
Человеческая жизнь слишком коротка, чтобы тратить ее на интеграцию и документацию. С помощью контрактов и кодогенераторов можно сократить рутинные операции и переписывание кода, обеспечить недосягаемое иными способами покрытие и достигнуть невыразимой чёткости бытия тестировщиков, разработчиков и систем.
Я занимаюсь автоматизацией тестирования в Яндексе с 2013 года. Из них более четырёх лет автоматизирую тестирование REST API-сервисов. На Heisenbug я рассказал об использовании OpenAPI-спецификации как основы для приёмочных тестов, а также о том, как легко поддерживать автотесты на огромное количество REST API-сервисов и добавлять автотесты на новые проекты.

Под катом — видеозапись и расшифровка моего доклада. Примеры из доклада есть на GitHub.
Как всё устроено
Яндекс.Вертикали — это три больших сервиса: Яндекс.Недвижимость, Яндекс.Работа и Auto.ru. Они имеют микросервисную архитектуру. Большинство бэкендов — это REST API-сервисы с разной кодовой базой, которые активно развиваются. К тому же у каждого REST API может быть несколько версий, которые также необходимо тестировать, чтобы старые клиенты не ломались при глобальных изменениях.
Команда
Наша команда — это четыре-пять человек. Это люди, которые занимаются инструментами для автоматизации, инфраструктурой, пишут и встраивают автотесты в процесс разработки. Я занимаюсь также мобильным направлением: инфраструктурой для автоматизации тестирования под iOS и Android. В автотестах на клиенты мы активно используем моки, поэтому мы не можем позволить себе тестировать наш REST API через клиент.
Итого:
- Несколько десятков бэкендов с разной кодовой базой, которые активно развиваются.
- Маленькая команда автоматизации, состоящая всего лишь из четырёх-пяти человек.
- Активное использование моков в тестировании.
С каким опытом мы подошли к нашей задаче
Три года назад картина у нас была следующая. У нас были автоматизаторы тестирования, которые имели достаточно стандартный подход и писали автотесты на Apache HTTP-клиенте. У нас были ручные тестировщики, которые не могли писать достаточно сложный код, поэтому использовали инструменты в виде Postman и писали автотесты, используя JavaScript. И у нас были разработчики, которые писали в основном юнит-тесты, интеграционные тесты. А некоторые вообще не понимали, зачем нужны автотесты, так как считали, что ничего не сломается.
Получалось, что все члены команды имели разные подходы к автоматизации тестирования. К тому же есть ещё одна важная проблема — наши REST API активно развиваются. Это означает, что при новых релизах в наших сервисах нам нужно править тестовый клиент. По факту у нас происходит гонка нашего тестового клиента и REST API. Наши клиенты устаревают очень быстро. Скажем так, у нас есть несколько десятков REST API и несколько десятков тестовых клиентов, которые нужно поддерживать. И это адский труд, который отнимает огромное количество времени и вообще не имеет никакого отношения к автоматизации тестирования.
Таким образом, у нас было очень много автотестов сомнительного качества. Они были понятны только тем, кто их пишет, тестовые клиенты моментально устаревали, а поддерживать их было некому. И главное, разработка не участвовала в тестировании.
В связи с этим мы сформировали определённые требования к автотестам:
- Мы решили, что автотесты должны писать все члены команды. И ручные тестировщики, и автоматизаторы тестирования, и разработка. И понимать автотесты должны все члены команды.
- Автотесты должны легко встраиваться в новые проекты. Соответственно, нужна «фабрика» автотестов.
- Автотесты нужно как можно реже править, желательно только когда добавляется новая бизнес-логика.
Об эволюции автотестов на REST API
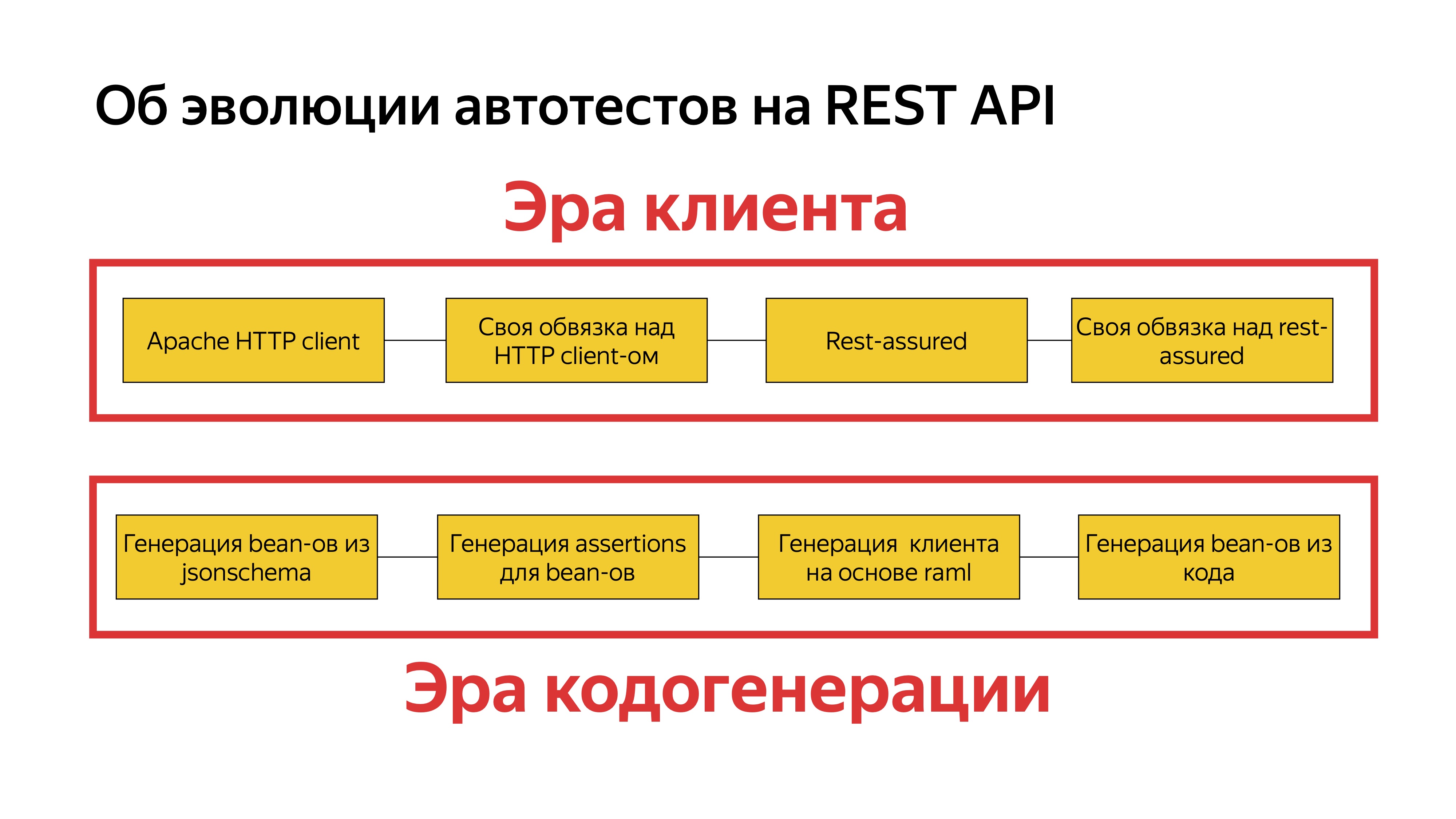
Необходимо понимать, с каким опытом мы пришли к этой задаче. Давайте поговорим об эволюции автотестов, которую мы прошли. Изначально мы писали автотесты на Apache HTTP client. Поняв, что дублируем много кода и он очень громоздкий, мы написали свою обвязку над HTTP client-ом. Это немного сокращало наши труды. Когда появились специализированные инструменты для автоматизации и появился REST Assured, мы начали его использовать. Потом мы осознали, что его тоже неудобно использовать, и написали свою обвязку над REST Assured. Всё это была эра клиента.
В какой-то момент мы поняли, что очень часто дублируем bean-ы для реквестов, для респонсов и решили их генерировать из JSON Schema. Это оказалось очень удобно: у нас переиспользуется код. Код упростился, и нам это очень понравилось. Стало ясно, что можно генерировать не только bean-ы, но и из них генерировать assertion-ы и получать типизированные assertion-ы для этих bean-ов.
Позже мы поняли, что можно генерировать не только bean-ны, assertion-ы, но ещё и тестовый клиент. Мы стали генерировать клиент на основе RAML-спецификации. Это тоже экономило много времени и делало клиент единообразным. У нас уменьшалось время внедрения людей в новый проект автотестов. Затем мы решили не генерировать bean-ы, а сразу брать их напрямую из кода и генерировать их в проекте автотестов. Мы назвали это эрой кодогенерации.
Ещё очень важный момент. У нас во всех проектах есть спецификации. В основном это спецификации двух версий — это OpenAPI-спецификации v1.0 и OpenAPI-спецификации v2.0. В какой-то момент пришёл менеджер и сказал, что мы больше не будем релизить новые REST API-сервисы без спецификаций.
Зачем мы вообще используем спецификацию? Всё благодаря этой замечательной странице Swagger UI.
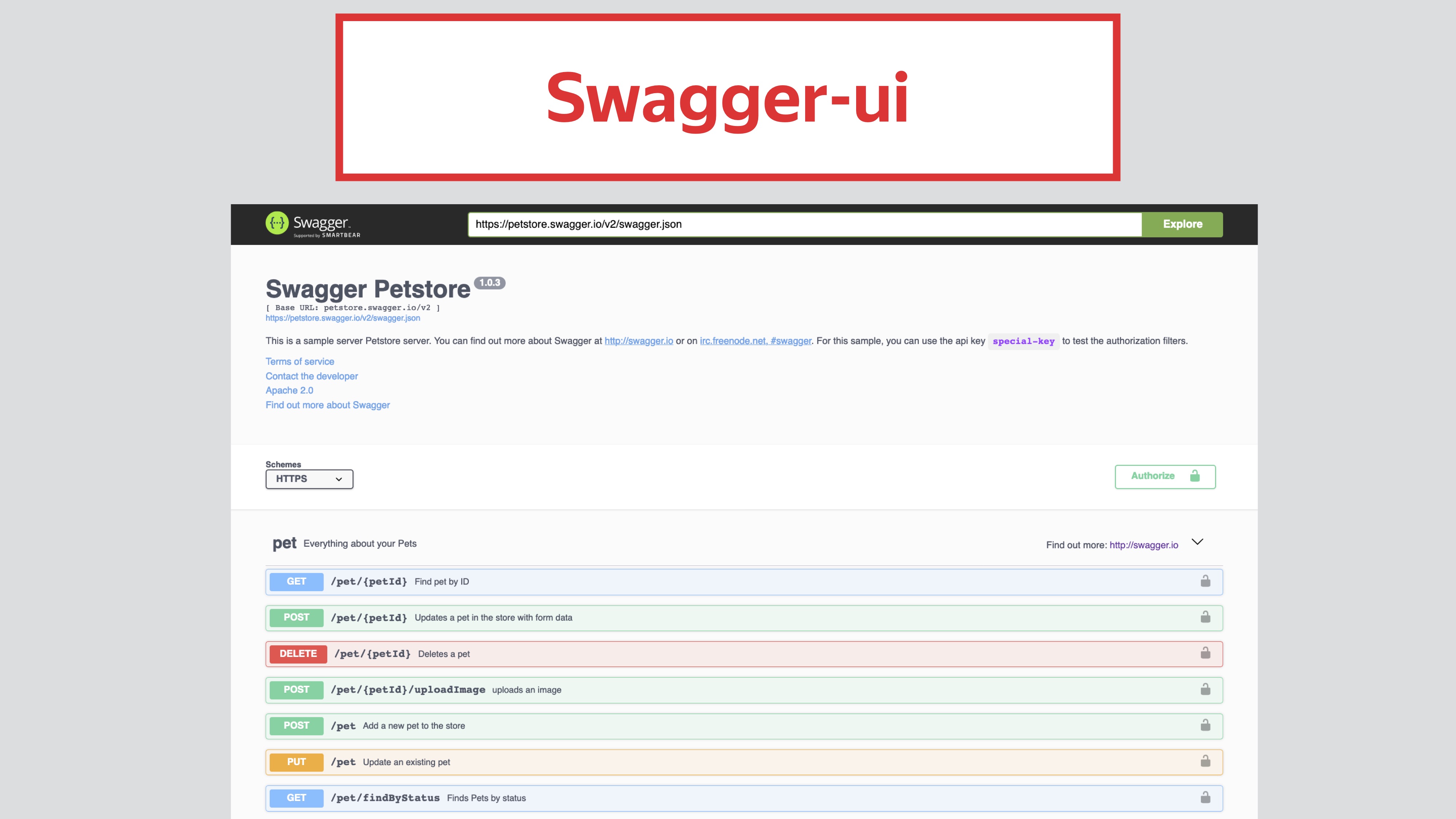
Из неё нам понятно, какой перед нами API, понятны все операции, понятно, как API используется и что вернётся. Это экономит огромное количество времени разработке для коммуникации с фронтендерами, разработчиками мобильных приложений, с ребятами, которые занимаются клиентами. Более того, через эту страницу можно делать запросы и получать ответы. Это оценили наши тестировщики, которые могут, не используя Curl, тестировать релиз. Исходя из этого мы решили, что будем строить наши автотесты на основе кодогенерации, и в качестве основы мы возьмём Swagger/OAS.
Мы решили строить такой процесс: у нас будет REST API, из него мы будем получать OpenAPI-спецификацию, а затем из OpenAPI-спецификации — тестовый клиент, с помощью которого мы и будем писать автотесты.
Что такое OpenAPI-спецификация
OpenAPI-спецификация — это opensource-проект, описывающий спецификацию и поддерживаемый линукс-сообществом (Linux Foundation Collaborative Project). Это популярный проект, у него 16000 звёздочек на GitHub.
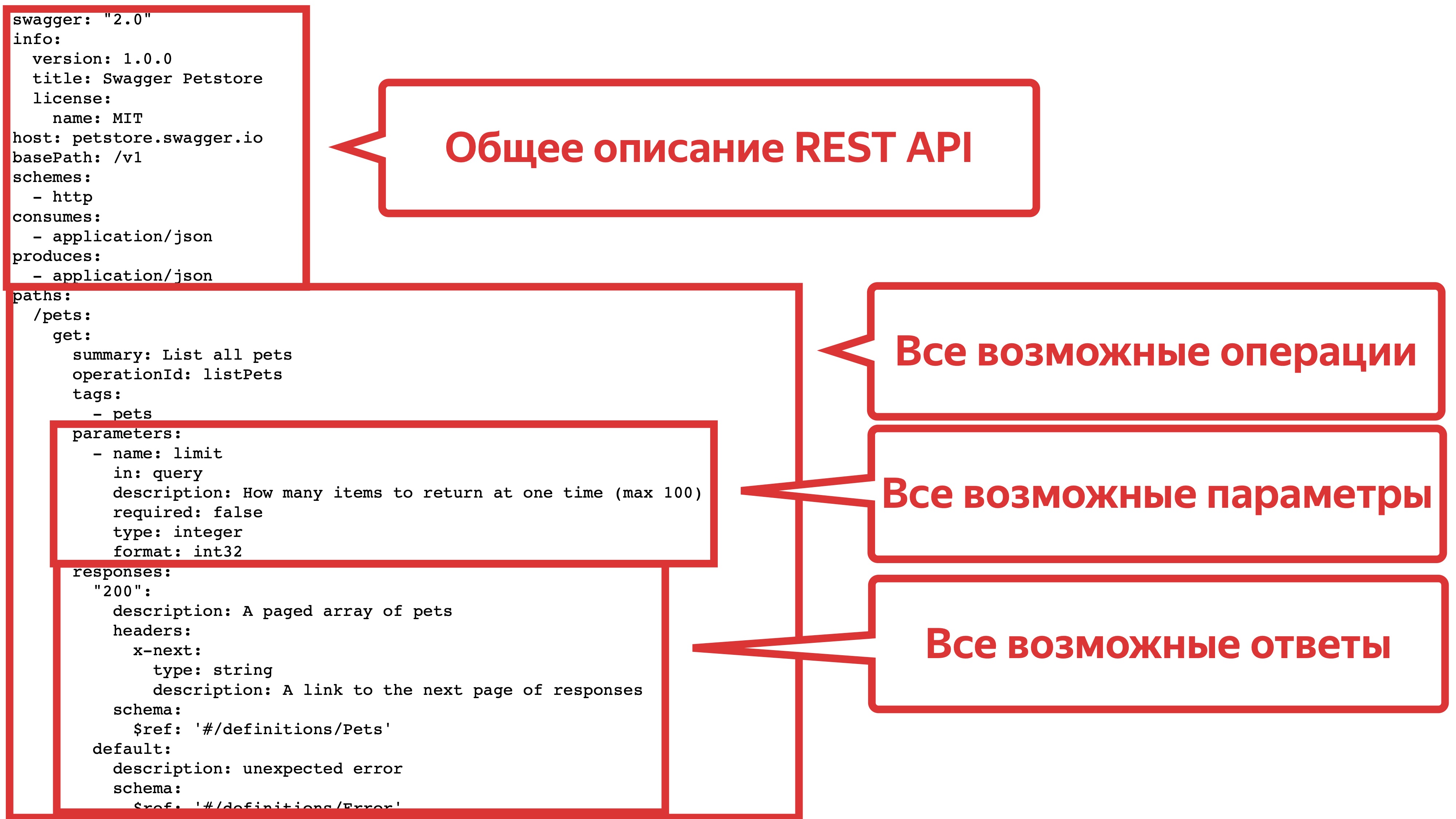
OpenAPI-спецификация определяет стандартизированное описание для REST API-сервисов, независимо от того, на каком языке программирования они написаны, удобна для использования как человеком, так и компьютерной программой, не требует доступа к коду. Спецификация может быть двух форматов. Это может быть JSON, которая понятна для машин и не очень понятна для человека и YAML-спецификация, которая более или менее читаема для человека.
Давайте подробнее разберём, что она собой представляет. У нас есть блок с общим описанием API. Мы там ставим версию нашего API, устанавливаем хосты, базовые пути, схемы и прочее. Также у нас есть блок с описанием всех возможных операций, в которых мы указываем параметры и все возможные ответы.
Наш Swagger UI и строится на основе этого файла спецификации — swagger.json.
Как получить OpenAPI-спецификацию
Самый простой способ — написать её в текстовом файлике. Это долго и не очень удобно.
Второй способ — использовать специализированные средства для написания спецификаций. Например, Swagger Editor. Вы в нем описываете вашу спецификацию, там есть удобный редактор, который сразу её валидирует. В правой части она у вас отображается в красивом виде.
Эти два инструмента полезны, когда у вас нет кода. Вы можете сначала написать спецификацию, потом на ее основе написать код.
Есть третий способ для получения спецификации: через Swagger-annotation в коде. Допустим, у вас есть какой-то API-ресурс, вы описываете для него Swagger-annotation. Annotation processor обработает аннотации вашего сервиса и вернёт спецификацию. Для каждого релиза вашего REST API получаем всегда актуальную OpenAPI-спецификацию. Если вы что-то удаляете, у вас автоматически это удаляется из OpenAPI-спецификации. И этот процесс постоянный.
Генерация клиента
Давайте разберёмся теперь с генерацией клиента. В opensource есть два больших, достаточно популярных проекта. Это Swagger Codegen, он на данный момент поддерживается компанией SmartBear. У него 11000 звёздочек на GitHub. И OpenAPI Generator, тоже opensource-проект, но он поддерживается комьюнити. В основном про него я и буду говорить.
По факту OpenAPI Generator является форком Swagger Codegen. Он отбренчевался от этого проекта в 2018 году.
Это произошло в связи с независимым развитием Swagger Codegen 3.X и Swagger Codegen 2.X. Из-за этого нарушилась обратная совместимость. Очень много клиентов исчезли и не были поддержаны. И ещё одна причина — это нестабильность релизного цикла. Релизы в Swagger Codegen были довольно редкие, тесты часто падали и комьюнити это не устраивало.
Давайте сгенерируем какой-нибудь клиент. Если у вас есть Docker, вы просто выполняете команду, указываете путь до спецификации, указываете язык, на котором хотите получить клиент, и папку для результата.

Есть второй способ: устанавливаете себе локальную консольную программу, выполняете команду и получаете клиент.
Вы получаете готовый проект. Там есть и клиент, и тест, даже скрипт, который пушит код на GitHub. По факту этот проект уже можно использовать. Но как только вы его начнёте использовать, то поймёте, что что-то идёт не так. Ниже реальный пример, где я использовал генерацию кода.

На самом деле мы пытаемся генерировать клиент из спецификации, которая на это не рассчитана. Данная спецификация использовалась только для Swagger UI, а мы хотим получить клиент. И мы можем получить что-то невразумительное. Вместо методов вашего тестового клиента у вас будут route1, route2, route16.
Проблемы, с которыми мы столкнулись при генерации
Также вы получите другие различные проблемы. Например, опечатки, потому что Swagger Annotation пишется руками разработчиков. Опечатки можно поправить — это не проблема. Могут быть различные проблемы с повторением моделей. Это достаточно легко решается, если к модели добавить имя пакета. И ещё одна проблема — неполнота спецификаций. Скоро вы обнаружите, что в вашем API есть внутренние операции, о которых вы не знали, но которые тоже надо тестировать. Самое приятное, что всё это легко исправляется.
Но есть тонкий момент — этот клиент и весь проект мы получаем один раз во время генерации. То есть проблема осталась: напомню, что при любом изменении REST API нам придётся снова поддерживать тестовые клиенты. Тогда мы решили, что будем генерировать клиент до запуска тестов и будем делать это с помощью плагина. OpenAPI Generator поддерживает множество плагинов. Например, это maven-plugin, gradle-plugin, sbt-plugin и bazel-plugin. В качестве примера я возьму maven-plugin.
Мы добавляем в наш pom.xml maven-plugin с определёнными настройками, указываем путь к нашей спецификации, папку для результата, язык генерации, dateLibrary, флаги «валидировать вашу спецификацию или нет во время генерации», «генерировать ли ваш клиент, если спецификация не менялась».
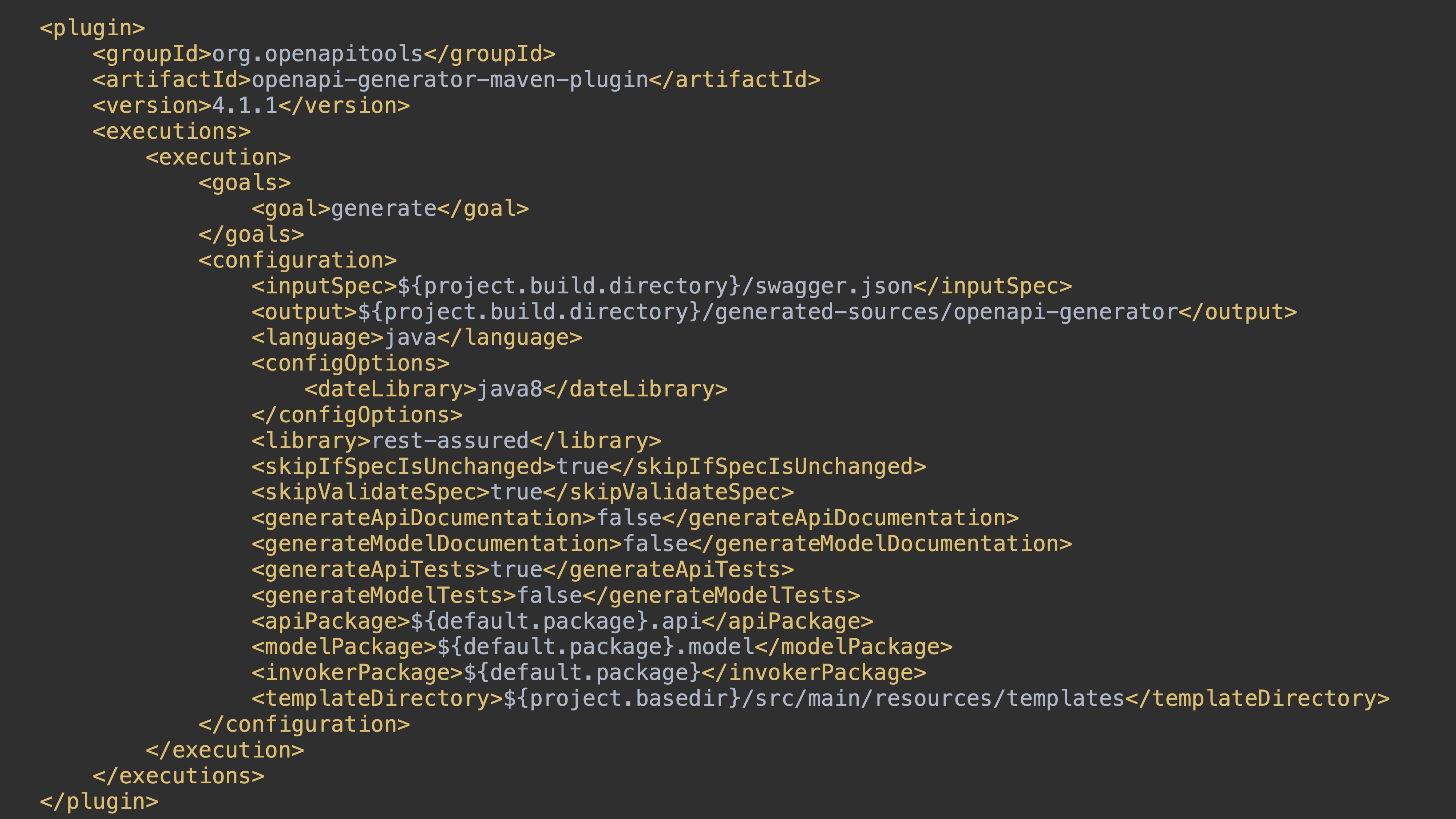
После компиляции у нас получается готовый клиент в target. Его можно использовать. По факту мы получили постоянный процесс: прямо из REST API с помощью Swagger-annotation мы получаем OpenAPI-спецификацию; из OpenAPI-спецификации мы получаем наш тестовый клиент.
Что делать, если у REST API несколько версий?
Например, есть версия v1.x, v2.x и vN.x. На самом деле всё то же самое. Мы в наш плагин добавляем второй . То есть у нас получается два , для версии v1 и для версии v2.

После компиляции у нас происходит генерация клиента для версии v1 и генерация клиента для версии v2.
Как добавляли клиент
Вернёмся в 2018 год. Когда мы только всё начинали, мы рассматривали множество клиентов в Swagger Codegen, написанных под разные языки, но ни один нас не устроил. Все эти клиенты очень жёстко привязаны к документации. В них мало точек расширения, и они не рассчитаны на то, что наша спецификация будет меняться. Мы решили, что напишем свой API-клиент, который будет обладать всеми необходимыми для нас возможностями.
В качестве библиотеки мы выбрали REST Assured. Она имеет fluent interface, эта библиотека предназначена для тестирования. В ней есть механизм Request specification и Response specification.
Сама генерация клиента в OpenAPI Generator основана на mustache template (Logic-less Mustache engine). Это круто, потому что генерация не зависит от языка программирования. Вы можете использовать mustache-шаблоны как для C#, так и для С++, так и для любого языка и получить клиент. Ещё один плюс — эти клиенты легко добавлять. Вам надо только добавить набор mustache-шаблонов, и у вас готовый клиент. И третья очень крутая фича — эти клиенты очень легко кастомизировать. Достаточно добавить свои шаблоны, которые просто будут использоваться при генерации.
Для того чтобы написать шаблоны, нам нужны переменные. В документации OpenAPI Generator описано, как их получить. Надо просто запустить нашу генерацию с флагом DebugOperations, и в итоге мы получим переменные для операций, которые будем использовать в шаблонах.
Аналогично можно получить те же переменные, но уже для моделей.
Итак, мы получили все переменные, написали все шаблоны и соответственно сделали pull request в Swagger Codegen. И этот pull request приняли. Теперь у нас есть собственный клиент.
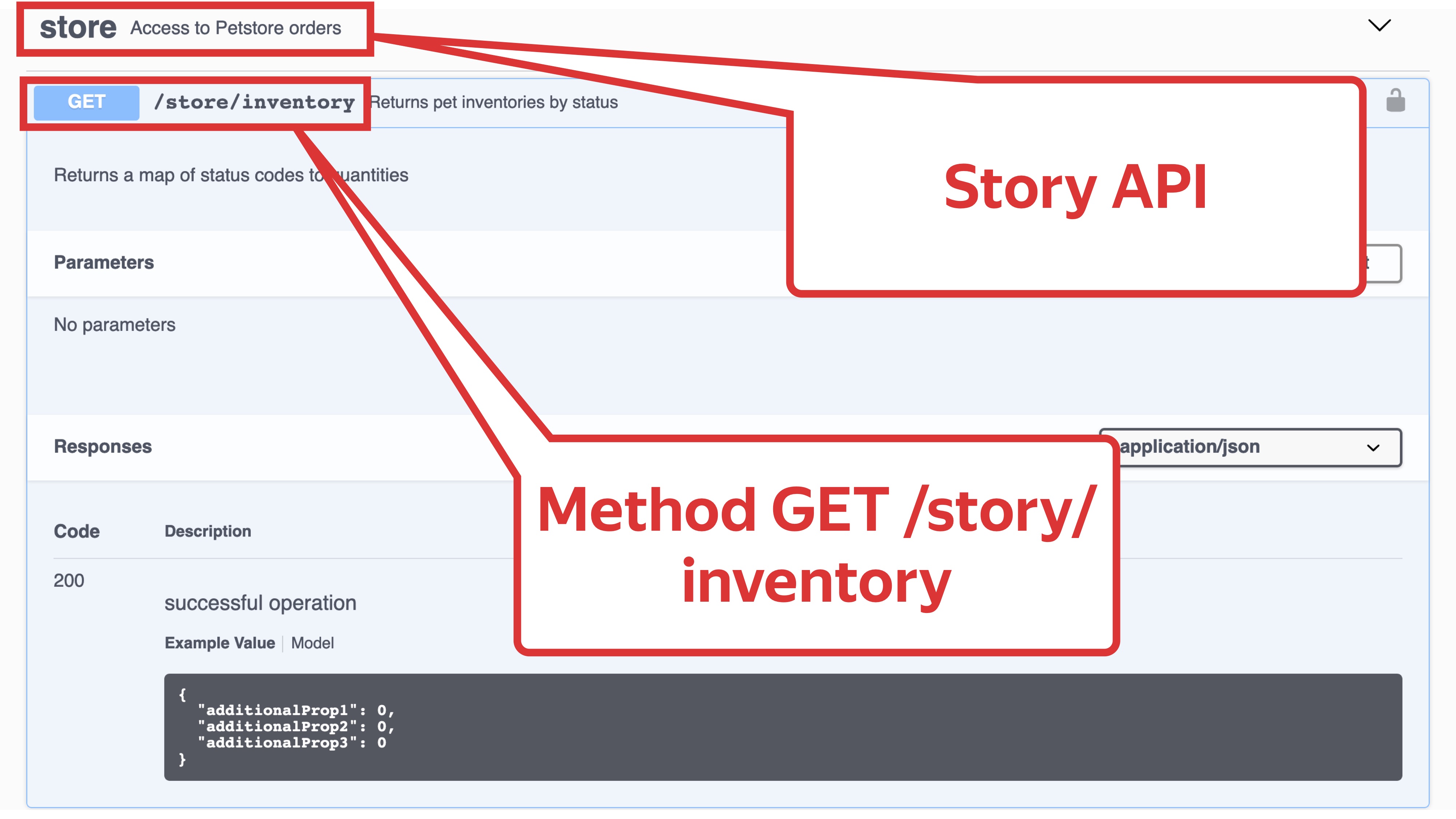
Давайте рассмотрим его подробнее. Возьмём в качестве примера простейшую операцию GET /store/Inventory из Story API и попробуем написать тест. Мы будем делать простейший запрос без параметров и валидировать ответ.
Retrofit
В качестве библиотеки для сравнения я возьму готовую библиотеку Retrofit, которая есть в OpenAPI Generator и Swagger Codegen. Так выглядит код теста, написанного на Retrofit.
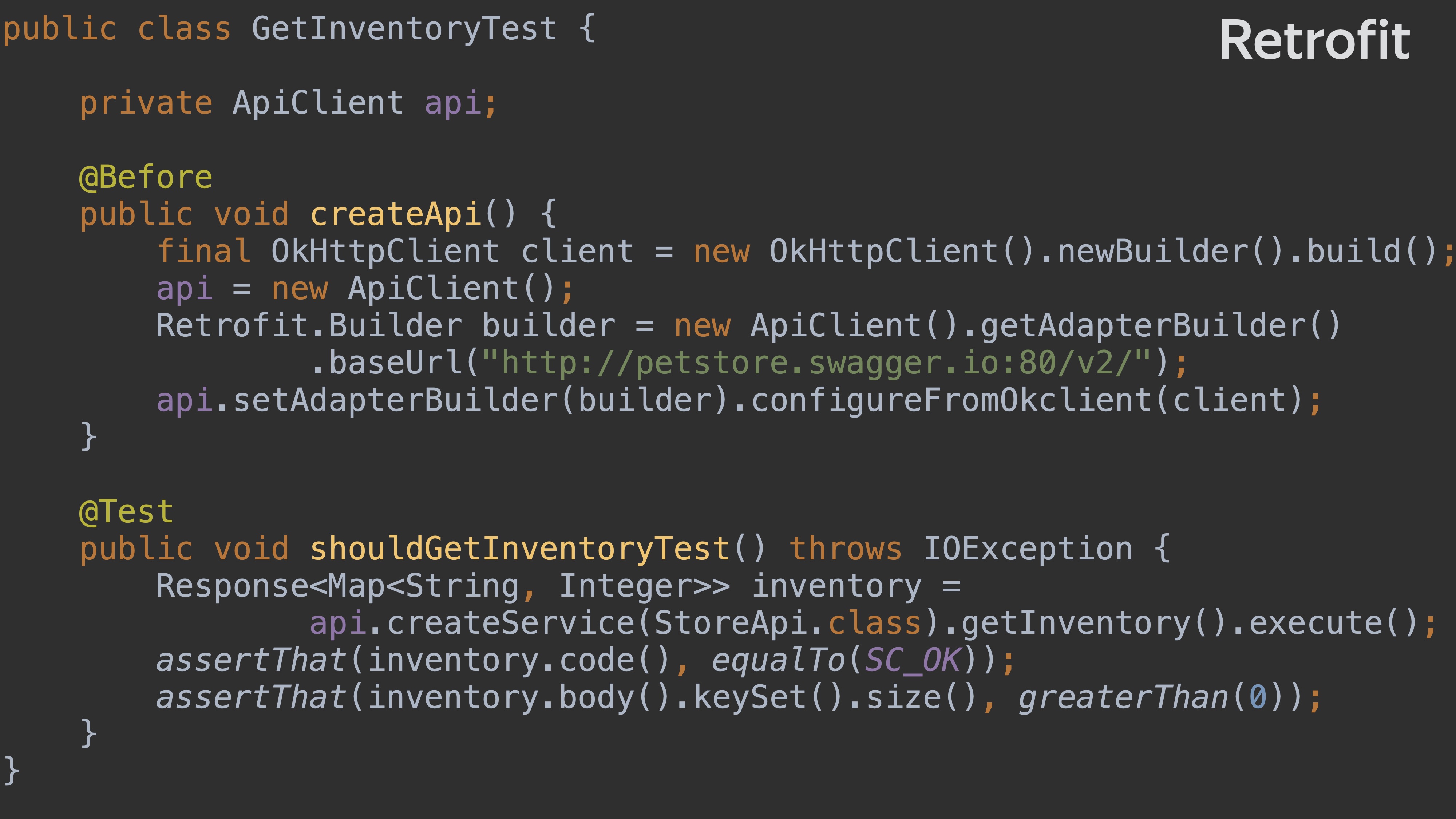
Здесь есть создание клиента: OkHttp сlient — из него билдится и настраивается Retrofit-клиент. Это простой тест: мы берём и проверяем, что конкретно у этого запроса статус OK и количество элементов больше нуля.
Давайте рассмотрим тест подробнее. Здесь api. — входная точка на наш клиент.
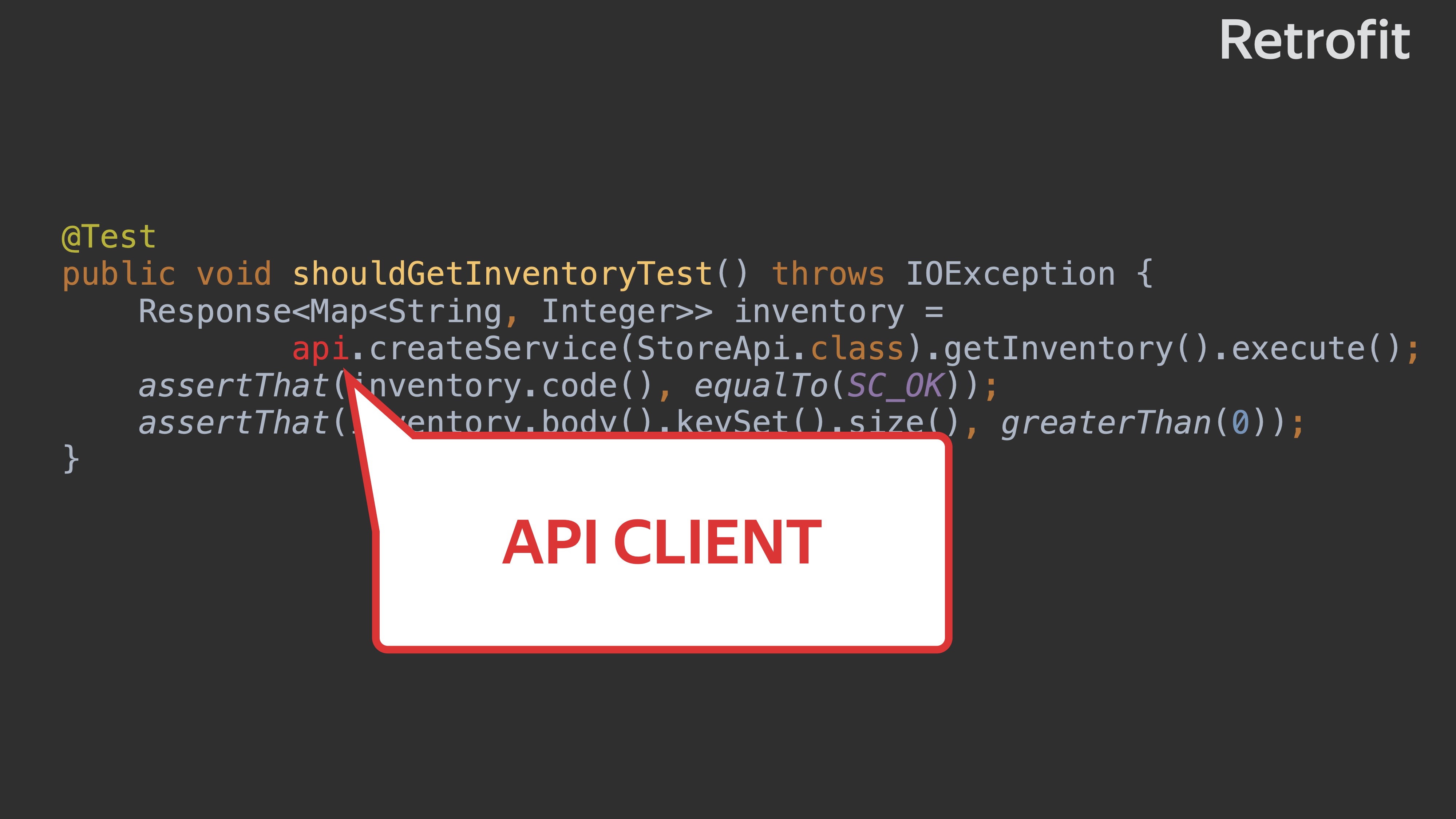
Здесь Story API, мы вызываем метод getInventory и его выполняем.

Здесь же валидация кода ответа. Мы просто проверяем, что код — 200.
REST Assured
Давайте напишем тот же тест, но уже на REST Assured. Вот у нас идёт создание клиента, мы его настраиваем, устанавливаем config, устанавливаем mapper, добавляем filter, добавляем BaseUri.

Это простейший тест, он чуть поменьше. Давайте его рассмотрим поподробнее. Что здесь происходит? Есть API-клиент, есть вызов Story API и метод getInventory.

Далее мы используем response specification — это особенность REST Assured. И валидируем сразу ответ, проверяем, что код — 200.

Два примера очень похожи. Возьмём пример посложнее. Возьмём ручку search.
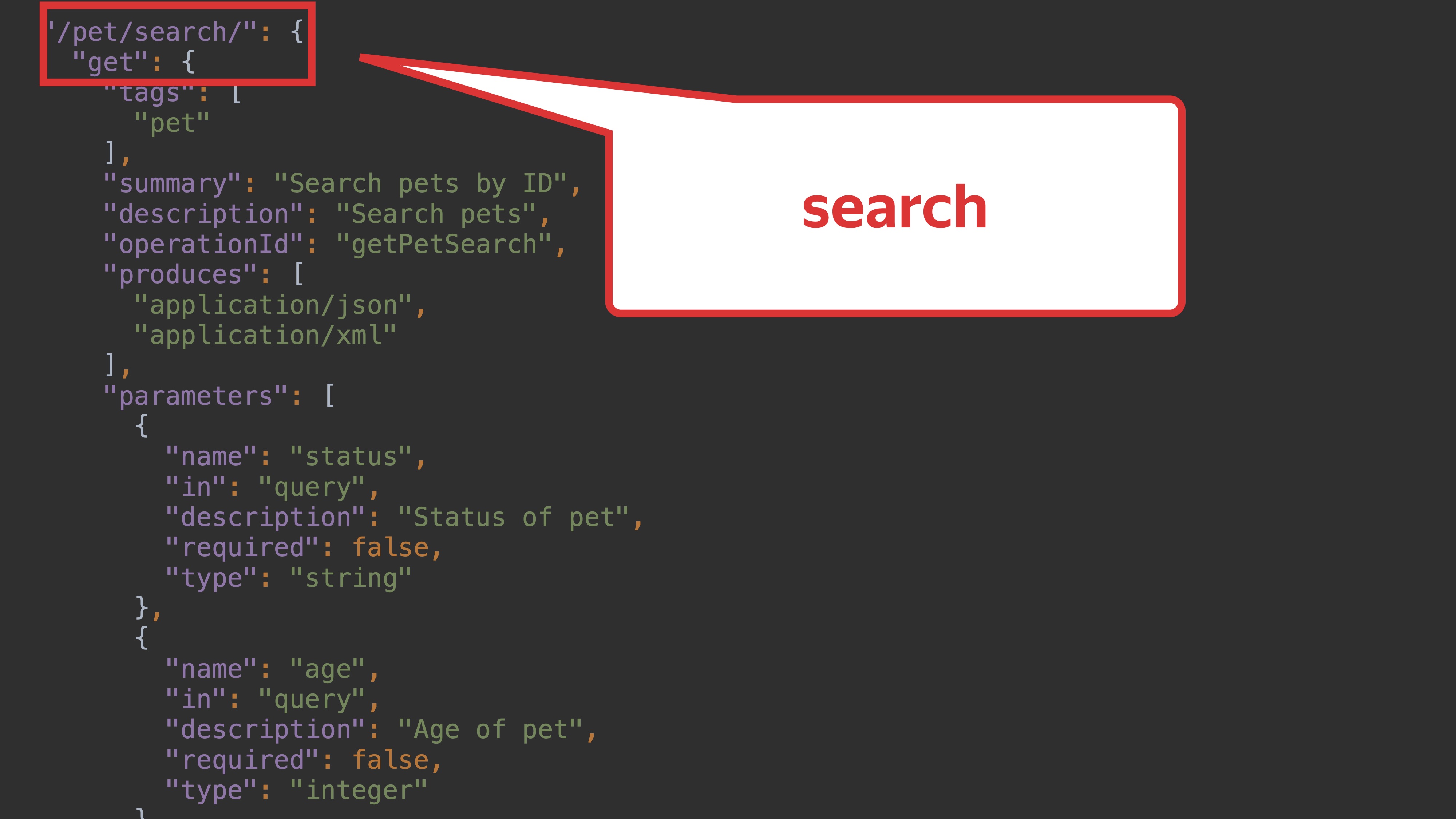
Пусть у неё будет множество параметров. Метод, который получится в Retrofit, будет выглядеть вот так.
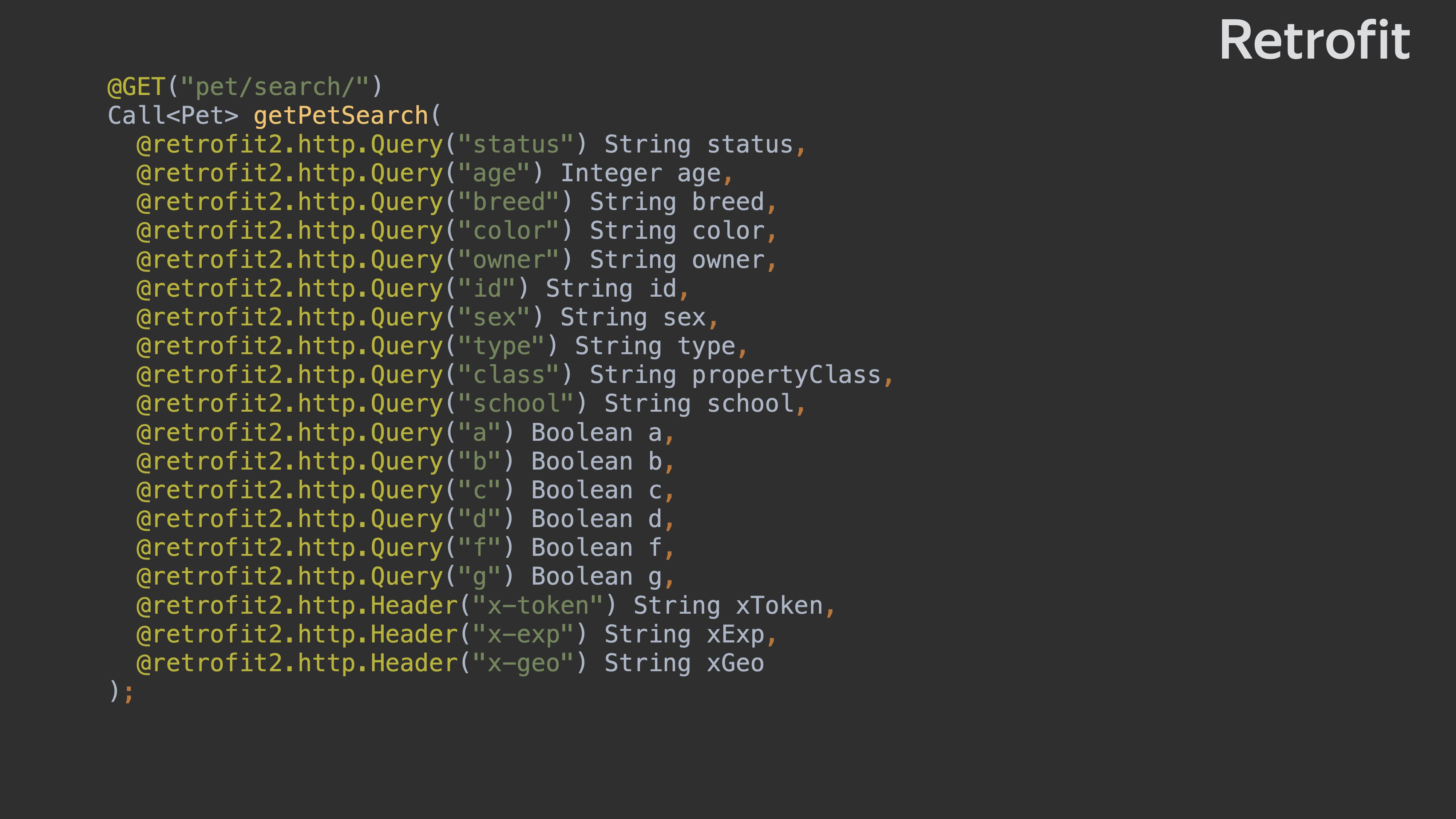
Когда вы начнёте писать тест, то получите тест с множеством null. Он не очень понятен.
В том же REST Assured мы использовали builder-паттерн, и у каждого вызова параметра собственный метод. И тест на REST Assured будет выглядеть вот так.

Добавим ещё один параметр к нашей ручке search. У нас есть спецификация, мы добавляем ещё один параметр, происходит генерация, и наш тест, написанный в Retrofit, ломается. Возникает ошибка компиляции, потому что мы добавили ещё один параметр, о котором мы ничего не знаем конкретно в этом методе.

В REST Assured ошибки не будет, потому что у нас builder-паттерн. Проблемы не возникает.
В стандартном Retrofit-клиенте параметры типизированы, для тестирования это не очень удобно. Нам бы хотелось, чтобы параметры были не типизированы, и мы могли вставить любые параметры, получить ошибку и её валидировать.
В REST Assured нетипизированные параметры. У Retrofit ответ всегда мапится на ответ из спецификации по умолчанию. В REST Assured ответ может мапиться на ответ из спецификации, а может не мапиться. Потому что, если мы тестируем невалидные кейсы, например, статус-коды не 200, то нам бы хотелось как-то кастомизировать наш ответ, чтобы получать что-то невалидное.
Retrofit не очень удобно кастомизировать. Например, если мне захочется добавить какой-то хедер, то в Retrofit это сделать не очень удобно. В REST Assured у нас есть механизм Request Specification, которым вы можете на любом этапе кастомизировать ваш запрос: как на этапе группы операций, так и на этапе самого запроса.
В данном случае я просто добавил к нашему запросу header — «x-real-ip».

Вообще, это полезно иметь для любого тестового клиента:
- Билдер для клиента, чтобы у нас тесты проще писались и не ломались.
- Нетипизированные параметры, чтобы писать тесты на кейсы с невалидными параметрами.
- Кастомизацию маппинга ответа.
- Кастомизацию запроса.
REST Assured сlient и Retrofit есть в OpenAPI Generator, их можно попробовать и использовать.
В Swagger Codegen с переходом на другой template-engine остался один Retrofit-клиент. REST Assured-клиента на данный момент нет, но есть открытое issue на его возвращение.
Тяжело ли поддерживать клиент
Главное, для чего создавался клиент, — чтобы добавление нового в спецификацию почти никогда не ломало компиляцию клиента. Ключевое слово — «почти». Понятно, что если мы добавим параметры, как я рассматривал раньше, всё будет хорошо. Но есть некоторые исключения.
Например, рассмотрим редкий случай. Допустим, у нас есть e-num с элементами c одинаковым префиксом. Есть enum, состоящий из следующего: PREFIX_SOLD, PREFIX_AVAIBLE, PREFIX_PENDING.
После генерации сам генератор вырезает этот префикс, и мы уже в тестах используем enum без префикса: SOLD, AVAILABLE, PENDING. Если мы в e-num добавляем значение RETURNED, то после генерации произойдёт следующее: PREFIX возвращается, и наши тесты, которые использовали этот enum без префикса, ломаются. Ломается компиляция. Это первая ситуация за два года, в которой я столкнулся с тем, что когда что-то добавляется, то ломается компиляция.
Удаление или изменение спецификации может сломать компиляцию клиента. Здесь более или менее всё понятно. Допустим, удаляем параметр status. Мы этот параметр используем в тесте, но его уже нет в клиенте. Получаем ошибку компиляции.

Ещё вариант — поиск с множеством параметров. Поменяем pet на search. Этого метода в API api.pet нет — и получаем ошибку компиляции. Что вполне ожидаемо.

И ещё: изменим в спецификации path. У нас был path /pet/search/, а мы его поменяем на /search/pet/. Что будет?

Поменяется только одна константа внутри нашей операции. И получится, что ошибок компиляции нет. Это неожиданно и ломает все представления об автотестах. Они должны ловить такие случаи, но сейчас получается, что всё работает. Чтобы отлавливать такие случаи, мы используем diff-спецификации, о которых чуть позже.
Несмотря на всё это, мы получили одну важную вещь: правим автотесты тогда, когда меняется бизнес-логика. Более того, у нас всегда актуальный клиент.
Про тесты и другие возможности
Здесь важно следующее: чем подробнее у нас спецификация, тем больше у нас возможностей.
Например, у наших спецификаций есть модели. Мы можем попробовать сгенерировать assertions на модели ответов с помощью плагина. Получается генерация в кубе. У вас есть в коде модели, эти модели переносятся в OpenAPI-спецификацию, из OpenAPI-спецификации у нас генерятся bean-ы и на эти bean-ы мы генерим assertions.
Например, мы возьмём в качестве библиотеки для генерации assertion такую популярную библиотеку как AssertJ. В AssertJ есть два плагина: есть плагин под Maven, есть плагин под Gradle. С помощью плагина получаем типизированный assertion, который можно использовать.
После настройки этого плагина мы просто указываем пакет, где у нас сгенерированные модели.

Вместо кода, где у нас не типизированные assertions, а стандартные hamcrest матчеры, мы получаем типизированные assertions — более удобные и понятные. Если у нас кроме модели ещё есть примеры значений параметров, то можем попробовать сгенерировать реальные шаблоны тестов и сами тесты. Нужно добавить парочку темплейтов, и получим тесты.
Нам пришла идея, почему бы не использовать свои темплейты. Тогда мы получим шаблоны тестов, которые можно использовать и писать. Значения в OpenAPI-спецификации второй версии хранятся в поле «x-exаmple». На это поле нет жёстких ограничений.
Какие тесты можно сгенерировать
Для того чтобы настроить генерацию тестов, нам надо прописать template_directory с нужными темплейтами и добавить шаблон для тестов.
Я буду рассматривать контрактные тесты и тесты на сравнение.
Давайте поговорим про контрактные тесты. Мы можем генерировать тесты на статус-коды, можем генерировать тесты на модели и тесты на параметры. Это почти всё, что у нас есть в спецификации по контракту. Здесь я привёл в пример mustache шаблон для генерации теста на статус-коды. Давайте чуть подробнее его рассмотрим. Мы проходим по всем респонсам, пишем бизнес-логику. Я ещё указал Allure-аннотации. Также делаем шаблон для имени теста. Мы устанавливаем в переменные нужные нам значения из спецификации и прокидываем их в вызов реквестов с тестового клиента. В конце добавлена валидация: проверка, что статус код — 200.
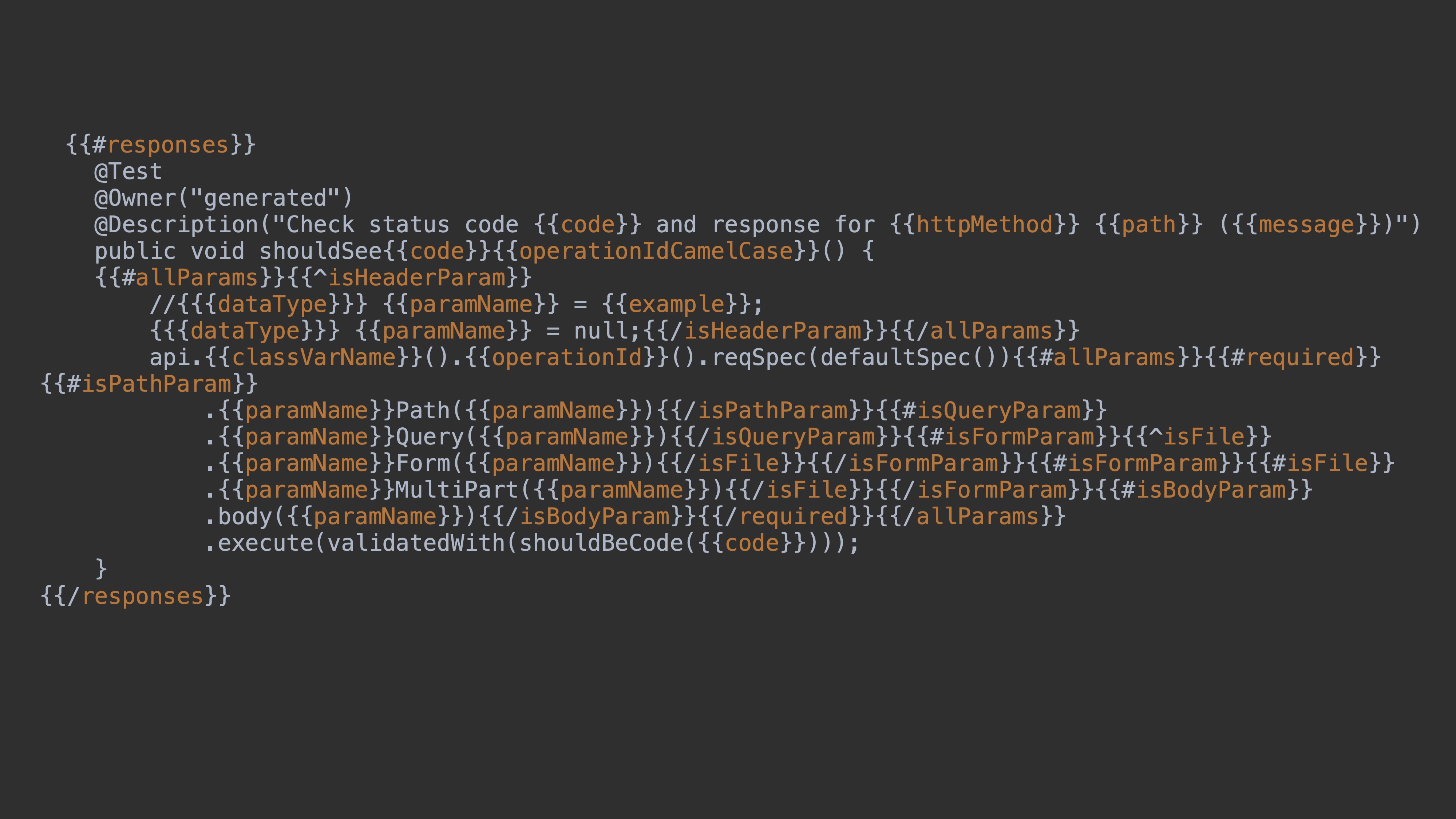
После генерации у нас в папке target возникают такие тесты. Это реальный тест «на 200», его можно запустить.
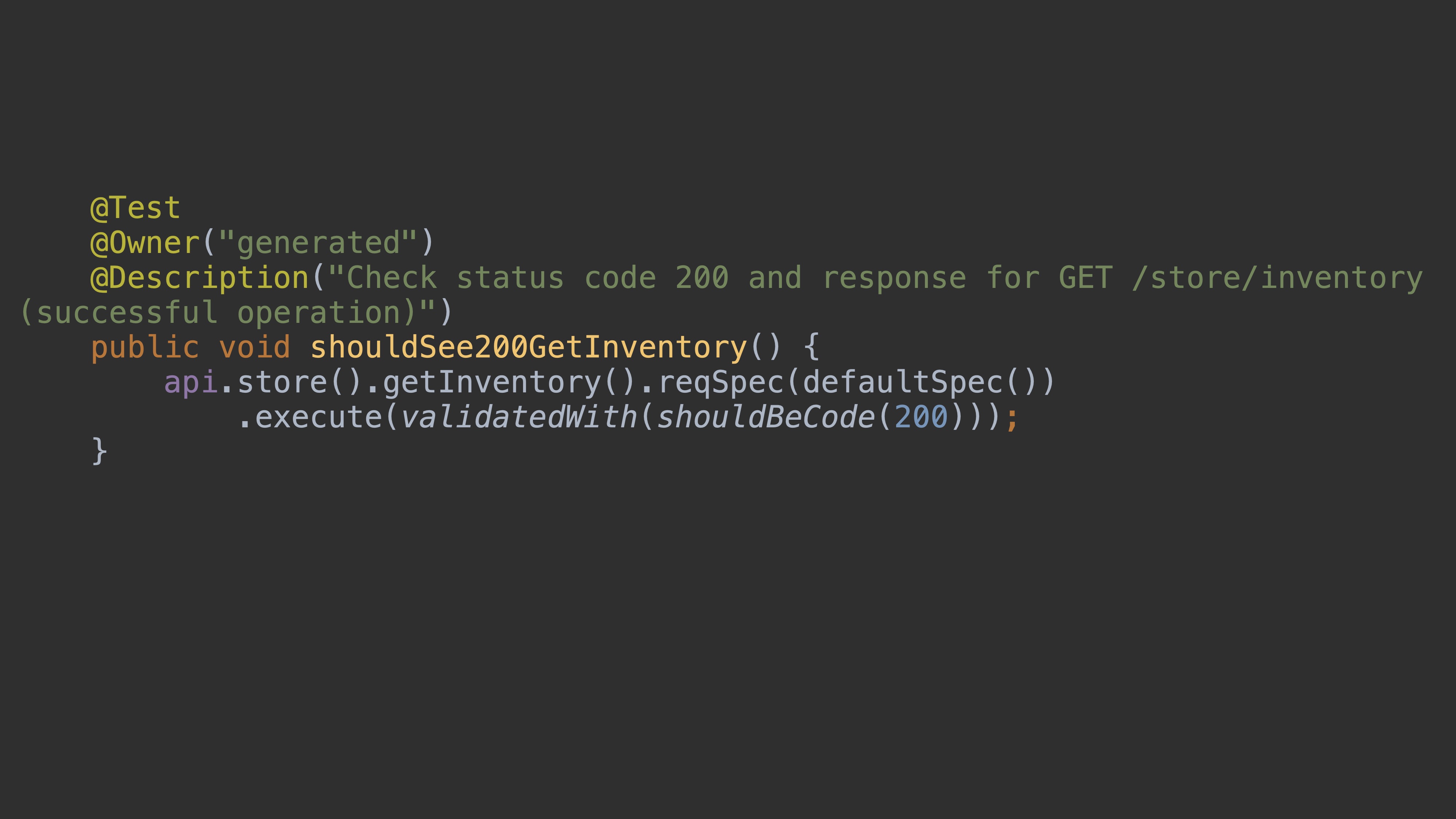
Код 404 будет выглядеть точно так же. Основная идея, что mustache-темплейты — logic-less, и тяжёлую логику нельзя таким образом сгенерировать. И потому это не совсем реальные тесты, а шаблоны тестов. Но дописав логики, вы получите вполне реальные тесты.
Аналогично можно сгенерировать тесты для параметров и моделей. Для параметров происходит то же самое. Вы просто проходите по всем параметрам и добавляете шаблоны тестов, чтобы для каждого параметра сгенерировались аналогичные тесты.
С моделями всё интересней. Мы можем проверять в тестах, что наш ответ после запроса соответствует определённой модели, которая описана в спецификации. Но в реальности это очень маленькое, узкое покрытие. Мы проверяем только модели и не проверяем значения. Если это, например, JSON, то мы проверяем только поля и что они соответствуют схеме. Но нам бы хотелось понимать, что ответ нашего запроса правильный.
Я обычно предпочитаю тесты на сравнение. Что это и как это работает? Допустим, у нас REST API, который мы тестируем. Рядом поднимаем тот же REST API, но со стабильной версией, о котором мы знаем, что он работает правильно. Делаем два запроса: запрос к REST API, который тестируем, и тот же запрос к стабильному REST API. Получаем два ответа. Первый ответ нам нужно протестировать, второй ответ мы считаем эталоном — expected response. Сравнивая два ответа, можем проанализировать, правильно всё работает или нет.
Давайте попробуем написать это в виде шаблонов. Для этого я привёл пример параметров для такого теста. У нас есть механизм в REST Assured Response и Request specification. Здесь параметром выступает Request specification. Мы устанавливаем в Request specification все возможные параметры со значениями, которые описаны у нас в спецификации.
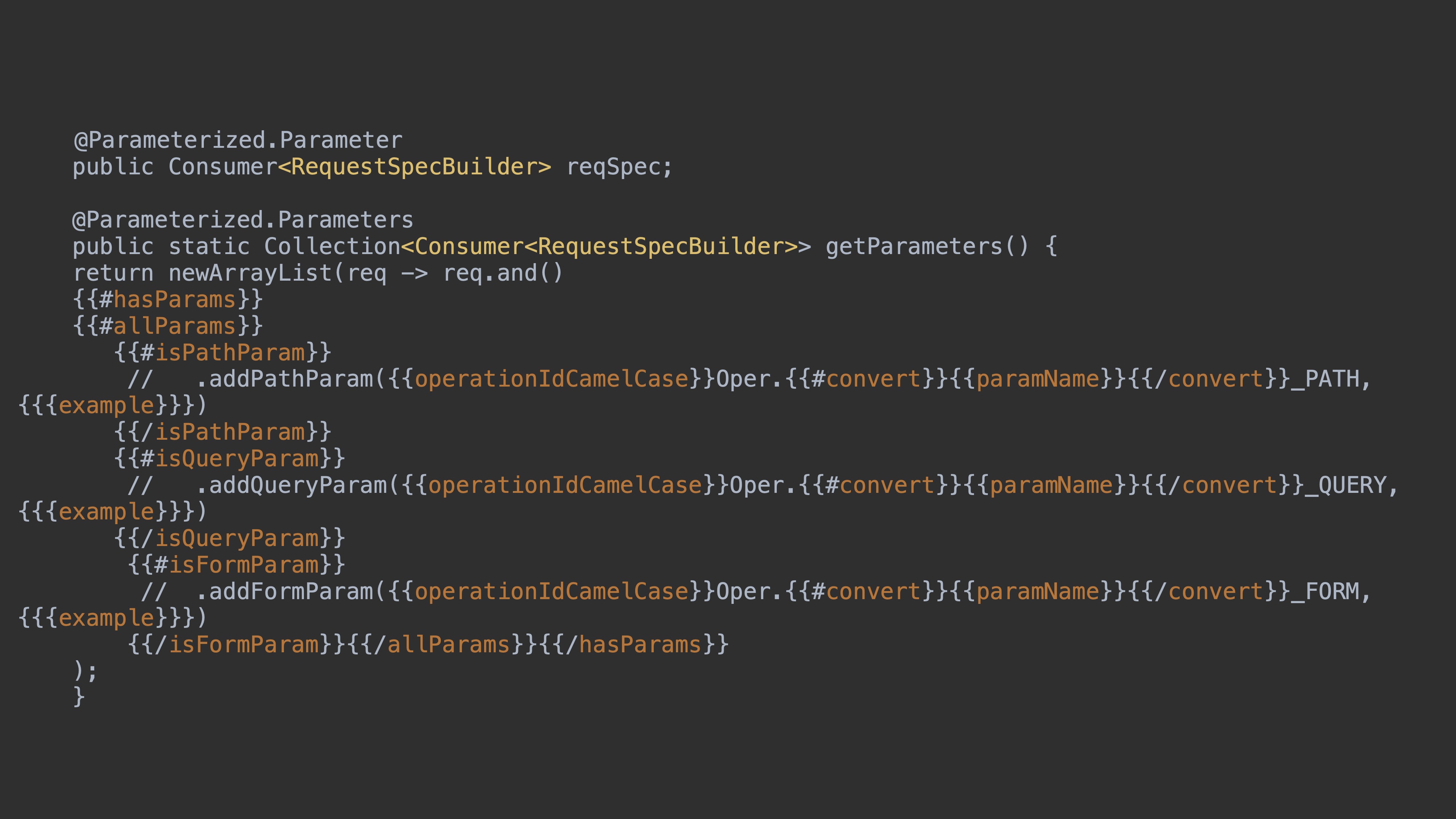
Здесь пример теста, который просто сравнивает эти два ответа. У нас есть функция, которую принимает API-клиент и возвращает ответ, который мы сравниваем через matcher jsonEquals.
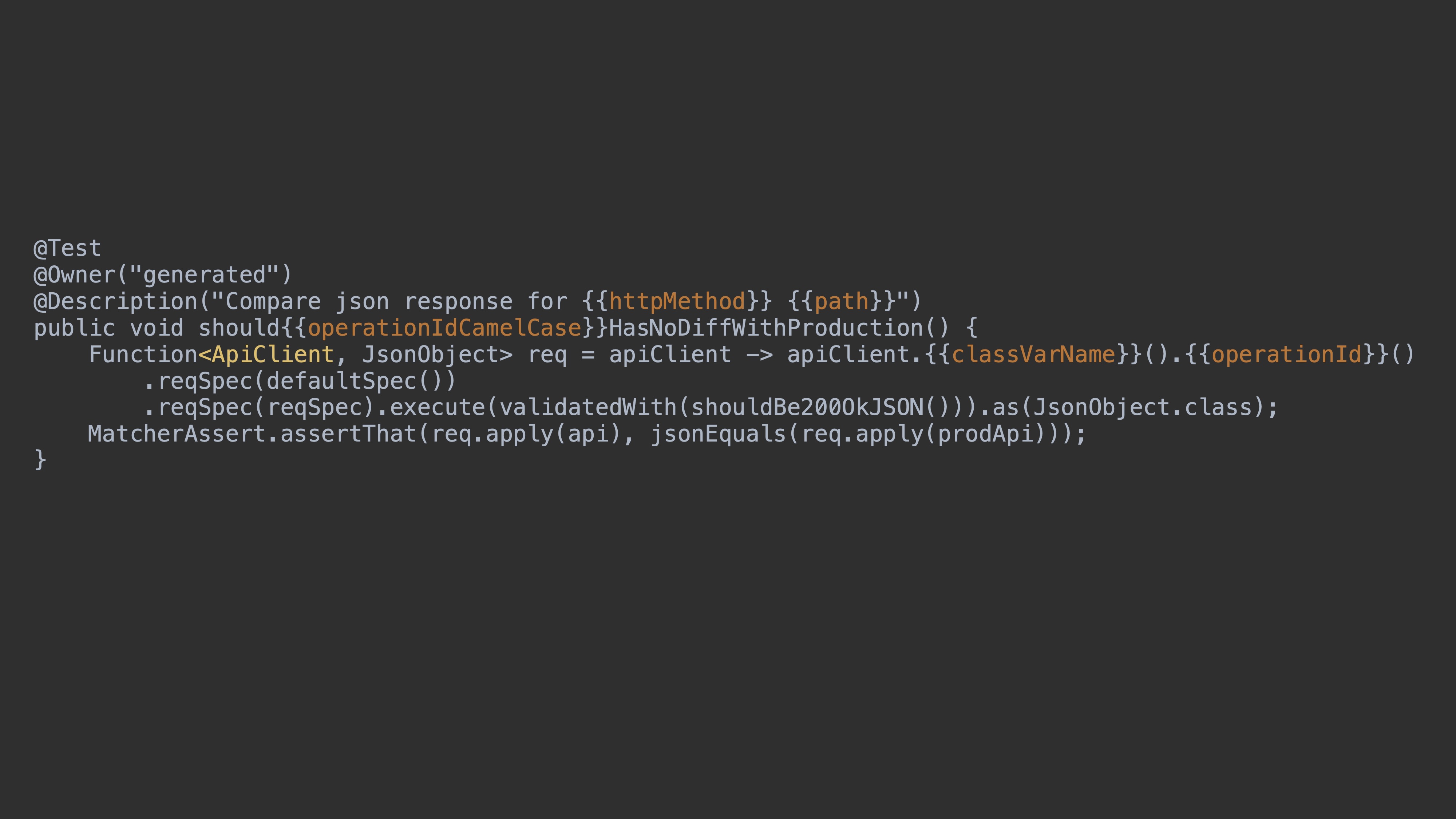
Тест после генерации будет выглядеть так. Здесь значения x-example такие же, как и в спецификации. И это получается вполне реальный тест. Осталось добавить реальных тестовых данных и можно его использовать.

Как в итоге мы стали писать тесты
У нас генерируются тестовые классы, мы можем поправить их в target, запустить и использовать. Через IDE нажимаем клавишу F6, и у нас возникает окошко.
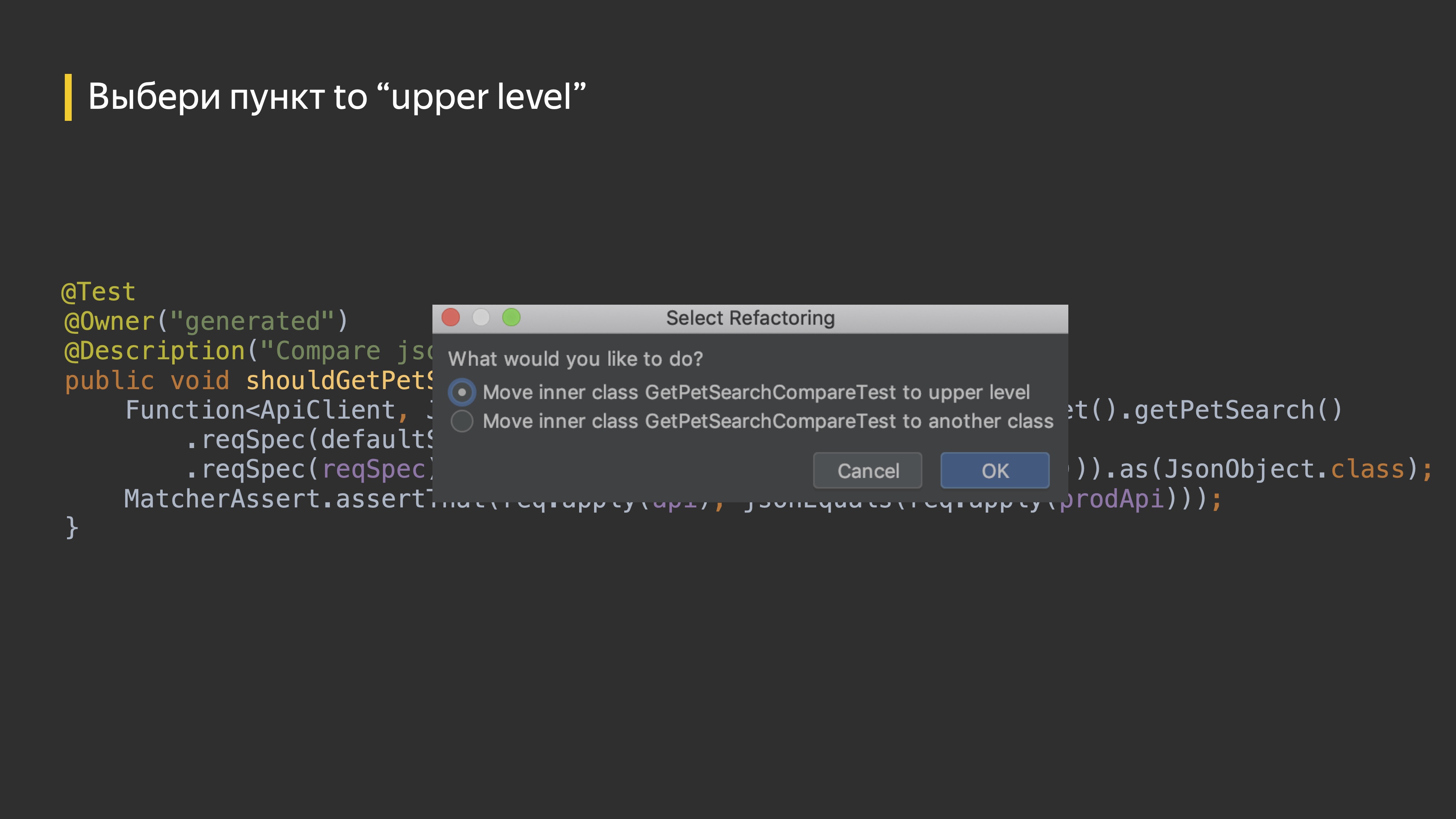
Мы выбираем первый пункт, указываем пакет, выбираем нужный модуль, если их несколько, и у нас получается тест. Работа выполнена.
Что мы получили:
- Простоту добавления новых тестовых классов. Мы можем легко перенести их в нужные нам тесты и использовать.
- Единые наименования тестовых методов и классов.
Для тестировщиков головная боль — именование тестовых методов и тестовых классов. У нас единое наименование на основе OpenAPI-спецификации. Из-за этого единообразия мы пришли к тому, что наши автотесты могут писать все. Их могут писать автоматизаторы тестирования и понимать ручные тестировщики и разработчики. Всю эту красоту мы вынесли в шаблон проекта с автотестами.
На GitHub создали project-template, где указали клиент, модуль с тестами, настроили генерацию. Если нам нужен проект автотестов на какой-то новый сервис, мы берём и наследуемся от этого шаблона. Чтобы проект заработал, нам достаточно поменять значения двух property, и получаем готовые тесты и сгенерированные клиенты.

По факту мы получили «фабрику» автотестов, используя которую стало легко добавлять автотесты на любой проект.
Об инструментах
Давайте поговорим об инструментах.
Бывает так, что проект автотестов не компилируется из-за изменений спецификации сервиса. Необходимо понимать, почему это происходит. Для этого нам надо получить разницу в документации, например, используя swagger-diff.
Swagger-diff — это opensource-проект, который помогает сравнить две спецификации. Я взял его в качестве примера, но есть и другие проекты.
В качестве сравнения берём старую и новую спецификацию: из стабильной версии REST API и тестовой. Далее сравнивая их, мы получаем diff в виде HTML.
Из HTML видим, что удалили параметры search, status и добавили header x-geo.
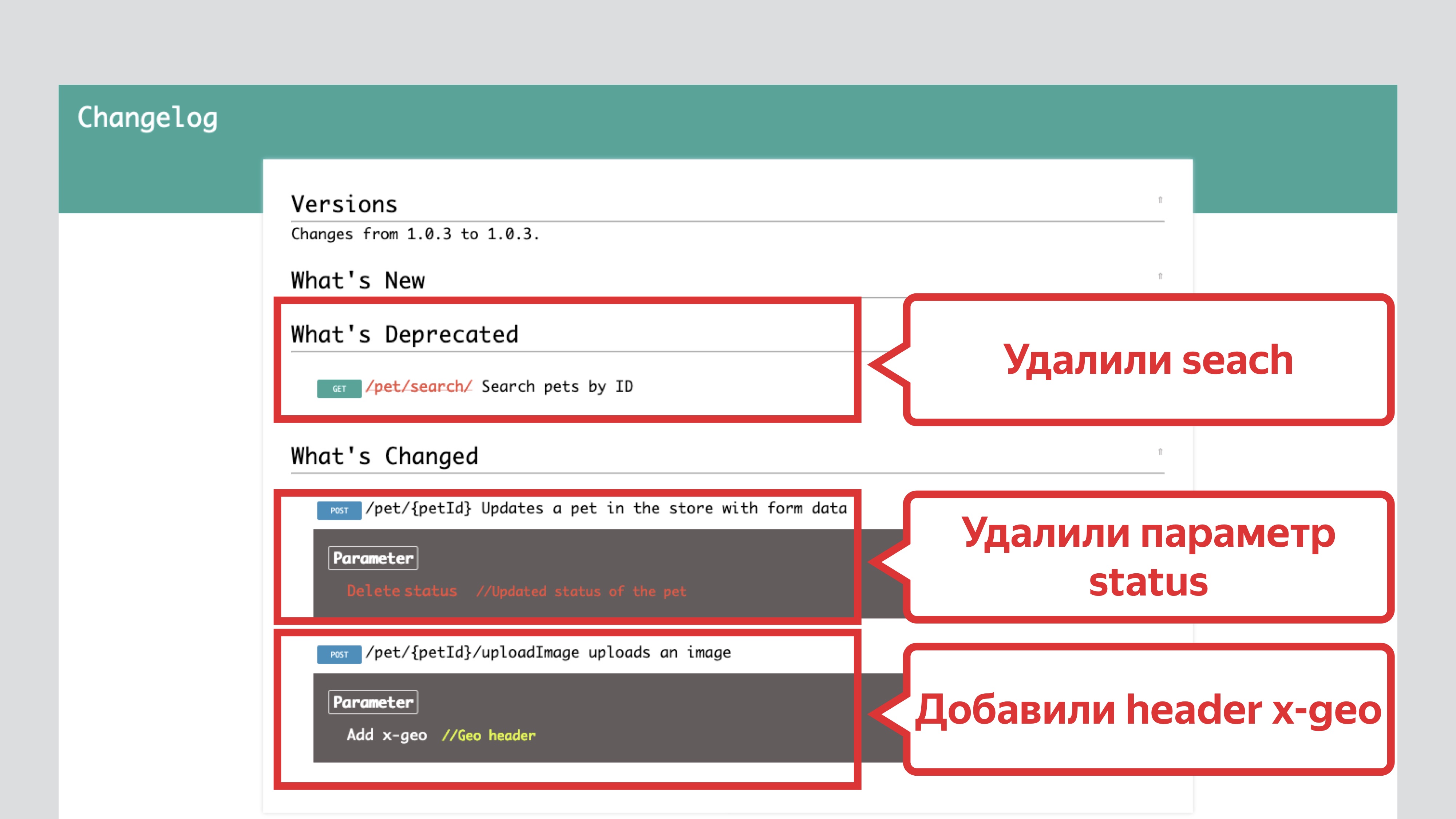
Из HTML понятно, что изменилось.
Мы также можем анализировать обратную совместимость. Выявлять случайное удаление параметров и другие изменения.
Swagger-coverage. Как его использовать?
С течением времени количество проектов стало расти, REST API постоянно менялись. При этом наши REST API имеют большое количество операций. В самом большом REST API, который я покрывал автотестами, было около 700 операций. Наши автотесты пишут все члены команды: ручные тестировщики, разработчики, автоматизаторы. Ещё мы наняли стажёров, которые тоже пишут тесты и которых тоже нужно контролировать. Возникает вопрос, как вообще понять, что покрыто тестами, а что нет?
Мы решили, что нам нужен инструмент, который позволит измерить это покрытие на основе OpenAPI-спецификации. Я хочу рассказать про Swagger-coverage, который мы недавно реализовали.
Как он работает? У вас есть исходная спецификация. Для каждого реквеста вы можете получить информацию в формате OpenAPI-спецификации. Далее мы агрегируем всю информацию из реквестов, сравниваем с исходной спецификацией и получаем coverage.
В результате мы получаем HTML-страницу, на которой видим общую информацию о покрытии операций, общую информацию по покрытию тегов, сколько условий мы покрываем.
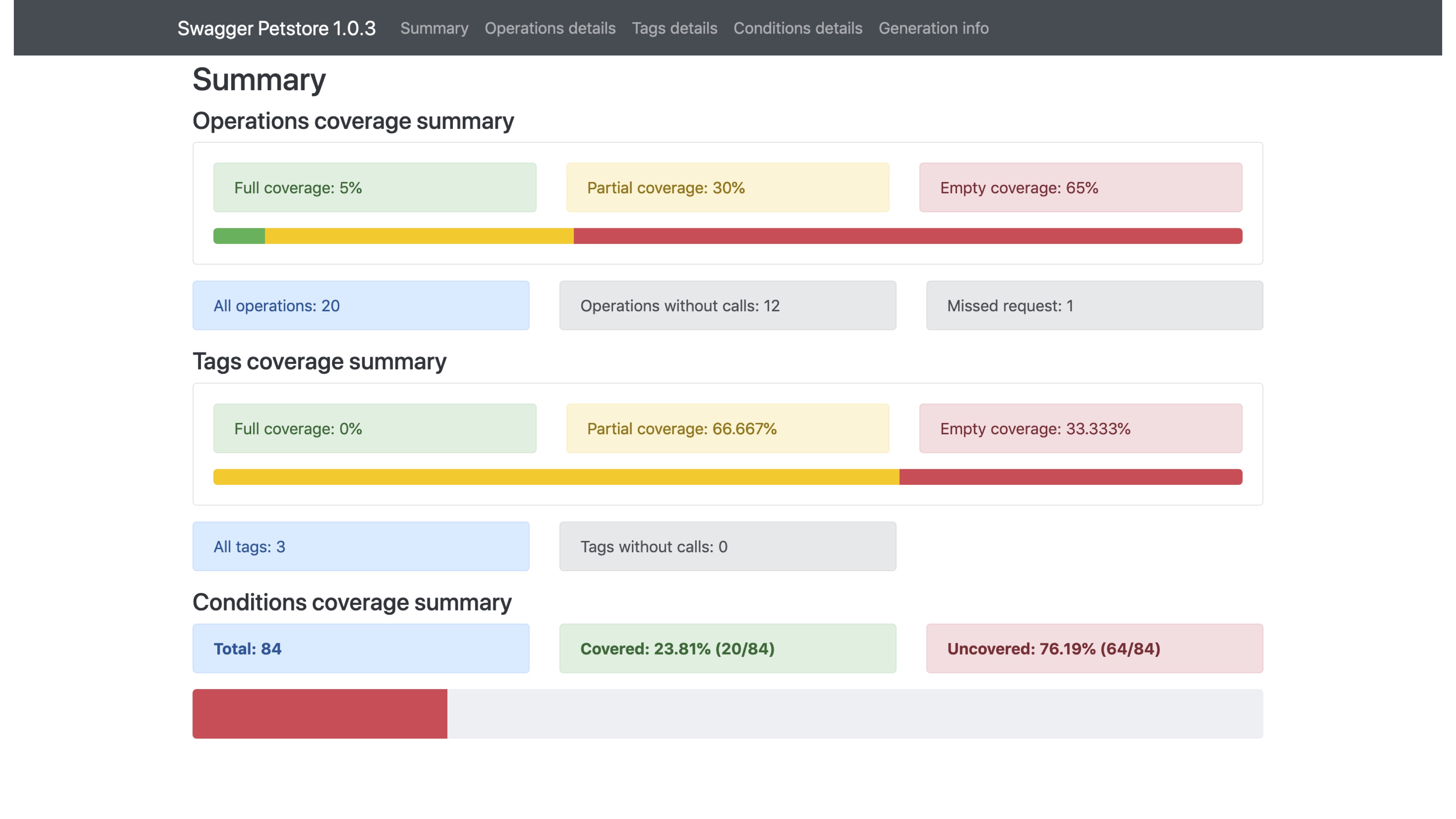
На странице есть фильтры. Мы знаем, какие операции у нас полностью покрыты, какие частично, какие вообще не покрыты. Также, если мы рассмотрим подробнее операцию, то увидим условия. Эти условия формируются на основе OpenAPI-спецификации. Например, если в OpenAPI-спецификации есть пять кодов ответа, то сформируется пять условий на эти коды ответа. В нашем примере видим, что у нас не проверяются все значения параметра status, мы не используем значение enum-а sold.
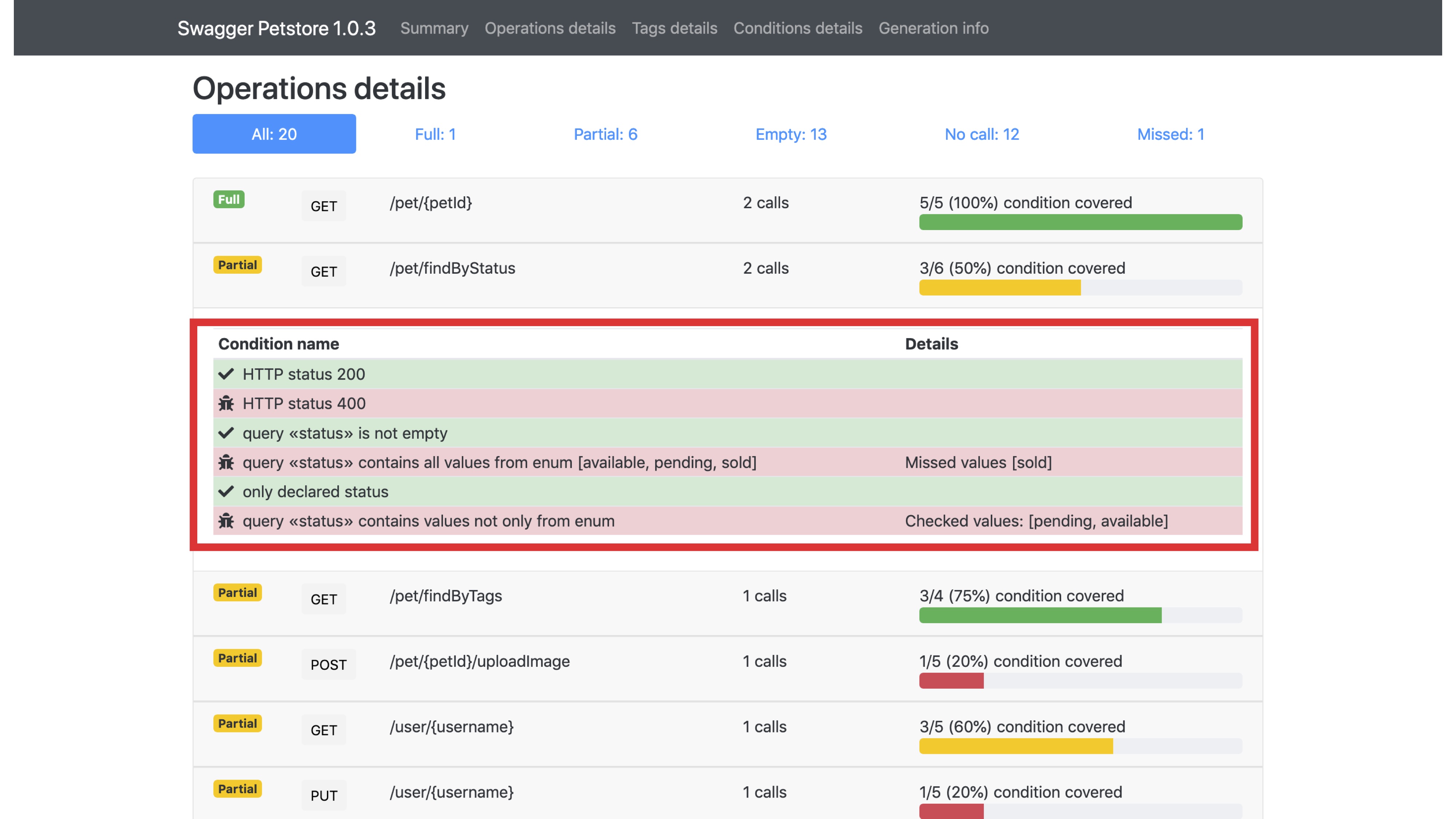
Все эти условия настраиваются через Config JSON.
Так же выглядят и теги — это группа операций. Мы можем понять, сколько операций покрывается, сколько вообще не покрыты. Ещё есть фильтры по условиям, можем посмотреть, какие условия не покрываются совсем.
Зачем это нужно, и как это использовать? Есть несколько способов использования.
- Анализировать прогресс автоматизации: нам нужно понимать, как и что мы покрываем тестами.
- Выбрать стратегию автоматизации. Например, покрывать то, что вообще не покрыто. Или сосредоточиться на параметрах и на операциях, которые хотя бы как-то покрыты.
- Отслеживать добавление новых сущностей без тестов.
Как построить процесс
Теперь давайте построим процесс, объединив всё в одну большую систему.
У нас есть два инструмента: Swagger-diff и Swagger-coverage. Swagger-diff возвращает json с диффом, Swagger-coverage тоже возвращает json о покрытии.
Мы можем сделать такие выводы: что-то изменилось и покрыто тестами или что-то изменилось, но не покрыто тестами.
Мы можем красить build в красный цвет и тем самым стимулировать разработчиков писать тесты.
Как построить процесс? У нас собрался build, и запустился Swagger-diff, и мы уже заранее знаем на этом этапе, сломалась ли обратная совместимость и изменилось ли что-нибудь. Это же может показать запуск тестов. Потом мы можем по результатам тестов построить coverage, чтобы понять, что покрыто, а что — нет, и на основе этого выбирать дальнейшую стратегию тестирования.
Подведём итог
Что такое Swagger/OAS как основа приёмочных тестов?
- Всегда актуальный тестовый клиент, понятный для всех членов команды
- Сгенерированные тесты и шаблоны тестов
- Лёгкое добавление автотестов на новые проекты, вне зависимости от языка программирования
- Прозрачность покрытия и изменений REST API через прозрачный инструментарий.
Минутка рекламы: читать расшифровки докладов по тестированию интересно, но ещё интереснее смотреть новые доклады в прямом эфире с возможностью задать вопрос спикеру. Уже на днях, 4 ноября, стартует Heisenbug 2020 Moscow — и там докладов по тестированию будет сразу множество.
")



