Если вы думаете, что локализация — это просто (нужно только вынести все тексты из кода приложения и перевести их), то в большом проекте всё иначе. Если над ним работают десятки разработчиков и ежедневно релизится новая функциональность, то с каждым релизом появляются новые текстовые блоки и меняются старые. Переведенные фрагменты смешиваются с новыми, а новые — это коктейль текстов из разных продуктовых задач. Так рождается хаос, который пожирает сначала разработчиков, а потом и пользователей.

В докладе я рассказал, как мы организовали локализацию в проекте с десятками тысяч фрагментов текста и командой более чем из 40 человек. В конце поста есть видео с рассказом.
— Привет. Меня зовут Дмитрий Андриянов, я из Яндекса. Команда, в которой я работал до недавнего времени, отвечает не только за продуктовые задачи, но и за локализацию. (...) Фронтендеров там в районе 40 человек. А если брать вообще всех, кто участвует в разработке продукта, — менеджеров, тестировщиков, бэкендеров, редакторов, то будет 128 человек. Можете себе представить, какая это толпа.
(...) Эти 40 фронтендеров каждый день коммитят новые изменения в проект. Там много текстов, и все они должны быть переведены на три языка: русский, английский и турецкий. Разработчики решают конфликты при мерже этих текстов в систему контроля версий. И нужно сделать, чтобы в интерфейсе отображались тексты на том языке, который выбран у пользователя.
Мы победили этот хаос: много экспериментировали с нашим процессом локализации и пришли к хорошему, на наш взгляд, варианту, когда все доработки выкатываются в продакшен сразу на всех языках. При этом все разложено по полочкам, ничего не конфликтует и не теряется. И что еще важнее, переводы не тормозят процесс разработки. То есть время, которое требуется на перевод, а это от нескольких часов до нескольких дней, почти не увеличивает длительность процесса разработки. Это классно, все довольны, особенно менеджеры.
В докладе я хочу вам рассказать о сути нашего процесса, о том, какими шагами мы к нему пришли, в какие стороны смотрели и почему он именно такой.
Для начала поговорим о двух понятиях — интернационализации, сокращенно i18n, и локализации, сокращенно l10n. Восемнадцать и десять — это количество букв между первой и последней в словах internationalization и localization. Эти два понятия часто нужны вместе и используются вместе, поэтому их часто путают. Но они означают разные вещи.
Кажется, что интернационализация — это сложно, а локализация — просто, рутинная работа.
Действительно ли это так? Нет, потому что есть два момента.
И вам в команде, если проект поддерживает несколько языков, нужно организовать процесс, при котором вы регулярно берете все непереведенные фразы из проекта и отправляете их на перевод. А потом, когда переводчики присылают вам результат, обратно раскладываете это в свой проект.
Я называю этот процесс continuous localization, по аналогии с continuous integration, это такая непрерывная локализация в течение всей жизни приложения.

Представим, что вы в проекте хотите организовать такой процесс. Вы столкнетесь с тремя проблемами:

Когда ребята в Яндексе в далеком 2013 году думали, как решить эти проблемы, они пришли к идее, что нужно работать с текстами и исходным кодом отдельно. Я не уверен, что эта идея была придумана в Яндексе, может быть, где-то вовне, но примерно в то же время. В чем она заключается?
Вы делаете отдельное хранилище: в нем хранятся тексты и переводы на все языки, переводчики работают с этим хранилищем. Оно решает проблемы, которые мы перечислили, потому что там вы можете хранить тексты в любом удобном виде, в базе данных, или работать с ними SQL-запросами. Вы можете сделать там любые дополнительные поля, хранить контекст, статусы, дополнительную справочную информацию, комментарии — любые дополнительные поля.
Так как вы полностью контролируете структуру этого хранилища и его API, вы можете накрутить туда любую автоматизацию. При работе с хранилищем будут автоматически выполняться нужные вам действия. Такое хранилище решает все проблемы, которые мы перечислили.
Как тексты будут попадать в исходный код, и вообще, как они будут попадать в хранилище?

Вы можете периодически выгружать из вашего проекта в хранилище русские фразы. Это очень простая операция, потому что она однонаправленная, загружает фразы на одном языке. У вас нет какой-то сложной логики.
Вторая операция — в обратную сторону: вы выгружаете из хранилища все переводы обратно в проект. Эта операция тоже простая, потому что вам не нужно смотреть на текущее состояние проекта, не нужно парсить все эти файлы с переводами. Вы просто берете из хранилища состояние переводов целиком и кладете его в проект.
Получается простая и надежная схема из двух операций. При этом переводчики работают с текстами удобно. Например, можно получить все тексты, которые необходимо перевести.
В Яндексе мы собрали команду разработки и написали сервис, который назвали Танкер. Это внутренний сервис Яндекса, как раз он и является хранилищем переводов.
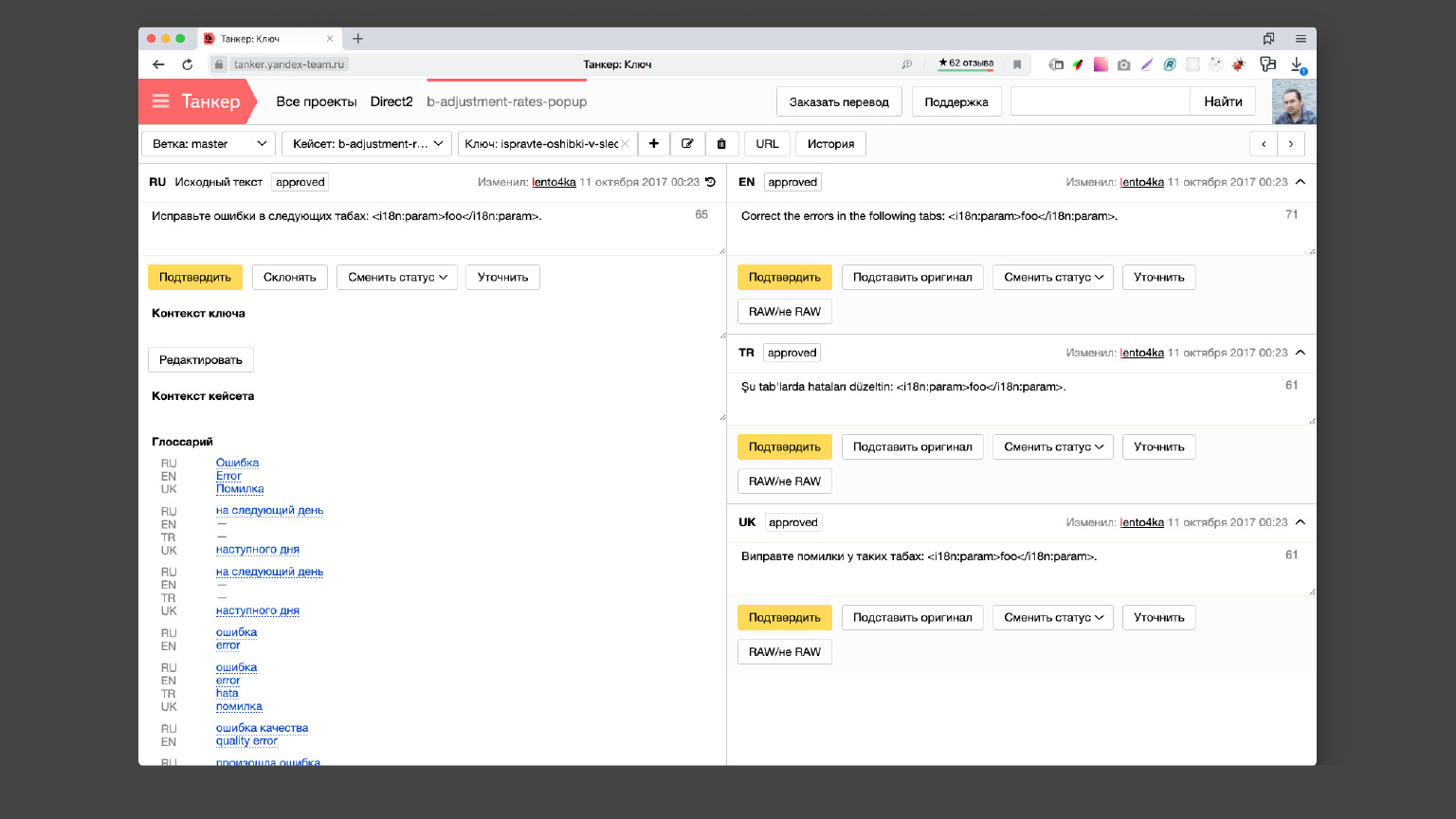
Все команды Яндекса выгружают свои русские фразы в Танкер. Дальше переводчики согласно своим процессам с ними работают, добавляют туда переводы на все нужные языки. После этого переводы выгружаются из Танкера обратно в свои проекты.
Таким образом у нас получается следующий процесс.

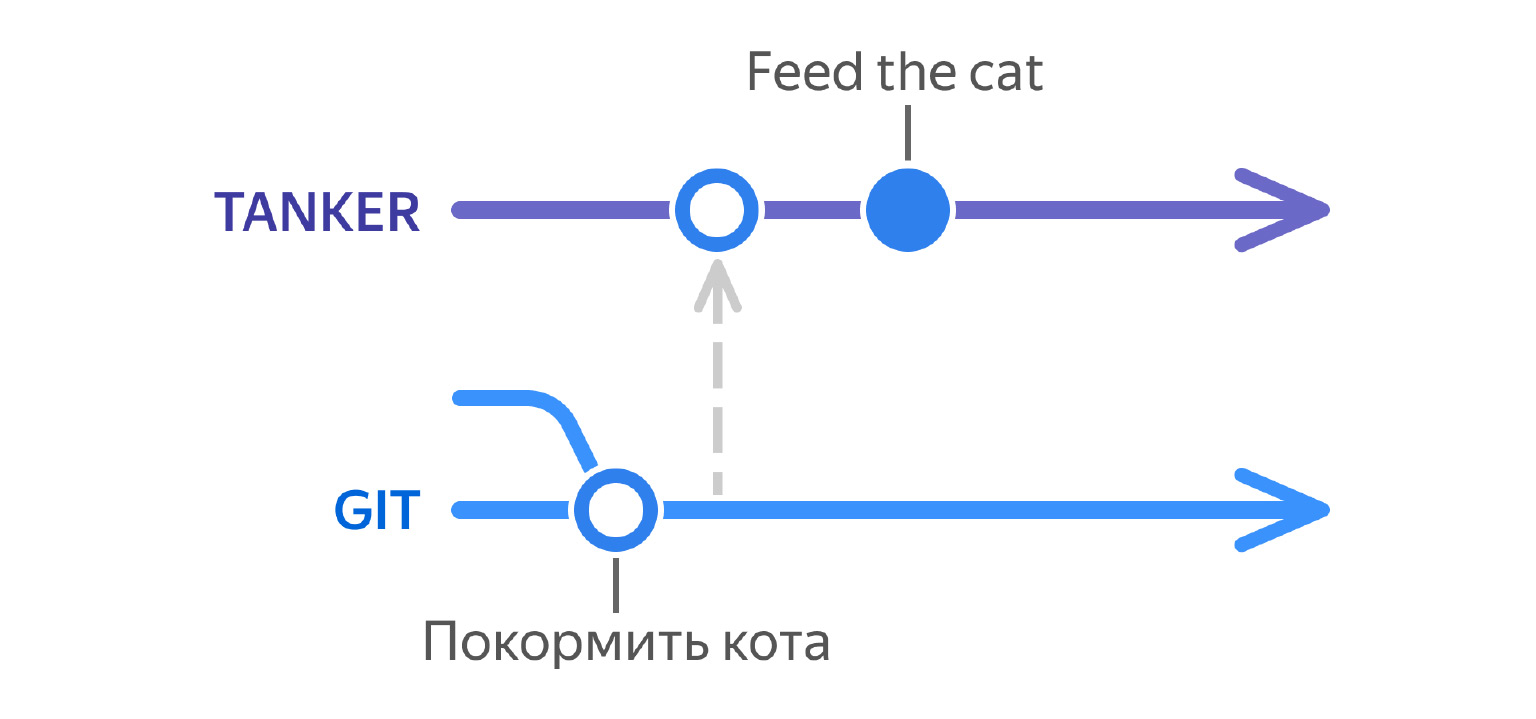
Представьте: вы разработчик, пишете проект, и вам нужно сделать вот такой pop-up, в котором есть кнопка «Покормить кота».

Вы вливаете в Git свою ветку с изменениями. Получается, в Git появился новый русский текст «Покормить кота».

После этого автоматически — например, ночью — запускается синхронизация, и русские тексты уезжают в Танкер. Не закрашенный кружочек — это текст без перевода.
Приходят переводчики и добавляют переводы для этого текста. Вы видите, что кружочек стал закрашенным.

Срабатывает еще одна синхронизация, перевод приезжает обратно в проект, затем происходит релиз. Пользователь видит в интерфейсе текст на понятном ему языке. Супер.
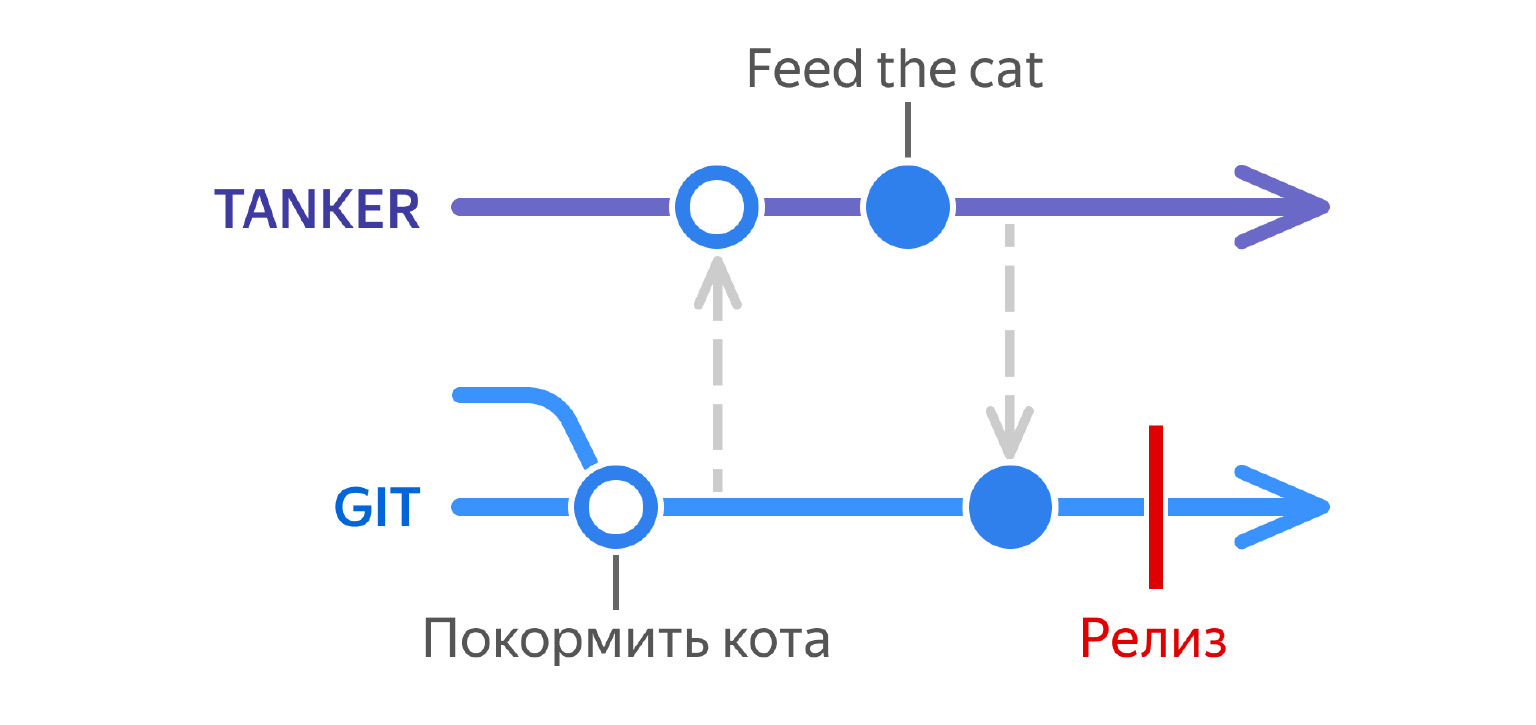
При помощи этой идеи с отделением переводов от кода проекта мы смогли организовать процесс многократный локализации. Мы можем после каждого коммита или после каждой пачки коммитов выгружать переводы и можем много раз загружать их обратно в проект.
Представим, что мы все это зарелизили, пошли в продакшен посмотреть, как у нас все красиво, и увидели, что там появилась новая кнопка, и она без переводов. Что же случилось?
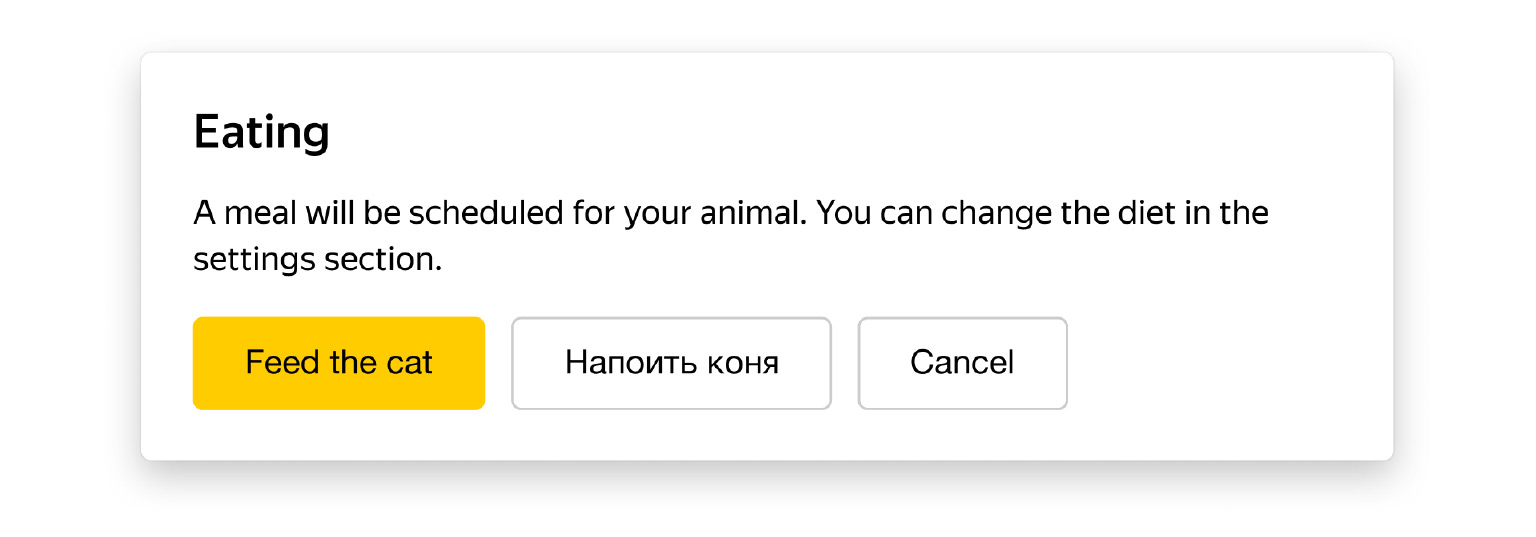
Проблема в параллельной разработке. Давайте вернемся к нашей схеме, посмотрим, что произошло.

Эта схема больше похожа на реальную жизнь. Тут проект разрабатывает не один разработчик, а несколько. И мы видим, что работа над переводами кнопки «Покормить кота» занимает время. Это маленькая фраза, и она одна. В реальных задачах могут быть десятки, сотни фраз. Перевод может занимать от нескольких часов до нескольких дней.
Пока велась работа над переводами, пришли другие разработчики и закоммитили еще какие-то свои изменения, например кнопку «Напоить коня». При следующей синхронизации изменения уехали в Танкер, и они будут когда-то в будущем переведены, но в момент релиза они находятся в проекте без переводов.
Фишка в том, что если у вас большая команда разработки, то будет и высокий темп разработки, много коммитов. Значит, за время, пока идут переводы очередных коммитов, гарантированно будут появляться новые. В вашем интерфейсе гарантированно и постоянно будут возникать куски без переводов. Они будут с каждым релизом меняться, каждый раз будут разными, но что-то обязательно будет без переводов, и это печально.
Что можно сделать? Для начала — понять, в чем корень проблемы. Проблем две
Вторую проблему, кажется, можно решить, потому что в момент, когда разработчик мержит в основную ветку свои изменения, у нас есть дифф между ветками, которые он мержит. Грубо говоря, содержимое пул-реквеста, который он вливает.
Так как переводы в проекте хранятся в json-файликах, то мы можем в этом диффе видеть разницу, что поменялось в этих json-файликах. Так мы можем понять, примерно какие фразы поменялись в этой задаче.
Я привел пример одного из наших проектов, там действительно фразы в json-файликах. Но у нас есть другие проекты, в которых фразы хранятся по-другому.
Например, русские фразы записаны прямо в коде как дефолтное значение, передаваемое в функцию локализации.
Тут мы тоже можем понять, какие фразы поменялись, но не можем делать это автоматически. Если человек смотрит — он поймет, какие фразы поменялись, но автоматом обработать эти изменения скриптом и получить список мы не можем. Но главное, что у нас хотя бы в таком неудобном виде есть нужная нам информация.
Что же делать с первой проблемой, с тем, что мы начинаем работать над переводами сразу, когда изменения попадают в master? Мы думали, как ее решить, и решили, что нужно сделать в Танкере, в хранилище переводов, механизм веток, похожий на ветки в системе контроля версий в Git.
То есть нужно уметь создавать ветки, строить между ними дифф, мержить их. Все как в системе контроля версий. Тогда можно было бы работать над переводами для разных задач в отдельных ветках, и они бы никак не конфликтовали.
Смотрите, какой процесс у нас получился. Разработчик коммитит свою ветку системы контроля версий с изменениями. Это та же самая кнопка «Покормить кота».

Дальше он выгружает изменения в Танкер, но не в ветку master, не в основную ветку Танкера. Для своей задачи он создает отдельную ветку и выгружает изменения в нее.
После этого мы автоматически строим дифф между двумя ветками Танкера — веткой задачи и master. Получается список фраз, которые изменились в рамках этой задачи. То есть в master у нас полное состояние проекта, а в ветке у нас полное состояние плюс новые фразы, которые выгрузились из ветки задачи. Этот дифф мы всегда можем легко получить, он не зависит от того, в каком виде в проекте хранятся переводы, потому что мы сравниваем, грубо говоря, две таблички в БД.
Мы получаем этот дифф и на его основе создаем тикет в трекере, по которому переводчики работают над текстами. Они уже не смотрят в Танкер, не ищут все фразы без переводов. Они просто идут по списку и добавляют переводы для фраз, которые там указаны.

Дальше. Переводчики добавили переводы для всех языков.

Мы синхронизируем тексты обратно, и переводы приезжают в проект. Но опять же, они приезжают не в master, а в ветку, где разработчик работал над задачей.
Тут важны два момента. Первый: в проекте есть ветка, она еще не влита в master, а в ней уже есть все переводы для нашей продуктовой задачи.
Второй важный момент в том, что разработчик отправляет тексты на перевод, не дожидаясь, пока задача поревьювится, потестируется. Как только он закончил работу над задачей, и у него появилось понимание, что тексты уже не будут меняться, он сразу отправляет их на перевод. Перевод идет параллельно с код-ревью и тестированием задачи.
Когда переводы вливаются в систему контроля версий, то задача уже, как правило, проревьюена и протестирована. Тестировщикам остается коротко проверить локализацию, то есть собрать новый стенд со всеми переводами и убедиться, что тексты на разных языках не ломают верстку.

После этого разработчик может вливать все в master. Параллельно ему нужно влить ветку Танкера в master.
Таким образом, каждая ветка каждого разработчика, каждая задача, вливается в master сразу с переводами. Мы в любой момент можем провести релиз. Мы уверены, что пользователь получит корректное состояние интерфейса, что все тексты будут на нужном ему языке. Круто.
Мы не сразу пришли к этому процессу. Много экспериментировали, проверяли теории. В результате у нас получилась вот такая схема, и мы были очень рады, потому что это здорово раскладывает все по полочкам и наводит порядок в процессе локализации.
Но когда мы хотели распространить это на всю команду, сделать, чтобы вся команда, 40 человек, работала по этому процессу, то столкнулись с человеческими ошибками.
Многие из вас пользуются системой контроля версий Git. Вспомните, что было, когда вы только начинали ее осваивать. Лично у меня в первые месяцы работы постоянно были ситуации, когда я что-то не туда смержил, неправильно решил конфликты, внес изменения и потом два дня разбирался, как откатить то, что у меня потерялось.
Мы дали команде новый инструмент работы с переводами, но это тоже новая система для разработчика. Там нужно было выполнять действия, принимать решения. Любое принятие решений — это стресс. А когда это новая вещь, вы можете принять неправильное решение, сделать ошибку. Ошибка — это десятикратный стресс.
Что делает человек, когда он в стрессе и совершает ошибку? Начинает злиться на того, кто принес ему этот инструмент, и того, кто вызвал этот стресс.
Представьте: у вас команда из 40 человек, каждый разработчик один-два раза в неделю делает ошибку и приходит к вам злиться. А теперь представьте, что эти 40 человек постоянно к вам приходят. Когда на вас злится столько людей, это не очень приятно.

Поэтому у нас в первое время был специальный дежурный, человек, который разруливал все проблемы, отвечал на вопросы, помогал вернуть потерянные изменения. Затем мы постепенно записали все вопросы, с которыми люди приходили, в документ и написали туда ответы. А потом мы все это дело автоматизировали.
Давайте вернемся к нашей схеме. Вот наш процесс, у нас получилось всего три точки, когда разработчику нужно принять решение и инициировать какие-то действия.
Мы их называем по аналогии с командами GIT PUSH, PULL и MERGE. С помощью каждой из этих команд разработчик запускает какой-то один скрипт, который делает все остальные действия и выполняет проверки.
Когда разработчик запускает PUSH, то скрипт сначала проверяет, есть ли ветка в Танкере с таким же названием, как у ветки задач. Если ее нет, она создается, если есть — актуализируется. В нее подмерживается ветка master из Танкера.

Дальше мы выгружаем из текущей ветки проекта фразы в ветку Танкера. После этого автоматически скриптом строим дифф, создаем в трекере тикет для переводчиков и автоматически передаем его в работу. То есть разработчик запускает скрипт и на выходе получает тикет, который уже находится в работе и через некоторое время будет переведен. Когда тикет закрыт, разработчик по изменению статуса будет видеть, что переводы для задачи готовы.
Следующая команда — PULL. Это относительно простая команда, позволяет подтянуть изменения из ветки Танкера в ветку проекта.

Что здесь происходит? Мы опять находим ветку в Танкере, соответствующую текущей задаче. Опять ее актуализируем. Вообще, мы актуализируем ветку в Танкере при запуске каждой команды. Подмерживаем туда master и выгружаем фразы из Танкера в проект.
Третья команда — MERGE. Мы находим ветку в Танкере, подмерживаем в нее ветку master, чтобы ветка в Танкере была актуальной. Дальше находим тикет на перевод и проверяем, что он закрыт. Это защищает разработчика от ситуации, когда он замержил ветки в Танкере, в которых еще не готовы переводы.

После этого мы мержим ветку Танкера в master Танкера и проставляем в тикете признак о том, что он закоммичен. Этот признак мы можем использовать в других проверках, которые происходят автоматически. Например, мы можем в Git сделать прекоммит-хук, не дающий замержить ветку, переводы в которой поменялись и не закоммичены в master Танкера.
Таким образом мы запустили процесс в большой команде, и ключевая вещь, которая позволила нам его запустить, — то, что мы все автоматизировали. Мы упростили действия, которые нужно делать людям, и они перестали совершать человеческие ошибки.
Последняя вещь, о которой я хочу с вами поговорить, — это конфликты слияния. Мы говорили, что в Танкере есть ветки. Разработчики параллельно меняют в них тексты. Такое происходит редко, но может получиться, что два разработчика поменяли одну и ту же фразу разными способами. Они получают конфликты слияния, как в Git. Как мы это решаем?
Первый разработчик мержит свою ветку в master Танкера и не получает конфликты, потому что в master Танкера еще нет конфликтующих изменений. Когда второй разработчик попытается замержить свою ветку, Танкер вернет ему вот такой json-фал, в котором есть вся информация о конфликтах.
Тут указано, во-первых, в какой фразе, в каком ключе произошел конфликт. Во-вторых, указаны две конфликтующие формы — как было в одной ветке и как стало в другой. Для каждого конфликта указан некоторый хэш. Это хэш-сумма от всех этих полей. По этому хэшу Танкер понимает, что данный элемент файла с конфликтами относится к определенному конфликту ветки.
Разработчику нужно заполнить в этом файле поле resolved. То есть он попытался смержить ветку, получил такой большой файл, в котором перечислены все конфликты, а поле resolved пустое. Он прошелся по этому файлику, указал в поле resolved правильное значение фразы. После этого он повторно пытается смержить ветку и отправляет этот файл с ложными значениями как один из параметров.
Если Танкер при мерже ветки встречает конфликт, он смотрит по хэш-сумме, есть ли для данного конфликта информация о его решении. Если есть — использует значение их поля resolved.
Это все, конечно, круто работает, но неудобно править большие json-файлы руками. Можно написать что-то не туда, перепутать фразы или поставить лишнюю запятую и будет синтаксическая ошибка. Танкер не сможет распарсить этот json-файл. Поэтому мы написали небольшую утилиту для интерактивного решения конфликтов. Это консольная утилита.
Вы открываете в ней json-файл, и она по очереди показывает вам все конфликты. Вы можете стрелочками выбрать нужный вариант или ввести свой.
Почему мы сделали ее консольной? Потому что работа с проектом у нас часто происходит на удаленном сервере, через терминал. С такой консольной утилитой можно тоже работать в терминале.
Еще один интересный момент: человек, который ее писал, назвал ее Танкер-Ганди — в честь миротворца Ганди, который много понимал в решении конфликтов.
Давайте подытожим все, о чем мы сейчас говорили. У нас был один огромный проект на три языка. В нем было больше 20 тысяч фрагментов текста, 40 фронтенд-разработчиков. За время, пока работает этот процесс, то есть за один год и два месяца, мы перевели 2 700 продуктовых тикетов, и все они сразу выкатились в продакшен с переводами на все языки.
Не было проблем с конфликтами, с тем, что фразы потерялись. Все отработало четко. Разработка при этом не тормозилась из-за того, что мы делаем дополнительную работу по переводу текстов. Кажется, это классный результат.
Я хочу, чтобы вы запомнили из моего доклада две вещи:
На этом у меня все, спасибо.
В докладе я рассказал, как мы организовали локализацию в проекте с десятками тысяч фрагментов текста и командой более чем из 40 человек. В конце поста есть видео с рассказом.
— Привет. Меня зовут Дмитрий Андриянов, я из Яндекса. Команда, в которой я работал до недавнего времени, отвечает не только за продуктовые задачи, но и за локализацию. (...) Фронтендеров там в районе 40 человек. А если брать вообще всех, кто участвует в разработке продукта, — менеджеров, тестировщиков, бэкендеров, редакторов, то будет 128 человек. Можете себе представить, какая это толпа.
(...) Эти 40 фронтендеров каждый день коммитят новые изменения в проект. Там много текстов, и все они должны быть переведены на три языка: русский, английский и турецкий. Разработчики решают конфликты при мерже этих текстов в систему контроля версий. И нужно сделать, чтобы в интерфейсе отображались тексты на том языке, который выбран у пользователя.
Мы победили этот хаос: много экспериментировали с нашим процессом локализации и пришли к хорошему, на наш взгляд, варианту, когда все доработки выкатываются в продакшен сразу на всех языках. При этом все разложено по полочкам, ничего не конфликтует и не теряется. И что еще важнее, переводы не тормозят процесс разработки. То есть время, которое требуется на перевод, а это от нескольких часов до нескольких дней, почти не увеличивает длительность процесса разработки. Это классно, все довольны, особенно менеджеры.
В докладе я хочу вам рассказать о сути нашего процесса, о том, какими шагами мы к нему пришли, в какие стороны смотрели и почему он именно такой.
Для начала поговорим о двух понятиях — интернационализации, сокращенно i18n, и локализации, сокращенно l10n. Восемнадцать и десять — это количество букв между первой и последней в словах internationalization и localization. Эти два понятия часто нужны вместе и используются вместе, поэтому их часто путают. Но они означают разные вещи.
- Интернационализация — это когда вы пишете в своем проекте код, который учит ваш проект переключаться между языками интерфейса. Вам нужно обратить фразы на нужном языке. А фразы могут быть вариативными, потому что могут зависеть от количества или от пола, сущностей, о которых в них говорится. Вам нужно отображать данные в правильном формате. Нужно отображать даты и адреса, номера телефонов, числа, денежные значения в формате того языка, который выбрал пользователь.
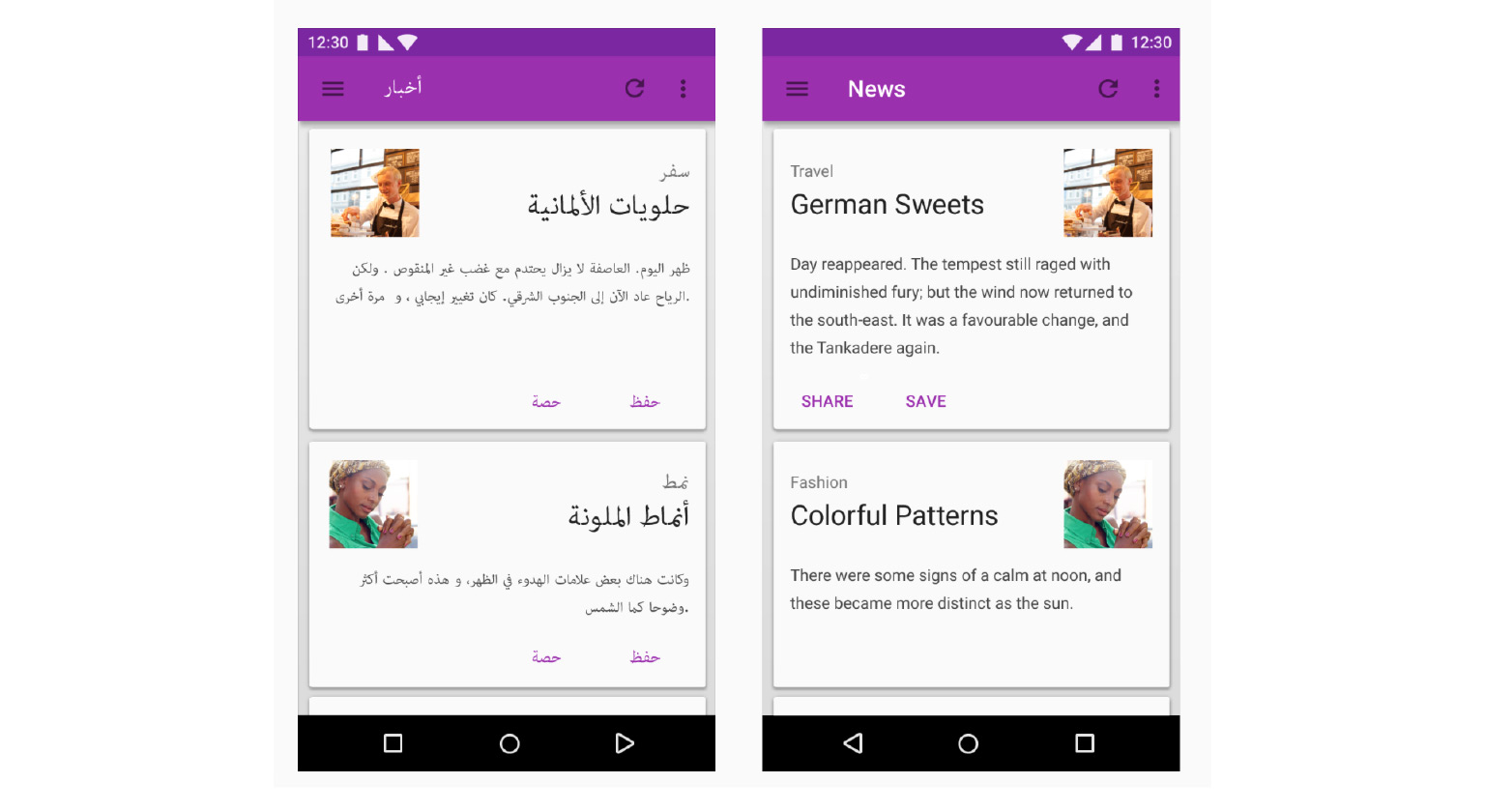
Выбранный язык может влиять не только на контент вашего приложения, не только на тексты. Он может влиять в том числе и на верстку.
Источник картинки
Например, на слайде вы видите интерфейс, в котором направление письма — справа налево, фотография выровнена по другому краю, кнопки Share и Save поменяны местами. Значит, вам нужно где-то в коде написать условия, которые в зависимости от языка отображают интерфейс либо одним, либо другим способом. Интернационализация — это сложно, нужно программировать, много нюансов. - А локализация — это когда вы учите ваше приложение работать на еще одном дополнительном языке: втором или 25-м, неважно.
В основном это значит, что вам нужно добавить в приложение много текстов. То есть оно у вас уже умеет переключаться между языками, умеет отображать даты и числа в правильном формате. Вам нужно просто добавить много переводов приложения.

Главное, чтобы это было возможно. Вам нужно не хардкодить тексты в верстке, а вынести их в отдельные файлы, хранить тексты отдельно от кода.

А в коде — ссылаться на них по ключам. Всё, дальше локализация — это просто. Переводчик идет по всем этим файлам с переводом и аккуратно добавляет туда новые фразы. Программировать не надо, думать не надо.
Кажется, что интернационализация — это сложно, а локализация — просто, рутинная работа.
Действительно ли это так? Нет, потому что есть два момента.
- В отличие от интернационализации, локализацию вам нужно выполнять постоянно и регулярно. Если вы делаете интернационализацию, то один раз научили приложение переключаться между языками и все. Но каждый раз, когда ваш разработчик коммитит в репозитории правки с изменениями интерфейса, ему нужно проверить, поменялись ли там тексты. И если да, нужно добавить переводы для всех этих текстов на все языки, которые поддерживают ваше приложение. И так в каждом коммите.
Вы можете либо делать это после каждого коммита, либо, например, раз в неделю накапливать все новые тексты и переводить их пачкой. Это был первый момент: локализацию нужно делать регулярно. - Разработчик, как правило, не владеет всеми языками, которые используются в приложении. В нашей стране, скорее всего, разработчик владеет русским и английским, а какими-нибудь турецким, немецким, французским, китайским — нет. В общем случае текст на этих языках для него как черный ящик. Он видит какие-то символы, но не понимает их смысл.
Значит, что разработчик никак не может оперировать этими текстами. Не может их менять, не может что-то поправить. Все тексты разработчик должен отдавать переводчику, который владеет соответствующим языком. И как правило, если языков много, то переводчик не один, а много.
И вам в команде, если проект поддерживает несколько языков, нужно организовать процесс, при котором вы регулярно берете все непереведенные фразы из проекта и отправляете их на перевод. А потом, когда переводчики присылают вам результат, обратно раскладываете это в свой проект.
Я называю этот процесс continuous localization, по аналогии с continuous integration, это такая непрерывная локализация в течение всей жизни приложения.
Представим, что вы в проекте хотите организовать такой процесс. Вы столкнетесь с тремя проблемами:
- Тексты хранятся в неудобном формате, в текстовых файлах. Понятно, почему это сделано: потому что это очень удобно при сборке приложения. Но это неудобно с точки зрения работы с текстами.
Представьте: у вас много файлов, они разбросаны по проекту, в них хранятся переводы. Для каких-то текстов есть переводы, для каких-то нет. Вам нужно найти все тексты без переводов и отдать переводчикам. Что вы будете делать? Напишете скрипт, который обходит файловую систему. Тексты хранятся в структурированном виде, например в xml или в json. Но вам все равно нужно их прочитать, распарсить, пройтись по их полям, поискать нужные тексты.
А еще в этих файлах могут быть синтаксические ошибки, вам нужно их как-то обработать. В общем, это целая большая проблема, на которую вам придется тратить время. И она возникает, потому что тексты хранятся в неудобном формате в виде json или xml-файлов. - Вам нужно придумывать, как вместе с текстами хранить дополнительную информацию, например статусы переводов или контекст. Представьте: у вас есть сотня фраз, и они все без перевода. Половину фраз вы уже отправили переводчикам, а половина — новая. Вам нужно ее взять и тоже отправить переводчикам.
Как вы их отличите между собой: тексты без перевода, отправленные и не отправленные переводчикам? Вам нужно понимать, в каком статусе текст. Например, хранить вместе с фразой признак, была ли она отправлена на перевод.

Еще один пример дополнительной информации — это контекст. Скажем, слово «перевести» в зависимости от контекста, в котором оно используется, может означать разные вещи. И если переводчик видит это слово, он без контекста не может понять, какой перевод от него ожидается.
Пример перевода без контекста — фотография меню в столовой во время Олимпиады в Сочи. Видите, есть блюдо «язык в тесте». Переведено слегка неправильно.

То есть вам нужно придумывать, как задать контекст для ваших переводов, и отдавать его переводчикам. А для этого вам нужно где-то хранить дополнительную информацию о нем с переводами. - Вам необходима автоматизация. Причем она не просто нужна в качестве удобства, облегчающего разработку, а именно необходима: без автоматизации вы можете делать ошибки, которые очень дорого исправлять. Ошибки из-за того, что разработчик не владеет языками и работает с текстами как с черным ящиком.

Представьте: у вас есть вот такая кнопка, «Добавить фото», и она переведена на три языка. Вы делаете продуктовую задачу, в которой меняется текст на кнопке, теперь там написано: «Добавить фото или видео».

Посмотрите на английский текст: перевод не соответствует русскому. Несмотря на то, что для этого фрагмента текста уже есть перевод, вам все равно нужно заново отправить его переводчикам, потому что он стал не актуальным.
А теперь посмотрите на турецкий язык. Лично я вижу непонятные символы и не могу сказать, соответствуют они тексту или нет. И понятно, что его тоже нужно отправить переводчику заново. Но если я забуду это сделать, то потом не смогу найти это место, т. к. не владею турецким языком. Это значит, что турецкие пользователи увидят в интерфейсе неправильный текст кнопки. В лучшем случае они сделают что-то неправильно, и им будет неудобно, а в худшем случае, они могут сделать не то действие и, например, потерять деньги, если ваш сервис как-то оперирует деньгами.
Если бы у вас была автоматизация, которая при изменении русского текста автоматически инвалидирует для него все переводы, то такой проблемы не было бы и вы не могли бы допустить такую ошибку. А руками вы можете ее допустить, и ее будет дорого исправлять.
Когда ребята в Яндексе в далеком 2013 году думали, как решить эти проблемы, они пришли к идее, что нужно работать с текстами и исходным кодом отдельно. Я не уверен, что эта идея была придумана в Яндексе, может быть, где-то вовне, но примерно в то же время. В чем она заключается?
Вы делаете отдельное хранилище: в нем хранятся тексты и переводы на все языки, переводчики работают с этим хранилищем. Оно решает проблемы, которые мы перечислили, потому что там вы можете хранить тексты в любом удобном виде, в базе данных, или работать с ними SQL-запросами. Вы можете сделать там любые дополнительные поля, хранить контекст, статусы, дополнительную справочную информацию, комментарии — любые дополнительные поля.
Так как вы полностью контролируете структуру этого хранилища и его API, вы можете накрутить туда любую автоматизацию. При работе с хранилищем будут автоматически выполняться нужные вам действия. Такое хранилище решает все проблемы, которые мы перечислили.
Как тексты будут попадать в исходный код, и вообще, как они будут попадать в хранилище?
Вы можете периодически выгружать из вашего проекта в хранилище русские фразы. Это очень простая операция, потому что она однонаправленная, загружает фразы на одном языке. У вас нет какой-то сложной логики.
Вторая операция — в обратную сторону: вы выгружаете из хранилища все переводы обратно в проект. Эта операция тоже простая, потому что вам не нужно смотреть на текущее состояние проекта, не нужно парсить все эти файлы с переводами. Вы просто берете из хранилища состояние переводов целиком и кладете его в проект.
Получается простая и надежная схема из двух операций. При этом переводчики работают с текстами удобно. Например, можно получить все тексты, которые необходимо перевести.
В Яндексе мы собрали команду разработки и написали сервис, который назвали Танкер. Это внутренний сервис Яндекса, как раз он и является хранилищем переводов.
Все команды Яндекса выгружают свои русские фразы в Танкер. Дальше переводчики согласно своим процессам с ними работают, добавляют туда переводы на все нужные языки. После этого переводы выгружаются из Танкера обратно в свои проекты.
Таким образом у нас получается следующий процесс.
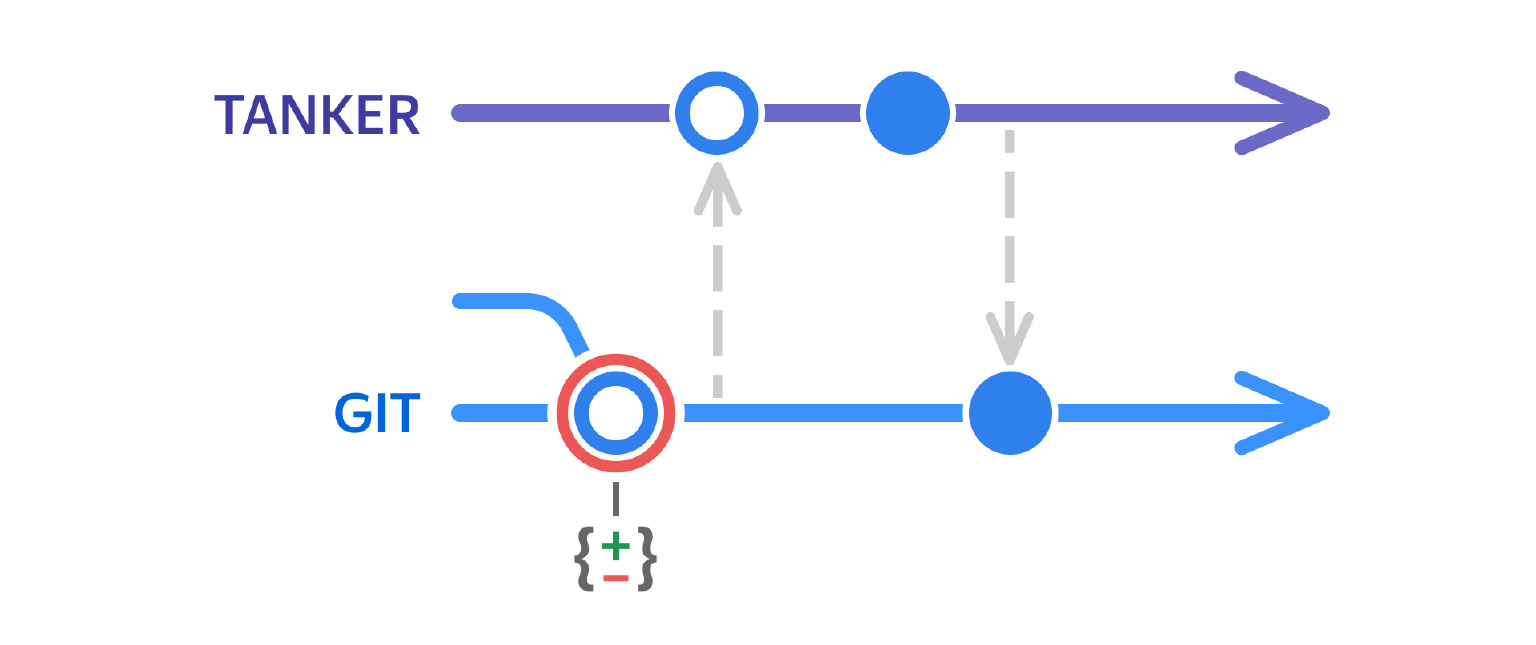
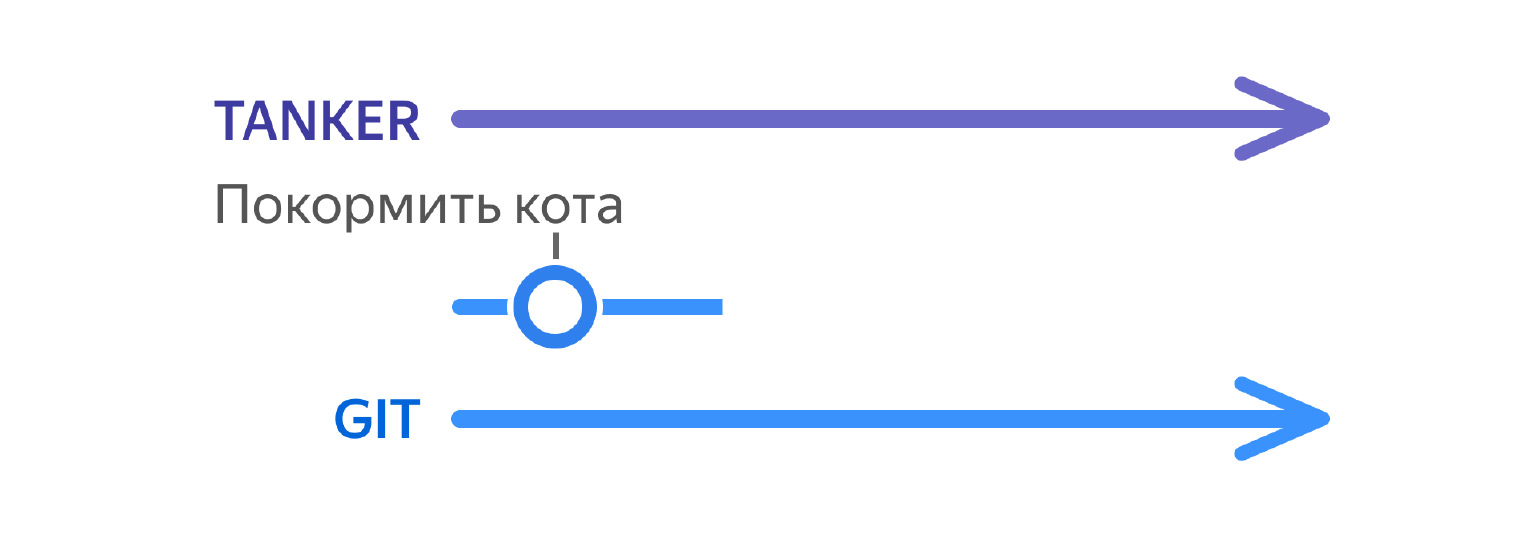
Представьте: вы разработчик, пишете проект, и вам нужно сделать вот такой pop-up, в котором есть кнопка «Покормить кота».
Вы вливаете в Git свою ветку с изменениями. Получается, в Git появился новый русский текст «Покормить кота».
После этого автоматически — например, ночью — запускается синхронизация, и русские тексты уезжают в Танкер. Не закрашенный кружочек — это текст без перевода.
Приходят переводчики и добавляют переводы для этого текста. Вы видите, что кружочек стал закрашенным.
Срабатывает еще одна синхронизация, перевод приезжает обратно в проект, затем происходит релиз. Пользователь видит в интерфейсе текст на понятном ему языке. Супер.
При помощи этой идеи с отделением переводов от кода проекта мы смогли организовать процесс многократный локализации. Мы можем после каждого коммита или после каждой пачки коммитов выгружать переводы и можем много раз загружать их обратно в проект.
Представим, что мы все это зарелизили, пошли в продакшен посмотреть, как у нас все красиво, и увидели, что там появилась новая кнопка, и она без переводов. Что же случилось?
Проблема в параллельной разработке. Давайте вернемся к нашей схеме, посмотрим, что произошло.
Эта схема больше похожа на реальную жизнь. Тут проект разрабатывает не один разработчик, а несколько. И мы видим, что работа над переводами кнопки «Покормить кота» занимает время. Это маленькая фраза, и она одна. В реальных задачах могут быть десятки, сотни фраз. Перевод может занимать от нескольких часов до нескольких дней.
Пока велась работа над переводами, пришли другие разработчики и закоммитили еще какие-то свои изменения, например кнопку «Напоить коня». При следующей синхронизации изменения уехали в Танкер, и они будут когда-то в будущем переведены, но в момент релиза они находятся в проекте без переводов.
Фишка в том, что если у вас большая команда разработки, то будет и высокий темп разработки, много коммитов. Значит, за время, пока идут переводы очередных коммитов, гарантированно будут появляться новые. В вашем интерфейсе гарантированно и постоянно будут возникать куски без переводов. Они будут с каждым релизом меняться, каждый раз будут разными, но что-то обязательно будет без переводов, и это печально.
Что можно сделать? Для начала — понять, в чем корень проблемы. Проблем две
- Работа над переводами начинается, уже когда код попал в master, в основную ветку проекта, мы при релизе выкатим его в продакшен, а переводы еще не готовы. Можно отводить релизные ветки и выкатывать не из master, а из релизных веток, но это значит, что когда вы отвели релизную ветку, пройдет несколько дней, прежде чем вы сможете ее выкатить.
Все релизы будут идти с задержкой на несколько дней. Задержка будет на то время, которое требуется для всех переводов в новом релизе. - У вас в Танкере все задачи валяются в общей куче. Вот хранилище переводов, там много текстов, и непонятно, к каким продуктовым задачам они относятся. Значит, для продуктовой задачи вы не можете ответить на вопрос, переведены ли все тексты под нее или нет. С этим тоже надо что-то делать.
Вы не можете принять решение, катить ли релиз в продакшен, не можете никак на перевод этой задачи. Не можете пойти к переводчикам и сказать: «Переведи вот эти тексты, потому что они мне срочно нужны для продуктового запуска». Что же делать?
Вторую проблему, кажется, можно решить, потому что в момент, когда разработчик мержит в основную ветку свои изменения, у нас есть дифф между ветками, которые он мержит. Грубо говоря, содержимое пул-реквеста, который он вливает.
Так как переводы в проекте хранятся в json-файликах, то мы можем в этом диффе видеть разницу, что поменялось в этих json-файликах. Так мы можем понять, примерно какие фразы поменялись в этой задаче.
--- src/components/Footer/lang/en.json Sat Jan 26 23:30:39 2020+++ src/components/Footer/lang/en.json Sat Jan 26 23:30:50 2020@@ -1,6 +1,6 @@ { "advertisement": "Advertising", - "guide-link": "Гид по интерфейсу",+ "guide-link": "Interface guide","self-agency-help-link": "Department for working with ad agencies" };
Я привел пример одного из наших проектов, там действительно фразы в json-файликах. Но у нас есть другие проекты, в которых фразы хранятся по-другому.
--- /trunk/src/desktop.blocks/trust-switcher.js Sat Jan 26 23:30:39 1991+++ /trunk/src/desktop.blocks/trust-switcher.js Sat Jan 26 23:30:50 1991@@ -9,3 +8,8 @@ }).then(function(response) {+ var frameTitle = shouldBindCard ? + iget2('trust-frame-title-bind', 'Привязка карты') : + iget2('trust-frame-title-pay', 'Пополнение общего счета'); +parent._setSubmitButtonProgress(false); parent._setTitle(frameTitle);
Например, русские фразы записаны прямо в коде как дефолтное значение, передаваемое в функцию локализации.
Тут мы тоже можем понять, какие фразы поменялись, но не можем делать это автоматически. Если человек смотрит — он поймет, какие фразы поменялись, но автоматом обработать эти изменения скриптом и получить список мы не можем. Но главное, что у нас хотя бы в таком неудобном виде есть нужная нам информация.
Что же делать с первой проблемой, с тем, что мы начинаем работать над переводами сразу, когда изменения попадают в master? Мы думали, как ее решить, и решили, что нужно сделать в Танкере, в хранилище переводов, механизм веток, похожий на ветки в системе контроля версий в Git.
То есть нужно уметь создавать ветки, строить между ними дифф, мержить их. Все как в системе контроля версий. Тогда можно было бы работать над переводами для разных задач в отдельных ветках, и они бы никак не конфликтовали.
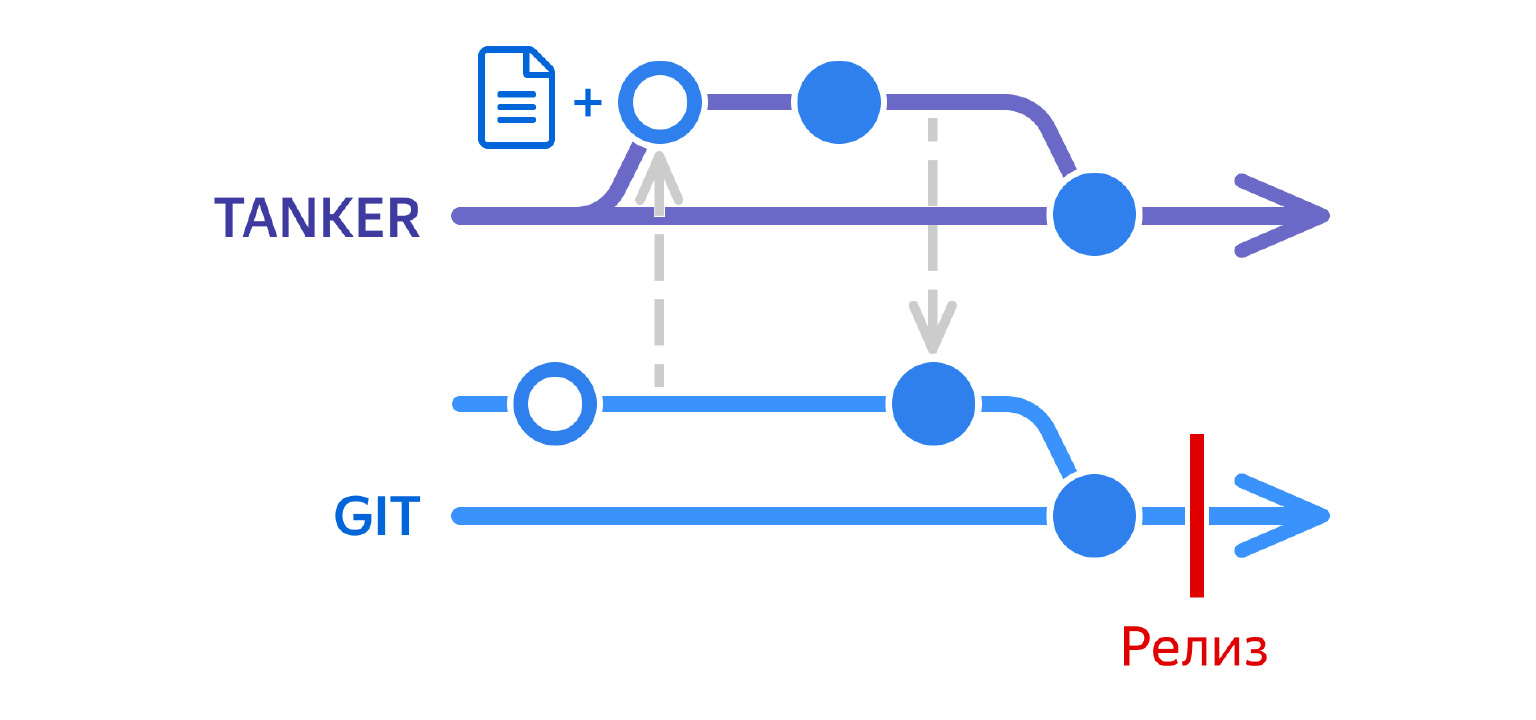
Смотрите, какой процесс у нас получился. Разработчик коммитит свою ветку системы контроля версий с изменениями. Это та же самая кнопка «Покормить кота».
Дальше он выгружает изменения в Танкер, но не в ветку master, не в основную ветку Танкера. Для своей задачи он создает отдельную ветку и выгружает изменения в нее.
После этого мы автоматически строим дифф между двумя ветками Танкера — веткой задачи и master. Получается список фраз, которые изменились в рамках этой задачи. То есть в master у нас полное состояние проекта, а в ветке у нас полное состояние плюс новые фразы, которые выгрузились из ветки задачи. Этот дифф мы всегда можем легко получить, он не зависит от того, в каком виде в проекте хранятся переводы, потому что мы сравниваем, грубо говоря, две таблички в БД.
Мы получаем этот дифф и на его основе создаем тикет в трекере, по которому переводчики работают над текстами. Они уже не смотрят в Танкер, не ищут все фразы без переводов. Они просто идут по списку и добавляют переводы для фраз, которые там указаны.
Дальше. Переводчики добавили переводы для всех языков.
Мы синхронизируем тексты обратно, и переводы приезжают в проект. Но опять же, они приезжают не в master, а в ветку, где разработчик работал над задачей.
Тут важны два момента. Первый: в проекте есть ветка, она еще не влита в master, а в ней уже есть все переводы для нашей продуктовой задачи.
Второй важный момент в том, что разработчик отправляет тексты на перевод, не дожидаясь, пока задача поревьювится, потестируется. Как только он закончил работу над задачей, и у него появилось понимание, что тексты уже не будут меняться, он сразу отправляет их на перевод. Перевод идет параллельно с код-ревью и тестированием задачи.
Когда переводы вливаются в систему контроля версий, то задача уже, как правило, проревьюена и протестирована. Тестировщикам остается коротко проверить локализацию, то есть собрать новый стенд со всеми переводами и убедиться, что тексты на разных языках не ломают верстку.
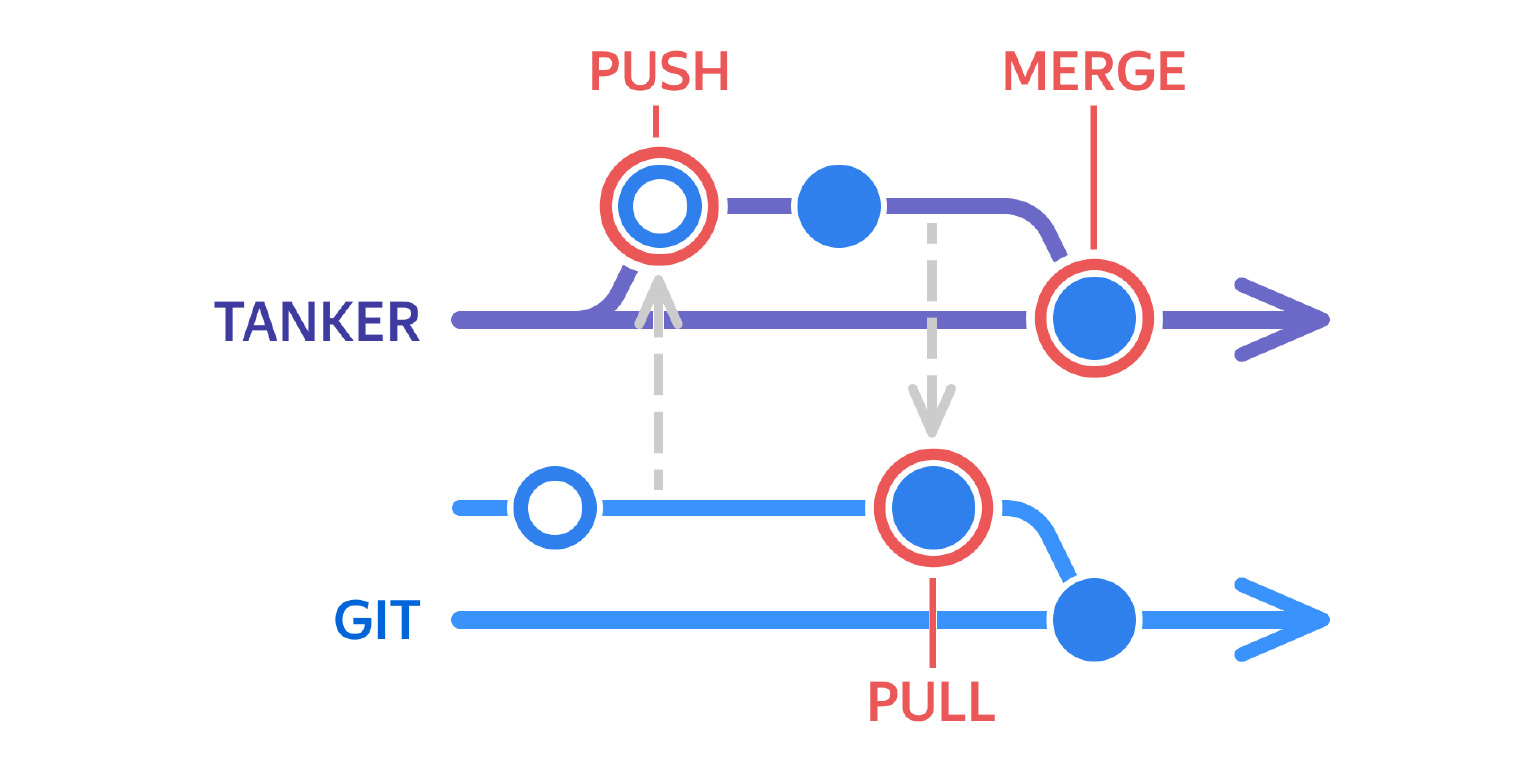
После этого разработчик может вливать все в master. Параллельно ему нужно влить ветку Танкера в master.
Таким образом, каждая ветка каждого разработчика, каждая задача, вливается в master сразу с переводами. Мы в любой момент можем провести релиз. Мы уверены, что пользователь получит корректное состояние интерфейса, что все тексты будут на нужном ему языке. Круто.
Мы не сразу пришли к этому процессу. Много экспериментировали, проверяли теории. В результате у нас получилась вот такая схема, и мы были очень рады, потому что это здорово раскладывает все по полочкам и наводит порядок в процессе локализации.
Но когда мы хотели распространить это на всю команду, сделать, чтобы вся команда, 40 человек, работала по этому процессу, то столкнулись с человеческими ошибками.
Многие из вас пользуются системой контроля версий Git. Вспомните, что было, когда вы только начинали ее осваивать. Лично у меня в первые месяцы работы постоянно были ситуации, когда я что-то не туда смержил, неправильно решил конфликты, внес изменения и потом два дня разбирался, как откатить то, что у меня потерялось.
Мы дали команде новый инструмент работы с переводами, но это тоже новая система для разработчика. Там нужно было выполнять действия, принимать решения. Любое принятие решений — это стресс. А когда это новая вещь, вы можете принять неправильное решение, сделать ошибку. Ошибка — это десятикратный стресс.
Что делает человек, когда он в стрессе и совершает ошибку? Начинает злиться на того, кто принес ему этот инструмент, и того, кто вызвал этот стресс.
Представьте: у вас команда из 40 человек, каждый разработчик один-два раза в неделю делает ошибку и приходит к вам злиться. А теперь представьте, что эти 40 человек постоянно к вам приходят. Когда на вас злится столько людей, это не очень приятно.
Поэтому у нас в первое время был специальный дежурный, человек, который разруливал все проблемы, отвечал на вопросы, помогал вернуть потерянные изменения. Затем мы постепенно записали все вопросы, с которыми люди приходили, в документ и написали туда ответы. А потом мы все это дело автоматизировали.
Давайте вернемся к нашей схеме. Вот наш процесс, у нас получилось всего три точки, когда разработчику нужно принять решение и инициировать какие-то действия.
Мы их называем по аналогии с командами GIT PUSH, PULL и MERGE. С помощью каждой из этих команд разработчик запускает какой-то один скрипт, который делает все остальные действия и выполняет проверки.
Когда разработчик запускает PUSH, то скрипт сначала проверяет, есть ли ветка в Танкере с таким же названием, как у ветки задач. Если ее нет, она создается, если есть — актуализируется. В нее подмерживается ветка master из Танкера.
Дальше мы выгружаем из текущей ветки проекта фразы в ветку Танкера. После этого автоматически скриптом строим дифф, создаем в трекере тикет для переводчиков и автоматически передаем его в работу. То есть разработчик запускает скрипт и на выходе получает тикет, который уже находится в работе и через некоторое время будет переведен. Когда тикет закрыт, разработчик по изменению статуса будет видеть, что переводы для задачи готовы.
Следующая команда — PULL. Это относительно простая команда, позволяет подтянуть изменения из ветки Танкера в ветку проекта.
Что здесь происходит? Мы опять находим ветку в Танкере, соответствующую текущей задаче. Опять ее актуализируем. Вообще, мы актуализируем ветку в Танкере при запуске каждой команды. Подмерживаем туда master и выгружаем фразы из Танкера в проект.
Третья команда — MERGE. Мы находим ветку в Танкере, подмерживаем в нее ветку master, чтобы ветка в Танкере была актуальной. Дальше находим тикет на перевод и проверяем, что он закрыт. Это защищает разработчика от ситуации, когда он замержил ветки в Танкере, в которых еще не готовы переводы.
После этого мы мержим ветку Танкера в master Танкера и проставляем в тикете признак о том, что он закоммичен. Этот признак мы можем использовать в других проверках, которые происходят автоматически. Например, мы можем в Git сделать прекоммит-хук, не дающий замержить ветку, переводы в которой поменялись и не закоммичены в master Танкера.
Таким образом мы запустили процесс в большой команде, и ключевая вещь, которая позволила нам его запустить, — то, что мы все автоматизировали. Мы упростили действия, которые нужно делать людям, и они перестали совершать человеческие ошибки.
Последняя вещь, о которой я хочу с вами поговорить, — это конфликты слияния. Мы говорили, что в Танкере есть ветки. Разработчики параллельно меняют в них тексты. Такое происходит редко, но может получиться, что два разработчика поменяли одну и ту же фразу разными способами. Они получают конфликты слияния, как в Git. Как мы это решаем?
Первый разработчик мержит свою ветку в master Танкера и не получает конфликты, потому что в master Танкера еще нет конфликтующих изменений. Когда второй разработчик попытается замержить свою ветку, Танкер вернет ему вот такой json-фал, в котором есть вся информация о конфликтах.
{ "account/btn-upload/ru": { "form": { "a": "Загрузить фото", "b": "Загрузить картинку или видео","resolved": null}, "hash": "2b5eea08e20948ade12e306c62e3dee" } }
Тут указано, во-первых, в какой фразе, в каком ключе произошел конфликт. Во-вторых, указаны две конфликтующие формы — как было в одной ветке и как стало в другой. Для каждого конфликта указан некоторый хэш. Это хэш-сумма от всех этих полей. По этому хэшу Танкер понимает, что данный элемент файла с конфликтами относится к определенному конфликту ветки.
Разработчику нужно заполнить в этом файле поле resolved. То есть он попытался смержить ветку, получил такой большой файл, в котором перечислены все конфликты, а поле resolved пустое. Он прошелся по этому файлику, указал в поле resolved правильное значение фразы. После этого он повторно пытается смержить ветку и отправляет этот файл с ложными значениями как один из параметров.
Если Танкер при мерже ветки встречает конфликт, он смотрит по хэш-сумме, есть ли для данного конфликта информация о его решении. Если есть — использует значение их поля resolved.
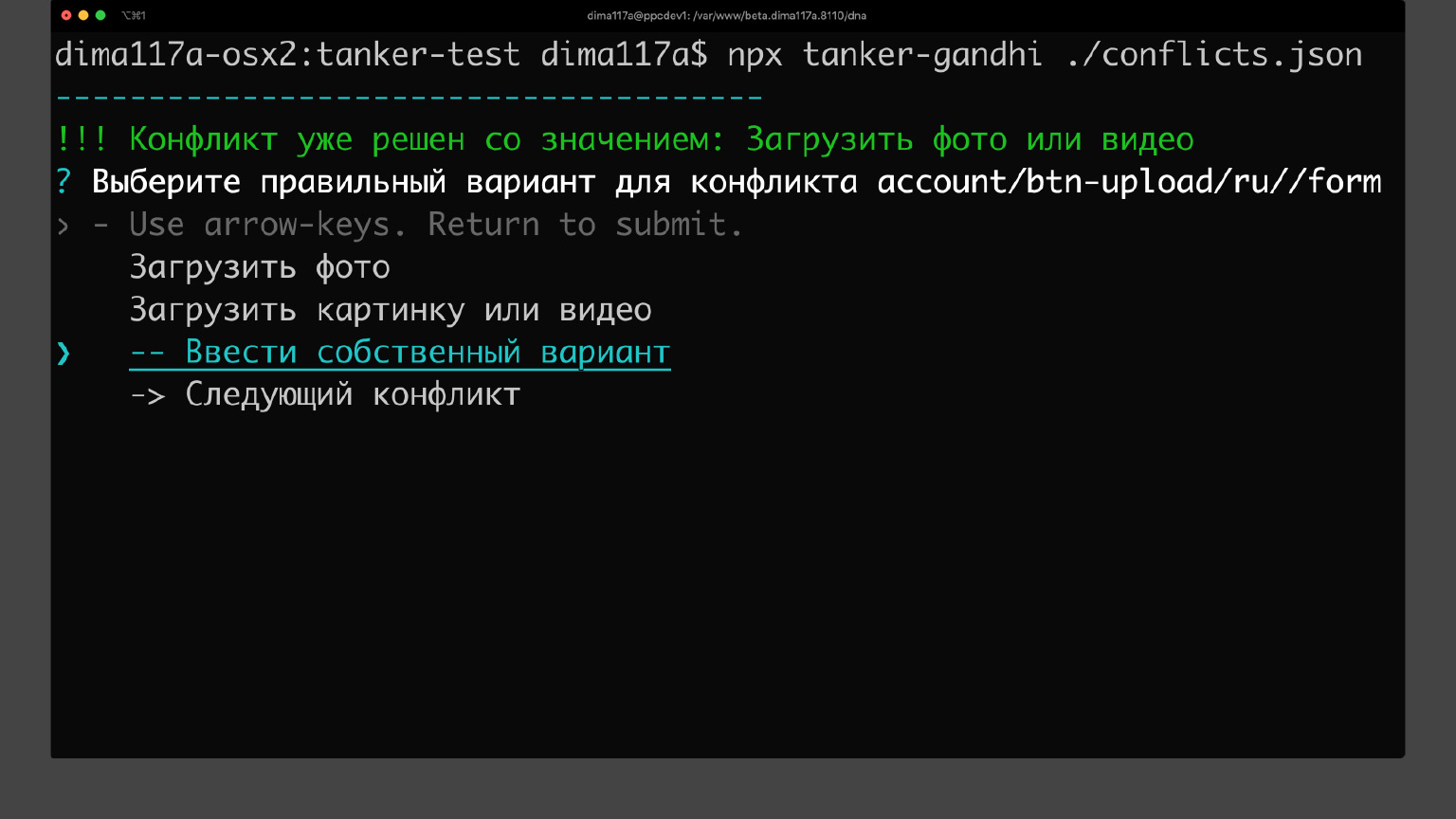
Это все, конечно, круто работает, но неудобно править большие json-файлы руками. Можно написать что-то не туда, перепутать фразы или поставить лишнюю запятую и будет синтаксическая ошибка. Танкер не сможет распарсить этот json-файл. Поэтому мы написали небольшую утилиту для интерактивного решения конфликтов. Это консольная утилита.
Вы открываете в ней json-файл, и она по очереди показывает вам все конфликты. Вы можете стрелочками выбрать нужный вариант или ввести свой.
Почему мы сделали ее консольной? Потому что работа с проектом у нас часто происходит на удаленном сервере, через терминал. С такой консольной утилитой можно тоже работать в терминале.
Еще один интересный момент: человек, который ее писал, назвал ее Танкер-Ганди — в честь миротворца Ганди, который много понимал в решении конфликтов.
Давайте подытожим все, о чем мы сейчас говорили. У нас был один огромный проект на три языка. В нем было больше 20 тысяч фрагментов текста, 40 фронтенд-разработчиков. За время, пока работает этот процесс, то есть за один год и два месяца, мы перевели 2 700 продуктовых тикетов, и все они сразу выкатились в продакшен с переводами на все языки.
Не было проблем с конфликтами, с тем, что фразы потерялись. Все отработало четко. Разработка при этом не тормозилась из-за того, что мы делаем дополнительную работу по переводу текстов. Кажется, это классный результат.
Я хочу, чтобы вы запомнили из моего доклада две вещи:
- Во-первых, используйте платформу для переводов. Идея отделить тексты от кода проекта — ключевая вещь, которая позволила нам организовать весь процесс локализации.
Я рассказывал в докладе про Танкер. Это внутренний сервис Яндекса, он недоступен снаружи. Но есть много других сервисов, вы можете пользоваться ими: gitlocalize.com, crowdin.com, locize.com. Они умеют примерно то же самое. Некоторые даже умеют делать переводы в ветках. Вы можете повторить этот процесс на своем проекте, если захотите. - Если у вас много людей, то автоматизация может помочь вам победить хаос в команде. Автоматизируйте все что можно, и вы сэкономите время себе и другим людям.
На этом у меня все, спасибо.
Видео доклада




