
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
В прошлой части мы провели анализ архитектуры, итогом которого стало внедрение дополнительного разделения на слои: Core (ядро) и Externals (источники данных).
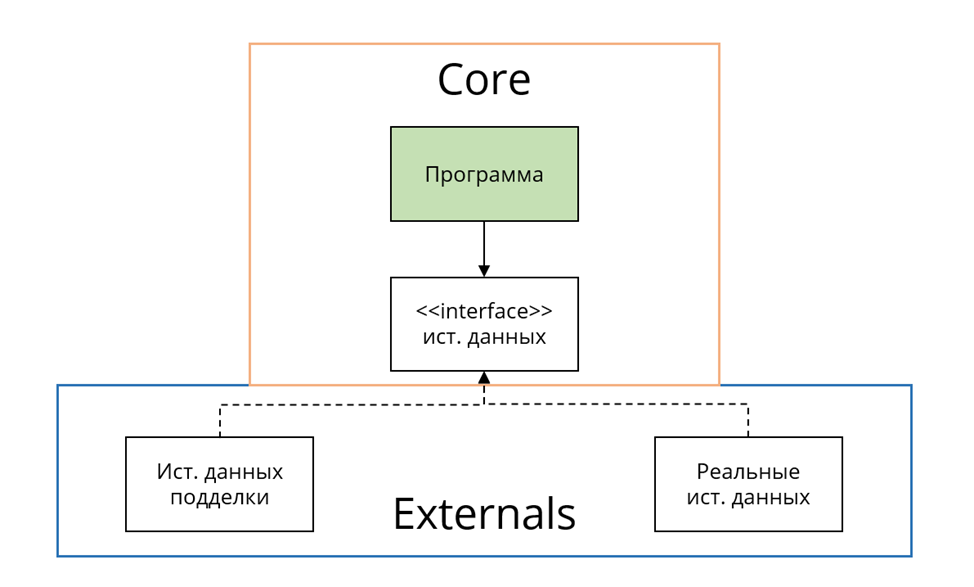
После чего, в целях имплементации самого процесса тестирования, в системе были выделены порты ввода/вывода, те самые границы, которые и определят итоговый метод тестирования и его свойства.

Но каким образом граница может повлиять на эффективность тестирования? Как выбор интерфейса взаимодействия с программой изменяет показатели свойств тестов: защиты от регресса, сопротивляемости рефакторингу, поддерживаемости и быстродействия?
Калькулятор
Представим, что вам доверили разработать приложение «Калькулятор».

В ходе реализации его функций вам стало очевидно, что без тестов тут не обойтись. В поисках жертвы вы натыкаетесь на самую легкую добычу из всех возможных:

Настолько простая функция ожидаемо не вызывает больших трудностей при ее тестировании:

Убедимся, что тест действительно что-то проверяет посмотрев, среагирует ли он на дефект в реализации:

Как видно из результата, тест написан и даже падает в случае некорректной реализации. Но действительно ли это является достаточным показателем качества выбранного метода тестирования?
Хрупкость
Предположим, что в ходе рефакторинга исходного кода разработчики решили несколько изменить сигнатуру функции sum:

При компиляции и запуске основной программы с измененной функцией система ведет себя как прежде, числа все также складываются, то есть никакого регресса нет, но при запуске ранее написанных тестов мы получаем ошибку:

Тест упал, что обычно должно интерпретироваться как наличие регресса в системе, но по факту ничего не сломано, разработчики лишь немного изменили структуру кода определенной функции, то есть выполнили рефакторинг. Такой результат тестирования называется ложноположительным:
Ложным, потому что не соответствует реальному положению вещей, а именно —отсутствию каких-либо дефектов.
Положительным, так как тест — это прежде всего поиск дефектов, как тест на грипп, например. Это можно считать простым соблюдением общей терминологии, хотя в падающем тесте для разработчика мало чего положительного.
Хрупкие тесты, а именно так их и называют, являются единственным признаком низкой сопротивляемости рефакторингу. Теперь, для того чтобы тест снова заработал, требуется поправить его исходный код:

Работы над рефакторингом увеличились на ровном месте. Хрупкие тесты являются опасным гостем на проекте. Поначалу их не воспринимают всерьез — ну подумаешь, упал после рефакторинга. Но чуть позднее, когда проблемы становятся критическими, менять что-то становится уже поздно: на написание тестов времени потрачено уже много, а удалять их жалко, ведь они действительно иногда могут что-то поймать.
Такой балласт усложнит практически любой рефакторинг и, несомненно, возглавит список основных причин быстрого устаревания проекта. Хрупкие тесты и быстрый рост их влияния на проект можно сравнить с тем, как болото медленно, но уверенно тянет беспомощную жертву вниз, начиная с самого малого, но в большинстве случаев заканчивая начатое до конца.
Ложь
Отметим также один достаточно очевидный факт: в таком сложном и составном приложении, как калькулятор, функция sum не будет использоваться сама по себе. Скорее всего она будет вызываться внутри других элементов системы, например в UI-компонентах. Теперь представим, что после очередной правки дефектов, доработки или рефакторинга разработчик допустил ошибку в такой композиции:

Если запустить программу и сложить два разных числа, то можно увидеть неожиданный результат. Налицо явный дефект. Но в то же самое время, если запустить тест, написанный ранее, то он пройдет успешно:

И неудивительно, что тест прошел успешно, ведь он проверяет лишь работу функции sum, реализация которой осталась неизменной. Изменилась только ее композиция с другими элементами системы. Это одно из основных проявлений низкой защиты от регресса. Такой результат запуска тестов называется ложноотрицательным. По аналогии с предыдущим примером, ложным такой результат является потому, что проходящий тест понимается как признак отсутствия дефектов, хотя на самом деле система ведет себя некорректно.
Конечно, можно поспорить и сказать, что тест на самом деле выполнил свою задачу и выдал истинноотрицательный результат, ведь сама функция sum не сломалась. И это действительно так. Но проблема заключается в том, что такая ситуация вообще случилась, ведь она целиком и полностью является результатом зависимости теста от конкретных деталей реализации. Тест знает о существовании функции sum и поэтому может протестировать ее отдельно.
Как будет показано далее, чтобы построить действительно полезные тесты, гораздо выгоднее рассматривать текущую ситуацию как негативную, то есть считать результат ложноотрицательным.
Тест соврал разработчику. Пару раз на это могут закрыть глаза, но если такая ситуация станет постоянной, то результатам выполнения тестовых сценариев перестанут доверять, их могут просто игнорировать. Сам процесс запуска тестов станет бессмысленным и будет проходить скорее для галочки, тем самым впустую тратя драгоценное время инженера.
Основная причина
Главная причина недостаточных показателей тестов в защите от регресса и сопротивляемости рефакторингу лежит в неверно расставленных границах тестирования.

На изображении выше обозначена условная шкала, на которой отмечены возможные границы взаимодействия с программой:
Крайней правой точкой является такая граница, которой известны полные детали реализации программы (как настоящему разработчику).
Далее, справа налево, идут компоненты как композиция функций.
Страницы как композиция компонентов.
Процессы как композиция страниц.
Общая клиентская логика приложения как композиция процессов.
В крайней точке слева располагается граница, представляющая собой целевые средства ввода и вывода информации из программы, именно те порты, с помощью которых с ПО взаимодействует настоящий пользователь системы.
Важно отметит и то, что QA-инженер, проверяющий требования, чаще всего это делает именно от лица пользователя системы. Этот факт будет принят за данность в дальнейшем.
Почему причиной возникновения негативных свойств тестов является расположение их границы? Возьмем пример с калькулятором и отразим расположение границы реализованного метода тестирования на шкале.

Сам факт того, что тесты проверяют функцию sum в отрыве от тех компонентов, с которыми она используется в целевом виде, и доказывает то, что граница тестирования располагается слишком близко к деталям реализации:

В нашем примере разработчики в ходе правки дефекта или рефакторинга изменили исходный код одного из промежуточных компонентов данной цепочки.

В таком случае выполняющийся тест функции sum будет доказывать работоспособность самой тестируемой функции, а не требования в целом, полностью игнорируя новое поведение измененного компонента Equals. Чего нельзя сказать про настоящих пользователей (QA), которые будут заводить дефекты, основываясь на поведении всех компонентов в агрегации. Проблема заключается в том, что тесты в их текущем виде располагаются слишком далеко в своих границах от реальных клиентов системы.
Здесь можно возразить и сказать, что возможно написать отдельные тесты для компонента Equals:

Сначала предположим, что отдельный тест для компонента Equals изолирует его от функции sum таким образом, что проверяется корректность работы именно самого компонента:

Из этого можно вывести следующее:
Часть регресса в компоненте Equals теперь предупреждается тестами. Ситуация уже лучше, чем была прежде.
В случае падения теста источник дефекта будет легко определен, так как тесты проверяют сильно изолированный функционал.
Сценарии тестов на sum и Equals будут пересекаться, так как обязаны покрывать одни и те же общие требования и допущения. Это вызывает дублирование и негативно сказывается на поддерживаемости.
Тесты верифицируют элементы в изоляции, тем самым игнорируя проверки на совместимость их контрактов. Об этом будет рассказано в части о принципе подстановки.
Ясно, что тестирование компонентов по отдельности, вне контекста их целевой композиции, только частично улучшает показатели защиты от регресса, но за собой тянет еще более серьезные проблемы, приводящие к сниженной поддерживаемости таких решений. Сопротивляемость рефакторингу тоже не улучшилась, ведь тесты все также зависят от деталей реализации программы.
Теперь предположим, что тест для компонента Equals также включает функцию sum.

Исходный код самого теста при этом выглядит следующим образом:

Здесь выводы уже совершенно иные:
Регресс теперь предупреждается как внутри компонента Equals, так и внутри функции sum.
Элементы тестируются в композиции друг с другом, тем самым косвенно проверяется контракт их взаимодействия, что дает дополнительную защиту от возможных дефектов.
В существовании отдельного теста на sum теперь нет смысла, ведь данная функция транзитивно проверяется тестами на Equals.
Тесты теперь не знают о существовании функции sum. Эту деталь реализации можно легко рефакторить, и тесты при этом не сломаются.
Кода в рамках тестирования выполняется больше, это негативно повлияет на время выполнения.
В случае падения теста, ошибку будет найти сложнее, так как покрывается бо́льшая площадь исходного кода.
Ситуация уже гораздо лучше. Тестирование более крупного блока выразилось в улучшенных показателях защиты от регресса, сопротивляемости рефакторингу и поддерживаемости. Основная причина заключается в том, что граница тестирования теперь располагается чуть ближе к реальному пользователю системы.

Давайте разберем причины возникновения такого положительного эффекта, вызванного смещением границы в сторону пользователя, более подробно, хотя это, скорее всего, интуитивно понятно.
Защита от регресса
Защита от регресса повысилась вследствие смещения границы тестирования на шкале влево, так как тестовые сценарии теперь верифицируют поведения более приближенные к тому, что видит перед собой пользователь.
Клиенты системы, в частности QA-инженеры, и есть те самые источники дефектов и требований, те самые лица, которые решают, что является корректным поведением, а что нет. Обратите внимание, как это похоже на то, чем должен заниматься тест: определять, какое поведение является дефектным, а какое нет.
Уменьшение расстояния между границами пользователей и тестов делает последних более похожими на реальных клиентов системы, тем самым положительно влияя на вероятность предупреждения дефекта.
Сопротивляемость рефакторингу
Сопротивляемость рефакторингу тоже увеличилась, но здесь ситуация немного сложнее. Рефакторинг — это процесс изменения деталей реализации без влияния на наблюдаемое поведение. Термин «наблюдаемое поведение» можно сделать более конкретным с точки зрения рассмотренных ранее терминов:
Наблюдаемое — это всего лишь место, где располагается конечный порт вывода информации. Это может быть монитор компьютера, API библиотеки, дисплей телефона, экран телевизора, аудиосистема — вариантов много, и все они зависят от того, кем является конечный пользователь системы.
Поведение — это содержание выводимой через порт информации.

Попробуем представить то же самое, но на уровне псевдокода:

Можно сделать следующие замечания:
Клиент полностью определяет интерфейсы для своих серверов. Это то самое допущение, сделанное в прошлой части. Обратите внимание, как точно оно отражает реальное положение вещей. Ведь именно конечные пользователи диктуют разработчикам те средства вывода, которые должны реализовываться системой.
Любое изменение, которое не влияет на контракт взаимодействия (интерфейс IUserInterface) и содержание выводимой через него информации, будет скрытым от пользователя, то есть будет являться рефакторингом, другими словами! Обратите внимание, как здесь проявляются свойства, рассмотренные ранее, а именно как интерфейсы защищают своих клиентов от изменений в имплементаторах.
Из этой достаточно долгой, но необходимой подводки можно сделать уверенный вывод: именно конечный пользователь системы определяет, что является рефакторингом, а что нет.
Тесты — это такой же пользователь системы, который рисует свои границы (или интерфейсы взаимодействия с системой). Из них следует, что является рефакторингом, а что нет, какие изменения являются наблюдаемыми, а какие нет. Для хрупких тестов граница располагается очень близко к деталям реализации, сильно уменьшая пространство для рефакторинга.

Для тестов, предоставляющих достаточную сопротивляемость рефакторингу, граница максимально приближена к той, которая определяется пользователем, тем самым понятия рефакторинга обоих становятся почти идентичными.

Подведем промежуточный итоги:
Пользователь системы определяет то, что является наблюдаемым в поведении системы, он определяет ее крайнюю границу, тот самый порт вывода информации.
Тесты — это такой же пользователь, который, в свою очередь, устанавливает собственные границы
Защита от регресса зависит от позиции границы. Если она располагается близко к деталям реализации, то итоговые тесты верифицируют крупный сценарий «по кусочкам» (по определению), игнорируя целевую композицию и пропуская целые цепочки функций.
Граница также влияет и на сопротивляемость рефакторингу. Более того, именно позиция границы, заданная настоящим пользователем, и определяет то, что является рефакторингом, а что нет. Чем дальше граница тестирования располагается от границы основного пользователя, тем чаще тесты будут падать при изменении деталей реализации, в то время как настоящий клиент системы ничего не заметит (по определению рефакторинга).
Матрица
После того как был определен основной инструмент контроля защиты от регресса и сопротивляемости рефакторингу, необходимо понять, каким образом можно измерить данные свойства для конкретного метода тестирования.
Для этого воспользуемся следующей таблицей:

Разберем матрицу, описывая ячейки слева направо:
Истинноположительный — результат, при котором в реальности имеет место дефект и тесты на него среагировали, то есть упали. Иными словами, предупредили регресс.
Истинноотрицательный — результат, при котором в реальности дефектов нет (в рамках подразумеваемого разработчиком поведения) и тесты проходят успешно, то есть не падают.
Ложноположительный — результат, при котором в реальности дефект отсутствует, но тесты при этом упали.
Ложноотрицательный — результат, при котором в реальности дефект присутствует, но тесты при этом проходят успешно, сигнализируя обратное.
В каждой из ячеек располагается число, обозначающее количество соответствующих событий, которые произошли во время эксплуатации выбранного тестирования. Например, представим, что разработчики реализовали на проекте некоторый метод тестирования, назовем его v1. В самом начале эксплуатации в каждой ячейке будет стоять 0.

Далее разработчики реализовали новое требование (изменили исходный код), убедились, что тесты проходят, и отдали на проверку QA, которые подтвердили, что все работает исправно. Такое событие соответствует истинноотрицательной ячейке, поэтому ей нужно дать одно очко.

Через некоторое время разработчики затеяли рефакторинг и изменили исходный код, в результате чего упали тесты. После фактической проверки оказалось, что дефект действительно есть. Данный результат является истинноположительным, поэтому и увеличивается значение соответствующей ячейки.

После этого разработчики реализовали очередную требуемую заказчиком функцию (изменили исходный код), убедились, что тесты проходят, и отдали QA, которые уже по итогу обнаружили дефекты в ранее работающем функционале, иными словами, поймали регресс. Тесты с новыми функциями прошли, хотя фактически имел место дефект. Данный результат является ложноотрицательным.

Затем, спустя некоторое время, инженеры затеяли очередной рефакторинг. После изменения деталей реализации некоторой функции тесты сообщили о наличии проблемы, то есть упали. При фактической проверке разработчиком оказалось, что никакого дефекта в наблюдаемом поведении нет. Такой результат является ложноположительным.

Обратите внимание на крайне важный факт: данная матрица наполняется не в статике, а в динамике, то есть после каждого осмысленного изменения исходного кода. Это может быть реализация новой функции, правка дефекта или рефакторинг. Иными словами, каждое очко в таблице соответствует какой-то задаче.
Теперь представим, что спустя некоторое время у разработчиков получилась матрица следующего содержания (для наглядности ячейки обогащены цветовой индикацией: чем темнее цвет, тем относительно большее число стоит в ячейке).

Нижний ряд более темный, чем верхний. Это говорит о том, что выбранный метод тестирования является хрупким и не предоставляет достаточной защиты от регресса. Как говорилось ранее, это скорее всего связано с неверно выставленной границей тестирования: она располагается слишком близко к деталям реализации.

Теперь представим, что разработчики сдвинули границу тестирования, переместив ее ближе к пользователю. Например, сменили тестирование простых функций тестированием UI-компонентов, как в примере с калькулятором. Анализ показал следующее:

Ситуация уже лучше, тесты пропускают меньше дефектов (истинноположительный и ложноотрицательный), но по-прежнему реагируют на рефакторинг (ложноположительный).
Логика процесса должна быть предельно ясной. Основной параметр оптимизации — это чаще всего граница тестирования. Целевая позиция матрицы, к которой должен стремиться любой метод тестирования для того, чтобы быть эффективным, выглядит следующим образом:

Подавляющее число событий, связанных с изменением исходного кода и последующей верификации его корректности, должно относиться к первой строчке матрицы. Чем ближе актуальная матрица к идеальной, тем выше показатели защиты от регресса и сопротивляемости рефакторингу.
Есть одно «но»
Хорошая защита от регресса и сопротивляемость рефакторингу требуют приближения тестов к реальному пользователю. Крайней точкой данного процесса являются E2E-тесты. Вспомним их показатели:

У этой матрицы есть один большой минус: она не учитывает поддерживаемость и быстродействие итогового решения. Опираясь на приведенный анализ E2E-тестов, можно сказать, что слишком близкое расположение тестов к пользователю или их фактическое «уравнивание» может крайне негативно сказаться на поддерживаемости.

Быстродействие также не исключение. Чем больше компонентов системы проверяется в агрегации (чем дальше граница тестирования), тем больше времени занимает выполнение тестов. На самом деле защита от регресса вместе с сопротивляемостью рефакторингу являются антагонистами по отношению к быстродействию. Другими словами, нельзя написать такой метод тестирования, в котором все три показателя будут максимальными.

Напомним, что показатель быстродействия является относительным. Это значит, что если разработчик сумел написать такое решение для тестов, которое предоставляет отличную защиту от регресса и сопротивляемость рефакторингу, а также выполняется быстро, то в таком случае у этого же самого разработчика получится ускорить эти же тесты еще сильнее, просто исключив некоторые компоненты из процесса тестирования, тем самым делая изначальное решение сравнительно слабым в быстродействии.
Поддерживаемость также вступает в противоречие с первыми двумя свойствами, но только в самых крайних точках границы. Субъективность данного пункта делает его по большей части управляемым безотносительно других показателей.
Покрытие кода
Отдельно стоит упомянуть такой метод измерения защиты от регресса, как генерация отчетов о покрытии исходного кода тестами. Работает данный инструмент достаточно примитивным образом: если какая-то строчка кода выполняется во время работы теста, то она помечается как покрытая. Все те участки кода, которые не задействуются во время выполнения, отмечаются как непокрытые:
 означает покрытый участок кода. Серый, напротив, непокрытый.")
Данный вид отчета является полезным негативным индикатором. То есть в случае, когда итоговый процент покрытия слишком низкий, это действительно может означать (и скорее всего означает), что тесты предоставляют низкую защиту от регресса.
Показатель же покрытия в 100% или близкий к нему, в свою очередь, не гарантирует абсолютно ничего, ведь выполнение какой-то строчки кода не значит проверку корректности результата ее работы:

Также инструменты сбора отчета могут (и скорее всего будут) игнорировать покрытие внутренних функций сторонних библиотек (в том числе и стандартной библиотеки языка), которые также стоит учитывать в процессе тестирования. Поэтому к подобного рода инструментам следует относиться с предельной осторожностью и внимательностью.
Итоговая роль границы
После рассмотрения того, каким образом граница тестирования влияет на их свойства, стоит передохнуть и подвести небольшой промежуточный итог:
Основным инструментом измерения защиты от регресса и сопротивляемости рефакторингу является формирование матрицы результатов тестирования. Важно то, что конкретный метод тестирования сложно оценить в статике, напротив, более точные результаты оценки могут быть получены только в движении: в процессе выполнения задач, правки дефектов и рефакторинге.
Основным методом управления данными показателями является расположение границы тестирования.
Стремясь к идеальным показателям, не стоит забывать и о двух других: поддерживаемости и быстродействии.
Поддерживаемость хоть и является по большей части субъективной, но может серьезно снижаться в крайних расположениях границ тестирования, например при использовании E2E-решений.
Быстродействие, в свою очередь, является прямым антагонистом защиты от регресса. Так, чем больше кода проверяется (то есть выполняется), тем выше защита от регресса, но и тем медленнее тесты.
Процент покрытия тестов является хорошим негативным показателем. Однако высокий процент в отчете не показывает абсолютно ничего по отношению к приведенным свойствам.
Разработчик, реализуя определенный метод тестирования, должен решить нетривиальную задачу, которая требует постоянного анализа (путем построения и заполнения матрицы) и доработки тестов таким образом, чтобы, помимо достижения целевых показателей в защите от регресса и сопротивляемости рефакторингу, оставить поддерживаемость и быстродействие на достаточно высоком уровне. Другими словами, идеального решения не бывает, а самое лучшее, что можно получить, лежит где-то посередине, как оно чаще всего и бывает.
В следующей части мы затронем достаточно важную проблематику, возникающую при тестировании с заглушками, а именно проблему подстановки (описываемую принципом подстановки LSP). И, конечно же, продолжим свое движение к той самой тестируемой архитектуре.




. Диффузионный паромасляный насос: реанимация и немного теории")