
В ClickHouse постоянно возникают задачи, связанные с обработкой строк. Например, поиск, вычисление свойств UTF-8 строк или что-то более экзотическое, будь то поиск типа учёта регистра или поиск по сжатым данным.
Всё началось с того, что руководитель разработки ClickHouse Лёша Миловидов o6CuFl2Q пришёл к нам на факультет компьютерных наук в НИУ ВШЭ и предложил огромное количество тем для курсовых и дипломов. Когда я увидел «Умные алгоритмы обработки строк в ClickHouse» (я, человек, который увлекается разными алгоритмами, в том числе экспериментальными), сразу же настроил планов, как сделаю самый крутой диплом. Мою радость и выражение лица можно описать следующей картинкой:

ClickHouse
В ClickHouse тщательно продумана организация хранения данных в памяти — по колонкам. В конце каждой колонки есть паддинг в 15 байт для безопасного чтения 16-байтового регистра. Например, ColumnString хранит строки null terminated вместе с оффсетами. С такими массивами очень удобно работать.

Ещё есть ColumnFixedString, ColumnConst и LowCardinality, но о них мы не так подробно поговорим сегодня. Главное в этом пункте то, что дизайн безопасного чтения хвостов просто прекрасен, и локальность данных тоже играет роль в обработке.
Поиск по подстрокам
Скорее всего, вы знаете много разных алгоритмов поиска подстроки в строке. Мы расскажем о тех, что используются в ClickHouse. Сначала введём пару определений:
- haystack — строка, в которой мы ищем; типично длина обозначается n.
- needle — строка или регулярное выражение, по которому мы ищем; длина будет обозначаться m.
После изучения большого количества алгоритмов могу сказать, что есть 2 (максимум 3) вида алгоритмов поиска подстрок. Первый — создание в том или ином виде суффиксных структур. Второй вид — алгоритмы, основанные на сравнении памяти. Ещё есть алгоритм Рабина — Карпа, который использует хэши, но он достаточно уникален в своём роде. Самого быстрого алгоритма не существует, всё зависит от размера алфавита, длины needle, haystack и частоты вхождения.
Почитать про разные алгоритмы можно здесь. А вот наиболее популярные алгоритмы:
- Кнута — Морриса — Пратта,
- Бойера — Мура,
- Бойера — Мура — Хорспула,
- Рабина — Карпа,
- Двусторонний (используется в glibc под названием «memmem»),
- BNDM.
Список можно продолжать. Мы в ClickHouse честно всё попробовали, но в итоге остановились на более экстраординарном варианте.
Алгоритм Волницкого
Алгоритм был опубликован в блоге программиста Леонида Волницкого в конце 2010 года. Он чем-то напоминает алгоритм Бойера — Мура — Хорспула, только улучшенную версию.
Если m < 4, то применяется стандартный алгоритм поиска. Сохраним все биграммы (2 идущих подряд байта) needle с конца в хэш-таблицу с открытой адресацией размера |Sigma|2 элементов (на практике это 216 элементов), где оффсеты данной биграммы будут значениями, а сама биграмма — хэшом и индексом одновременно. Изначальная позиция будет на позиции m — 2 от начала haystack. Походим по haystack с шагом m — 1, посмотрим на очередную биграмму с этой позиции в haystack и рассмотрим все значения по биграмме в хэш-таблице. Затем будем сравнивать два куска памяти обычным алгоритмом сравнения. Хвост, который останется, обработаем этим же алгоритмом.
Шаг m — 1 выбран таким образом, что если есть вхождение needle в haystack, то мы обязательно рассматриваем биграмму этого вхождения — тем самым гарантируя, что вернём позицию вхождения в haystack. Первое вхождение гарантируется тем, что в хэш-таблицу по биграмме мы добавим индексы с конца. Это значит, что когда пойдём слева направо, то сначала будем рассматривать биграммы с конца строки (возможно, изначально рассматривая совершенно ненужные биграммы), потом — ближе к началу.
Рассмотрим пример. Пусть строка haystack будет abacabaac и needle равна aaca. Хэш-таблица будет {aa : 0, ac : 1, ca : 2}.
0 1 2 3 4 5 6 7 8 9
a b a c a b a a c a
^ - курсор изначальный здесьВидим биграмму ac. В needle она есть, подставляем в равенство:
0 1 2 3 4 5 6 7 8 9
a b a c a b a a c a
a a c aНе совпало. После ac в хэш-таблице нет никаких записей, шагаем с шагом 3:
0 1 2 3 4 5 6 7 8 9
a b a c a b a a c a
^ - курсор теперь здесьБиграммы ba в хэш-таблице нет, идём дальше:
0 1 2 3 4 5 6 7 8 9
a b a c a b a a c a
^ - курсор теперь здесьБиграмма ca в needle есть, смотрим на оффсет и находим вхождение:
0 1 2 3 4 5 6 7 8 9
a b a c a b a a c a
a a c aУ алгоритма много плюсов. Во-первых, можно не выделять память на куче, а 64 КБ на стеке не являются сейчас чем-то заоблачным. Во-вторых, 216 — отличное число для взятия по модулю для процессора; это просто инструкции movzwl (или как мы шутим, «мовзвл») и семейство.
В среднем этот алгоритм проявил себя лучше всех. Данные мы взяли из Яндекс.Метрики, запросы почти реальные. Скорость на один поток, больше лучше, KMP: алгоритм Кнута — Морриса — Пратта, BM: Бойера — Мура, BMH: Бойера — Мура — Хорспула.
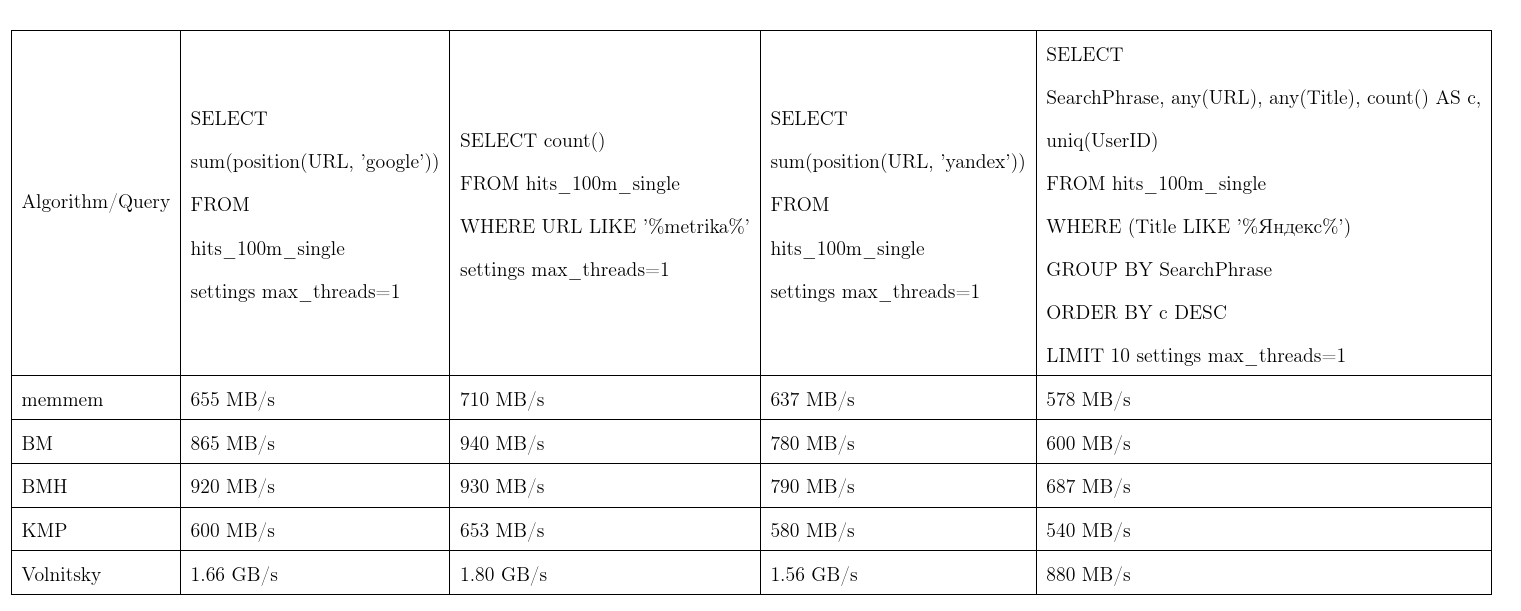
Чтобы не быть голословным, алгоритм может работать квадратичное время:

Он используется в функции position(Column, ConstNeedle), а также выступает оптимизацией для поиска по регулярным выражениям.
Поиск по регулярным выражениям
Расскажем, как в ClickHouse оптимизирован поиск по регулярным выражениям. Много регулярных выражений содержат внутри подстроку, которая обязательно должна быть внутри haystack. Чтобы не строить конечный автомат и проверять по нему, будем вычленять такие подстроки.
Сделать это достаточно просто: любые открывающие скобки увеличивают уровень вложенности, любые закрывающие — уменьшают; также есть символы, специфичные для регулярных выражений (например, '.', '*', '?', '\w' и т. д.). Нам надо достать все подстроки на уровне 0. Рассмотрим пример:
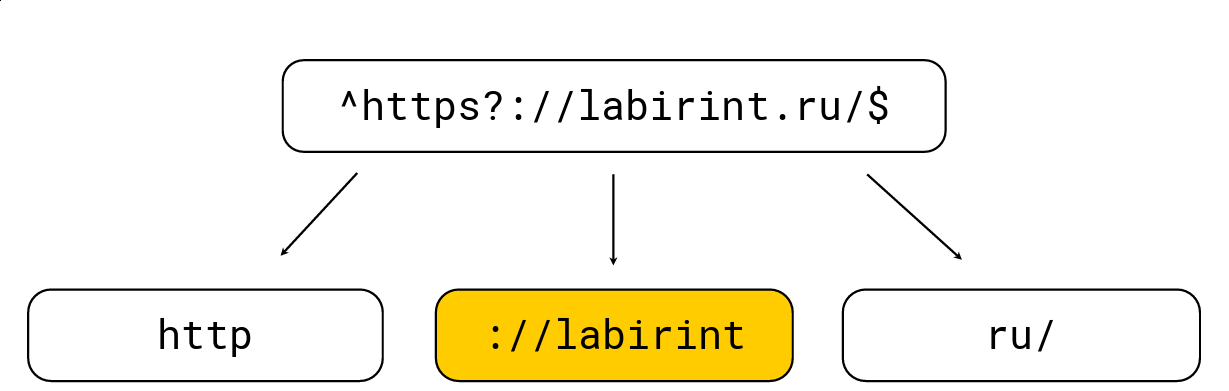
Разбиваем на те подстроки, которые обязаны быть в haystack из регулярного выражения, после чего выбираем максимальную длину, ищем по ней кандидатов и дальше уже проверяем обычным движком регулярных выражений RE2. На картинке выше есть регулярное выражение, оно обрабатывается обычным движком RE2 за 736 МБ/с, Hyperscan (о нём чуть позже) справляется за 1,6 ГБ/с, а мы справляемся за 1,69 ГБ/c на одно ядро вместе с разжатием LZ4. В целом, такая оптимизация лежит на поверхности и сильно ускоряет поиск по регулярным выражениям, но часто её не имплементируют в тулзах, что меня сильно удивляет.
Ключевое слово LIKE тоже оптимизировано с помощью данного алгоритма, только после LIKE может идти очень упрощённое регулярное выражение через %%%%% (произвольная подстрока) и _ (произвольный символ).
К сожалению, не все регулярные выражения подвержены таким оптимизациям, например из yandex|google нельзя явно вычленить подстроки, которые обязаны встречаться в haystack. Поэтому мы придумали совершенно иное решение.
Поиск по многим подстрокам
Задача заключается в том, что есть много needle, и хочется понять, входит ли хотя бы одна из них в haystack. Существуют достаточно классические методы такого поиска, например алгоритм Ахо — Корасик. Но он оказался не слишком быстрым для нашей задачи. Об этом чуть позже поговорим.
Лёша ClickHouse любит нестандартные решения, поэтому мы решили попробовать что-то иное и, возможно, самим сделать новый алгоритм поиска. И сделали.
Мы посмотрели на алгоритм Волницкого и модифицировали его так, чтобы он начал искать сразу много подстрок. Для этого надо всего лишь добавлять биграммы всех строк и хранить в хэш-таблице дополнительно индекс строки. Шаг будет выбран как минимум из всех длин needle минус 1, чтобы снова гарантировать свойство, что при наличии вхождения мы посмотрим его биграмму. Хэш-таблица вырастет до 128 КБ (строки длиннее 255 обрабатываются стандартным алгоритмом, будем рассматривать не более 256 needle). Я очень ленивый, поэтому вот пример из презентации (читать слева направо сверху вниз):


Начали смотреть, как такой алгоритм ведёт себя по сравнению с другими (строки взяты из реальных данных). И для маленького количества строк он уделывает всех (указана скорость вместе с разжатием — примерно 2,5 ГБ/с).
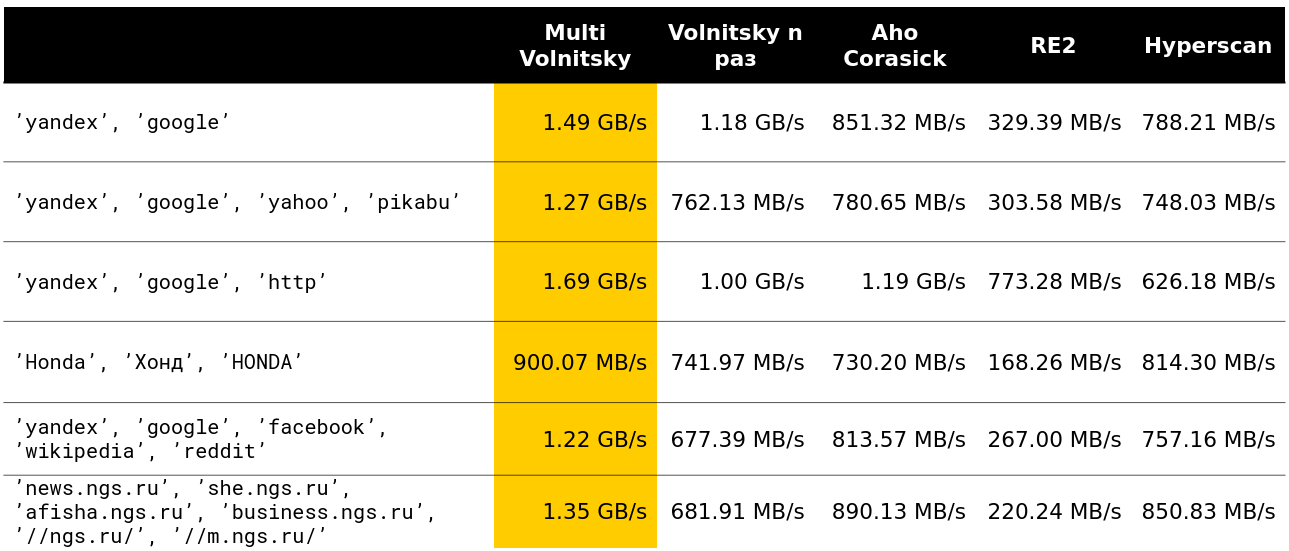
Дальше стало интересно. Например, при большом количестве похожих биграмм мы проигрываем некоторым конкурентам. Оно и понятно — начинаем сравнивать много кусков памяти и деградировать.

Нельзя сильно ускоряться, если минимальная длина needle достаточно большая. Очевидно, что у нас больше возможностей пропустить целые куски haystack, ничего за это не заплатив.

Переломный момент начинается где-то на 13-15 строках. Примерно 97% запросов, которые я видел на кластере, были меньше 15 строк:
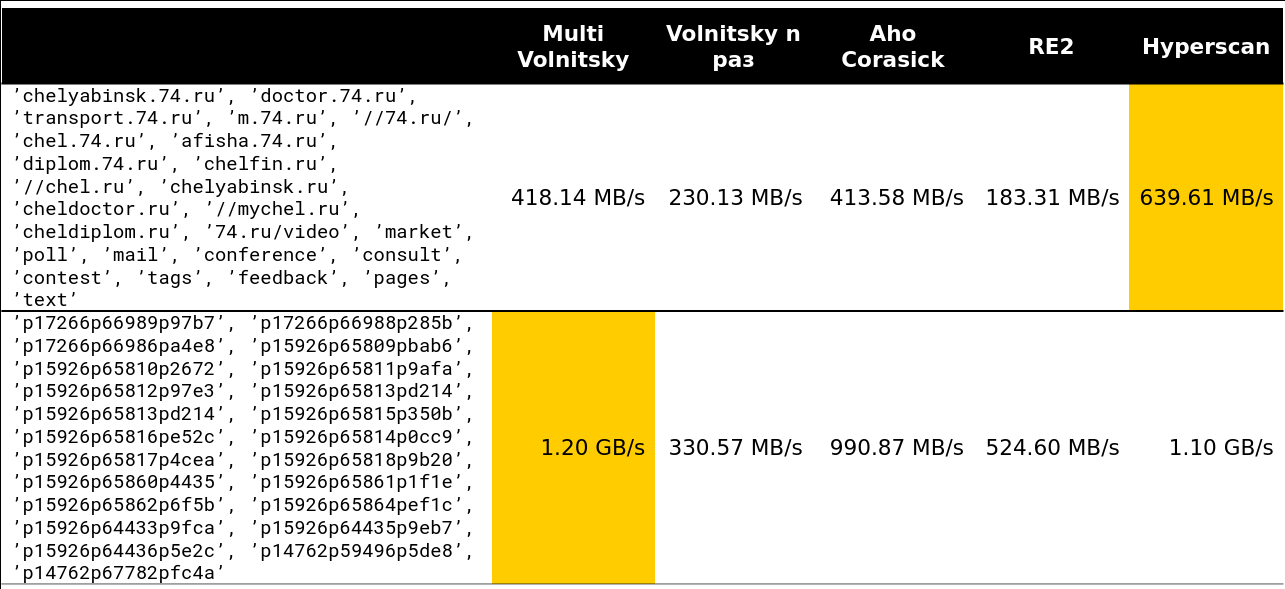
Ну и совсем страшная картинка — 41 строка, много повторяющихся биграмм:

В итоге в ClickHouse (19.5) мы реализовали через этот алгоритм следующие функции:
— multiSearchAny(h, [n_1, ..., n_k]) — 1, если хоть кто-то из needle входит в haystack.
— multiSearchFirstPosition(h, [n_1, ..., n_k]) — самая левая позиция вхождения в haystack (с единицы) или 0, если не нашлось.
— multiSearchFirstIndex(h, [n_1, ..., n_k]) — самый левый индекс needle, который нашёлся в haystack; 0, если не нашлось.
— multiSearchAllPositions(h, [n_1, ..., n_k]) — все первые позиции всех needle, возвращает array.
Суффиксы -UTF8 (не нормализируем), -CaseInsensitive (добавляем 4 биграммы с разным регистром), -CaseInsensitiveUTF8 (есть условие, что большие и маленькие буквы должны быть одинакового количества байтов). Реализацию можно посмотреть здесь.
После этого мы задумались, можно ли что-то подобное провернуть со многими регулярными выражениями? И нашли решение, которое уже проспойлерили в бенчмарках.
Поиск по многим регулярным выражениям
Hyperscan — библиотека от Intel, которая ищет сразу по многим регулярным выражениям. Она использует эвристики вычленения подслов из регулярных выражений, о которых мы писали, и много SIMD для поиска по автомату Глушкова (алгоритм, кажется, называется Teddy).
В общем, всё в лучших традициях вытаскивания максимума из поиска регулярных выражений. Библиотека реально делает то, что заявлено в её функциях.

К счастью, за мой месяц разработки в ClickHouse я смог обогнать 12-летнюю разработку на приличном классе запросов и очень этим доволен.
В Яндексе библиотека Hyperscan также используется в антиспаме. Судя по отзывам, она спокойно обрабатывает тысячи регулярных выражений и быстро ищет по ним.
У библиотеки есть несколько минусов. Первый — недокументированное количество потребляемой памяти и странная особенность, что haystack обязан быть меньше 232 байт. Второй — нельзя бесплатно возвращать первые позиции, самые левые индексы needle и т. д. И третий минус — возникают какие-то баги на ровном месте. Поэтому в ClickHouse мы реализовали следующие функции с использованием Hyperscan:
— multiMatchAny(h, [n_1, ..., n_k]) — 1, если хоть кто-то из needle подошёл под haystack.
— multiMatchAnyIndex(h, [n_1, ..., n_k]) — любой индекс из needle, который подошёл под haystack.
Мы заинтересовались, а как можно искать не точно, а приближённо? И придумали несколько решений.
Приближённый поиск
Стандартом в приближённом поиске считается расстояние Левенштейна — минимальное количество символов, которое можно заменить, добавить и удалить, чтобы из строки a длины m получить строку b длины n. К сожалению, наивный алгоритм с динамическим программированием работает за O(mn); лучшие умы ШАДа умеют за O(mn/log max(n, m)); несложно придумать за O( (n + m) ⋅ alpha), где alpha — ответ; наука умеет за O( (alpha − |n − m|)min(m, n, alpha) + m + n) (алгоритм простой, хоть в ШАДе читай) или, если чуть понятнее, за O(alpha^2 + m + n). Есть ещё минус: от квадратичного времени в худшем случае полиномиально избавиться, скорее всего, нельзя — про это Пётр Индик написал очень мощную статью.
Есть упражнение: представьте, что за замену символа в расстоянии Левенштейна вы платите штраф не единицу, а двойку; тогда придумайте алгоритм за O( (n + m) log (n + m)).
Это всё равно никуда не годится, слишком долго и дорого. Но с помощью такого расстояния мы сделали обнаружение опечаток в запросах.
Кроме расстояния Левенштейна, существует расстояние Хэмминга. С ним тоже всё довольно плохо, но чуть лучше, чем с расстоянием Левенштейна. Оно не учитывает удаление символов, а считает только для двух строк одинаковой длины количество символов, в которых они различаются. Поэтому если и использовать расстояние для строк длины m < n, то только в поиске наиболее близких подстрок.
Как вычислить такой массив расхождений (массив d из n — m + 1 элемента, где d[i] — количество различных символов в i-м от начала наложении) за O(|Sigma| (n + m) log (n + m))? Сначала сделаем |Sigma| битовых масок, означающих, равен ли данный символ рассмотренному. Далее посчитаем ответ для каждых из масок Sigma и сложим — получим исходный ответ.
Рассмотрим пример. abba, подстрока ba, бинарный алфавит. Получаем 2 маски 1001, 01 и 0110, 10.
Совпадения по букве a
1001
01 - 0 совпадений
01 - 0 совпадений
01 - 1 совпадениеСовпадения по букве b
0110
10 - 0 совпадений
10 - 1 совпадение
10 - 1 совпадениеПолучаем массив [0, 1, 2] — это почти правильный ответ. Но заметим, что для каждой буквы количество совпадений — просто скалярное произведение фиксированной бинарной needle на все подстроки haystack. И для этого, конечно же, есть быстрое преобразование Фурье!
Для тех, кто не знает: БПФ умеет перемножать два многочлена степеней m < n за время O(n log n) при условии, что работа с коэффициентами выполняется за единицу времени. Свёртки очень похожи на скалярные произведения. Достаточно у первого многочлена продублировать коэффициенты, а второй — развернуть и дополнить нужным количеством нулей, тогда мы получим все скалярные произведения одной бинарной строки на все подстроки другой за O(n log n) — магия какая-то! Но поверьте, это абсолютно реально, и люди иногда так делают.
Но не в ClickHouse. Для нас работа с |Sigma| = 30 уже большая, а БПФ — не самый приятный практический алгоритм для процессора или, как говорят в простонародье, «константа большая».
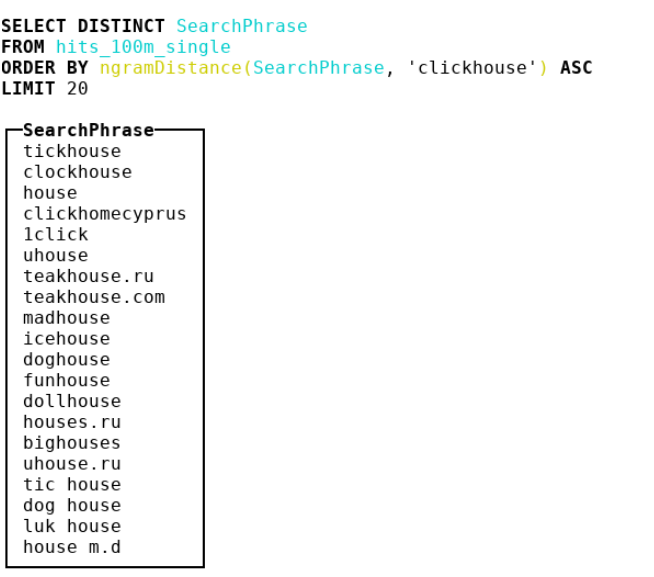
Поэтому мы решили смотреть на другие метрики. Дошли до биоинформатики, где люди используют n-граммное расстояние. По факту мы берём все n-граммы haystack и needle, рассматриваем 2 мультимножества c этими n-граммами. Затем берём симметрическую разность и делим на сумму мощностей двух мультимножеств с n-граммами. Получаем число от 0 до 1 — чем ближе к 0, тем более строки похожи. Рассмотрим пример, где n = 4:
abcda → {abcd, bcda}; Size = 2
bcdab → {bcda, cdab}; Size = 2
Берём симметрическую разность и делим её на сумму мощностей.
|{abcd, cdab}| / (2 + 2) = 0.5В итоге мы сделали 4-граммное расстояние и засунули туда кучу идей из SSE, ещё и немного ослабили реализацию до двухбайтных crc32-хэшей.
Посмотрите реализацию. Осторожно: очень забористый и оптимизированный под компиляторы код.
Особенно советую обратить внимание на грязный хак для приведения нижнего регистра у ASCII и русских кодовых точек.
— ngramDistance(haystack, needle) — возвращает число от 0 до 1; чем ближе к 0, тем более строки похожи друг на друга.
— -UTF8, -CaseInsensitive, -CaseInsensitiveUTF8 (грязный хак для русских и ASCII).
Hyperscan тоже не стоит на месте — в ней есть функциональность по приближённому поиску: можно по константному расстоянию Левенштейна искать строки, похожие на регулярные выражения. Создаются distance + 1 автоматов, которые между собой связаны удалением, заменой или вставкой символа, означающие «штраф», после чего применяется обычный алгоритм проверки на принятие автомата той или иной строки. В ClickHouse мы реализовали их под следующими именами:
— multiFuzzyMatchAny(haystack, distance, [n_1, ..., n_k]) — аналогично multiMatchAny, только с расстоянием.
— multiFuzzyMatchAnyIndex(haystack, distance, [n_1, ..., n_k]) — аналогично multiMatchAnyIndex, только с расстоянием.
С увеличением distance скорость начинает сильно деградировать, но всё ещё остаётся на довольно приличном уровне.
Закончим с поиском и приступим к обработке UTF-8 строк. Тут тоже было много интересного.
Обработка UTF-8 строк
Признаюсь, что пробить потолок наивных реализаций в UTF-8 закодированных строках оказалось сложно. Особенно трудно было прикручивать SIMD. Поделюсь некоторыми идеями, как это можно делать.
Вспомним, как выглядит валидная UTF-8 последовательность:
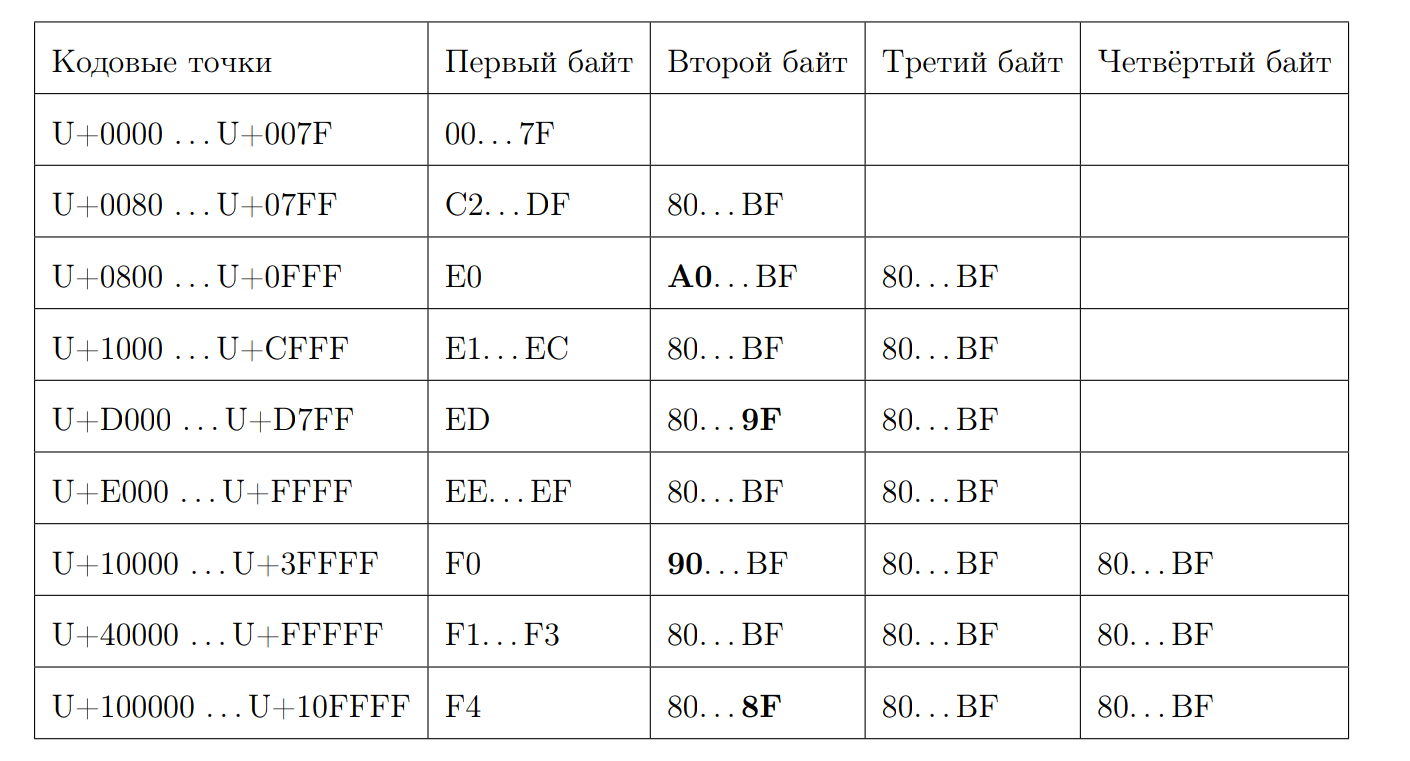
Попробуем вычислить длину кодовой точки по первому байту. Тут начинается битовая магия. Снова выпишем несколько свойств:
— Начинающиеся на 0xC и на 0xD имеют 2 байта
— 0xC2 = 11000010
— 0xDF = 11011111
— 0xE0 = 11100000
— 0xF4 = 11110100, дальше 0xF4 ничего нет, а если бы был 0xF8, была бы другая история
— Ответ 7 минус позиция первого нуля с конца, если это не ASCII символ
Вычисляем длину:
inline size_t seqLength(const UInt8 first_octet) {
if (first_octet < 0x80u)
return 1;
const auto first_zero = bitScanReverse(static_cast<UInt8>(~first_octet));
return 7 - first_zero;
}Благо у нас в запасе есть инструкции, которые умеют вычислять количество нулевых бит, начиная со старших.
f = __builtin_clz(val) // (bsrl, количество нулевых бит с конца) f(2) = 30, f(8) = 28, f(7) = 29 Вычисляем bitScanReverse:
unsigned int bitScanReverse(unsigned int x) {
return 31 - __builtin_clz(x);
}Попробуем вычислить длину UTF-8 строки по кодовым точкам через SIMD. Для этого посмотрим на каждый байт как на знаковое число и заметим следующие свойства:
— 0xBF = -65
— 0x80 = -128
— 0xC2 = -62
— 0x7F = 127
— все первые байты лежат в [0xC2, 0x7F]
— все не первые байты лежат в [0x80, 0xBF]
Алгоритм достаточно прост. Сравниваем каждый байт с -65 и, если он больше, чем это число, добавляем единицу. Если мы хотим использовать SIMD, то это обычный load 16 байт из input stream. Затем идёт байтовое сравнение, которое в случае положительного результата даст байт 0xFF, а в случае отрицательного — 0x00. Потом инструкция pmovmskb, которая соберёт старшие биты каждого байта регистра. Потом количество нижних подчёркиваний увеличивается, мы используем интринсик для SSE4-инструкции popcnt. Схему этого алгоритма можно проиллюстрировать примером:

Получается, что вместе с разжатием обработка на одно ядро будет примерно 1,5 ГБ/с.
Функции называются:
— lengthUTF8(string) — возвращает длину корректно закодированной UTF-8 строки, на некорректные строки что-то считается, исключение не бросается.
Мы пошли дальше, потому что хотели ещё больше функций с обработкой UTF-8 строк. Например, проверку на валидность и приведение к валидному UTF-8 выражению.
Для проверки на валидность я взял https://github.com/cyb70289/utf8/, адаптировал под ClickHouse (на самом деле просто поменял обработку хвостов) и получил 1,22 ГБ/с скорости по сравнению с 900 МБ/с для наивного алгоритма. Сам алгоритм описывать не буду, он достаточно сложный для восприятия.
— isValidUTF8(string) — возвращает 1, если строка корректно UTF-8 закодирована, иначе 0.
— toValidUTF8(string) — заменяет некорректные символы UTF-8 на символ � (U+FFFD). Все идущие подряд некорректные символы схлопываются в один заменяющий символ. No rocket science.
В общем, в UTF-8 строках из-за не самой приятной статичной схемы всегда сложно придумать что-то, хорошо оптимизированное.
Что дальше?
Напомню, что это была моя дипломная работа. Конечно же, я защитил её на 10/10. Мы уже съездили с ней на Highload++ Siberia (правда, мне показалось, что она мало кого заинтересовала). Посмотрите презентацию. Мне понравилось, что практическая часть дипломной работы вылилась в большое интересное исследование. А вот и сам диплом. В нём много опечаток, потому что его никто не вычитывал. :)
Ещё в рамках подготовки диплома я сделал кучу другой похожей работы:
— Соптимизировал функцию concat в 2 раза;
— Сделал простейший python format для запросов;
— Ускорил LZ4 ещё на 4%;
— Внедрил mimalloc для отдельной аллокации кэшей;
— Проделал огромную работу по SIMD для ARM и PPC64LE;
— Почти внедрил GCC9;
— И проконсультировал пару студентов ФКН с дипломами по ClickHouse.
В итоге оказалось, что, по моим впечатлениям, каждый месяц Лёша пытался схантить меня ClickHouse максимально приятная система для написания высокопроизводительного кода, где есть документация, комментарии, прекрасная developer- и devops-поддержка. ClickHouse офигенен, серьёзно. Устали от перекладывания форматов JSON? Придите к Лёше и попросите задачу любого уровня — он вам её предоставит, и за выходные вы получите огромное удовольствие от написания кода.
Но при всех достижениях ClickHouse и его дизайна, дело, наверное, не в них. Даже в первую очередь не в них.
Я прошёл 4 года бакалавриата ФКН, в июне закончил Вышку с красным дипломом, проработал полтора года в офигенной команде в Яндексе, хорошо прокачавшись. Без суммарного опыта за всё это время и железа ничего из написанного в посте не получилось бы. ФКН очень крут, если брать от него максимум. Спасибо Ване Пузыревскому ivan_puzyrevskiy, Игнату Колесниченко, Глебу Евстропову, Максу Бабенко maxim_babenko за то, что встретились в моём забавном приключении на ФКН. А также спасибо всем преподавателям, которые чему-то меня научили.


