Так как нас не устраивала скорость и надежность исходной имплементации на Ruby, в последние несколько лет мы постепенно выводили критический функционал из нашего Rails-монолита GitHub.com и переписывали часть кода на Go. Например, на Github Satellite в прошлом году мы анонсировали — и имплементировали — возможность «более контролируемой авторизации» с использованием сервиса
Работа с
Кроме того, проблемы с большими задержками при открытии TCP соединений на наших Kubernetes кластерах особенно влияли на пул соединений Go MySQL драйвера. Это добавляло работы, ведь именно на Kubernetes мы и развернули
Так чего нам в итоге стоила подготовка
Более двух лет назад я впервые обнаружил и зарепортил самый неуловимый из всех известных багов MySQL,
Задача Go SQL драйвера — предоставлять «SQL соединение», обычный примитив к идущему в стандартной библиотеке Go пакету
Каждый раз, когда при работе с
В прерывании TCP соединений нет ничего необычного, и с помощью специальной имплементации драйвера пакет
Так что же приводит ко всем этим ошибкам «invalid connection» в
Между протоколом TCP и протоколом MySQL поверх него есть очень тонкое несоответствие: в полностью двустороннем TCP соединении данные свободно передаются в обоих направлениях независимо друг от друга, но стоит протоколу MySQL оказаться в командной фазе, клиентская сторона получает над ним полный контроль. Это происходит из-за передачи MySQL сервером пакета MySQL клиенту только в ответ на пакет от клиента. Когда сервер закрывает активное соединение в командной фазе, например, по времени ожидания или по вине активно подрезающих соединения процессов вида
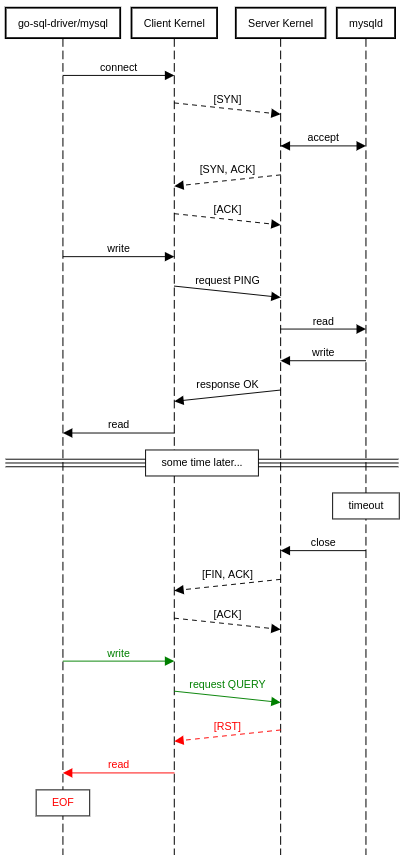
Рисунок 1: Диаграмма сети демонстрирует передачу пакетов между MySQL сервером и MySQL клиентом.
На этой визуализации бага мы можем наблюдать стандартное TCP рукопожатие и следующую за ним пару запроса и ответа на уровне MySQL. После длительного перерыва без новых запросов к MySQL серверу на стороне сервера происходит таймаут, и сервер закрывает сокет активным
Клиент проводит
Результат такого соединения хорошо виден на диаграмме. После периода ожидания мы успешно высылаем серверу
Теперь мы знаем причину прерывания наших MySQL соединений (они становятся неактуальны), но не причину последующих падений приложения. Почему при прерывании наш MySQL драйвер не возвращает
События, как на диаграмме выше, происходят слишком уж часто, наши MySQL кластеры на продакшне фиксируют тысячи подобных случаев в минуту, чаще всего в наименее загруженные часы, когда наши сервисы простаивают и достигают таймаутов. Но соединения могут прерываться далеко не только по таймаутам.
Что будет, если в ходе здорового соединения мы проведем
Как нам с этим справиться? Самым простым решением — мы им в свое время воспользовались для
Оптимальным вариантом было бы проверять состояние здоровья соединения после того, как оно взято из пула, но до того, как на него отправят какой-либо
Проверку состояния здоровья такого соединения можно провести двумя методами: на MySQL уровне и на TCP уровне. Проверка на MySQL уровне включается в себя отправку пакета
Проверка на уровне TCP очень проста и нетребовательна к ресурсам: нам нужно только провести неблокирующее чтение нашего соединения до попытки внесения какой-либо записи. Если соединение все еще открыто, мы сразу получим ошибку
Вооружившись новым API, я сумел реализовать проверку состояния здоровья соединения, которая решала проблему «устаревших соединений» с менее чем пятью микросекундами пинга. Неблокирующие чтения действительно очень быстры, ведь в этом-то и есть их суть— не блокировать.
После ввода решения в продакшн все скачки «Invalid Connection» тут же пропали, и наш сервис впервые вышел на девять баллов по показателю доступности.

Рисунок 2: Скачки и повторные попытки со стороны клиента после ввода
Когда мы добавляем сервисы наподобие
Со стороны Rails нам необходимо быть очень осторожными с тем, как мы проводим RPC реквесты к сервису и как мы отслеживаем их по времени. С серверной стороны Go это означает лишь одно —
Ответственная за разработку нового сервиса команда инженеров проделала шикарную работу по обеспечению всех методов в
Тем не менее, на практике все выглядело так, будто

Рисунок 3: Время внутрисервисного отклика на развертывание
Одного взгляда на эти метрики достаточно чтобы понять: пусть мы и успешно распространяем
Проблема заключалась в том, что мы не распространяем
В предыдущем следе стека явно видно, как в (8) мы перестаем распространять наш
Что же нам с этим делать? Нашей первой попыткой было изменение значения
Корректное решение потребовало рефакторинга большого куска Go MySQL драйвера. Основная проблема возникла еще в Go 1.8 с имплементацией API
К счастью, у меня нашлись и время, и терпение на подобный рефакторинг. После выгрузки итогового драйвера с новым интерфейсом
Обратите внимание, как
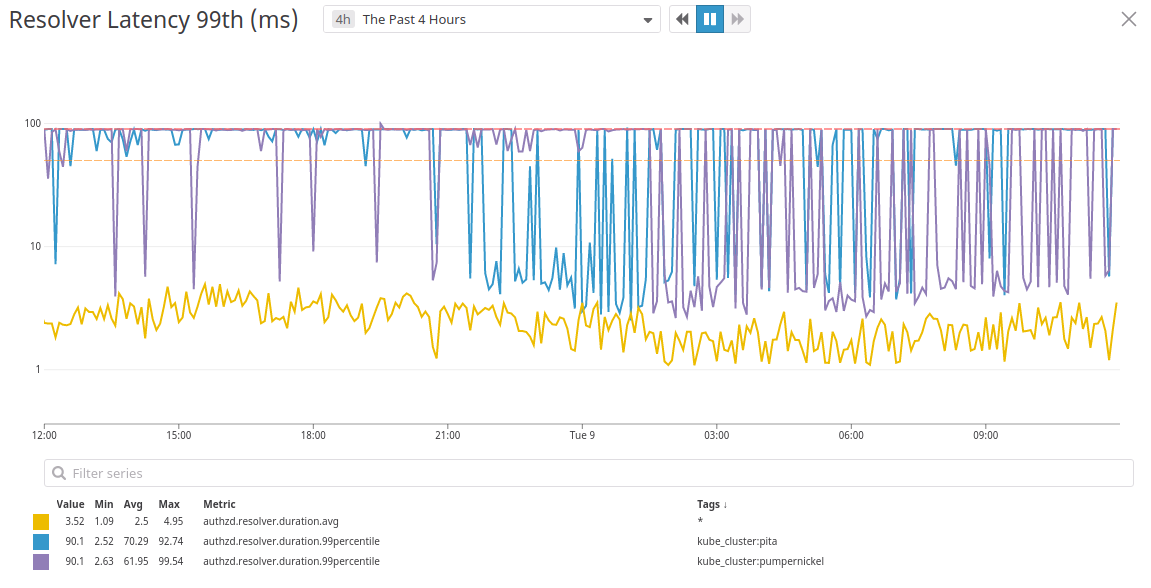
Рисунок 4: Время отклика распознавателя с таймаутом в 90мс. Можно быть уверенными, что
Напоследок будет очень серьезная, коварная и неуловимая проблема безопасности, вызванная data race. Мы много говорили о том, что
В отличие от простого вызова
Обмен данными между обычным SQL запросом и
На практике этот подход прямолинеен:
На самом деле, имплементация с основным драйвером выглядит сложнее: драйвер возвращает свой собственный обернутый в
Как вы могли сразу догадаться, наша проблема безопасности вызвана украденной памятью. В контракте драйвера очень рекомендуют возвращать временную память, эта важная оптимизация на практике хорошо ложится на MySQL и позволяет нам возвращать указатели в буфер соединения для считывания результатов напрямую. Как только информация строк SQL запроса доставлена, ее можно передать методу Scan, который распарсит строчное отображение в ожидаемые пользователем типы (
… Так все и было, по крайней мере, пока в Go 1.8 не появился API
Подобное поведение может показаться неожиданным, но так как обнуление нашего
Эта data race уже звучит пугающе, но вот в чем главная загвоздка: на практике однозначно сказать случилась data race в вашем приложении или еще нет не получится. В прошлом примере использования
Проверка возвратного значения вызова
Я знаю несколько способов устранения этой data race. Самый очевидный — и самый медленный — предлагает всегда клонировать память при возвращении из
Сначала я попробовал «опустошать» MySQL соединения без использования основного буфера соединений, ведь data race не возникнет, если мы не пишем в буфер. Но так как MySQL может высылать множество необходимых для опустошения пакетов, и разные размеры этих пакетов определяются их заголовками, мои попытки вскоре превратились в кошмарный спагетти-код. Частично парсить заголовки без буфера очень неприятно.
Я размышлял над этой проблемой еще некоторое время, и в один момент меня осенило — двойная буферизация. Это решение оказалась безумно простым и достаточно быстрым, чтобы в дальнейшем замержить его вверх. Еще во времена древних стеков компьютерной графики подобный стек записывал индивидуальные пиксели прямо на буфер кадров, а монитор одновременно с этим считывал пиксели со своей кадровой частотой. Когда стек писал данные в буфер кадров одновременно с тем, как экран считывал из него, наблюдалось мерцание, старый графический глич. Фундаментально мерцание можно определить как видимую невооруженным взглядом data race, что само по себе довольно интересный концепт. Проще всего устранить мерцание можно двумя буферами кадров: из одного буфера будет считывать данные экран (передний буфер), а в другой будет записывать данные графический процессор (задний буфер). Когда графический процессор завершает визуализацию кадра, мы автоматически меняем передний и задний буфер местами, поэтому монитор никогда не считает незаконченный кадр.
Рисунок 5: Двойная буферизация графического стека Nintendo 64. Если Марио этого достаточно, то и для MySQL драйвера сойдет.
Наша проблема и эта ситуация очень похожи, поэтому мы можем воспользоваться приемом с двумя буферами. В нашем случае, мы меняем местами наш буфер соединений с задним буфером, когда структура
После аккуратной сборки нескольких тестов производительности регрессии двойной буферизации не было выявлено ни в одном из случаев, я наконец-то направил фикс вверх. К несчастью, особенности бага не дают посмотреть частоту чтения поврежденной памяти, однако его легко воспроизвести, поэтому таких чтений наверняка было довольно много.
Развертывание кода на новом языке программирования в продакшн, особенно в масштабах Github, — это всегда вызов. Производительность и сложность наших моделей использования MySQL отражает нашу многолетнюю тонкую настройку MySQL клиента под Ruby, а теперь мы рады делать то же самое для Go MySQL драйвера. Релиз 1.5.0 Go MySQL драйвера содержит в себе все переданные нами вверх в ходе нашего первого развертывания Go фиксы и есть теперь в общем доступе. Мы же параллельно с ростом нашего использования Go в продакшне и дальше продолжим привносить исправления в драйвер и расширять его функционал.
Спасибо сопровождающим Go MySQL специалистам, @methane и @julienschmidt за их помощь с патчами!
authzd.Работа с
authzd оказалась очень интересной и значимой для нас задачей, поскольку это был наш первый сервис на Go для работы с чтением данных из баз MySQL на продакшне в ходе веб-реквеста. У нас имелся опыт развертывания других работающих с базами MySQL-сервисов на Go, но при этом они были либо службами внутреннего контроля (наша кластерная поисковая система manticore), либо асинхронными пакетными заданиями (оркестратор резервного копирования Git gitbackups). Требования к производительности и надежности authzd отличаются от них повышенной строгостью, поскольку обычный реквест к Rails-монолиту вызывает этот сервис неоднократно.Кроме того, проблемы с большими задержками при открытии TCP соединений на наших Kubernetes кластерах особенно влияли на пул соединений Go MySQL драйвера. Это добавляло работы, ведь именно на Kubernetes мы и развернули
authzd. Одним из самых опасных самообманов программиста в этом отношении является вера в надежность сети, поскольку да, в большинстве случаев сеть действительно надежна… но как только она начинает тормозить или барахлить, нас настигают базовые проблемы таких же базовых библиотек, и все начинает рушиться.Так чего нам в итоге стоила подготовка
authzd к обработке всего нашего рабочего трафика через SQL, да еще и в соответствии с нашими целями доступности?Падение
Более двух лет назад я впервые обнаружил и зарепортил самый неуловимый из всех известных багов MySQL,
"Invalid connection (unexpected EOF)". Впервые мы столкнулись с ним в ходе развертывания в продакшн исходных версий нашего оркестратора резервного копирования (gitbackups), и мы вынуждено обошли проблему правкой кода приложения, поскольку команда сопровождающих MySQL драйвер никак не могла определиться, как поправить баг на своей стороне. Этот баг вновь проявил себя в прошлом году, как раз во время первого развертывания authzd в продакшн: частота ошибочных откликов authzd резко возросла на фоне сотен и сотен ошибок Invalid connection в минуту. Такое поведение системы заставило меня вновь взяться за баг, и я наконец-то разработал не требующий каких-либо изменений в коде приложения фикс этой проблемы. Давайте посмотрим на него повнимательней.Решение проблемы
Задача Go SQL драйвера — предоставлять «SQL соединение», обычный примитив к идущему в стандартной библиотеке Go пакету
database/sql. Драйвер предоставляет соединения с хранением состояния, и по определению на всех крупных SQL серверах, включая MySQL и Postrgres, эти соединения не могут вестись параллельно. Пакет database/sql со своей стороны контролирует доступ и длительность таких соединений и является входной точкой для всех возможных проводимых над базой данных SQL операций, а его структура DB — это абстракция над предоставляемым драйвером пулом отдельных соединений. Таким образом, обращение к методам вида (*DB).Query или (*DB).Exec требует сложной логики: для начала необходимо выбрать из пула соединений активное, но свободное соединение, или вызвать основной драйвер для создания нового соединения при занятости всех других, а затем выполнить команду или запрос и вернуть соединения обратно в пул либо сбросить его при уже полном пуле.Каждый раз, когда при работе с
gitbackups и authzd мы забирали соединение из пула и создавали запрос, у нас проявлялась ошибка «unexpected EOF», и, по данным логов, MySQL сервер закрывал превышающие свое время ожидания соединения за слишком долгое присутствие в пуле Go sql.(*DB). При этом, ак как мы хотим быть уверены в отсутствии слишком большого числа соединений в любой момент, время ожидания наших MySQL кластеров на продакшне жестко ограничено — не более 30 секунд. Тем не менее, постоянные оповещения об ошибках нас порядком озадачивали — и являлись серьезной проблемой, ведь из-за них постоянно падал наш сервис.В прерывании TCP соединений нет ничего необычного, и с помощью специальной имплементации драйвера пакет
database/sql умеет в любой момент времени справляться с прерыванием в любом из сотен одновременных соединений из пула (*DB). Будь то закрытие, плохой пакет или что-нибудь не то с SQL соединением, драйвер должен вернуть driver.ErrBadConn на следующий вызов любого из методов в соединении, как только он заметит, что соединение драйвера стало нездоровым по какой-либо из множества возможных причин.ErrBadConn — это такой волшебный сигнал, который указывает пакету database/sql на неактуальность соединения с сохранением состояния: если соединение было в пуле, его необходимо оттуда убрать, а если его уже выбрали для выполнения запроса, необходимо отбросить текущее соединение и выбрать либо создать новое. Учитывая такое поведение, мы не ожидаем от (*DB).Query падения из-за ошибки «invalid connection», поскольку с возвратом driver.ErrBadConn запрос незаметно для пользователя повторится на новом соединении.Так что же приводит ко всем этим ошибкам «invalid connection» в
authzd?Между протоколом TCP и протоколом MySQL поверх него есть очень тонкое несоответствие: в полностью двустороннем TCP соединении данные свободно передаются в обоих направлениях независимо друг от друга, но стоит протоколу MySQL оказаться в командной фазе, клиентская сторона получает над ним полный контроль. Это происходит из-за передачи MySQL сервером пакета MySQL клиенту только в ответ на пакет от клиента. Когда сервер закрывает активное соединение в командной фазе, например, по времени ожидания или по вине активно подрезающих соединения процессов вида
pt-kill, такая ситуация приводит к проблемам. Давайте посмотрим на диаграмму сети:Рисунок 1: Диаграмма сети демонстрирует передачу пакетов между MySQL сервером и MySQL клиентом.
На этой визуализации бага мы можем наблюдать стандартное TCP рукопожатие и следующую за ним пару запроса и ответа на уровне MySQL. После длительного перерыва без новых запросов к MySQL серверу на стороне сервера происходит таймаут, и сервер закрывает сокет активным
close. Когда TCP сервер закрывает сокет, его ядро отсылает клиенту пару [FIN, ACK], что означает завершение передачи данных сервером. Ядро клиента подтверждает [FIN, ACK] ответным [ACK], но еще не закрывает свою сторону соединения — под этим мы и подразумеваем «полностью двустороннее соединение». Сторона записи соединения «клиент -> сервер» независима и должна быть явно закрыта вызовом close со стороны клиента.Клиент проводит
read чтение с сервера, и как только он получает [SYN, ACK], следующее чтение возвращает ошибку EOF, поскольку ядро в курсе, что сервер не станет больше записывать данные в это соединение, поэтому такая ситуация обычно не создает проблем в большинстве протоколов поверх TCP. Но, как мы уже отметили ранее, клиент считывает данные с сервера только после отправки запроса, поскольку сервер высылает данные только в ответ на запрос от клиента, ведь как только MySQL соединение оказывается в своей командной фазе, MySQL протокол управляется со стороны клиента.Результат такого соединения хорошо виден на диаграмме. После периода ожидания мы успешно высылаем серверу
write реквест, так как наша сторона соединения все еще открыта. В ответ сервер отправляет пакет [RST], ведь сервер уже закрыт, просто мы этого еще не знаем. После чего клиент пытается прочесть ответ от MySQL сервера, получает ошибку EOF и слишком поздно осознает, что соединение прервано.Теперь мы знаем причину прерывания наших MySQL соединений (они становятся неактуальны), но не причину последующих падений приложения. Почему при прерывании наш MySQL драйвер не возвращает
driver.ErrBadConn? И почему он не позволяет database/sql переотправить запрос через новое соединение? К несчастью, потому что открытая переотправка запроса небезопасна.События, как на диаграмме выше, происходят слишком уж часто, наши MySQL кластеры на продакшне фиксируют тысячи подобных случаев в минуту, чаще всего в наименее загруженные часы, когда наши сервисы простаивают и достигают таймаутов. Но соединения могут прерываться далеко не только по таймаутам.
Что будет, если в ходе здорового соединения мы проведем
UPDATE, MySQL выполнит его, а затем наша сеть отключится до того, как сервер успеет нам ответить? После актуального запроса на запись Go MySQL драйвер тоже получит в ответ ошибку EOF, но если он вернет driver.ErrBadConn, то database/sql запустит UPDATE на новом соединении. А ведь это повреждение данных! Казалось бы, мы знаем, что в типичном случае (когда MySQL убивает наше соединение) переотправлять запросы можно без опаски.Ошибки при записи запроса в сеть не было, и мы знаем, что MySQL не получил его, не говоря уже о том, чтобы выполнить. Но в такой ситуации надо ожидать худшего и исходить из того, что запрос все же достиг сервера. И вот поэтому возвращать driver.ErrBadConn небезопасно. В какой же мерзкой ситуации мы оказались!Как нам с этим справиться? Самым простым решением — мы им в свое время воспользовались для
gitbackups — было вызвать на нашем клиенте (*DB).SetConnMaxLifetime и задать порог длительности для таких соединений ниже таймаута ожидания MySQL кластера. Подобный метод далек от идеала: SetConnMaxLifetime задает максимальную длительность в целом, а не максимальную длительность ожидания. Из-за этого database/sql будет прерывать соединения строго по таймеру, вне зависимости от статуса активности соединений и готовности сервера прерывать их по таймауту. Не все серверы имплементируют концепт таймаута по ожиданию, поэтому в пакете database/sql нет API для «максимальной длительности ожидания». О, муки абстракций… На практике же такое решение работает нормально, если не брать во внимание постоянные сетевые переподключения и случаи, когда MySQL сервер активно обрезает соединения — этот метод их не обнаруживает.Оптимальным вариантом было бы проверять состояние здоровья соединения после того, как оно взято из пула, но до того, как на него отправят какой-либо
write реквест. К несчастью, до появления интерфейса SessionResetter в Go 1.10 узнать, когда соединение возвращается в пул, было невозможно, из-за чего баг так и висел без подобающего фикса почти два года.Проверку состояния здоровья такого соединения можно провести двумя методами: на MySQL уровне и на TCP уровне. Проверка на MySQL уровне включается в себя отправку пакета
PING и ожидание ответа, и так как PING не проводит никаких операций записи в MySQL (хотелось бы надеяться), в этом случае можно без опаски возвращать driver.ErrBadConn. С другой стороны, явным недостатком такого метода является добавление случайной задержки к первой операции на соединение из пула. В итоге мы выбрали проверку на закрытие MySQL сервером своего соединения на NCP уровне, поскольку в Go приложении соединения довольно часто добавляются и вынимаются из пула, и дополнительная задержка другого метода немного напрягает.Проверка на уровне TCP очень проста и нетребовательна к ресурсам: нам нужно только провести неблокирующее чтение нашего соединения до попытки внесения какой-либо записи. Если соединение все еще открыто, мы сразу получим ошибку
EWOULDBLOCK, поскольку данных на чтение (пока еще) нет, а если сервер закрыл свою сторону соединения, то нам тут же вернется уже знакомый ответ EOF. К тому же все сокеты в Go программе уже выставлены в неблокирующий режим. Но не дайте обмануть себя элегантной абстракцией Goroutines: под ее красивым фасадом Go планировщик использует асинхронный цикл событий, чтобы усыпить Goroutines и пробудить, только когда у них появятся данные для чтения. (Необычно, не правда ли?) К несчастью, мы не можем проводить неблокирующие чтения через методы вида net.Conn.Read, иначе планировщик нас тут же усыпит (опять же, элегантные абстракции Goroutines). Корректный интерфейс для проведения неблокирующего чтения впервые появился в Go 1.9: (*TCPConn).SyscallConn дает нам доступ к основному дескриптору файла, и мы можем напрямую использовать системный вызов read.Вооружившись новым API, я сумел реализовать проверку состояния здоровья соединения, которая решала проблему «устаревших соединений» с менее чем пятью микросекундами пинга. Неблокирующие чтения действительно очень быстры, ведь в этом-то и есть их суть— не блокировать.
После ввода решения в продакшн все скачки «Invalid Connection» тут же пропали, и наш сервис впервые вышел на девять баллов по показателю доступности.
Рисунок 2: Скачки и повторные попытки со стороны клиента после ввода
authzd в продакшн.Советы в продакшн
- Если ваш MySQL сервер использует таймауты по ожиданию или активно обрезает соединения, вашим сервисам нет нужды вызывать
(*DB).SetConnMaxLifetime, поскольку драйвер может изящно обнаруживать и повторно пробовать устаревшие соединения. Добавление максимума длительности соединений будет постоянно удалять и создавать здоровые соединения, заставляя систему делать лишние телодвижения. - Настройка вашего
sql.(*DB)пула ((*DB).SetMaxIdleConnsи(*DB).SetMaxOpenConns)со значениями, которые поддерживают трафик пиковых часов нагрузки на ваш сервис, станет хорошей моделью по контролю высокопроизводительного доступа к MySQL. Также стоит проверить, что в остальные часы ваш MySQL сервер активно подрезает ожидающие соединения: он будет удалять их и пересоздавать при необходимости.
Таймаут
Когда мы добавляем сервисы наподобие
authzd зависимостью в стандартный маршрут реквестов нашего монолита, его время отклика добавляется к общему времени отклика всех реквестов нашего приложения или реквестов с тем или иным методом авторизации — а их у нас очень много. Слишком долгое время обработки запросов authzd может привести к массовой деградации производительности, поэтому критически важно гарантировать выполнение запросов в рамках выделенного им времени. Со стороны Rails нам необходимо быть очень осторожными с тем, как мы проводим RPC реквесты к сервису и как мы отслеживаем их по времени. С серверной стороны Go это означает лишь одно —
Context. API context был доступен отдельной библиотекой уже несколько лет, но в стандартную библиотеку его ввели только в Go 1.7. Идея этого пакета проста: сделать ваш сервис осведомленным об обнулении реквестов через передачу context.Context всем вовлеченным в жизненный цикл реквестов вашего сервиса функциям. Каждый входящий HTTP реквест предоставляет объект Context, который обнуляется в случае, если клиент рано разъединился, что позволит вам использовать ранние обнуления и таймауты реквестов через единый API. Кроме того, вы можете расширить свой Context дедлайном.Ответственная за разработку нового сервиса команда инженеров проделала шикарную работу по обеспечению всех методов в
authzd передачей Context, включая методы, которые направляют запросы к MySQL. Так как это самая дорогостоящая в плане ресурсов часть жизненного цикла наших реквестов, фундаментально важно передавать Context методам запросов database/sql. Мы должны убедиться в получении этими методами Context для быстрого обнуления наших MySQL запросов на случай их слишком долгой обработки.Тем не менее, на практике все выглядело так, будто
authzd не брал обнуление запросов или тайматуы в расчет:Рисунок 3: Время внутрисервисного отклика на развертывание
authzd. Таймаут распознавателя был установлен на 1000мс — это можно понять по красной пунктирной линии, но уж точно не по рандомным скачкам, достигающим добрых 5000мс. Одного взгляда на эти метрики достаточно чтобы понять: пусть мы и успешно распространяем
Context наших реквестов через весь код приложения, в жизненном цикле некоторых из них есть места, где обнуление попросту игнорируется. Поиск таких мест через просмотр кода может оказаться очень трудоемким процессом, даже если мы небезосновательно подозреваем драйвер Go MySQL, поскольку больше никто в нашем сервисе не совершает внешние запросы. Желая обнаружить, где блокируется код, в этой ситуации я за несколько попыток поймал актуальный след стека от хоста продакшна, и все стало очевидно, как только я поймал тот, что блокировался на вызове QueryContext:0 0x00000000007704cb in net.(*sysDialer).doDialTCP
at /usr/local/go/src/net/tcpsock_posix.go:64
1 0x000000000077041a in net.(*sysDialer).dialTCP
at /usr/local/go/src/net/tcpsock_posix.go:61
2 0x00000000007374de in net.(*sysDialer).dialSingle
at /usr/local/go/src/net/dial.go:571
3 0x0000000000736d03 in net.(*sysDialer).dialSerial
at /usr/local/go/src/net/dial.go:539
4 0x00000000007355ad in net.(*Dialer).DialContext
at /usr/local/go/src/net/dial.go:417
5 0x000000000073472c in net.(*Dialer).Dial
at /usr/local/go/src/net/dial.go:340
6 0x00000000008fe651 in github.com/github/authzd/vendor/github.com/go-sql-driver/mysql.MySQLDriver.Open
at /home/vmg/src/gopath/src/github.com/github/authzd/vendor/github.com/go-sql-driver/mysql/driver.go:77
7 0x000000000091f0ff in github.com/github/authzd/vendor/github.com/go-sql-driver/mysql.(*MySQLDriver).Open
at <autogenerated>:1
8 0x0000000000645c60 in database/sql.dsnConnector.Connect
at /usr/local/go/src/database/sql/sql.go:636
9 0x000000000065b10d in database/sql.(*dsnConnector).Connect
at <autogenerated>:1
10 0x000000000064968f in database/sql.(*DB).conn
at /usr/local/go/src/database/sql/sql.go:1176
11 0x000000000065313e in database/sql.(*Stmt).connStmt
at /usr/local/go/src/database/sql/sql.go:2409
12 0x0000000000653a44 in database/sql.(*Stmt).QueryContext
at /usr/local/go/src/database/sql/sql.go:2461
[...]Проблема заключалась в том, что мы не распространяем
Context наших реквестов настолько глубоко, как мы думали. Пусть при выполнении SQL запросов мы и передаем Context для QueryContext, и этот Context используется для исполнения и таймаута SQL запросов, мы упускаем крайний случай в API database/sql/driver. Когда мы пытаемся выполнить запрос, а в пуле нет ни одного SQL соединения, вызовом driver.Driver.Open() мы должны создать новое, но этот метод интерфейса не берет context.Context!В предыдущем следе стека явно видно, как в (8) мы перестаем распространять наш
Context и попросту вызываем (*MysqlDriver).Open() в нашу базу данных через DSN. Открытие MySQL соединения — это недешевая операция: она включает в себя открытие TCP, SSL-общение (если мы пользуемся SSL), рукопожатие и аутентификацию MySQL и настройку любых базовых опций соединения. Итого нашим правилам таймаута не подчиняются, как минимум, шесть разных сетевых соединений, и все из-за их Context-неосведомленности.Что же нам с этим делать? Нашей первой попыткой было изменение значения
timeout на DSN нашего соединения, что, в свою очередь, влияет на таймаут используемого (*MySQLDriver).Open открытого TCP. Этого оказалось недостаточно, так как открытое TCP — лишь первый шаг инициализации соединения. Последующие шаги (MySQL рукопожатие, аутентификация и так далее) не подчинялись никаким таймаутам, поэтому превышающие 1000мс таймаут реквесты так никуда и не делись.Корректное решение потребовало рефакторинга большого куска Go MySQL драйвера. Основная проблема возникла еще в Go 1.8 с имплементацией API
QueryContext и ExecContext. Они формально могли обнулять SQL запросы, но несмотря на их Context-осведомленность, метод driver.Open не был обновлен для получения аргумента context.Context. Лишь два патча спустя, в Go 1.10, добавили новый интерфейс Connector, и его необходимо было имплементировать отдельно от самого драйвера. В итоге команда сопровождающих Go MySQL драйвер так и не удосужилась имплементировать новый интерфейс, во многом из-за указанных выше сложностей и недостатка информации о потенциальных проблемах с доступностью старого интерфейса Driver.Open, поскольку поддержка и старого driver.Driver, и нового driver.Connector интерфейсов требовала значительных правок в структуре любого SQL драйвера.К счастью, у меня нашлись и время, и терпение на подобный рефакторинг. После выгрузки итогового драйвера с новым интерфейсом
Connector в authzd, мы на следах стеков подтвердили корректное распространение контекста QueryContext при новых MySQL соединениях:0 0x000000000076facb in net.(*sysDialer).doDialTCP
at /usr/local/go/src/net/tcpsock_posix.go:64
1 0x000000000076fa1a in net.(*sysDialer).dialTCP
at /usr/local/go/src/net/tcpsock_posix.go:61
2 0x0000000000736ade in net.(*sysDialer).dialSingle
at /usr/local/go/src/net/dial.go:571
3 0x0000000000736303 in net.(*sysDialer).dialSerial
at /usr/local/go/src/net/dial.go:539
4 0x0000000000734bad in net.(*Dialer).DialContext
at /usr/local/go/src/net/dial.go:417
5 0x00000000008fdf3e in github.com/github/authzd/vendor/github.com/go-sql-driver/mysql.(*connector).Connect
at /home/vmg/src/gopath/src/github.com/github/authzd/vendor/github.com/go-sql-driver/mysql/connector.go:43
6 0x00000000006491ef in database/sql.(*DB).conn
at /usr/local/go/src/database/sql/sql.go:1176
7 0x0000000000652c9e in database/sql.(*Stmt).connStmt
at /usr/local/go/src/database/sql/sql.go:2409
8 0x00000000006535a4 in database/sql.(*Stmt).QueryContext
at /usr/local/go/src/database/sql/sql.go:2461
[...]Обратите внимание, как
(*DB).conn напрямую вызывает интерфейс Connector нашего драйвера, в обход текущего Context. Помимо этого, стало ясно что глобальный таймаут реквестов распространяется на все реквесты:Рисунок 4: Время отклика распознавателя с таймаутом в 90мс. Можно быть уверенными, что
Context не игнорируется, поскольку 99й процентиль больше похож на штрихкод, чем на график.Советы для продакшена
- Вам не нужно менять инициализацию вашего
sql.(*DB)для использования нового APIsql.OpenDB. Даже при вызовеsql.Openв Go 1.10 пакетdatabase/sqlзамечает интерфейсConnector, и новые соединения создаютсяContext–осведомленными. - Тем не менее, изменение вашего приложения под использование
sql.OpenDBвместе сmysql.NewConnectorнесет в себе несколько преимуществ, в особенности возможность настройки опций соединения для вашего MySQL кластера из структурыmysql.Config, без необходимости составлять DSN. - Не назначайте на вашем MySQL драйвере
?timeout=(или его аналогmysql.(Config).Timeout), это плохая идея, поскольку статичное значение таймаута исходящего соединения не учитывает расход вашего запаса ресурсов на выполнение реквестов. - Вместо этого убедитесь в использовании интерфейсов
QueryContext/ExecContextкаждой SQL операцией вашего приложения. Тогда они будут обнулены на основеContextвашего текущего реквеста вне зависимости от причин, будь то неудачное соединение либо слишком долгое исполнение запроса.
Гонка
Напоследок будет очень серьезная, коварная и неуловимая проблема безопасности, вызванная data race. Мы много говорили о том, что
sql.(*DB) — это попросту обертка вокруг пула соединений хранения состояния, но есть одна деталь, которую мы еще не затронули. Проведение SQL запроса, одной из самых частых операций над базами данных, как через (*DB).Query, так и через (*DB).QueryContext, на самом деле крадет соединение из пула.В отличие от простого вызова
(*DB).Exec, который не возвращает никаких данных из базы, (*DB).Query возвращает одну или несколько строк, и мы должны взять под контроль соединение с хранением состояния, в которое сервер запишет эти строки, чтобы прочесть их из кода нашего приложения. Здесь нам помогает структура sql.(*Rows), которая возвращается после каждого вызова Query и QueryContext: она оборачивает украденное из пула соединение для прочтения из него индивидуальных строк Row. И если по завершении обработки результатов запроса не вызывать (*Rows).Close, украденное соединение так и не вернется в пул.Обмен данными между обычным SQL запросом и
databaseb/sql не менялся с самого первого стабильного релиза Go:rows, err := db.Query("SELECT a, b FROM some_table")
if err != nil {
return err
}
defer rows.Close()
for rows.Next() {
var a, b string
if err := rows.Scan(&a, &b); err != nil {
return err
}
...
}На практике этот подход прямолинеен:
(*DB).Query возвращает sql.(*Rows), а он крадет из SQL пула соединение, на котором мы провели запрос. Последующие вызовы (*Rows).Next прочтут итоговую строку из соединения, и мы можем извлечь ее содержимое вызовом (*Rows).Scan, пока мы наконец не вызовем (*Rows).Close, после чего все последующие вызовы Next вернут false, а все вызовы Scan вернут ошибку.На самом деле, имплементация с основным драйвером выглядит сложнее: драйвер возвращает свой собственный обернутый в
sql.(*Rows) интерфейс Rows. Тем не менее, благодаря оптимизации у Rows драйвера вместо метода Scan имеется итератор Next(dest []Value) error. Итератор возвращает объекты Value за каждый столбец в SQL запросе, поэтому вызов sql.(*Rows).Next попросту вызывает подо всем этим driver.Rows.Next, сохраняя указатель на возвращенных драйвером значениях. Затем, когда пользователь вызывает sql.(*Rows).Scan, библиотека стандартов конвертирует объекты Value драйвера в заданные пользователем целевые типы в виде аргументов для Scan. А значит, драйверу не нужно проводить конвертацию аргументов (об этом заботится библиотека стандартов Go), и вместо указания новых значений Value драйвер может вернуть украденную память из своего итератора строк, все равно метод Scan и так конвертирует память.Как вы могли сразу догадаться, наша проблема безопасности вызвана украденной памятью. В контракте драйвера очень рекомендуют возвращать временную память, эта важная оптимизация на практике хорошо ложится на MySQL и позволяет нам возвращать указатели в буфер соединения для считывания результатов напрямую. Как только информация строк SQL запроса доставлена, ее можно передать методу Scan, который распарсит строчное отображение в ожидаемые пользователем типы (
int, bool, string и так далее). Этот безопасный метод не вызывает никаких data race, потому что без нового вызова пользователем sql.(*Rows).Next мы не переписываем наш буфер.… Так все и было, по крайней мере, пока в Go 1.8 не появился API
QueryContext. С новыми интерфейсами можно вызывать db.QueryContext с объектом Context, который прервет запрос раньше — мы уже это детально разобрали. Однако прерывание или отключение запроса по таймауту, когда мы сканируем его результаты, открывает серьезную уязвимость для безопасности. Как только SQL запрос прерывается посреди вызова sql.(*Rows).Scan, драйвер переписывает основной буфер MySQL соединения, и Scan возвращает поврежденные данные.Подобное поведение может показаться неожиданным, но так как обнуление нашего
Context означает обнуление SQL запроса на клиенте, а не на MySQL сервере, ситуация становится яснее. Сервер продолжает выдавать результаты запроса через активное MySQL соединение, поэтому если мы хотим восстановить соединение на месте обнуления запроса, мы должны сначала «опустошить» все переданные сервером пакеты результатов. Для опустошения и сброса оставшихся в запросе строк мы должны прочесть эти пакеты в наш буфер соединения, и так как обнуление запроса может произойти одновременно с запросом Scan, мы переписываем ответственную за значения Value память, в которой пользователь ведет поиск. В результате с очень высокой долей вероятности получаются поврежденные данные.Эта data race уже звучит пугающе, но вот в чем главная загвоздка: на практике однозначно сказать случилась data race в вашем приложении или еще нет не получится. В прошлом примере использования
rows.Scan нет какого-либо надежного способа сказать, обнулился ли наш SQL запрос из-за истекшего Context, даже несмотря на наши проверки на ошибки. Если обнуление Context случилось внутри вызова rows.Scan (например, в удобном для старта data race месте), то значения строк будут отсканированы с потенциально поврежденными данными и не будет возвращена ошибка, поскольку rows.Scan проверяет закрытие строк только единожды, при входе в функцию. Таким образом, при data race мы получаем поврежденные данные без возврата ошибки и не можем сказать, обнулялся запрос или нет, до тех пор, пока не совершим наш следующий вызов rows.Scan. Но этот вызов никогда не произойдет, потому что rows.Next() вернет false, и снова без ошибки.Проверка возвратного значения вызова
rows.Close — это единственный способ проверки корректного завершения сканирования строк нашего SQL запроса, но мы не совершаем этот вызов, так как строки закрыты в операторе defer. Кроме того, быстрый поиск кода по rows.Close() на Github демонстрирует, что практически никто явно не проверяет возвратное значение rows.Close() в своем коде. До API QueryContext такой подход был безопасен, но со времен Go 1.8 одного rows.Scan недостаточно. Без проверки обратного значения rows.Close() вы не узнаете, просканировали ли вы все все строки вашего SQL запроса, даже после устранения этого data race на Go MySQL драйвере. Так что обновляйте ваши lint’ы.Я знаю несколько способов устранения этой data race. Самый очевидный — и самый медленный — предлагает всегда клонировать память при возвращении из
driver.Rows.Next. Так как распределение памяти отложено до вызова пользователем sql.(*Rows).Scan, то драйверу не нужно выделять память при вызове driver.Rows.Next, в этом заключается сама идея контракта драйвера. Если мы станем распределять в Next, мы будем распределять память по два раза для каждой строки, и это вызовет сильную регрессию производительности. Ни команда сопровождающих Go MySQL, ни я не были довольны таким положением дел. Другие похожие методы, например, усечение основного буфера соединения при вызове sql.(*Rows).Close, были отвергнуты по той же причине — они потенциально распределяют память при каждом вызове Scan. В итоге критический баг так и провисел шесть месяцев без фикса, потому что команда не нашла устраивающего их ответа. Лично я очень опасаюсь ситуаций с долгим провисанием критически опасных багов, поэтому для исправления проблемы без вызова регрессии на наших хостах мне пришлось придумать нечто совершенно новое.Сначала я попробовал «опустошать» MySQL соединения без использования основного буфера соединений, ведь data race не возникнет, если мы не пишем в буфер. Но так как MySQL может высылать множество необходимых для опустошения пакетов, и разные размеры этих пакетов определяются их заголовками, мои попытки вскоре превратились в кошмарный спагетти-код. Частично парсить заголовки без буфера очень неприятно.
Я размышлял над этой проблемой еще некоторое время, и в один момент меня осенило — двойная буферизация. Это решение оказалась безумно простым и достаточно быстрым, чтобы в дальнейшем замержить его вверх. Еще во времена древних стеков компьютерной графики подобный стек записывал индивидуальные пиксели прямо на буфер кадров, а монитор одновременно с этим считывал пиксели со своей кадровой частотой. Когда стек писал данные в буфер кадров одновременно с тем, как экран считывал из него, наблюдалось мерцание, старый графический глич. Фундаментально мерцание можно определить как видимую невооруженным взглядом data race, что само по себе довольно интересный концепт. Проще всего устранить мерцание можно двумя буферами кадров: из одного буфера будет считывать данные экран (передний буфер), а в другой будет записывать данные графический процессор (задний буфер). Когда графический процессор завершает визуализацию кадра, мы автоматически меняем передний и задний буфер местами, поэтому монитор никогда не считает незаконченный кадр.
Рисунок 5: Двойная буферизация графического стека Nintendo 64. Если Марио этого достаточно, то и для MySQL драйвера сойдет.
Наша проблема и эта ситуация очень похожи, поэтому мы можем воспользоваться приемом с двумя буферами. В нашем случае, мы меняем местами наш буфер соединений с задним буфером, когда структура
driver.Rows закрывается по причине раннего обнуления запроса, и таким образом пока мы осушаем MySQL соединение в задний буфер, пользователь все еще может вызвать sql.Rows.Scan на передний. Когда в следующий раз SQL запрос поступит на то же самое соединение, мы продолжим чтение из заднего буфера, пока Rows не закроется вновь и мы не поменяем буферы обратно. Эта очень тривиальная имплементация распределяет память один раз за SQL соединение, амортизируя потери продуктивности. Мы сумели улучшить ситуацию для крайнего случая через задержку распределения в задний буфер до необходимости в первый раз опустошить в него данные, поэтому когда в обычной ситуации в MySQL соединении ни один запрос не обнуляется раньше, то не происходит и дополнительного распределения памяти.После аккуратной сборки нескольких тестов производительности регрессии двойной буферизации не было выявлено ни в одном из случаев, я наконец-то направил фикс вверх. К несчастью, особенности бага не дают посмотреть частоту чтения поврежденной памяти, однако его легко воспроизвести, поэтому таких чтений наверняка было довольно много.
Советы в продакшн
- Всегда проводите явную проверку возврата ошибки в вызове
(*Rows).Close, другого способа проверить, был ли SQL запрос потревожен в ходе сканирования, попросту нет. Тем не менее, не убирайте из вашего приложения вызовdefer rows.Close()— только им можно закрыть строки, если случаетсяpanicили ранний возврат в ходе вашего сканирования. Всегда безопасно несколько раз вызвать(*Rows).Close. - Никогда не используйте
(*Rows).Scanвместе с цельюsql.RawBytes. Даже если Go MySQL драйвер теперь намного более стойкий, при раннем обнулении доступ кRawBytesможет и будет падать с другими SQL драйверами. Если это случится, то вы с высокой вероятностью прочтете некорректные данные. Единственная разница между сканированием[]byteиsql.RawBytesв том, что raw версия распределяет дополнительную память, и столь крохотная оптимизация не стоит потенциальной data race в Context–осведомленном приложении.
Заключение
Развертывание кода на новом языке программирования в продакшн, особенно в масштабах Github, — это всегда вызов. Производительность и сложность наших моделей использования MySQL отражает нашу многолетнюю тонкую настройку MySQL клиента под Ruby, а теперь мы рады делать то же самое для Go MySQL драйвера. Релиз 1.5.0 Go MySQL драйвера содержит в себе все переданные нами вверх в ходе нашего первого развертывания Go фиксы и есть теперь в общем доступе. Мы же параллельно с ростом нашего использования Go в продакшне и дальше продолжим привносить исправления в драйвер и расширять его функционал.
Спасибо сопровождающим Go MySQL специалистам, @methane и @julienschmidt за их помощь с патчами!

 файла в 1С-Битрикс")

