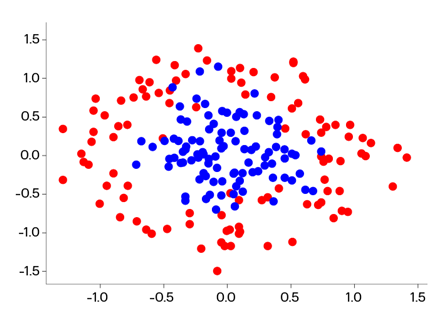
Логика эксперимента следующая. По форме датасета видно, что зависимость у него нелинейная и линейная модель точно не справится с такими данными, зато хорошо справится алгоритм SVM с радиальным ядром. Однако добавление признаков, которые четко ассоциируются с конкретным классом, ведет к тому, что линейная модель может запросто их использовать для успешного предсказания. Тогда, если AFLite обладает качеством удаления смещенных примеров, результирующий датасет станет сложным для линейной модели, но выполнимым для SVM. Ниже представлены результаты эксперимента
lr_first | 0.82 |
svm_first | 0.88 |
lr_abl | 0.83 |
svm_abl | 0.84 |
lr_filt | 0.50 |
svm_filt | 0.90 |
dataset_remaining_size | 200.00 |
Первые две строки демонстрируют точности моделей на исходном датасете со смещенными признаками. Следующие две строки показывают результаты моделей, которые обучены на случайной подвыборке, равной количеству оставшихся после фильтрации примеров (dataset_remaining_size). И следующие две строчки показывают точность моделей, обученных на фильтрованных примерах. Мы четко можем видеть, что линейная модель показала себя значительно хуже, когда SVM даже немного прибавила в точности.
Если задуматься, то складывается довольно странная картина. С одной стороны, всегда на вопрос: «Сколько нужно данных для обучения?» отвечают: «Чем больше, тем лучше». С другой стороны, в этой работе говорится о том, что для получения неискаженного результата, необходимо количество данных сократить. В одном из своих экспериментов на реальных данных (датасет SNLI) авторы показывают, что dev-точность модели RoBERTa падает с 92.6% до 62.6% (на 30%) при использовании фильтрованного датасета по сравнению с исходным. При этом датасет сократился на 458 тысяч из 550 тысяч примеров, оставив таким образом 92 тысячи. Показательно, что модель, обученная на случайной подвыборке в 92 тысячи примеров, показала точность в 88.3 процента. Подобные результаты уже не дают так буквально воспринимать совет выше и действительно заставляют задуматься о качественном составе данных.
Ручная или автоматические идентификация смещения и построение модели с его учетом
При ручной идентификации смещения проводится анализ различных характеристик датасета: количество токенов на метку, сложность синтаксиса, сентиментальная поляризация, распределение н-грам, отдельных слов и т.д. В этом случае смещение будет выражаться как сильный перекос конкретного признака в сторону какого-то класса. Пример такого анализа есть в статье [6], а более детально можно посмотреть в презентации [7]. Далее по этим признакам строят модель, которая делает предсказания, основываясь на таких «скошенных» признаках.
Примером ручной идентификации может слуджить работа [12], в которой были показаны некоторые артефакты в SNLI, такие как:
добавление because к предпосылке, ведущее к тому, что пример предсказывается как нейтральный;
добавление not или never к предпосылке, ведущее к тому, что пример предсказывается как противоречие.
В случае автоматической идентификации предлагается использовать большие модели типа BERTa, поскольку исследования показывают, что они в первую очередь опираются на легко усваиваемые признаки, а не на сложные глубокие взаимосвязи, что звучит вполне логично. Это явление называется rapid surface learning. Полагается, что различные смещения – это простые взаимосвязи и сеть их выучит в первую очередь. Для достижения этого эффекта нужно обучать модель в специальном режиме: на маленьком подмножестве основного датасета несколько эпох.
Имея такую модель смещения, можно пойти двумя путями: учесть предсказания смещенной модели в функции потерь или обучить модель с помощью подхода product-of-experts, при котором мы комбинируем выходы обеих моделей так, что уверенность предсказания смещенной модели определяет какое влияние пример будет иметь на обучение основной модели.
Общую интуицию подходов можно резюмировать следующим образом. Так как у нас есть модель, которая отвечает за смещение, подобные зависимости не будут перетекать в новую модель. Предполагается, что новая модель станет местом сосредоточения глубоких знаний о природе задачи. [8][9].
Есть еще один интересный подход, который предлагается в статье [10]. Авторы работы занимались QA: задача – обучить модель, которая содержала бы в себе знания нескольких датасетов, и давала хорошие результаты на in-domain и out-of-domain. Интересная особенность этого подхода в том, что он может показать, как распределены смещения по примерам.
Общая последовательность действий выглядит следующим образом:
Обучить на каждом датасете по модели;
Обучить множество смещенных моделей;
Взвесить примеры с учетом смещения в них по методу, описанному в статье;
Дистиллировать модели из пункта 1 в одну с помощью функции потерь, которая учитывает смещение.
Графическое представление – на изображении:

Заключение
Тема смещения в данных набирает обороты в последние годы. Я считаю это направление очень важным, так как оно приближает нас к пониманию того, как следует собирать данные, чтобы достичь максимальной генерализации. Это свойство, теоретически, можно считать ключевым для моделей машинного обучения. За время написания этой статьи появились новые данные, которые показывают, что здесь представлена лишь вершина айсберга. Впереди – тернистый путь проб и ошибок до конечной цели – эффективной оценки качества датасетов.
Ссылки
[1] Matt Gardner et al., Evaluating nlp models via contrast sets, 2020
[2] Divyansh Kaushik et al., Learning the difference that makes a difference with counterfactually-augmented data, 2019
[3] Yixin Nie et al., Adversarial nli: A new benchmark for natural language understanding, 2019
[4] Rowan Zellers et al., Swag: A large-scale adversarial dataset for grounded commonsense inference, 2018
[5] Ronan Le Bras et al., Adversarial Filters of Dataset Biases, 2020
[6] Rishi Sharma et al., Tackling the Story Ending Biases in The Story Cloze Test, 2018
[7] Rishi Sharma et al., Tackling the Biases in the Story Cloze Test Endings, 2018
[8] Rabeeh Karimi Mahabadi et al., End-to-End Bias Mitigation by Modelling Biases in Corpora, 2020
[9] Prasetya Ajie Utama et al., Towards Debiasing NLU Models from Unknown Biases, 2020
[10] Mingzhu Wu et al., Improving QA Generalization by Concurrent Modeling of Multiple Biases, 2020
[11] Дэвид Майерс, Социальная психология, 7-е издание, 2020
[12] Adam Poliak et al., Hypothesis Only Baselines in Natural Language Inference, 2018




