
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Можно ли найти пару для носка с помощью машинного обучения? Оказывается, можно. Это небольшой проект по обучению и развертыванию модели распознавания объектов на оборудовании AWS DeepLens для идентификации моих носков.

Идея
У меня есть сумасшедшая идея, что я могу соединить свои беспарные носки с помощью машинного обучения. Имея достаточные данные для обучения, я смогу настроить модель на классификацию носков и поиск пары. Больше никаких одиноких носков!

Этот проект также дает хороший шанс протестировать (или оправдать ее покупку?) мою новую AWS Deeplens — ’’видеокамеру с поддержкой глубокого обучения’’. Deeplens — это устройство стоимостью 300 долларов, с 4-мегапиксельной видеокамерой, процессором Intel Atom, 8 ГБ оперативной памяти, работает под управлением Ubuntu.

Проект и все файлы доступны здесь.
Захват изображения
Любой хороший проект машинного зрения начинается с обучающих данных. В моем случае мне нужно подготовить набор обучающих изображений — сделать много фотографий носков и классифицировать изображения, чтобы я мог научить модель классифицировать носки по их типу.

Фотографировать носки — звучит увлекательно. К счастью, я обнаружил, что 30 фотографий каждого носка было достаточно, чтобы точно его идентифицировать, так что съемка не заняла слишком много времени.

Чтобы сэкономить время, я убедился, что каждый носок заполняет кадр камеры. Это означает, что мне не нужно было добавлять ограничивающие рамки к изображениям, поскольку весь кадр был заполнен одним изображением.
Подготовка изображения
Хотя вы можете обучить модель на папке, полной изображений, предпочтительнее оптимизировать формат изображений, чтобы уменьшить нагрузку на ввод-вывод во время обучения модели. Я подготовлю свой набор данных изображений носков в формате ImageRecord.

Чтобы подготовить мой набор данных носков в формате ImageRecord, мне сначала нужно сгенерировать .lstфайл, текстовый файл, описывающий классификацию изображений и имя файла. Я использовал Apache MXNet im2rec.py python-файл в выполнении этих шагов.
python3 -m venv myenv
source myenv/bin/activate
pip install mxnet opencv-python
curl --output im2rec.py https://raw.githubusercontent.com/apache/incubator-mxnet/master/tools/im2rec.pyЯ решил разделить фотографии на части: 80% на учебные изображения и 20% на проверку модели. В моих данных было 8 классификаций (то есть 8 разных сортов носков), для каждой из которых было около 30 изображений. Чтобы случайным образом распределить изображения по наборам обучения и проверки, я запускаю.
python im2rec.py --list --train-ratio 0.8 --recursive ./sock-images_rec sock-images/После выполнения вы находите файлы sock-images_rec_train.lstи sock-images_rec_val.lstи генерируете их. Эти текстовые файлы описывают изображения и классификацию для обучающих и проверочных наборов.
wc -l *.lst
544 sock-images_rec_train.lst
137 sock-images_rec_val.lst
681 totalТеперь я хочу сжать изображения моих носков в ImageRecord и уменьшить размер каждого изображения до 512x512 пикселей.
python im2rec.py --resize 512 --center-crop --num-thread 4 ./sock-images_rec ./sock-images/Это дает еще четыре файла: (sock-images_rec_train.idx, sock-images_rec_train.rec, sock-images_rec_val.idx, sock-images_rec_val.rec). Теперь у меня есть файлы ImageRecord как для обучения, так и для проверки. Я скопирую их на s3, чтобы я мог запустить обучение в облаке.
aws s3 cp . s3://deeplens-sagemaker-socksort --exclude "*" --include "*.idx" --include "*.rec" --include "*.lst" --recursiveОбучение модели
Теперь хочу обучить модель классификации изображений, которая может классифицировать изображения носков. Мы будем использовать трансфертное обучение, чтобы использовать знания из аналогичных задач классификации, для начальной загрузки моей модели классификации носков. Я могу запустить эту модель обучения в размещенном Jupyter (AWS Sagemaker) на Python.
Основные шаги:
Импортируйте набор данных носков в формате recordio.
Постройте модель классификации изображений (см. Классификация носков.ipynb). После запуска у вас должен быть файл модели с именем
 {DATE}/output/model.tar.gz
{DATE}/output/model.tar.gzРазверните временный классификатор для проверки функции вывода (то есть разверните вашу модель с временной конечной точкой).
Проведите тест на нескольких демонстрационных изображениях для проверки классификации.
Убедите себя, что это время потрачено не зря.
Более подробное объяснение здесь
Модель MXNet Deeplens и лямбда-функция
Пока нам удалось обучить модель и протестировать ее с помощью интерактивного ноутбука Jupyter, размещенного в облаке. Теперь я хочу, чтобы эта модель работала на моем локальном оборудовании для изображений, снятых и обработанных на оборудовании камеры Deeplens. Мне нужно будет развернуть обученную модель локально и написать локальную лямбда-функцию функцию.
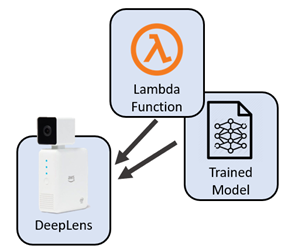
Нам нужно создать, опубликовать и развернуть лямбда-функцию вывода AWS DeepLens для сортировки носков. По сути, это zip-файл, содержащий мой код на Python (который извлекает изображения с камеры и вызывает модель классификации), а также библиотеки поддержки Python (такие как библиотеки брокеров MQTT) и базовые настройки конфигурации.
Шаги по сборке sock_deeplens_inference_function.zipподробно описаны здесь. То же самое относится и к шагам, необходимым для загрузки нашей ранее созданной модели классификации объектов в мое оборудование Deeplens.
Опубликовать сортировку носков с помощью функции вывода AWS DeepLens

Теперь у нас есть обученная модель и лямбда-функция вывода, развернутая локально на моем оборудовании Deeplens. При включении устройства все изображения, снятые камерой, должны проходить через модель классификации. Если найдено вероятное совпадение, детали накладываются на изображение. Я могу просматривать прямую трансляцию с камеры в веб-браузере, а текстовое наложение это отображение классификации носков. Я также включаю прогноз классификации в тему MQTT.

У нас есть локальная модель, которая может идентифицировать отдельные носки ... но мы прошли только половину пути! Наша следующая часть процесса это поиск пары.
Для этого мне понадобится ksqlDB - довольно крутая платформа для потоковой передачи событий. Несколько команд позволяют создать подробное приложение для обработки потоков в реальном времени. Захват, преобразование и выполнение непрерывных преобразований в Kafka с помощью упрощенного диалекта SQL. Кроме того, ksqlDB позволяет захватывать события из внешней системы с помощью Kafka connect.
Посмотрим, как Kafka + ksqlDB могут извлекать сообщения о классификации носков с камеры и выполнять преобразования потока, чтобы найти пары подходящих носков.

MQTT с помощью ksqlDB
Первая задача - получить предсказания носков с помощью камеры DeepLens. Изображения, классифицированные камерой, помещаются в топик MQTT.
MQTT - это легкий протокол обмена сообщениями TCP / IP, идеально подходит для небольших мобильных устройств и датчиков с низким энергопотреблением. Позволяет создавать короткие эффективные сообщения. Это больше похоже на доску объявлений, чем на очередь, и позволяет отправлять легкие сообщения, такие как “Видимый носок - это Google, с уверенностью 98%”.
Мы можем просматривать сообщения MQTT с помощью mosquitto_sub(или потрясающего графического интерфейса MQTT.fx). Вот типичная последовательность, в топике sockfound.
mosquitto_sub -h ${MQTT_HOST} -p ${MQTT_PORT} -u ${MQTT_USER} -P ${MQTT_PASS} -t sockfound
{"image": "Blank", "probability": 37.59765625}
{"image": "Blank", "probability": 41.162109375}
{"image": "Google", "probability": 97.314453125}
{"image": "Google", "probability": 94.970703125}
{"image": "Google", "probability": 64.6484375}
{"image": "Blank", "probability": 67.3828125}
{"image": "Blank", "probability": 50.634765625}MQTT, Kafka и Kafka Connect
Мы хотим добавить распознанные носки в потоковый процессор Kafka. MQTT действует как хранилище ключей / значений, тогда как Kafka - это полноценная потоковая платформа. MQTT сообщения отправляются в Kafka с помощью платформы Kafka Connect. С помощью драйвера MQTT, добавленного в Kafka Connect, мы можем настроить соединение с источником так, чтобы он постоянно помещал новые события прогнозирования из MQTT в раздел Kafka.
Традиционным способом настройки Kafka connect (который я использовал при отслеживании гонки с Kafka KSQL, MQTT и Kibana) было использование curl для прямого взаимодействия со службой Kafka Connect. Хотя это работает, теперь есть гораздо более простой способ…
Kafka подключается к ksqlDB
В ksqlDB теперь есть команды, позволяющие напрямую настраивать и управлять Kafka Connect. Давайте посмотрим, как мы можем настроить источник MQTT, используя только ksqlDB.

Мы можем создать источник Kafka Connect для MQTT с помощью команды ksqlDB, подобной этой. Обратите внимание, что я описываю местоположение и учетные данные для брокера MQTT, а также название моей целевой темы Kafka, и ... вот и все
CREATE SOURCE CONNECTOR `mqtt-source` WITH( "connector.class"='io.confluent.connect.mqtt.MqttSourceConnector',
"mqtt.server.uri"='tcp://something.example.com:14437',
"mqtt.username"='some-user',
"mqtt.password"='my-password',
"mqtt.topics"='sockfound',
"kafka.topic"='data_mqtt',
);Кстати, если вы беспокоитесь о том, чтобы поместить секреты (например, пароли) в свой скрипт KSQL, взгляните на управление секретами Kafka Connect с помощью ksqlDB.
Протестируем MQTT на Kafka
Мы можем проверить, попадают ли входящие сообщения MQTT в Kafka, запросив раздел Kafka с помощью KSQL.
ksql> print 'data_mqtt';Все идет хорошо, вы увидите что-то такое.
{"image": "Running Science", "probability": 43.994140625}
{"image": "Mongo", "probability": 50.29296875}
{"image": "Mongo", "probability": 86.279296875}
{"image": "Mongo", "probability": 53.076171875}Проблема № 1: “Призрачные” носки
Классификатор изображений DeepLens работает довольно быстро — и я могу распознавать 3 или 4 изображения в секунду. Но не все классификации изображений верны. Взгляните на этот поток (обратите внимание, что время указано в ЧЧ: MM: СС). В течение 4 секунд с 18:10:51 до 18:10:55 я видел сообщения с указанием “пусто”, одно сообщение “Mongo”, 9 последовательных сообщений “Google”, еще одно сообщение “Mongo” и, наконец, “пустые” последовательности.

Что я действительно хочу сделать, так это определить серию похожих сообщений в течение определенного промежутка времени

Переключение окон с помощью ksqlDB
Первым шагом является использование ksqlDB для создания потока, представляющего обновления сообщений в разделе MQTT.
create stream sock_stream(image varchar, probability double)
with (kafka_topic='data_mqtt', value_format='json');Теперь мы можем использовать windowed aggregation в SQL для загрузки изображений носков в окна продолжительностью 5 секунд. То есть мы будем группировать поступающие изображения в окна с интервалом в 5 секунд, чтобы определить наиболее распространенное видимое изображение. Я определяю, что классификация изображений нормальна, если она появляется больше 3 раз в этом 5-секундном окне.
create table sock_stream_smoothed as
select image
, timestamptostring(windowstart(), 'hh:mm:ss') as last_seen
, windowstart() as window_start
from sock_stream
window tumbling (size 5 seconds)
group by image having count(*) > 3
emit changes;Поток sock_stream_smoothed теперь представляет поток вероятных изображений, удаляющих случайные носки—призраки.
Проблема № 2: это стена, а не носок
Моя вторая проблема была немного глупой. Мне нужен способ не только различать носки, но и понимать когда у меня не было носка! Поскольку я хотел посчитать носки, мне нужно было исключить “пустые” изображения.
Первым шагом является использование ksqlDB для создания потока, представляющего обновления сообщений в разделе MQTT.
create stream sock_stream(image varchar, probability double)
with (kafka_topic='data_mqtt', value_format='json');Я могу исключить изображения стены (полезную нагрузку ‘blank’), просто исключив их из потока.
create stream sock_stream_without_blanks as
select image
from sock_stream
where image != 'blank';Поиск пар носков
Теперь у нас есть постоянный набор идентифицированных носков и нам нужно найти пары одинаковых изображений. Чтобы найти пары носков, я буду искать носки, которые появляются в четных числах. Вот примерный сегмент KSQL.
select image
, case when (count(*)/2)*2 = count(*) then 'Pair' else 'Un-matched' end as pair_seen
, count(*) as number_socks_seen
from sock_stream_smoothed
group by image
emit changes;Появится что-то вроде этого.
+--------------+-------------+--------------------+
|IMAGE |PAIR_SEEN |NUMBER_SOCKS_SEEN |
+--------------+-------------+--------------------+
|Mongo |Pair |2 |
|Streamset |Un-matched |1 |
|Google |Pair |2 |
|Confluent |Pair |2 |Сработало ли это?
Ну, да. Я был в восторге от результата. Между распознаванием изображения и идентификацией пары возникла небольшая задержка, которую я надеюсь еще оптимизировать. Но в целом, я очень доволен этим проектом.

Код проекта
У вас есть носки без пары? Можете их найти - полный код проекта по адресу: https://github.com/saubury/socksort


")

