
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Как показала история, сеть из миллиардов связанных между собой документов — очень хрупкая и эфемерная система. Странички живут недолго. Если нашли интересную страницу, сайт или видео — нельзя просто сделать закладку и надеяться, что контент по ссылке останется доступен в будущем. Не останется. Информация исчезнет, ссылки изменятся, домены сменят владельцев, статьи на Хабре спрячут в черновики. У каждой страницы свой срок жизни. Ничто не вечно под луной, и ничего с этим не поделать.
К счастью, у нас есть инструменты, чтобы сохранить информацию на десятилетия. Свой персональный архив, полностью под контролем, со всеми сайтами и актуальными страницами. Отсюда никто ничего не удалит без вашего ведома, никогда.
Вымирание ссылок
Вымирание ссылок — известный феномен. У большинства СМИ и других организаций нет политики долговременного сохранения информации. Они просто публикуют веб-страницы — и забывают про них. На старые страницы всем плевать, сменят они адреса или исчезнут навсегда. Неудивительно, что именно так и происходит.
Анализ внешних ссылок New York Times с 1996 по 2019 годы показал вымирание ссылок на уровне примерно 6% в год. По итогу с 1996 года пропало около 70% веб-страниц.
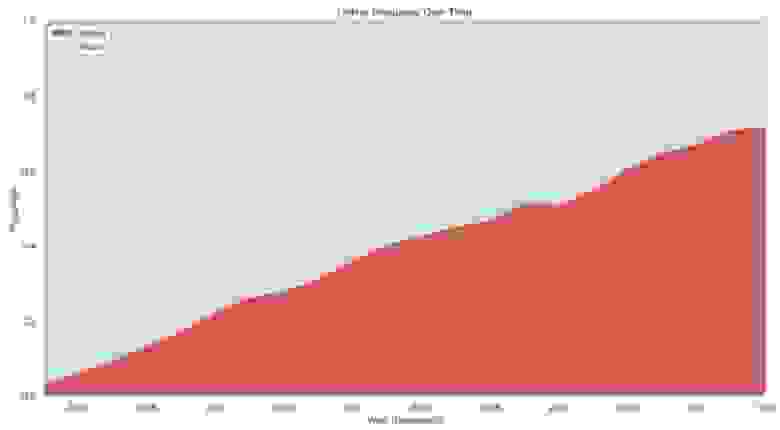
Проверка ссылок в научных статьях показала вымирание 23—53% в статьях с 1993 по 1999 годы.

Проверка проводилась в 2001 году. Наверняка сейчас, двадцать лет спустя, в тех статьях осталось ещё меньше живых ссылок. В 2016 году другая проверка источников в научных статьях с 1997 по 2012 годы показала, что по 75% ссылкам контент исчез или изменился, а снапшоты в веб-архивах остались только для трети пропавших страниц.
Для решения этой проблемы был создан Архив интернета и знаменитая Машина времени (Wayback Machine). Мотивация такая, что мы обязаны сохранить существующий контент для будущих поколений, иначе он безвозвратно исчезнет.
Но в Архив интернета попадают далеко не все страницы. В кэш Google попадает больше, но там определённый срок хранения. И никакой гарантии, что сохранится именно нужная информация. Так что лучше взять дело в свои руки — и создать собственный архив.
Инструменты для веб-архивирования
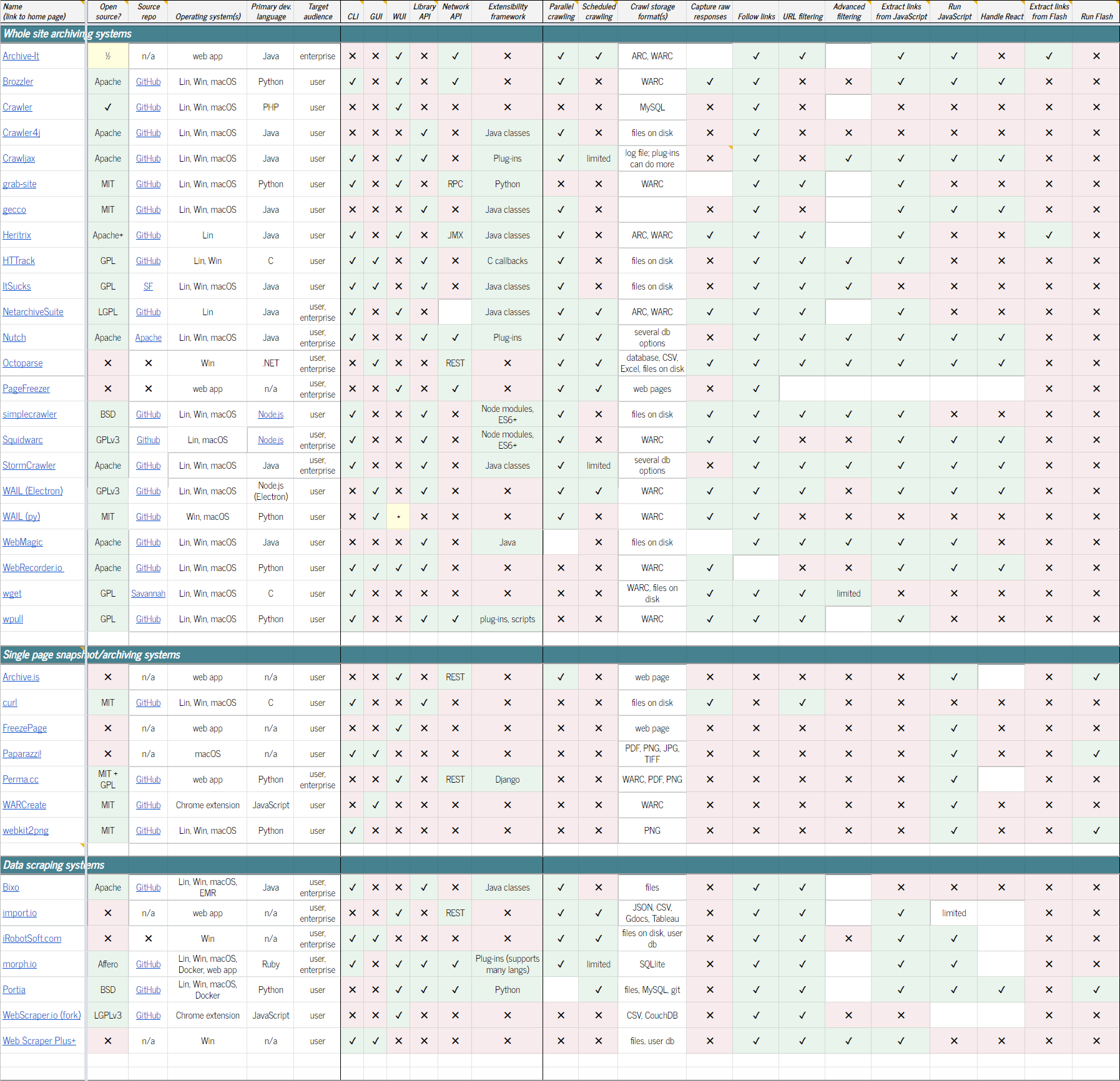
Существует ряд опенсорсных программ для веб-архивирования. Возможно, самый полный список таких проектов собран здесь. Есть также таблица со сравнением функциональности инструментов. Вот небольшой список некоторых проектов:
Архивирование целых сайтов
- Archive-It: курируемая служба веб-архивирования. Предлагает годовую подписку на доступ к своему веб-приложению с различными услугами: полнотекстовый поиск, краулинг контента с различной частотой, выдача отчётов и т. д.
- ArchiveWeb.page: десктопная программа и расширение для Chrome для создания веб-архивов. Расширение можно поставить на «запись», то есть на автоматическое сохранение всех страниц, которые открывались в браузере или в конкретной вкладке. Просматривать архивы в форматах WARC, WACZ, HAR или WBN можно даже в онлайне, для этого создан сайт ReplayWeb.page

- Brozzler: опенсорсная утилита, которая для скачивания контента использует настоящий браузер (Chrome или Chromium), а также youtube-dl и rethinkdb
- Crawler
- Crawler4j: опенсорсный краулер на Java с простым интерфейсом
- grab-site: предварительно сконфигурированный опенсорсный граббер сайтов, граф ссылок хранит на диске, а не в памяти, поэтому может успешно скачать сайт даже с 10 млн страниц. Результат записывает в формате WARC
- gecco
- Heritrix
- HTTrack
- ItSucks (не поддерживается с 2010 года)
- NetarchiveSuite: разработка Датской королевской библиотеки
- Nutch: краулер с локальным поиском изначально создавался как альтернатива аналогичному корпоративному продукту Google
- Octoparse: проприетарная платная программа, работает только под Windows
- PageFreezer: ещё одна проприетарная система, веб-приложение, специализируется на автоматической архивации сайтов и соцсетей для юридических целей
- simplecrawler: простой API для краулера, не поддерживается
- Squidwarc: ещё один краулер, который работает через браузер (Chrome или Chromium), поэтому умеет выполнять скрипты и извлекать оттуда ссылки для краулинга
- StormCrawler: опенсорсный SDK для построения распределённых, масштабируемых краулеров на Apache Storm
- WAIL (Electron): Web Archiving Integration Layer (WAIL) — графический интерфейс работает поверх многих веб-архиваторов, чтобы упростить пользователям процесс сохранения и последующего просмотра веб-страниц
- WAIL (py): версия на Python
- WebMagic: масштабируемый фреймворк
- Conifer (бывш. WebRecorder.io): выделил пользовательскую утилиту WebRecorder в отдельный опенсорсный проект, сам продвигает услугу облачного веб-архивирования с бесплатным лимитом 5 ГБ
- wget: популярная утилита из набора GNU тоже умеет сохранять на диске веб-архивы в виде файлов WARC
- wpull: wget-совместимый веб-архиватор, написанный на Python
Архивирование отдельных страниц
- Archive.is: общедоступный сервис для съёмки снапшотов страниц, которые получают новые URL, сохраняются в архиве для всеобщего просмотра
- curl: известная утилита командной строки для скачивания страничек
- FreezePage: веб-интерфейс для скачивания страничек, сохранять их можно в облаке или на диске
- Paparazzi!: маленькая утилита под macOS, которая делает графические скриншоты страниц
- Perma.cc: сокращатель ссылок и веб-архиватор позиционируется как инструмент для школьников, студентов, юристов и всех остальных, кто хочет получить надёжную ссылку на документ с гарантией, что он не исчезнет и не изменится
- WARCreate: расширение Google Chrome, которое сохраняет любую страницу в формате Web ARChive (WARC)
- webkit2png: утилита командной строки для сохранения скриншотов простой командой типа
webkit2png http://www.google.com/
Системы скрапинга данных
- Import.io: платная корпоративная система для скрапинга преимущественно финансовой информации с интеграцией собранных данных в сторонний софт
- iRobotSoft.com: персональный «менеджер», который автоматизирует рутинные ежедневные задачи в интернете: созданные «роботы» могут в том числе ходить по сайтам, кликать по ссылкам и собирать данные с веб-страниц
- morph.io: инструментарий для написания скраперов на Ruby, Python, PHP, Perl и Node.js, коллекция более 10 800 публичных скраперов
- Zyte (бывш. Scrapinghub): платный сервис дата-скрапинга через Extraction API
- WebScraper.io: расширение Chrome и Firefox для удобного скрапинга, экспорт в CSV, XLSX и JSON. Поддерживает работу в облаке по расписанию, через API, с продвинутым парсингом и т. д.
Выбор данных для скрапинга в расширении Chrome
- Web Scraper Plus+: платный парсер под Windows, давно не поддерживается и даже не совместим с Windows 7
Сравнительную таблицу со всеми функциями см. ниже.
Отдельно стоит отметить приложения для хранения закладок с распределением по папкам, категориям, с тегами. Здесь же копии всех веб-страниц. Такие программы можно назвать «архивами закладок». Например, LinkAce или Wallabag.

LinkAce (платная)
ArchiveBox: личный архив
ArchiveBox — одно из самых функциональных решений для архивирования веб-страниц на своём хостинге. Программа отличается тем, что у неё одновременно есть и веб-интерфейс, и продвинутая утилита командной строки (официально поддерживаются macOS, Ubuntu/Debian и BSD). Скоро появится десктопное приложение на электроне под Linux, macOS и Windows (оно пока в альфе).
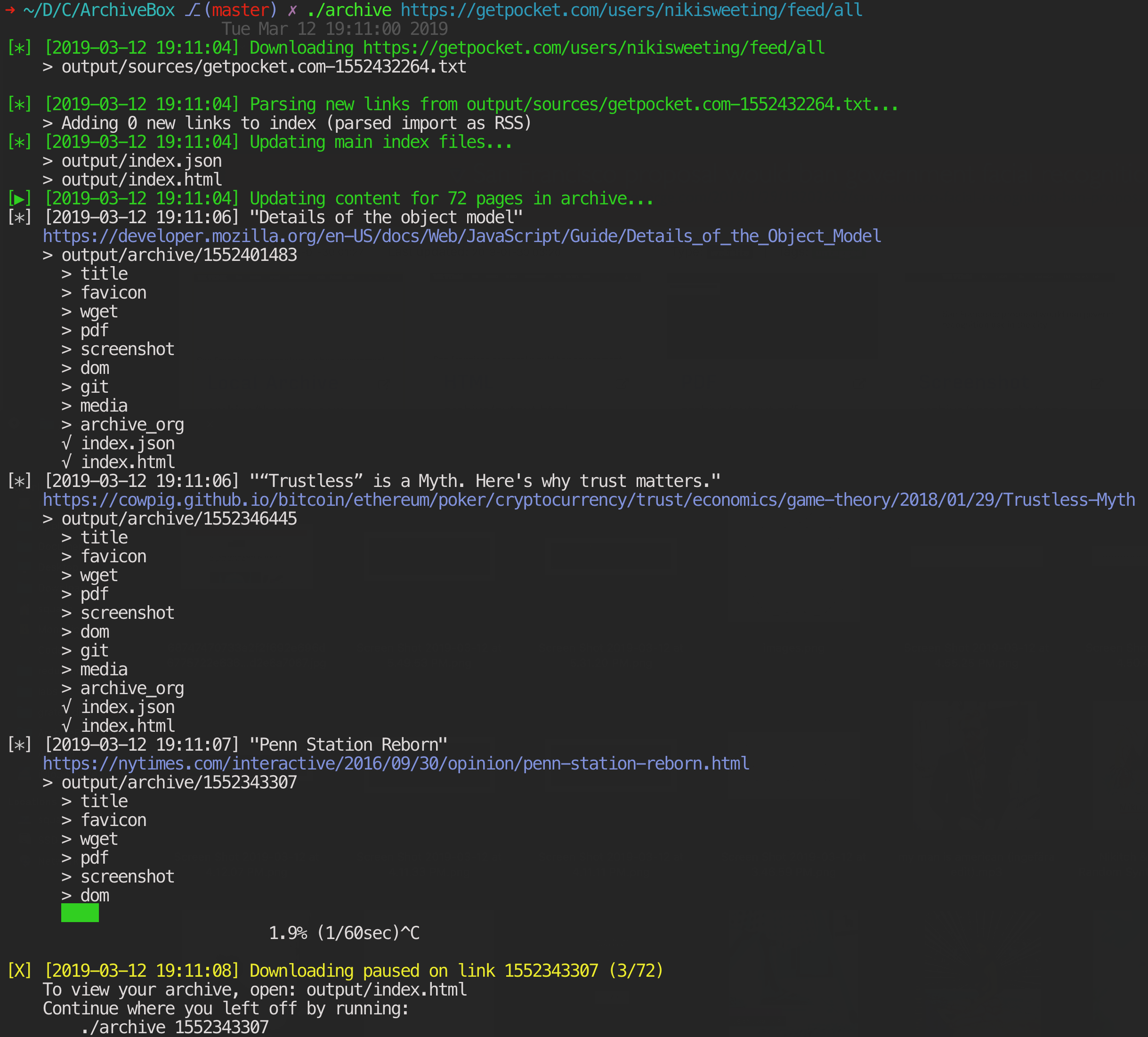
В ArchiveBox можно скинуть URL и указать формат сохранения: HTML, PDF, скриншот PNG или WARC. Автоматически сохраняется вся контекстная информация вроде заголовков, фавиконов и т. д. Грамотно скачивает медиафайлы с помощью youtube-dl, статьи (readability), код (git) и другие типы контента: всего около 12 модулей-экстракторов.
По умолчанию «для надёжности» все страницы вашего архива сохраняются также на archive.org. Опцию можно (и нужно) отключить.
См. также документацию по форматам сохранения и варианты конфигурации.
Инструмент командной строки работает очень просто.
Добавить ссылку в архив:
archivebox add 'https://example.com'Добавлять контент раз в день:
archivebox schedule --every=day --depth=1 https://example.com/rss.xmlАргумент
depth=1 означает, что сохраняется эта страница, а также все страницы, на которые она ссылается.Импорт списка адресов из истории посещённых страниц:
./bin/export-browser-history --chrome
archivebox add < output/sources/chrome_history.json
# или
./bin/export-browser-history --firefox
archivebox add < output/sources/firefox_history.json
# или
./bin/export-browser-history --safari
archivebox add < output/sources/safari_history.jsonИмпорт списка адресов из текстового файла:
cat urls_to_archive.txt | archivebox add
# или
archivebox add < urls_to_archive.txt
# или
curl https://getpocket.com/users/USERNAME/feed/all | archivebox addСамые популярные настройки из командной строки:
TIMEOUT=120 # default: 60 добавить больше секунд на скачивание для медленной сети или тормозного сайта CHECK_SSL_VALIDITY=True # default: False True = allow сохранение URL с некорректным SSL SAVE_ARCHIVE_DOT_ORG=False # default: True отключить дублирование на Archive.org MAX_MEDIA_SIZE=1500m # default: 750m увеличить/уменьшить максимальный размер файлов для youtube-dl PUBLIC_INDEX=True # default: True публичный доступ к индексу PUBLIC_SNAPSHOTS=True # default: True публичный доступ к страницам (снапшотам) PUBLIC_ADD_VIEW=False # default: False разрешение/запрет всем пользователям добавлять URL в архив
Как вариант, можно добавлять ссылки через веб-интерфейс на локалхосте:

Сервер с веб-интерфейсом тоже запускается из командной строки:
archivebox manage createsuperuser archivebox server 0.0.0.0:8000 # открыть http://127.0.0.1:8000 # опции, упомянутые выше archivebox config --set PUBLIC_INDEX=False archivebox config --set PUBLIC_SNAPSHOTS=False archivebox config --set PUBLIC_ADD_VIEW=False
По сохранённому архиву работает полнотекстовый поиск.
Накопители
На чём хранить личный архив? Теоретически можно сбрасывать архив на компакт-диски или магнитную ленту. Но с ними возникнет проблема поиска в реальном времени. Ведь это основная функция информационного архива — выдавать информацию мгновенно по запросу. Так что самым реалистичным вариантом видится информационное хранилище на HDD (с резервированием по типу RAID).
Многое зависит от объёмов архива. Если у вас скачаны все голливудские фильмы за последние 50 лет в разрешении 4K, то не остаётся вариантов, кроме магнитной ленты. Современные картриджи формата LTO-9 объёмом 45 терабайт стоят не очень дорого.

Копия памяти человека
Кто-то считает, что нужно сохранять в архиве всю информацию, какую человек когда-либо увидел или прочитал, в том числе фотографии, видеоролики, заметки, книги, веб-страницы, статьи. Возможно, даже записи с видеорегистратора, который постоянно работает и записывает всё, что происходит вокруг. Желательно свои мысли тоже записывать (в которых есть смысл).
Такой архив — это своеобразная «цифровая память» человека, копия его жизни, всех событий и воспоминаний, с полнотекстовым поиском. Цифровая копия всего, что попадало в мозг или возникало в нём самопроизвольно. Впрочем, это уже ближе к киберпанку.
НЛО прилетело и оставило здесь промокоды для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
— 20% на выделенные серверы AMD Ryzen и Intel Core — HABRFIRSTDEDIC.
Доступно до 31 декабря 2021 г.
![[Личный опыт] «Разработчики не читают польские контракты, и очень зря». IT-инженер в Польше: документы, подводные камни](/upload/resize_cache/iblock/1a0/105_70_0/1a001c51c3058e94bb09d533cebd3472.jpeg "[Личный опыт] «Разработчики не читают польские контракты, и очень зря». IT-инженер в Польше: документы, подводные камни")
![[Личный опыт] Как живется в Польше: европейская инфраструктура и российские медицина и образование](/upload/resize_cache/iblock/e0f/105_70_0/e0f195fe5ec3f2c27138ea343620aedd.jpeg "[Личный опыт] Как живется в Польше: европейская инфраструктура и российские медицина и образование")


