
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
InfiniBox – модерновая система хранения, сразу попавшая в правую часть магического квадрата. В чем ее уникальность?
Краткая предыстория
Что такое InfiniBox? Это система хранения компании Infinidat. Что такое компания Infinidat? Это компания, созданная Моше Янаем (создатель Symmetrix и XIV) для реализации проекта идеальной СХД Enterprise-уровня.
Компания создана как разработчик ПО, которое ставится на проверенное оборудование, то есть это SDS, но поставляется как единый монолитный комплект.
Введение
В этой статье мы рассмотрим систему хранения InfiniBox, ее архитектуру, как она работает и как достигается высокая надежность (99,99999%), производительность, емкость при сравнительно невысокой цене. Поскольку основа системы хранения — это ее ПО, а для этой системы в особенности, то основной упор будет именно на софте, красивых фото железок не будет.
Зачем нужна еще одна система хранения на рынке?
Есть ряд задач, для которых нужна очень большая емкость, при этом надежность и производительность тоже важны. Например, облачные системы, стандартные задачи крупных компаний, интернет вещей, генные исследования, системы безопасности для больших структур. Оптимальную СХД для таких задач найти достаточно сложно, особенно если смотреть на цену. С прицелом на такие задачи и была построена программная архитектура InfiniBox.
Адресация
Каким образом можно хранить неограниченные объемы данных? Путем предоставления неограниченного адресного пространства. Для этого в InfiniBox используется VUA — Virtual User Address space (виртуальное пользовательское адресное пространство). Все созданные на InfiniBox объекты, доступные пользователю (тома, снимки, файловые системы), входят в это VUA, и общий размер этих объектов и составляет текущий размер VUA. Адресация тонкая и не связана с дисками: то есть размер VUA может быть гораздо больше доступной дисковой емкости и фактически никак не ограничен.

Далее нам нужно разделить это пространство на части, которые мы будем обслуживать, — так с ними проще работать.
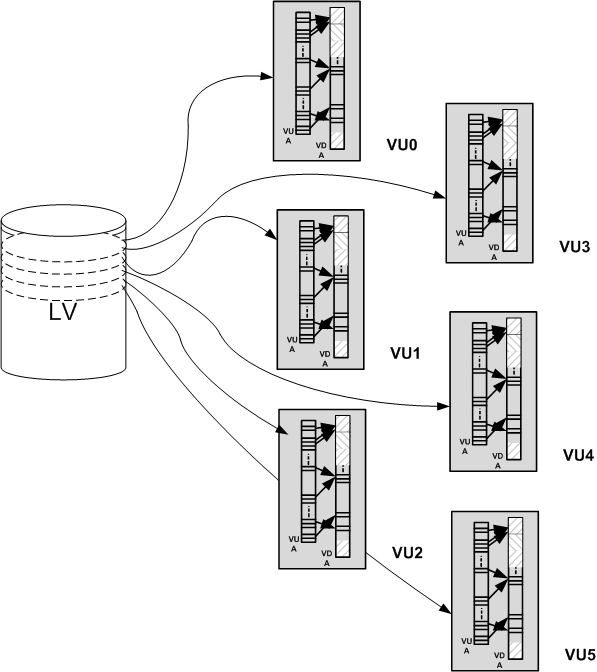
Все адресное пространство разбивается на 6 частей — VU (virtual unit — виртуальный кусок). Адресное пространство каждого объекта, например, тома, равномерно распределяется между этими частями. Запись идет блоками по 64кБ, и в процессе работы можно невероятно просто и быстро понять, какому VU принадлежит данный адрес тома (остаток от деления LBA/64кБ, функция modulo, делается очень быстро за минимальное число циклов ЦПУ).
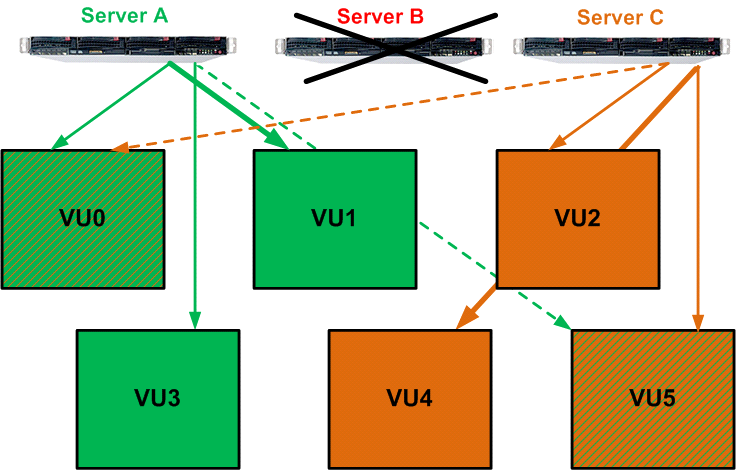
Кроме упрощения работы с пространствами меньшего размера, VU являются первым уровнем абстрагирования от физических дисков и основой для отказоустойчивости системы на уровне контроллеров. Например, есть 3 контроллера (физических сервера), каждый из которых отвечает за работу и является основным для двух VU, а также резервным для двух других VU. Контроллер не обслуживает тот VU, для которого он является резервом, но при этом получает от другого контроллера метаданные и операции записи для данного VU, чтобы в случае сбоя основного контроллера сразу подхватить всю работу с этим VU.

В случае выхода из строя одного контроллера два других берут на себя его задачу — работу с его VU.
Адресация, моментальные снимки, кэширование
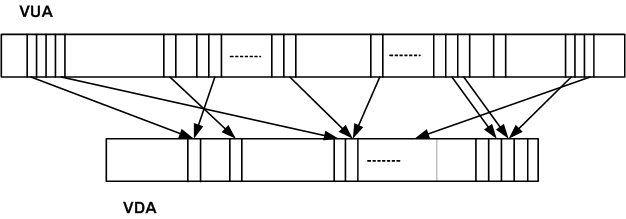
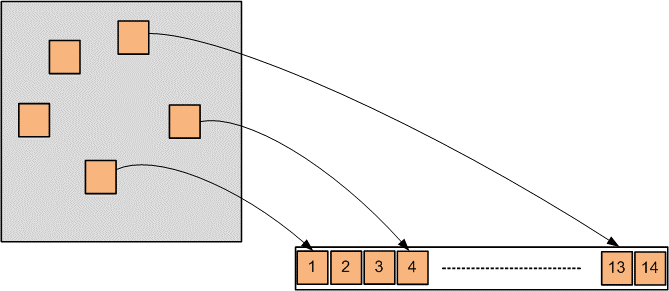
VUA — это виртуальное адресное пространство, доступное пользователю и фактически не ограниченное. VDA (Virtual Disk Address) — это виртуальное внутреннее пространство для хранения данных. Его размер заранее строго определен количеством и емкостью жестких дисков (за вычетом четности, метаданных и пространства для замены вышедших из строя дисков). Связь между VUA и VDA организована через trie (префиксное дерево). Каждая запись в дереве — это указатель из пользовательского пространства (VUA) на внутреннее пространство (VDA). Адресация в виде префиксного дерева позволяет адресовать блоки любого размера. То есть, когда на диски складывается элемент любого размера (файл, последовательный поток данных, объект), он может адресоваться одной записью в дереве и дерево остается компактным.
Однако наиболее важной особенностью дерева является высокая производительность при поиске и расширении дерева. Поиск выполняется при операции чтения, когда необходимо найти блок с заданным адресом на диске. Расширение дерева происходит при операции записи, когда мы складываем новые данные на диск и должны добавить к дереву адрес, где их можно найти. Производительность крайне важна при работе с большими структурами, и префиксное дерево позволяет ее достичь с огромным запасом на будущее, например, на случай увеличения объема дисков.
Что можно сказать про связь VUA и VDA:
Таким образом, организация VUA и VDA, связи между ними и адресация этих связей позволяют реализовать очень быстрые снимки и thin provisioning. Поскольку создание моментального снимка — это просто обновление метаданных в памяти и является постоянно происходящей операцией при работе, то фактически эта операция не занимает никакого времени. Как правило, при создании снимков классические системы хранения прекращают обновление метаданных и/или ввод-вывод для того, чтобы гарантировать целостность транзакций. Это ведет к неравномерности задержек операций ввода-вывода. Рассматриваемая система работает иначе: ничего не останавливается, а для определения попадания операции в снимок используется timestamp из метаданных блока (64+4КБ). Таким образом, система может делать сотни тысяч снимков, не замедляя работы, и производительность тома с сотнями снимков и тома без снимков никак не отличается. Поскольку все делается в памяти и это штатные процессы, то на группы томов можно делать десятки снимков в секунду. Это позволяет реализовать асинхронную репликацию на мгновенных снимках с разницей между копиями в секунды и даже меньше и без влияния на производительность, что тоже немаловажно.
Посмотрим на систему в целом, как идут данные. Операции поступают через порты всех трех контроллеров (servers). Драйвера портов работают в User space, что позволяет просто перезапускать их, если какая-либо комбинация событий на портах подвесит драйвера. В классических же реализациях это делается в ядре и проблема решается перезапуском контроллера целиком.
Далее поток разбивается на секции по 64КБ+4КБ. Что такое эти дополнительные 4КБ? Это защита от «тихих ошибок» (silent errors), и там записаны контрольные суммы, время и дополнительная информация об операции, которая используется для классифицирования этой операции и применяется для оптимизации кэширования и упреждающего чтения.

Кэширование записи – довольно простая вещь, чего нельзя сказать про чтение. Кэширование чтения хорошо работает, если мы знаем, что надо считывать. В классических системах используются алгоритмы упредительного чтения при последовательном доступе. Но что делать при произвольном? Полностью произвольный доступ крайне редко встречается в работе реальных приложений, даже эмулировать правильно его достаточно сложно, написание генератора реально случайных чисел — довольно интересная задача. Но если рассматривать каждую операцию ввода-вывода отдельно, как делается в классических системах, то все они являются произвольными и непредсказуемыми, кроме полностью последовательных. Однако если смотреть на весь поток ввода-вывода некоторое время, то можно увидеть закономерности, объединяющие разные операции.
Кэш системы принципиально не знает ничего о томах, файлах, о любой логической структуре, построенной на VUA. Кэш смотрит только на секции и на их метаданные, основывая кэширование на их поведении и атрибутах, что позволяет находить зависимости между разными приложениями, которые в реальности связаны. Для операций ввода-вывода строятся вектора активности.
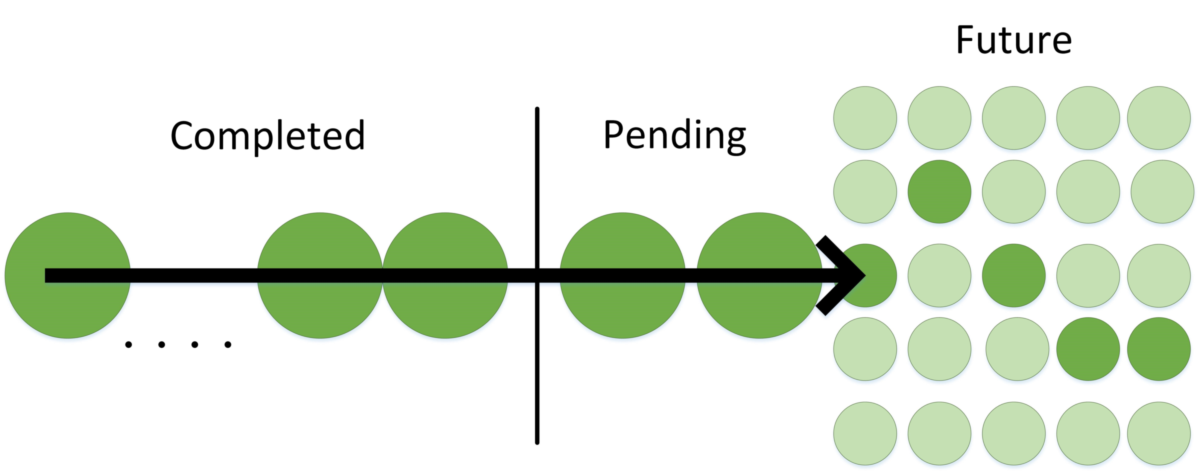
Система накапливает статистику, строит эти вектора активности, затем пытается идентифицировать текущий ввод-вывод и привязать его к известным векторам или построить новый. После идентификации происходит упредительное чтение согласно вектору, то есть предсказывается поведение приложений, и делается упредительное чтение для вроде бы произвольной нагрузки.
Запись на диски
14 секций собираются в страйп для сброса на диски. Это делается специальным процессом, который подбирает секции для такого страйпа.
Далее считаются две секции четности — страйп готов к записи на диски. Четность считается через несколько операций на основе XOR, что в два раза быстрее, чем на базе кода Рид-Соломона. Дальше страйп (14+2 секции) присваивается RAID группе (RG). RAID-группа – это просто объект для хранения нескольких страйпов, не более того. Страйпы собираются в группу, как показано ниже, один над другим, и вертикальный столбец называется членом RAID группы. VDS (Virtual Disk Space) – это дисковое пространство, доступное для пользовательских данных, а VDA – это адреса в нем.

Столбец или член RAID-группы записывается на один диск (PD – Physical Drive) в одной полке (Disk Unit). Место, куда записывается член RAID-группы, называется дисковой партицией (DP – Drive Partition). Число DP на диске постоянно и равно 264, размер зависит от размера диска. Такая конструкция позволяет равномерно нагрузить все диски. При этом алгоритм распределяет столбцы из одной RAID-группы максимально далеко друг от друга, на разных дисках и полках. Это приводит к тому, что при выходе из строя двух дисков одновременно количество общих страйпов на них минимально, и система переходит из состояния защиты N в N+1 за минуты, перестраивая те страйпы, где не хватает сразу двух столбцов (надежность ведь – семь девяток).
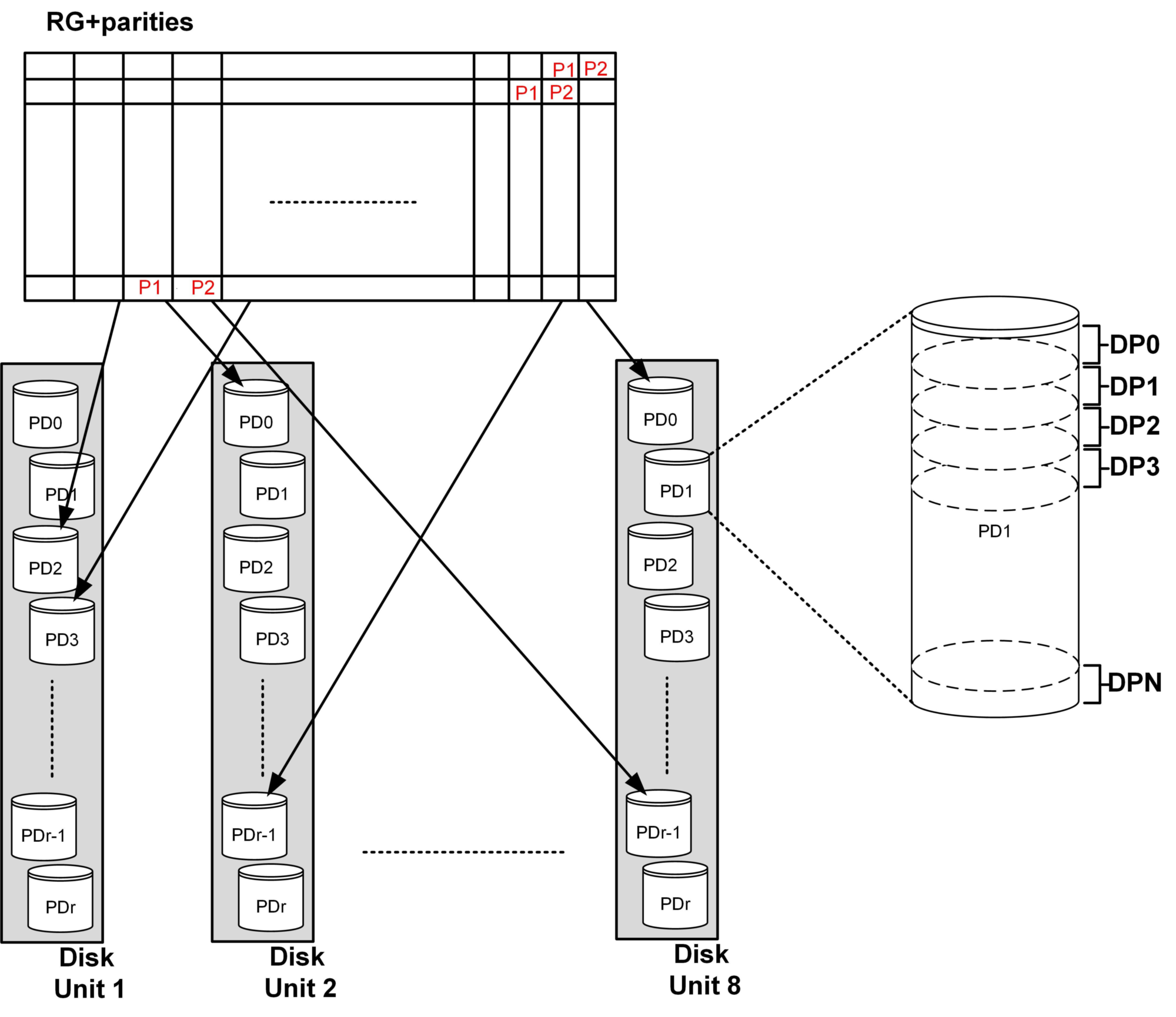
В итоге логическая конструкция системы в целом выглядит достаточно просто и представлена на схеме ниже.
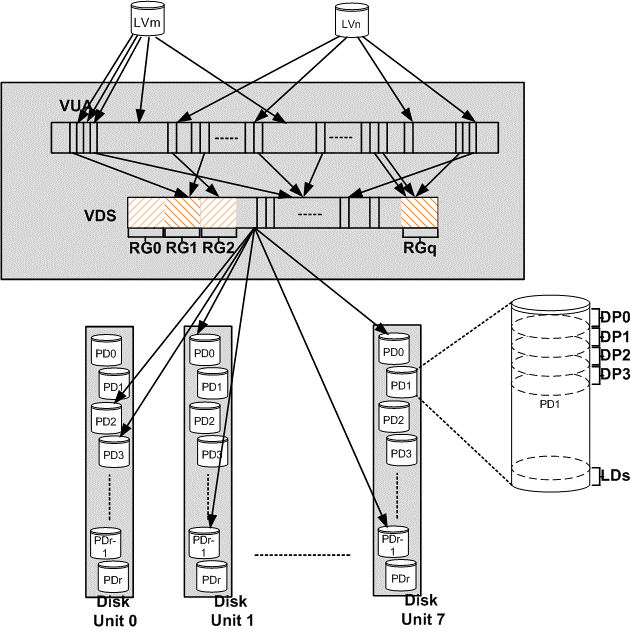
Физическая реализация
Система сделана так, что все ее компоненты защищены по схеме N+2 или 2N, включая питание и каналы данных внутри массива. Вот схема реализации электропитания.
ATS (Automatic Transfer Switch) – АВР, переключатель фазы
BBU (Battery Backup Unit) – ИБП, источник бесперебойного питания
Node – контроллер
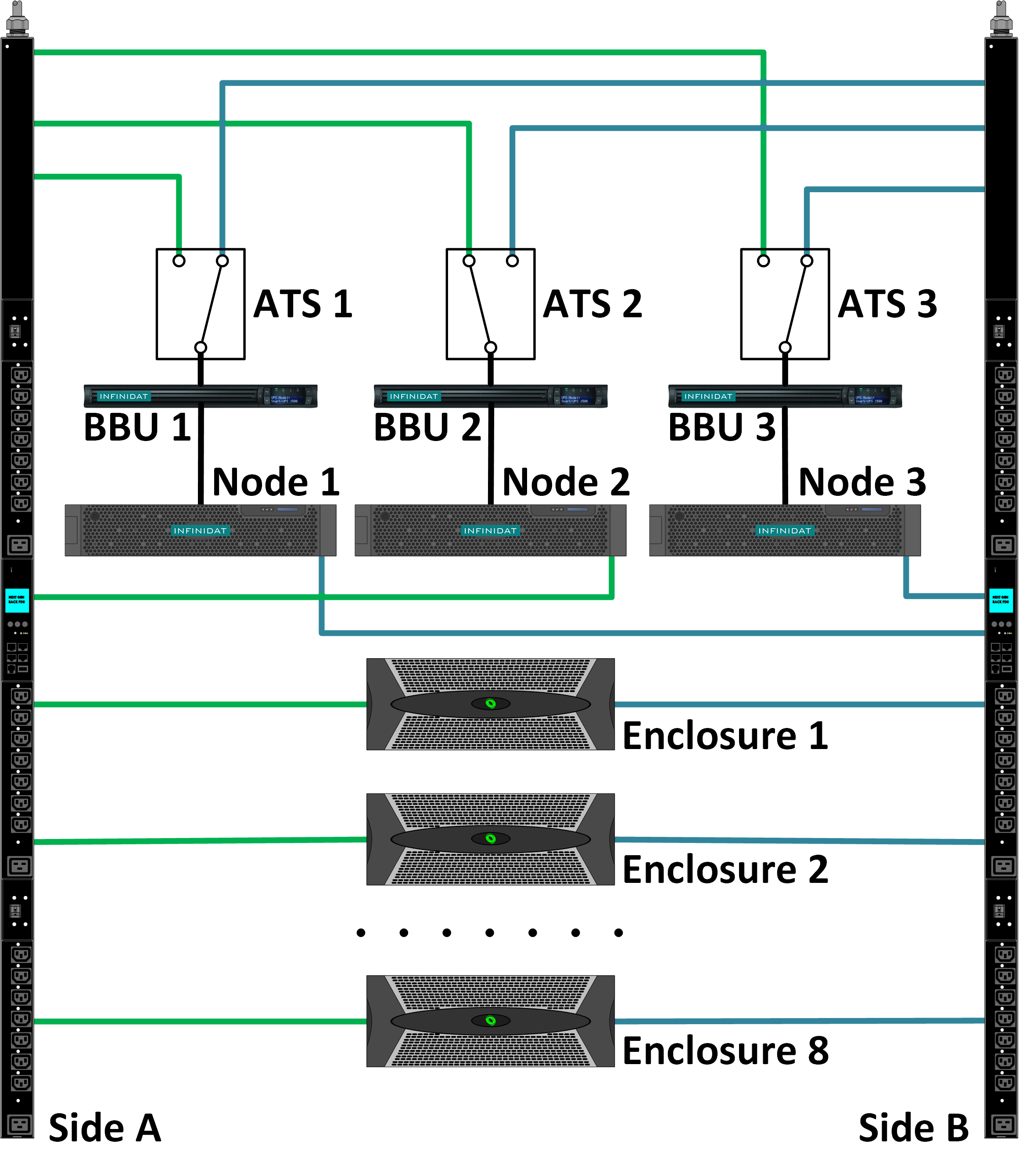
Такая схема позволяет защитить контроллеры и целостность памяти при сложных событиях, например, при отказе блока питания и временном отключении одной цепи питания. ИБП управляемые, что позволяет получать точную информацию о заряде и гибко менять размер кэша, чтобы контроллер всегда успел его сбросить. То есть система гораздо раньше начнет активно использовать кэш в отличие от классической схемы, когда кэш включается только тогда, когда батарейка полностью заряжена.
Вот схема каналов передачи данных внутри системы.
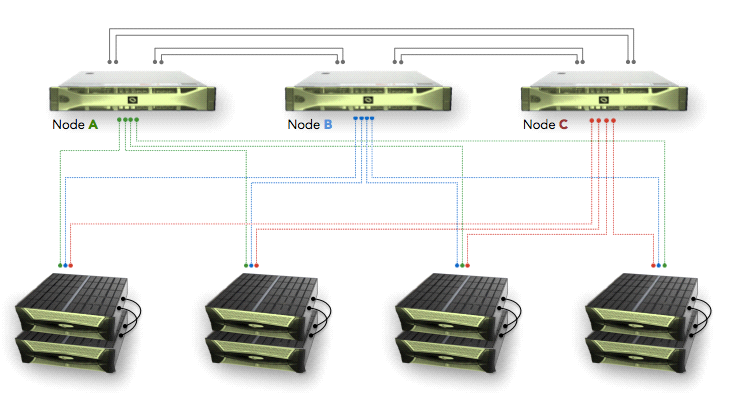
Контроллеры между собой соединяются по Infiniband, а с дисками они соединены через SAS. Каждый контроллер может обратиться к каждому диску в системе. При этом если связь между контроллером и диском не работает, то контроллер может запросить данные через другой контроллер, выступающий как прокси, через Infiniband. Полки содержат в себе SAS-коммутаторы для одновременного доступа к дискам. В каждой полке содержится 60 дисков, полок может быть две, четыре или восемь, итого до 480 дисков по 3, 4, 6, 8 или 12ТБ. Общая емкость, доступная пользователю, составляет более 4.1ПБ без учета компрессии. Кстати про компрессию, для реализации компрессии без потери производительности, память не компрессируется, в итоге система иногда работает с включенной компрессией даже быстрее – при чтении надо читать меньше, мощности процессоров хватает с запасом, а при записи ответ идет сразу из памяти и компрессия делается асинхронно во время непосредственной записи на диски.
Контроллеры содержат внутри себя две группы дисков: одна, системная, для сброса оперативной памяти и вторая, на SSD, для кэширования операций чтения (до 368ТБ на систему). Такой большой кэш позволяет предиктивно читать большими кусками, а поскольку данные в страйпе подбираются с примерно одинаковой частотой обращения, то такие большие куски не только снижают нагрузку на физические диски, но и имеют большие шансы быть востребованными в ближайшее время.
Резюме
Итак, мы поговорили про одну очень интересную систему хранения, которая имеет современную архитектуру и обеспечивает большую емкость, высокую надежность, отличную производительность и адекватную стоимость.

Источники
1 https://techfieldday.com/video/infinidat-solution-deep-dive/
2 https://support.infinidat.com/hc/en-us
Краткая предыстория
Что такое InfiniBox? Это система хранения компании Infinidat. Что такое компания Infinidat? Это компания, созданная Моше Янаем (создатель Symmetrix и XIV) для реализации проекта идеальной СХД Enterprise-уровня.
Компания создана как разработчик ПО, которое ставится на проверенное оборудование, то есть это SDS, но поставляется как единый монолитный комплект.
Введение
В этой статье мы рассмотрим систему хранения InfiniBox, ее архитектуру, как она работает и как достигается высокая надежность (99,99999%), производительность, емкость при сравнительно невысокой цене. Поскольку основа системы хранения — это ее ПО, а для этой системы в особенности, то основной упор будет именно на софте, красивых фото железок не будет.
Зачем нужна еще одна система хранения на рынке?
Есть ряд задач, для которых нужна очень большая емкость, при этом надежность и производительность тоже важны. Например, облачные системы, стандартные задачи крупных компаний, интернет вещей, генные исследования, системы безопасности для больших структур. Оптимальную СХД для таких задач найти достаточно сложно, особенно если смотреть на цену. С прицелом на такие задачи и была построена программная архитектура InfiniBox.
Адресация
Каким образом можно хранить неограниченные объемы данных? Путем предоставления неограниченного адресного пространства. Для этого в InfiniBox используется VUA — Virtual User Address space (виртуальное пользовательское адресное пространство). Все созданные на InfiniBox объекты, доступные пользователю (тома, снимки, файловые системы), входят в это VUA, и общий размер этих объектов и составляет текущий размер VUA. Адресация тонкая и не связана с дисками: то есть размер VUA может быть гораздо больше доступной дисковой емкости и фактически никак не ограничен.
Далее нам нужно разделить это пространство на части, которые мы будем обслуживать, — так с ними проще работать.
Все адресное пространство разбивается на 6 частей — VU (virtual unit — виртуальный кусок). Адресное пространство каждого объекта, например, тома, равномерно распределяется между этими частями. Запись идет блоками по 64кБ, и в процессе работы можно невероятно просто и быстро понять, какому VU принадлежит данный адрес тома (остаток от деления LBA/64кБ, функция modulo, делается очень быстро за минимальное число циклов ЦПУ).
Кроме упрощения работы с пространствами меньшего размера, VU являются первым уровнем абстрагирования от физических дисков и основой для отказоустойчивости системы на уровне контроллеров. Например, есть 3 контроллера (физических сервера), каждый из которых отвечает за работу и является основным для двух VU, а также резервным для двух других VU. Контроллер не обслуживает тот VU, для которого он является резервом, но при этом получает от другого контроллера метаданные и операции записи для данного VU, чтобы в случае сбоя основного контроллера сразу подхватить всю работу с этим VU.
В случае выхода из строя одного контроллера два других берут на себя его задачу — работу с его VU.
Адресация, моментальные снимки, кэширование
VUA — это виртуальное адресное пространство, доступное пользователю и фактически не ограниченное. VDA (Virtual Disk Address) — это виртуальное внутреннее пространство для хранения данных. Его размер заранее строго определен количеством и емкостью жестких дисков (за вычетом четности, метаданных и пространства для замены вышедших из строя дисков). Связь между VUA и VDA организована через trie (префиксное дерево). Каждая запись в дереве — это указатель из пользовательского пространства (VUA) на внутреннее пространство (VDA). Адресация в виде префиксного дерева позволяет адресовать блоки любого размера. То есть, когда на диски складывается элемент любого размера (файл, последовательный поток данных, объект), он может адресоваться одной записью в дереве и дерево остается компактным.
Однако наиболее важной особенностью дерева является высокая производительность при поиске и расширении дерева. Поиск выполняется при операции чтения, когда необходимо найти блок с заданным адресом на диске. Расширение дерева происходит при операции записи, когда мы складываем новые данные на диск и должны добавить к дереву адрес, где их можно найти. Производительность крайне важна при работе с большими структурами, и префиксное дерево позволяет ее достичь с огромным запасом на будущее, например, на случай увеличения объема дисков.
Что можно сказать про связь VUA и VDA:
- Размер VUA может намного превышать размер VDA
- VUA никак не связан с VDA, пока туда ничего не записали (thin provisioning)
- Больше чем один VUA могут ссылаться на один VDA (snapshots/clones)
Таким образом, организация VUA и VDA, связи между ними и адресация этих связей позволяют реализовать очень быстрые снимки и thin provisioning. Поскольку создание моментального снимка — это просто обновление метаданных в памяти и является постоянно происходящей операцией при работе, то фактически эта операция не занимает никакого времени. Как правило, при создании снимков классические системы хранения прекращают обновление метаданных и/или ввод-вывод для того, чтобы гарантировать целостность транзакций. Это ведет к неравномерности задержек операций ввода-вывода. Рассматриваемая система работает иначе: ничего не останавливается, а для определения попадания операции в снимок используется timestamp из метаданных блока (64+4КБ). Таким образом, система может делать сотни тысяч снимков, не замедляя работы, и производительность тома с сотнями снимков и тома без снимков никак не отличается. Поскольку все делается в памяти и это штатные процессы, то на группы томов можно делать десятки снимков в секунду. Это позволяет реализовать асинхронную репликацию на мгновенных снимках с разницей между копиями в секунды и даже меньше и без влияния на производительность, что тоже немаловажно.
Посмотрим на систему в целом, как идут данные. Операции поступают через порты всех трех контроллеров (servers). Драйвера портов работают в User space, что позволяет просто перезапускать их, если какая-либо комбинация событий на портах подвесит драйвера. В классических же реализациях это делается в ядре и проблема решается перезапуском контроллера целиком.
Далее поток разбивается на секции по 64КБ+4КБ. Что такое эти дополнительные 4КБ? Это защита от «тихих ошибок» (silent errors), и там записаны контрольные суммы, время и дополнительная информация об операции, которая используется для классифицирования этой операции и применяется для оптимизации кэширования и упреждающего чтения.
Кэширование записи – довольно простая вещь, чего нельзя сказать про чтение. Кэширование чтения хорошо работает, если мы знаем, что надо считывать. В классических системах используются алгоритмы упредительного чтения при последовательном доступе. Но что делать при произвольном? Полностью произвольный доступ крайне редко встречается в работе реальных приложений, даже эмулировать правильно его достаточно сложно, написание генератора реально случайных чисел — довольно интересная задача. Но если рассматривать каждую операцию ввода-вывода отдельно, как делается в классических системах, то все они являются произвольными и непредсказуемыми, кроме полностью последовательных. Однако если смотреть на весь поток ввода-вывода некоторое время, то можно увидеть закономерности, объединяющие разные операции.
Кэш системы принципиально не знает ничего о томах, файлах, о любой логической структуре, построенной на VUA. Кэш смотрит только на секции и на их метаданные, основывая кэширование на их поведении и атрибутах, что позволяет находить зависимости между разными приложениями, которые в реальности связаны. Для операций ввода-вывода строятся вектора активности.
Система накапливает статистику, строит эти вектора активности, затем пытается идентифицировать текущий ввод-вывод и привязать его к известным векторам или построить новый. После идентификации происходит упредительное чтение согласно вектору, то есть предсказывается поведение приложений, и делается упредительное чтение для вроде бы произвольной нагрузки.
Запись на диски
14 секций собираются в страйп для сброса на диски. Это делается специальным процессом, который подбирает секции для такого страйпа.
Далее считаются две секции четности — страйп готов к записи на диски. Четность считается через несколько операций на основе XOR, что в два раза быстрее, чем на базе кода Рид-Соломона. Дальше страйп (14+2 секции) присваивается RAID группе (RG). RAID-группа – это просто объект для хранения нескольких страйпов, не более того. Страйпы собираются в группу, как показано ниже, один над другим, и вертикальный столбец называется членом RAID группы. VDS (Virtual Disk Space) – это дисковое пространство, доступное для пользовательских данных, а VDA – это адреса в нем.
Столбец или член RAID-группы записывается на один диск (PD – Physical Drive) в одной полке (Disk Unit). Место, куда записывается член RAID-группы, называется дисковой партицией (DP – Drive Partition). Число DP на диске постоянно и равно 264, размер зависит от размера диска. Такая конструкция позволяет равномерно нагрузить все диски. При этом алгоритм распределяет столбцы из одной RAID-группы максимально далеко друг от друга, на разных дисках и полках. Это приводит к тому, что при выходе из строя двух дисков одновременно количество общих страйпов на них минимально, и система переходит из состояния защиты N в N+1 за минуты, перестраивая те страйпы, где не хватает сразу двух столбцов (надежность ведь – семь девяток).
В итоге логическая конструкция системы в целом выглядит достаточно просто и представлена на схеме ниже.
Физическая реализация
Система сделана так, что все ее компоненты защищены по схеме N+2 или 2N, включая питание и каналы данных внутри массива. Вот схема реализации электропитания.
ATS (Automatic Transfer Switch) – АВР, переключатель фазы
BBU (Battery Backup Unit) – ИБП, источник бесперебойного питания
Node – контроллер
Такая схема позволяет защитить контроллеры и целостность памяти при сложных событиях, например, при отказе блока питания и временном отключении одной цепи питания. ИБП управляемые, что позволяет получать точную информацию о заряде и гибко менять размер кэша, чтобы контроллер всегда успел его сбросить. То есть система гораздо раньше начнет активно использовать кэш в отличие от классической схемы, когда кэш включается только тогда, когда батарейка полностью заряжена.
Вот схема каналов передачи данных внутри системы.
Контроллеры между собой соединяются по Infiniband, а с дисками они соединены через SAS. Каждый контроллер может обратиться к каждому диску в системе. При этом если связь между контроллером и диском не работает, то контроллер может запросить данные через другой контроллер, выступающий как прокси, через Infiniband. Полки содержат в себе SAS-коммутаторы для одновременного доступа к дискам. В каждой полке содержится 60 дисков, полок может быть две, четыре или восемь, итого до 480 дисков по 3, 4, 6, 8 или 12ТБ. Общая емкость, доступная пользователю, составляет более 4.1ПБ без учета компрессии. Кстати про компрессию, для реализации компрессии без потери производительности, память не компрессируется, в итоге система иногда работает с включенной компрессией даже быстрее – при чтении надо читать меньше, мощности процессоров хватает с запасом, а при записи ответ идет сразу из памяти и компрессия делается асинхронно во время непосредственной записи на диски.
Контроллеры содержат внутри себя две группы дисков: одна, системная, для сброса оперативной памяти и вторая, на SSD, для кэширования операций чтения (до 368ТБ на систему). Такой большой кэш позволяет предиктивно читать большими кусками, а поскольку данные в страйпе подбираются с примерно одинаковой частотой обращения, то такие большие куски не только снижают нагрузку на физические диски, но и имеют большие шансы быть востребованными в ближайшее время.
Резюме
Итак, мы поговорили про одну очень интересную систему хранения, которая имеет современную архитектуру и обеспечивает большую емкость, высокую надежность, отличную производительность и адекватную стоимость.
Источники
1 https://techfieldday.com/video/infinidat-solution-deep-dive/
2 https://support.infinidat.com/hc/en-us



