
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Передо мной стояла задача выбрать библиотеку для расчета на Python, использующего операции над матрицами. Я выбрал и протестировал несколько вариантов, как использующих видеокарту (GPU), так и работающие только на процессоре.
Использовал три библиотеки: Numpy, Pytorch и Numba.
Описание задачи для теста
Расчеты будем делать на плоскости. Генерируем случайным образом 2D фигуры, состоящие из 4-8 точек. Количество фигур меняется от теста к тесту от 1 и до 1000000. Начинаем перемещать их по плоскости. У нас три степени свободы и мы можем двигать их вдоль любой из двух осей или вращать вокруг центра фигуры. Основной объем расчетов перемещений делается с помощью операций над матрицами 3х3.
Практического смысла в задаче нет, абстрактная задача просто для теста разных операций над матрицами.
Numpy
На Numpy я написал две тестируемые функции - “наивный numpy” и “numpy”. В первой все массивы перебираются в циклах, так как обычно это описывают в учебниках по программированию. Эффективность такого подхода ниже плинтуса.
Вторая функция, когда массив обрабатывается параллельно, с точки зрения питона одновременно весь. Параллельность обеспечивается, насколько я понимаю, отсутствием нативных питоновских циклов, внутренней оптимизацией numpy и использованием ядер процессора. Впрочем от циклов полностью избавиться мне не удалось.
Pytorch
На Pytorch функция фактически написана одна, но ее выполняем один раз на CPU, один раз на видеокарте (GPU). На графиках результаты подписаны “Pytorch CPU” и “Pytorch GPU”.
Numba
Для начала не перепутайте Numba и Numpy. Это разные библиотеки, хотя у них названия и похожи.
Код для Numba пишется сразу с учетом того, что он будет разнесен на разные ядра GPU. Без GPU использовать эту библиотеку возможно, но для меня не было смысла.
Код я писал так, что одно ядро GPU считало одну точку фигуры. Можно было разнести код по ядрам иначе. Например, что одно ядро - одна фигура или наоборот, 9 ядер на одну матрицу 3x3. Так как Numba сходу выигрывала с большим отрывом, то тестировать другие варианты я не стал.
Тесты по 1000 циклов
Берем для теста какое-то количество фигур и перемещаем каждую по плоскости 1000 раз. По оси X - количество фигур, по оси Y - время на расчет. На графике фигуры подписаны, как агенты.
По результатам графики говорят сами за себя, тут мало что можно прокомментировать.

Numpy
Numpy хорошо себя показывает при относительно небольшом числе фигур. Видно, что время работы алгоритма “наивный numpy” растет линейно сразу от 1 фигуры. Оптимизации при таком подходе скорее всего нет. Проигрыш “наивного numpy” обычному numpy уже к 1000 фигур составляет примерно 55 (!) раз. Так что, если быстродействие сколько нибудь критично, то используйте Numpy правильно.
С ростом числа фигур Numpy опускается на последнее место в общем зачете, т.к. библиотека не использует Gpu.
Pytorch
Еще на отладке я понял, что, что быстродействие кода на Pytorch очень сильно зависит от его оптимизации. Прямо таки замерял время выполнения отдельных участков и правил кодж. В итоге разница между CPU и GPU вариантами, не особенно велика. Pytorch-GPU в 3.1 раза быстрее при числе фигур больше, чем 10000.
Честно говоря ожидал большего от Pytorch-GPU. Может быть связано с тем что библиотека рассчитана все таки на несколько другие задачи связанные с ИИ.
Numba.
Если продолжительность расчета 1000 циклов, то Numba выигрывает при любом количестве агентов. Причем побеждает она с большим отрывом. На 100000 агентов Numba выигрывает в 5.8 раз у ближайшего конкурента Pytorch-CPU.
Раньше не рассматривал Numba , как постоянное средство разработки. Эта библиотека не слишком распространена по сравнением с тем же Pytorch. Начал использовать Numba только потому что сам разбирался с тем, как работает Gpu при распараллеливании расчетов. Поэтому и в тест взял. Видимо теперь буду использовать, при необходимости.
При числе фигур свыше 10000 , все графики ведут себя одинаково и параллельно растут (при логарифмической шкале).
Каждый тест по 10 циклов.
10 циклов на тест это очень мало, обычно любой пошаговый расчет (мат. модель например) это гораздо дольше. Я прогнал этот тест, просто потому что мог.
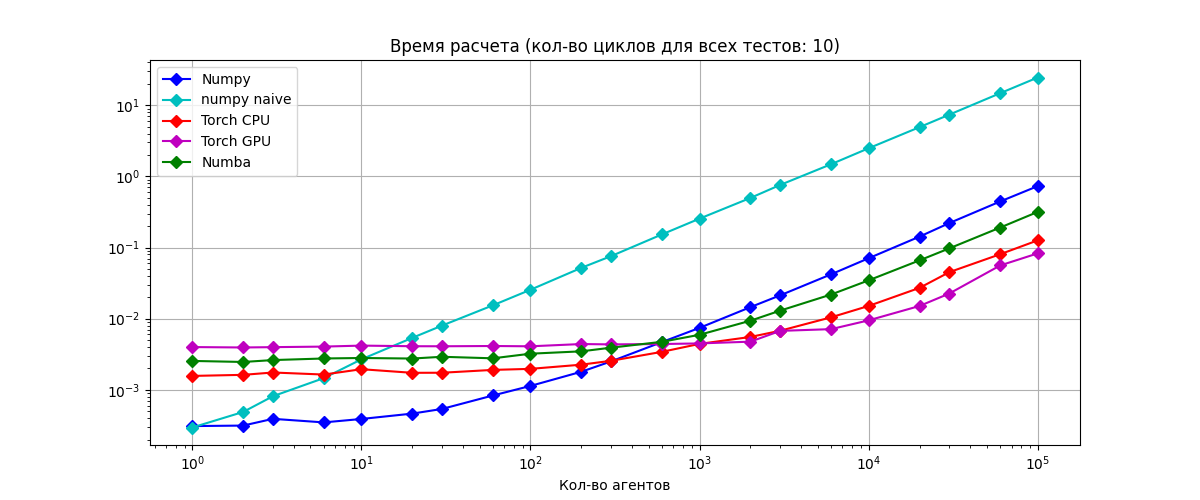
Numpy резко улучшил показатели и вышел на первое место. Судя по всему ему требуется меньше всего времени на инициализацию. А Numba наоборот пострадала сравнявшись с Pytorch. По сути они поменялись местами.
При небольшом числе циклов логично использовать Numpy или Pytorch.
Прочее разное
Железо на котором гонял тесты:
Win10
intel Core i5 9400F
RAM 16Gb
RTX 2060 6Gb, 1920 cores
Версии библиотек:
Python 3.8
Pytorch 1.8.1
Numpy 1.20.3
Numba 0.54.1
Код на гитхабе.
Ни на какую особенную истину не претендую. Статья отражает лишь мой частный опыт.
Всем добра.



