
Введение: Соревнование от финансовой группы HOME CREDIT по определению риска дефолта заемщика
Соревнования Kaggle с использованием структурированных данных очень часто выигрывают специалисты по разработке признаков: побеждают те, кто может создавать наиболее полезные признаки из данных. Это представляет собой одну из закономерностей в машинном обучении: разработка признаков дает больший возврат инвестиций, чем построение модели и настройка гиперпараметров. Как говорит один из ведущих ученых в области машинного обучения – Эндрю Ын: «Прикладное машинное обучение — это в основном разработка признаков».
Хотя выбор правильной модели и ее оптимальная настройка, несомненно, очень важны, модель может учиться только на основе предоставленных данных. Обеспечение максимального соответствия этих данных задаче – задача специалиста по данным. Конструирование признаков может включать, как создание признаков: добавление новых признаков из существующих данных, так и выбор признаков: выбор только наиболее важных признаков или другие методы уменьшения размерности. Есть много методов, которые мы можем использовать как для создания, так и для выбора признаков.
В рамках этой статьи я рассмотрю два простых метода построения признаков:
Полиномиальные признаки;
Признаки, основанные на понимании предметной области.
ПОЛИНОМИАЛЬНЫЕ ПРИЗНАКИ
Одним из простых методов построения признаков является создание полиномиальных признаков. В этом методе создаются признаки, которые являются степенями существующих признаков, а также определенными взаимодействиями между существующими признаками. Например, мы можем создать переменные EXTSOURCE1 ^ 2 и EXTSOURCE2 ^ 2, а также такие переменные, как EXTSOURCE1 * EXTSOURCE2, EXTSOURCE1 * EXTSOURCE2 ^ 2, EXTSOURCE1 ^ 2 x EXTSOURCE2 ^ 2 и так далее. Эти признаки, представляющие собой комбинацию нескольких отдельных переменных, называются условиями взаимодействия, поскольку они фиксируют взаимодействия между переменными. Другими словами, хотя две переменные сами по себе могут не иметь сильного влияния на цель, объединение их вместе в одну взаимодействующую переменную может показать связь с целью. Термины взаимодействия обычно используются в статистических моделях, чтобы уловить влияние нескольких переменных, но в машинном обучении используются не очень часто. Тем не менее, мы можем попробовать несколько вариантов, чтобы увидеть, могут ли они помочь нашей модели предсказать, вернет ли клиент ссуду или нет.
Следующим программным кодом я создам полиномиальные признаки, используя переменные EXTSOURCE и переменную DAYSBIRTH. В Scikit-Learn есть полезный классPolynomialFeatures, который создает полиномы и условия взаимодействия до определенной степени. Достаточно использовать степень 3, чтобы увидеть результат (при создании полиномиальных признаков, нежелательно использовать слишком высокую степень, потому что количество признаков экспоненциально масштабируется со степенью, а также можно столкнуться с проблемами переобучения).
poly_features = app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH', 'TARGET']]
poly_features_test = app_test[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
from sklearn.preprocessing import Imputer
imputer = Imputer(strategy = 'median')
poly_target = poly_features['TARGET']
poly_features = poly_features.drop(columns = ['TARGET'])
poly_features = imputer.fit_transform(poly_features)
poly_features_test = imputer.transform(poly_features_test)
from sklearn.preprocessing import PolynomialFeatures
# Создаем объект PolynomialFeatures, указав степень взаимодействия, равную 3
poly_transformer = PolynomialFeatures(degree = 3)
poly_transformer.fit(poly_features)
poly_features = poly_transformer.transform(poly_features)
poly_features_test = poly_transformer.transform(poly_features_test)
print('Polynomial Features shape: ', poly_features.shape)Polynomial Features shape: (307511, 35)
Чтобы получить названия новых признаков, нужно использовать метод get_feature_names.
poly_transformer.get_feature_names(input_features = ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH'])[:15]
Теперь у нас имеется 35 признаков новых: индивидуальные признаки; признаки, повышенные до степени 3; взаимодействующие признаки. Можно посмотреть, коррелируют ли какие-либо из этих новых признаков с целевой меткой.
poly_features = pd.DataFrame(poly_features,
columns = poly_transformer.get_feature_names(['EXT_SOURCE_1', 'EXT_SOURCE_2',
'EXT_SOURCE_3', 'DAYS_BIRTH']))
poly_features['TARGET'] = poly_target
# Найдем корреляцию с целевой меткой
poly_corrs = poly_features.corr()['TARGET'].sort_values()
print(poly_corrs.head(10))
print(poly_corrs.tail(5))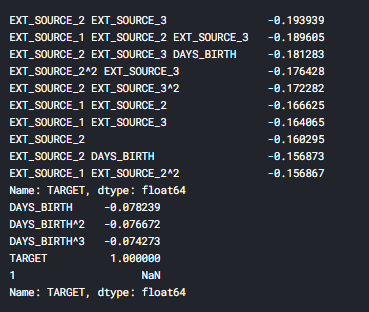
Некоторые из новых признаков имеют большую (с точки зрения абсолютной величины) корреляцию с целью, чем исходные признаки. При создании модели машинного обучения, можно попробовать использовать или не использовать эти признаки, чтобы определить, действительно ли они помогают модели учиться.
Добавим эти признаки в копию данных обучения и тестирования, а затем оценим модели с этими признаками и без них. Часто в машинном обучении единственный способ узнать, сработает ли тот или иной подход, — это попробовать его.
poly_features_test = pd.DataFrame(poly_features_test,
columns = poly_transformer.get_feature_names(['EXT_SOURCE_1', 'EXT_SOURCE_2',
'EXT_SOURCE_3', 'DAYS_BIRTH']))
poly_features['SK_ID_CURR'] = app_train['SK_ID_CURR']
app_train_poly = app_train.merge(poly_features, on = 'SK_ID_CURR', how = 'left')
poly_features_test['SK_ID_CURR'] = app_test['SK_ID_CURR']
app_test_poly = app_test.merge(poly_features_test, on = 'SK_ID_CURR', how = 'left')
app_train_poly, app_test_poly = app_train_poly.align(app_test_poly, join = 'inner', axis = 1)
print('Training data with polynomial features shape: ', app_train_poly.shape)
print('Testing data with polynomial features shape: ', app_test_poly.shape)Training data with polynomial features shape: (307511, 275)
Testing data with polynomial features shape: (48744, 275)
ПРИЗНАКИ, ОСНОВАННЫЕ НА ПОНИМАНИИ ПРЕДМЕТНОЙ ОБЛАСТИ
Теперь попробуем сконструировать несколько признаков, которые попытаются уловить то, что, возможно, может быть важным для определения того, не совершит ли клиент дефолт по ссуде. Для знакомства с конструированием подобных признаков я использую информацию публичного скрипта:
CREDITINCOMEPERCENT: процент суммы кредита относительно дохода клиента;
ANNUITYINCOMEPERCENT: процент аннуитетного платежа кредита относительно дохода клиента;
CREDITTERM: продолжительность платежа в месяцах;
DAYSEMPLOYED_PERCENT: процент отработанных дней по отношению к возрасту клиента.
app_train_domain = app_train.copy()
app_test_domain = app_test.copy()
app_train_domain['CREDIT_INCOME_PERCENT'] = app_train_domain['AMT_CREDIT'] / app_train_domain['AMT_INCOME_TOTAL']
app_train_domain['ANNUITY_INCOME_PERCENT'] = app_train_domain['AMT_ANNUITY'] / app_train_domain['AMT_INCOME_TOTAL']
app_train_domain['CREDIT_TERM'] = app_train_domain['AMT_ANNUITY'] / app_train_domain['AMT_CREDIT']
app_train_domain['DAYS_EMPLOYED_PERCENT'] = app_train_domain['DAYS_EMPLOYED'] / app_train_domain['DAYS_BIRTH']
app_test_domain['CREDIT_INCOME_PERCENT'] = app_test_domain['AMT_CREDIT'] / app_test_domain['AMT_INCOME_TOTAL']
app_test_domain['ANNUITY_INCOME_PERCENT'] = app_test_domain['AMT_ANNUITY'] / app_test_domain['AMT_INCOME_TOTAL']
app_test_domain['CREDIT_TERM'] = app_test_domain['AMT_ANNUITY'] / app_test_domain['AMT_CREDIT']
app_test_domain['DAYS_EMPLOYED_PERCENT'] = app_test_domain['DAYS_EMPLOYED'] / app_test_domain['DAYS_BIRTH']Необходимо визуально изучить эти признаки, отражающие знания о предметной области. Для всего этого построим график KDE, окрашенный значением TARGET.
plt.figure(figsize = (12, 20))
for i, feature in enumerate(['CREDIT_INCOME_PERCENT', 'ANNUITY_INCOME_PERCENT', 'CREDIT_TERM', 'DAYS_EMPLOYED_PERCENT']):
plt.subplot(4, 1, i + 1)
sns.kdeplot(app_train_domain.loc[app_train_domain['TARGET'] == 0, feature], label = 'target == 0')
sns.kdeplot(app_train_domain.loc[app_train_domain['TARGET'] == 1, feature], label = 'target == 1')
plt.title('Distribution of %s by Target Value' % feature)
plt.xlabel('%s' % feature); plt.ylabel('Density');
plt.tight_layout(h_pad = 2.5)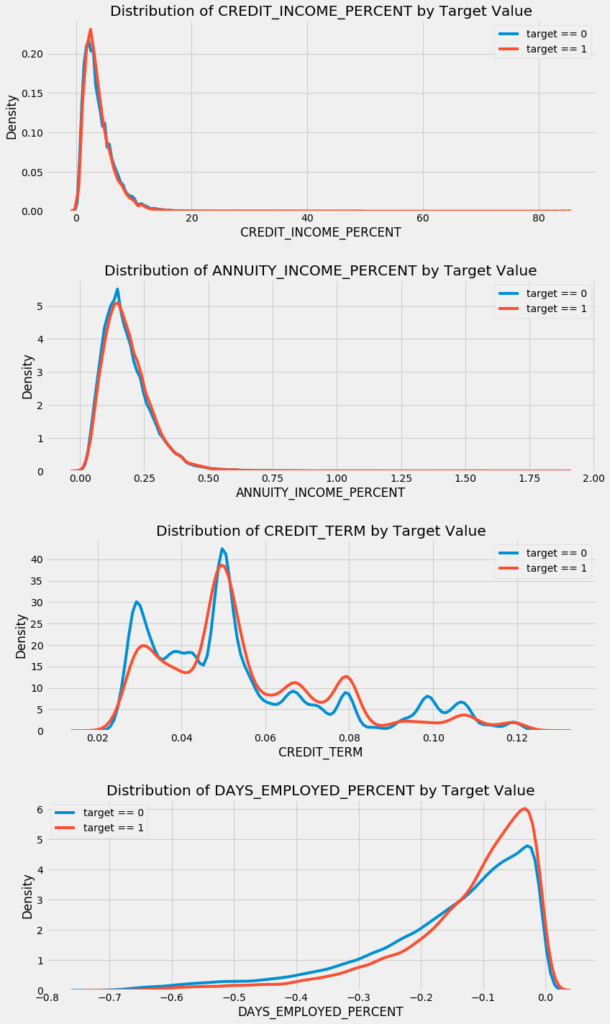
Сложно сказать заранее, будут ли полезны эти новые признаки. Единственный способ узнать наверняка — попробовать их.
BASELINE
Для наивного решения можно было бы указать одно и то же значение для всех примеров из тестового набора. Нас просят предсказать вероятность невыплаты ссуды, поэтому можно предположить вероятность 0,5 для всех наблюдений на тестовой выборке. Это даст нам площадь под кривой ошибок (AUC ROC), равную 0,5. Но лучше воспользоваться для нашего бейзлайна чуть более сложной моделью: логистической регрессией.
РЕАЛИЗАЦИЯ ЛОГИСТИЧЕСКОЙ РЕГРЕССИИ
Чтобы получить базовый уровень, я использую рассмотренные ранее признаки, за исключением созданных вручную. Предварительно обработаю данные, заполнив недостающие значения и нормализуя диапазон признаков (масштабирование признаков). Следующий код выполняет оба этих шага предварительной обработки.
from sklearn.preprocessing import MinMaxScaler, Imputer
if 'TARGET' in app_train:
train = app_train.drop(columns = ['TARGET'])
else:
train = app_train.copy()
features = list(train.columns)
test = app_test.copy()
# Заполняем пропущенные значения медианным значением признака
imputer = Imputer(strategy = 'median')
# Масштабируем признаки в диапазон 0-1
scaler = MinMaxScaler(feature_range = (0, 1))
imputer.fit(train)
train = imputer.transform(train)
test = imputer.transform(app_test)
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
print('Training data shape: ', train.shape)
print('Testing data shape: ', test.shape)Training data shape: (307511, 240)
Testing data shape: (48744, 240)
Для первой модели я использую LogisticRegression из библиотеки Scikit-Learn. Единственное изменение, которое потребуется в настройки модели по умолчанию, — уменьшу параметр регуляризации C, контролирующий степень переобучения (более низкое значение должно уменьшить переобучение). Это даст чуть лучшие результаты, чем LogisticRegression с параметрами по умолчанию, но все равно установит низкую планку для любых будущих моделей.
Сначала создаем модель, затем обучаем ее с помощью метода .fit, а затем делаем прогнозы на основе тестовых данных с помощью метода .predict_proba (нам нужны вероятности, а не целые числа 0 или 1).
from sklearn.linear_model import LogisticRegression
# Создаем модель и тренируем ее
log_reg = LogisticRegression(C = 0.0001)
log_reg.fit(train, train_labels)
Теперь, когда модель обучена, можно использовать ее для прогнозирования. В задаче требуется спрогнозировать вероятность невыплаты ссуды, поэтому использую метод модели predict.proba. Он возвращает массив m*2, где m — количество наблюдений. Первый столбец — это вероятность того, что цель будет равна 0, а второй – вероятность того, что цель будет равна 1 (поэтому для каждой строки два столбца в сумме должны быть равными 1). Нам нужна вероятность того, что ссуда не будет погашена, поэтому выберу второй столбец.
Следующая строка кода формирует прогнозы и выбирает правильный столбец.
log_reg_pred = log_reg.predict_proba(test)[:, 1]Прогнозы должны быть в формате, показанном в файле samplesubmission.csv, где есть только два столбца: SKID_CURR и TARGET. Создадим фрейм данных в этом формате из набора тестов и прогнозов.
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = log_reg_pred
submit.head()
Прогнозы представляют собой вероятность от 0 до 1 того, что ссуда не будет возвращена. Если бы требовалось использовать их для классификации заемщиков, можно было бы установить порог вероятности для определения рискованности ссуды.
submit.to_csv('log_reg_baseline.csv', index = False)Файл с результатом теперь сохранен в виртуальной среде, в которой работает наш код. Чтобы получить доступ к нему, в конце программы необходимо нажать синюю кнопку «Зафиксировать и запустить» в правом верхнем углу экрана. Это действие запускает весь код, а затем позволяет загружать любые файлы, созданные во время запуска.
После запуска программы созданные файлы будут доступны на вкладке «Версии» раздела «Вывод». Отсюда файлы с результатами можно отправить на оценку или скачать. Поскольку в этой программе несколько моделей, файлов результата будет несколько.
При отправке результата на оценку базовый показатель данной модели должен быть приблизительно равен 0,671.
УЛУЧШЕННАЯ МОДЕЛЬ: СЛУЧАЙНЫЙ ЛЕС
Чтобы попытаться улучшить низкую производительность базовой модели, можно обновить алгоритм. Давайте попробуем использовать случайный лес на тех же данных обучения, чтобы увидеть, как это влияет на производительность. Случайный лес — гораздо более мощная модель, особенно при использовании сотен деревьев.
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(n_estimators = 100, random_state = 50, verbose = 1, n_jobs = -1)
random_forest.fit(train, train_labels)
# Определяем важность признаков
feature_importance_values = random_forest.feature_importances_
feature_importances = pd.DataFrame({'feature': features, 'importance': feature_importance_values})
# Формируем предсказания для тестовых данных
predictions = random_forest.predict_proba(test)[:, 1]
Оценка этой модели чуть выше базового уровня и составляет примерно 0,678 балла.
ДЕЛАЕМ ПРОГНОЗЫ, ИСПОЛЬЗУЯ СПЕЦИАЛЬНЫЕ ПРИЗНАКИ
Единственный способ увидеть, улучшили ли модель полиномиальные признаки и признаки на основе знания предметной области, — это обучить модель с их использованием. Затем можно сравнить полученную оценку с оценкой для модели без этих признаков, чтобы оценить эффект от разработки признаков.
poly_features_names = list(app_train_poly.columns)
imputer = Imputer(strategy = 'median')
poly_features = imputer.fit_transform(app_train_poly)
poly_features_test = imputer.transform(app_test_poly)
scaler = MinMaxScaler(feature_range = (0, 1))
poly_features = scaler.fit_transform(poly_features)
poly_features_test = scaler.transform(poly_features_test)
random_forest_poly = RandomForestClassifier(n_estimators = 100, random_state = 50, verbose = 1, n_jobs = -1)
random_forest_poly.fit(poly_features, train_labels)
# Формируем предсказания на тестовых данных
predictions = random_forest_poly.predict_proba(poly_features_test)[:, 1]
app_train_domain = app_train_domain.drop(columns = 'TARGET')
domain_features_names = list(app_train_domain.columns)
imputer = Imputer(strategy = 'median')
domain_features = imputer.fit_transform(app_train_domain)
domain_features_test = imputer.transform(app_test_domain)
scaler = MinMaxScaler(feature_range = (0, 1))
domain_features = scaler.fit_transform(domain_features)
domain_features_test = scaler.transform(domain_features_test)
random_forest_domain = RandomForestClassifier(n_estimators = 100, random_state = 50, verbose = 1, n_jobs = -1)
random_forest_domain.fit(domain_features, train_labels)
feature_importance_values_domain = random_forest_domain.feature_importances_
feature_importances_domain = pd.DataFrame({'feature': domain_features_names, 'importance': feature_importance_values_domain})
predictions = random_forest_domain.predict_proba(domain_features_test)[:, 1]Оценка для этой модели составляет 0,679 балла, что указывает на низкую значимость разработанных признаков в этом случае.
ИНТЕРПРЕТАЦИЯ МОДЕЛИ: ВАЖНОСТЬ ПРИЗНАКОВ
В качестве простого метода определения наиболее релевантных признаков можно взглянуть на важность признаков для модели случайного леса. Учитывая корреляции, которые мы видели в исследовательском анализе данных, следует ожидать, что наиболее важными признаками являются EXTSOURCE и DAYSBIRTH.
def plot_feature_importances(df):
df = df.sort_values('importance', ascending = False).reset_index()
df['importance_normalized'] = df['importance'] / df['importance'].sum()
plt.figure(figsize = (10, 6))
ax = plt.subplot()
ax.barh(list(reversed(list(df.index[:15]))),
df['importance_normalized'].head(15),
align = 'center', edgecolor = 'k')
ax.set_yticks(list(reversed(list(df.index[:15]))))
ax.set_yticklabels(df['feature'].head(15))
plt.xlabel('Normalized Importance'); plt.title('Feature Importances')
plt.show()
return df
# Отображаем важность признаков без учета специальных признаков
feature_importances_sorted = plot_feature_importances(feature_importances)
Как и ожидалось, наиболее важные признаки связаны с EXTSOURCE и DAYSBIRTH. Можно заметить, что существует лишь несколько признаков, имеющих существенное значение для модели. Это говорит о том, что можно отказаться от многих признаков без снижения качества (и даже увидеть его увеличение). Это не самый изощренный метод интерпретации модели или уменьшения размерности, но он позволяет начать понимать, какие факторы модель принимает во внимание при прогнозировании.
feature_importances_domain_sorted = plot_feature_importances(feature_importances_domain)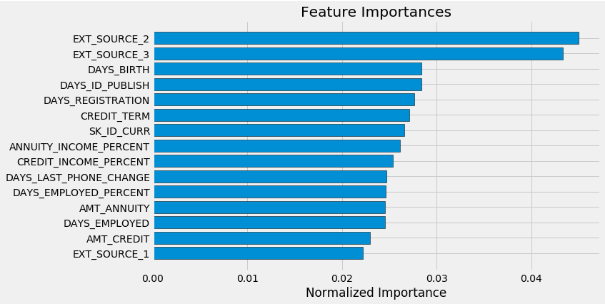
Все четыре созданные вручную признака вошли в топ-15 самых важных. Это должно вселить в нас уверенность в том, что наши знания в предметной области хотя бы частично соответствуют правильному пути.
ВЫВОДЫ
В этой и предыдущей статьях я постарался показать, как начать соревнования по машинному обучению Kaggle. Сначала постарайтесь понять данные, задачу и метрику, по которой будут оцениваться результаты. Затем проведите простой EDA, чтобы попытаться определить взаимосвязи, тенденции или аномалии, которые могут помочь в моделировании. Попутно можно выполнить необходимые шаги предварительной обработки, такие как кодирование категориальных переменных, заполнение пропущенных значений и масштабирование признаков. Затем создайте новые признаки на основе существующих данных, чтобы посмотреть, может ли это помочь модели.
По завершении исследования данных, подготовки данных и проектирования признаков следует реализовать базовую модель. Затем постройте немного более сложную модель, чтобы побить первый результат. И так далее. Кроме того, необходимо определить эффект добавления инженерных признаков.
В целом, необходимо следовать общей схеме проекта машинного обучения:
Разберитесь в проблеме и данных
Очистите и отформатируйте данные (в основном это сделали для нас организаторы конкурса)
Проведите исследовательский анализ данных
Создайте базовую модель
Улучшить модель
Интерпретируйте модель
Соревнования по машинному обучению немного отличаются от типичных задач науки о данных тем, что в их рамках участники озабочены только достижением наилучших результатов по одному показателю и не заботятся об интерпретации. Однако, пытаясь понять, как модели принимают решения, мы можем попытаться улучшить их или изучить ошибки, чтобы исправить их.
Я надеюсь, что моя статья помогла вам принять участие в этом (или каком-либо другом) соревновании по машинному обучению, и что теперь вы готовы самостоятельно и с помощью сообщества начать дальнейшую работу над серьезными проблемами!
При подготовке статьи были использованы материалы из открытых источников: источник1, источник2.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
А вы участвуете в соревнованиях?
-
0,0%Да0
-
0,0%Нет0



