
В прошлой статье я рассказал про нашу инфраструктуру большого нагрузочного теста. В среднем мы создаём порядка 100 серверов для подачи нагрузки и порядка 150 серверов для работы нашего сервиса. Все эти сервера нужно создавать, удалять, конфигурировать и запускать. Мы используем для этого те же инструменты, что и на проде, чтобы уменьшить количество ручной работы:
Благодаря скриптам Terraform и Ansible, все операции от создания инстансов до запуска сервера выполняются всего шестью командами:
В час пик на продакшене у нас бывает более 20K онлайн-пользователей одновременно, а в другие часы их может быть 6K. Нет смысла постоянно держать полный объём серверов, поэтому мы настроили автомасштабирование для board-серверов, на которых открываются доски в момент захода на них пользователей, и для API-серверов, которые обрабатывают API-запросы. Теперь сервера создаются и удаляются тогда, когда это необходимо.
Такой механизм очень эффективен в нагрузочном тестировании: по умолчанию у нас может быть минимально необходимое количество серверов, а в момент выполнения теста они автоматически поднимутся в нужном количестве. В начале у нас может быть 4 board-сервера, а в пике — до 40. При этом новые сервера создаются не сразу, а только после того, как нагрузятся текущие сервера. Например, критерием для создания новых инстансов может быть 50% использования CPU. Это позволяет не тормозить рост виртуальных пользователей в сценарии и не создавать лишних серверов.
Бонусом этого подхода служит то, что благодаря динамическому масштабированию мы узнаём, сколько нам понадобится мощностей для разного количества пользователей, которого у нас ещё не было на проде.
Для мониторинга нагрузочных тестов существует множество подходов и инструментов, но мы пошли по своему пути.
Продакшен мы мониторим стандартным стеком: Logstash, Elasticsearch, Kibana, Prometheus и Grafana. Наш кластер для тестов аналогичен проду, поэтому мониторинг мы решили сделать таким же, как на проде, с такими же метриками. Причин для этого две:
Важно, чтобы все результаты хранились в одном месте. Так их будет удобно сравнивать друг с другом от запуска к запуску.
Отчёты мы делаем в нашем продукте (пример доски с отчётом):
На создание отчёта уходит много времени. Поэтому в наших планах сделать сбор общей информации автоматическим с помощью нашего публичного API.
У нас за качество продукта отвечают не QA Engineers, а вся команда. Нагрузочные тесты — это один из инструментов обеспечения качества. Круто, если команда понимает, что важно проверять под нагрузкой изменения, которые она внесла. Чтобы начать об этом задумываться, ей нужно стать ответственной за работу продакшена. Здесь нам помогают принципы DevOps культуры, которые мы начали внедрять в работу.
Но начать задуматься о проведении нагрузочных тестов — это только первый шаг. Команда не сможет продумать тесты без понимания устройства работы продакшена. Мы столкнулись с такой проблемой, когда начали настраивать процесс проведения нагрузочных тестов в командах. На тот момент у команд не было никакой возможности разобраться в устройстве продакшена, поэтому им было сложно работать над дизайном тестов. Причин было несколько: отсутствие актуальной документации или одного человека, который бы хранил в голове всю картину прода; кратный рост команды разработки.
Помочь командам, разобраться в работе прода, может подход Инфраструктура как код, который мы стали использовать в команде разработки.
Какие проблемы мы уже начали решать с помощью этого подхода:
Этот подход хочется распространить не только на создание инфраструктуры, но и на поддержку различных инструментов. Например, тест БД, про который я рассказывал в прошлой статье, мы полностью превратили в код. Благодаря этому, вместо заранее подготовленной площадки у нас есть набор скриптов, с помощью которого за 7 минут мы получаем настроенное окружение в полностью пустой учётке AWS и можем приступать к тесту. По этой же причине мы сейчас внимательно рассматриваем Gatling, который создатели позиционируют как инструмент для “Load test as code”.
Подход к инфраструктуре как коду влечёт за собой аналогичный подход к её тестированию и скриптам, которые пишет команда для поднятия инфраструктуры новых фичей. Всё это должно покрываться тестами. Также есть различные фреймоврки для тестирования, например Molecule. Существуют инструменты для chaos monkey тестирования, для AWS есть платные инструменты, для Docker есть Pumba и т.д. Они позволяют решать разные виды задач:
Решение подобных задач у нас в ближайших планах.
- Для создания и удаления тестового окружения — Terraform скрипты;
- Для конфигурирования, обновления и запуска — Ansible скрипты;
- Для динамического масштабирования в зависимости от нагрузки — самописные Python-скрипты.
Благодаря скриптам Terraform и Ansible, все операции от создания инстансов до запуска сервера выполняются всего шестью командами:
#запускаем нужные инстансы в консоли aws
ansible-playbook deploy-config.yml #обновляем версии серверов
ansible-playbook start-application.yml #запускаем наше приложение на этих серверах
ansible-playbook update-test-scenario.yml --ask-vault-pass #обновляем Jmeter сценарий, если в нём были изменения
infrastructure-aws-cluster/jmeter_clients:~# terraform apply #создаем jmeter сервера для подачи нагрузки
ansible-playbook start-jmeter-server-cluster.yml #запускаем jmeter кластер
ansible-playbook start-stress-test.yml #запускаем тестДинамическое масштабирование серверов
В час пик на продакшене у нас бывает более 20K онлайн-пользователей одновременно, а в другие часы их может быть 6K. Нет смысла постоянно держать полный объём серверов, поэтому мы настроили автомасштабирование для board-серверов, на которых открываются доски в момент захода на них пользователей, и для API-серверов, которые обрабатывают API-запросы. Теперь сервера создаются и удаляются тогда, когда это необходимо.
Такой механизм очень эффективен в нагрузочном тестировании: по умолчанию у нас может быть минимально необходимое количество серверов, а в момент выполнения теста они автоматически поднимутся в нужном количестве. В начале у нас может быть 4 board-сервера, а в пике — до 40. При этом новые сервера создаются не сразу, а только после того, как нагрузятся текущие сервера. Например, критерием для создания новых инстансов может быть 50% использования CPU. Это позволяет не тормозить рост виртуальных пользователей в сценарии и не создавать лишних серверов.
Бонусом этого подхода служит то, что благодаря динамическому масштабированию мы узнаём, сколько нам понадобится мощностей для разного количества пользователей, которого у нас ещё не было на проде.
Сбор метрик как на проде
Для мониторинга нагрузочных тестов существует множество подходов и инструментов, но мы пошли по своему пути.
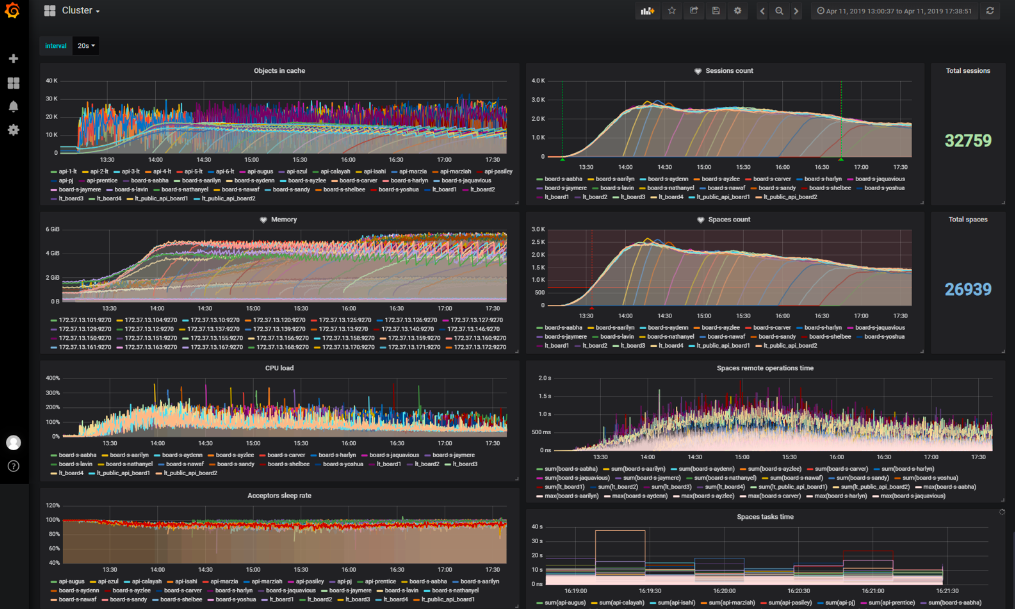
Продакшен мы мониторим стандартным стеком: Logstash, Elasticsearch, Kibana, Prometheus и Grafana. Наш кластер для тестов аналогичен проду, поэтому мониторинг мы решили сделать таким же, как на проде, с такими же метриками. Причин для этого две:
- Не нужно строить с нуля систему мониторинга, она уже есть у нас полная и сразу;
- Мы дополнительно тестируем мониторинг прода: если во время мониторинга теста мы понимаем, что нам не хватает данных для анализа проблемы, значит их не хватит и на продакшене, когда такая проблема там появится.
Что мы показываем в отчётах
- Технические характеристики стенда;
- Сам сценарий, описанный словами, а не кодом;
- Результат, понятный всем участникам команды, как разработчикам, так и менеджерам;
- Графики общего состояния стенда;
- Графики, которые показывают узкое место или то, на что повлияла оптимизация, проверяемая в тесте.
Важно, чтобы все результаты хранились в одном месте. Так их будет удобно сравнивать друг с другом от запуска к запуску.
Отчёты мы делаем в нашем продукте (пример доски с отчётом):
На создание отчёта уходит много времени. Поэтому в наших планах сделать сбор общей информации автоматическим с помощью нашего публичного API.
Инфраструктура как код
У нас за качество продукта отвечают не QA Engineers, а вся команда. Нагрузочные тесты — это один из инструментов обеспечения качества. Круто, если команда понимает, что важно проверять под нагрузкой изменения, которые она внесла. Чтобы начать об этом задумываться, ей нужно стать ответственной за работу продакшена. Здесь нам помогают принципы DevOps культуры, которые мы начали внедрять в работу.
Но начать задуматься о проведении нагрузочных тестов — это только первый шаг. Команда не сможет продумать тесты без понимания устройства работы продакшена. Мы столкнулись с такой проблемой, когда начали настраивать процесс проведения нагрузочных тестов в командах. На тот момент у команд не было никакой возможности разобраться в устройстве продакшена, поэтому им было сложно работать над дизайном тестов. Причин было несколько: отсутствие актуальной документации или одного человека, который бы хранил в голове всю картину прода; кратный рост команды разработки.
Помочь командам, разобраться в работе прода, может подход Инфраструктура как код, который мы стали использовать в команде разработки.
Какие проблемы мы уже начали решать с помощью этого подхода:
- Всё должно быть заскриптовано и может быть поднято в любой момент. Это существенно сокращает время восстановления прода на случай аварии дата-центра и позволяет держать нужное количество актуальных тестовых сред;
- Разумная экономия: разворачиваем среды на Openstack, когда это может заменить дорогие площадки вроде AWS;
- Команды самостоятельно создают нагрузочные тесты, потому что понимают устройство прода;
- Код заменяет собой документацию, поэтому нет необходимости её бесконечно актуализировать, она всегда полная и актуальна;
- Не нужен отдельный эксперт в узкой области, чтобы решать рядовые задачи. Любой инженер может разобраться с кодом;
- Имея понятную структуру прода гораздо легче планировать исследовательские нагрузочные тесты, вроде chaos monkey testing или длинных тестов на утечки памяти.
Этот подход хочется распространить не только на создание инфраструктуры, но и на поддержку различных инструментов. Например, тест БД, про который я рассказывал в прошлой статье, мы полностью превратили в код. Благодаря этому, вместо заранее подготовленной площадки у нас есть набор скриптов, с помощью которого за 7 минут мы получаем настроенное окружение в полностью пустой учётке AWS и можем приступать к тесту. По этой же причине мы сейчас внимательно рассматриваем Gatling, который создатели позиционируют как инструмент для “Load test as code”.
Подход к инфраструктуре как коду влечёт за собой аналогичный подход к её тестированию и скриптам, которые пишет команда для поднятия инфраструктуры новых фичей. Всё это должно покрываться тестами. Также есть различные фреймоврки для тестирования, например Molecule. Существуют инструменты для chaos monkey тестирования, для AWS есть платные инструменты, для Docker есть Pumba и т.д. Они позволяют решать разные виды задач:
- Как при падении одного из инстансов в AWS проверить, перебалансируется ли нагрузка на оставшиеся сервера и выживет ли сервис от такого резкого перенаправления запросов;
- Как имитировать медленную работу сети, её обрыв и прочие технические проблемы, после которых не должна ломаться логика работы инфраструктуры сервиса.
Решение подобных задач у нас в ближайших планах.
Выводы
- Не стоит тратить время на ручную оркестровку инфраструктуры теста, лучше автоматизировать эти действия, чтобы надёжнее управлять всеми окружениями, включая прод;
- Динамическое масштабирование существенно снижает затраты на содержание прода и большой тестовой среды, а также снижает человеческий фактор при масштабировании;
- Можно не использовать отдельную систему мониторинга для тестов, а взять её с прода;
- Важно, чтобы отчёты о нагрузочных тестах автоматически собирались в едином месте и имели унифицированный вид. Это позволит их легко сравнивать и анализировать изменения;
- Нагрузочные тесты станут процессом в компании, когда команды почувствуют ответственность за работу прода;
- Нагрузочные тесты — инфраструктурные тесты. Если нагрузочный тест прошел успешно — возможно, что он был составлен неправильно. Для валидации корректности проведения теста требуется глубокое понимание работы прода. У команд должна быть возможность самостоятельно разобраться в устройстве работы прода. Мы решаем эту проблему с помощью подхода Инфраструктура как код;
- Скрипты подготовки инфраструктуры также требуют тестирования как и любой другой код.




