

Привет! На связи Артемий – энтузиаст в сфере Data Warehousing, Analytics, DataOps.
Уже продолжительное время я занимаюсь моделированием DWH с использованием dbt, и сегодня пришло время познакомить вас с package для построения Data Vault – dbtVault.
В публикации:
Готовим датасет TPC-H
Поднимаем кластер Greenplum в Яндекс.Облаке
Погружаемся в кодогенерацию и макросы dbtVault
Cимулируем инкрементальное наполнение Data Vault
Кодогенерация для Data Vault
Подход к построению Хранилища Данных на основе методолгии Data Vault или гибридных, схожих с ней, обретает новый виток популярности и интереса в последнее время. Это неудивительно – несмотря на сложность и обилие объектов в БД, преимущества и гибкость однозначно перевешивают в долгосрочной перспективе:
Единая логическая модель данных – мыслим бизнес-сущностями, а не системами-источниками
Возможность быстрого, параллельного и инкрементального наполнения Хранилища
Гибкость расширения модели и схемы данных – новые сущности и атрибуты
Хэш-сумма для генерации суррогатных ключей и отслеживания изменений атрибутов

И любой, кто когда-либо изучал Data Vault согласится, что обойтись без инструментов кодогенерации будет весьма затруднительно. Инструменты этого класса призваны решить ряд задач:
Генерация кода по шаблонам для десятков и сотен объектов
Управление метаданными
Построение графа зависимостей (DAG)
Документация проекта
Одним из таких инструментов является проект dbtVault, который представляет из себя модуль для dbt.
Готовим исходные данные – TPC-H
Мы будем работать со знаменитым датасетом для сравнения производительности баз данных (benchmarking) TPC-H. Это синтетические данные, описывающие предметную область оптовых поставок-продаж. К тому же, при генерации можно указать scale factor и получить данные в кратном объеме (х10, х100, х1000).

Для тех, кому не терпится приступить к моделированию, я заботливо сгенерировал исходные файлы общим объемом 10Гб и разместил в Yandex Object Storage:
mkdir tpch && cd tpch
# option 1 – curl
curl -O "https://storage.yandexcloud.net/otus-dwh/tpch-dbgen/{customer,lineitem,nation,orders,part,partsupp,region,supplier}.csv"
# option 2 – aws s3
aws configure # enter your Key ID / Secret Key
aws --endpoint-url=https://storage.yandexcloud.net s3 ls s3://otus-dwh/tpch-dbgen/ # list files
aws --endpoint-url=https://storage.yandexcloud.net s3 sync s3://otus-dwh/tpch-dbgen/ . # sync filesВ github gist есть инструкция по генерации файлов самостоятельно: Generate data with DBGen
Готовим кластер Greenplum в Яндекс.Облаке
В целях демонстрации я предлагаю использовать кластер Greenplum в Яндекс.Облаке. Следующей конфигурации будет достаточно для работы с нашим датасетом:
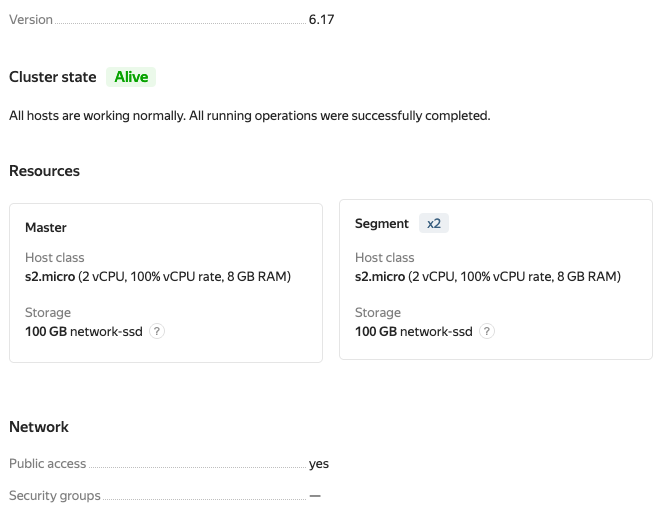
Альтернативно – можно пробовать использовать любую другую СУБД семейства PostgreSQL: Redshift, Vertica, Greenplum. Еще более альтернативно – с минимальными адаптациями код может быть исполнен почти в любой СУБД на ваш выбор. Об этом чуть ниже.
Наполним Greenplum данными
Сначала создадим определения для таблиц:
DDL scripts to create table
CREATE TABLE customer
(C_CUSTKEY INT,
C_NAME VARCHAR(25),
C_ADDRESS VARCHAR(40),
C_NATIONKEY INTEGER,
C_PHONE CHAR(15),
C_ACCTBAL DECIMAL(15,2),
C_MKTSEGMENT CHAR(10),
C_COMMENT VARCHAR(117))
WITH (appendonly=true, orientation=column)
DISTRIBUTED BY (C_CUSTKEY);
CREATE TABLE lineitem
(L_ORDERKEY BIGINT,
L_PARTKEY INT,
L_SUPPKEY INT,
L_LINENUMBER INTEGER,
L_QUANTITY DECIMAL(15,2),
L_EXTENDEDPRICE DECIMAL(15,2),
L_DISCOUNT DECIMAL(15,2),
L_TAX DECIMAL(15,2),
L_RETURNFLAG CHAR(1),
L_LINESTATUS CHAR(1),
L_SHIPDATE DATE,
L_COMMITDATE DATE,
L_RECEIPTDATE DATE,
L_SHIPINSTRUCT CHAR(25),
L_SHIPMODE CHAR(10),
L_COMMENT VARCHAR(44))
WITH (appendonly=true, orientation=column, compresstype=ZSTD)
DISTRIBUTED BY (L_ORDERKEY,L_LINENUMBER)
PARTITION BY RANGE (L_SHIPDATE)
(start('1992-01-01') INCLUSIVE end ('1998-12-31') INCLUSIVE every (30),
default partition others);
CREATE TABLE nation
(N_NATIONKEY INTEGER,
N_NAME CHAR(25),
N_REGIONKEY INTEGER,
N_COMMENT VARCHAR(152))
WITH (appendonly=true, orientation=column)
DISTRIBUTED BY (N_NATIONKEY);
CREATE TABLE orders
(O_ORDERKEY BIGINT,
O_CUSTKEY INT,
O_ORDERSTATUS CHAR(1),
O_TOTALPRICE DECIMAL(15,2),
O_ORDERDATE DATE,
O_ORDERPRIORITY CHAR(15),
O_CLERK CHAR(15),
O_SHIPPRIORITY INTEGER,
O_COMMENT VARCHAR(79))
WITH (appendonly=true, orientation=column, compresstype=ZSTD)
DISTRIBUTED BY (O_ORDERKEY)
PARTITION BY RANGE (O_ORDERDATE)
(start('1992-01-01') INCLUSIVE end ('1998-12-31') INCLUSIVE every (30),
default partition others);
CREATE TABLE part
(P_PARTKEY INT,
P_NAME VARCHAR(55),
P_MFGR CHAR(25),
P_BRAND CHAR(10),
P_TYPE VARCHAR(25),
P_SIZE INTEGER,
P_CONTAINER CHAR(10),
P_RETAILPRICE DECIMAL(15,2),
P_COMMENT VARCHAR(23))
WITH (appendonly=true, orientation=column)
DISTRIBUTED BY (P_PARTKEY);
CREATE TABLE partsupp
(PS_PARTKEY INT,
PS_SUPPKEY INT,
PS_AVAILQTY INTEGER,
PS_SUPPLYCOST DECIMAL(15,2),
PS_COMMENT VARCHAR(199))
WITH (appendonly=true, orientation=column)
DISTRIBUTED BY (PS_PARTKEY,PS_SUPPKEY);
CREATE TABLE region
(R_REGIONKEY INTEGER,
R_NAME CHAR(25),
R_COMMENT VARCHAR(152))
WITH (appendonly=true, orientation=column)
DISTRIBUTED BY (R_REGIONKEY);
CREATE TABLE supplier
(S_SUPPKEY INT,
S_NAME CHAR(25),
S_ADDRESS VARCHAR(40),
S_NATIONKEY INTEGER,
S_PHONE CHAR(15),
S_ACCTBAL DECIMAL(15,2),
S_COMMENT VARCHAR(101))
WITH (appendonly=true, orientation=column)
DISTRIBUTED BY (S_SUPPKEY);Затем наполним таблицы данными. На машине с установленной CLI-утилитой psql загрузим csv-файлы в базу:
export GREENPLUM_URI="postgres://greenplum:<pass>@<host>:5432/postgres"
psql $GREENPLUM_URI
\copy customer from '/home/dbgen/tpch-dbgen/data/customer.csv' WITH (FORMAT csv, DELIMITER '|');
\copy lineitem from '/home/dbgen/tpch-dbgen/data/lineitem.csv' WITH (FORMAT csv, DELIMITER '|');
\copy nation from '/home/dbgen/tpch-dbgen/data/nation.csv' WITH (FORMAT csv, DELIMITER '|');
\copy orders from '/home/dbgen/tpch-dbgen/data/orders.csv' WITH (FORMAT csv, DELIMITER '|');
\copy part from '/home/dbgen/tpch-dbgen/data/part.csv' WITH (FORMAT csv, DELIMITER '|');
\copy partsupp from '/home/dbgen/tpch-dbgen/data/partsupp.csv' WITH (FORMAT csv, DELIMITER '|');
\copy region from '/home/dbgen/tpch-dbgen/data/region.csv' WITH (FORMAT csv, DELIMITER '|');
\copy supplier from '/home/dbgen/tpch-dbgen/data/supplier.csv' WITH (FORMAT csv, DELIMITER '|');Ура! Теперь мы готовы к наполнению Data Vault.
Инициируем проект dbt
1. Склонируйте себе репо с проектом dbt dbtvault_greenplum_demo
git clone https://github.com/kzzzr/dbtvault_greenplum_demo.git2. Настройте подключение к СУБД Greenplum
dbt будет искать файл с описанием подключения (хост/порт/логин/пасс) в директории ~/.dbt/profiles.yml. Подробнее можно почитать в документации dbt – Configure your profile. По понятным причинам файл не версионируется в репозитории.
Пример содержимого файла profiles.yml:
config:
send_anonymous_usage_stats: False
use_colors: True
partial_parse: True
dbtvault_greenplum_demo:
outputs:
dev:
type: postgres
threads: 2
host: {yc-greenplum-host}
port: 5432
user: greenplum
pass: {yc-greenplum-pass}
dbname: postgres
schema: public
target: dev3. Установите dbt версии 0.19.0
Проект был подготовлен и протестирован именно на этой версии. dbt – это не что иное как python-приложение. Есть множество вариантов установки dbt. Но самый простой вариант – использовать готовый Pipfile в репозитории:
pipenv install
pipenv shellПроверьте корректность установки и подключение к СУБД:
dbt --version
dbt debug
4. Импортируем модуль dbtVault
Здесь начинается особая магия. Для кодогенерации Data Vault нам понадобится зависимость (модуль или package) dbtVault. Оригинальная версия модуля предназначена для работы только с СУБД Snowflake. Но после ряда нехитрых манипуляций модуль готов к работе с Greenplum (PostgreSQL): 47e0261.
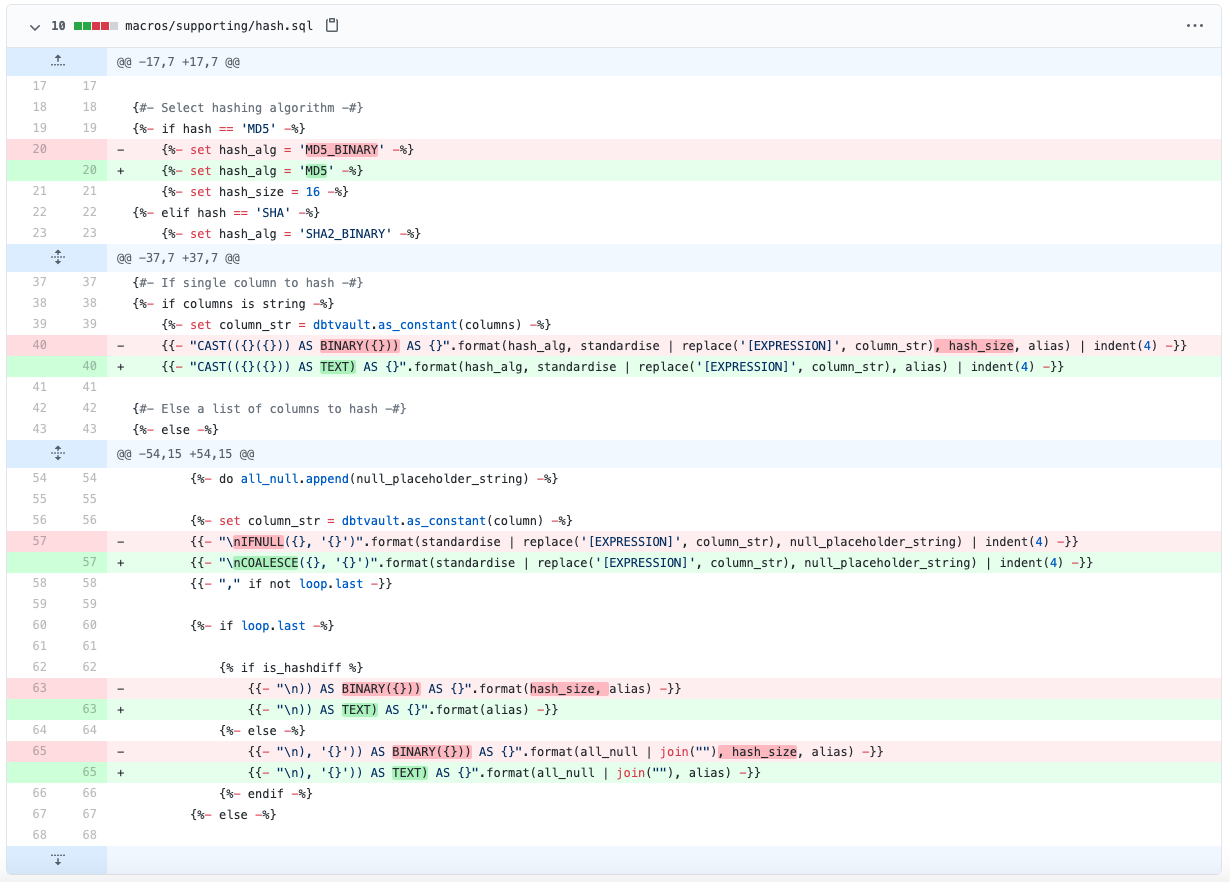
Устанавливаемые модули объявляются в файле packages.yml проекта:
packages:
# - package: Datavault-UK/dbtvault
# version: 0.7.3
- git: "https://github.com/kzzzr/dbtvault.git"
revision: master
warn-unpinned: falseУстановим модуль командой:
dbt depsCимулируем инкрементальную загрузку данных для TPC-H
Одно из ключевых преимуществ Data Vault в быстром инкрементальном наполнении детального слоя данных. Из статического датасета TPC-H мы попытаемся симулировать ежедневные инкрементальные пакеты данных, нарезая исходный набор данных по дням.
Всего в TPC-H имеем 4 атрибута с датами:
ORDERDATE (ORDERS)
SHIPDATE (LINEITEM)
RECEIPTDATE (LINEITEM)
COMMITDATE (LINEITEM)
В большинстве случаев факты идут в хрнологическом порядке: ORDERDATE (заказ), SHIPDATE (отправка), RECEIPTDATE (оплата), COMMITDATE (получение). Минималная дата ORDERDATE в датасете – 1992-01-01, максимальная – 1998-08-02. 2405 дней – вполне достаточно, чтобы имитировать инкрементальное историческое наполнение.
В итоге, из 8-ми таблиц исходного TPC-H мы формируем слой Raw Stage состоящий из 3-х таблиц:
raw_inventory – статический датасет складского учета
raw_orders – заказы, которые будем грузить подневно
raw_transactions – транзакции к заказам
dbt run -m tag:raw
Готовим слой Stage
А теперь давайте приступим к подготовке атрибутов, необходимых для наполнения Data Vault.
Хэш-суммы для суррогатных ключей и отслеживания изменений
Переимнование атрибутов
Константы и метаданные

Для подготовки этого слоя моделей мы воспользуемся макросом dbtvault.stage():
{%- set yaml_metadata -%}
source_model: 'raw_transactions'
derived_columns:
RECORD_SOURCE: '!RAW_TRANSACTIONS'
LOAD_DATE: (TRANSACTION_DATE + 1 * INTERVAL '1 day')
EFFECTIVE_FROM: 'TRANSACTION_DATE'
hashed_columns:
TRANSACTION_PK:
- 'CUSTOMER_ID'
- 'TRANSACTION_NUMBER'
CUSTOMER_PK: 'CUSTOMER_ID'
ORDER_PK: 'ORDER_ID'
{%- endset -%}
{% set metadata_dict = fromyaml(yaml_metadata) %}
{% set source_model = metadata_dict['source_model'] %}
{% set derived_columns = metadata_dict['derived_columns'] %}
{% set hashed_columns = metadata_dict['hashed_columns'] %}
{{ dbtvault.stage(include_source_columns=true,
source_model=source_model,
derived_columns=derived_columns,
hashed_columns=hashed_columns,
ranked_columns=none) }}В рамках самого кода модели мы задаем метаданные и передаем в качестве аргументов в макрос:
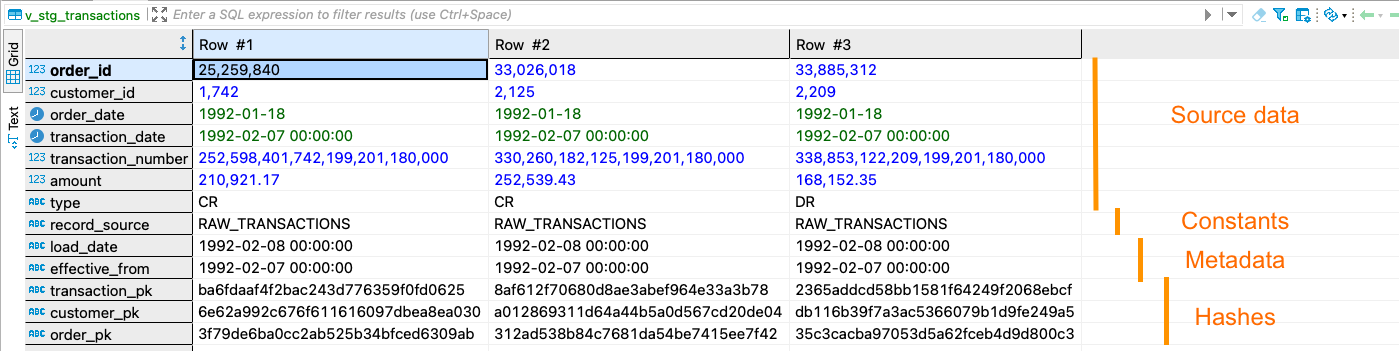
Таблица с исходными данными:
source_modelРасчетные колонки:
RECORD_SOURCE,LOAD_DATE,EFFECTIVE_FROMКолонки с хэш-суммой:
TRANSACTION_PK,CUSTOMER_PK,ORDER_PK
С кодом самого макроса stage.sql можно ознакомиться в репозитории dbtVault или в папке ./dbt_modules/dbtvault/macros/ нашего dbt-проекта, как и со всеми остальными макросами, которые помогают строить Data Vault. Это и есть те самые шаблоны для кодогенерации.
В результате, к исходным данным добавляется ряд новых и необходимых атрибутов:
Наполняем Raw Data Vault день за днём
Каждая модель типа hub, link, satellite собирается соответствующим макросом. Пример:
{%- set source_model = "v_stg_orders" -%}
{%- set src_pk = "CUSTOMER_PK" -%}
{%- set src_nk = "CUSTOMERKEY" -%}
{%- set src_ldts = "LOAD_DATE" -%}
{%- set src_source = "RECORD_SOURCE" -%}
{{ dbtvault.hub(src_pk=src_pk, src_nk=src_nk, src_ldts=src_ldts,
src_source=src_source, source_model=source_model) }}
Мы готовы к наполнению нашего детального слоя Data Vault:
dbt run -m tag:raw_vault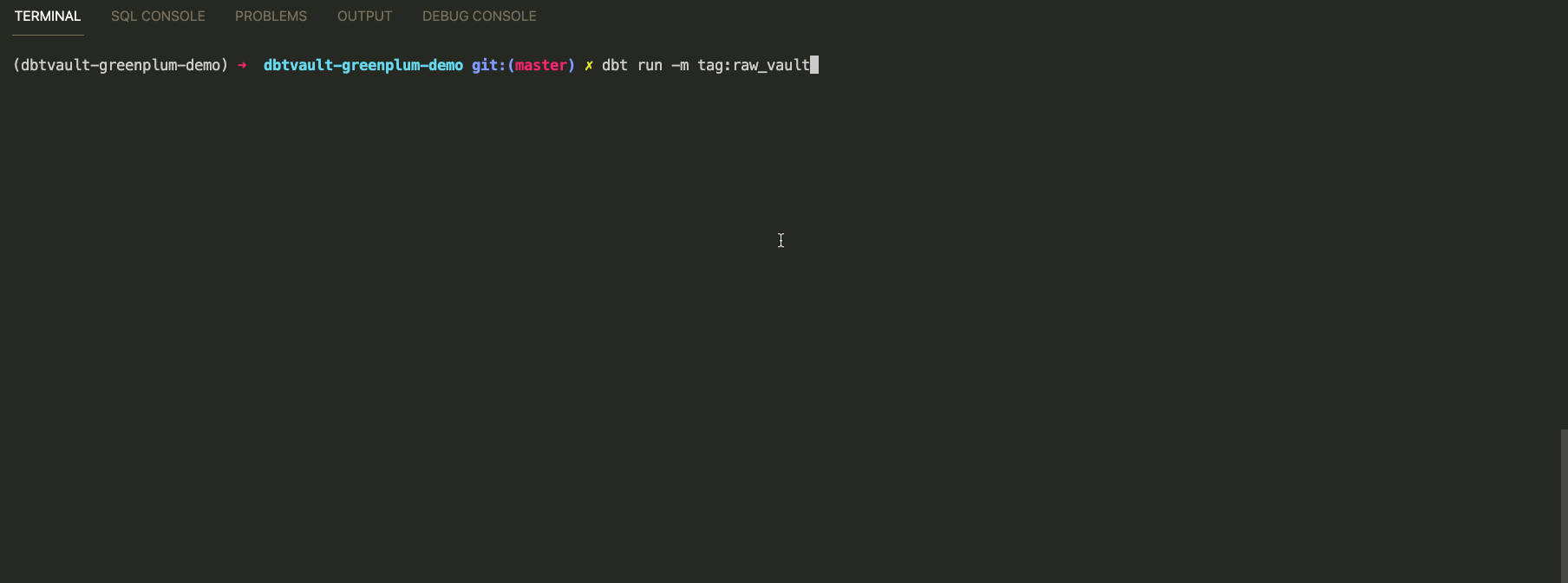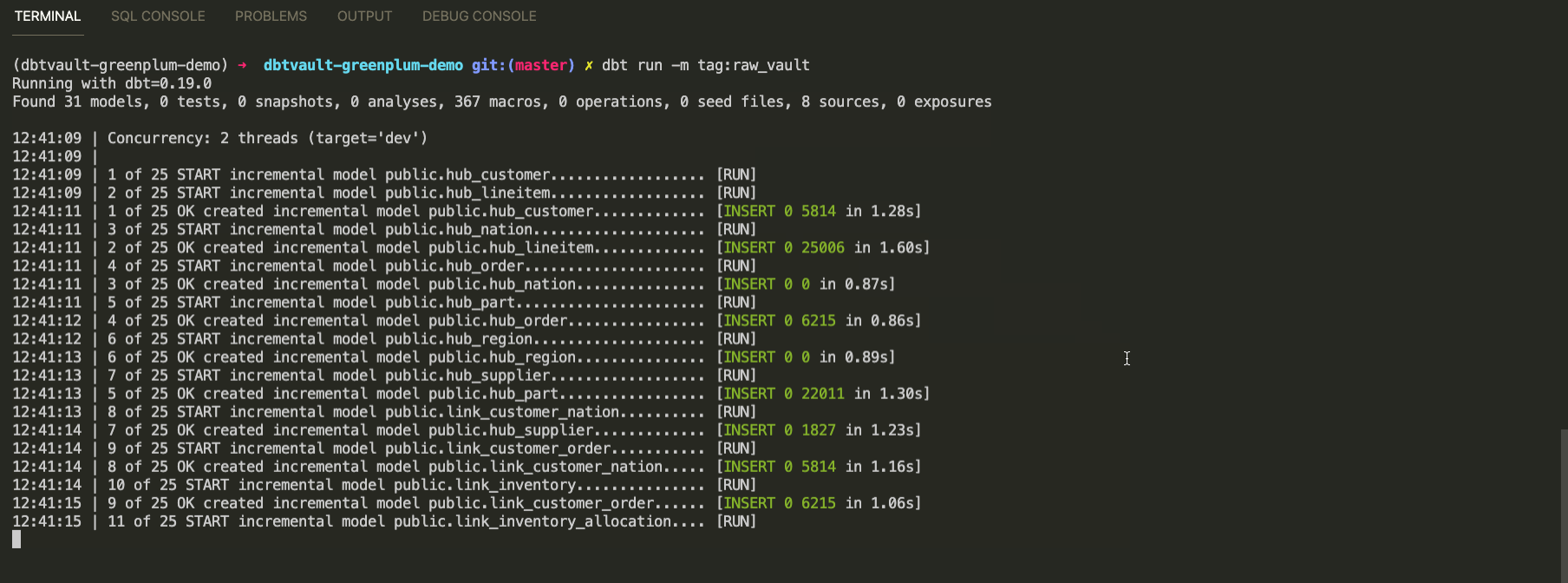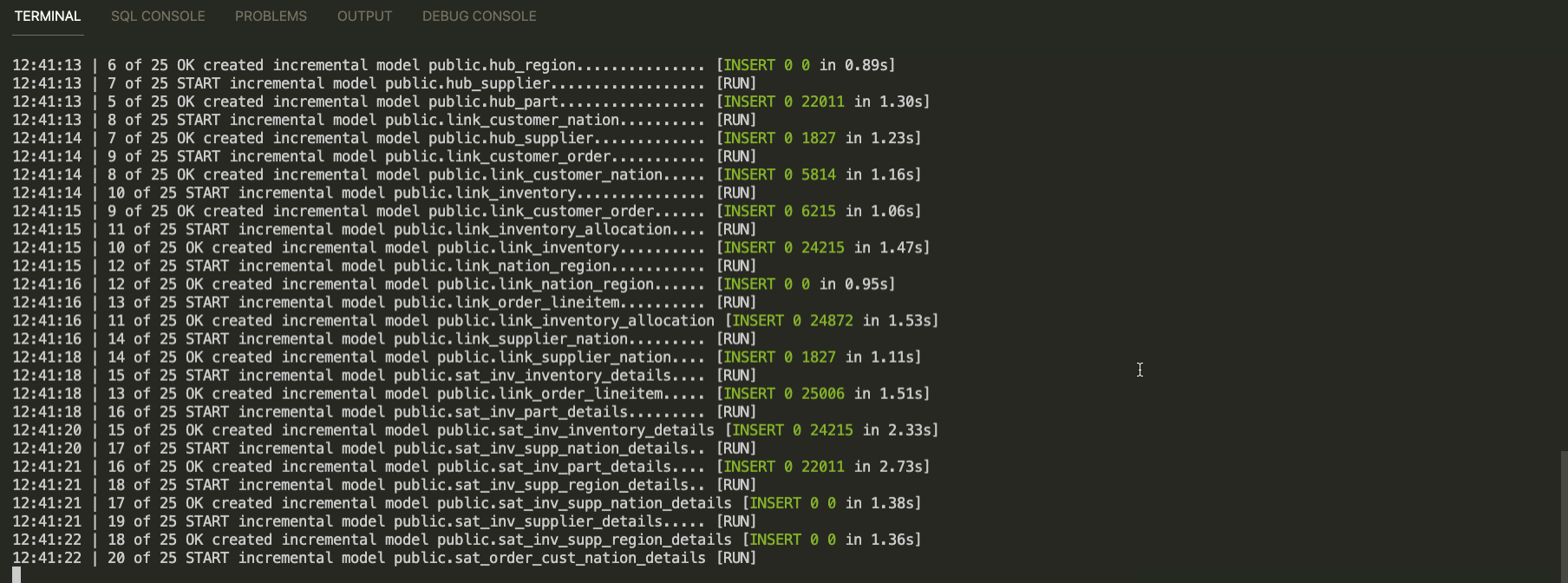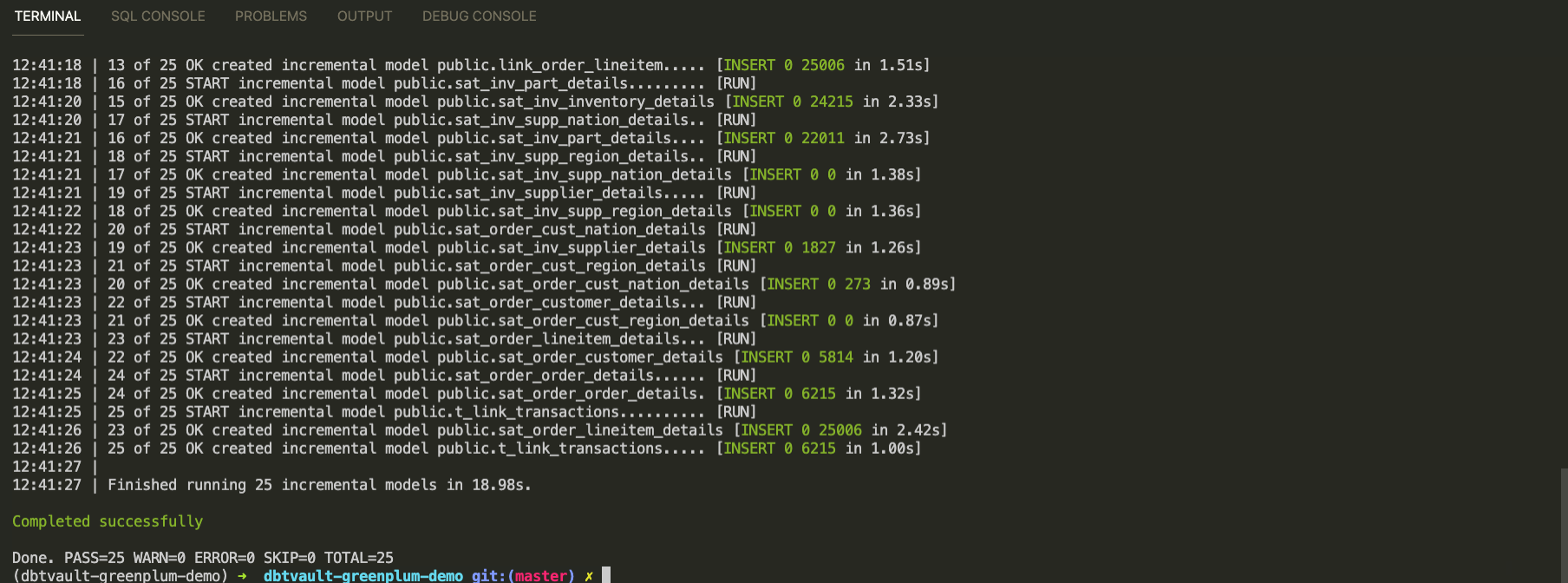
Итого:
Обработан пакет данных за одни сутки 1992-01-08
Сформировано 25 моделей за 19 секунд
Среди них: 7 hubs, 8 links, 11 satellites
Обратите внимание на то, что повторный запуск за те же самые сутки будет выполнен почти мгновенно и вставит 0 записей. Это происхоит потому, что таблицы Data Vault наполняются инкрементально и те записи, которые уже попали в детальный слой, вставлены повторно не будут!

Чтобы загрузить инкремент за следующие сутки, просто поменяйте значение переменной load_date в файле dbt_profiles.yml на следующий день и запустите загрузку повторно:
# dbt_profiles.yml
vars:
load_date: '1992-01-08' # increment by one day '1992-01-09'Дальнейшие шаги
1. Посмотрите историю адаптации исходного проекта для нашего демо на Greenplum – commit history:
eafed95 - configure dbt_project.yml for greenplum
aa25600 - configure package (adapted dbt_vault) for greenplum
bba7437 - configure data sources for greenplum
dfc5866 - configure raw layer for greenplum
a97a224 - adapt prepared staging layer for greenplum
А также github gist Data Vault 2.0 + Greenplum + dbtVault assignment.
2. Изучите документацию проекта, визуальный граф моделей (DAG) в автоматически сгенерированном веб-приложении:
dbt docs generate
dbt docs serve3. Разберитесь с макросами и кодогенерацией dbtVault
4. Ознакомьтесь с литературой по теме:
Building a Scalable Data Warehouse with Data Vault 2.0
Серия из 4-х статей от Kent Graziano (Snowflake)
Pentaho® Kettle Solutions: Chapter 19. Data Vault Management
5. Приходите на live сессии и вебинары
Я и мои коллеги стремимся делиться своим лучшим опытом и знаниями в рамках занятий на курсах Data Engineer и Analytics Engineer:
Практики от лидеров отрасли в рамках живого общения
Ваучер Яндекс.Облака на все эксперименты и задания
3 вебинара в программе только по теме Data Vault
Движуха в Slack и сообщество
Спасибо за внимание!




