
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

SQL – это не скучно. С современными инструментами возможности языка кратно возросли. Мультитул для моделирования данных dbt, современные колоночные аналитические СУБД позволяют буквально творить с данными чудеса.
Меня зовут Артемий и я Analytics Engineer в компании Wheely. И сегодня я подготовил небольшой экскурс в реальные и интересные сценарии использования гибридного SQL:
Операции Pivot и Unpivot для табличных данных
Генерирование суррогатного ключа и ключа конкатенации
Гибкая фильтрация записей из таблиц-источников
Автоматизация экспорта данных из Хранилища в S3
Валютные курсы, Continuous Integration, Data Quality
Операции Pivot и Unpivot для табличных данных
Операция pivot позволяет повернуть плоскую двумерную таблицу таким образом, что значения в строках образуют новые колонки. Операция unpivot позволит выполнить обратное действие и уменьшить размерность таблицы, превратив колонки в строки. Иначе это можно назвать манипуляциями со сводными таблицами (сross-tables).
Проще всего показать это на небольших примерах:
Input: orders
| size | color |
|------|-------|
| S | red |
| S | blue |
| S | red |
| M | red |
Pivot output:
| size | red | blue |
|------|-----|------|
| S | 2 | 1 |
| M | 1 | 0 |
--------------
Input: orders
| date | size | color | status |
|------------|------|-------|------------|
| 2017-01-01 | S | red | complete |
| 2017-03-01 | S | red | processing |
Unpivot output:
| date | status | field_name | value |
|------------|------------|------------|-------|
| 2017-01-01 | complete | size | S |
| 2017-01-01 | complete | color | red |
| 2017-03-01 | processing | size | S |
| 2017-03-01 | processing | color | red |Соответствующие макросы dbt, реализующие преобразования данных через SQL, позволяют просто и гибко сформировать результирующий набор данных требуемого формата, без привязки к используемой СУБД.
Реальная ситуация, в которой это может применяться – подготовка выгрузки по заранее оговоренной структуре для внешних пользователей. Например, выгрузка пользовательских атрибутов в формате ключ-значение.
Исходный набор данных:

Результирующий набор данных:
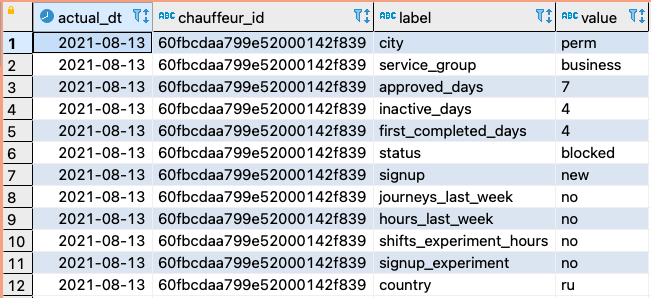
Макрос, используемый в SQL-скрипте выглядит довольно просто:
{{ dbt_utils.unpivot(
relation=ref('dim_chauffeurs_labels'),
cast_to='varchar',
exclude=['actual_dt', 'chauffeur_id'],
field_name='label',
value_name='value'
) }}Преимущество такого подхода в том, что сколько бы дополнительных атрибутов не появилось, это не потребует ни единого изменения в существующий код, что очень удобно.
Генерирование суррогатного ключа и ключа конкатенации
Использование суррогатных ключей – важнейший аспект любого хранилища данных. Это ключи, позволяющие однозначно идентифицировать строки и соединять таблицы фактов и измерений. Обычно я использую хэш-функции, подавая на вход значения бизнес-ключей из систем-источников. Эта практика также широко распространена в Data Vault 2.0 и позволяет иметь согласованные результаты между данными из различных источников.
Но иногда в случае составного ключа вы хотели бы сохранить интерпретируемость и читаемость (human-readable) всех значений. В частности это особенно актуально в маркетинговой аналитике, где ключ строки может содержать набор меток: utm_source, utm_medium, utm_campaign, ads_group_id, keyword_id.
Удобочитаемые (human-readable) значения помогают быстро отслеживать источники и исправлять баги, в то время как хешированные суррогатные ключи используются для оптимальных соединений таблиц:
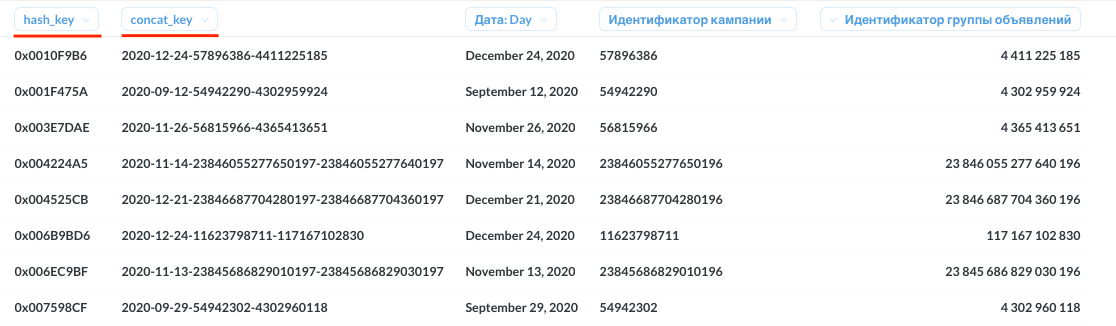
Генерация этих ключей выполняется с помощью макросов hash(), concat(), surrogate_key() (адаптер MS SQL):
hash(), concat(), surrogate_key() macros
------------------------
--- MSSQL hash macro ---
------------------------
{% macro hash(field) -%}
HASHBYTES('SHA2_256', {{field}})
{%- endmacro %}
--------------------------
--- MSSQL concat macro ---
--------------------------
{% macro concat(fields) -%}
concat({{ fields|join(', ') }})
{%- endmacro %}
--------------------------
--- Surrogate hash key ---
--------------------------
{%- macro surrogate_key(field_list) -%}
{%- if varargs|length >= 1 %}
{%- do exceptions.warn("Warning: the `surrogate_key` macro now takes a single list argument instead of multiple string arguments. Support for multiple string arguments will be deprecated in a future release of dbt-utils.") -%}
{# first argument is not included in varargs, so add first element to field_list_xf #}
{%- set field_list_xf = [field_list] -%}
{%- for field in varargs %}
{%- set _ = field_list_xf.append(field) -%}
{%- endfor -%}
{%- else -%}
{# if using list, just set field_list_xf as field_list #}
{%- set field_list_xf = field_list -%}
{%- endif -%}
{%- set fields = [] -%}
{%- for field in field_list_xf -%}
{%- set _ = fields.append(
"coalesce(cast(" ~ field ~ " as NVARCHAR " ~ "), '')"
) -%}
{%- if not loop.last %}
{%- set _ = fields.append("'-'") -%}
{%- endif -%}
{%- endfor -%}
{# {{ concat(fields) }} #}
{{ mybi_dbt_core.hash(mybi_dbt_core.concat(fields)) }}
{%- endmacro -%}Следует обратить особое внимание на следующие моменты:
Преобразование составных значений атрибутов в текстовую форму
Обработка значений null, если таковые присутствуют
Последовательность соединения атрибутов ключа
Использование разделителя между значениями ключа (тире, подчеркивания или любого другого)
Вызов макросов в коде выглядит следующим образом:
select
{{ surrogate_key(["dt", "campaign_id", "ads_id"]) }} as hash_key
, {{ concat_key(["dt", "campaign_id", "ads_id"]) }} as concat_keyАктуальный код, который будет запущен в СУБД (скомпилированная версия):
select
HASHBYTES('SHA2_256', concat(coalesce(cast([dt] as NVARCHAR ), ''), '-', coalesce(cast([campaign_id] as NVARCHAR ), ''), '-', coalesce(cast([ads_id] as NVARCHAR ), ''))) as hash_key
, concat(coalesce(cast([dt] as NVARCHAR ), ''), '-', coalesce(cast([campaign_id] as NVARCHAR ), ''), '-', coalesce(cast([ads_id] as NVARCHAR ), '')) as concat_keyГибкая фильтрация записей из таблиц-источников
Как правило Хранилище Данных объединяет информацию из десятков или даже сотен источников. Каждый из них обладает своими особенностями и в разных случаях имеет смысл ограничивать выборки, обращаясь к исходным данным.
Имейте в виду следующие сценарии:
Чтение актуальных данных (deleted_flag is not true)
Формирование ограниченной выборки для разработки и Continuous Integration
Поиск дельты для инкрементального наполнения витрин
При этом помните, что названия колонок, по которым мы фильтруем данные могут отличаться от источника к источнику. Различаться могут также и типы данных – epoch (bigint) vs timestamp.
Все эти вводные хорошо ложатся на шаблонизированное формирование выражений в конструкции WHERE.
select
...
from {{ source('backend', 'orders') }}
{{ hevo_filter_rows(
deleted_rows_filter=true,
last_n_days_of_data=false,
timestamp_column='created_at',
incremental_column='__metadata_timestamp'
) }}Сам макрос может выглядеть следующим образом (с пояснениями):
macro hevo_filter_rows()
-- filter data for deleted rows; resize for dev, ci pipelines; apply incremental load filters
{% macro hevo_filter_rows(
deleted_rows_filter=true,
last_n_days_of_data=false,
timestamp_column='created_at',
incremental_column='__metadata_timestamp'
) -%}
{#- prepare expression to filter deleted rows by flag __hevo__marked_deleted where it exists -#}
{%- set deleted_rows_expression = '__hevo__marked_deleted is not true' if deleted_rows_filter == true else '1 = 1' -%}
{#- cast epoch to timestamp if necessary -#}
{%- set timestamp_column = epoch_to_timestamp('__hevo__ingested_at')
if timestamp_column == '__hevo__ingested_at' else timestamp_column -%}
{#- prepare expression to filter rows to last 'development_days_of_data' (e.g. last 3 days) -#}
{% set get_dev_watermark_query = 'select dateadd(day, ' ~ -1 * var('development_days_of_data') ~ ', current_timestamp::date)' %}
{# {{ log("get_dev_watermark_query: " ~ get_dev_watermark_query, info=True) }} #}
{% if execute %}
{% set dev_watermark = "'" ~ run_query(get_dev_watermark_query).columns[0][0] ~ "'" %}
{% endif %}
{%- set dev_rows_expression = timestamp_column ~ ' >= ' ~ dev_watermark
if target.name in ['dev', 'ci'] and last_n_days_of_data == true else '1 = 1' -%}
{#- prepare expression to filter only delta rows on incremental build -#}
{%- set incremental_expression =
epoch_to_timestamp('__hevo__ingested_at') ~ '
>= dateadd(h, -24, (select max(' ~ incremental_column ~ ') from ' ~ this ~ '))'
if is_incremental() else '1 = 1' -%}
{#- prepare final filter expression -#}
where 1 = 1
and {{ deleted_rows_expression }}
and {{ dev_rows_expression }}
and {{ incremental_expression }}
{%- endmacro -%}Результат для первого (с нуля) формирования таблицы в dev-контуре:
select
...
from {{ source('backend', 'orders') }}
where 1 = 1
and __hevo__marked_deleted is not true
and created_at >= '2021-08-10 00:00:00'
and 1 = 1
Автоматизация экспорта данных из Хранилища в S3
А теперь давайте вспомним первый пример, где мы формировали unpivot-таблицу для внешних пользователей. Предположим, что в этот раз они обратились к нам с просьбой сформировать выгрузку не внутри Хранилища, но как плоские файлы в Object Storage (S3).
Вполне реальный сценарий. Мы могли бы начать думать об инструментах, которые способны это сделать, выстраивать пайплайны, выбирать языки программирования, но не следует привлекать новые сущности без крайней на то необходимости. Воспользуемся тем, что умеет сама СУБД.
Операция UNLOAD (синтаксис Amazon Redshift), выполняемая как post-hook модели dbt:
UNLOAD to S3
{{
config(
materialized='view',
post_hook=[
"
{%- if target.name == 'prod' -%}
UNLOAD ('SELECT actual_dt, chauffeur_id, label, value FROM {{ this.schema }}.{{ this.table }} ORDER BY actual_dt, chauffeur_id')
TO 's3://my-analytics-bucket/dwh/unload/chauffeurs_labels'
IAM_ROLE 'arn:aws:iam::88002000000:role/redshift-role'
FORMAT AS CSV
PARTITION BY (actual_dt) INCLUDE
HEADER
CLEANPATH
{%- endif -%}
"
]
)
}}
{{ dbt_utils.unpivot(
relation=ref('dim_chauffeurs_labels'),
cast_to='varchar',
exclude=['actual_dt', 'chauffeur_id'],
field_name='label',
value_name='value'
) }}Таким образом, на каждый регулярный расчет (раз в сутки, раз в час) будет сформирована и сохранена в S3 по указанному пути csv-выгрузка. А чтобы не хранить данные в СУБД, материализуем выгрузку как представление (view, виртуальная таблица).
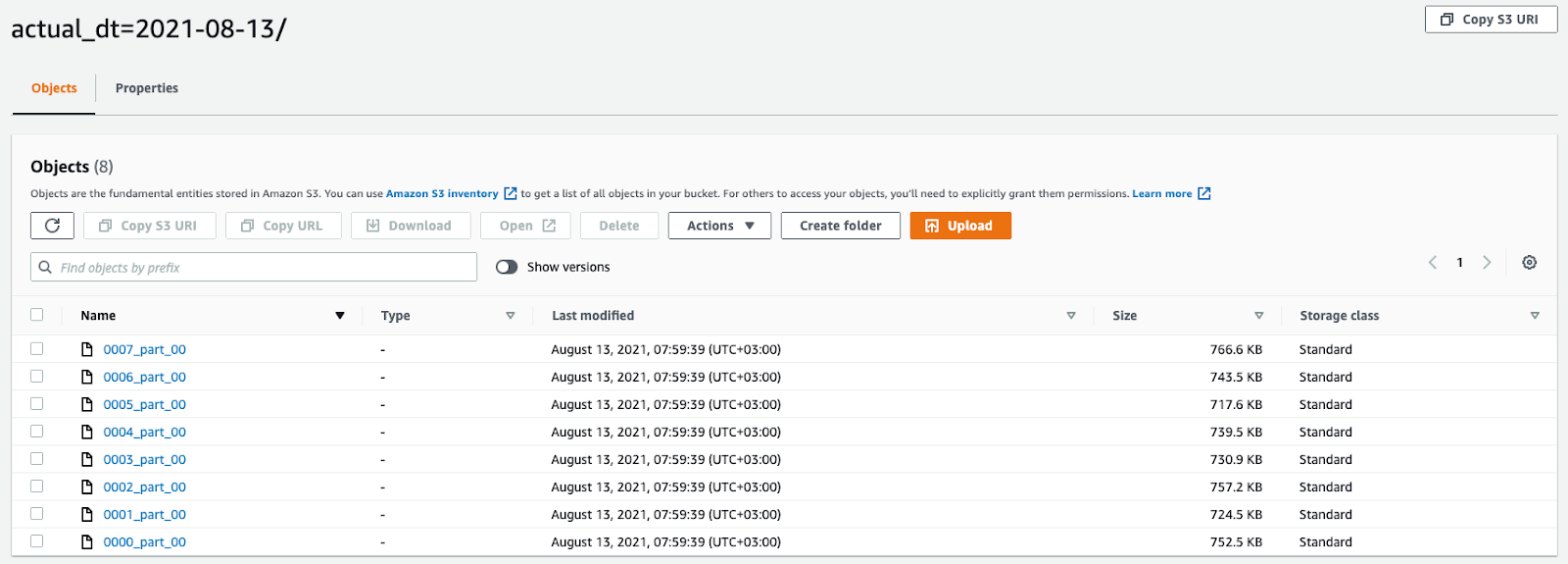
8 файлов по количеству узлов в кластере (принцип MPP-базы данных)
Еще больше примеров
Ранее я писал о других интересных сценариях и использовании современного аналитического стека:
Интеграционные тесты для Хранилища Данных – Настраиваем Slim CI для DWH
Формирование окружения для CI
Гибкое управление схемой, использование идентификатора Pull Request
Курсы валют и аналитика – использование обменных курсов в Хранилище Данных
Макросы для работы с внешними данными (External Tables)
Автоматизация пересчета курсов валют на лету
Кто ответит за качество аналитики: QA для Хранилища Данных
Тестирование ожиданий (expectations) от данных
Формирование тестов на бизнес-логику
Практические навыки и живое общение
Между тем, если вас интересует не только чтение, но и практика вкупе с получением знаний из первых уст, ознакомьтесь с платформой ОТУС и занятиями, в рамках которых я и мои коллеги делимся всех тем, что умеем и любим делать.
Data Engineer – один из самых успешных тиражных курсов, в запусках которого я участвую уже более 2-х лет. К новому старту готовы кардинальные обновления по содержанию, используемым инструментам, инфраструктуре, включая выделенные вебинары на разбор домашних заданий.
Analytics Engineer – попытка закрыть потребность на людей-мультиинструменталистов, которые сильны и в понимании специфики бизнеса, моделировании и в инженерной части. Львиная доля курса посвящена современным аналитическим СУБД, BI-инструментам, практикам продвинутой аналитики и моделирования в dbt.
Спасибо за внимание!
Материал подготовлен в рамках курса Data Engineer. Если вас интересует развитие в сфере работы с данными с нуля до Pro, предлагаем узнать про специализацию Data Engineer.
Также приглашаем всех желающих на Demo-урок «Введение в оркестрацию». На этом занятии подробно разберем, что такое платформы оркестрации, какие решения есть сегодня на рынке и даже углубимся в практический пример использования одной из самых распространенных платформ на сегодня: Apache Airflow.>>РЕГИСТРАЦИЯ




