
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Меня зовут Юрий, я руководитель группы системного администрирования в Ситимобил. Сегодня поделюсь опытом работы с технологией тонкого резервирования (thin provisioning) файловых систем Linux и расскажу, как ее можно применять в технологических CI/CD-процессах компании. Мы разберем ситуацию, когда для автоматического тестирования кода при доставке его в production нам как можно быстрее необходимы копии БД MySQL, максимально приближенные к «боевой» версии, доступные на чтение и на запись.
Введение: зачем давать вредные советы?
Логичный вопрос, ведь есть отработанные механизмы миграций схем БД в тестовые среды. Зачем вообще доводить основную нешардированную СУБД до таких объемов? Да и для тестирования нужны не все данные. Постараюсь объяснить.
Примерно год назад на фоне активного роста нашего агрегатора такси (за 2018 год выросли по завершенным поездкам примерно в 15 раз), выросли объемы данных, нагрузка на серверы, частота выкаток. Мы оказались в следующей ситуации:
- Основная БД MySQL увеличилась примерно до 1000 таблиц общим объемом в 2,5 Тб, и продолжала расти.
- Не было возможности быстро зашардироваться и разнести базу. Это не позволял старый подход «пишу в базу что хочу и как хочу», куча JOIN’ов и внутренних зависимостей таблиц.
- Не было механизма миграций схемы БД в тестовые окружения.
- Не было автоматического тестирования кода при выкатке в эксплуатацию.
Последнюю проблему хотелось решить максимально быстро. Были уже написаны тесты Postman для проверки основного PHP-монолита, но не хватало актуальной базы данных. При этом мы не могли создавать ночью реплику, делать ее мастером и отдавать на растерзание днем: очень большое количество выкаток и изменений, в том числе в данных и схеме БД, сделали бы стенд неработоспособным уже к середине дня. Да и ограничивать выкатки всего лишь рабочим днем было бы неэффективно.
Тем не менее, задача была выполнена: первый рабочий стенд мы получили уже через две недели. За прошедший год он претерпел много изменений и продолжает использоваться.
Далее я подробно опишу все шаги и этапы развития нашего решения. Вы убедитесь, что этот метод заслуживает право на существование.
Что такое «тонкое резервирование»?
Это аппаратная или программная технологий (другое название — sparse volumes), позволяющая выделять большее количество требуемого ресурса, чем есть в наличии. При этом выделяемый объем должен соответствовать критериям just-enough (столько, сколько нужно) и just-in-time (за необходимое время). В основном тонкое резервирование применяется в различных СХД, чтобы предоставлять дисковое пространство в необходимых объемах, превышающих фактически доступные. Технология поддерживается различными файловыми системами, например, LVM2, ZFS, BTRFS. Она широко используется в гипервизорах виртуализации. Нам тонкое резервирование позволяло быстро создать из снапшотов основного раздела с данными столько копий этого раздела, сколько нам нужно (data-директория СУБД MySQL).
Первый стенд, технология Thin LVM
Это главу можно ещё назвать «Как сделать максимально быстрые снапшоты больших объемов данных с помощью Thin LVM, уменьшив стабильность файловой системы и СУБД MySQL до неприличных показателей».
Поскольку мы уже использовали LVM для построения основных разделов ОС, то решили начать именно с нее. Для начала нам потребовалась отдельная физическая машина — реплика нашей основной базы MySQL, на которой мы могли бы по запросу создавать снапшот реплики и поднимать его рядом отдельным экземпляром MySQL. На время тестирования мы разрешили применять на этом экземпляре изменяющие операции, и по завершении тестов благополучно его удаляли. Конфигурация сервера была такой:
- 2 x Intel Silver 4114 (10x2,2 ГГц HT)
- 8 x 32 ГБ DDR4
- 8 x 1920 ГБ Intel SSD в RAID-контроллер Adaptec в RAID-10
На тему выбора между RAID-контроллером и программным RAID MD можно писать отдельную статью. Скажу лишь, что наш выбор повлияли два фактора:
- Во времена постановки задачи мы все СУБД ставили на RAID-контроллеры, поэтому можно сказать, что так сложилось исторически.
- Различие в производительности на синтетических тестах файловой системы и тестах с различными операциями в MySQL было минимальным.
Мы разделили получившийся RAID-10: сделали единый Volume Group (VG) на весь объем (с накладными расходами примерно 6,7 Гб) и создали логический раздел (Logical Volume, LV) под систему на 50 Гб. В обычной ситуации все остальное место мы определяем под раздел c MySQL. Но нам нужно было тонкое резервирование, поэтому сначала мы создали так называемый pool, внутри которого создали раздел под /var/lib/mysql на 3,5 Тб (исходя из предполагаемых объемов БД):
lvcreate -l 100%FREE -T vga/thin
lvcreate -V 3.5T -T vga/thin -n mysqlОтформатировали раздел в ext4, примонтировали его, записали реплику и получили исходный стенд. Затем сделали обвязку в виде API, который должен создавать снапшоты, поднимать экземпляр БД MySQL на заданном порте и удалять созданный экземпляр. Поскольку при этом используются исключительно системные вызовы, в качестве языка написания скриптов мы выбрали обычный bash, а в качестве провязки API HTTP → bash развернули open source-решение goexpose, написанное на Go.
Когда-нибудь мы выложим наши bash-скрипты в open source, а пока я просто опишу основной алгоритм:
Создание основного снапшота snapmain:
- Останавливаем основную реплику.
- Ставим блокировку на операции со снапшотом snapmain.
- Создаем новый снапшот snapmain.
- Запускаем MySQL и убираем блокировку.
Создание БД на произвольном порте из snapmain:
- Ставим блокировку на конкретный экземпляр БД (порт).
- Проверяем наличие блокировки создания основного снапшота. Если она есть, то ждем и перепроверяем каждые 5 секунд.
- Проверяем, есть ли старый LV-раздел экземпляра.
3.1 Если есть, то останавливаем с помощью kill -9 экземпляр MySQL и удаляем LV-раздел. - Создаем из snapmain новый экземпляр.
- Готовим и монтируем директории для этого экземпляра.
- Убираем признаки слэйва (файлы) и запускаем экземпляр MySQL.
- Делаем из него мастер.
- Убираем блокировку.
Удаление БД на произвольном порте:
- Ставим блокировку на конкретный экземпляр БД (порт).
- Убиваем экземпляр MySQL с помощью kill -9.
- Отмонтируем директории.
- Удаляем LV-раздел и снимаем блокировку.
Пример команд для клонирования разделов нового экземпляра БД:
lvcreate -n stage_3307 -s vga/snapmain
lvchange -ay -K vga/stage_3307
mount -o noatime,nodiratime,data=writeback /dev/mapper/vga-stage_3307 /mnt/stage_3307Теперь расскажу про основную проблему, с которой мы столкнулись при использовании тонкого резервирования. Мы уперлись в производительность SSD-дисков. Произошло это из-за особенностей Thin LVM: она в своей основе оперирует на уровне устройства низкоуровневыми чанками размером по умолчанию в 4 Мб. Как это выглядело:
- Создаем снапшот из основного раздела /var/lib/mysql.
- Запускаем репликацию, чтобы догнать мастера.
- Любое изменение в таблицах реплики заставляет сохранять старые, неизмененные чанки данных в разделе снапшота.
- Любое изменение в поднятом тестовом экземпляре заставляет сохранять старые, неизмененные чанки данных в разделе склонированного снапшота для этого экземпляра.
- Получаем загруженность операций ввода-вывода в 100% на устройство, замедление любых операций и постепенное отставание реплики.
- К концу рабочего дня получаем отставший на несколько часов стенд.
Как мы с этим боролись, чтобы получить более вменяемый результат (основные моменты):
RAID-контроллер:
- Выключили по умолчанию все виды кэширования.
- Выставили writeback (при попадании данных в буфер запись завершается прежде, чем выполняется фактическое сохранение на диск).
Файловая система:
- В точке монтирования /var/lib/mysql прописали noatime,nodiratime,data=writeback
- Выключили журналирование ext4 с помощью tune2fs.
MySQL:
- Прописали innodb_flush_method = O_DSYNC (увеличили скорость записи, снизив тем самым надежность).
- Отключили журналирование, логи нам не нужны.
- Прописали innodb_buffer_pool_size = 4G (чем меньше размер пула InnoDB, тем быстрее погаснет MySQL при остановке, и тем быстрее мы создадим снапшот).
Это далеко не полный список, особенно по MySQL. Впрочем, остальные изменения минорны и зачастую применимы не всегда и не точно. Например, в попытке разгрузить диски мы даже унесли innodb_parallel_doublewrite_path в /dev/shm, что в некоторых случаях при старте некорректно завершенного экземпляра экономило нам до 5 секунд.
Почему мы останавливаем MySQL перед тем, как делать снапшот? Ведь мы можем снять его с работающей реплики. Все верно, вот только новый экземпляр БД на этом снапшоте будет по умолчанию считаться поврежденным и потребует полного сканирования при запуске. Останавливать реплику определенно быстрее, хоть это в итоге и является самой длительной операцией во всем процессе.
В результате мы получили более приемлемые тайминги и готовый к работе стенд. Хотя, как видно по наиболее красноречивому графику отставания репликации основной реплики, ситуация все еще далека от идеала:
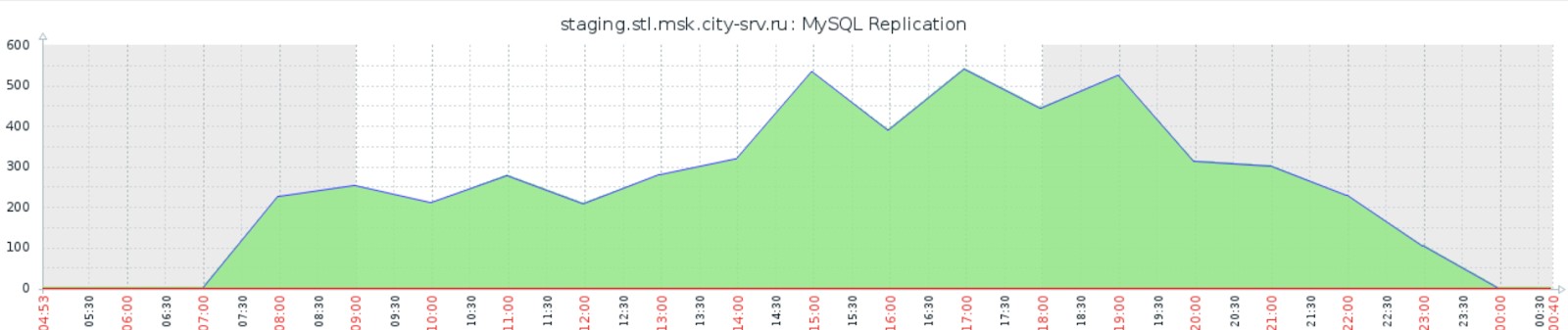
Из других недостатков стоит отметить практическую невозможность мониторинга пула Thin LVM: помимо системных стандартных функций iostat, понять, например, какой элемент пула сейчас производит наибольшую нагрузку на файловую систему невозможно.
Отдельно стоит отметить один большой недостаток, связанный с описанной выше оптимизацией: мы получили YOLO-стенд. Примерно раз в один-два месяца ext4 не выдерживала подобных надругательств над собой и безвозвратно ломалась, требуя переформатирования и перезаливки реплики. Выиграв в скорости, мы безнадежно угробили стабильность.
За какими метриками стоит следить в процессе эксплуатации Thin LVM:
- Thin pool data %
- Thin pool metadata %
Если закончившееся место под данные наш стенд переживет (достаточно почистить диски), то закончившееся место под метаданные приведет к полному краху пула и необходимости его пересоздания с нуля.
Файловая система внутри пула со временем очень сильно фрагментируется. Рекомендую раз в сутки запускать по крону команду fstrim -v /var/lib/mysql.
Промежуточные итоги:
- Технология легко применима, как и сам LVM, и не требует особой квалификации инженера.
- Она хорошо подойдет для БД небольшого размера и не слишком нагруженных. Чем меньше БД, тем меньше чанков перемещается по файловой системе внутри пула, и тем ниже нагрузка на диски.
- Для нашей задачи мы стали искать иные решения, о чем и пойдет речь в следующем разделе.
Второй стенд, технология ZFS
Когда-то давно я имел дело с файловой системой ZFS, но тогда достоверно хорошо ZFS работала на своем родном семействе ОС Solaris. Существовала портированная на FreeBSD версия с достаточно хорошим уровнем реализации. Был также недоделанный порт на Linux, который мало кто применял. Из-за структуры хранения данных B-tree (кстати, такая же структура хранения и у InnoDB MySQL) ZFS плохо себя показывала на инсталляциях с очень большим количеством файлов. Всё это в совокупности с необходимостью учить матчасть перед использованием надолго вычеркнуло из моей практики эту файловую систему. Появились ext4 и xfs, которые превратились в стандарт. Но учитывая, что под нашу задачу ZFS более чем подходит, да и Linux-версия, судя по отзывам, выросла во вполне вменяемый продукт (хоть и не на полной поддержке, из-за чего поставить систему на ZFS полностью с нуля можно только при помощи различных шаманств), мы решили её попробовать.
По понятным причинам стенд выбрали аналогичной конфигурации (за исключением RAID-контроллера). Установили восемь SSD-дисков по 1920 Гб. Не было желания писать свой сетевой образ для заливки сервера на голую ZFS, поэтому мы откусили от всех дисков по 50 Гб и сделали на них MD RAID-10 под систему. Оставшиеся 1950 Гб на каждом диске объединили в ZFS-аналог RAID-10:
zpool create zpool mirror /dev/sda2 /dev/sdb2 mirror /dev/sdc2 /dev/sdd2 mirror /dev/sde2 /dev/sdf2 mirror /dev/sdg2 /dev/sdh2Сделали разделы под MySQL:
zfs create zpool/mysql
zfs set compression=gzip zpool/mysql
zfs set recordsize=128k zpool/mysql
zfs set atime=off zpool/mysql
zfs create zpool/mysql/data
zfs set recordsize=16k zpool/mysql/data
zfs set primarycache=metadata zpool/mysql/data
zfs set mountpoint=/var/lib/mysql zpool/mysql/dataОбратите внимание, что мы включили штатное сжатие данных gzip. Процессорных ресурсов у нас на сервере много и они не полностью используются В результате 3 Тб нашей БД превратились в 1,6 Тб, и поскольку слабым звеном, как и в прошлом случае, является максимальная производительность дисков, то чем меньше данных — тем лучше, мы с самого начала получаем отличный бонус от ZFS! В час пик на полной нагрузке на поддержание работы gzip уходит до 4 ядер, но нам и не жалко.
Дальше внедрение пошло быстрее. Под копирку перенесли c LVM-стенда настройки реплики MySQL. Пришлось потратить некоторое время на переписывание скриптов на команды ZFS, но в целом алгоритмы остались прежними. Пример создания снапшота:
zfs set snapdir=visible zpool/mysql/data
zfs create zpool/stage_3307
zfs clone zpool/mysql/data@snapmain zpool/stage_3307/data
zfs set mountpoint=/mnt/stage_3307 zpool/stage_3307/dataИз дополнительного тюнинга: вынесли в память ZFS-разделы с метаданными и логами l2arc и zil. Для нашей задачи, как оказалось в дальнейшем, это было избыточно, но пока что мы оставили эту оптимизацию, поменять при случае несложно. Из негативных эффектов — приходится после перезагрузки сервера пересоздавать соответствующие области памяти. Данные при этом не теряются. Вырезка zpool status:
logs
/dev/shm/zil_slog.img ONLINE 0 0 0
cache
/dev/shm/l2arc.img ONLINE 0 0 0В такой конфигурации мы начали тестировать стенд и получили прекрасные результаты: с двумя одновременно работающими экземплярами БД (и активной основной репликой) на снапшотах мы получили загруженность дисков на 50-60 %.
Мы избавились от нашей основной проблемы, что видно на графике отставания репликации (сравните с предыдущим графиком в разделе Thin LVM):
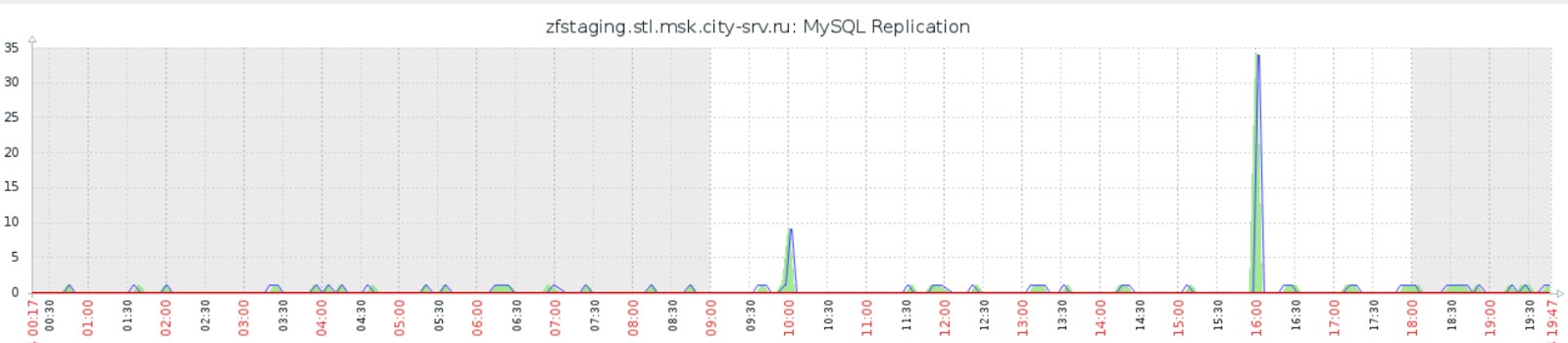
Помимо и благодаря этому мы сильно ускорились во всех операциях: полное создание снапшота с остановкой и запуском реплики занимает до 40 секунд, развёртывание из снапшота нового экземпляра MySQL занимает до 20 секунд. Что более чем устраивает как нас, так и наши тесты программного кода.
Промежуточные итоги:
- Результаты полностью удовлетворили нашу потребность в получении копии боевой БД для тестирования кода.
- Технология требует вхождения: нужно понимать, что такое ZFS и как с ней работать.
- Мы не проверяли текущий статус работы ZFS с большим количеством (от 1 млн) маленьких файлов. Но предполагаем, что проблема сохраняется, поэтому я не стал бы рекомендовать эту файловую систему для каких-либо файловых хранилищ.
Что дальше?
В рамках стенда делать больше ничего, результат нас устраивает. Возможно, в дальнейшем добавим в настройку репликации стенда исключения таблиц, не нужных для тестирования, это еще больше сократит объем БД. Мы не тестировали систему BTRFS и ее реализацию технологии тонкого резервирования. Впрочем, такой задачи уже не стоит, поскольку основная цель достигнута. В целом, конечно же, хочется уйти от вышеописанного подхода — реализовать рабочие миграции БД в тестовую среду, создать отдельный тестовый контур БД, заняться шардированием основной базы. Многое из этого мы уже воплощаем в жизнь, о чем обязательно расскажем в будущих статьях.
Итоги
Исходная задача была решена, хоть и необычным способом. В промежуточных выводах были описаны достоинства и недостатки каждой из примененных технологий, поэтому давайте решим, какую технологию и когда можно использовать:
- Thin LVM — на небольших БД и когда не хочется или нет времени изучать ZFS.
- ZFS — если есть опыт работы с ней или возможность потратить время на изучение в любых ситуациях.
На более высоком уровне представления эта статья — не просто сравнение технологии двух файловых систем. Основная идея, которую я хотел бы передать и закрепить, заключается в том, что не стоит бояться мыслить нестандартно в ситуациях, критичных для бизнеса, и брать только готовые рецепты. Когда-то мы могли всем техническим департаментом покачать головой и сказать, что задача создания трехтерабайтных копий БД меньше чем за минуту невыполнима, и нам не нужны рискованные технологии, давайте сделаем как надо. Это было возможно, но мы потеряли бы примерно полгода-год и много поездок клиентов (поездки — наш основной бизнес-показатель) без тестов и во время внедрения. Поступив нестандартно, мы потеряли не так много времени на внедрение, получили опыт в новых и забытых старых технологиях, и предоставили тестирование именно в тот момент, когда мы в нем очень нуждались. Несомненно, это положительно сказалось на всех наших показателях. Выбор всегда за вами, а мы со своей стороны продолжим рассказывать в нашем блоге про интересные текущие и будущие достижения.



