
«ReFS» (Resilient File System) – это новая файловая система от Microsoft, которая создавалась как замена «NTFS». У нее есть несколько солидных преимуществ, а именно, разработчики исправили все ошибки «NTFS». Она гораздо больше защищена от повреждения информации, она лучше переносит возросшую нагрузку, а также масштабируется гораздо проще.

Целостность информации, использование контрольных сумм для метаданных.
Запись информации — Integrity streams (повышенная защита файлов при ошибке части носителя).
«allocate on write» — новая транзакционная модель.
Масштабируемость, увеличенные лимиты на объем каталогов, файлов, разделов.
Работа с пулами разделов, виртуализация разделов.
«data sriping» — система увеличивает производительность и отказоустойчивость данных, избыточная запись информации как в RAID массивах.
Чтобы выявить скрытые ошибки используется функция — «disk scrubbing», очистка диска в фоне.
Пересохранение информации возле проблемных блоков диска.
Единые пулы носителей, на нескольких компьютерах по сети, повышает отказоустойчивость, уменьшает нагрузку.
Поддержка большинства стандартных функций «NTFS».
Система верификации информации.
Отключение «ReFS» невозможно, так как сбойные сектора изолируются.
«Storage Spaces» — новая уникальная гибкая архитектура.
Еще новая ФС унаследовала часть функционала «NTFS»: работа с «BitLocker», «USN» журналирование, «ACL» контролируемый доступ, «mount points»… Естественно, общий объем данных и подключение к разделам«ReFS», доступны по тем же «API».
Контрольные суммы теперь используются для метаданных по умолчанию, также их применяют и к данным отдельных файлов. Так, в процессе чтения\записи, осуществляется верификации «на лету». Когда ФС обнаружит повреждение файлов, то моментально удалит записи без перезагрузки компьютера. То есть, «ReFS» теперь самостоятельно себя корректирует при появлении ошибок.
«ReFS» обеспечивает более высокую надежность сохранения информации, по сравнению со старой ФС. Для хранения файлов и метаданных используются «B+-деревья». Размеры, количество разделов и файлов теперь ограничены максимальным 64-битным значением. Пустое пространство хранится в трех разных таблицах, разбитых по объемам фрагментов (малых, средних, больших). Названия файлов и пути пишуться в «Unicode», они не должны превышать 32 килобайта, то есть название файла можно указывать в 30 тысяч знаков.
Защита от отключения питания. Допустим вы прописываете новое имя файла (или другие метаданные), пропало электричество и вы не успели их сохранить. В «NTFS» — файл будет поврежден, так как вы меняете метаданные напрямую. Но «ReFS» всего лишь делает копию метаданных, и не меняет основные пока не произойдет сохранение, особенность работы функции «Copy-on-write».
Технология «Storage Spaces» — это функция виртуализации носителей. Она позволяет создать единое пространство из нескольких физических дисков на одном ПК или нескольких по локальной сети. Также есть возможность настроить «зеркалирование» как RAID массивах.
«ReFS» изначально создана для поддержки больших объемов разделов, файлов, каталогов и их имен. Новая ФС может включать до двести шестидесяти двух тысяч эксабайт информации, а «NTFS» — только шестнадцать эксабайт.
Еще, в ней отсутствуют функции шифрования, сжатия, дедупликации, дисковые квоты, жесткие ссылки и расширенные атрибуты. Некоторые из них заменены на новые, например, «ReFS» полностью поддерживает шифрование «BitLocker».
Сейчас, в файловую систему «ReFS» вы сможете отформатировать только пул дисков (пространство хранения), где новая ФС покажет себя во всей красе. Но Windows 10 не разрешит отформатировать обычный носитель в «ReFS». Разработчики подчеркивают значение «ReFS» именно для серверов, она доступна на серверных ОС или в «LTSC» версии.
ОС Windows Server 2016 позволит отформатировать обычные тома в «ReFS», но не позволит отформатировать загрузочный диск, потому что загрузочный сектор должен быть на «NTFS» разделе.
Структур ReFS значительно отличается от всех остальных файловых систем для Windows. Главными структурными элементами выступают «B+ деревья». Они бывают одноуровневыми (как листья) и многоуровневыми (как деревья). Это обуславливает хорошее масштабирование, для каждого элемента, входящего в структуру ФС. Эта схема, а также 64-битная адресация каждого элемента, делают невозможным проблемы при ее дальнейшем увеличении.
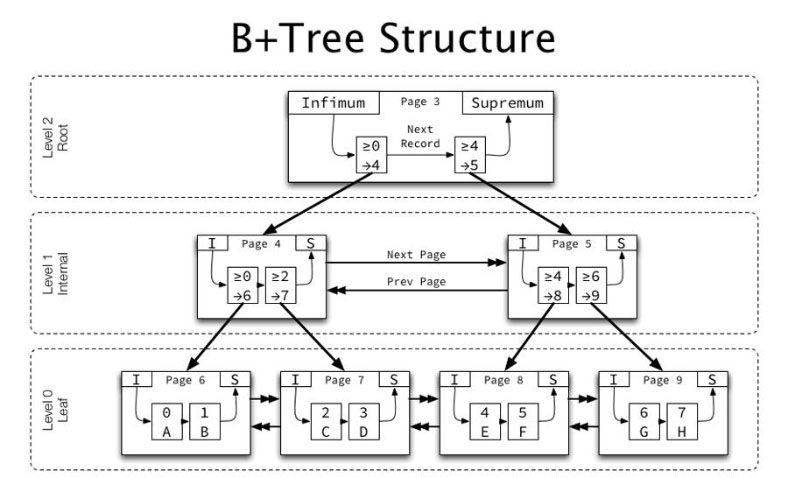
Как корневая запись B+дерева, остальные записи имеют такой же объем в 16 кб, для блока метаданных. Размер в 60 байт — выделен для промежуточны (адресных) узлов. Следовательно, для правильного описания масштабных структур хранения потребуется малое количество уровней. Это позволило увеличить производительность ФС, по сравнению с другими.
«ReFS» можно определить по специфической сигнатуре, которая расположена в начале раздела:

0x4000 байт — длина всех страниц ReFS.

Номер первой страницы — 0x1e, то есть 0x78000 байт которые идут сразу за загрузочным разделом. Это стандартное отображение Microsoft, которое информирует, что первые метаданные нужно искать после фиксированного смещения.
Утилиты для восстановления данных выполнят полное сканирование дискового пространства, отформатированного под «ReFS», используя алгоритм анализа по сигнатурам. Проверяя диск блок за блоком, они обнаружат готовые последовательности данных, определят их и выведут результаты. Так как API для работы с дисками для «ReFS» и «NTFS» одинаковы, то и процессы восстановления данных предельно схожи.
Сначала определяется «Volume Header», в нем записано количество секторов на кластер и какой объем сектора. Основная версия лежит в нулевом секторе, а копия расположена в последнем. Далее считывается «Superblock», он расположен в 30-ом блоке и также есть 2 копии во втором и третьем блоке в конце. Из него, извлекается ссылки на «чекпоинт» и его копию, определяется его последняя актуальная версия по «Virtual Allocated Clock».
Checkpoint содержит информацию об основных таблицах, далее считываются заголовки «Page Header» и блоки с указателями (Pointers) на полный список таблиц. Потом ищется «Container Table» для получения физических адресов из виртуальных, и выполняется поиск по «Object ID Table» — все таблицы найдены.
Утилиты доходят до нулевых уровней — то есть «листов b-дерева», и считывают данные файлов. Так как поиск ведется постранично, то если есть сбои — эти элементы просто исключаются из анализа, а сам процесс сканирования идет дальше. Таким образом утилиты для восстановления данных находят всю информацию, которую возможно «достать» с диска.
Полную версию статьи со всеми дополнительными видео уроками смотрите в источнике.
Основные функции Resilient File System
Целостность информации, использование контрольных сумм для метаданных.
Запись информации — Integrity streams (повышенная защита файлов при ошибке части носителя).
«allocate on write» — новая транзакционная модель.
Масштабируемость, увеличенные лимиты на объем каталогов, файлов, разделов.
Работа с пулами разделов, виртуализация разделов.
«data sriping» — система увеличивает производительность и отказоустойчивость данных, избыточная запись информации как в RAID массивах.
Чтобы выявить скрытые ошибки используется функция — «disk scrubbing», очистка диска в фоне.
Пересохранение информации возле проблемных блоков диска.
Единые пулы носителей, на нескольких компьютерах по сети, повышает отказоустойчивость, уменьшает нагрузку.
Поддержка большинства стандартных функций «NTFS».
Система верификации информации.
Отключение «ReFS» невозможно, так как сбойные сектора изолируются.
«Storage Spaces» — новая уникальная гибкая архитектура.
Еще новая ФС унаследовала часть функционала «NTFS»: работа с «BitLocker», «USN» журналирование, «ACL» контролируемый доступ, «mount points»… Естественно, общий объем данных и подключение к разделам«ReFS», доступны по тем же «API».
Особенности «ReFS»
Контрольные суммы теперь используются для метаданных по умолчанию, также их применяют и к данным отдельных файлов. Так, в процессе чтения\записи, осуществляется верификации «на лету». Когда ФС обнаружит повреждение файлов, то моментально удалит записи без перезагрузки компьютера. То есть, «ReFS» теперь самостоятельно себя корректирует при появлении ошибок.
«ReFS» обеспечивает более высокую надежность сохранения информации, по сравнению со старой ФС. Для хранения файлов и метаданных используются «B+-деревья». Размеры, количество разделов и файлов теперь ограничены максимальным 64-битным значением. Пустое пространство хранится в трех разных таблицах, разбитых по объемам фрагментов (малых, средних, больших). Названия файлов и пути пишуться в «Unicode», они не должны превышать 32 килобайта, то есть название файла можно указывать в 30 тысяч знаков.
Защита от отключения питания. Допустим вы прописываете новое имя файла (или другие метаданные), пропало электричество и вы не успели их сохранить. В «NTFS» — файл будет поврежден, так как вы меняете метаданные напрямую. Но «ReFS» всего лишь делает копию метаданных, и не меняет основные пока не произойдет сохранение, особенность работы функции «Copy-on-write».
Технология «Storage Spaces» — это функция виртуализации носителей. Она позволяет создать единое пространство из нескольких физических дисков на одном ПК или нескольких по локальной сети. Также есть возможность настроить «зеркалирование» как RAID массивах.
Отличия от NTFS
«ReFS» изначально создана для поддержки больших объемов разделов, файлов, каталогов и их имен. Новая ФС может включать до двести шестидесяти двух тысяч эксабайт информации, а «NTFS» — только шестнадцать эксабайт.
Еще, в ней отсутствуют функции шифрования, сжатия, дедупликации, дисковые квоты, жесткие ссылки и расширенные атрибуты. Некоторые из них заменены на новые, например, «ReFS» полностью поддерживает шифрование «BitLocker».
Сейчас, в файловую систему «ReFS» вы сможете отформатировать только пул дисков (пространство хранения), где новая ФС покажет себя во всей красе. Но Windows 10 не разрешит отформатировать обычный носитель в «ReFS». Разработчики подчеркивают значение «ReFS» именно для серверов, она доступна на серверных ОС или в «LTSC» версии.
ОС Windows Server 2016 позволит отформатировать обычные тома в «ReFS», но не позволит отформатировать загрузочный диск, потому что загрузочный сектор должен быть на «NTFS» разделе.
Архитектура файловой системы
Структур ReFS значительно отличается от всех остальных файловых систем для Windows. Главными структурными элементами выступают «B+ деревья». Они бывают одноуровневыми (как листья) и многоуровневыми (как деревья). Это обуславливает хорошее масштабирование, для каждого элемента, входящего в структуру ФС. Эта схема, а также 64-битная адресация каждого элемента, делают невозможным проблемы при ее дальнейшем увеличении.
Как корневая запись B+дерева, остальные записи имеют такой же объем в 16 кб, для блока метаданных. Размер в 60 байт — выделен для промежуточны (адресных) узлов. Следовательно, для правильного описания масштабных структур хранения потребуется малое количество уровней. Это позволило увеличить производительность ФС, по сравнению с другими.
Структура файловой системы ReFS
«ReFS» можно определить по специфической сигнатуре, которая расположена в начале раздела:
0x4000 байт — длина всех страниц ReFS.
Номер первой страницы — 0x1e, то есть 0x78000 байт которые идут сразу за загрузочным разделом. Это стандартное отображение Microsoft, которое информирует, что первые метаданные нужно искать после фиксированного смещения.
Алгоритм поиска удаленных данных
Утилиты для восстановления данных выполнят полное сканирование дискового пространства, отформатированного под «ReFS», используя алгоритм анализа по сигнатурам. Проверяя диск блок за блоком, они обнаружат готовые последовательности данных, определят их и выведут результаты. Так как API для работы с дисками для «ReFS» и «NTFS» одинаковы, то и процессы восстановления данных предельно схожи.
Сначала определяется «Volume Header», в нем записано количество секторов на кластер и какой объем сектора. Основная версия лежит в нулевом секторе, а копия расположена в последнем. Далее считывается «Superblock», он расположен в 30-ом блоке и также есть 2 копии во втором и третьем блоке в конце. Из него, извлекается ссылки на «чекпоинт» и его копию, определяется его последняя актуальная версия по «Virtual Allocated Clock».
Checkpoint содержит информацию об основных таблицах, далее считываются заголовки «Page Header» и блоки с указателями (Pointers) на полный список таблиц. Потом ищется «Container Table» для получения физических адресов из виртуальных, и выполняется поиск по «Object ID Table» — все таблицы найдены.
Утилиты доходят до нулевых уровней — то есть «листов b-дерева», и считывают данные файлов. Так как поиск ведется постранично, то если есть сбои — эти элементы просто исключаются из анализа, а сам процесс сканирования идет дальше. Таким образом утилиты для восстановления данных находят всю информацию, которую возможно «достать» с диска.
Полную версию статьи со всеми дополнительными видео уроками смотрите в источнике.


