
Микросервисы — модная и распространённая сегодня архитектура. Но когда количество микросервисов разрастается до тысяч и десятков тысяч микросервисов, что делать со «спагетти» огромного графа зависимостей, как удобно изменять сервисы? Специально к старту нового потока курса «профессия Data Scientist» мы подготовили перевод материала, в котором рассказывается о Viaduct — ориентированной на данные сервисной сетке от Airbnb, по сути, повторяющей путь парадигм программирования — от процедурного до ориентированного на данные подхода. Подробности под катом.

22 октября мы представили Viaduct — то, что мы называем data-ориентированной сервисной сеткой. Она, как нам кажется, — шаг к улучшению модульности нашей сервисно-ориентированной архитектуры (SOA), основанной на микросервисах. Здесь мы расскажем о философии Viaduct и дадим приблизительный набросок её работы. Чтобы узнать о деталях, пожалуйста, посмотрите видеопрезентацию.
Какое-то время сервисно-ориентированные архитектуры движутся в направлении все большего количества небольших микросервисов. Современные приложения могут состоять из тысяч и десятков тысяч подключаемых без ограничений микросервисов. В результате нередко можно увидеть такие графы зависимостей:
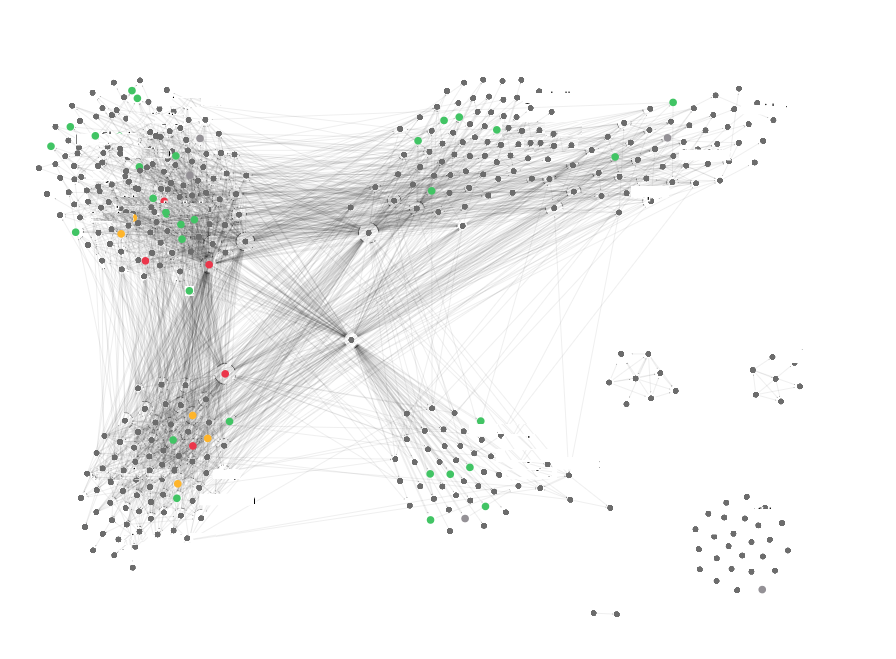
Это граф зависимостей в Airbnb, но такие графы не редкость. Amazon, Netflix и Uber — примеры компаний, работающих с похожими графами зависимостей.
Такие графы напоминают спагетти-код, но на уровне микросервисов. Подобно тому, как спагетти-код со временем всё труднее и труднее изменять, затрудняются изменения и спагетти-SOA. Чтобы помочь управлять большим количеством микросервисов, нам нужны организационные принципы, а также технические меры их реализации. Мы попытались найти такие меры и принципы. Исследования привели нас к концепции сервисной сетки, ориентированной на данные, которая, по нашему мнению, привносит в SOA новый уровень модульности.
Организация больших программ в модульные блоки — не новая проблема в программной инженерии. Вплоть до 1970-х годов основная парадигма организации программного обеспечения сосредоточивалась на группировке кода в процедуры, а процедур — в модули. При таком подходе модули публикуют открытый API для использования другим кодом вне модуля; за этим открытым API модули скрывают внутренние вспомогательные процедуры и другие детали реализации. На этой парадигме основаны такие языки, как Pascal и C.
С 1980-х годов процедурная парадигма сместилась в сторону организацией программного обеспечения в первую очередь вокруг данных, а не процедур. В этом подходе модули определяют классы объектов, которые инкапсулируют внутреннее представление объекта, доступ к представлению осуществляется через открытый API методов объекта. Пионерами этой формы организации были Simula и Clu.
SOA — это шаг назад, к более процедурно-ориентированным конструкциям. Сегодняшний микросервис — это набор процедурных конечных точек — классический модуль в стиле 1970-х годов. Мы считаем, что SOA должна развиваться до поддержки ориентированного на данные дизайна и что эта эволюция может обеспечиваться путем перехода нашей сервисной сетки от процедурной ориентации к ориентации на данные.
Центральное место в современных масштабируемых SOA-приложениях занимает сервисная сетка (например Istio, Linkerd), направляющая вызовы служб к экземплярам микросервисов, которые, в свою очередь, могут их обрабатывать. Сегодняшний отраслевой стандарт для сервисных сеток состоит в том, чтобы организовываться исключительно вокруг удаленных вызовов процедур, ничего не зная о данных. Наше видение в том, чтобы заменить эти процедурно-ориентированные сервисные сетки сервисными сетками, которые организованы вокруг данных.
В Airbnb GraphQL️ используется для построения ориентированной на данные сервисной сетки под названием Viaduct. Сетка обслуживания Viaduct определяется в терминах схемы GraphQL, состоящей из:
Типы (и интерфейсы) в схеме определяют единый граф для всех данных, управляемых в пределах сервисной сети. Например, в компании электронной коммерции схема сервисной сети может определять поле
Запрошенные таким запросом элементы данных могут поступать из множества различных микросервисов. В ориентированной на процедуры сервисной сетке потребитель данных должен воспринимать эти сервисы как явные зависимости. В нашей сервисной сетке, ориентированной на данные, именно сервисная сетка, то есть Viaduct, а не потребитель данных, знает, какие службы предоставляют какой элемент данных. Viaduct абстрагирует зависимости сервиса от любого отдельного потребителя.
Здесь мы обсудим, как в отличие от других распределенных систем GraphQL, таких как GraphQL Modules или Apollo Federation Viaduct рассматривает схему в качестве единого артефакта и реализует несколько примитивов, позволяющих нам поддерживать единую схему, в то же время позволяя многим командам продуктивно сотрудничать по этой схеме. По мере того как Viaduct заменяет все больше и больше наших базовых ориентированных на процедуры сервисных сетей, его схема все более и более полно фиксирует управляемые нашим приложением данные.
Мы воспользовались преимуществами этой «центральной схемы», как мы её называем, в качестве места для определения API-интерфейсов некоторых микросервисов. В частности, мы начали использовать GraphQL для API некоторых микросервисов. Схемы GraphQL этих сервисов определены как подмножество центральной схемы. В будущем мы хотим развить эту идею дальше, используя центральную схему для определения схемы данных, хранящихся в нашей базе данных.
Среди прочего использование центральной схемы для определения API-интерфейсов и схем баз данных решит одну из самых серьезных проблем крупномасштабных приложений SOA: подвижность данных. В современных приложениях SOA изменение схемы базы данных часто требует ручного отражения в API-интерфейсах двух, трёх, а иногда и более уровней микросервисов, прежде чем оно может быть представлено клиентскому коду. Такие изменения могут потребовать недель координации между несколькими командами. При получении сервисных API и схемы базы данных из единой центральной схемы подобное изменение схемы базы данных может быть передаваться клиентскому коду одним обновлением.
Часто в больших SOA-приложениях существует множество сервисов «производных данных» без сохранения состояния, а также сервисов «бэкенд для фронтенда», которые берут необработанные данные из сервисов нижнего уровня и преобразуют их в данные, более подходящие для представления на клиентах. Такая логика без сохранения состояния хорошо подходит для модели бессерверных вычислений, которая полностью устраняет операционные издержки микросервисов и вместо этого размещает логику в структуре «облачных функций».
В Viaduct есть механизм для вычисления того, что мы называем «производными полями», с использованием бессерверных облачных функций, которые работают над графом без знания о нижележащих сервисах. Эти функции позволяют перемещать трансформационную логику из сервисной сети в контейнеры без сохранения состояния, при этом сохраняя граф чистым и уменьшая количество и сложность необходимых сервисов.
Viaduct построен на graphql-java и поддерживает детализированный выбор полей с помощью наборов выбора GraphQL. Viaduct использует современные методы загрузки данных, а также такие методы обеспечения надежности, как «короткое замыкание» и мягкие зависимости, реализует кэш внутри запроса. Viaduct обеспечивает наблюдаемость данных, позволяя нам понять вплоть до уровня полей, какие сервисы и какие данные потребляют. Будучи интерфейсом GraphQL, Viaduct позволяет использовать преимущества большой экосистемы инструментов с открытым исходным кодом, включая Live IDE, заглушки серверов и визуализаторы схем.
Viaduct начал поддерживать производственные процессы на Airbnb более года назад. Мы начали с нуля, с чистой схемы из нескольких сущностей и расширили её, включив 80 основных сущностей, которые могут работать с 75 % нашего современного трафика API.

22 октября мы представили Viaduct — то, что мы называем data-ориентированной сервисной сеткой. Она, как нам кажется, — шаг к улучшению модульности нашей сервисно-ориентированной архитектуры (SOA), основанной на микросервисах. Здесь мы расскажем о философии Viaduct и дадим приблизительный набросок её работы. Чтобы узнать о деталях, пожалуйста, посмотрите видеопрезентацию.
Большие графы зависимостей SOA
Какое-то время сервисно-ориентированные архитектуры движутся в направлении все большего количества небольших микросервисов. Современные приложения могут состоять из тысяч и десятков тысяч подключаемых без ограничений микросервисов. В результате нередко можно увидеть такие графы зависимостей:
Это граф зависимостей в Airbnb, но такие графы не редкость. Amazon, Netflix и Uber — примеры компаний, работающих с похожими графами зависимостей.
Такие графы напоминают спагетти-код, но на уровне микросервисов. Подобно тому, как спагетти-код со временем всё труднее и труднее изменять, затрудняются изменения и спагетти-SOA. Чтобы помочь управлять большим количеством микросервисов, нам нужны организационные принципы, а также технические меры их реализации. Мы попытались найти такие меры и принципы. Исследования привели нас к концепции сервисной сетки, ориентированной на данные, которая, по нашему мнению, привносит в SOA новый уровень модульности.
Процедурный и Data-ориентированный дизайн
Организация больших программ в модульные блоки — не новая проблема в программной инженерии. Вплоть до 1970-х годов основная парадигма организации программного обеспечения сосредоточивалась на группировке кода в процедуры, а процедур — в модули. При таком подходе модули публикуют открытый API для использования другим кодом вне модуля; за этим открытым API модули скрывают внутренние вспомогательные процедуры и другие детали реализации. На этой парадигме основаны такие языки, как Pascal и C.
С 1980-х годов процедурная парадигма сместилась в сторону организацией программного обеспечения в первую очередь вокруг данных, а не процедур. В этом подходе модули определяют классы объектов, которые инкапсулируют внутреннее представление объекта, доступ к представлению осуществляется через открытый API методов объекта. Пионерами этой формы организации были Simula и Clu.
SOA — это шаг назад, к более процедурно-ориентированным конструкциям. Сегодняшний микросервис — это набор процедурных конечных точек — классический модуль в стиле 1970-х годов. Мы считаем, что SOA должна развиваться до поддержки ориентированного на данные дизайна и что эта эволюция может обеспечиваться путем перехода нашей сервисной сетки от процедурной ориентации к ориентации на данные.
Viaduct: Data-ориентированная сервисная-сетка
Центральное место в современных масштабируемых SOA-приложениях занимает сервисная сетка (например Istio, Linkerd), направляющая вызовы служб к экземплярам микросервисов, которые, в свою очередь, могут их обрабатывать. Сегодняшний отраслевой стандарт для сервисных сеток состоит в том, чтобы организовываться исключительно вокруг удаленных вызовов процедур, ничего не зная о данных. Наше видение в том, чтобы заменить эти процедурно-ориентированные сервисные сетки сервисными сетками, которые организованы вокруг данных.
В Airbnb GraphQL️ используется для построения ориентированной на данные сервисной сетки под названием Viaduct. Сетка обслуживания Viaduct определяется в терминах схемы GraphQL, состоящей из:
- типов (и интерфейсов), описывающих данные, управляемые в вашей сервисной сетке;
- запросов (и подписок), предоставляющих средства доступа к этим данным, которые абстрагируются от точек входа сервиса, которые предоставляют эти данные;
- мутаций, предоставляющих способы обновления данных, опять же абстрагированные от точек входа в сервис.
Типы (и интерфейсы) в схеме определяют единый граф для всех данных, управляемых в пределах сервисной сети. Например, в компании электронной коммерции схема сервисной сети может определять поле
productById (id: ID), которое возвращает результаты типа Product. С этой отправной точки один запрос позволяет потребителю данных перейти к информации о производителе продукта, например productById {Manufacturer}, отзывах о продукте, например productById {reviews} и даже об авторах отзывов, например productById {reviews {author}}.Запрошенные таким запросом элементы данных могут поступать из множества различных микросервисов. В ориентированной на процедуры сервисной сетке потребитель данных должен воспринимать эти сервисы как явные зависимости. В нашей сервисной сетке, ориентированной на данные, именно сервисная сетка, то есть Viaduct, а не потребитель данных, знает, какие службы предоставляют какой элемент данных. Viaduct абстрагирует зависимости сервиса от любого отдельного потребителя.
Размещение схемы в центре
Здесь мы обсудим, как в отличие от других распределенных систем GraphQL, таких как GraphQL Modules или Apollo Federation Viaduct рассматривает схему в качестве единого артефакта и реализует несколько примитивов, позволяющих нам поддерживать единую схему, в то же время позволяя многим командам продуктивно сотрудничать по этой схеме. По мере того как Viaduct заменяет все больше и больше наших базовых ориентированных на процедуры сервисных сетей, его схема все более и более полно фиксирует управляемые нашим приложением данные.
Мы воспользовались преимуществами этой «центральной схемы», как мы её называем, в качестве места для определения API-интерфейсов некоторых микросервисов. В частности, мы начали использовать GraphQL для API некоторых микросервисов. Схемы GraphQL этих сервисов определены как подмножество центральной схемы. В будущем мы хотим развить эту идею дальше, используя центральную схему для определения схемы данных, хранящихся в нашей базе данных.
Среди прочего использование центральной схемы для определения API-интерфейсов и схем баз данных решит одну из самых серьезных проблем крупномасштабных приложений SOA: подвижность данных. В современных приложениях SOA изменение схемы базы данных часто требует ручного отражения в API-интерфейсах двух, трёх, а иногда и более уровней микросервисов, прежде чем оно может быть представлено клиентскому коду. Такие изменения могут потребовать недель координации между несколькими командами. При получении сервисных API и схемы базы данных из единой центральной схемы подобное изменение схемы базы данных может быть передаваться клиентскому коду одним обновлением.
Приходим к бессерверности
Часто в больших SOA-приложениях существует множество сервисов «производных данных» без сохранения состояния, а также сервисов «бэкенд для фронтенда», которые берут необработанные данные из сервисов нижнего уровня и преобразуют их в данные, более подходящие для представления на клиентах. Такая логика без сохранения состояния хорошо подходит для модели бессерверных вычислений, которая полностью устраняет операционные издержки микросервисов и вместо этого размещает логику в структуре «облачных функций».
В Viaduct есть механизм для вычисления того, что мы называем «производными полями», с использованием бессерверных облачных функций, которые работают над графом без знания о нижележащих сервисах. Эти функции позволяют перемещать трансформационную логику из сервисной сети в контейнеры без сохранения состояния, при этом сохраняя граф чистым и уменьшая количество и сложность необходимых сервисов.
Заключение
Viaduct построен на graphql-java и поддерживает детализированный выбор полей с помощью наборов выбора GraphQL. Viaduct использует современные методы загрузки данных, а также такие методы обеспечения надежности, как «короткое замыкание» и мягкие зависимости, реализует кэш внутри запроса. Viaduct обеспечивает наблюдаемость данных, позволяя нам понять вплоть до уровня полей, какие сервисы и какие данные потребляют. Будучи интерфейсом GraphQL, Viaduct позволяет использовать преимущества большой экосистемы инструментов с открытым исходным кодом, включая Live IDE, заглушки серверов и визуализаторы схем.
Viaduct начал поддерживать производственные процессы на Airbnb более года назад. Мы начали с нуля, с чистой схемы из нескольких сущностей и расширили её, включив 80 основных сущностей, которые могут работать с 75 % нашего современного трафика API.
- Обучение профессии Data Science
- Обучение профессии Data Analyst
- Онлайн-буткемп по Data Analytics
- Курс «Python для веб-разработки»
Eще курсы
- Обучение профессии C#-разработчик
- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Machine Learning
- Разработчик игр на Unity
- Профессия Веб-разработчик
- Профессия Java-разработчик
- Курс по JavaScript
- C++ разработчик
- Курс по аналитике данных
- Курс по DevOps
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
Рекомендуемые статьи
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд
- Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в России и за рубежом в 2020
- Machine Learning и Computer Vision в добывающей промышленности




