
Tarantool, как известно, поддерживает любой язык, который совместим с C и компилируется в машинный код. В том числе есть возможность реализации хранимых функций и модулей на Lua и C. Тем не менее, уже в двух своих проектах мы использовали Rust (в одном из них полностью перенесли Lua-код на Rust) и получили 5-кратное увеличение производительности по сравнению с Lua и сопоставимый результат, который дает по производительности C.
Меня зовут Олег Уткин и в Tarantool я занимаюсь высоконагруженными системами хранения данных. Я расскажу про упомянутые два проекта, а также о том, чем так хорош Rust, в котором уже давно существуют различные биндинги для API Tarantool и написания Lua-модулей. Например, вы можете прямо сейчас взять Rust и написать код под Tarantool, в том числе, хранимые процедуры и сторонние модули, которые можно использовать без Lua. Интересно? Поехали!

Казалось бы, Lua или C — неплохие языки. Если бы не их существенные недостатки. Например, хоть Lua и позволяет быстро разрабатывать код, но в некоторых ситуациях он бывает недостаточно быстрым.
И, откровенно говоря, у него не очень хорошая экосистема, просто потому, что обычно этот язык встраивают в приложения, чтобы пользователь мог расширить их функционал и написать свой код. Это приводит к тому, что существующие Lua-модули зачастую несовместимы с Tarantool — например, для работы с сетью и прочими асинхронными операциями. А код, написанный для одного окружения, допустим, OpenResty на Nginx, вы не сможете запустить на Tarantool или на чистом Lua-интерпретаторе. Из-за этого получаются немного изолированные экосистемы.
Если говорить о С, то код быстро исполняется, но его достаточно тяжело писать из-за ручного управления памятью. Что может вызывать различные баги в работе с ней и замедлять время отладки кода. Кроме того, у него достаточно сложный интерфейс для написания Lua-модулей и бывает трудно интегрироваться со сторонними библиотеками. Во-первых, из-за огромного зоопарка систем сборки, которые для использования приходится интегрировать со своим кодом. А, во-вторых, из-за отличий подходов, например, к работе с сетью — подходы приходится «женить».
Поэтому я составил список того, чего бы я хотел от языка:
Богатая экосистема пакетов, которые можно переиспользовать, экономя время на разработку, отладку и тестирование.
Удобный пакетный менеджер, чтобы можно было подключить и отслеживать зависимости.
Удобная система сборки, которая будет все это собирать, линковать и упрощать интеграцию с другими библиотеками.
Относительно быстрая скорость разработки.
Безопасная работа с памятью.
Скорость исполнения.
Как мне показалось, Rust вполне удовлетворяет этим критериям. Давайте посмотрим это сначала на наших кейсах.
Кейс: разработка хранимых процедур для Tarantool
Это простейшая хранимая процедура, которая принимает три параметра: год, квартал и минимальную стоимость:
Код на Lua
function some_procedure(year, quarter, min_cost)
local space = box.space.some_space.index.some_index
local result = space
:pairs({ year, quarter }, { iterator = 'GE' })
:take_while(function(record)
return record.year == year
and record.quarter == quarter
end)
:filter(function(record)
return record.earning > min_cost
end)
:totable()
return result
endЧто она делает? Из таблицы с транзакциями, которые разбиты по кварталам, выбирает те, что соответствуют определенному кварталу и при этом имеют большую сумму, чем мы указали в запросе.
На Lua это сделать достаточно просто. Но если нам нужно было получить код, который работает быстрее, мы переписывали его на C, и он выглядел так:
Код на C
int some_procedure(box_function_ctx_t* ctx, const char* args, const char* args_end) {
uint32_t args_n = mp_decode_array(&args);
assert(args_n == 3);
uint32_t year = mp_decode_uint(&args);
uint32_t quarter = mp_decode_uint(&args);
double min_cost = mp_decode_double(&args);
uint32_t space_id = box_space_id_by_name("some_space", strlen("some_space"));
uint32_t index_id = 0;
char key_buf[128];
char *key_end = key_buf;
key_end = mp_encode_array(key_end, 3);
key_end = mp_encode_uint(key_end, year);
key_end = mp_encode_uint(key_end, quarter);
key_end = mp_encode_double(key_end, min_earnings);
box_iterator_t* it = box_index_iterator(space_id, index_id, ITER_GE, key_buf, key_end);
while (1) {
box_tuple_t* tuple;
if (box_iterator_next(it, &tuple) != 0) {
return -1;
}
if (tuple == NULL) {
break;
}
uint32_t args_n = mp_decode_array(&tuple);
assert(args_n == 3);
uint32_t record_year = mp_decode_uint(&tuple);
uint32_t record_quarter = mp_decode_uint(&tuple);
double record_cost = mp_decode_double(&tuple);
if (record_year != year || record_quarter != quarter) {
break;
}
if (record_cost <= min_cost) {
continue;
}
box_return_tuple(ctx, tuple);
}
box_iterator_free(it);
return 0;
}Он раза в три больше. Причем две трети этого кода — не сама логика хранимой процедуры, а просто работа по десериализации данных, которые приходят из хранилища. Для сравнения, на Rust это выглядит так:
Код на Rust
#[derive(Serialize, Deserialize)]
struct Record { year: u16, quarter: u8, earnings: f64 }
fn some_procedure(ctx: &FunctionCtx, args: FunctionArgs) -> c_int {
let args_tuple: Tuple = args.into();
let (year, quarter, min_cost): (u16, u8, f64) = args.as_struct().unwrap();
let space = Space::find("some_space").index("some_index");
let result: Vec<Record> = index
.select(IteratorType::GE, &(year, quarter))
.map(|tuple| tuple.as_struct::<Record>())
.take_while(|record| record.year == year && record.quarter == quarter)
.filter(|record| record.cost >= min_cost)
.collect()
match ctx.return_mp(&result) {
Ok(_) => 0,
Err(_) => -1,
}
}По размеру и логике это аналогично Lua, но производительность такая же, как у C. За счет чего это достигается?
Кодогенерация, макросы
Одна из крутых вещей, которая есть в Rust — это метод программирования. Вы можете писать свои макросы, которые во время компиляции будут работать с вашим кодом через манипуляции с абстрактным синтаксическим деревом. По сути, это нечто вроде хранимой процедуры, которая принимает это дерево и может делать с ним любые модификации.
Вы это даже можете не писать сами. Уже есть много библиотек, которые сделают это за вас. Как правило, они используют фреймворк Serde (Serializer, Deserializer):
Serde
#[derive(Serialize, Deserialize)]
struct Record {
year: u16,
quarter: u8,
cost: f64,
}
fn parse_record(raw_data: &str) -> Result<Record, ParseError> {
let record: Record = serde_json::from_str(raw_data)?;
return record;
}Serde, по сути, реализует универсальный интерфейс для написания библиотек, который будет сериализовать/десериализовать ваши данные во время компиляции. На основе этого кода можно подключить любую библиотеку, которая умеет сериализовать JSON либо MessagePack, и делает это буквально в одну строку.
Функциональное программирование, итераторы
Rust включает в себя различные операции для обработки данных, которые приходят из итераторов. Например, можно cмаппить данные с помощью оператора map, отфильтровать или агрегировать их с reduce:

Здесь видно, что запрос, который мы делаем на Rust, занимает примерно столько же кода, сколько мы могли бы написать на Lua, и логически выглядит примерно также.
Результаты
Приведу пример теста. На процедуре выборки и на одном инстансе Tarantool (один поток) при 100% утилизации CPU получаются такие результаты:

Видим, что код на Lua дает 340 RPS, а на C — 1700. Rust при этом позволяет написать столько же простого кода как на Lua, но получить производительность сопоставимую с C.
Кейс: разработка модулей
Следующий кейс, в котором мы использовали Rust — это разработка модулей. Это пример, как код на Rust можно обернуть в биндинг, и не важно, Lua это, JS или Python — вы получите готовый модуль для вашего языка программирования. Покажу на простейшем примере:

Есть процедура, написанная на Lua, которая выводит «hello, world». Чтобы реализовать ее на Rust, достаточно соблюсти некоторую сигнатуру функций, которые дальше мы можем пробросить в Lua. При этом никаких преобразований данных делать не нужно. И это касается всех примитивных типов данных, которые есть в Rust: они будут автоматически кодированы в тип, удобный для работы в Lua.
Если у вас есть какой-то кастомный тип, то вы можете для своей структуры определить методы, которые будут проброшены в Rust. Вот хороший пример:
Avro-сообщения с помощью Lua внутри Tarantool
struct Avro { schema: Schema }
impl Avro {
pub fn new(schema: &str) -> Result<Self, avro_rs::Error> {
Ok(Avro { schema: Schema::parse_str(schema)? })
}
pub fn decode<R: Read>(&self, reader: &mut R) -> Result<Value, avro_rs::Error> {
let avro_value = avro_rs::from_avro_datum(&self.schema, reader, None)?;
Ok(Value::try_from(avro_value)?)
}
}
impl mlua::UserData for Avro {
fn add_methods<'lua, M: LuaUserDataMethods<'lua, Self>>(methods: &mut M) {
methods.add_method("decode", |lua, this: &Avro, blob: LuaString| {
let json_value = this.decode(&mut blob.as_bytes())?;
lua.to_value_with(&json_value)
});
}
}В нашем реальном кейсе была задача декодировать Avro-сообщения с помощью Lua внутри Tarantool. К сожалению, реализации Avro на Lua не существовало, а если бы и существовало, то, скорее всего, она работала бы достаточно медленно. Но у нас уже была готовая библиотека, написанная на Rust. Мы портировали её на Lua, просто написав для нее proper.
Конечно, это не все возможные области применения Rust. Говоря в общем, Rust может заменить такие языки, как C и C++, поскольку он так же, как они, компилируется в машинный код. При этом за все возможности языка вы платите только один раз — во время компиляции.
Но вы сможете его использовать и в более прикладных задачах. Например, ускорить бэкенд, переписав код на Rust и затратив на это немного усилий. Также есть большое количество библиотек реализации блокчейнов. Думаю, он так популярен там просто потому, что им необходима высокая скорость исполнения кода и несложность разработки. Rust всё это дает.
А теперь посмотрим, что в принципе делает Rust таким крутым. Я разбил его особенности на 4 основных категории: память, типы, экосистема и разработка сетевых приложений.
Чем хорош Rust
Память
Одна из особенностей Rust — это понятия владения и аффинных типов данных:
Инициализация и переиспользование
struct User { name: String, country: String, age: i32 }
pub fn main() {
let user = User {
name: String::from("Igor"),
country: String::from("Russia"),
age: 30,
};
print_user_age(user);
// здесь происходит перемещение user внутрь функции
}
fn print_user_age(user: User) {
println!("{} is {} years old", user.name, user.age);
// Здесь вызовется деструктор user
}Это означает, что данные, которые вы инициализируете в некоторой области видимости, точно освободятся, причем ровно один раз. Не будет ситуации, что они ушли в другую область видимости, освободились там, а вы переиспользуете данные, на которые уже вызваны деструкторы. Компилятор может это отследить и сообщить программисту, чтобы он это исправил.
Заимствование
В случае, когда мы не хотим передавать владение какими-то нашими переменными в другие скоупы, мы можем передать их по ссылке:
Передача владения
struct User { name: String, country: String, age: i32 }
pub fn main() {
let user = User {
name: String::from("Igor"),
country: String::from("Russia"),
age: 30,
};
print_user_age(user); // здесь происходит перемещение user внутрь функции
print_user_country(user); // ошибка: используем перемещенный объект
}
fn print_user_age(user: User) { println!("{} is {} years old", user.name, user.age); }
fn print_user_country(user: User) { println!("{} lives in {}", user.name, user.country); }Владение переменными, которые мы выделяем в текущем скоупе, остается там же, и там же будет вызван деструктор. Но теоретически может случиться, что у нас появится ссылка, которая была объявлена во внешнем скоупе, а данные, на которые она указывает — выделены в дочернем скоупе.
То есть данные, на которые указывает ссылка, могут быть освобождены до того, как была освобождена ссылка, и в этот момент она укажет на невалидные данные. Здесь на помощь придет Borrow checker (проверщик заимствований), который встроен в компилятор Rust:
Borrow checker
struct User { age: i32 }
pub fn main() {
let user_ref: &User;
{
let user = User { age: 30 };
user_ref = &user; // ошибка компиляции, т.к. может вызвать невалидную ссылку
// здесь вызовется деструктор user, делая ссылку user_ref невалидной
}
// здесь вызовется деструктор user_ref
}Если у вас действительно возникнет такая ситуация, то компилятор вам об этом скажет, а ваш код не скомпилируется. В принципе, можно сказать, что компилятор Rust дает гарантию того, что у вас не будет ссылок, которые указывают на невалидные данные.
Умные указатели
Но что, если мы не можем определить размер данных во время компиляции? Тут на помощь приходит тип Box. Он позволяет выделять данные на heap. По сути, это умный указатель, похожий на std::unique_ptr в C++. Мы выделяем данные на стеке, сразу перемещаем их на heap, а их поведение остается такое же, как если бы мы эти данные выделили на стеке. Здесь видно, что точно так же мы перемещаем переменную user в вызываемую функцию, и там данные уже освобождаются:
тип Box
struct User { name: String, country: String, age: i32 }
pub fn main() {
let user = Box::new(User {
name: String::from("Igor"),
country: String::from("Russia"),
age: 30,
});
print_user_age(user); // здесь происходит перемещение user внутрь функции
}
fn print_user_age(user: Box<User>) {
println!("{} is {} years old", user.name, user.age);
// Здесь вызовется деструктор user
}Но бывают ситуации, когда нужно использовать ссылку на одни и те же в несколькими областях видимости или передать в другие потоки исполнения. Для этого в Rust есть тип Rc (reference counter), и это тоже умный указатель. Когда мы выделяем память с помощью Rc, то у нас есть счётчик, который указывает — сколько есть ссылок на конкретно эти данные. Когда мы явно клонируем этот указатель, то счетчик ссылок на эти данные инкрементируется. И декрементируется, если указатель вызывает свой деструктор. Если счётчик становится 0, то данные освобождаются:
тип Rc (reference counter)
struct User { name: String, country: String, age: i32 }
pub fn main() {
let user = Rc::new(User {
name: String::from("Igor"),
country: String::from("Russia"),
age: 30,
});
let user2 = user.clone(); // клонируем умный указатель
print_user_age(user2); // здесь происходит перемещение указателя на user внутрь функции
print_user_country(user); // здесь происходит перемещение user внутрь функции
}
fn print_user_age(user: Rc<User>) { println!("{} is {} years old", user.name, user.age); }
fn print_user_country(user: Rc<User>) { println!("{} lives in {}", user.name, user.country); }Этот подход называется подсчетом ссылок и используется еще много где. Чем же он хорош? Например, вот графики из достаточно интересной статьи Discord о том, как они с помощью перехода с Go на Rust смогли ускорить свои сервисы:
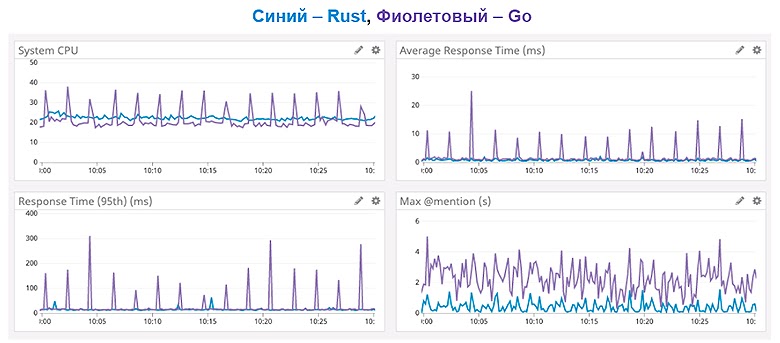
Garbage Collection заставляет прервать исполнение кода и начать освобождать неиспользуемую память. Но такие остановки негативно влияют на latency запросов, особенно на 95% и выше. На графике видно, что при использовании Rust удалось значительно сократить latency, а нагрузку на CPU сделать более равномерной.
Unsafe
Мы говорили о возможностях, которые позволяют Rust проверять используемую память на безопасность. Но бывают ситуации, когда нам нужно делать операции с сырыми указателями, а их компилятор Rust проверять не умеет. Поэтому ответственность за проверку того, что за данные лежат под указателями и насколько они валидные, ложится на разработчика.
Для таких ситуаций в Rust есть специальное ключевое слово unsafe, позволяющее выделить блок кода, где компилятор сможет дать доступ разработчику к unsafe-операциям:
let mut num = 5;
let r1 = &num as *const i32;
let r2 = &mut num as *mut i32;
unsafe {
println!("r1 is: {}", *r1);
println!("r2 is: {}", *r2);
}Благодаря этому, вы сможете разыменовывать сырые указатели. Это могут быть нулевые указатели или указывающие на невалидный участок памяти. А также иметь возможность вызывать функции, помеченные как unsafe. Внутри таких функций можно выполнять unsafe операции, но сами они могут вызываться только из unsafe блоков. Используя unsafe-функции, программист должен понимать, что компилятор не может точно сказать, испортит ли данный код данные или нет. И будут ли валидными указатели, которые он передает или получаете из нее.
Также вы сможете работать с FFI, когда, допустим, вы подключаете динамическую библиотеку. Естественно, компилятор не может проверить, что операции, которые вы будете делать в этой динамической библиотеке, точно никак не повлияют на вашу память.
Теперь перейдём к следующей категории.
Алгебраические типы данных
Алгебраические типы данных пришли в Rust из функционального программирования. По сути, это что-то типа суммы типов, и в некоторых языках их называют тегированные enum. Они позволяют в одном типе хранить сразу несколько вариантов того, как он будет выглядеть и какую структуру иметь:
Enum
enum Shape {
Square { width: u32, length: u32 },
Circle { radius: u32 },
Triangle { side1: u32, side2: u32, side3: u32 },
}
pub fn main() {
let square = Shape::Square { width: 10, length: 20 };
let circle = Shape::Circle { radius: 20 };
let shape: Shape = square;
match shape {
Shape::Square { width, length } => println!("square({}, {})", width, length),
Shape::Circle { radius } => println!("circle({})", radius),
_ => println!("other shape"),
}
}В примере мы выделяем несколько вариантов enum (Square, Circle, Triangle) и присваиваем их общей переменной Shape. Потом, с помощью pattern matching, определяем, что у нас лежит внутри этой переменной, и на основе этого реализовываем какую-то логику.
На основе этого механизма в Rust также организована работа с ошибками:
Проверка на ошибки
enum Result<T, E> {
Ok(T),
Err(E),
}
fn do_something_that_might_fail(i: i32) -> Result<f32, String> {
if i == 42 {
Ok(13.0)
} else {
Err(String::from("this is not the right number"))
}
}
fn main() -> Result<(), String> {
let v = do_something_that_might_fail(42)?;
println!("found {}", v);
// эквивалентно
let result = do_something_that_might_fail(42);
match result {
Ok(v) => println!("found {}", v),
Err(e) => return Err(err),
}
Ok(())
}Как это работает? Из функции возвращается тип Result, который может находиться в двух состояниях: Ok(T), то есть выполнилось с успехом или Err(E), возвращая какую-то ошибку. Мы можем работать с этим явно — с помощью того же pattern matching). Либо используя специальный оператор (знак вопроса), который возвращает то, что вернулось из функции при успехе. Если завершилось с ошибкой, то он передает её дальше в ту функцию, которая вызвала исполнение.
Таким же образом решается проблема с нулевыми указателями. У нас есть переменные, которые могут в себе хранить данные, а могут не хранить. Тут на помощь приходит тип Option, который может находиться в двух состояниях. Это либо None (в текущей переменной нет данных), либо Some(T), которое хранит данные, что мы хотим вернуть:
тип Option
enum Option<T> {
None,
Some(T),
}
fn do_something_that_might_fail(i: i32) -> Option<f32> {
if i == 42 {
Some(13.0)
} else {
None
}
}
fn main() {
let result = do_something_that_might_fail(42);
match result {
Some(v) => println!("found {}", v),
None => println!("not found"),
}
}Это позволяет нам во время компиляции точно обработать все случаи, когда в переменной нет данных.
Traits (типажи)
Ещё один из ключевых механизмов языка — это traits (типажи), что-то вроде интерфейсов или абстрактных классов, которые есть в ООП-языках. Traits позволяют определить желаемое поведение некой структуры или enum, указав, какие методы они должны реализовывать.
Помимо этого, traits позволяют реализовать дефолтные методы, которые, например, основаны на обязательных методах. То есть, реализовав всего парочку обязательных методов, мы можем получить множество методов, основанных на них — и автоматически реализовывать логику для наших структур:
traits (типажи)
trait Animal {
pub fn get_name(&self);
pub fn say();
}
struct Dog { name: String };
impl Animal for Dog {
pub fn get_name(&self) -> String { self.name.clone() }
pub fn say() { println!("bark"); }
}
struct Cat { name: String };
impl Animal for Cat {
pub fn get_name(&self) -> String { self.name.clone() }
pub fn say() { println!("meow"); }
}
fn main() {
let animal: Animal = Dog{ name: String::from("Rex") };
animal.say();
println!("animal's name is {}", animal.get_name());
}Теперь перейдём к следующей категории.
Экосистема
Пакетный менеджер и система сборки
В Rust есть Cargo, который совмещает в себе очень удобный пакетный менеджер и систему сборки. Cargo позволяет на основе описания вашего пакета со всеми зависимостями и любой дополнительной метаинформации, автоматически скачать, собрать и слинковать эти зависимости. При этом есть возможность описания дополнительной логики при сборке:

Чем это может быть полезно? Например, при сборке нашего пакета мы можем сразу скомпилировать реализацию Protobuf спецификации. А если мы хотим скомпилировать наш проект на Rust «сишным» кодом, то это можно будет сделать автоматически во время компиляции — просто указав, какие файлы нужно к нему прилинковать.
Сторонние библиотеки
В экосистеме Rust есть огромное количество пакетов, которые могут нам пригодиться на все случаи жизни: от различных сетевых протоколов коннекторов к БД до HTTP-фреймворков. Но если вам и этого недостаточно, то в Rust есть интерфейс для взаимодействия со сторонними языками. Например, вы можете писать код на C и вызывать его в коде на Rust:

Это очень удобно, если у вас уже есть часть кодовой базы, которая написана на C — вы просто можете переписать часть кода на Rust. Либо наоборот, у вас есть небольшой код на Rust, и тогда вы сможете интегрировать его в свой проект.
Стоит заметить, что вызов «сишного» кода по FFI в Rust всегда считается unsafe. Тут программисту нужно быть более аккуратным, чтобы обработать случаи, когда происходит небезопасная работа с памятью. Он должен написать безопасную обертку над небезопасным интерфейсом.
Инструменты отладки
Также из C в Rust пришли различные инструменты для отладки. Например, Valgrind для поиска утечек, дебаггеры GDB и LLDB, а также профайлеры perf и dtrace. Вот пример трейса через perf простого приложения:
Видно, что все символы удобно подтягиваются. Также можно смотреть по функциям, кто сколько процессорного времени отъедает.
Документация
У Rust есть специальный сайт, где собрана документация для всех пакетов, которые есть в их registry. Вы можете в своем пакете описать комментарии к вашим функциям, добавив части документов прямо в код — и всё будет отображаться на сайте вместе с остальной документацией по пакетам Rust.
Кроме этого, есть очень хорошая официальная документация Rust book, в качестве учебника от разработчиков языка. В ней с примерами описаны все компоненты, которые есть в языке. В принципе, прочитав Rust book, вы сможете сказать, что умеете программировать на Rust.
И, наконец, по работе с unsafe есть Rustonomicon — подробное руководство, как правильно писать обертки на unsafe-код, которые будут безопасны уже для работы из Rust’ового кода. Это руководство также описывает некоторые внутренности языка, и его полезно почитать.
Для начинающих я бы рекомендовал пройти Rust tour — он показывает все возможности языка, приводя различные примеры для каждой. Для себя я еще нашел лекции Алексея Кладова. Он достаточно подробно и популярно объясняет, что и как работает в Rust.
А у нас осталась последняя категория, которую нужно разобрать, чтобы понимать особенности Rust.
Разработка сетевых приложений
Асинхронные интерфейсы, async/await
В стандартной библиотеке Rust из коробки идут интерфейсы, которые позволяют реализовывать свои асинхронные рантаймы и взаимодействовать с чужими из вашего кода. Но при этом сам Rust в себе рантайм не содержит — его реализуют сторонние разработчики. Для этого есть две самые популярные библиотеки: Tokio и async-std. Они похожи интерфейсами и производительностью, но Tokio появилась чуть раньше, поэтому более популярна и для неё больше пакетов.
Из самого основного, что нужно, Tokio включает в себя многопоточный work-stealing-рантайм для исполнения асинхронного кода. Это значит, что внутри рантайма есть тредпул, который на каждый поток CPU запускает поток ОС. Те асинхронные задачи, которые вы исполняете в своем коде, будут равномерно балансироваться между этими потоками — то есть вы сможете задействовать в коде все ядра процессора.
Work-stealing означает, что один из потоков, выполнив все свои задачи, может начать выполнять задачи из очереди другого потока. Это позволяет нагружать процессор более равномерно, и у вас не будет ситуации, когда один поток, выполнив свои задачи, простаивает в ожидании новых.
Кроме этого, Tokio включает в себя часть стандартной библиотеки, отвечающей за работу с асинхронным кодом и несет огромную экосистему уже готовых пакетов. В целом в Tokio это очень похоже на подход, который используется в языке Go. Только горутины (goroutine) в Rust называются тасками (task), которые уже рантайм балансируют между потоками. Вот достаточно простой пример TCP сервера:

Сначала мы создаем TcpListener, который будет в бесконечном потоке принимать соединения из сокета. Каждое отдельное соединение можно запустить в отдельной таске, и они будут балансироваться между потоками процессора, равномерно его утилизируя.
Или, например, так же как в Go, в Rust вместе с Tokio можно создать каналы, которые позволят обмениваться данными между тасками через передачу сообщений:

Выводы
Rust может выступить более удобной заменой для языков C и C++ в качестве языка системной разработки. Например, на нем можно писать модули для Linux, которые до сих пор нельзя было писать на C++.
Также он подходит не только для системной, но и для прикладной разработки. По сути, как я говорил, можно переписать бэкенд на Rust и получить большой прирост по скорости.
И наконец, Rust хорошо подходит для написания модулей для других языков (Lua, JS, Python), если мы хотим ускорить код или в том языке нет библиотек, которые мы хотели бы использовать.
Конференция Highload++ Foundation пройдет 17 и 18 марта в Москве, в Крокус-Экспо. Описание докладов и раcписание уже готовы. Билеты можно купить на сайте.
А сейчас идет открытое голосование по Open Source трибуне, где определятся 5 лучших решений. Отдайте свой голос за то, что вам нравится и помогите определить лучших!
")



