
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Очень часто драматически и патетически утверждают, что техдолг лучше не плодить — потом не устранишь. Да, без него, конечно, лучше. Но последствия устранить все-таки можно, и глава Программного комитета Артем Каличкин на конференции DevOpsConf 2020 поделился своим опытом в этой области.
Можно спросить, а причем здесь техдолг, если конференция DevOps? Холиварить об этом можно, например, в рамках DevOps-фуршета, но настолько ли это широкое понятие? Мы узнали, что Артем относит к техдолгу все изменения и доработки, инфраструктурные модификации и изменения процессов, изменения структур команд, направленные на устранение гэпов — которые были допущены (осознанно или нет) в рамках запуска продуктов и фич, и которые со временем сильно мешать жить.
А так как такие вещи невозможно исправить без твердой и уверенной спайки производственного и операционного цехов, то и получается, что эта история напрямую — про DevOps.
Почему я про это говорю, какое у меня право? Дело в том, что с operations, production и техдолгом я так или иначе связан 16 лет своей жизни:
До 2004 года я работал программистом-разработчиком на Java в различных компаниях, которые занимаются заказной разработкой ПО, и со временем стал чувствовать себя, извиняюсь за метафору, «суррогатной матерью». Я рождаю какой-то продукт, отдаю его и дальше его судьба мне не ведома. Меня это очень печалило, потому что я хотел знать обратную сторону жизни продуктов — как живет на production то, что я создаю. Эту возможность я нашел в авиакомпании Сибирь (тогда S7 так называлась). Пришел я туда системным аналитиком, а уходил с позиции заместителя директора по IT. Отвечал я за внедрение программных продуктов, ввод и разворачивание новых инфраструктур на — конечно же — production.
В авиации уже в те годы степень зависимости от автоматизации была очень высокой. Это одна из передовых отраслей с этой точки зрения — по крайней мере, в нулевых годах она в этом шла впереди планеты всей. Например, в 2006 году по всему миру отменили печатные билеты, остались только электронные. А сама авиационная деятельность напрямую влияет на бизнес-процессы, на судьбы людей, на всю нашу жизнь. Остановка этих систем и инфраструктур приводит к тяжелым последствиям для огромного количества людей — это и задержки вылетов, и проблемы с регистрацией. Так что по ночам спать я перестал уже тогда. Я уже 16 лет по ночам сплю, вздрагивая, потому что имею отношение к обеспечению на production жизни сервисов, которым стоять никак нельзя.
Но со временем я все-таки понял, что хочу заниматься не только operations, то есть не только вопросами эксплуатации, но разработка мне тоже близка. Мне захотелось заниматься всем производственным циклом, что я и нашел в компании Центр Финансовых Технологий — в рамках тех сервисов, где я сейчас работаю, мы обеспечиваем полный производственный цикл: от идеи до production (включая сам production), обеспечение и доступность.
Здесь, правда, спать стало еще тяжелее, потому что это финтех. Здесь не то, что простой, а задержки со скоростью проведения платежей уже вызывают праведный гнев у клиентов. О потере, порче или неконсистентности данных говорить вообще нельзя — это недопустимо в принципе с финансовой информацией и персональными данными (как и в авиакомпаниях, конечно).
С 2018 года я стал техническим директором сервиса Faktura.ru — это интернет-банк для физических и юридических лиц. И ко всему прочему в моем багаже добавился еще и фактор highload, то есть 10000+ tps, внезапные наплывы пользователей и совершенно безумная, непонятно с чем связанная, активность пользователей на production. Это теперь моя реальная жизнь — я отвечаю как за производство, так и за эксплуатацию.
И на всём своём пути я всегда боролся за качество продукта, потому что я все-таки люблю спать по ночам. Я боролся за то, чтобы уделялись время и усилия повышению качества продукта и устранению технологических гэпов, которые так или иначе неизбежно закладываются на проектных этапах.
И я хочу поделиться этим опытом, моей рефлексией и теми выводами, к которым я пришел спустя долгие 16 лет, особенно на базе последних 3 лет, что я работаю в Faktura.ru. Здесь мне удалось реализовать интересную комбинацию, так сказать — каскад подходов, и у меня окончательно сформировалась мысль, как же делать техдолг. И эта каскадная структура — та фишка, про которую я хочу вам рассказать.
Но для начала — корень проблемы — почему мы вообще говорим о техдолге? Потому что нам очень обидно, что бизнес не выделяет на это время. Это просто красной нитью проходит через все доклады, митапы, коммуникации разработчиков и эксплуатации — злой, плохой, страшный бизнес не выделяет время на работу с техдолгом. Возникает даже праведный вопрос: «Им вообще что ли качество не нужно?!» Забегая вперед, скажу: «Качество никому не нужно», но эту мысль раскрою чуть позже, пусть она вас пока побомбит.
Для анализа этой ситуации давайте задумаемся — почему же так бизнес с нами поступает? И для получения ответа надо задуматься над тем, а вообще техдолг — это чья головная боль? Он чей?

Спустя годы участия в этом всем, я понимаю, что мы как Фродо, который всем предлагал кольцо — помогите мне нести эту ношу! Мы ждем, что бизнес захочет (именно захочет), чтобы мы занялись техдолгом. Но корневая причина нашего взаимонепонимания с бизнесом в том, что он никогда не захочет. Для нас это — инженерно интересная задача, способ повысить совершенство продукта или даже механизм повышения гордости за наш продукт. А для бизнеса это всегда помеха, неизбежное зло (или необходимость), на которое приходится тратить время.
Представьте, вы сели в такси, а таксист такой: «Я заскочу на автомоечку?»

Вы в этой ситуации — бизнес, а таксист — мы, разработчики. Вы возмущаетесь: «Как же так?! Я деньги плачу за время в пути, а ты поедешь на автомойку!» На что таксист резонно отвечает:
— Вы что, не хотите ехать в чистой машине, в которой хорошо пахнет?
— Блин, конечно, хочу! Но я жду этого по умолчанию и не готов ради этого заезжать на автомойку сейчас!
Так нас воспринимает бизнес с техдолгом — как предложение заехать на автомойку. Чтобы у меня был чистый салон или салон лакшери, я выбираю соответствующую категорию при заказе такси. На этапе заказа я готов в это вложиться, а вот заезжать на автомойку — нет. Потому что, как я уже сказал ранее, качество не нужно никому. Но его ждут по умолчанию.
Это данность, и нужно исходить из этого. Смиряться и не заезжать на автомойку нельзя, заезжать туда за счет своего личного времени — выгорим. Что же делать? Бизнес — это локомотив, ему нужны фичи, продажи и клиенты. Продать бизнесу техдолг через наши «хочу» и «желаю» — невозможно. Но можно замотивировать бизнес другим путем.
В процессе своего путешествия я сформировал три категории мотивации бизнеса к «покупке» техдолга:

А дальше я расскажу о своем опыте, что с этим делаю я, и что получается у меня и моей замечательной команды.
Когда я пришел в сервис 3 года назад, мне нужно было понять, как глубока кроличья нора, то есть как много этого самого техдолга. Что он есть, я знал по статистике запросов, в том числе, от бизнеса и партнеров. Мне нужно было разобраться, с чем я имею дело вообще. Это нормальный и обязательный первый шаг процесса работы с техдолгом — не надо бросаться делать первое обнаруженное, нужно проанализировать ситуацию в целом.
Исходя из того, что я увидел тогда, у меня появилось предположение, что одна из корневых проблем — это большая связанность кода, то есть очень сильный coupling. Сейчас я вовлекаю всех в этот процесс уже меньше, но тогда я собрал всю команду производства, чтобы зафиксировать, какие слои мы хотим выделить в нашем комплексе приложений.
В нашем приложении было не меньше 80 различных компонент (дистрибутивов, не инсталляций). И, разложив их по слоям (чтобы понять, где мы нарушаем принципы изоляции, роли и пр.), мы совместно построили такую картину:
Увидев ее, я понял, что мои предположения были верны — у нас действительно достаточно сильный coupling. Этот способ также хорош, чтобы взглянуть на свою систему в целом с точки зрения ее общей организации, так как просто сказать, что у нас есть бэкенд, фронтенд и хранение — это ещё не онтология, а тот самый прямой путь к сильному связыванию. А здесь ds можете увидеть слои, что позволит сформировать некую онтологию платформы.
После того, как мы выяснили ситуацию, с ней надо было как-то бороться.
Я, такой умный, придумал, что сделаю вид, что у всех есть время, и сформировал вокруг каждого компонента «виртуальную команду»: «Ребята, кто за какой компонент возьмется? Сформируйте свои предложения, как его улучшать». Но чтобы не расползаться мыслью по древу и быть в фокусе, мы все вместе сформулировали критерии оптимизации первой фазы:
Конечно, это был не фокус, а набор критериев практически для всех аспектов разработки ПО. Весь список можно заменить одной фразой: «Исправить всё». Эта фаза закончилась фейлом, в том смысле, что просто ничего не случилось. Мы очень мало продвинулись в реализации каких-то вещей, потому что я пытался их планировать через общий бэклог. Задачи были мутные и непонятные, на нашем с вами языке, который продакт вообще не хотел понимать. В работу они ставились вручную — если я, как техдир, пришел на планирование, то вставил какую-то штуку в бэклог, а нет — так нет. И я быстро понял, что это тяжело и мне, и команде, плюс постоянно растут конфликты и споры.
Тогда я перешел ко второй фазе.
Первым шагом я договорился с CEO нашего сервиса о том, что мы введем квотирование бэклога: на бизнес-фичи тратим 70%, на устранение дефектов — 15%, и 15% — на тот самый техдолг.
Во-вторых, на предыдущей фазе я понял, что если за вопрос отвечают все, то за этот вопрос не отвечает никто. Это вообще не бирюзовое утверждение, оно самому мне не нравится, но обратное требует очень высокого уровня зрелости и сработанности команды, а в тех условиях конфликтов, которые тогда у нас шли, говорить об этом было преждевременно. Поэтому я решил сформировать институт техлидов.
Но я не просто назначал человека техлидом компонента. Я максимально излагал свои ожидания и определял их путь развития (и что техлид должен делать), а также возлагал на них ответственность за ситуацию на production. Если твой компонент дуркует на production, то это не OPS’ы не спят и ты не спишь, а вы вместе не спите и пытаетесь ситуацию решить:

И так мы отправились в путь — есть техлиды, т.е. ответственные и есть 15% квота на техдолг, т.е. есть время. Но как в итоге выглядела реальность?
Первое, с чем мы столкнулись — у нас же финтех, compliance, segregation of duties, то есть у меня и разработки доступа до production нет и быть не может по определению. А при этом я говорю: «Ребята, за ситуацию на production отвечаете вы!»
Когда вы возлагаете на людей ответственность, дайте им в руки инструмент. И это первое, чем мы занялись вместе с OPS’ами — предоставление логов техлидам, чтобы они видели логи своих компонент в бою. И у нас была действительно совместная работа — наш первый шажочек к DevOps, когда эксплуатация с разработкой работают вместе. Эксплуатация настраивала передачу логов (Kibana и пр.), а разработке при этом необходимо было сделать так, чтобы в логах не было чувствительной информации (персональных данных и пр.)
Реальность такова, что несмотря на квоту 15%, в жизни в каждом спринте возникают какие-то бизнес-криты, срочные инжекты, ибо «Партнеру надо сейчас либо он уйдет!» Конечно же, в первую очередь из спринта выталкивается этот самый техдолг — в результате у нас бывали спринты с 0%. Бывали и с 15%, но в среднем на техдолг выходило всего 5-8%. Это большая проблема, потому что программист не может знать, сколько у него будет времени на реализацию.
Со своей стороны я пытался этой ситуации помочь, неустанно порхая коршуном над всеми командами. Мы научились собирать детальные метрики по каждому спринту, я смотрел в итоге факт спринта и важным для меня был триггер «взлом спринта»:

Взлом спринта — это когда квота техдолга систематически нарушается. Если в одном спринте квота не выполнена, это еще не значит, что всё плохо — действительно, бывают разные ситуации и нужно быть гибкими. Но когда это повторялось систематически, я собирал продактов, ругался и объяснял, как это важно и недопустимо, ведь в конце концов квота согласована. Это была моя повседневная работа для того, чтобы двигать процесс в той модели.
И он двигался на самом деле, но сейчас я считаю, что у такого подхода есть свои, и существенные, недостатки.

Продакты привыкли, что бэклог весь их и все задачи согласовывают они: «Квота – хорошо, но только мы решаем, что в эту квоту техдолга будет делать команда!» И когда ребята приходили с задачами (вспомните про сильную связанность) типа рефакторинга, что нужно boilerplates устранять, спагетти убирать и пр., то получали логичную реакцию: «Что?! Какой boilerplate? Причем здесь какая-то кухня-столовая? О чем речь идет?!»
В результате задачи подменялись теми, которые можно отнести к техдолгу, но которые были условно выгодны продакту. Поэтому мне пришлось занять жесткую позицию и сказать: «Техдолг — он мой! И я утверждаю, что войдет в техдолг каждой продуктовой команды в квоту техдолга на каждый спринт. А для вас он черный ящик».
Так мы и жили. Хоть нормально жилось и делалось, но недоверие росло все сильнее и сильнее: когда мы что-то делаем и никому не говорим — что, и время это не тратится на бизнес-задачи, то всем непонятно, какой результат мы приносим.

Так как статистика по использованию квоты техдолга была скачущая, конечно же, мы столкнулись с тем, что мы не можем делать большие темы. К тому же большие темы часто требуют участия нескольких команд. Это тоже было невозможно, потому что у нас каждая продуктовая команда заточена на свой продукт и живет в своих реалиях — их невозможно состыковать на сложной теме.

Кроме того, никто не включил в спринты эксплуатацию — у них нет спринтов и бэклогов как у производства. Они завалены задачами с production, но это в общие планы не включалось. И когда разработка приходила с чем-то сделанным в рамках тех небольших кусочков техдолга, чтобы раскатать на production, это могло достаточно долго мариноваться в заявках у OPS’ов. Потому что ребятам реально было некогда, а их грузят левыми задачами, дергают и мешают работать.
Но несмотря на все отрицательные стороны такого подхода, нам достаточно многого удалось добиться:

Существенно перелопатив весь CI процесс, мы сделали его цивилизованным, за который не стыдно. На графике видно, как сократились затраты на регресс.
Сделали модуляризацию, уменьшили boilerplates и это все, что бизнесу не продаваемо вообще. Эти задачи невозможно продать бизнесу даже через страх. Если ваши технологические гэпы в продукте содержат такие проблемы, и вам их необходимо устранить (если они есть, их необходимо сделать в первую очередь), то даже не нужно пытаться это продать. Это можно делать только через модель «Техдолг — он мой», только через квоту. Я много раз видел попытки и сам пытался сделать это по-другому на первой фазе — ничего не вышло.
Правда, работа в таком режиме долго продолжаться не может. Это ограниченный карт-бланш, который вам дает руководство, доверяя вам как техническому директору и тимлиду. Если вы останетесь в модели черного ящика, ваш ждет катастрофа — конфликт, истерика, а в худших традициях корпоративных историй это может быть и снятие с должности. Короткая история с черным ящиком необходима, но с ней надо очень быстро заканчивать.
Спустя какое-то время (где-то год) я зашевелился в сторону того, что пора открываться и выходить на белый свет.
Тогда мы инициировали фазу №3 – «легитимный» проект по работе над техдолгом. Предполагалось, что мы уходим от закрытой квоты, планируемся через общий продуктовый бэклог (то есть продакты принимают, что эти проекты надо делать) и выходим на чистую продажу. Чтобы это случилось, мы делаем две вещи:
Важный момент — у нас есть определенная иллюзия в том, что мы пытаемся посчитать бизнес-value от техдолга, хотя это возможно очень редко. А если все-таки можно посчитать, значит у нас кошмарный техдолг!
Для бизнеса лучше работает позитивная ценность, чем негативная. Если сказать: «Уйдет такой-то клиент, он приносит столько-то денег» — то пока он не ушел, это не сработает. Это не бизнес-ценность. Тем более, что культура работы с рисками, особенно в России, пока еще не очень высокая, поэтому включается режим: «Пока не ушел — потери нет». А еще не обязательно показывать бизнес-value. Там, где можно показать — покажите, но можно показать технологическое value, только оно должно быть реально посчитано.
Весь workflow продажи этой фазы я представил на схеме:
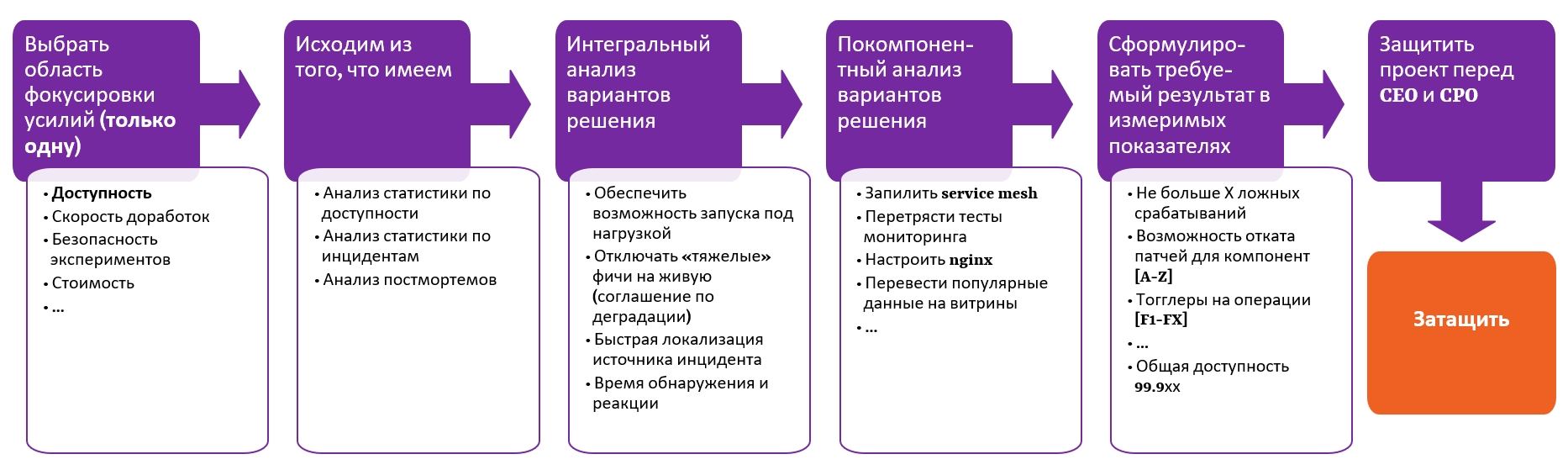
Поскольку здесь идет продажа через страх, то выбираем ту область, которая реально бомбит и аффектит ваш бизнес. Области могут быть абсолютно разными: доступность, скорость доработок, безопасность проведения А/В тестов и экспериментов, стоимость доработки — огромное количество направлений и тем.
В моем случае выбор пал на доступность, потому что она была на слуху бизнеса и оказывала определенное влияние на наш сервис. Очень важно не распыляться и выбрать только одну тему — каждая из них гигантская и по каждой можно писать диссертацию.
Я проанализировал статистику по доступности и статистику по инцидентам за год, а также провел детальный анализ всех постмортемов по всем ситуациям, которые были в течение года. После чего сформировал верхнеуровневое понимание над чем нам нужно работать максимально технически, но опять же — предметно.
Например, у нас есть ситуация, когда в случае сбоя, падения нам очень тяжело запуститься под нагрузкой. Условно говоря, мы быстрее «выжираем» очередь, чем успеваем инициировать все соединения.
Первое правило обеспечения доступности — не пытаться построить систему, которая будет всегда доступна, но быть готовыми к тому, что инцидент произошел. Это мы и должны обеспечить.
Второй вопрос и второе базовое правило школы доступности — это соглашение по деградации: что-нибудь когда-нибудь обязательно произойдет, и вы должны быть готовы сохранить ваш сервис, возможно, ценой отказа от определенной функциональности, которую вы предоставляете, — и отключив которую, вы сможете лететь дальше. Эта классическая история, которая называется соглашение по деградации. Это соглашение надо поддерживать, в том числе на программном уровне.
Третий вопрос связан с мониторингом и observability — это быстрая локализация источников инцидентов плюс время обнаружения реакции. Если у вас очень много флаппающих тестов, у вас включится режим «Мальчик — волки, волки!» и вы перестаете доверять своему мониторингу. Если в ваших тестах на production есть инструкции для service desk реакции типа: «Если через 5 минут не потух, то звони», — вы не мониторите ситуацию на production. Тест должен быть максимально однозначным: «Загорелось — значит, где-то беда, побежали!»
Для этого мы по каждому направлению, по каждому компоненту сформировали, что конкретно будем делать: куда service mesh затаскивать, как перетрясем мониторинг и на базе чего. Здесь перечислено процентов 15, а на деле там очень много программных доработок, большая хорошая тема с витринами (получение популярных данных через витрины).
Ок, мы все разложили, но само по себе это еще не продаваемо. Для того, чтобы можно было теперь выйти и в открытую это показать, за каждым проектом этой фазы мы
Мы очень боимся количественных показателей: как можно измерить качество работы разработчиков в количественных показателях? У нас очень много аргументов против количественных показателей, но не надо их воспринимать в лоб – также, как value не надо воспринимать только как бизнес-value. Их можно сформулировать, например, как «не больше Х ложных срабатываний». Вы можете перечислить конкретный набор компонент, для которых критично обеспечить канареечные релизы или возможность гарантированного отката патчей. Общая доступность, конечно же, должна быть количественным показателем — это обязательно.
С этим набором прагматичных проектов, максимально понятных метрик и результатов, к которым мы должны прийти, я пошел сдаваться: «Ребята, мне нужна квота техдолга. Мне нужно, чтобы вы эти проекты включили в ваш пул проектов, их отскорили, чтобы они шли в общем планировании на полностью законном основании вместе с бизнес-задачами».
Это было услышано, мы это сделали и это сработало. Кажется, это как в ролике о том, как нарисовать сову: «Нарисуйте овал и две черточки», и в конце — магия — получилась сова! Но вся магия в том, что вам надо запилить весь этот проект и дотащить его до конца. Не просто поделать в этом направлении какие-то вещи, а довести до конечного результата, то есть обязательно выйти на заявленные количественные показатели и их показать. Это та самая пропасть, которую нельзя перепрыгнуть на 95%. Ее надо перепрыгнуть полностью.
И так мы пошли «прыгать» (через пропасть), и в целом делаем это успешно — сейчас мы на втором витке этого проекта. То есть первый пул проектов мы затащили, согласовали второй пул проектов. Что изменилось?
Если мы затаскиваем и показываем реальные количественные показатели, то благодаря открытости мощно повышается доверие. Но правда в том, что, конечно же, продажи заходят через страх. Эту ступеньку нельзя избежать. Но и не надо этого бояться или стыдиться. Главное — не спекулируйте страхом, а реально анализируйте, как я показывал на разных фазах (интегральный анализ, покомпонентный анализ).
Благодаря тому, что это теперь узаконенные проекты, мы можем синхронизировать между командами и тащить реально длинные темы. Некоторые темы, разбитые на фазы, делались последовательно из спринта в спринт. Мы трекаемся регулярно (раз в неделю) в рамках этого проекта составом технологической команды и понимаем, кто где находится (на какой фазе). Это максимально открытая и прозрачная информация — ход проектов и текущие статусы опубликованы и доступны продактам (и всем, кто хочет посмотреть).
Самое главное — мы поняли, что нам много чего нужно переделывать и в инфраструктуре, и в процессе выкатки — и OPS’ов в явном виде включили в этот проект. В моем понимании это больше DevOps, чем Kubernetes и Docker — когда OPS’ы вместе с разработчиками обсуждают, как изменить архитектуру компонента, а разработчики обсуждают с OPS’ами, как лучше изменить инфраструктуру. Несмотря на то, что у нас Infrastructure-as-Code на базе Ansible, а в силу технологического стека Docker совсем чуть-чуть (и тот в основном используется в CI процессах, на бою его совсем мало для новых компонент), — эта спайка, эта совместная работа тоже инструмент, которым можно пользоваться и работать. С другой стороны одна она — не DevOps, так как DevOps — это именно модель работы.
Здесь мы возвращаемся к тому, о чем я говорил в конце фазы 2: раньше бы это не сработало. Потому что то, что мы затащили на фазе 2 — тот спагетти-код, который мы перепахали, то наращивание мышечной массы тестов и перелопачивание CI-процессов — было бы невозможно продать бизнесу в терминах измеримых показателей. Та ситуация не маппировалась ни с одним конкретным страхом, а наш стандартный аргумент: «Мы долго пилим, потому что спагетти-код» — никто из бизнеса не слушает: «Да программисты всегда ноют!» Поэтому ту историю мы бы не смогли затащить через этот подход.
С моей точки зрения, если у вас технологическая платформа требует таких глубинных инфраструктурных переработок, то фазы 2 — режима черного ящика — вам не избежать. Нужно на него идти, но быть готовым не только постоянно порхать как коршун, но и свернуть эту лавочку достаточно быстро, чтобы не потерять доверие вашего бизнеса.
Что меня беспокоит теперь? У нас второй виток на третьей фазе, и я считаю, что ее пора заканчивать — подход этой фазы после второго витка себя исчерпает, и нужно искать что-то новое, какой-то другой подход.
Почему? Потому что сейчас я наблюдаю:
В реальной жизни этот цикл нам придется повторять постоянно, потому что потом снова возникает гарь. Мы все делаем что-то совершенно непонятное для бизнеса, и это нормально 3 это наша с вами инженерная гордость, что мы такие непонятные и сложные. Но поэтому это требует такой огромной работы:

Чем я хочу завершить мое выступление:
Можно спросить, а причем здесь техдолг, если конференция DevOps? Холиварить об этом можно, например, в рамках DevOps-фуршета, но настолько ли это широкое понятие? Мы узнали, что Артем относит к техдолгу все изменения и доработки, инфраструктурные модификации и изменения процессов, изменения структур команд, направленные на устранение гэпов — которые были допущены (осознанно или нет) в рамках запуска продуктов и фич, и которые со временем сильно мешать жить.
А так как такие вещи невозможно исправить без твердой и уверенной спайки производственного и операционного цехов, то и получается, что эта история напрямую — про DevOps.
Да как я посмел?
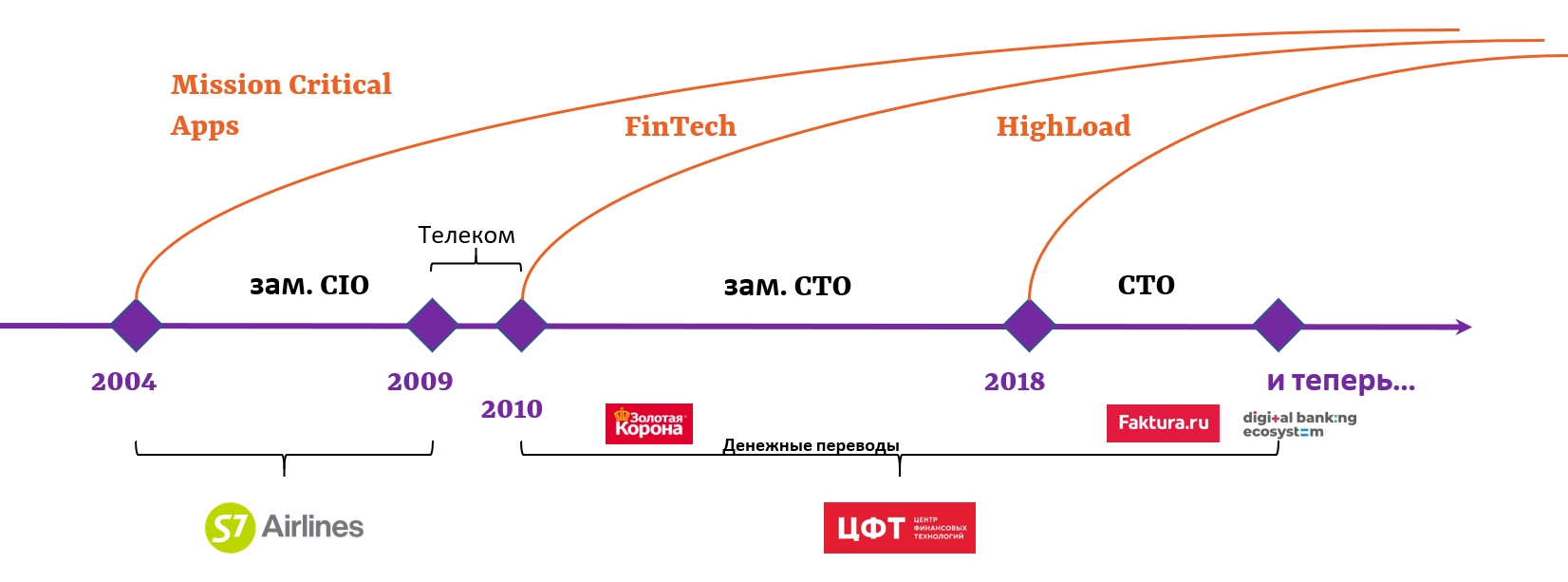
Почему я про это говорю, какое у меня право? Дело в том, что с operations, production и техдолгом я так или иначе связан 16 лет своей жизни:
До 2004 года я работал программистом-разработчиком на Java в различных компаниях, которые занимаются заказной разработкой ПО, и со временем стал чувствовать себя, извиняюсь за метафору, «суррогатной матерью». Я рождаю какой-то продукт, отдаю его и дальше его судьба мне не ведома. Меня это очень печалило, потому что я хотел знать обратную сторону жизни продуктов — как живет на production то, что я создаю. Эту возможность я нашел в авиакомпании Сибирь (тогда S7 так называлась). Пришел я туда системным аналитиком, а уходил с позиции заместителя директора по IT. Отвечал я за внедрение программных продуктов, ввод и разворачивание новых инфраструктур на — конечно же — production.
В авиации уже в те годы степень зависимости от автоматизации была очень высокой. Это одна из передовых отраслей с этой точки зрения — по крайней мере, в нулевых годах она в этом шла впереди планеты всей. Например, в 2006 году по всему миру отменили печатные билеты, остались только электронные. А сама авиационная деятельность напрямую влияет на бизнес-процессы, на судьбы людей, на всю нашу жизнь. Остановка этих систем и инфраструктур приводит к тяжелым последствиям для огромного количества людей — это и задержки вылетов, и проблемы с регистрацией. Так что по ночам спать я перестал уже тогда. Я уже 16 лет по ночам сплю, вздрагивая, потому что имею отношение к обеспечению на production жизни сервисов, которым стоять никак нельзя.
Но со временем я все-таки понял, что хочу заниматься не только operations, то есть не только вопросами эксплуатации, но разработка мне тоже близка. Мне захотелось заниматься всем производственным циклом, что я и нашел в компании Центр Финансовых Технологий — в рамках тех сервисов, где я сейчас работаю, мы обеспечиваем полный производственный цикл: от идеи до production (включая сам production), обеспечение и доступность.
Здесь, правда, спать стало еще тяжелее, потому что это финтех. Здесь не то, что простой, а задержки со скоростью проведения платежей уже вызывают праведный гнев у клиентов. О потере, порче или неконсистентности данных говорить вообще нельзя — это недопустимо в принципе с финансовой информацией и персональными данными (как и в авиакомпаниях, конечно).
С 2018 года я стал техническим директором сервиса Faktura.ru — это интернет-банк для физических и юридических лиц. И ко всему прочему в моем багаже добавился еще и фактор highload, то есть 10000+ tps, внезапные наплывы пользователей и совершенно безумная, непонятно с чем связанная, активность пользователей на production. Это теперь моя реальная жизнь — я отвечаю как за производство, так и за эксплуатацию.
И на всём своём пути я всегда боролся за качество продукта, потому что я все-таки люблю спать по ночам. Я боролся за то, чтобы уделялись время и усилия повышению качества продукта и устранению технологических гэпов, которые так или иначе неизбежно закладываются на проектных этапах.
И я хочу поделиться этим опытом, моей рефлексией и теми выводами, к которым я пришел спустя долгие 16 лет, особенно на базе последних 3 лет, что я работаю в Faktura.ru. Здесь мне удалось реализовать интересную комбинацию, так сказать — каскад подходов, и у меня окончательно сформировалась мысль, как же делать техдолг. И эта каскадная структура — та фишка, про которую я хочу вам рассказать.
Техдолг — он чей?
Но для начала — корень проблемы — почему мы вообще говорим о техдолге? Потому что нам очень обидно, что бизнес не выделяет на это время. Это просто красной нитью проходит через все доклады, митапы, коммуникации разработчиков и эксплуатации — злой, плохой, страшный бизнес не выделяет время на работу с техдолгом. Возникает даже праведный вопрос: «Им вообще что ли качество не нужно?!» Забегая вперед, скажу: «Качество никому не нужно», но эту мысль раскрою чуть позже, пусть она вас пока побомбит.
Для анализа этой ситуации давайте задумаемся — почему же так бизнес с нами поступает? И для получения ответа надо задуматься над тем, а вообще техдолг — это чья головная боль? Он чей?
Спустя годы участия в этом всем, я понимаю, что мы как Фродо, который всем предлагал кольцо — помогите мне нести эту ношу! Мы ждем, что бизнес захочет (именно захочет), чтобы мы занялись техдолгом. Но корневая причина нашего взаимонепонимания с бизнесом в том, что он никогда не захочет. Для нас это — инженерно интересная задача, способ повысить совершенство продукта или даже механизм повышения гордости за наш продукт. А для бизнеса это всегда помеха, неизбежное зло (или необходимость), на которое приходится тратить время.
Представьте, вы сели в такси, а таксист такой: «Я заскочу на автомоечку?»
Вы в этой ситуации — бизнес, а таксист — мы, разработчики. Вы возмущаетесь: «Как же так?! Я деньги плачу за время в пути, а ты поедешь на автомойку!» На что таксист резонно отвечает:
— Вы что, не хотите ехать в чистой машине, в которой хорошо пахнет?
— Блин, конечно, хочу! Но я жду этого по умолчанию и не готов ради этого заезжать на автомойку сейчас!
Так нас воспринимает бизнес с техдолгом — как предложение заехать на автомойку. Чтобы у меня был чистый салон или салон лакшери, я выбираю соответствующую категорию при заказе такси. На этапе заказа я готов в это вложиться, а вот заезжать на автомойку — нет. Потому что, как я уже сказал ранее, качество не нужно никому. Но его ждут по умолчанию.
Это данность, и нужно исходить из этого. Смиряться и не заезжать на автомойку нельзя, заезжать туда за счет своего личного времени — выгорим. Что же делать? Бизнес — это локомотив, ему нужны фичи, продажи и клиенты. Продать бизнесу техдолг через наши «хочу» и «желаю» — невозможно. Но можно замотивировать бизнес другим путем.
В процессе своего путешествия я сформировал три категории мотивации бизнеса к «покупке» техдолга:
- «Жирное» безразличие. Когда есть богатый инвестор, SEO может себе позволить своей команде разработчиков этих странных гиков (парней, девчат), которым нравятся какие-то их штуки: «Ну, пусть делают! Главное, чтобы продукт сделали и чтобы командный дух был ого-го, чтобы всё было круто и мы были бы лучшим офисом в мире». Это классная вольница, которая, с моей точки зрения, нередко приводит к катастрофе, потому что техдолг требует прагматичности. Когда мы делаем это не прагматично, то создаем Левиафана псевдо-крутой архитектуры.
- Страх. Это одна из самых эффективных, распространённых и действенных моделей «продажи» техдолга. О каком «хочу» здесь может идти речь, когда страшно? Это о том, когда жареный петух клюнул — когда что-то случилось, клиент из-за сбоя ушел, захейтили на сторах, — и это все из-за низкого качества, тормозов или чего-то еще. Но тупо продавать через страх тоже плохо — спекуляция страхом работает против доверия. Продавать нужно аккуратно и максимально честно — не пытаться под ситуацию подтянуть желаемые проекты, а выбирать те, которыми действительно необходимо заняться. И постепенно идти к формированию следующей мотивации.
- Доверие — это когда бизнес выделяет вам столько времени, сколько вам нужно на работу с техдолгом. Да, радуга, единороги, какая прекрасная жизнь! Правда, доверие работает и сохраняется только тогда, когда вы скрупулёзно мало относительно общей доли и максимально прагматично берете это самое время. Иначе доверие разрушается. Более того, оно не накапливается. Это постоянный процесс, который идет волнами: доверие то увеличивается, то затухает. Поэтому невозможно выйти на плато доверия, чтобы расслабиться. Нет, это постоянная работа наша с вами — как минимум, тимлидов и CTO.
А дальше я расскажу о своем опыте, что с этим делаю я, и что получается у меня и моей замечательной команды.
Как глубока кроличья нора?
Когда я пришел в сервис 3 года назад, мне нужно было понять, как глубока кроличья нора, то есть как много этого самого техдолга. Что он есть, я знал по статистике запросов, в том числе, от бизнеса и партнеров. Мне нужно было разобраться, с чем я имею дело вообще. Это нормальный и обязательный первый шаг процесса работы с техдолгом — не надо бросаться делать первое обнаруженное, нужно проанализировать ситуацию в целом.
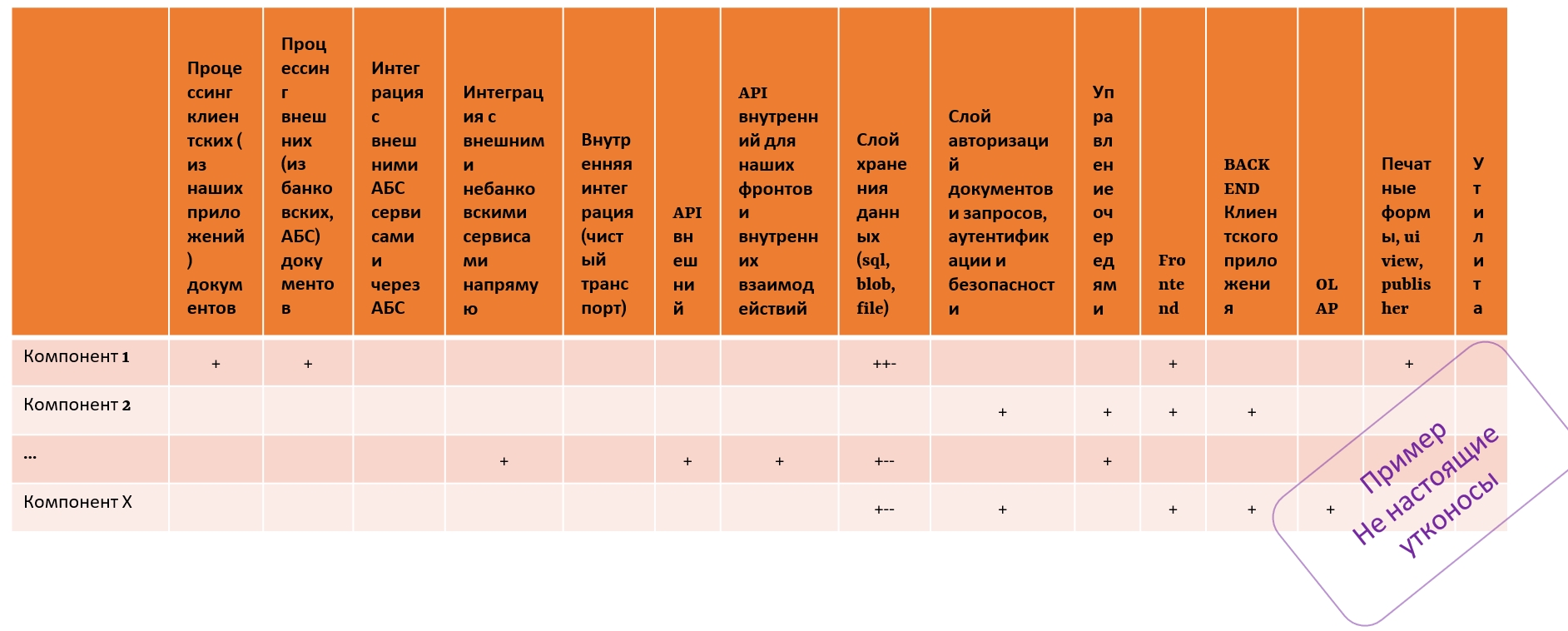
Исходя из того, что я увидел тогда, у меня появилось предположение, что одна из корневых проблем — это большая связанность кода, то есть очень сильный coupling. Сейчас я вовлекаю всех в этот процесс уже меньше, но тогда я собрал всю команду производства, чтобы зафиксировать, какие слои мы хотим выделить в нашем комплексе приложений.
В нашем приложении было не меньше 80 различных компонент (дистрибутивов, не инсталляций). И, разложив их по слоям (чтобы понять, где мы нарушаем принципы изоляции, роли и пр.), мы совместно построили такую картину:
Увидев ее, я понял, что мои предположения были верны — у нас действительно достаточно сильный coupling. Этот способ также хорош, чтобы взглянуть на свою систему в целом с точки зрения ее общей организации, так как просто сказать, что у нас есть бэкенд, фронтенд и хранение — это ещё не онтология, а тот самый прямой путь к сильному связыванию. А здесь ds можете увидеть слои, что позволит сформировать некую онтологию платформы.
После того, как мы выяснили ситуацию, с ней надо было как-то бороться.
Фаза №1. «Виртуальные команды»
Я, такой умный, придумал, что сделаю вид, что у всех есть время, и сформировал вокруг каждого компонента «виртуальную команду»: «Ребята, кто за какой компонент возьмется? Сформируйте свои предложения, как его улучшать». Но чтобы не расползаться мыслью по древу и быть в фокусе, мы все вместе сформулировали критерии оптимизации первой фазы:
- Слабая связанность;
- Разумная по затратам масштабируемость;
- Простое подключение новых разработчиков (простые и понятные принципы: что именно можно делать в этом компоненте, а что нельзя, плюс изоляция кода, который нельзя «трогать» всем);
- Возможность «выставления» внешнего api там, где это нужно;
- Доступность предлагаемого технологического стека;
- QuickWin-оптимизации в текущих решениях;
- Простота мониторинга и траблшутинга;
- Аудит + принципы лицензионной чистоты;
- Принципы версионирования и устаревания.
Конечно, это был не фокус, а набор критериев практически для всех аспектов разработки ПО. Весь список можно заменить одной фразой: «Исправить всё». Эта фаза закончилась фейлом, в том смысле, что просто ничего не случилось. Мы очень мало продвинулись в реализации каких-то вещей, потому что я пытался их планировать через общий бэклог. Задачи были мутные и непонятные, на нашем с вами языке, который продакт вообще не хотел понимать. В работу они ставились вручную — если я, как техдир, пришел на планирование, то вставил какую-то штуку в бэклог, а нет — так нет. И я быстро понял, что это тяжело и мне, и команде, плюс постоянно растут конфликты и споры.
Тогда я перешел ко второй фазе.
Фаза №2. «Техдолг — он мой»
Первым шагом я договорился с CEO нашего сервиса о том, что мы введем квотирование бэклога: на бизнес-фичи тратим 70%, на устранение дефектов — 15%, и 15% — на тот самый техдолг.
Во-вторых, на предыдущей фазе я понял, что если за вопрос отвечают все, то за этот вопрос не отвечает никто. Это вообще не бирюзовое утверждение, оно самому мне не нравится, но обратное требует очень высокого уровня зрелости и сработанности команды, а в тех условиях конфликтов, которые тогда у нас шли, говорить об этом было преждевременно. Поэтому я решил сформировать институт техлидов.
Но я не просто назначал человека техлидом компонента. Я максимально излагал свои ожидания и определял их путь развития (и что техлид должен делать), а также возлагал на них ответственность за ситуацию на production. Если твой компонент дуркует на production, то это не OPS’ы не спят и ты не спишь, а вы вместе не спите и пытаетесь ситуацию решить:
И так мы отправились в путь — есть техлиды, т.е. ответственные и есть 15% квота на техдолг, т.е. есть время. Но как в итоге выглядела реальность?
Первое, с чем мы столкнулись — у нас же финтех, compliance, segregation of duties, то есть у меня и разработки доступа до production нет и быть не может по определению. А при этом я говорю: «Ребята, за ситуацию на production отвечаете вы!»
Дайте людям логи!
Когда вы возлагаете на людей ответственность, дайте им в руки инструмент. И это первое, чем мы занялись вместе с OPS’ами — предоставление логов техлидам, чтобы они видели логи своих компонент в бою. И у нас была действительно совместная работа — наш первый шажочек к DevOps, когда эксплуатация с разработкой работают вместе. Эксплуатация настраивала передачу логов (Kibana и пр.), а разработке при этом необходимо было сделать так, чтобы в логах не было чувствительной информации (персональных данных и пр.)
5% — уже, считай, повезло…
Реальность такова, что несмотря на квоту 15%, в жизни в каждом спринте возникают какие-то бизнес-криты, срочные инжекты, ибо «Партнеру надо сейчас либо он уйдет!» Конечно же, в первую очередь из спринта выталкивается этот самый техдолг — в результате у нас бывали спринты с 0%. Бывали и с 15%, но в среднем на техдолг выходило всего 5-8%. Это большая проблема, потому что программист не может знать, сколько у него будет времени на реализацию.
Со своей стороны я пытался этой ситуации помочь, неустанно порхая коршуном над всеми командами. Мы научились собирать детальные метрики по каждому спринту, я смотрел в итоге факт спринта и важным для меня был триггер «взлом спринта»:
Взлом спринта — это когда квота техдолга систематически нарушается. Если в одном спринте квота не выполнена, это еще не значит, что всё плохо — действительно, бывают разные ситуации и нужно быть гибкими. Но когда это повторялось систематически, я собирал продактов, ругался и объяснял, как это важно и недопустимо, ведь в конце концов квота согласована. Это была моя повседневная работа для того, чтобы двигать процесс в той модели.
И он двигался на самом деле, но сейчас я считаю, что у такого подхода есть свои, и существенные, недостатки.
Ограничения подхода
Продакты привыкли, что бэклог весь их и все задачи согласовывают они: «Квота – хорошо, но только мы решаем, что в эту квоту техдолга будет делать команда!» И когда ребята приходили с задачами (вспомните про сильную связанность) типа рефакторинга, что нужно boilerplates устранять, спагетти убирать и пр., то получали логичную реакцию: «Что?! Какой boilerplate? Причем здесь какая-то кухня-столовая? О чем речь идет?!»
В результате задачи подменялись теми, которые можно отнести к техдолгу, но которые были условно выгодны продакту. Поэтому мне пришлось занять жесткую позицию и сказать: «Техдолг — он мой! И я утверждаю, что войдет в техдолг каждой продуктовой команды в квоту техдолга на каждый спринт. А для вас он черный ящик».
Так мы и жили. Хоть нормально жилось и делалось, но недоверие росло все сильнее и сильнее: когда мы что-то делаем и никому не говорим — что, и время это не тратится на бизнес-задачи, то всем непонятно, какой результат мы приносим.
Так как статистика по использованию квоты техдолга была скачущая, конечно же, мы столкнулись с тем, что мы не можем делать большие темы. К тому же большие темы часто требуют участия нескольких команд. Это тоже было невозможно, потому что у нас каждая продуктовая команда заточена на свой продукт и живет в своих реалиях — их невозможно состыковать на сложной теме.
Кроме того, никто не включил в спринты эксплуатацию — у них нет спринтов и бэклогов как у производства. Они завалены задачами с production, но это в общие планы не включалось. И когда разработка приходила с чем-то сделанным в рамках тех небольших кусочков техдолга, чтобы раскатать на production, это могло достаточно долго мариноваться в заявках у OPS’ов. Потому что ребятам реально было некогда, а их грузят левыми задачами, дергают и мешают работать.
Но несмотря на все отрицательные стороны такого подхода, нам достаточно многого удалось добиться:
Чего мы достигли
Нарастили мышечную массу автотестов
Существенно перелопатив весь CI процесс, мы сделали его цивилизованным, за который не стыдно. На графике видно, как сократились затраты на регресс.
Успешно реализовали во многих компонентах борьбу со спагетти-кодом
Сделали модуляризацию, уменьшили boilerplates и это все, что бизнесу не продаваемо вообще. Эти задачи невозможно продать бизнесу даже через страх. Если ваши технологические гэпы в продукте содержат такие проблемы, и вам их необходимо устранить (если они есть, их необходимо сделать в первую очередь), то даже не нужно пытаться это продать. Это можно делать только через модель «Техдолг — он мой», только через квоту. Я много раз видел попытки и сам пытался сделать это по-другому на первой фазе — ничего не вышло.
Правда, работа в таком режиме долго продолжаться не может. Это ограниченный карт-бланш, который вам дает руководство, доверяя вам как техническому директору и тимлиду. Если вы останетесь в модели черного ящика, ваш ждет катастрофа — конфликт, истерика, а в худших традициях корпоративных историй это может быть и снятие с должности. Короткая история с черным ящиком необходима, но с ней надо очень быстро заканчивать.
Спустя какое-то время (где-то год) я зашевелился в сторону того, что пора открываться и выходить на белый свет.
Фаза №3. «Легитимный» проект
Тогда мы инициировали фазу №3 – «легитимный» проект по работе над техдолгом. Предполагалось, что мы уходим от закрытой квоты, планируемся через общий продуктовый бэклог (то есть продакты принимают, что эти проекты надо делать) и выходим на чистую продажу. Чтобы это случилось, мы делаем две вещи:
- Я максимально сузил скоуп работ, которые мы начали делать в рамках этого проекта;
- Сформировал конкретные предметные ожидания относительно того, за что мы будем биться на production. Это был полный отказ от идеализма, потому что наши задачи должны быть реально максимально прагматичными, понятными и полезными сервису с точки зрения бизнеса.
Важный момент — у нас есть определенная иллюзия в том, что мы пытаемся посчитать бизнес-value от техдолга, хотя это возможно очень редко. А если все-таки можно посчитать, значит у нас кошмарный техдолг!
Для бизнеса лучше работает позитивная ценность, чем негативная. Если сказать: «Уйдет такой-то клиент, он приносит столько-то денег» — то пока он не ушел, это не сработает. Это не бизнес-ценность. Тем более, что культура работы с рисками, особенно в России, пока еще не очень высокая, поэтому включается режим: «Пока не ушел — потери нет». А еще не обязательно показывать бизнес-value. Там, где можно показать — покажите, но можно показать технологическое value, только оно должно быть реально посчитано.
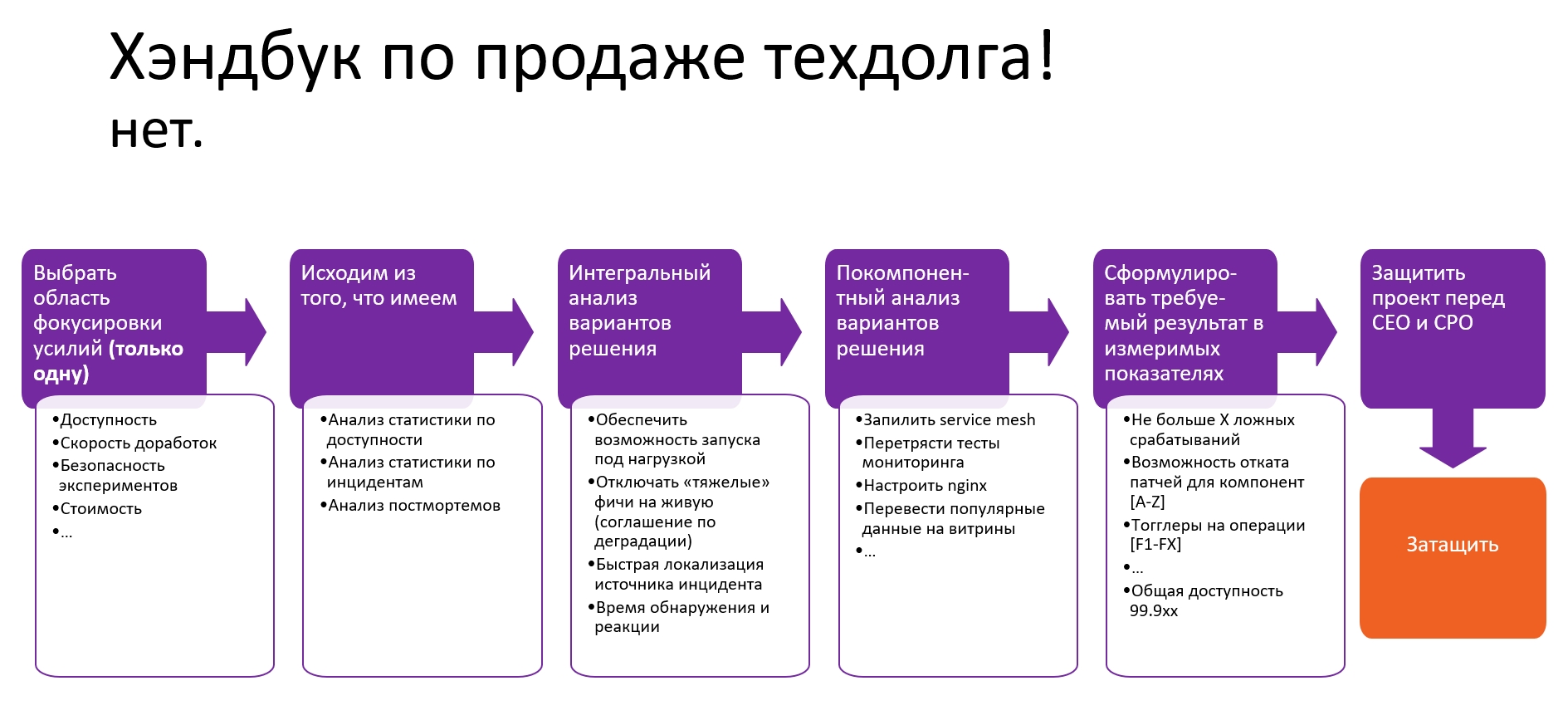
Хэндбук по продаже техдолга!
Весь workflow продажи этой фазы я представил на схеме:
Выбираем область фокусировки усилий (только одну)
Поскольку здесь идет продажа через страх, то выбираем ту область, которая реально бомбит и аффектит ваш бизнес. Области могут быть абсолютно разными: доступность, скорость доработок, безопасность проведения А/В тестов и экспериментов, стоимость доработки — огромное количество направлений и тем.
В моем случае выбор пал на доступность, потому что она была на слуху бизнеса и оказывала определенное влияние на наш сервис. Очень важно не распыляться и выбрать только одну тему — каждая из них гигантская и по каждой можно писать диссертацию.
Делаем интегральный анализ – как глубока кроличья нора
Я проанализировал статистику по доступности и статистику по инцидентам за год, а также провел детальный анализ всех постмортемов по всем ситуациям, которые были в течение года. После чего сформировал верхнеуровневое понимание над чем нам нужно работать максимально технически, но опять же — предметно.
Например, у нас есть ситуация, когда в случае сбоя, падения нам очень тяжело запуститься под нагрузкой. Условно говоря, мы быстрее «выжираем» очередь, чем успеваем инициировать все соединения.
Первое правило обеспечения доступности — не пытаться построить систему, которая будет всегда доступна, но быть готовыми к тому, что инцидент произошел. Это мы и должны обеспечить.
Второй вопрос и второе базовое правило школы доступности — это соглашение по деградации: что-нибудь когда-нибудь обязательно произойдет, и вы должны быть готовы сохранить ваш сервис, возможно, ценой отказа от определенной функциональности, которую вы предоставляете, — и отключив которую, вы сможете лететь дальше. Эта классическая история, которая называется соглашение по деградации. Это соглашение надо поддерживать, в том числе на программном уровне.
Третий вопрос связан с мониторингом и observability — это быстрая локализация источников инцидентов плюс время обнаружения реакции. Если у вас очень много флаппающих тестов, у вас включится режим «Мальчик — волки, волки!» и вы перестаете доверять своему мониторингу. Если в ваших тестах на production есть инструкции для service desk реакции типа: «Если через 5 минут не потух, то звони», — вы не мониторите ситуацию на production. Тест должен быть максимально однозначным: «Загорелось — значит, где-то беда, побежали!»
Раскладываем на компонентный анализ
Для этого мы по каждому направлению, по каждому компоненту сформировали, что конкретно будем делать: куда service mesh затаскивать, как перетрясем мониторинг и на базе чего. Здесь перечислено процентов 15, а на деле там очень много программных доработок, большая хорошая тема с витринами (получение популярных данных через витрины).
Ок, мы все разложили, но само по себе это еще не продаваемо. Для того, чтобы можно было теперь выйти и в открытую это показать, за каждым проектом этой фазы мы
Формулируем предметные, количественные показатели
Мы очень боимся количественных показателей: как можно измерить качество работы разработчиков в количественных показателях? У нас очень много аргументов против количественных показателей, но не надо их воспринимать в лоб – также, как value не надо воспринимать только как бизнес-value. Их можно сформулировать, например, как «не больше Х ложных срабатываний». Вы можете перечислить конкретный набор компонент, для которых критично обеспечить канареечные релизы или возможность гарантированного отката патчей. Общая доступность, конечно же, должна быть количественным показателем — это обязательно.
Защищаем проекты
С этим набором прагматичных проектов, максимально понятных метрик и результатов, к которым мы должны прийти, я пошел сдаваться: «Ребята, мне нужна квота техдолга. Мне нужно, чтобы вы эти проекты включили в ваш пул проектов, их отскорили, чтобы они шли в общем планировании на полностью законном основании вместе с бизнес-задачами».
Это было услышано, мы это сделали и это сработало. Кажется, это как в ролике о том, как нарисовать сову: «Нарисуйте овал и две черточки», и в конце — магия — получилась сова! Но вся магия в том, что вам надо запилить весь этот проект и дотащить его до конца. Не просто поделать в этом направлении какие-то вещи, а довести до конечного результата, то есть обязательно выйти на заявленные количественные показатели и их показать. Это та самая пропасть, которую нельзя перепрыгнуть на 95%. Ее надо перепрыгнуть полностью.
Преимущества подхода
И так мы пошли «прыгать» (через пропасть), и в целом делаем это успешно — сейчас мы на втором витке этого проекта. То есть первый пул проектов мы затащили, согласовали второй пул проектов. Что изменилось?
Повышаем доверие
Если мы затаскиваем и показываем реальные количественные показатели, то благодаря открытости мощно повышается доверие. Но правда в том, что, конечно же, продажи заходят через страх. Эту ступеньку нельзя избежать. Но и не надо этого бояться или стыдиться. Главное — не спекулируйте страхом, а реально анализируйте, как я показывал на разных фазах (интегральный анализ, покомпонентный анализ).
Тащим «длинные» темы
Благодаря тому, что это теперь узаконенные проекты, мы можем синхронизировать между командами и тащить реально длинные темы. Некоторые темы, разбитые на фазы, делались последовательно из спринта в спринт. Мы трекаемся регулярно (раз в неделю) в рамках этого проекта составом технологической команды и понимаем, кто где находится (на какой фазе). Это максимально открытая и прозрачная информация — ход проектов и текущие статусы опубликованы и доступны продактам (и всем, кто хочет посмотреть).
OPS’ы в проекте
Самое главное — мы поняли, что нам много чего нужно переделывать и в инфраструктуре, и в процессе выкатки — и OPS’ов в явном виде включили в этот проект. В моем понимании это больше DevOps, чем Kubernetes и Docker — когда OPS’ы вместе с разработчиками обсуждают, как изменить архитектуру компонента, а разработчики обсуждают с OPS’ами, как лучше изменить инфраструктуру. Несмотря на то, что у нас Infrastructure-as-Code на базе Ansible, а в силу технологического стека Docker совсем чуть-чуть (и тот в основном используется в CI процессах, на бою его совсем мало для новых компонент), — эта спайка, эта совместная работа тоже инструмент, которым можно пользоваться и работать. С другой стороны одна она — не DevOps, так как DevOps — это именно модель работы.
А чего же я так сразу-то не сделал?
Здесь мы возвращаемся к тому, о чем я говорил в конце фазы 2: раньше бы это не сработало. Потому что то, что мы затащили на фазе 2 — тот спагетти-код, который мы перепахали, то наращивание мышечной массы тестов и перелопачивание CI-процессов — было бы невозможно продать бизнесу в терминах измеримых показателей. Та ситуация не маппировалась ни с одним конкретным страхом, а наш стандартный аргумент: «Мы долго пилим, потому что спагетти-код» — никто из бизнеса не слушает: «Да программисты всегда ноют!» Поэтому ту историю мы бы не смогли затащить через этот подход.
С моей точки зрения, если у вас технологическая платформа требует таких глубинных инфраструктурных переработок, то фазы 2 — режима черного ящика — вам не избежать. Нужно на него идти, но быть готовым не только постоянно порхать как коршун, но и свернуть эту лавочку достаточно быстро, чтобы не потерять доверие вашего бизнеса.
Что в результате?
Доступность сервиса (август и сентябрь 2020 года) = 100%:
- Если сравнивать с ситуациями, которые были до августа и где было не 100% — время на устранение инцидентов сократилось.
- Сейчас мы не оказываемся в ситуации busy threads, когда вообще не понимаем, где что происходит и почему.
- Сейчас нам гораздо легче перезапуститься с повсеместной кластеризацией, накатить патчи, фичи и пр.
- Создана системная подложка под то, чтобы доступность была на очень высоком уровне. Хотя я, как человек, потративший на доступность 16 лет, убежден, что нельзя говорить и ждать, что инцидентов не будет. Надо быть к ним готовым, постоянно к ним адаптируясь.
Текущие вызовы
Что меня беспокоит теперь? У нас второй виток на третьей фазе, и я считаю, что ее пора заканчивать — подход этой фазы после второго витка себя исчерпает, и нужно искать что-то новое, какой-то другой подход.
Почему? Потому что сейчас я наблюдаю:
- Локальное давление на инженеров в командах со стороны продактов и бизнеса: «Делай вот так, так быстрее», чтобы создать новый технический долг.
- Этот подход при проектировании новых интеграционных межкомандных решений не обеспечивает их качество.
- Расфокусировку инжектов техдолга. Сами техлиды стали говорить: «У меня в проекте это, но сейчас важнее сделать этот техдолг». Я вижу, как мы начали этому поддаваться и терять фокус.
- Доверие… опять начинает плыть: «Непонятно, что там у «вас» в проекте делается». Несмотря на то, что всё открыто, продакты начинают это говорить — накопилась усталость, а определенные бизнес-фичи ждут своего часа. На фазу доверия нужно не только выходить, на этой фазе нужно постоянно удерживаться.
Ну и как формировать доверие?
- Подтверждение опытом (вписался => затащи!) Действительно нужно жить в режиме, что пропасть перепрыгивается только на 100%.
- Гибкость и адаптируемость (поддержка MVP, A/B, гипотез, изоляция @кода). Настаивая на качестве решения, необходимо обеспечивать гибкость, понимая, что если мы сейчас здесь «нагавнокодим», это может зааффектить весь наш модуль. Мы должны придумать, как сделать изоляцию «гавнокода» для тестировании гипотез и чего-то еще. Это наша с вами задача, никто за нас ее не сделает, и некого обвинять в том, что у нас архитектура это не позволяет. Только мы сами можем это изменить — и должны это изменить.
- Результат в измеримых показателях. Когда у нас есть прозрачные критерии того, ниже чего мы падать не можем, и того, как мы улучшаемся, и когда мы готовы двигаться, адаптируясь под бизнес-ситуацию, — мы получаем это самое доверие.
В реальной жизни этот цикл нам придется повторять постоянно, потому что потом снова возникает гарь. Мы все делаем что-то совершенно непонятное для бизнеса, и это нормально 3 это наша с вами инженерная гордость, что мы такие непонятные и сложные. Но поэтому это требует такой огромной работы:
Выводы
Чем я хочу завершить мое выступление:
- Качество действительно не нужно никому… Потому что все ожидают качество по умолчанию.
- Программист не находится на галерах, никто его не казнит и никто ему ничего физически плохого не сделает. Депремирование практически нигде не практикуется — я ни разу не работал в компании, где оно было. Но что вынуждает программиста написать плохой код? Он сам решает это сделать. Вынуждает его внутреннее состояние: «Раз вы мне не даете времени написать хорошо, то я напишу прямо г… о!» Но когда времени мало, можно написать чуть хуже, но, тем не менее, хороший и качественный код. Соответствующие критерии помогут это сделать. А они зависят уже от нас, это наша с вами ответственность.
- Как бы мы не воспринимали то, что бизнес не выделяет время на техдолг, это не является никаким оправданием тому, чтобы с ним не работать. Устранять техдолг и обеспечивать качество продукта нужно пытаться постоянно, несмотря ни на что — это наша прямая обязанность, наша с вами прямая работа, как минимум, техдиректоров, техдлидов и людей, которые за это отвечают.
28 января в 19:00 Мск ждём вас на совместный онлайн-митап Онтико и Deutsche Telekom IT Solutions: DevOps Life Cycle. Участие бесплатное, необходима регистрация
Спикеры — инженеры и технические менеджеры Deutsche Telekom IT Solutions:
- Лев Гончаров – Lead Expert Software Engineer
- Константин Григель – Lead Configuration Manager Expert
- Владимир Муравьев – Lead Configuration Manager
Вы узнаете, как в Deutsche Telekom IT Solutions находят узкие места, используют метрики, ищут пути решения для разных кейсов и готовят IAC. Мы поговорим о жизненных циклах создания продукта и обсудим проблемы, возникающие на разных итерациях жизненных циклов, pipelines и workflows и подходы к их решению.
А на DevOpsConf 2021 продолжается прием заявок на доклады. Конференция пройдет 20 и 21 мая в Radisson Slavyanskaya.
Мы ждем ваши заявки!



