
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Stargate — это open source фреймворк для работы с Apache Cassandra. Как он устроен и какие преимущества даёт, на конференции Cassandra Day Russia 2021 рассказал Дмитрий Бурлачков, Software Engineer в DataStax и один из разработчиков Stargate. Под катом расшифровка его доклада.
Что такое Stargate и как он взаимодействует с Cassandra
Stargate — это фреймворк для организации доступа к базам данных и, прежде всего, к Apache Cassandra (есть поддержка версий 3.11, 4.0 и DataStax Enterprise).
Stargate встраивается между нодами, которые хранят данные, и клиентскими приложениями. Он содержит в себе абстракцию хранилища данных и модульные конструкции, которые позволяют свободно вставлять что-то новое как с клиентской стороны, так и со стороны хранения данных.
Как это все работает концептуально: на нижнем уровне мы имеем кассандровское кольцо, где хранятся данные.
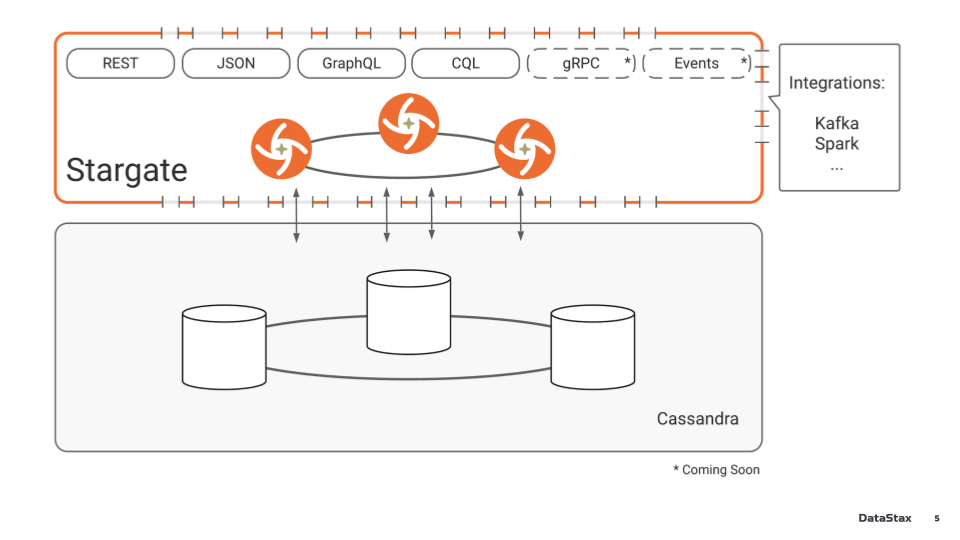
С ними взаимодействуют ноды Stargate, которые могут конфигурироваться по количеству, независимо от нод в Cassandra. Внутри Stargate есть модули для клиентской части:
- REST,
- JSON,
- GraphQL,
- CQL (поддерживается через драйверы для Cassandra);
- gRPC рассматривается на будущее.
При необходимости можно интегрироваться с Kafka, Spark и другими стримингами или аналитическими платформами.
Если следовать терминологии Cassandra, Stargate исполняет роль координатора. Он принимает первичные запросы от клиентов, интерпретирует (в том числе определяет местоположение реальных данных) и уже по интернод-протоколу отправляет запросы либо на сохранение, либо на загрузку данных.
Традиционно в Cassandra эта роль выполняется обычными нодами, которые содержат данные: запрос поступает на любой нод из кассандровского кольца, интерпретируется по ключу и затем более конкретные запросы идут на ноды, где хранятся данные.
Со Stargate это не так, поскольку Stargate не хранит данные. Данные хранятся только на кассандровских нодах. Но в остальном он выглядит для клиента (если мы сопрягаемся по протоколу CQL) как полноценный кассандровский нод. Он принимает запрос, точно так же может его интерпретировать, определить местоположение данных в реальном кольце и взаимодействовать с ними по интернод-протоколу — либо делать изменения, либо данные подгружать.
С точки зрения Cassandra Stargate не является частью кольца — не регистрирует себя как хранилище данных, поэтому если делать команду nodetool status, его там не видно. Но он просвечивается, если делать nodetool describecluster.
Stargate можно раздувать и сдувать по количеству нодов и по размеру каждого нода. Независимо от того, сколько нодов в Cassandra для хранения данных, это очень удобно. Это делается благодаря тому, что данные реально в Stargate не хранятся, поэтому нет проблем, чтобы добавить или удалить количество в Stargate. Соответственно, добавляется больше ресурсов для первичной обработки, чтобы делать координацию. Но нет никаких проблем, чтобы производить миграцию данных, это все делается очень быстро.
Архитектура Stargate
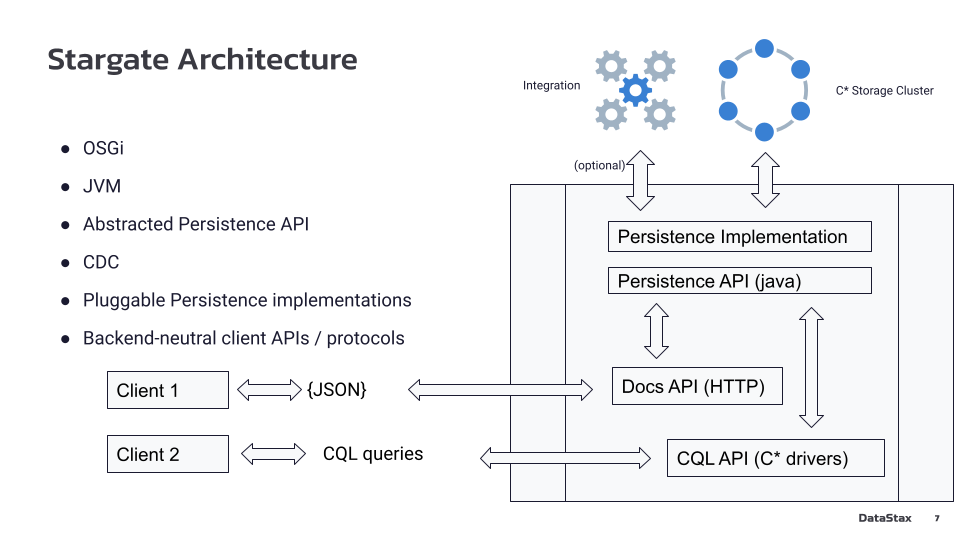
Stargate бежит как обычный Java-процесс. У нас есть Java Virtual Machine, в которой мы используем OSGi, чтобы работать с модулями; есть Persistence API, который абстрагирован в виде Java-интерфейсов, и различные имплементации интерфейса для конкретной базы. Если у нас база данных Cassandra 3.11 — загружается persistence 3.11, если Cassandra 4.0 — загружается 4.0, если DataStax Enterprise — загружается DataStax Enterprise. В одном джавовском процессе может поддерживаться только один тип базы, но потенциально можно рассматривать варианты работы с разными кластерами, версиями и даже типами — принципиальных препятствий нет.
CDC (Change Data Capture) — отслеживание или захват изменения данных. В Cassandra он реализован, но работать с ним было трудно. Предполагается, что в Stargate будет легко, потому что весь доступ к базе данных и хранилищу идет через один канал, что позволяет контролировать поток данных в одной точке и направлять его в разные системы. Например, приходит какой-то insert, он идёт в Cassandra, мы его можем в стрим отправить, каким-то образом закодировав, и уже клиенту давать acknowledgement, когда он будет сохранён в обеих системах. Эта вещь еще до конца в open source не функционирует, но потенциал есть.
Поверх Persistence могут подгружаться клиентские модули, как традиционный CQL, который работает через такой же протокол, как и Cassandra. Он даже может поддерживать более общий протокол. Например, одна из целей Stargate была — дать возможность клиентам пользоваться новейшим кассандровским протоколом, но данные хранить в старой версии. Если есть Cassandra 3.11 кластер, в принципе можно поднимать Stargate, который с ним сопрягается через свой persistence, интернод-протокол старого образца, но с точки зрения клиентов выглядит как новая Cassandra. Дополнительные возможности и улучшения, которые в новом протоколе реализованы, становятся доступны клиенту. Для клиента не важно, что за storage там крутится.
Естественно, сверкающие всякие штучки вроде Json и документа API реализованы отдельным модулем. Тут уже никакого CQL нет. Все взаимодействие с клиентом происходит через http и джейсоновские документы – они интерпретируются уже в Stargate и непосредственно сразу транслируются в запросы через persistence API, идут сразу в storage.
Document API

Что такое интерфейс документов? Это возможность бессхемного сохранения джейсоновских документов в Cassandra. Это в чем-то революционная концепция. Все курсы, которые вы слышали, начинаются с моделирования данных именно в кассандровской терминологии. Этот документ API идет с другой стороны. Экспериментальная в значительной степени вещь. Но она позволяет, не определяя схему, сразу начать работать с сохранением и доступом данных в формате json в Cassandra. Имеем доступ к всевозможным приятным вещам в Cassandra: перфоманс, можно масштабируемость достигать. Но особо там не надо заботиться о том, чтобы определить какие-то конкретные таблицы. Можно даже начать работать, не имея никакого опыта с Cassandra.
Для демонстрации я использую наши докеровские контейнеры, которые находятся в публичном доступе, на Хабе лежат. Я его запустил заранее, там порты форвардятся. Тут мы запускаем developer mode – это для того, чтобы было полегче. Там нет никакой репликации, все крутится на одном моде для демонстрации. В реальной ситуации надо заботиться, чтобы была какая-то репликация. Запустил заранее, но в принципе он быстро стартует.
Таких докеровских контейнеров опубликовано несколько. По каждой в Cassandra у нас различные идут. Как вы видите, версия 1.0.16. Все интерфейсы, которые идут через http, авторизуются с помощью токенов. Сначала мы этот токен должны получить, отправляем обычный запрос, тут авторизатор есть. Обычный кассандровский юзернейм, пароль отправляем туда, получаем токен. Экспортируем его в переменную для удобства.
Первым делом нужно создать keyspace – это единственная кассандровская концепция, которая требуется, чтобы начать взаимодействовать с document API. В принципе там ничего сложного нет, можно даже по умолчанию что-то создать. Мы с параметром «по умолчанию» сделаем demo 1. Это точно такой же джейсоновский запрос с другим URL. Мы его отправляем – keyspace создался. Есть также возможность посмотреть, что такое у нас есть. Можно получить список всего. Тут просвечивают системные вещи, которые в Cassandra есть по умолчанию. На них можно не обращать внимания. Наше demo 1 тоже тут появилось.
Дальше самое интересное начинается. Хотим мы что-то сохранить. Тут пример тривиальный: некий джейсоновский документ произвольной формы. Мы его сохраняем, и он сразу в Cassandra. Мы здесь писали id некоторые – это наши внутренние id, прямого отношения к Cassandra не имеют. То, что мы сделали post – он транслируется в insert в Cassandra, и ее айдишник – наш ключ по базе данных – генерируется автоматически.
Можно создать и свой ключ, его можно прописать. Сделаем test 1. Не заработало, я забыл как его делать. В документации все прописано подробно.
Создадим другой документ с другим json, отправим запрос через url, отформатируем. Наши два документа автоматически создались – это id и структура. Обратите внимание, они похожи, но у них немного по-другому сделаны внутренние под-документы. Здесь у нас Z 3 на третьем уровне, здесь он на втором. Это будет критично, когда будем делать поиск по базе.
Можно сделать запрос по конкретному ключу. Его мы приписываем сюда и получаем отдельно стоящий документ. Это все тривиально, потому что ключ – он в базе данных ключ. Если кому интересно, можно посмотреть, как это выглядит с точки зрения самой Cassandra. Мы можем пойти туда через CQLSH и сделаем use demo 1 и describe tables. Вот наша coll 1. Можно что-то селектом попробовать. Выглядит ужасно, потому что документ разбивается на несколько рядов, и это неудобоваримо с точки зрения CQL. Docs API позволяет нам в удобной форме делать запрос через rest.
Например, можно сделать поиск по базе, где колонка x=1. Наш документ нашелся. Этот модуль Docs API принимает запрос в виде json, сам его интерпретирует, транслирует это все на конкретную модель, которую он сам сгенерил для нашей коллекции. И отправляет 1 или больше запросов на хранение данных, чтобы нам что-то найти.
Например, можно попробовать найти по колонке z. Если мы напишем z3 – у нас так просто не находится, потому что z у нас находится внутри документа. Как вы помните, у нас было 2 документа, в которых в начале мы видим, у нас есть под-документ а, в нем b, и в нем уже z 3. Мы указываем наш путь а.b.z 3. И он находится. Второй документ был y.z3 – он тоже находится. Мы имеем возможность делать запросы, которые смотрят в глубину документа. Это все интерпретируется на Stargate. Он принимает решение, как это все надо выискивать. Например, можно поставить *. Просто поставить * вместо a b, и z=3. Значит, во всей гуще документов мы ищем поле z, которое на 3-м уровне глубины находится и со значением 3.
Создадим документ для примера. Сделаем не z=4. Мы отправляем, а тут мы поменяем, чтобы у нас было >0. Не хочет находить. По умолчанию решил нам выдавать по одному, поэтому сразу не нашлось, сейчас я сделал на page size 3, и оба документа нашлись. В обоих случаях z на 3-м уровне и значение >0. Если мы второй поменяем на b, он тоже их находит, потому что в обоих случаях b на 2-м уровне. Если захотим на 1-й уровень поставить а, на 2-й *, то находится только один, потому что хоть b под * попадает, у нас только в 1-м случае есть, как бы это все отрабатывается. Есть гибкость, как мы можем эти документы высматривать. Как вы могли заметить, не находится документ, где z на 2-м уровне, потому что запрос не предполагал их. Если сделаем z на 2-м уровне, он находится.
Есть набор разных предикатов и конструкций, которые доступны. Это можно посмотреть в документации в Stargate.io. Это дело новое, постоянно происходят улучшения. Если кого-то заинтересует, и какая-то функциональность недоступна на данный момент, то мы выслушаем всех с интересом. В Stargate.io можно посмотреть контактную информацию, на Гитхабе открывать тикеты. Если есть предложения, как конкретно делать поиск по всем документам, приветствуется открывание ish в Github или можно на Дискорд заходить и вопросы задавать.
Как вы заметили, есть возможность эти документы подгружать по ходу. Если у нас page size не специфицирован или документов больше, чем в первый ответ влезает, у нас выдается page state, который можно скармливать на втором запросы и дальше по списку проходить.
Ответы на вопросы слушателей
Все ноды Stargate работают как один кластер. Как делается load balancing от клиентов?
Хороший вопрос, правильный. Я опрометчиво сказал, что Stargate можно без проблем сдувать и раздувать. Тут над вести дискуссии конкретно по протоколу. Проще всего разобраться в http. В каждом конкретном случае можно по-разному к этому подходить. Я расскажу, как у нас сделано в Cassandra as a Service в приложении DataStax Astra, в котором Stargate летает. По http просто стоит обычный прокси, который знает, сколько Stargate. И каждый конкретный запрос отправляется, как load balancer решит. Он мониторит, съемка идет на конкретный старгейтовский нод, он его интерпретирует и делает исполнение. С точки зрения http трафика они round robin идут.
Для CQL все интереснее. Для более классических решений, которые именно используют Cassandra как Cassandra, идет запрос через CQL. В CQL все сильно зависит от драйвера. Есть драйвера, которые не очень поддерживают load balancing, и они тоже случайным образом куда-то посылают запрос. А джавовские драйвера довольно умные. Они могут по ключу, когда с Cassandra разговаривают, направлять запрос на конкретный нод. В Stargate не так. У драйвера есть специальная табличка. Есть system local и system peers, в которых содержится информация о всем кластере. Когда драйвер, который имеет об этом понятие, подсоединяется к Stargate, Stargate сам реальную информацию о storage не показывает, он в эти таблички вставляет информацию о себе. Соответственно, в system peers будут только Stargate, в system local каждый конкретный Stargate. Плюс там не будет токенов, поскольку Stargate сам является stateless, он данных не содержит, токены не показывает клиенту. В результате клиент будет делать round robin по Stargate. А как load balancing будет в конкретной реализации с эти разбираться – это ноу-хау, тут есть над чем поработать. Если делать все по-серьезному самим, там есть над чем подумать. Но это все проходит через прозрачный кассандровский протокол, который с драйверами общается. Это все решаемо. Но ноу-хау – это DataStax Astra, где это все уже реализовано в облачных решениях.
Есть 12 нод с РФ 3, получится 4 шарда с 2 репликами…
А почему 2 реплики? Если РФ 3, 3 реплики должно быть. Это больше по Cassandra вопрос. Если у нас есть 12 нодс и РФ 3, то каждая нода будет содержать информацию с 3 разных сегментов кольца.
У меня нет продакшен опыта с Cassandra, поэтому не понимаю. Можно еще раз, для чего используется Stargate, чтобы снять нагрузку с координатора?
Не то чтобы снять нагрузку с координатора, а чтобы иметь возможность, чтобы scale был разный. У координатора и storage разный функционал. Storage в основном занят тем, чтобы работать с хранением данных. В классической схеме у нас есть диск – он SSD или крутящийся. На storage пришел запрос – ему нужно быстро все это записать в commit log, записать в память и отрапортовать, что все готово, данные не пропадут. Основная функция – работа с вводом/выводом с периферийным устройством. Но в облаках используются облачные решения, но все равно идет ввод/вывод. Забота о том, чтобы данные сохранить в неубиваемом месте и отрапортовать.
У координатора задача другая. Он в первую очередь занимается интерпретацией CQL – он парсит, prepare statement делает, занимается вытаскиванием данных из запроса и направляет их в конкретной колонке. Много работы идет именно с нагрузкой на процессор. Плюс он еще ждет, если надо – consistency level, нагрузка другого характера. И подкручивать разные параметры надо по-другому. В общих чертах, координатору нужен процессор в основном. Storage тоже процессор нужен, но он не настолько критичен, поэтому имеется возможность быстро эти координаторы сдувать и раздувать, а Storage оставлять практически тем же. Если Storage нагрузку поддерживает, но у нас резко пошли запросы, которые требуют большего процессорного времени, то можно просто добавить именно координаторов и таким образом проблему решить, потому что это гораздо легче делать, чем нод добавлять в кольцо.
Одна из идей Stargate была именно дать возможность другим протоколам иметь общение со storage. Понятно, если мы просто с Cassandra общаемся, то кассандровский координатор понимает только CQL. Здесь мы открываем возможность, чтобы другие протоколы (как реализованы documentation API) имели доступ к данным, но с клиентами общались по-другому. Интерпретация запроса происходит в другом ключе – у нас там json и свои способы определить, как надо данные искать. Это все интерпретируется внешним модулем, потом отправляется в persistence API, который занимается координацией на уровне Cassandra и получает или сохраняет данные. И мы достигаем того, что есть возможность открывать другие протоколы для пользователя. Большая надежда, когда gRPC выйдет, что это будет для пользователя очень полезно.
В Cassandra есть некое условное ограничение на количество таблиц и колонок. Stargate как-то следит за этим при работе с document API?
Как сейчас реализован document API – это одна таблица на collection. Когда я отправлял запрос… у нас есть collections, потом collection 1. Вот этот collection сейчас транслируется на одну конкретную таблицу. Проект новый, тут, возможно, будут какие-то изменения, но пока работает так. Количество колонок не маленькое, разумное, по умолчанию порядка 70 колонок. Это немного для Cassandra. И дальше документ растет только в глубину. Каждый документ занимает один Partition Cassandra. И в зависимости от его структуры и сложности будет расти только количество записей в документе. Количество колонок от сложности структуры документа не растет.
Реализация GraphQL как-нибудь связана с реализацией графовой опции DSE и Gremlin
Хороший вопрос. Нет, не связано, но идут разговоры про GraphQL и Gremlin и сделать его модулем в Stargate. GraphQL реализован через Apollo GraphQL. Мы с ними интегрируемся, и все, что у них работает, должно работать и в Stargate. Графовые опции DSE есть разговор, что возможно она скоро будет реализовываться. Если есть интерес, присоединяйтесь к нашему каналу на Дискорде. Это можно обсудить там, это будет приветствоваться. Если есть интерес со стороны пользователей, будем очень рады услышать. Можно принимать участие в дискуссиях, каким образом это все реализовывать, для каких решений конкретные задачи. Это все для перспектив.
Доводилось ли деплоить Cassandra на одном кластере несколько серверов Cassandra? Можно ли поднять Cassandra на нескольких разделах дисков?
Да, это возможно. С опенсорсной Cassandra я такого не делал, но в DataStax Enterprise несколько нодов на одном сервере — это вполне обычная ситуация. Я думаю с Cassandra это тоже можно реализовать. Просто в DSE это проще – там есть специальный набор инструментов, который упрощает работу. Несколько разделов дисков – это глубокая тема про оптимизацию, не хотел бы углубляться. Надо иметь по возможности несколько разделов, в том смысле, что commit log, у нас только append on, хорошо просто писать вперед, не делать скачки по диску. А сстейблы больше бегают туда-сюда. Хорошо бы их держать на разных контроллерах, чтобы это быстрее все работало.
Можно ли использовать Stargate для применения миграции в схеме данных в Cassandra?
В принципе можно реализовать, но это потребует нового клиентского модуля. Потому что что сейчас реализовано, если CQL запрос идет, он его отправляет в какую-то таблицу. Но это все open source – можно легко прийти, взять его, подточить, переделать немножко и направлять на 2 разные таблицы. Люди в принципе это делают при миграции какими-то другими средствами. Но я думаю, что это можно реализовать в Stargate. На данный момент это не реализовано, проект новый. Но я думаю, что относительно легко реализовать своими силами, используя уже имеющийся код, просто в виде дополнительного модуля.
Если я добавлю +1, нечто на запрос по документам, это будет уже новая таблица?
Нет. Я не очень понимаю вопрос, правда. Если что-то меняется в самом документе, это новую таблицу не создает. Новая таблица создается, если мы делаем новый collection – набор документов. у всех collection на данный момент структура таблицы одинаковые. Разделение такое идет, чтобы было можно отрабатывать запросы быстрее. Имя таблицы – первичный ключ, который соответствует имени collection. А вторичный ключ – это уже primary key, в который генерируются ее id или снаружи можно подавать. Все таблицы сейчас имеют одинаковую структуру. Но я не знаю, как это будет дальше эволюционировать, потому что сейчас мы работаем над тем, чтобы оптимизировать запросы и поиск по документам, поэтому может на будущее это будет как-то по-другому реализовано.
Какие решения используются в реализации CDC? Debezium?
Debezium не используем, но он похож, но у нас другие. Debezium просто выбирает данные из CDC-файлов, которые Cassandra сама генерирует. У Stargate подход другой. У Stargate мы получаем запрос от клиента, сами его интерпретируем и на моменте координации имеем возможность отправить запросы на storage и в Kafka одновременно. Потом ждем, когда storage отрапортует свой consistency level, но мы все равно ждем, когда Kafka. Kafka отрапортовала, мы шлем подтверждение клиенту. Такая идея. Но к сожалению, насколько я помню, она сейчас еще не до конца реализована. Если интересно, пишите или можно даже руками в код лезть и все это дотачивать. Концепция принципиально отличается от того, что делает Debezium и от того, что CDC делает в Cassandra – именно возможностью контролировать весь процесс и получать все подтверждения именно на этапе координации. И клиент будет иметь полную уверенность. Если клиент получил добро, значит данные ушли в Kafka, Pulsar (он сейчас модный) или на storage.
Как оптимизировать данные для хранения в документах? Вы показали пагинацию, я так понимаю.
С оптимизацией большой вопрос. Это еще новый проект. Мы сделали первичную имплементацию, сейчас как раз работаем над оптимизацией. С точки зрения клиента пока ничего сделать особо нельзя, кроме того, что разумно подходить к вопросу генерации ключей. Если это UUID, это максимум, что можно с точки зрения клиента сделать. Изнутри мы копаем, думаем сильно над этим. Посмотрим, может быть, в ближайшее время будут какие-то изменения.
Пагинация сделана для того, чтобы не грузить коннекшн. Хороший вопрос, как это работает с load balancing. Наверное, load balancer его туда направляет. Я не очень в курсе. В paging state, который возвращается. Мы как бы кодируем paging state из Cassandra. Даже если запрос на вторую страниц падает на другой нод, мы все равно знаем конкретное положение данных и конкретное положение курсора в storage, где он находился. И мы можем из другого stargate пойти в правильный storage нод и уже дальше продолжить чтение по тому разделу, где мы остановились. И дальше по ходу генерируются документы и отправляются.

Rest API – тот же самый Json, http и кассандровская схема. Чем отличается от document API? В принципе, тот же самый rest. Но document API генерирует схему за клиента. Клиент не должен никак за схему волноваться. А Rest API просто дает возможность доступаться к той схеме, которая уже определена в самой Cassandra. Схему можно делать даже в CQL.
Создадим другой keyspace. Сделаем табличку просто через CQL руками с двумя записями. Отсюда мы уже можем через Rest API доступаться. Даже в самом Rest API есть возможность создавать схемы, но там она немного выглядит коряво, на мой взгляд. Через Rest API, можно и через http подавать запросы на создание схемы, но концептуально там все то же самое, что в Cassandra: колонки, типы данных, primary key, просто другим образом выражено через json. С моей точки зрения занудно, поэтому я сделал через CQL. А данные можно вставлять через http, json отправляем, где у нас все по колонкам в плоском документе разложено. Мы перезаписали, поскольку x, y у нас primary key demo 1 1 1. Выдается primary key в ответ.
Можно запросы подавать. Запросы эквивалентны тому, что мы делаем обычно в Cassandra, но есть возможность посылать его через http. Имеется в перспективе открывать этот доступ вебовских приложений, им надо просто доступиться в Cassandra, но там драйвер неудобный.
Сделали get x=1. Функционал такой же, как в Cassandra. Можно делать и множественные запросы. По умолчанию все через tnd идет, никаких or тут не поддерживается. X=1, y>0. Как и в Cassandra, если у нас есть clustering call, мы по ней можем делать sort. Здесь мы делаем sort по y descending. Вставим что-нибудь с 3 и 5. По y descending идет, x=3 y=4, можно делать в обратную сторону. Тот же функционал, как и в Cassandra, просто через http. Что можно делать в CQL, можно сделать здесь и наоборот. Исключительно, чтобы людям было удобно достучаться от всяких веб-приложений.

Имеется в виду Apollo GraphQL. Он может существовать в двух вариантах. Что сейчас реализовано – это Cassandra Schema First. То есть кассандровская схема является первичной, GraphQL на нее садится сверху, все это перерабатывает в GraphQL-схему и делает возможным доступ через GraphQL. Сейчас идет интенсивная работа о том, чтобы сделать родную схему GraphQL first. Человек приходит с GraphQL-схемой, посылает ее в сервис. Он ее перерабатывает и уже автоматически генерирует в Cassandra-схему. Это скоро должно выходить. Кто интересуется, знайте, что работы идут в этом направлении. Сейчас доступна обычная кассандровская схема. И мы можем к ней доступаться через GraphQL. У нас swagger на rest API прицеплен.
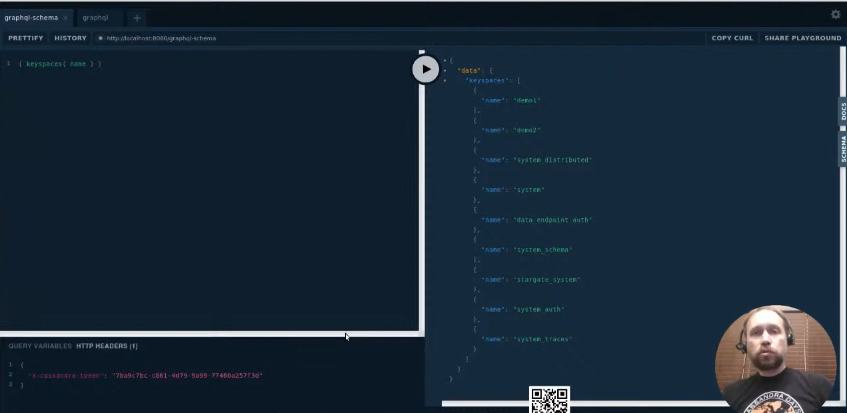
Схемку выдает, высвечивает все keyspace. Это endpoint схемовский. Можно пойти конкретно на наш keyspace demo 2. Схема с артефактами, которые с генерацией связаны. Может показаться кривой, но она делается автоматически. Сделаем один запрос, обычный GraphQL пишем. У нас query идет, вот таблица А, мы даем ключ х и хотим получить х, y, value. Отправляем, все получилось. Все штуки GraphQL работают. Если нас y не интересует, мы его не запрашиваем, он не возвращается.
Посылаем сортировку по y, все отработало, можно х сюда вписать. Order by – тут такие артефакты встречаются – y_DESC. Это все автоматически сгенерировалось в схеме. Технические моменты, что надо адаптировать кассандровскую схему на GraphQL. Версия, которая будет для GraphQL родная, будет не так угловато смотреться.
Для плавного перехода на Stargate достаточно добавить его, но сохранить текущее взаимодействие с Cassandra?
Да, это возможно. Часть клиентов может непосредственно входить в Cassandra по прямому, часть может входить через Stargate. Должно работать, не вижу никаких причин, почему это может не работать. Можно рассмотреть вариант, когда клиенты нового образца, которые через http работают, идут через Stargate, а клиенты CQL идут просто в Cassandra. Такое тоже возможно.
Есть ли смысл хранить бекапы каждой ноды, если РФ 3?
По РФ и бекапы хорошие вопросы. Не имею возможности больше вдаваться, потому что это больше, как Cassandra конфигурировать, я бы хотел остановить внимание на Stargate. Есть форумы на русском про Cassandra.
Как Stargate работает с страсстор для доступа к базе данных?
Все, что доступно в Cassandra, доступно и в Stargate. Если вы хотите сконфигурировать шифрование на интернод-протоколе, Cassandra поддержит, Stargate тоже поддержит. Это немного непросто. Сейчас в документации не найдете, но если у вас есть опыт работы с Cassandra, то вы можете кассандровский yaml скормить Stargate – есть специальные опции для этого. Вам надо по ресурсам прошерстить или на Дискорде спросите. Можно скормить обычный кассандровский yaml в ней. И в нем, как и в Cassandra можно отконфигурировать и траст стор, и ключи. И будет все работать для интернод-протокола.
Можно ли нам авторизоваться через траст стор?
Да, для продакшена это используется. DataStax сам использует Stargate в продукте DataStax Astra. Если вы там регистрируетесь, все, что под кодовым названием serverless – все идет через Stargate. Если вы хотите сделать в Astra ваш личный кластер, не multi-tenant – у вас будет там будет опция. Можно с Cassandra, можно с Stargate. Проект молодой, но используется уже. Проблемы есть, но летает.
Deployment

Как я уже говорил, self-managed. На Docker Hub опубликованы наши контейнеры. Их можно брать, мутузить как угодно, вынимать из них jar ненужный, вставлять, добавлять. Есть jars, которые в zip лежат на Git Hub, их можно распаковывать. Предварительно прочитайте документацию на Git Hub. На Stargate.io больше для клиентской части. Если вы хотите копаться в докерах, на Git Hub есть репозитории, можно почитать. Можно компилировать самим.
Сейчас уже DataStax Astra использует Stargate в нашем облачном решении: multi-cloud, multi-tenant, AWS, Azure, GCP. Можно бесплатно попробовать на неограниченное время, если загрузка небольшая.
Будущее
Как я уже говорил, GraphQL родная схема, gRPC. Сейчас много над Document API, в CDC тоже есть куда стремиться. Из потенциально интересного — можно сделать SQL. Я над этим немного работал. Если вы будете копаться на open source, вы сможете увидеть, что есть ветка по поводу SQL.
Бекенды ориентированы на Cassandra. Все, что похоже на Cassandra, но не Cassandra тоже поддерживается легко. Если есть интерес, можно самим даже делать, это все open source на Github. Проект молодой, возможностей много.



