
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

1-го апреля завершился финал SNA Hackathon 2019, участники которого соревновались в сортировке ленты социальной сети с использованием современных технологий машинного обучения, компьютерного зрения, обработки тестов и рекомендательных систем. Жесткий онлайн отбор и двое суток напряженной работы над 160 гигабайтами данных не прошли даром :). Рассказываем о том, что помогло участникам прийти к успеху и о других интересных наблюдениях.
О данных и задаче
На конкурс были представлены данные механизмов подготовки ленты пользователей социальной сети OK, состоящие из трех частей:
- логи показов контента в лентах пользователей с большим количеством признаков, описывающих пользователя, контент, автора и другие свойства;
- тексты, связанные с показанным контентом;
- тела картинок, использованных в контенте.
Суммарный объем данных превышает 160 гигабайт, из них более 3-х приходится на логи, еще 3 на тексты и остальное на картинки. Большой объем данных не испугал участников: по статистике ML Bootcamp в конкурсе приняло участие почти 200 человек, отправивших более 3000 сабмитов, а самые активные сумели пробить планку в 100 отправленных решений. Возможно, их мотивировал к этому и призовой фонд в 700 000 рублей + 3 видеокарты GTX 2080 Ti.

Участникам конкурса необходимо было решить задачу сортировки ленты: для каждого отдельного пользователя отсортировать показанные объекты таким образом, что те, которые получили отметку "Класс!", находились ближе к голове списка.
В качестве метрики оценки качества использовалась ROC-AUC. При этом метрика считалась не по всем данным в целом, а отдельно для каждого пользователя и затем усреднялась. Этот вариант расчета примечателен тем, что алгоритмы, научившиеся выделять ставящих много классов пользователей, не получают преимущества. С другой стороны, такого варианта работы нет в стандартных пакетах Python, что вскрыло некоторые интересные моменты, о чем ниже.
О технологиях
Традиционно SNA Hackathon это не только алгоритмы, но и технологии — объем отгруженных данных превышает 160 гигабайт, что ставит участников перед интересными техническими задачами.
Parquet vs. CSV
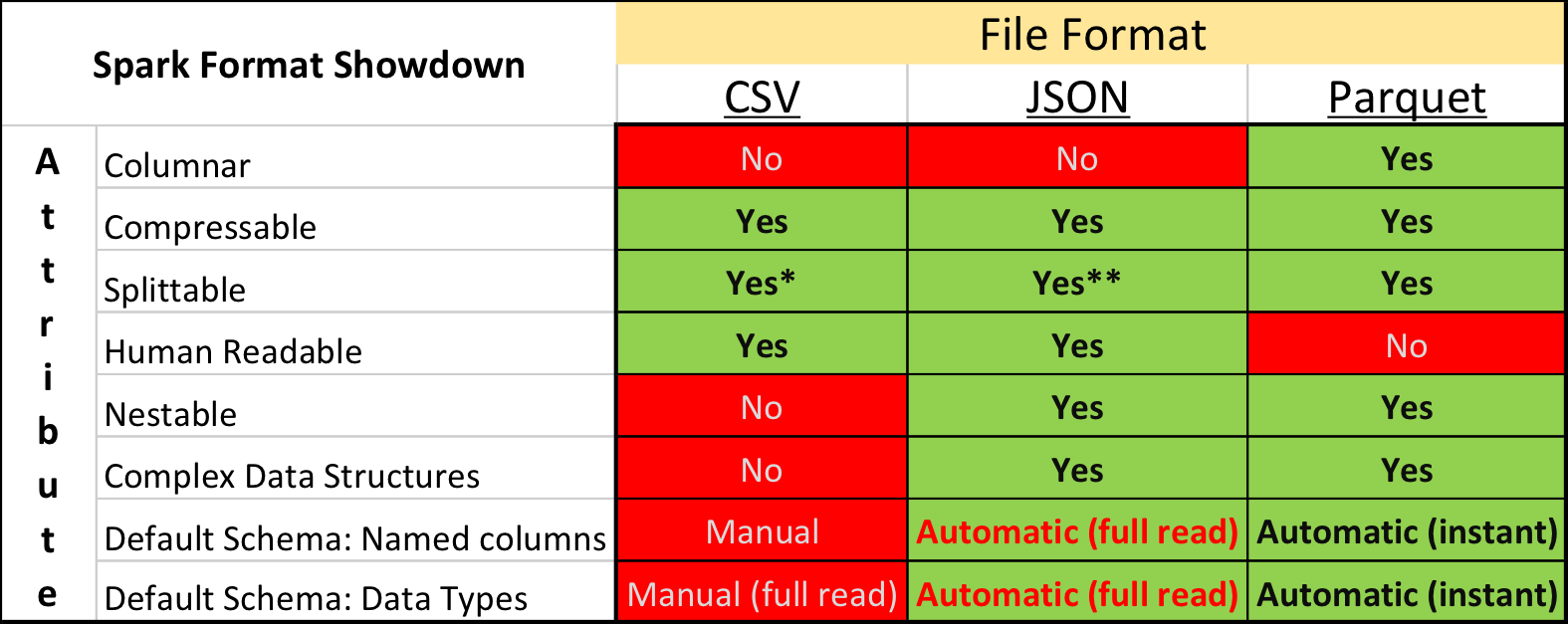
В академических исследования и на Kaggle доминирующим форматом данных является CSV, а также другие форматы с "открытым текстом". Однако в индустрии ситуация несколько иная – существенно большей компактности и скорости обработки можно добится используя "бинарные" форматы хранения.
В частности, в экосистеме построенной на базе Apache Spark, наибольшей популярностью пользуется Apache Parquet — колоночный формат хранения данных с поддержкой многих важных для эксплуатации возможностей:
- явно специфицированной схемой с поддержкой эволюции;
- чтением только нужных колонок с диска;
- базовой поддержкой индексов и фильтров при чтении;
- поколоночным сжатием.
Но несмотря на наличие очевидных преимуществ, предоставление данных на конкурс в формате Apache Parquet встретило жесткую критику со стороны некоторых участников. Помимо консерватизма и нежелания тратить время на освоение чего-то нового было и несколько действительно неприятных моментов.
Во-первых поддержка формата в библиотеке Apache Arrow, основного средства для работы с Parquet из Python, пока далека от совершенства. Все структурные поля при подготовке данных пришлось развернуть до плоских, и все равно при чтении текстов многие участники столкнулись с багом и вынуждены были устанавливать старую версию библиотеки 0.11.1 вместо актуальной на тот момент 0.12. Во-вторых в Parquet-файл не заглянешь с помощью простых консольных утилит: cat, less и т.д. Однако, этот недостаток относительно легко компенсировать используя пакет parquet-tools.
Тем не менее те, кто изначально пытался конвертировать все данные в CSV, чтобы затем работать в привычной среде, в конце концов отказались от этой идеи – все-таки Parquet работает ощутимо быстрее.
Бустинг и ГПУ

На конференции SmartData в Санкт-Петербурге «широко известный в узких кругах» Алексей Натёкин сравнивал производительность нескольких популярных инструментов для бустинга при работе на CPU/GPU и пришел к выводу что ощутимого выигрыша GPU не дает. Но уже тогда этот вывод привел к активной полемике, в первую очередь с разработчиками отечественного инструмента CatBoost.
За прошедшие два года прогресс в развитии GPU и адаптации алгоритмов не стоял на месте и финал SNA Hackathon можно считать триумфом пары CatBoost+GPU — все победители использовали именно её и вытягивали метрику в первую очередь за счет возможности вырастить больше деревьев за единицу времени.
Свой вклад в высокий результат решений на базе CatBoost внес и интегрированный вариант реализации mean target encoding, но количество и глубина деревьев давали более существенный прирост.
В похожем направлении движутся и другие инструменты бустинга, добавляя и совершенствуя поддержку GPU. Так что, grow more trees!
Spark vs. PySpark

Инструмент Apache Spark прочно занимает лидирующие позиции в индустриальном Data Science, в том числе и благодаря наличию API для Python. Тем не менее, использование Python сопряжено с дополнительными накладными расходами на интеграцию между разными средами выполнения и работу интерпретатора.
Само по себе это не является проблемой, если пользователь отдает себе отчет в том, к какому объему дополнительных расходов приводит то или иное действие. Однако, оказалось, что очень многие не осознают масштабов проблемы — несмотря на то, что участники не использовали Apache Spark, дискуссии на тему Python vs. Scala возникали в чате хакатона регулярно, что привело к появлению соответствующего поста с разбором.
Если кратко, то замедление от использования Spark через Python по сравнению с использованием Spark через Scala/Java можно разбить на следующие уровни:
- используется только Spark SQL API без User Defined Functions (UDF) — в этом случае накладные расходы практически отсутствуют, так как весь план выполнения запроса вычисляется в рамках JVM;
- используется UDF на Python без вызова пакетов с C++ кодом — в этом случае производительность этапа, на котором вычисляется UDF, падает в 7-10 раз;
- используется UDF на Python с обращением к C++ пакету (numpy, sklearn и т.д.) — в этом случае производительность падает в 10-50 раз.
Отчасти негативный эффект можно компенсировать используя PyPy (JIT для Python) и векторизированные UDF, однако и в этих случаях разница производительности кратная, а сложность реализации и развертывания идет дополнительным "бонусом".
Об алгоритмах
Но самое интересное на Data Science-хакатонах это, конечно, не технологии, а новые модные и старые проверенные алгоритмы. В этом году на SNA Hackathon тотально доминировал CatBoost, но было и несколько альтернативных подходов. О них и поговорим :).
Дифференцируемые графы

Одна из первых публикаций решений по итогам отборочного тура была посвещана отнють не деревьям, а дифференцируемым графам (так же именуемым искуственными нейронными сетями). Автор является сотрудником ОК, поэтому может позволить себе не гнаться за призами, а получать удовольствие строя перспективное решение на базе цельного математического фундамента.
Основная идея предложенного решения заключалась в том, чтобы построить единый вычислительный дифференцируемый граф, переводящий имеющиеся признаки в прогноз, учитывающий различные аспекты входных данных:
- эмбединги объектов и пользователей позволяют позволяют добавить элемент классических коллаборативных рекомендаций;
- переход от скалярного произведения эмбедингов к аггрегации через MLP позволяет добавлять произвольные признаки;
- query-key-value attention позволил модели динамически адаптироваться к поведению даже незнакомого ранее пользователя глядя на его недавнюю историю.
Эта модель очень хорошо показала себя на онлайн-отборе в решении задачи рекомендации текстового контента, поэтому сразу несколько команд попытались воспроизвести её на финале, однако, к успеху не пришли. Отчасти это было связано с тем, что для этого нужны время и опыт, а отчасти от того, что количество признаков в финале было значительно больше и методы на базе деревьев получили за счет них существенное преимущество.
Коллаборативная доминанта

Конечно при организации конкурса мы знали о том, что в логах есть достаточно сильный сигнал, ведь собранные там признаки отражают существенную часть проделанной в ОК работы по ранжированию ленты. Тем не менее до самого конца надеялись, что у участников получится справится с "проклятием третьего знака" — ситуации когда огромные человеческие и машинные ресурсы вкладываемые в разработку модели извлечения признаков из контента (текстов и фото) выливаются в крайне скромные приросты качества по сравнению с уже подготовленными, преимущественно коллаборативными, признаками.
Зная об этой проблеме мы изначально разбили задачу на три трека в отборочном туре и сформировали объединенный набор данных только на финале, но в формате хакатона с фиксированной метрикой команды, инвестировавшие в развитие контентных моделей, оказались в заведомо проигрышной ситуации в сравнении с командами, развивашими коллаборативную часть.
Компенсировать эту несправедливость помог приз жюри...
Deep Cluster

Который практически единогласно был присужден за работу по воспроизведению и апробации алгоритма Deep Cluster от facebook. Простой и не требующий изначальной разметки метод построения кластеров и эмбедингов картинок подкупал новизной идеи и многообещающими результатами.
Суть метода предельно проста:
- вычисляете вектора-эмбединги для изображений любой осмысленной нейросетью;
- кластеризуете вектора в полученном пространстве с помощью k-means;
- тренируете нейросеть-классификатор на предсказание кластера картинки;
- повторяете пункты 2-3 до сходимости (если у вас 800 ГПУ) или пока хватает времени.
С минимумом усилий удалось получить качественную кластеризацию картинок ОК, хорошие эмбединги и прирост метрики в третьем знаке.
Взгляд в будущее

В любых данных можно найти "лазейки", позволяющие улучшить прогноз. Само по себе это не так плохо, гораздо хуже если "лазейки" находятся сами и долгое время проявляются только в виде непонятных расхождений между результатами валидации на исторических данных и А/Б тестами.
Одна из самых распространенных "лазеек" такого рода — использование информации из будущего. Подобная информация часто является очень сильным сигналом и алгоритм машинного обучения, если ему это позволить, начнет её с уверенностью использовать. Когда делаешь модель для своего продукта, то всячески стараешься избежать просачивания информации из будущего, но на хакатоне это хороший шанс поднять метрику, чем и воспользовались участники.
Самая очевидная лазейка заключалась в наличии в данных полей со счетчиками реакций на объекте на момент показа — numLikes и numDislikes. Сравнив два ближайших по времени события, связанные с одним и тем же объектом, можно было с высокой точностью установить какова была реакция на объект в первом из них. Подобных счетчиков в данных было несколько, и их использование давало заметное преимущество. Естественно, в реальной эксплуатации подобная информация будет недоступна.
В жизни на подобную проблему можно наткнутся и не осознавая этого, как правило с негативными результатами. Например, посчитав статистику по количеству отметок "Класс!" для объекта по всем данным и взяв как отдельный признак. Или, как сделали в одной из участвовавших команд, добавив в модель идентификатор объекта как категориальный признак. На тренировочном множестве модель с таким признаком работает хорошо, но на тестовое множество обобщиться не может.
Вместо заключения

Все материалы конкурса, включая данные и презентации решений участников доступны в Облаке Mail.ru. Данные доступны для использования исследовательских проектах без ограничений, кроме наличия ссылки. Для истории, оставим здесь финальную таблицу с метриками команд-финалистов:
- Крадущаяся Scala, затаившийся Python — 0.7422, разбор решения доступен здесь, а код здесь и здесь.
- Magic City — 0.7256
- Кефир — 0.7226
- Team 6 — 0.7205
- Трое в лодке — 0.7188
- Hall #14 — 0.7167 и приз жюри
- BezSNA — 0.7147
- PONGA — 0.7117
- Team 5 — 0.7112
SNA Hackathon 2019, как и предыдущие мероприятия серии, удался во всех смыслах. Нам удалось собрать под одной крышей классных специалистов в разных областях и плодотворно провести время, за что огромное спасибо и самим участникам, и всем тем кто помогал с организацией.
Можно было что-то сделать еще лучше? Конечно да! Каждый проведенный конкурс обогащает нас новым опытом, который мы учитываем при подготовке следующего и не собираемся останавливаться на достигнутом. Так что, до скорых встреч на мероприятиях серии SNA Hackathon!


")
