
Всем привет! Меня зовут Паша, и я QA инженер команды Order Processing в Lamoda. Недавно я выступал на PHP Badoo Meetup. Сегодня хочу представить расшифровку своего доклада.
Речь пойдет про Codeception, про то, как мы его используем в Lamoda и как на нем пишем тесты.
В Lamoda много сервисов. Есть сервисы клиентские, которые взаимодействуют непосредственно с нашими пользователями, с пользователями сайта, мобильного приложения. Про них мы говорить не будем. А есть то, что у нас в компании называется глубокие бэкенды — это наши системы бэк-офиса, которые автоматизируют наши бизнес-процессы. К ним относятся доставка, склад, автоматизация фотостудий и колл-центра. Большинство этих сервисов разрабатываются на PHP.
Если говорить кратко про наш стек, то это PHP + Symfony. Кое-где старые проекты на Zend’e. В качестве баз данных используется PostgreSQL и MySQL, в качестве систем обмена сообщениями — Rabbit или Kafka.
Почему PHP-бэкенды?
Потому что у них, как правило, развесистый API — это либо REST, кое-где есть чуть-чуть SOAP’а. Если у них есть UI, то это UI больше вспомогательный, который используют наши внутренние пользователи.
Зачем нам в Lamoda автотесты?
Вообще, когда я пришел работать в Lamoda, там был такой лозунг: “Давайте избавимся от ручного регресса”. Не будем вручную ничего регрессионно тестировать. И мы работали над этой задачей. Собственно, вот одна из главных причин, зачем нам нужны автотесты — чтобы не гонять регресс руками. А зачем нам это нужно? Правильно, чтобы быстро релизить. Чтобы мы могли безболезненно, очень быстро выкатывать наши релизы и при этом иметь некоторую сетку из автотестов, которые нам будут говорить, хорошо или нехорошо. Это, наверное, самые главные цели. Но есть еще парочка вспомогательных, про которые я тоже хочу сказать.
Зачем нужны автотесты?
Ок, поговорили о том, зачем нам нужны автотесты. Теперь поговорим о том, какие тесты мы пишем в Lamoda.
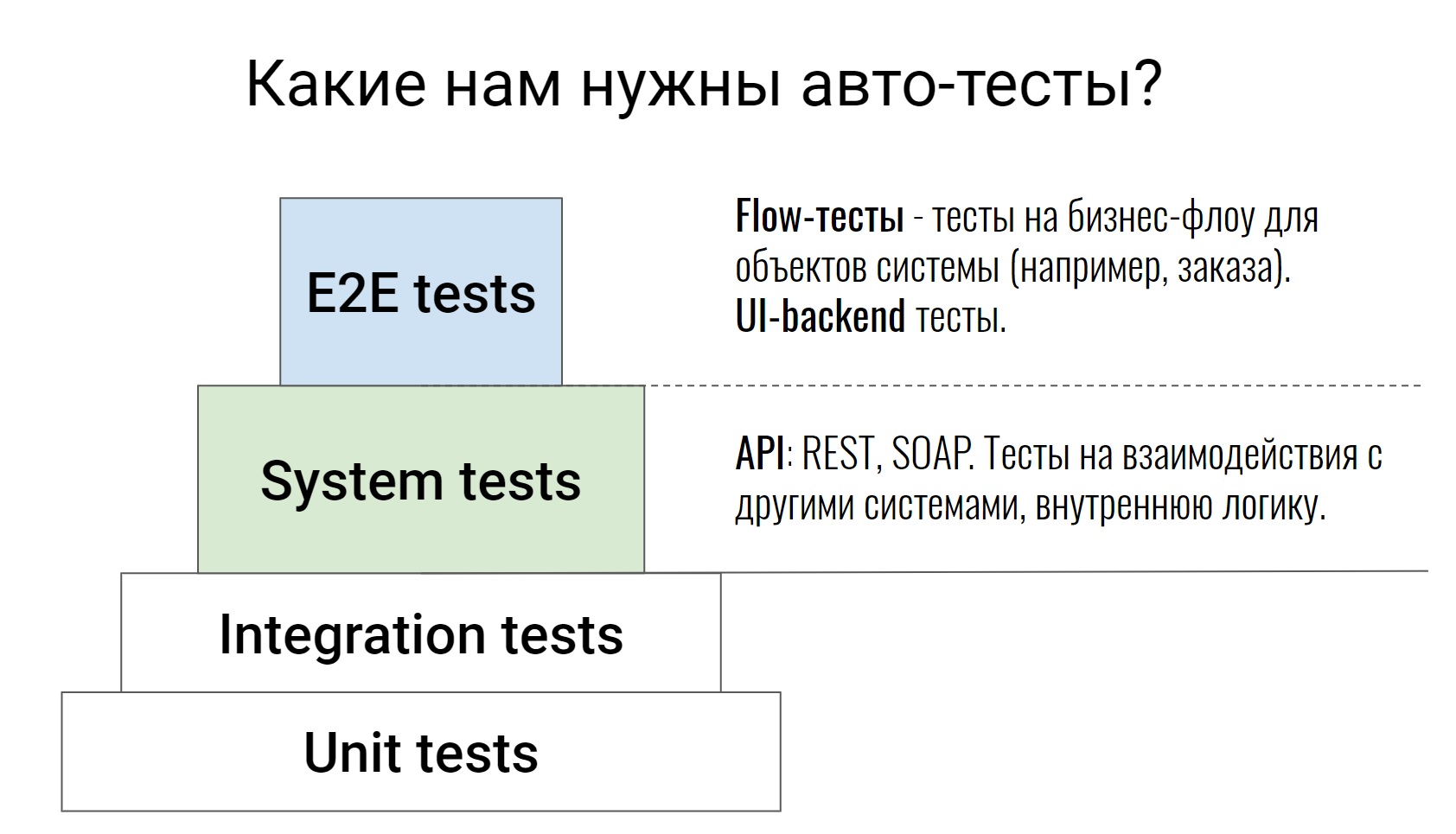
Это достаточно стандартная пирамида тестирования, начиная от unit-тестов, заканчивая E2E-тестами, где тестируются уже некоторые бизнес-цепочки. Про нижние два уровня я говорить не буду, не зря они таким белым цветом закрашены. Это тесты на сам код, их пишут у нас разработчики. Тестировщик, в крайнем случае, может зайти в Pull Request, посмотреть код и сказать: “Ну, что-то тут недостаточно кейсов, давайте покроем еще что-нибудь”. На этом работа тестировщика для этих тестов заканчивается.
Мы будем говорить про уровни выше, которые у нас пишут и разработчики, и тестировщики. Начнем с системных тестов. Это тесты, которые тестируют API (REST или SOAP), тестируют некую внутреннюю логику систем, различные команды, разборы очередей в Rabbit или обмен с внешними системами. Как правило, эти тесты достаточно атомарные. Они не проверяют какую-то цепочку, а проверяют одно действие. Например, один API-метод или одну команду. И проверяют как можно на большем количестве кейсов, как позитивных, так и негативных.
Идем дальше, E2E-тесты. Я их поделил на 2 части. У нас есть тесты, которые тестируют связку UI и бэкенда. И есть тесты, которые мы называем flow-тесты. Они тестируют цепочку — жизнь объекта от начала до конца.
Например, у нас есть система управления процессинга нашими заказами. Внутри такой системы может быть тест — заказ от создания до доставки, то есть прохождение его по всем статусам. Именно по таким тестам потом очень легко и просто смотреть, как работает система. Вы сразу видите весь flow определенных объектов, с какими внешними системами все это взаимодействует, какие команды для этого используются.
Поскольку у нас этим UI пользуются внутренние пользователи, нам не важна кросс-браузерность. Мы не гоняем на каких-то фермах эти тесты, нам достаточно проверить в одном браузере, а иногда даже не нужно использовать браузер.
“Почему Codeception мы выбрали для автоматизации тестирования?” — наверное, спросите вы.
Если честно, у меня нет ответа на этот вопрос. Когда я пришел в Lamoda, Codeception уже был выбран как стандарт, чтобы писать автотесты, и я столкнулся с ним по факту. Но, поработав какое-то время с этим фреймворком, я все-таки понял, почему Codeception. Этим я и хочу с вами поделиться.
Почему Codeception?
Кратко скажу, что из себя представляет Codeception, поскольку многие с ним работали.

Codeception работает по модели акторов. После того, как вы его затягиваете в проект и инициализируете, генерируется такая структура.
У нас есть yml-файлы, вот там снизу — functional.suite.yml, integration.suit.yml, unit.suite.yml. В них создается конфигурация ваших тестов. Есть папочки под каждый вид тестов, где эти тесты лежат, есть 3 вспомогательных папочки:
_data — для тестовых данных;
_output — куда кладутся отчеты (xml, html);
_support — куда кладутся какие-то вспомогательные хелперы, функции и все, что вы напишите, чтобы использовать в ваших тестах.
Для начала я расскажу, что мы взяли от Codeception и используем из коробки, ничего не дорабатывая, не решая дополнительных задач или проблем.
Стандартные модули
Первый такой модуль — это PhpBrowser. Этот модуль — обертка над Guzzle, который позволяет взаимодействовать с вашим приложением: открывать странички, заполнять формы, сабмитить формы. И если вам не важно кроссбраузерное и браузерное тестирование, если вы вдруг тестируете UI, можно использовать PhpBrowser. Как правило, в наших UI-тестах мы его и используем, потому что нам не нужно какой-то сложной логики взаимодействия, нам достаточно открыть страничку и что-то небольшое там сделать.
Второй модуль, который мы используем, — REST. Думаю, из названия понятно, что он делает. Для любых http-взаимодействий можно использовать этот модуль. В нем, мне кажется, решены практически все взаимодействия: хедеры, cookie, авторизация. Все, что нужно, в нем есть.
Третий модуль, который мы используем из коробки, — это модуль Db. В последних версиях Codeception туда добавлена поддержка не одной, а нескольких баз данных. Поэтому, если вдруг у вас в проекте несколько баз данных, теперь это работает из коробки.
Модуль Cli, который позволяет запускать shell — и bash-команды из тестов, и мы его тоже используем.
Есть модуль AMQP, который работает с любыми брокерами сообщений, которые основаны на этом протоколе. Хочу заметить, что официально он протестирован на RabbitMQ. Поскольку мы используем RabbitMQ, у нас с ним все окей.
На самом деле, Codeception, по крайней мере, в нашем случае покрывает 80-85% всех нужных нам задач. Но над кое-чем все-таки пришлось поработать.
Начнем с SOAP.

В наших сервисах кое-где есть SOAP-эндпоинты. Их нужно тестировать, дергать, что-то с ними делать. Но вы скажете, что в Codeception есть такой модуль, который позволяет отправлять запросы и что-то потом делать с ответами. Как-то парсить, проверочки добавлять и все окей. Но SOAP-модуль не работает из коробки с несколькими эндпоинтами SOAP.

У нас, например, есть монолиты, у которых несколько WSDL, несколько SOAP-эндпоинтов. Это означает, что нельзя в Codeception-модуле это так сконфигурировать в yml-файле, чтобы работать сразу с несколькими.

У Codeception есть динамическая реконфигурация модуля, и вы можете написать какой-то свой адаптер, чтобы получать, например, модуль SOAP и динамически его реконфигурировать. В данном случае необходимо подменять эндпоинт и используемую схему. Тогда в тесте, если вам нужно поменять эндпоинт, на который вы хотите отправить запрос, получаем наш адаптер и меняем на новый эндпоинт, на новую схему и отправляем на нее запрос.

В Codeception нет работы с Kafka и нет никаких сторонних более-менее официальных аддонов, чтобы работать с Kafka. В этом нет ничего страшного, мы написали свой модуль.

Так он конфигурируется в yml-файле. Задаются некоторые настройки для брокеров, для консьюмеров и для топиков. Эти настройки, когда вы пишете свой модуль, можно потом подтянуть в модули функцией initialize и этот модуль инициализировать этими же настройками. И, собственно, у модуля реализовать все остальные методы — положить сообщение в топик и считать его. Это все, что вам нужно от этого модуля.

Вывод: модули для Codeception писать легко.
Идем дальше. Как я уже сказал, в Codeception есть модуль Cli — обертка для shell-команд и работы с их output’ом.

Но иногда shell-команду нужно запустить не в тестах, а в приложении. Вообще тесты и приложения — это немного разные сущности, они могут лежать в разных местах. Тесты могут запускаться в одном месте, а приложение может быть в другом.
Так зачем нам нужно запускать shell в тестах?
У нас есть в приложениях команды, которые, например, разбирают очереди в RabbitMQ и двигают объекты по статусам. Эти команды в прод-режиме запускаются из-под супервизора. Супервизор следит за их выполнением. Если они упали, то он их заново запускает и так далее.
Когда мы тестируем, супервизор у нас не запущен. Иначе тесты становятся нестабильными, непредсказуемыми. Мы сами хотим управлять запуском этих команд внутри приложения. Поэтому нам нужно из тестов запустить эти команды в приложении. У нас используются два варианта. Что один, что другой — в принципе, все то же самое, и все работает.
Как запускать shell в приложении?
Первое: запускать тесты в том же самом месте, где находится приложение. Поскольку все приложения у нас в Docker’е, тесты можно запускать в том же контейнере, где находится сам сервис.
Второй вариант: делать под тесты отдельный контейнер, некоторый test runner, но делать его таким же, как приложение. То есть из того же Docker-образа, и тогда все будет работать аналогично.

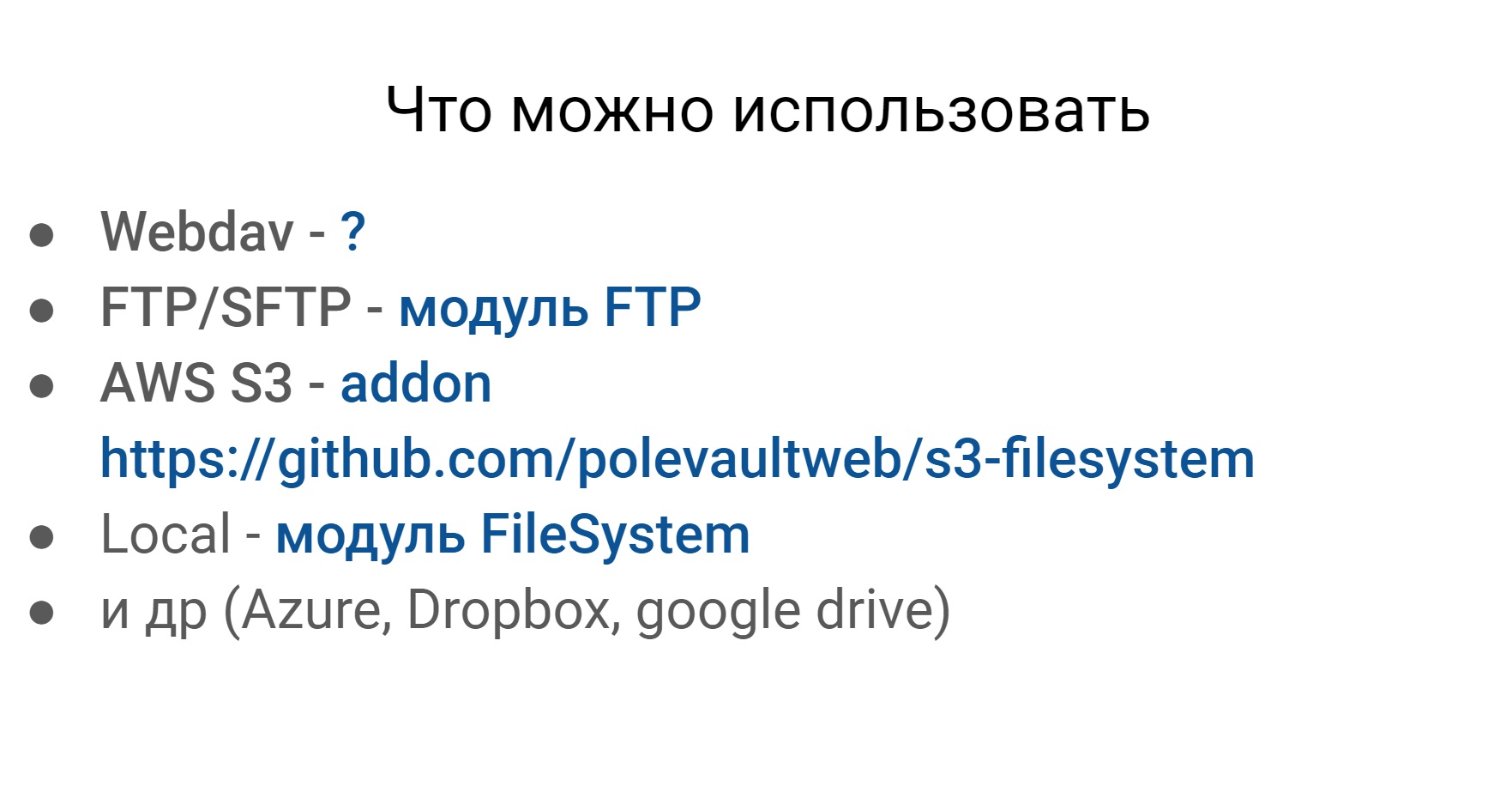
Еще одна задача, с которой мы столкнулись в тестах — это работа с различными файловыми системами. Ниже пример того, с чем можно и нужно работать. Для нас актуальны первые три. Это Webdav, SFTP и амазоновская файловая система.
С чем нужно работать?
Если порыться в Codeception, можно найти какие-то модули практически для любой более-менее популярной файловой системы.
Единственное, что я не нашел, это для Webdav’a. Но эти файловый системы плюс-минус одинаковые в плане внешней работы с ними, и нам хочется работать с ними одинаково.
Мы написали свой модуль, который называется Flysystem. Он лежит на Github в открытом доступе и поддерживает 2 файловые системы — SFTP и Webdav — и позволяет работать с обеими по одинаковому API.

Получить список файлов, почистить директорию, записать файл, и так далее. Если туда добавить еще и амазоновскую файловую систему, наши потребности точно покроются.
Следующий момент, я считаю, очень важный для автотестов, тем более системного уровня, — это работа с базами данных. Вообще, хочется чтобы было, как на картинке, — ВЖУХ и все завелось, заработало, и вот эти базы данных в тестах меньше бы поддерживать.

Какие я вижу здесь основные задачи:
Для всех 3-х задач в Codeception есть 2 модуля — Db, про который я уже говорил, другой называется Fixtures.
Из этих 2 модулей и 3 задач мы используем только DB для третьей задачи.
Для первой задачи можно использовать DB. Там можно сконфигурировать SQL-дамп, из которого будет разворачиваться база данных, ну и модуль с фикстурами, думаю, понятно, зачем нужен.
Там будут фикстуры в виде массивов, которые можно персистить в базу данных.
Как я сказал, первые 2 задачи мы решаем немного по-другому, сейчас я расскажу, как мы это делаем.
Разворачивание БД
Первое — про разворачивание базы данных. Каким образом у нас происходит это в тестах. Мы поднимаем контейнер с нужной базой данных — либо PostgreSQL, либо MySQL, потом накатываем все нужные миграции с помощью doctrine migrations. Все, база данных нужной структуры готова, ее можно использовать в тестах.
Почему мы не используем дапм — потому что тогда его не нужно поддерживать. Это какой-то дамп, который лежит с тестами, который нужно постоянно актуализировать, если что-то меняется в базе данных. Есть миграции — не нужно поддерживать дамп.
Второй момент — создание тестовых данных. Мы не используем модуль Fixtures от Codeception, мы используем Symfony-бандл для фикстур.

Здесь есть ссылка на него и пример того, как можно создавать фикстуру в базу данных.
У вас фикстура тогда будет создаваться как некоторый объект предметной области, ее можно заперсистить в базу данных, и тестовые данные будут готовы.
Почему DoctrineFixtureBundle?
Почему мы его используем? Да по той же причине — эти фикстуры гораздо проще поддерживать, чем фикстуры от Codeception. Проще создавать цепочки связанных объектов, потому что это все заложено в Symfony-бандл. Нужно меньше дублировать данные, потому что фикстуры можно наследовать, это классы. Если меняется структура базы данных, эти массивы всегда нужно править, а классы — не всегда. Фикстуры в виде объектов предметной области всегда нагляднее, чем массивы.
Про базы данных поговорили, поговорим немного про моки.
Поскольку это тесты достаточно высокого уровня, которые тестируют систему целиком и поскольку наши системы достаточно сильно взаимосвязаны, понятно, что есть некоторые обмены и взаимодействия. Сейчас мы поговорим про моки на взаимодействие между системами.
Правила для моков
Взаимодействия — это некоторые http-взаимодействия по REST или SOAP. Все эти взаимодействия в рамках тестов мы мокируем. То есть у нас в тестах нигде не идет реального обращения к внешним системам. Это делает тесты стабильными. Потому что внешний сервис может работать, может не работать, может медленно отвечать, может быстро, в общем, неизвестно, какое у него поведение. Поэтому мы все это покрываем моками.
Еще у нас есть такое правило. Мы мокаем не только позитивные взаимодействия, но и стараемся проверять какие-то негативные кейсы. Например, когда сторонний сервис отвечает 500ой ошибкой либо выдает какую-то более осмысленную ошибку, — это все стараемся проверять.
Для моков мы используем Wiremock, сам Codeception поддерживает…, у него есть такой официальный аддон Httpmock, но Wiremock нам понравился больше. Каким образом он работает?
Wiremock поднимается как отдельный Docker-контейнер во время тестов, и все запросы, который должны идти ко внешней системе, идут на Wiremock.
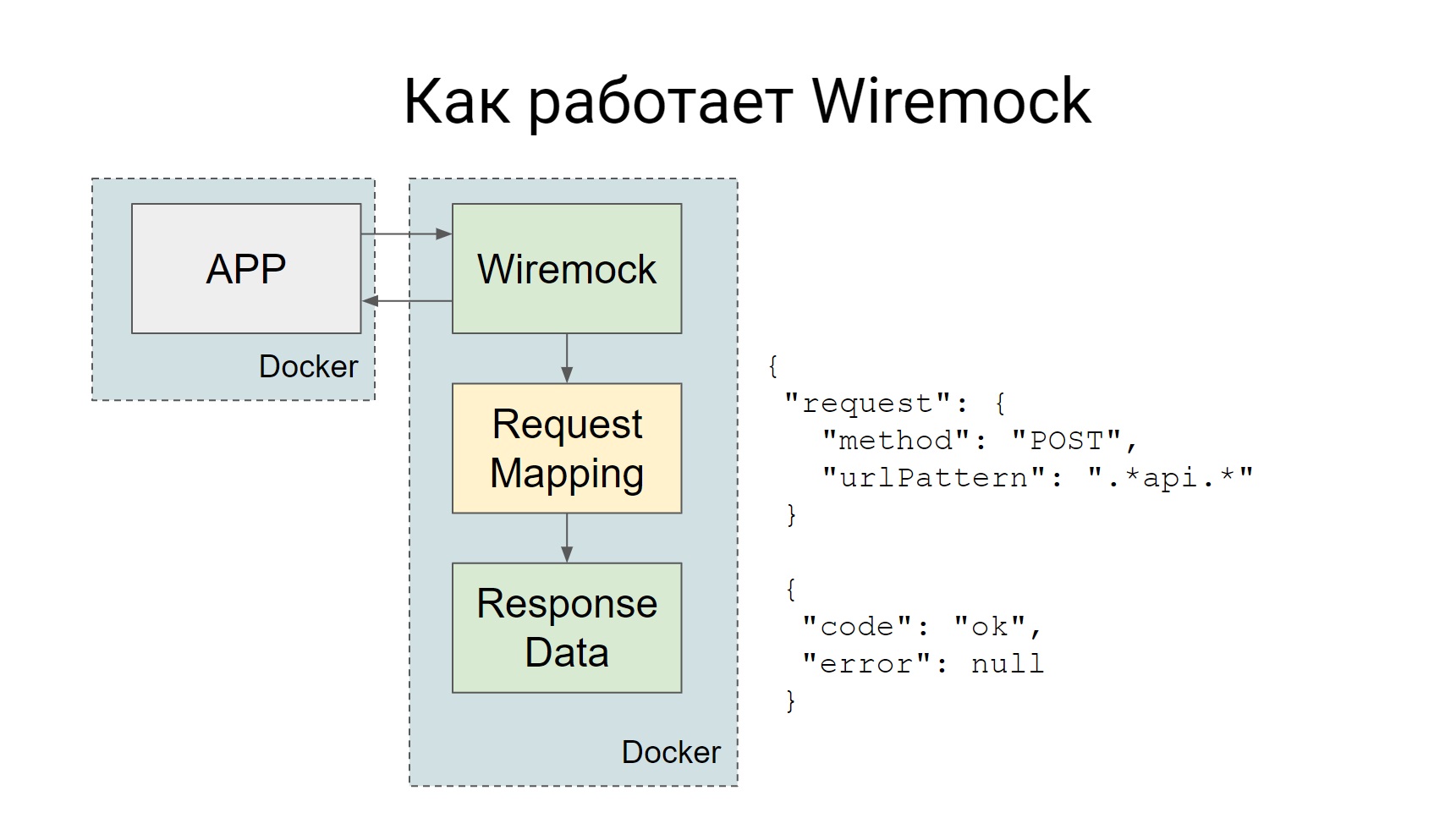
У Wiremock, если посмотреть на слайд — там есть такой квадратик, Request Mapping, у него есть набор таких маппингов, которые говорят о том, что, если пришел такой запрос, надо отдать такой ответ. Все очень просто: пришел запрос — получил мок.
Моки можно создавать статически, тогда контейнер, когда уже с Wiremock поднимется, эти моки будут доступны, их можно использовать в ручном тестировании. Можно создавать динамически, прямо в коде, в каком-нибудь тесте.
Здесь приведен пример, как создать мок динамически, вы видите, описание достаточно декларативное, из кода сразу понятно, что за мок мы создаем: мок для метода GET, который придет на такой URL, и, собственно, что вернуть.

Кроме того, что этот мок можно создать, у Wiremock есть возможность потом еще и проверить, какой запрос ушел на этот мок. Это тоже бывает очень полезно в тестах.
Про сам Codeception, наверное, все, и несколько слов о том, как запускаются наши тесты, и немного инфраструктурщины.
Что у нас используется?

Ну, во-первых, все сервисы у нас в Docker, поэтому запуск тестового окружения представляет собой поднятие нужных контейнеров.
Для внутренних команд используется Make, в качестве CI используется Bamboo.
Как выглядит запуск тестов на CI?

Сначала мы билдим нужную версию приложения, потом поднимаем окружение — это приложение, все сервисы, которые ему нужны, вроде Kafka, Rabbit, база данных и на базу данных мы накатываем миграцию.
Все это окружение поднимается с помощью Docker Compose. Именно в CI, на проде все контейнеры крутятся под Kubernetes. Затем запускаем тесты и прогоняем.
Сколько времени это все занимает?
Все зависит от конкретного сервиса, но, как правило, подъем окружения до запуска тестов — это 5-10 минут, тесты — от 6 до 30 минут.

Сразу предупрежу этот вопрос, пока все тесты гоняются в одном потоке.
Ну и такой вопрос. Как часто надо запускать тесты? Конечно, чем чаще, тем лучше. Чем раньше вы сможете поймать проблему, тем быстрее вы сможете ее решить.
У нас есть 2 главных правила. Когда задача переходит в тестирование, на ней должны проходить все тесты, и unit, и не unit-тесты. Если какие-то тесты не проходят, это повод перевести задачу в фиксинг.
Естественно, когда мы выкатываем релиз. На релизе все тесты должны обязательно проходить.
В конце мне хотелось бы сказать что-то воодушевляющее — пишите тесты, пусть они будут зелеными, используйте Codeception, делайте моки. Думаю, вы все это прекрасно понимаете.
Речь пойдет про Codeception, про то, как мы его используем в Lamoda и как на нем пишем тесты.
В Lamoda много сервисов. Есть сервисы клиентские, которые взаимодействуют непосредственно с нашими пользователями, с пользователями сайта, мобильного приложения. Про них мы говорить не будем. А есть то, что у нас в компании называется глубокие бэкенды — это наши системы бэк-офиса, которые автоматизируют наши бизнес-процессы. К ним относятся доставка, склад, автоматизация фотостудий и колл-центра. Большинство этих сервисов разрабатываются на PHP.
Если говорить кратко про наш стек, то это PHP + Symfony. Кое-где старые проекты на Zend’e. В качестве баз данных используется PostgreSQL и MySQL, в качестве систем обмена сообщениями — Rabbit или Kafka.
Почему PHP-бэкенды?
Потому что у них, как правило, развесистый API — это либо REST, кое-где есть чуть-чуть SOAP’а. Если у них есть UI, то это UI больше вспомогательный, который используют наши внутренние пользователи.
Зачем нам в Lamoda автотесты?
Вообще, когда я пришел работать в Lamoda, там был такой лозунг: “Давайте избавимся от ручного регресса”. Не будем вручную ничего регрессионно тестировать. И мы работали над этой задачей. Собственно, вот одна из главных причин, зачем нам нужны автотесты — чтобы не гонять регресс руками. А зачем нам это нужно? Правильно, чтобы быстро релизить. Чтобы мы могли безболезненно, очень быстро выкатывать наши релизы и при этом иметь некоторую сетку из автотестов, которые нам будут говорить, хорошо или нехорошо. Это, наверное, самые главные цели. Но есть еще парочка вспомогательных, про которые я тоже хочу сказать.
Зачем нужны автотесты?
- Не тестировать регресс руками
- Быстро релизить
- Использовать в качестве документации
- Ускорить onboarding новых сотрудников
- Автотесты удобно использовать (в некоторых случаях) в качестве документации. Иногда проще зайти в тесты, посмотреть, какие кейсы покрыты, как они работают, и понять, как работает тот или иной функционал, и ускорить вхождение новых сотрудников — как разработчиков, так и тестировщиков, — в новый проект. Когда садишься писать автотесты, сразу становится понятно, как работает система.
Ок, поговорили о том, зачем нам нужны автотесты. Теперь поговорим о том, какие тесты мы пишем в Lamoda.
Это достаточно стандартная пирамида тестирования, начиная от unit-тестов, заканчивая E2E-тестами, где тестируются уже некоторые бизнес-цепочки. Про нижние два уровня я говорить не буду, не зря они таким белым цветом закрашены. Это тесты на сам код, их пишут у нас разработчики. Тестировщик, в крайнем случае, может зайти в Pull Request, посмотреть код и сказать: “Ну, что-то тут недостаточно кейсов, давайте покроем еще что-нибудь”. На этом работа тестировщика для этих тестов заканчивается.
Мы будем говорить про уровни выше, которые у нас пишут и разработчики, и тестировщики. Начнем с системных тестов. Это тесты, которые тестируют API (REST или SOAP), тестируют некую внутреннюю логику систем, различные команды, разборы очередей в Rabbit или обмен с внешними системами. Как правило, эти тесты достаточно атомарные. Они не проверяют какую-то цепочку, а проверяют одно действие. Например, один API-метод или одну команду. И проверяют как можно на большем количестве кейсов, как позитивных, так и негативных.
Идем дальше, E2E-тесты. Я их поделил на 2 части. У нас есть тесты, которые тестируют связку UI и бэкенда. И есть тесты, которые мы называем flow-тесты. Они тестируют цепочку — жизнь объекта от начала до конца.
Например, у нас есть система управления процессинга нашими заказами. Внутри такой системы может быть тест — заказ от создания до доставки, то есть прохождение его по всем статусам. Именно по таким тестам потом очень легко и просто смотреть, как работает система. Вы сразу видите весь flow определенных объектов, с какими внешними системами все это взаимодействует, какие команды для этого используются.
Поскольку у нас этим UI пользуются внутренние пользователи, нам не важна кросс-браузерность. Мы не гоняем на каких-то фермах эти тесты, нам достаточно проверить в одном браузере, а иногда даже не нужно использовать браузер.
“Почему Codeception мы выбрали для автоматизации тестирования?” — наверное, спросите вы.
Если честно, у меня нет ответа на этот вопрос. Когда я пришел в Lamoda, Codeception уже был выбран как стандарт, чтобы писать автотесты, и я столкнулся с ним по факту. Но, поработав какое-то время с этим фреймворком, я все-таки понял, почему Codeception. Этим я и хочу с вами поделиться.
Почему Codeception?
- Можно писать и запускать одинаково тесты любых видов (unit, functional, acceptance).
- Многие грабли уже решены, много модулей уже написано.
- Во всех проектах, несмотря на немного разные потребности, тесты будут выглядеть одинаково.
- Концепция Codeception предполагает, что на этом фреймворке вы пишете любые тесты: unit, интеграционные, функциональные, приемочные. И они у вас, по крайней мере, будут одинаково запускаться.
- Codeception — это достаточно мощный комбайн, в котором уже решено много проблем, много вопросов, много задач для тестов. Если что-то не решено, то скорее всего, вы найдете что-то извне — некоторый аддон для какой-то специфической работы. Вам не нужно писать какие-то тестовые обертки для баз данных, для еще чего-то. Просто берете и подключаете к Codeception модули и работаете с ними.
- Ну и такой плюс (наверное, он больше подходит для больших компаний, когда у вас много проектов и сервисов) — во всех проектах тесты будут выглядеть плюс-минус одинаково. Это очень здорово.
Кратко скажу, что из себя представляет Codeception, поскольку многие с ним работали.
Codeception работает по модели акторов. После того, как вы его затягиваете в проект и инициализируете, генерируется такая структура.
У нас есть yml-файлы, вот там снизу — functional.suite.yml, integration.suit.yml, unit.suite.yml. В них создается конфигурация ваших тестов. Есть папочки под каждый вид тестов, где эти тесты лежат, есть 3 вспомогательных папочки:
_data — для тестовых данных;
_output — куда кладутся отчеты (xml, html);
_support — куда кладутся какие-то вспомогательные хелперы, функции и все, что вы напишите, чтобы использовать в ваших тестах.
Для начала я расскажу, что мы взяли от Codeception и используем из коробки, ничего не дорабатывая, не решая дополнительных задач или проблем.
Стандартные модули
- PhpBrowser
- REST
- Db
- Cli
- AMQP
Первый такой модуль — это PhpBrowser. Этот модуль — обертка над Guzzle, который позволяет взаимодействовать с вашим приложением: открывать странички, заполнять формы, сабмитить формы. И если вам не важно кроссбраузерное и браузерное тестирование, если вы вдруг тестируете UI, можно использовать PhpBrowser. Как правило, в наших UI-тестах мы его и используем, потому что нам не нужно какой-то сложной логики взаимодействия, нам достаточно открыть страничку и что-то небольшое там сделать.
Второй модуль, который мы используем, — REST. Думаю, из названия понятно, что он делает. Для любых http-взаимодействий можно использовать этот модуль. В нем, мне кажется, решены практически все взаимодействия: хедеры, cookie, авторизация. Все, что нужно, в нем есть.
Третий модуль, который мы используем из коробки, — это модуль Db. В последних версиях Codeception туда добавлена поддержка не одной, а нескольких баз данных. Поэтому, если вдруг у вас в проекте несколько баз данных, теперь это работает из коробки.
Модуль Cli, который позволяет запускать shell — и bash-команды из тестов, и мы его тоже используем.
Есть модуль AMQP, который работает с любыми брокерами сообщений, которые основаны на этом протоколе. Хочу заметить, что официально он протестирован на RabbitMQ. Поскольку мы используем RabbitMQ, у нас с ним все окей.
На самом деле, Codeception, по крайней мере, в нашем случае покрывает 80-85% всех нужных нам задач. Но над кое-чем все-таки пришлось поработать.
Начнем с SOAP.
В наших сервисах кое-где есть SOAP-эндпоинты. Их нужно тестировать, дергать, что-то с ними делать. Но вы скажете, что в Codeception есть такой модуль, который позволяет отправлять запросы и что-то потом делать с ответами. Как-то парсить, проверочки добавлять и все окей. Но SOAP-модуль не работает из коробки с несколькими эндпоинтами SOAP.
У нас, например, есть монолиты, у которых несколько WSDL, несколько SOAP-эндпоинтов. Это означает, что нельзя в Codeception-модуле это так сконфигурировать в yml-файле, чтобы работать сразу с несколькими.
У Codeception есть динамическая реконфигурация модуля, и вы можете написать какой-то свой адаптер, чтобы получать, например, модуль SOAP и динамически его реконфигурировать. В данном случае необходимо подменять эндпоинт и используемую схему. Тогда в тесте, если вам нужно поменять эндпоинт, на который вы хотите отправить запрос, получаем наш адаптер и меняем на новый эндпоинт, на новую схему и отправляем на нее запрос.
В Codeception нет работы с Kafka и нет никаких сторонних более-менее официальных аддонов, чтобы работать с Kafka. В этом нет ничего страшного, мы написали свой модуль.
Так он конфигурируется в yml-файле. Задаются некоторые настройки для брокеров, для консьюмеров и для топиков. Эти настройки, когда вы пишете свой модуль, можно потом подтянуть в модули функцией initialize и этот модуль инициализировать этими же настройками. И, собственно, у модуля реализовать все остальные методы — положить сообщение в топик и считать его. Это все, что вам нужно от этого модуля.
Вывод: модули для Codeception писать легко.
Идем дальше. Как я уже сказал, в Codeception есть модуль Cli — обертка для shell-команд и работы с их output’ом.
Но иногда shell-команду нужно запустить не в тестах, а в приложении. Вообще тесты и приложения — это немного разные сущности, они могут лежать в разных местах. Тесты могут запускаться в одном месте, а приложение может быть в другом.
Так зачем нам нужно запускать shell в тестах?
У нас есть в приложениях команды, которые, например, разбирают очереди в RabbitMQ и двигают объекты по статусам. Эти команды в прод-режиме запускаются из-под супервизора. Супервизор следит за их выполнением. Если они упали, то он их заново запускает и так далее.
Когда мы тестируем, супервизор у нас не запущен. Иначе тесты становятся нестабильными, непредсказуемыми. Мы сами хотим управлять запуском этих команд внутри приложения. Поэтому нам нужно из тестов запустить эти команды в приложении. У нас используются два варианта. Что один, что другой — в принципе, все то же самое, и все работает.
Как запускать shell в приложении?
Первое: запускать тесты в том же самом месте, где находится приложение. Поскольку все приложения у нас в Docker’е, тесты можно запускать в том же контейнере, где находится сам сервис.
Второй вариант: делать под тесты отдельный контейнер, некоторый test runner, но делать его таким же, как приложение. То есть из того же Docker-образа, и тогда все будет работать аналогично.
Еще одна задача, с которой мы столкнулись в тестах — это работа с различными файловыми системами. Ниже пример того, с чем можно и нужно работать. Для нас актуальны первые три. Это Webdav, SFTP и амазоновская файловая система.
С чем нужно работать?
- Webdav
- FTP/SFTP
- AWS S3
- Local
- Azure, Dropbox, google drive
Если порыться в Codeception, можно найти какие-то модули практически для любой более-менее популярной файловой системы.
Единственное, что я не нашел, это для Webdav’a. Но эти файловый системы плюс-минус одинаковые в плане внешней работы с ними, и нам хочется работать с ними одинаково.
Мы написали свой модуль, который называется Flysystem. Он лежит на Github в открытом доступе и поддерживает 2 файловые системы — SFTP и Webdav — и позволяет работать с обеими по одинаковому API.
Получить список файлов, почистить директорию, записать файл, и так далее. Если туда добавить еще и амазоновскую файловую систему, наши потребности точно покроются.
Следующий момент, я считаю, очень важный для автотестов, тем более системного уровня, — это работа с базами данных. Вообще, хочется чтобы было, как на картинке, — ВЖУХ и все завелось, заработало, и вот эти базы данных в тестах меньше бы поддерживать.
Какие я вижу здесь основные задачи:
- Как раскатать БД нужной структуры — Db
- Как заполнить БД тестовыми данными — Db, Fixtures
- Как делать выборки и проверки — Db
Для всех 3-х задач в Codeception есть 2 модуля — Db, про который я уже говорил, другой называется Fixtures.
Из этих 2 модулей и 3 задач мы используем только DB для третьей задачи.
Для первой задачи можно использовать DB. Там можно сконфигурировать SQL-дамп, из которого будет разворачиваться база данных, ну и модуль с фикстурами, думаю, понятно, зачем нужен.
Там будут фикстуры в виде массивов, которые можно персистить в базу данных.
Как я сказал, первые 2 задачи мы решаем немного по-другому, сейчас я расскажу, как мы это делаем.
Разворачивание БД
- Поднимаем контейнер с PostgreSQL или MySQL
- Накатываем все миграции с помощью doctrine migrations
Первое — про разворачивание базы данных. Каким образом у нас происходит это в тестах. Мы поднимаем контейнер с нужной базой данных — либо PostgreSQL, либо MySQL, потом накатываем все нужные миграции с помощью doctrine migrations. Все, база данных нужной структуры готова, ее можно использовать в тестах.
Почему мы не используем дапм — потому что тогда его не нужно поддерживать. Это какой-то дамп, который лежит с тестами, который нужно постоянно актуализировать, если что-то меняется в базе данных. Есть миграции — не нужно поддерживать дамп.
Второй момент — создание тестовых данных. Мы не используем модуль Fixtures от Codeception, мы используем Symfony-бандл для фикстур.
Здесь есть ссылка на него и пример того, как можно создавать фикстуру в базу данных.
У вас фикстура тогда будет создаваться как некоторый объект предметной области, ее можно заперсистить в базу данных, и тестовые данные будут готовы.
Почему DoctrineFixtureBundle?
- Проще создавать цепочки связанных объектов.
- Меньше дупликации данных, если фикстуры для разных тестов похожи.
- Меньше правок при изменении структуры БД.
- Фикстуры-классы гораздо нагляднее чем массивы.
Почему мы его используем? Да по той же причине — эти фикстуры гораздо проще поддерживать, чем фикстуры от Codeception. Проще создавать цепочки связанных объектов, потому что это все заложено в Symfony-бандл. Нужно меньше дублировать данные, потому что фикстуры можно наследовать, это классы. Если меняется структура базы данных, эти массивы всегда нужно править, а классы — не всегда. Фикстуры в виде объектов предметной области всегда нагляднее, чем массивы.
Про базы данных поговорили, поговорим немного про моки.
Поскольку это тесты достаточно высокого уровня, которые тестируют систему целиком и поскольку наши системы достаточно сильно взаимосвязаны, понятно, что есть некоторые обмены и взаимодействия. Сейчас мы поговорим про моки на взаимодействие между системами.
Правила для моков
- Мокаем все внешние http-взаимодейтвия сервиса
- Проверяем не только позитивные, но и негативные сценарии
Взаимодействия — это некоторые http-взаимодействия по REST или SOAP. Все эти взаимодействия в рамках тестов мы мокируем. То есть у нас в тестах нигде не идет реального обращения к внешним системам. Это делает тесты стабильными. Потому что внешний сервис может работать, может не работать, может медленно отвечать, может быстро, в общем, неизвестно, какое у него поведение. Поэтому мы все это покрываем моками.
Еще у нас есть такое правило. Мы мокаем не только позитивные взаимодействия, но и стараемся проверять какие-то негативные кейсы. Например, когда сторонний сервис отвечает 500ой ошибкой либо выдает какую-то более осмысленную ошибку, — это все стараемся проверять.
Для моков мы используем Wiremock, сам Codeception поддерживает…, у него есть такой официальный аддон Httpmock, но Wiremock нам понравился больше. Каким образом он работает?
Wiremock поднимается как отдельный Docker-контейнер во время тестов, и все запросы, который должны идти ко внешней системе, идут на Wiremock.
У Wiremock, если посмотреть на слайд — там есть такой квадратик, Request Mapping, у него есть набор таких маппингов, которые говорят о том, что, если пришел такой запрос, надо отдать такой ответ. Все очень просто: пришел запрос — получил мок.
Моки можно создавать статически, тогда контейнер, когда уже с Wiremock поднимется, эти моки будут доступны, их можно использовать в ручном тестировании. Можно создавать динамически, прямо в коде, в каком-нибудь тесте.
Здесь приведен пример, как создать мок динамически, вы видите, описание достаточно декларативное, из кода сразу понятно, что за мок мы создаем: мок для метода GET, который придет на такой URL, и, собственно, что вернуть.
Кроме того, что этот мок можно создать, у Wiremock есть возможность потом еще и проверить, какой запрос ушел на этот мок. Это тоже бывает очень полезно в тестах.
Про сам Codeception, наверное, все, и несколько слов о том, как запускаются наши тесты, и немного инфраструктурщины.
Что у нас используется?
Ну, во-первых, все сервисы у нас в Docker, поэтому запуск тестового окружения представляет собой поднятие нужных контейнеров.
Для внутренних команд используется Make, в качестве CI используется Bamboo.
Как выглядит запуск тестов на CI?
Сначала мы билдим нужную версию приложения, потом поднимаем окружение — это приложение, все сервисы, которые ему нужны, вроде Kafka, Rabbit, база данных и на базу данных мы накатываем миграцию.
Все это окружение поднимается с помощью Docker Compose. Именно в CI, на проде все контейнеры крутятся под Kubernetes. Затем запускаем тесты и прогоняем.
Сколько времени это все занимает?
Все зависит от конкретного сервиса, но, как правило, подъем окружения до запуска тестов — это 5-10 минут, тесты — от 6 до 30 минут.
Сразу предупрежу этот вопрос, пока все тесты гоняются в одном потоке.
Ну и такой вопрос. Как часто надо запускать тесты? Конечно, чем чаще, тем лучше. Чем раньше вы сможете поймать проблему, тем быстрее вы сможете ее решить.
У нас есть 2 главных правила. Когда задача переходит в тестирование, на ней должны проходить все тесты, и unit, и не unit-тесты. Если какие-то тесты не проходят, это повод перевести задачу в фиксинг.
Естественно, когда мы выкатываем релиз. На релизе все тесты должны обязательно проходить.
В конце мне хотелось бы сказать что-то воодушевляющее — пишите тесты, пусть они будут зелеными, используйте Codeception, делайте моки. Думаю, вы все это прекрасно понимаете.



