Введение
В этой статье я хочу простым языком рассказать о некоторых особенностях работы реактивного веб-сервиса в сравнении с традиционным REST. На данном этапе не буду углубляться в спецификацию. Предполагается базовое знание Java, Spring Boot. У вас должны быть установлены среда разработки, JDK 8+, Maven.
Представим, что у нас есть ресторан быстрого питания. Оператор принимает заказ от клиента, передает его повару и ждет, пока повар готовит. Когда заказ приготовлен, клиент получает его и только после этого оператор может принять следующий заказ. Такой синхронный и блокирующий рабочий процесс приведет к тому, что в нашем ресторане выстроится длинная очередь и клиенты будут, мягко говоря, недовольны.

Давайте организуем рабочий процесс в реактивном стиле, который асинхронен и неблокирующий. Оператор будет принимать заказ, передавать его повару и, не дожидаясь пока повар его приготовит, принимать следующий. Сделав заказ, клиент подписывается на получение готового заказа. Клиент — это Subscriber, а повар — Publisher.
Подготовка
В качестве примера напишем простое веб приложение, которое возвращает данные в формате JSON. В приложении будет два эндпоинта: "/products" и "/products/stream". Первая возвращает List<Product> на синхронный блокирующий запрос, вторая возвращает Flux<Product> на асинхронный неблокирующий запрос.
Создадим Spring Boot приложение (я использую Spring Initializr). Сборка Maven, Spring Boot версия 2.7.17, Java 11.

Добавим зависимости: Spring Reactive Web для webflux и Lombok чтобы избавиться от шаблонного кода.

Напишем главный класс:
package ru.programstore.prostowebflux;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ProstoWebfluxApplication {
public static void main(String[] args) {
SpringApplication.run(ProstoWebfluxApplication.class, args);
}
}Запустим приложение, чтобы убедиться в его работоспособности и посмотрим логи в консоли IDE. По умолчанию Spring Boot приложение запускается на Tomcat сервере, но при добавлении зависимости Spring Reactive Web начинаем использовать сервер Netty. Что и видим в логах.
Наше приложение запущено на Netty на порту 8080:

Блокирующий подход
Напишем наш DTO класс:
package ru.programstore.prostowebflux.dto;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class ProductDto {
private int id;
private String name;
}В этом примере не используется база данных, в качестве источника данных — список объектов в DAO классе:
package ru.programstore.prostowebflux.dao;
import org.springframework.stereotype.Component;
import ru.programstore.prostowebflux.dto.ProductDto;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
@Component
public class ProductDao {
private final List<String> productNames = List.of("Чикен Бургер", "Биг Спешиал Ростбиф", "Плов рыбный",
"Двойной Чизбургер", "Биг Спешиал", "Чикен Премьер", "Наггетсы", "Тост с ветчиной", "Пирожок с кудябликами",
"Клецки свекольные");
public List<ProductDto> getProducts() {
return IntStream.rangeClosed(1, productNames.size())
.peek(i -> System.out.println("processing count: " + i))
.mapToObj(i -> new ProductDto(i, productNames.get(i - 1)))
.collect(Collectors.toList());
}
}В сервисном классе инжектим наш DAO и вызываем getProducts(). Разность end - start покажет как долго выполняется традиционный REST запрос.
package ru.programstore.prostowebflux.service;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import ru.programstore.prostowebflux.dao.ProductDao;
import ru.programstore.prostowebflux.dto.ProductDto;
import java.util.List;
@Service
@RequiredArgsConstructor
public class ProductService {
private final ProductDao productDao;
public List<ProductDto> loadAllProducts() {
long start = System.currentTimeMillis();
List<ProductDto> products = productDao.getProducts();
long end = System.currentTimeMillis();
System.out.println("Total execution time : " + (end - start));
return products;
}
}В контроллере инжектим сервис и создаем традиционный REST endpoint:
package ru.programstore.prostowebflux.controller;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import ru.programstore.prostowebflux.dto.ProductDto;
import ru.programstore.prostowebflux.service.ProductService;
import java.util.List;
@RestController
@RequestMapping("/products")
@RequiredArgsConstructor
public class ProductController {
private final ProductService service;
@GetMapping
public List<ProductDto> getAllProducts() {
return service.loadAllProducts();
}
}Total execution time в консоли покажет количество миллисекунд, потраченное на выполнение данного метода.
Перезапускаем приложение и в браузере идем на http://localhost:8080/products

Вывод в консоли IDE:

Тут мы видим, что наш запрос выполнен за 1 миллисекунду.
Имея 10 записей в нашем источнике данных, мы не увидим разницы в производительности между традиционным REST запросом и реактивным. Сымитируем задержку между элементами стрима.
Добавим в наш DAO приватный метод для имитации задержки:
private void sleepExecution() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}В методе getProducts() добавим промежуточный вызов метода sleepExecution()
public List<ProductDto> getProducts() {
return IntStream.rangeClosed(1, productNames.size())
.peek(i -> System.out.println("processing count: " + i))
.peek(it -> sleepExecution())
.mapToObj(i -> new ProductDto(i, productNames.get(i - 1)))
.collect(Collectors.toList());
}Теперь если выполняем GET запрос на http://localhost:8080/products , на стороне сервера он выполняется ~10000 миллисекунд:
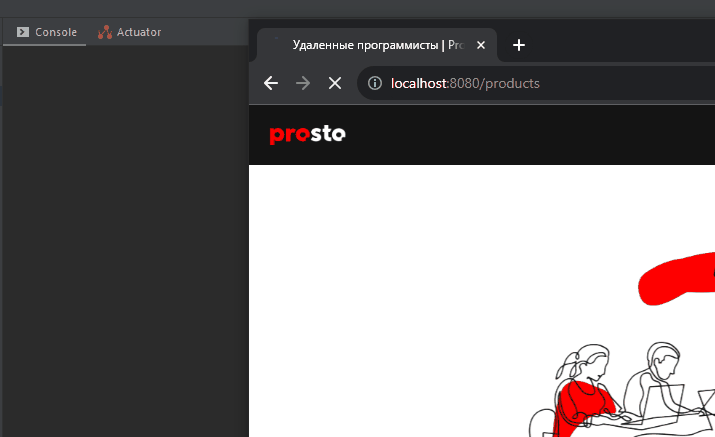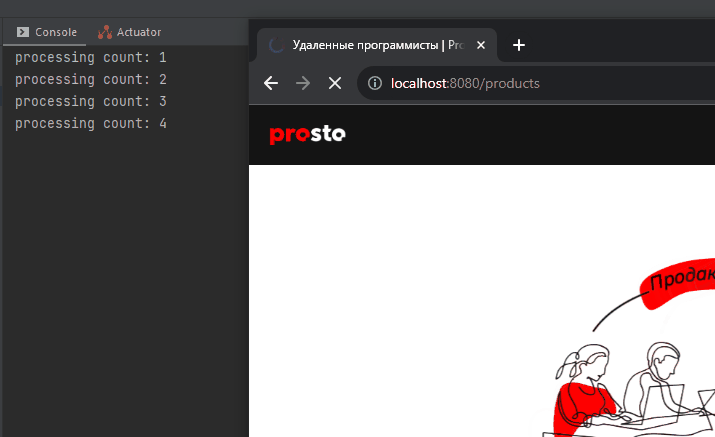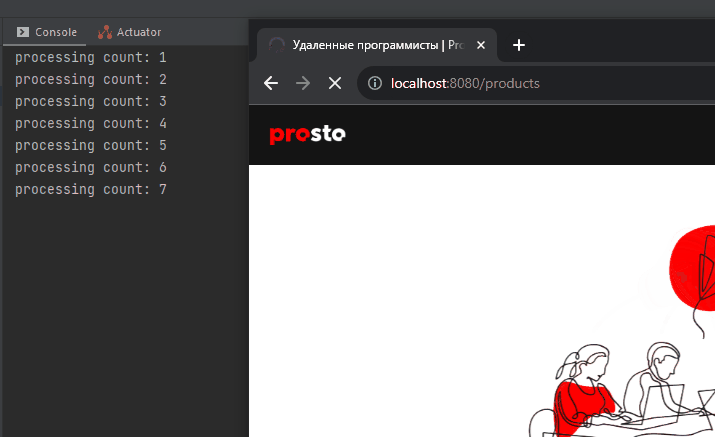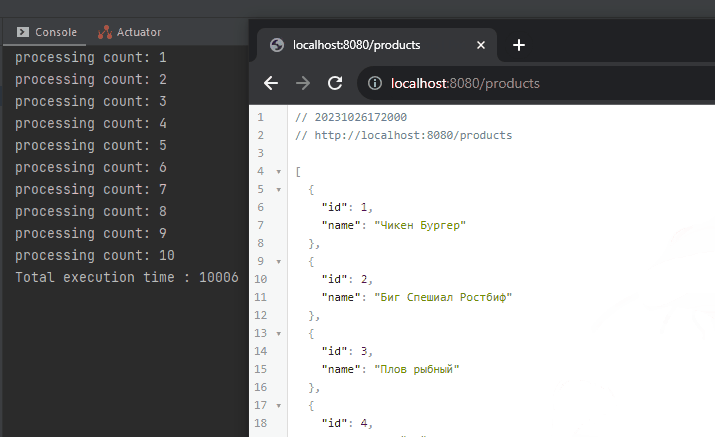
Когда выполнение запроса завершено на сервере, в клиенте выводятся запрашиваемые данные.
Таким образом, мы увидели синхронную и блокирующую работу нашего REST сервиса. Здесь Subscriber не получает данные до тех пор, пока Publisher не выполнил запрос до конца. Если бы у нас было не десять записей, а миллион, нам не пришлось бы имитировать задержку.
Реактивный подход
Теперь попробуем реактивный подход. В нашем DAO классе напишем реактивную версию метода getProducts():
public Flux<ProductDto> getProductsReactive() {
return Flux.range(1, productNames.size())
.delayElements(Duration.ofSeconds(1))
.doOnNext(i -> System.out.println("processing count: " + i))
.map(i -> new ProductDto(i, productNames.get(i - 1)));
}Возвращаемое значение, на этот раз, Flux<Product>вместо List<Product>. Класс Flux имплементирует Publisher, по сути представляет из себя поток(stream) от 0 до N элементов.
Вместо IntStream.rangeClosed напрямую используем метод range() класса Flux. Вместо mapToObj() — map().
Вместо peek() — метод doOnNext() из класса Flux, который добавляет поведение когда отдельно взятый элемент воспроизведен потоком. В нашем случае это вывод в консоль.
Вместо вызова метода sleepExecution() задерживаем поток delayElements(Duration.ofSeconds(1)).
В сервисном классе вызываем этот метод:
public Flux<ProductDto> loadAllProductsReactive() {
long start = System.currentTimeMillis();
Flux<ProductDto> products = productDao.getProductsReactive();
long end = System.currentTimeMillis();
System.out.println("Total execution time : " + (end - start));
return products;
}В контроллере добавляем endpoint, который отправляет данные слушателям в виде TEXT_EVENT_STREAM_VALUE:
@GetMapping(value = "/reactive",
produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ProductDto> getAllCustomersReactive() {
return service.loadAllProductsReactive();
}Перезапускаем приложение. В браузере делаем запрос на http://localhost:8080/products/reactive

Мы видим Total execution time = 0.
В данном случае не надо путать это значение с тем, за какое время клиент у себя увидит весь результат. На скриншоте выше это наглядно проиллюстрировано: на экран выводится сразу не весь список, а по одному с указанной нами задержкой в 1 секунду.
Учитывая установленную нами задержку в 1 секунду перед получением каждого элемента из списка, общее время получения результата будет одинаковым ~10 секунд.
Итоги
Пример в данной статье показывает, что время для получения всего результата будет одинаковым, но есть нюансы.
В блокирующем подходе Spring MVC использует и не отпускает поток пока полностью не завершит свою работу, а в реактивном подходе поток будет освобожден при вызове блокирующей задачи (в нашем случае sleep), а как только получит результат — возьмет первый свободный поток. Благодаря этому различию видим разный эффект в браузере (в блокирующем ждем ~10 секунд и получаем весь результат, а в реактивном — видим построчный вывод).
Для того, чтобы максимально эффективно использовать Spring WebFlux, необходимо сделать приложение полностью неблокирующим. По этой причине не стоит использовать стандартное JDBC. Вместо него необходимо использовать R2DBC для взаимодействия с реляционной СУБД. Но в таком случае мы получим ряд ограничений. Конкретно на них не будем останавливаться, т.к. это уже выходит за рамки данной статьи.
Вышесказанное не значит, что при использовании Spring WebFlux мы не можем взаимодействовать с блокирующими внешними источниками. Совершенно нормально использовать взаимодействие микросервисов с разными подходами. Например, наш реактивный сервис может обращаться к блокирующему микросервису, который работает с СУБД используя JDBC.
Также не стоит забывать, что блокирующий подход Spring MVC более прост и понятен в разработке за счет императивного подхода. Перед выбором подхода для своего сервиса рекомендую хорошо проанализировать свою ситуацию и сравнить плюсы и минус обоих решений. Зачастую блокирующий вариант Spring MVC будет для вас хорошим решением.
А вы на какой стороне?



 + масштабирование нагрузки через Nginx балансер")
