
Туториал: Собираем нейронную сеть на примере классификации нарисованных животных в режиме "обучения без обучения".
Цель: Научиться быстро создавать классификаторы для множества задач, без данных и без разметки, используя нейросеть CLIP от OpenAI.
Уровень: Туториал подходит под любой уровень: от нулевого до профи.
Совсем недавно я писал статью про нейронную сеть CLIP от OpenAI — классификатор изображений, решающий практически любую задачу, и который вообще не нужно обучать! Теперь давайте посмотрим, как CLIP работает на практике. Собираем CLIP из рубрики: Разбираем и Собираем Нейронные Сети на примере мультфильмов.
Дисклеймер: Пять минут, пять минут. Как же я устал от "все за пять минут". TensorFlow за пять минут, PyTorch за пять часов. Нейронные сети за выходные. Любой язык за двадцать один день. Но что я могу сделать, если OpenAI выложили в открытый доступ нейронную сеть CLIP? И на написание кода, и создание готового обученного классификатора и у меня и у любого, даже не знакомого с Python, уйдет именно столько времени. Интересно как? На самом деле все очень просто. + Рабочий код: Читай и запускай! Приятного прочтения!
О рубрике Разбираем и Собираем Нейронные Сети
Недавно я запустил рубрику Разбираем и Собираем Нейронные Сети, целью которой является не только разбор новых (как CLIP) и классических статей по машинному обучению, но и получение практического опыта. Частота выхода подобных публикаций в рубрике Разбираем и Собираем Нейронные Сети напрямую зависит от твоей заинтересованности в теме, показать которую ты можешь подняв эту публикацию, и предложив тему, интересующую именно тебя!
Если тебе интересно машинное обучение, то приглашаю в «Мишин Лернинг» — мой субъективный телеграм-канал об искусстве глубокого обучения, нейронных сетях и новостях из мира искусственного интеллекта.
Перед началом сборки?
В этом туториале мы будем создавать сеть под задачу классификации мультяшных животных.

Я подготовил более полусотни изображений 10ти классов животных. От четырех до десяти изображений на класс. Этого явно не хватит, чтобы обучиться (хотя чем черт не шутит1), но хватит, чтобы протестировать нейросеть обученную на CLIP в режиме Обучения без Обучения. Теперь осталось лишь прояснить, как работает CLIP.
Если коротко:
Суммаризация статьи: Разбираем CLIP

Разберем, как именно должно реализовываться обучение без обучения, и как получить классификатор под новый класс задач, и как его использовать. На самом деле все очень просто. CLIP принимает изображение и текстовые описания. На выходе для каждой картинки мы можем получить метрику схожести всех текстовых описаний, что мы подали в модель. Например, мы подаем на вход изображение собаки и несколько текстовых описаний: a photo of a plane, a photo of a car, a photo of a dog, …, a photo of a bird. Если CLIP хорошо предобучен, то мы можем ожидать, что для фотографии собаки максимальную численную схожесть получит вариант a photo of a dog. Двигаясь дальше в нашем рассуждении, мы можем подавать на вход и другие изображения, получать (ранжируя, сортируя по метрике схожести) текст, который будет ближе всего соответствовать новому изображению. Можно сказать, что это классификация изображений на классы, описанные на естественном языке!
Обратите внимание, что запрос стоит формулировать специфически: а photo of a ____ или a centered satellite photo of ____. Как можно догадаться, подобная формулировка позволяет более узко производить настройку или адаптацию под конкретный датасет во время обучения без обучения. Черт возьми, это чуть ли не машинное обучение на словах! Правильная словесная формулировка и описание классов — готовый классификатор.
Если подробно: Вот целая статья Разбираем CLIP, посвященная теории, результатам и аспектам обучения без обучения нейронной сети:
Разбираем нейронную сеть CLIP от OpenAI: Классификатор, который не нужно обучать. Да здравствует Обучение без Обучения
Теория — хорошо, а практика лучше! Так что начнем!
Модель для сборки: CLIP
Подготовка Colab. Установка PyTorch 1.7.1.
Загружаем CLIP. Загружаем Нейронную Сеть.
Препроцессинг данных. Разбираем препроцессинг изображений и текстов.
Обучение без Обучения. Получаем классификатор в режиме "обучение без обучения" для своей задачи не имея никаких данных!
Результаты. Смотрим и анализируем примеры классификации.
Beyond the Infinite. Неужели мы получили машинное обучение на словах?
Подготовка Colab
Если будете запускать код в colab, то убедитесь, что вы используете runtime c графическим процессором. Если нет, то выберите «GPU» в качестве аппаратного ускорителя в в меню Runtime > Change Runtime Type. После запуска блока нас ждет установка PyTorch 1.7.1.
Загружаем CLIP
Скачиваем CLIP, предобученный на 400М пар изображение-текст. Его можно использовать в режиме обучения без обучения (например ViT-B/32 CLIP). После запуска блока нас ждет установка скачивание model.pt модели CLIP: Visual Transformer2 "ViT-B/32" + Text Transformer
Параметры модели: CLIP: Visual Transformer "ViT-B/32" + Text Transformer
Model parameters: 151,277,313
Input resolution: 224
Context length: 77
Vocab size: 49408
Препроцессинг данных
Так как модель CLIP представляет из себя Visual Transformer "ViT-B/32", это означает, что вход модели должен быть фиксированного разрешения 224x224 пикселя. Препроцессинг изображений представляет из себя изменение размера входного изображения и обрезку его по центру. Перед этим нормализуем яркость пикселей картинки, используя поканальное среднее значение датасета 400М пар изображение-текст и стандартное отклонение.
Текстовый препроцессинг для Text Transformer части сети CLIP использует нечувствительный к регистру токенизатор. Код токенизатора скрыт во второй ячейке блока. Далее текст паддится до длины сontext length, и готов подаваться в трансформер.
Обучение без обучения
Перед непосредственным обучением без обучения разберем на примере, как работает CLIP.
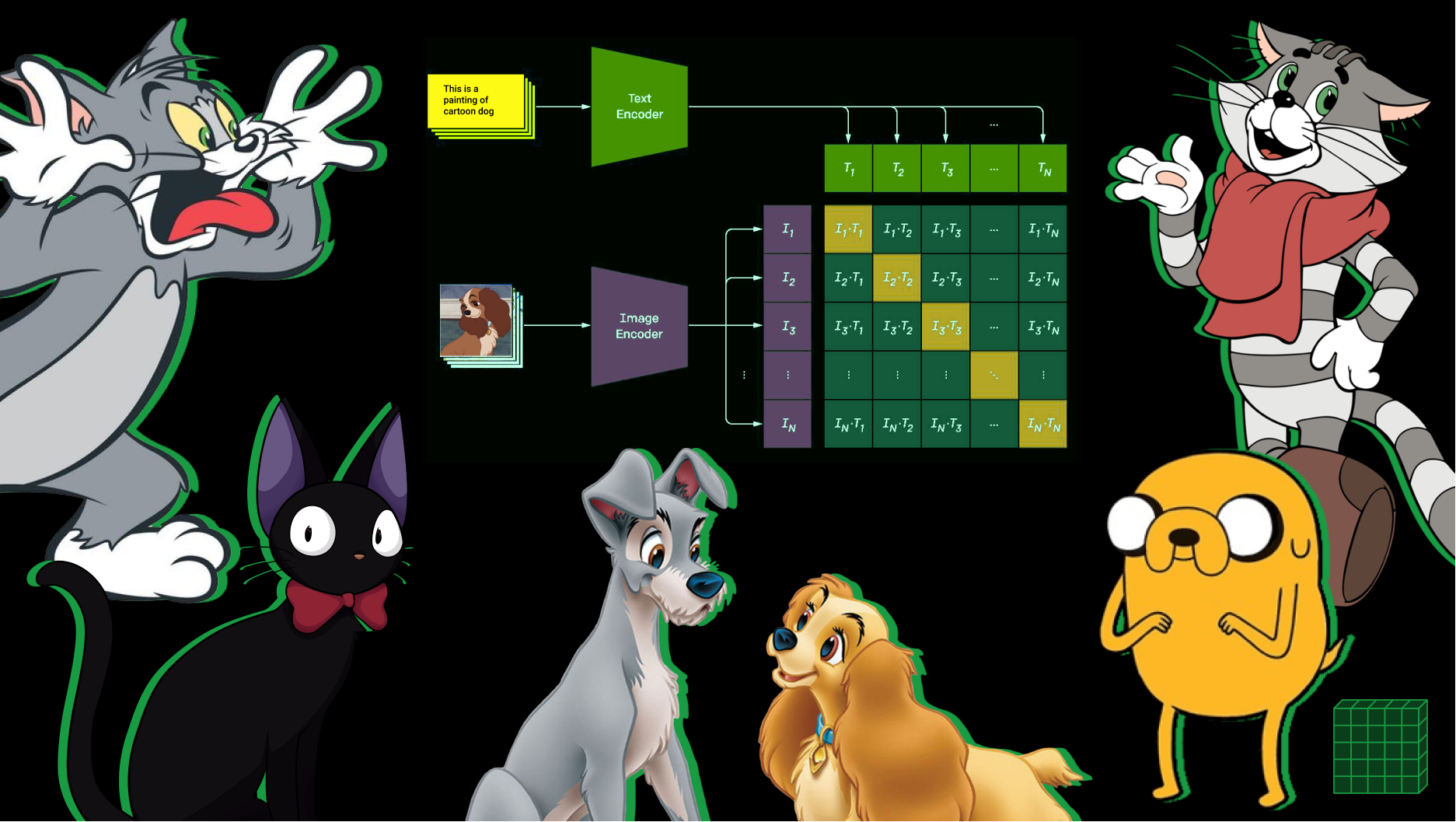
Давайте скормим модели 10 изображений по одному примеру на класс и их текстовые описания. А потом построим матрицу косинусных расстояний между векторами изображений и векторами текстов (cosine similarity в общем пространстве визуальных и текстовых репрезентаций).

Как мы видим по матрице cosine similarity, максимальная схожесть векторных репрезентаций изображений и текстовых описаний находится на главной диагонали. Их этого мы можем сделать вывод, что CLIP подходит под нашу задачу.
В нашем примере тонкую настройку головы классификатора в режиме обучения без обучения под домен мультфильмов я решил производить перфиксом this is a painting of cartoon ________.
Так как же получить классификатор под свою задачу в режиме обучения без обучения?
На самом деле мы его уже получили. Ведь если cosine similarity векторных репрезентаций изображений и текстовых описаний максимальна у правильных пар изображение-текст, то все что нам нужно это прогнать тексты и изображения и найти для каждой картинки текст, чья векторная репрезентация будет ближе всего. Это и есть классификация. Но нам не нужно прогонять текст каждый раз, для каждого вызова классификатора. Мы можем сделать это один раз и получить готовый классификатор. Теперь осталось прогнать эти текстовые описания через Text Transformer и забрть векторные репрезентации.
Cosine similarity — это косинус угла между векторами, что по определению есть скалярное произведение между отнормированными (по длине, L2) этими векторами. Значит мы можем отнормировать текстовые векторные репрезентации и сохранить их. Вот мы и обучили классификационную голову в режиме обучения без обучения.
Результаты
Для того, чтобы говорить о качестве нужен хоть какой-то датасет. OpenAI cделали сравнение CLIP и слоя logistic regression на фичах классического ResNet-50 полученного обычным обучением с учителем, и показали, что CLIP на 16 из 27 датасетов превосходит baseline классификаторы (обучение с учителем).
Сравнение точности CLIP в режиме обучения без обучения на разных датасетах.

Обучение без обучения на CLIP может конкурировать с baseline (слоя logistic regression на фичах классического ResNet-50) полученного обычным обучением с учителем. Перед вами список из 27 датасетов. Обучение без обучения на CLIP превосходит baseline классификаторы, полученные обучением с учителем на 16 из 27 датасетов, включая ImageNet! В качестве фича-экстрактора выступает ResNet-50. Интересно и то, что CLIP значительно превосходит baseline по двум датасетам Kinetics700 и UCF101 в задаче "распознавания действий на видео". Это связано с тем, что естественный язык обеспечивает более подробную репрезентацию для этой задачи.
Так как у меня нет возможности разместить достаточное количество изображений, ограничимся визуальной оценкой. Я не убирал неудачные примеры. Посмотрим.

Сразу бросается в глаза то, что Леди похожа на львенка, а болонка королевы — на кошку (разве что хвост собачий). Собаки из adventure time, кстати, чаще определяются как свинки.

Тут все отлично. Достаточно легкие оказались примеры. Я добавил еще несколько примеров под спойлер. Остальное найдете уже в Colab.
Больше примеров
Тут почти без ошибок. Хотя коты кардинала — явно не олени. И похожего тоже мало. Стоит лишь сказать, что кот в сапогах на одном из изображений имеет что-то общее с лисой (хотя бы цвет). Дальше вообще все отлично. Чистая случайность.




Beyond the Infinite
Оценим время написания классификатора:
Установка PyTorch и загрузка модели CLIP ~ 30 секунд
Загрузка изображений по url и вызов всех команд в colab ~ 30 секунд
Написание 10-ти предложений на английском языке + проверка и переформулировка ~ 3 минуты
Написать 1 строчку и c_pickle_ить (сериализовать) векторы головы классификатора
text_features /= text_features.norm(dim=-1, keepdim=True)~ 1 минута
Справедливости ради, если бы еще пару лет назад мне сказали, что такое будет возможно, то я бы не поверил. Это действительно ИИ, который мы заслужили. Даже BiT3 меня впечатлил меньше. Особенно со стороны совершенного новой для CV парадигмы обучения без обучения.
Заключение
Как мы видим, нейрогибридная сеть CLIP — это действительно новый взгляд на объединение NLP и CV. Последние несколько лет мы наблюдали триумфы в области обработки естественного языка, и языковые модели действительно наделали много шума, совершив новую революцию и, в очередной раз, отложив новую "зиму" искусственного интеллекта в долгий ящик. Совсем недавно мы начали наблюдать явление, когда технологии, вроде бы изначально присущие только NLP, стали бить рекорды в компьютерном зрении: Vision Transformers. Методы few-shot и zero-shot learning проникают в сферу компьютерного зрения уже благодаря гибридным nlp и cv моделям. Посмотрим, что нас ждет дальше, и какие еще модели и методы пополнят наши славные ряды!
В туториале мы показали, как можно создать классификатор в режиме обучения без обучения. Я насчитал 6 ошибок на 64, размеченных мной изображениях. Конечно это не говорит о численной оценки точности, но показывает, то что модель хорошо справляется с этой задачей. В контексте обучения без обучения: получить работающую модель, подготовить PoC и двигаться дальше, собирая датасет для оценки качества — явно неплохая (а еще и выгодная с точки зрения времени) стратегия.
Код доступен для всех энтузиастов машинного обучения. В телеграм-канале тебя ждет ссылка на Colab с кодом "Собираем CLIP: Обучение без Обучения. Классификатор животных из мультфильмов. Без данных и за 5 минут" и множество других полезных материалов!
Полезные ссылки
Чтобы сделать публикацию еще более полезной, я добавил образовательные материалы, которые могут быть интересны начинающим и продолжающим свой путь в мир машинного обучения:
Статья на хабре для начинающих. Краткий курс машинного обучения или как создать нейронную сеть для решения скоринг задачи
ИИ итоги 2020-го года в мире машинного обучения. Самые громкие открытия в мире компьютерного зрения, обработки естественного языка, генерации изображений и видео, а также крупный прорыв в области биологии
YouTube-Лекция: Нейронные сети: как их создают и где применяют? Два часа о “самом главном”
Сноски
Качество zero-shot CLIP сопоставимо с BiT-M после 16-shot linear probes. При этом, если продолжать few-shot learning на CLIP, он начинает быстро обгонять другие модели, обучаемые тем же linear probes на том же количестве новых размеченных данных. Теперь идея с обучением на плюс-минус восьми картинках на класс кажется возможной, что даже превосходит Big Transfer (BiT).
Vision Transformers начинают вытеснять сверточные нейронные сети. И в ближайшее время мы увидим все больше интереса именно к этим архитектурам. Создатели CLIP обучили CLIP-ViT на основе Vision Transformer'ов. Это три модели обученные на разрешении 224x224 : ViT-B/32, ViT-B/16, ViT-L/14, и модель ViT-L/14, fine-tune которой производился на изображениях 336х336.
Big Transfer (BiT): General Visual Representation Learning - https://arxiv.org/abs/1912.11370v3
Ну вот и все! Надеюсь, что материал оказался полезным. Спасибо за прочтение!
Что ты думаешь о CLIP и об Обучении без Обучения? Какой интересный пример использования "обучения без обучения" можешь предложить ты? Где, по-твоему, может быть полезна такая технология? Насколько тебя впечатлили результаты? Есть ли какие-то вопросы? Интересна ли тебе новая рубрика "Разбираем и Собираем Нейронные Сети"? Какие темы тебе были бы интересны? Давай обсудим в комментариях!




