
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
 Привет, Хабр! В этой статье я хочу рассказать о решении одной из типичных проблем, с которой Embox справляется лучше GNU/Linux. Речь идет о времени реакции на пакет, переданный по протоколу Ethernet. Как известно, основной характеристикой передачи данных по сети является пропускная способность, и с ней у GNU/Linux все хорошо. Но когда речь заходит об уменьшении времени на прием/передачу единичного сетевого пакета, могут возникнуть проблемы. В частности, у заказчика была плата DE0-Nano-SoC с Linux, и с помощью этой платы хотелось управлять неким объектом по сети. Топология сети — точка-точка, никаких роутеров и хабов нет. По модели управления время реакции должно быть меньше 100 мкс, а на базе Linux удавалось добиться только 500 мкс.
Привет, Хабр! В этой статье я хочу рассказать о решении одной из типичных проблем, с которой Embox справляется лучше GNU/Linux. Речь идет о времени реакции на пакет, переданный по протоколу Ethernet. Как известно, основной характеристикой передачи данных по сети является пропускная способность, и с ней у GNU/Linux все хорошо. Но когда речь заходит об уменьшении времени на прием/передачу единичного сетевого пакета, могут возникнуть проблемы. В частности, у заказчика была плата DE0-Nano-SoC с Linux, и с помощью этой платы хотелось управлять неким объектом по сети. Топология сети — точка-точка, никаких роутеров и хабов нет. По модели управления время реакции должно быть меньше 100 мкс, а на базе Linux удавалось добиться только 500 мкс.

Для оценки времени передачи создаем стенд, состоящий из двух хостов.
В качестве первого хоста выступает компьютер общего назначения с GNU/Linux, в качестве второго хоста — отладочная плата DE0-Nano-SoC Kit с Embox. Эта плата содержит FPGA и HPS (Hard Processing System, т.е. обычный ARM), и именно на ней нужно уменьшать время отклика. Напишем тестовое приложение, которое просто будет отвечать UDP-пакетом с идентичным содержимым:
while (1) {
char buf[BUFLEN];
recvfrom(s, buf, BUFLEN);
sendto(s, buf, BUFLEN);
}Его будем запускать на втором хосте, то есть на DE0-Nano-SoC.
На первом хосте программа будет посылать пакеты, ждать ответа и измерять время между отправкой и приемом:
for (int i = 0; i < N; i++) {
char buf_tx[BUFLEN], buf_rx[BUFLEN];
sprintf(buf_tx, "This is packet %d\n", i);
time_t time_begin = time_now();
sendto(s, buf_tx, BUFLEN);
recvfrom(s, buf_rx, BUFLEN);
time_t time_end = time_now();
if (memcmp(buf_tx, buf_rx, sizeof(buf))) {
printf("%d: Buffer mismatch\n", i);
}
if (time_end - time_begin > TIME_LIMIT) {
printf("Slow answer #%d: %d\n", i, time_end - time_begin);
}
}При этом вычислим среднее, максимальное и минимальное время отклика.
Код есть на Github.
Сделав пробный запуск и удостоверившись, что пакеты приходят и уходят, на стороне отладочной платы сразу применим очевидные оптимизации:
- Уберём весь отладочный вывод в UART — это дало самый значительный выигрыш, уж слишком он медленный
- Соберём с флагом
-O2 - Включим кэш-контроллер второго уровня PL310 (это не помогло практически никак)
При отправке 500 000 пакетов (столько же отправлялось и в следующих примерах) получились такие значения:
Avg: 4.52ms
Min: 3.12ms
Max: 12.24msЭто в несколько раз медленнее, чем ориентировочные значения, предоставленные со стороны заказчика — среднее значение должно быть хотя бы на порядок меньше. Заказчик говорил, что у него на Linux получались даже лучшие характеристики. Мы начали думать, что может быть не так.
Возможно, дело в других процессах? Но нет, кроме данной программы на плате ничего не запускается.
Возможно, много времени уходит на обработку каких-то прерываний, например, таймера? Тоже нет — снижение частоты его срабатываний никак не влияет на результат.
Как оказалось, дело было в скорости самого ethernet-соединения — использовался USB-адаптер, поддерживающий максимум 100Мбит/с, да и в драйвере не было поддержки гигабитной скорости.
После замены сетевой карты и добавления поддержки 1Гбит в драйвере получаем ещё один значительный скачок в производительности:
Avg: 0.08ms
Min: 0.07ms
Max: 4.31msСравнение с Linux
Достаточно естественно сравнить это время с Linux. То же самое приложение очень просто кросс-компилировать: arm-linux-gnueabihf-gcc server.c -O2. Получившийся ELF заливаем на плату и запускаем:
Avg: 0.77ms
Min: 0.74ms
Max: 5.31msТаким образом, Embox "отвечает" примерно в 9 раз быстрее, что не может не радовать!
Исследование разброса
Среднее время отклика вполне хорошее, но есть "выбросы", которые не только имеют слишком большую задержку, но и вносят значительную непредсказуемость.
Для того, чтобы определить источник задержек, было решено замерить аппаратным таймером время, которой занимает обработка UDP-пакета от его приёма до отправки соответствующего ответа.
Можно накапливать статистику на отладочной плате, но проще сразу же передать на хост данные прямо в UDP-пакете.
В итоге мы решили, что прямо в пакет UDP будем ставить метки времени прихода и отправления. Причём время получения пакета записывается до передачи пакета пользовательскому приложению, прямо в обработчике прерывания. Время отправления будет получать перед самой отправкой пакета в сеть. Ну а дальше приблизительно такой код:
int net_tx(...) {
if (is_udp_packet()) {
timestamp2 = timer_get();
memcpy(packet[UDP_OFFT],
×tamp1,
sizeof(timestamp1));
memcpy(packet[UDP_OFFT + sizeof(timestamp2)],
×tamp2,
sizeof(timestamp2));
...
}
}В данном случае не важно, с какой частотой работает таймер, достаточно убедиться, что выбросы по времени совпадают с более долгой обработкой пакета внутри Embox.
Получили такие результаты
Avg: 8673
Min: 6191
Max: 11950При изучении полученных данных оказалось, что разброс времени обработки пакета составляет (между средним и максимальным) где то 25%, что конечно никак не может объяснить разброс на хосте (Avg: 0.08ms Max: 4.31ms). То есть либо задержки происходят вне проверяемого интервала (после получения пакета, но до входа в соответствующий обработчик прерывания, либо после того, как начинается отправка), либо задержки возникают на другом конце провода. В любом случае, ситуацию программно уже не удастся улучшить, точнее её можно улучшить только на 25%.
Может, проблема на другой стороне?
Остаётся один вариант — задержки возникают на стороне приложения Linux, ведь мы для измерений использовали обычный хост.
Как это проверить?
Первое, что приходит в голову — запустить процесс с высоким приоритетом:
nice -n -20 ./client
Ощутимых изменений это не дало — казалось, небольшой прирост есть, но разброс от раза к разу всё равно значительно его перекрывал.
Ещё один способ — запустить процесс с алгоритмом планирования round robin и с высоким приоритетом, это можно сделать с помощью chrt:
chrt --rr 99 ./client
И на этот раз нужный эффект действительно был достигнут — количество длительных задержек уменьшилось на порядок. Приведу гистрограмму распределения задержек для разных стратегий планировщика (масштаб оси ординат имеет логарифмический масштаб, т.к. при линейном столбцы после первого не различимы).
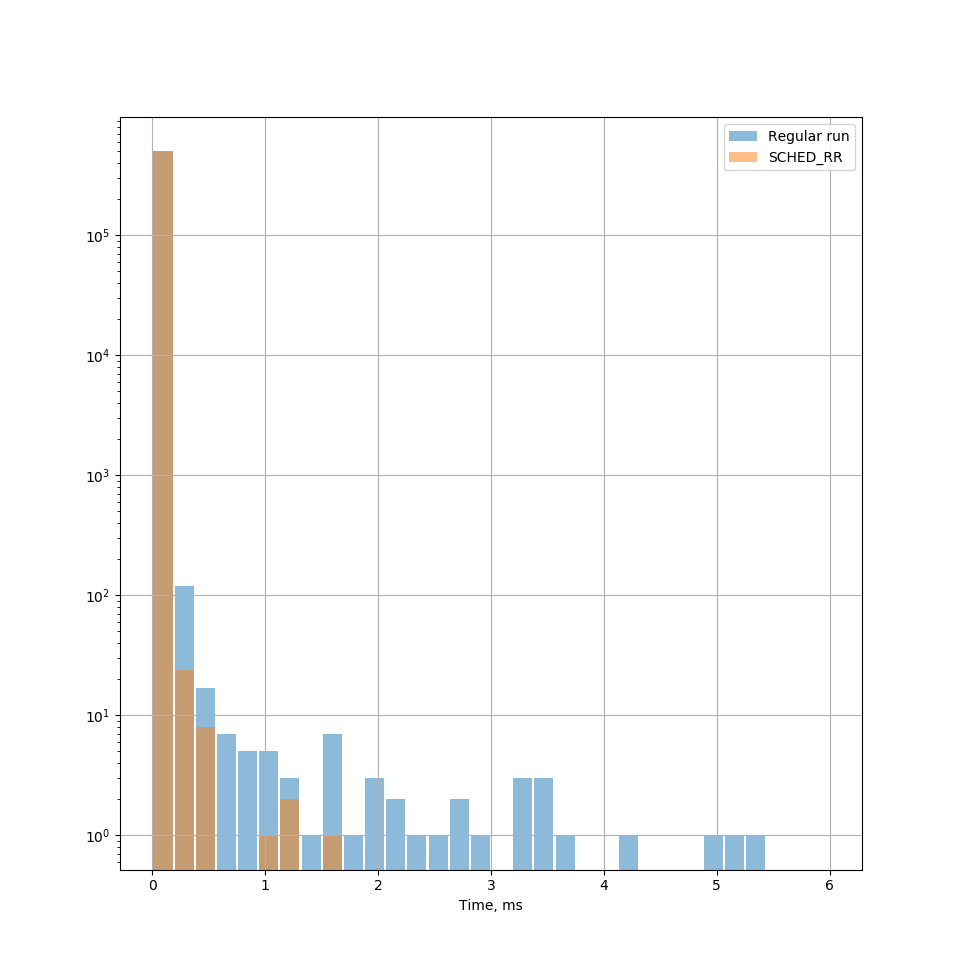
Используя Embox удалось достаточно просто решить поставленную задачу, уменьшить время отклика на один пакет почти в 10 раз. При этом прикладное ПО у заказчика остается фактически без изменений, следовательно, его не нужно переписывать и отлаживать. Может кто нибудь подскажет, можно ли добиться оптимизации данного параметра средствами Linux, например используя какой-нибудь bpfilter.
Если есть какие-то вопросы — пишите в рассылку embox-devel@googlegroups.com, или в наш телеграм-чат, или в комментарии здесь.



