
Как обновить значение атрибута для всех записей таблицы? Как добавить первичный или уникальный ключ в таблицу? Как разбить таблицу на две? Как ...
Если приложение может быть недоступно какое-то время для проведения миграций, то ответы на эти вопросы не представляют сложности. А что делать, если миграции нужно проводить на горячую — не останавливая базу данных и не мешая другим с ней работать?
На эти и другие вопросы, возникающие при проведении миграций схемы и данных в PostgreSQL, постараемся дать ответы в виде практических советов.
Эта статья – расшифровка выступления на конференции SmartDataConf (здесь можно найти презентацию, со временем появится видео). Текста получилось много, поэтому материал будет разбит на 2 статьи:
- базовые миграции
- подходы по обновлению больших таблиц.
В конце есть выжимка всей статьи в виде сводной таблицы-шпаргалки.
Содержание
Суть проблемы
Добавление столбца
Добавление столбца со значением по умолчанию
Удаление столбца
Создание индекса
Создание индекса для партиционированной таблицы
Создание ограничения NOT NULL
Создание внешнего ключа
Создание ограничения уникальности
Создание первичного ключа
Краткая шпаргалка с миграциями
Суть проблемы
Предположим, что у нас есть приложение, которое работает с базой данных. В минимальной конфигурации оно может состоять из 2 узлов – самого приложения и базы данных, соответственно.

При такой схеме обновления приложения зачастую происходят с простоем (downtime). В это же время можно обновлять БД. В такой ситуации главный критерий – это время, то есть нужно выполнить миграцию как можно быстрее, чтобы минимизировать время недоступности сервиса.
Если приложение растет и появляется необходимость проводить релизы без простоя, мы начинаем использовать несколько серверов приложений. Их может быть сколько угодно, и они будут на разных версиях. В этом случае появляется необходимость обеспечения обратной совместимости.

На следующем этапе роста данные перестают влезать в одну БД. Мы начинаем масштабировать также и БД – путем шардирования. Поскольку на практике синхронно проводить миграции нескольких баз данных очень сложно, это значит, что в какой-то момент они будут иметь разные схемы данных. Соответственно, мы будем работать в гетерогенной среде, где сервера приложений могут иметь разный код, а базы данных разные схемы данных.
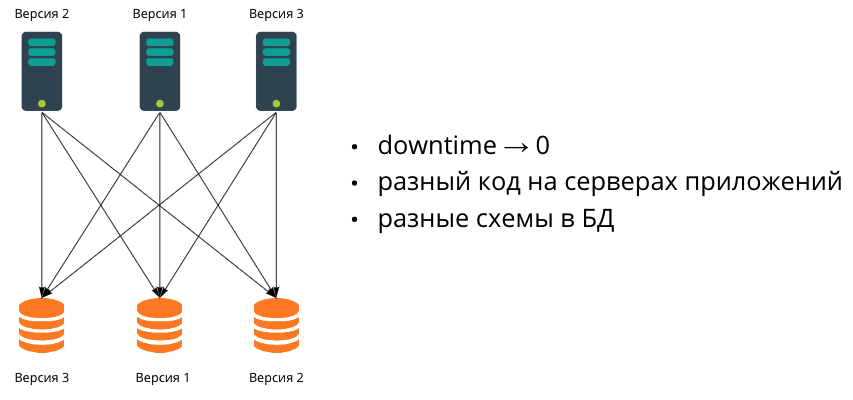
Именно про такую конфигурацию мы поговорим в этой статье и рассмотрим самые популярные миграции, которые пишут разработчики – от простых к более сложным.
Наша цель – проводить SQL-миграции с минимальным влиянием на работу приложения, т.е. изменять данные или схему данных таким образом, чтобы приложение продолжало работать и пользователи ничего не замечали.
Добавление столбца
ALTER TABLE my_table ADD COLUMN new_column INTEGER -- быстро и безопасно
Наверное, любой человек, который работает с БД, писал подобную миграцию. Если говорить про PostgreSQL, то такая миграция весьма дешевая и безопасная. Сама команда, хоть и захватывает блокировку самого высокого уровня (AccessExclusive), выполняется очень быстро, поскольку «под капотом» происходит лишь добавление метаинформации о новом столбце без перезаписи данных самой таблицы. В большинстве случаев это происходит незаметно. Но проблемы могут возникнуть, если в момент миграции есть долгие транзакции, работающие с этой таблицей. Чтобы понять суть проблемы рассмотрим на небольшом примере как упрощенно работают блокировки в PostgreSQL. Этот аспект будет очень важен при рассмотрении большинства других миграций в том числе.
Предположим, у нас есть большая таблица, и мы делаем из нее SELECT всех данных. В зависимости от размера БД и самой таблицы он может длиться несколько секунд или даже минут.

На время выполнения транзакции захватывается самая слабая блокировка AccessShare, которая защищает от изменений структуры таблицы.
В этот момент приходит другая транзакция, которая как раз таки пытается сделать запрос ALTER TABLE к этой таблице. Команда ALTER TABLE, как уже было сказано ранее, захватывает блокировку AccessExclusive, которая не совместима вообще ни с какой другой. Она встает в очередь.
Эта очередь блокировок «разгребается» в строгом порядке, т.е. даже если после ALTER TABLE приходят другие запросы (например, также SELECTы), которые сами по себе не конфликтуют с первым запросом, они все встают в очередь за ALTER TABLE. В итоге приложение «встало» и ждет, пока ALTER TABLE выполнится.
Что делать в такой ситуации? Можно ограничить время захвата блокировки с помощью команды SET lock_timeout. Выполняем эту команду перед ALTER TABLE (ключевое слово LOCAL означает, что настройка действует только в пределах текущей транзакции, иначе – в пределах текущей сессии):
SET LOCAL lock_timeout TO '100ms'
и если за 100 миллисекунд команда не сможет получить блокировку, она закончится неудачей. Затем мы либо повторно ее перезапускаем, ожидая, что она выполнится успешно, либо идем разбираться почему транзакция выполняется долго, если такого в нашем приложении быть не должно. В любом случае – главное, что мы не завалили приложение.
Стоит сказать, что установка таймаута полезна перед любой командой, которая захватывает строгую блокировку.
Добавление столбца со значением по умолчанию
-- быстро и безопасно с PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42
Если эта команда выполняется в PostgreSQL старой версии (ниже 11), то это приводит к перезаписи всех строк в таблице. Очевидно, что если таблица большая, то это может занять много времени. А поскольку на время выполнения захватывается строгая блокировка (AccessExclusive), то все запросы к таблице также блокируются.
Если версия PostgreSQL 11 или свежее, эта операция обходится весьма дешево. Дело в том, что в 11й версии была сделана оптимизация, благодаря которой вместо перезаписи таблицы значение по умолчанию сохраняется в специальную таблицу pg_attribute, и в дальнейшем при выполнении SELECT, все пустые значения этого столбца будут «на лету» заменяться на это значение. При этом впоследствии, когда будет происходить перезапись строк в таблице из-за других модификаций, значение будет записываться в эти строки.
Более того, с 11й версии также можно сразу создавать новый столбец и помечать его как NOT NULL:
-- быстро и безопасно с PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42 NOT NULL
Как быть, если PostgreSQL старше, чем 11?
Миграцию можно провести в несколько шагов. Сперва создаем новый столбец без ограничений и значений по умолчанию. Как уже было сказано ранее, это дешево и быстро. В той же транзакции изменяем этот столбец, добавляя значение по умолчанию.
ALTER TABLE my_table ADD COLUMN new_column INTEGER;
ALTER TABLE my_table ALTER COLUMN new_column SET DEFAULT 42;
Такое разделение одной команды на две может показаться немного странным, но механика такова, что когда создается новый столбец сразу же со значением по умолчанию, оно влияет на все записи, которые есть в таблице, а когда значение устанавливаете для уже существующего столбца (пусть даже только что созданного, как в нашем случае), то это влияет только на новые записи.
Таким образом после выполнения этих команд, нам остается обновить значения, которые уже были в таблице. Грубо говоря, нам нужно сделать примерно вот так:
UPDATE my_table set new_column = 42 -- небезопасно на большой таблице
Но такой UPDATE «в лоб» делать на самом деле нельзя, поскольку при обновлении большой таблицы мы надолго заблокируем всю таблицу. Во второй статье (здесь в будущем будет ссылка) мы рассмотрим, какие существуют стратегии для обновления больших таблиц в PostgreSQL, а пока будем предполагать, что мы каким-то образом обновили данные, и теперь и старые данные, и новые будут с необходимым значением по умолчанию.
Удаление столбца
ALTER TABLE my_table DROP COLUMN new_column -- быстро и безопасно
Здесь логика такая же, как и при добавлении столбца: данные таблицы не модифицируются, происходит только изменение метаинформации. В данном случае столбец помечается как удаленный и недоступный при запросах. Это объясняет тот факт, что при удалении столбца в PostgreSQL физически место не освобождается (если не выполнять VACUUM FULL), то есть данные старых записей по-прежнему остаются в таблице, но недоступны при обращении. Освобождение происходит постепенно при перезаписи строк в таблице.
Таким образом, сама миграция простая, но, как правило, ошибки иногда встречаются на стороне бэкенда. Перед тем, как удалять столбец, нужно сделать несколько простых подготовительных шагов.
- Для начала необходимо убрать все ограничения (NOT NULL, CHECK, ...), которые есть на этом столбце:
ALTER TABLE my_table ALTER COLUMN new_column DROP NOT NULL - Следующий шаг – обеспечить совместимость бэкенда. Нужно убедиться, что столбец нигде не используется. Например, в Hibernate необходимо пометить поле с помощью аннотации
@Transient. В JOOQ, который мы используем, поле добавляется в исключения с помощью тэга<excludes>:
<excludes>my_table.new_column</excludes>
Также нужно внимательно посмотреть на запросы"SELECT *"– фреймворки могут «мапить» все столбцы в структуру в коде (и наоборот) и, соответственно, снова можно столкнуться с проблемой обращения к несуществующему столбцу.
После вывода изменений на все сервера приложений можно удалить столбец.
Создание индекса
CREATE INDEX my_table_index ON my_table (name) -- небезопасно, блокировка таблицы
Те, кто работает с PostgreSQL, наверное, знают, что такая команда блокирует всю таблицу. Но еще с очень старой версии 8.2 существует ключевое слово CONCURRENTLY, которое позволяет создавать индекс в неблокирующем режиме.
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name) -- безопасно
Команда работает медленнее, но не мешает параллельным запросам.
У этой команды есть один нюанс. Она может завершиться ошибкой – например, при создании уникального индекса в таблице, содержащей дублирующиеся значения. Индекс при этом будет создан, но он будет помечен как невалидный и не будет использоваться в запросах. Статус индекса можно проверить при помощи следующего запроса:
SELECT pg_index.indisvalid
FROM pg_class, pg_index
WHERE pg_index.indexrelid = pg_class.oid
AND pg_class.relname = 'my_table_index'В такой ситуации нужно удалить старый индекс, поправить значения в таблице и затем создать его заново.
DROP INDEX CONCURRENTLY my_table_index
UPDATE my_table ...
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name)
Важно заметить, что команда REINDEX, которая как раз предназначена для пересоздания индекса, до 12й версии работает только в блокирующем режиме, что не дает возможности ее использовать. В 12й версии PostgreSQL появилась поддержка CONCURRENTLY, и теперь и ей можно пользоваться.
REINDEX INDEX CONCURRENTLY my_table_index -- с PG 12
Создание индекса для партиционированной таблицы
Отдельно стоит обсудить создание индексов для партиционированных таблиц. В PostgreSQL существует 2 вида партиционирования: через наследование и декларативное, появившееся в 10й версии. Рассмотрим оба на простом примере.
Предположим, что мы хотим партиционировать таблицу по дате, и каждая партиция будет содержать данные за один год.
При партиционировании через наследование мы будем иметь примерно следующую схему.
Родительская таблица:
CREATE TABLE my_table (
...
reg_date date not null
)
Дочерние партиции для 2020 и 2021 годов:
CREATE TABLE my_table_y2020 (
CHECK ( reg_date >= DATE '2020-01-01' AND reg_date < DATE '2021-01-01' ))
INHERITS (my_table);
CREATE TABLE my_table_y2021 (
CHECK ( reg_date >= DATE '2021-01-01' AND reg_date < DATE '2022-01-01' ))
INHERITS (my_table);
Индексы по полю партиционирования для каждой из партиций:
CREATE INDEX ON my_table_y2020 (reg_date);
CREATE INDEX ON my_table_y2021 (reg_date);
Создание триггера/правила для вставки данных в таблицу оставим за рамками.
Самое важное здесь то, что каждая из партиций – это практически самостоятельная таблица, которая обслуживается по отдельности. Таким образом, создание новых индексов также проводится как с обычными таблицами:
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name);
CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
Теперь рассмотрим декларативное партиционирование.
CREATE TABLE my_table (...) PARTITION BY RANGE (reg_date);
CREATE TABLE my_table_y2020 PARTITION OF my_table FOR VALUES FROM ('2020-01-01') TO ('2020-12-31');
CREATE TABLE my_table_y2021 PARTITION OF my_table FOR VALUES FROM ('2021-01-01') TO ('2021-12-31');
Создание индексов зависит от версии PostgreSQL. В 10й версии индексы создаются по отдельности – точно так же как в предыдущем подходе. Соответственно, создание новых индексов для существующей таблицы также производится аналогично.
В 11й версии декларативное партиционирование было доработано и теперь таблицы обслуживаются вместе. Создание индекса на родительской таблице автоматически приводит к созданию индексов для всех существующих и новых партиций, которые будут созданы в будущем:
-- с PG 11 удобно для новой (пустой) партиционированной таблицы
CREATE INDEX ON my_table (reg_date)
Это удобно при создании партиционированной таблицы, но неприменимо при создании нового индекса для уже существующей таблицы, поскольку команда захватывает строгую блокировку на время создания индексов.
CREATE INDEX ON my_table (name) -- блокировка таблиц
К сожалению, CREATE INDEX не поддерживает ключевое слово CONCURRENTLY для партиционированных таблиц. Чтобы обойти ограничение и провести миграцию без блокировок можно сделать следующее.
- Создать индекс для родительской таблицы с опцией ONLY
CREATE INDEX my_table_index ON ONLY my_table (name)
Команда создаст пустой невалидный индекс без создания индексов для партиций. - Создать индексы для каждой из партиций:
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name); CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name); - Прикрепить индексы партиций к индексу родительской таблицы:
Как только все индексы будут прикреплены, индекс родительской таблицы автоматически станет валидным.ALTER INDEX my_table_index ATTACH PARTITION my_table_y2020_index; ALTER INDEX my_table_index ATTACH PARTITION my_table_y2021_index;
Ограничения
Теперь пройдемся по ограничениям: NOT NULL, внешние, уникальные и первичные ключи.
Создание ограничения NOT NULL
ALTER TABLE my_table ALTER COLUMN name SET NOT NULL -- блокировка таблицы
Создание ограничения таким образом приведет к сканированию всей таблицы – все строки будут проверены на условие not null, и если таблица большая, то это может занять длительное время. Строгая блокировка, захватываемая этой командой, заблокирует все параллельные запросы до ее завершения.
Что можно сделать? В PostgreSQL есть другой тип ограничения, CHECK, с помощью которого можно получить желаемый результат. Это ограничение проверяет любое булево условие, состоящее из столбцов строки. В нашем случае условие тривиально –
CHECK (name IS NOT NULL). Но самое важное то, что ограничение CHECK поддерживает невалидность (ключевое слово NOT VALID):ALTER TABLE my_table ADD CONSTRAINT chk_name_not_null
CHECK (name IS NOT NULL) NOT VALID -- безопасно, с PG 9.2
Созданное таким образом ограничение действует только для вновь добавляемых и изменяемых записей, а существующие не проверяются, поэтому сканирования таблицы не происходит.
Для обеспечения гарантии, что существующие записи также удовлетворяют ограничению необходимо провести его валидацию (конечно же, предварительно обновив данные в таблице):
ALTER TABLE my_table VALIDATE CONSTRAINT chk_name_not_null
Команда итерируется по строкам таблицы и проверяет, что все записи не not null. Но в отличие от обычного NOT NULL ограничения, блокировка, захватываемая в этой команде, не такая строгая (ShareUpdateExclusive) – она не блокирует операции insert, update и delete.
Создание внешнего ключа
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) -- блокировка обеих таблиц
При добавлении внешнего ключа все записи дочерней таблицы проверяются на наличие значения в родительской. Если таблица большая, то это сканирование будет долгим, и блокировка, которая удерживается на обеих таблицах, также будет долгой.
К счастью, внешние ключи в PostgreSQL также поддерживают NOT VALID, а это значит мы можем использовать тот же подход, что был рассмотрен ранее с CHECK. Создаем невалидный внешний ключ:
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) NOT VALID
затем обновляем данные и проводим валидацию:
ALTER TABLE my_table VALIDATE CONSTRAINT fk_group_id
Создание ограничения уникальности
ALTER TABLE my_table ADD CONSTRAINT uk_my_table UNIQUE (id) -- блокировка таблицы
Как и в случае с ранее рассмотренными ограничениями, команда захватывает строгую блокировку, под которой проводит проверку всех строк в таблице на соответствие ограничению – в данном случае уникальности.
Важно знать, что «под капотом» PostgreSQL реализует уникальные ограничения с помощью уникальных индексов. Иными словами, когда создается ограничение, происходит создание соответствующего уникального индекса с таким же наименованием, который обслуживает это ограничение. С помощью следующего запроса можно узнать обслуживающий индекс ограничения:
SELECT conindid index_oid, conindid::regclass index_name
FROM pg_constraint
WHERE conname = 'uk_my_table_id'
При этом большая часть времени создания ограничения как раз таки уходит на индекс, а его последующая привязка к ограничению происходит очень быстро. Более того, если у вас уже есть созданный уникальный индекс, то такую привязку можно осуществить самостоятельно, создавая индекс с помощью ключевых слов USING INDEX:
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id UNIQUE
USING INDEX uk_my_table_id -- быстро, с PG 9.1
Таким образом, идея простая – создаем уникальный индекс CONCURRENTLY, как мы рассматривали ранее, и затем на его основе создаем уникальное ограничение.
В этот момент может возникнуть вопрос – зачем вообще создавать ограничение, если индекс выполняет ровно то, что требуется – гарантирует уникальность значений? Если исключить из сравнения partial индексы, то с функциональной точки зрения результат действительно почти идентичен. Единственное отличие, которое удалось найти, состоит в том, что ограничения могут быть отложенными (deferrable), а индексы – нет. В документации к старым версиям PostgreSQL (до 9.4 включительно) была сноска с информацией о том, что предпочтительный способ создания ограничения уникальности – это явное создание ограничения
ALTER TABLE ... ADD CONSTRAINT, а использование индексов стоит рассматривать как деталь реализации. Однако, в более свежих версиях эту сноску удалили.Создание первичного ключа
Первичный ключ помимо уникальности накладывает ограничение not null. Если столбец изначально имел такое ограничение, то «превратить» его в первичный ключ не составит труда – также создаем уникальный индекс CONCURRENTLY, а затем первичный ключ:
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id PRIMARY KEY
USING INDEX uk_my_table_id -- если id is NOT NULL
Важно отметить, что столбец должен иметь «честное» ограничение NOT NULL – рассмотренный ранее подход с помощью CHECK не сработает.
Если же ограничения нет, то до 11-й версии PostgreSQL ничего не поделать – без блокировки первичный ключ никак не создать.
Если у вас 11-й PostgreSQL или свежее, эту задачу можно решить путем создания нового столбца, который будет заменять существующий. Итак, по шагам.
Создаем новый столбец, который по умолчанию not null и имеет значение по умолчанию:
ALTER TABLE my_table ADD COLUMN new_id INTEGER NOT NULL DEFAULT -1 -- безопасно с PG 11
Настраиваем синхронизацию данных старого и нового столбцов с помощью триггера:
CREATE FUNCTION on_insert_or_update() RETURNS TRIGGER AS
$$
BEGIN
NEW.new_id = NEW.id;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg BEFORE INSERT OR UPDATE ON my_table
FOR EACH ROW EXECUTE PROCEDURE on_insert_or_update();
Далее необходимо обновить данные строк, которые не затронулись триггером:
UPDATE my_table SET new_id = id WHERE new_id = -1 -- не делать на большой таблице
Запрос с обновлением выше написан «в лоб», на большой таблице так делать не стоит, т.к. будет длительная блокировка. Как уже было сказано ранее, во второй статье будут рассмотрены подходы по обновлению больших таблиц. Пока же предположим, что данные обновлены, и остается лишь поменять столбцы.
ALTER TABLE my_table RENAME COLUMN id TO old_id;
ALTER TABLE my_table RENAME COLUMN new_id TO id;
ALTER TABLE my_table RENAME COLUMN old_id TO new_id;
В PostgreSQL команды DDL транзакционные – это значит, что можно переименовывать, добавлять, удалять столбцы, и при этом параллельная транзакция не будет этого видеть в процессе своих операций.
После смены столбцов остается создать индекс и «прибраться за собой» – удалить триггер, функцию и старый столбец.
Краткая шпаргалка с миграциями
Перед любой командой, которая захватывает строгую блокировку (почти все
ALTER TABLE ...) рекомендуется вызывать:SET LOCAL lock_timeout TO '100ms'
| Миграция | Рекомендуемый подход |
|---|---|
| Добавление столбца | |
| Добавление столбца со значением по умолчанию [и NOT NULL] | c PostgreSQL 11:до PostgreSQL 11:
|
| Удаление столбца |
|
| Создание индекса | Если завершилось ошибкой:
|
| Создание индекса для партиционированной таблицы | Партиционирование через наследование + декларативное в PG 10:Декларативное партиционирование с PG 11:
|
| Создание ограничения NOT NULL |
|
| Создание внешнего ключа |
|
| Создание ограничения уникальности |
|
| Создание первичного ключа | Если столбец IS NOT NULL:
Если столбец IS NULL c PG 11:
|
В следующей статье рассмотрим подходы по обновлению больших таблиц.
Всем легких миграций!




