
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Привет, Хабр! Представляю вашему вниманию перевод статьи «Interview with Weld’s main contributor: accelerating numpy, scikit and pandas as much as 100x with Rust and LLVM».
Проработав несколько недель с data science инструментарием в Python и R, я начал задаваться вопросом, а нет ли какого промежуточного представления (Intermediate representation, IR) наподобие CUDA, которое можно использовать в разных языках. Должно же быть что-то получше, чем реимплементация и оптимизация одних и тех же методов в каждом языке. В дополнение к этому было бы неплохо иметь общую среду выполнения (common runtime), чтобы оптимизировать всю программу целиком, а не каждую функцию в отдельности.
После нескольких дней исследования и тестирования различных проектов я нашел Weld (можете ознакомиться с академической статьей).
К моему удивлению одним из автором Weld является Матей Захария (Matei Zaharia), создатель Spark.
Итак, я связался с Шоумиком Палкаром (Shoumik Palkar), основным контрибьютором Weld, и взял интервью у него. Шоумик — аспирант факультета компьютерных наук в Стэнфордском университете, куда поступил по совету Матея Захарии.
Weld еще не готова к промышленному использованию, но весьма перспективна. Если вам интересно будущее data science и Rust в частности, вам понравится это интервью.
Цель создания Weld состоит в том, чтобы увеличить производительность для приложений, использующих высокоуровневые API, такие как NumPy и Pandas. Основная проблема, которую он решает — это кросс-функциональные и кросс-библиотечные оптимизации, не предоставляемые сегодня другими библиотеками. В частности, многие широко используемые библиотеки имеют современные реализации алгоритмов для отдельных функций (например, алгоритм быстрого соединения (join), реализованный в Pandas на C, или быстрое умножение матриц в NumPy), но не обеспечивают возможности оптимизации сочетания этих функций. Например, предотвращение ненужных сканирований памяти при выполнении умножения матрицы с последующим агрегированием.
Weld же предоставляет общую среду исполнения, которая позволяет библиотекам выражать вычисления в общем промежуточном представлении (IR). Этот IR можно затем оптимизировать с помощью оптимизатора компилятора, а затем скомпилировать «на лету» (JIT) в параллельный машинный код с такими оптимизациями, как слияние циклов, векторизация и т.д. IR в Weld изначально параллелен, поэтому программы, выраженные в нем, всегда могут быть тривиально распараллелены.
Также у нас есть новый проект Split annotations, который будет интегрирован с Weld и призван снизить барьер для включения подобных оптимизаций в существующих библиотеках.
Weld обеспечивает оптимизацию сочетания функций в этих библиотеках, тогда как оптимизация библиотек может ускорить вызовы только отдельных функций. Фактически, многие из этих библиотек уже очень хорошо оптимизированы для каждой отдельной функции, но обеспечивают производительность ниже пределов современного оборудования, поскольку они не используют параллелизм или не эффективно используют иерархию памяти.
Например, многие функции NumPy для многомерных массивов (ndarray) реализованы на низкоуровневом языке C, но для вызова каждой функции требуется полное сканирование входных данных. Если эти массивы не помещаются в кэши ЦП, большая часть времени выполнения может идти на загрузку данных из основной памяти, а не на выполнение вычислений. Weld может просматривать отдельные вызовы функций и выполнять оптимизации, такие как объединение циклов, которые будут хранить данные в кэшах или регистрах ЦП. Подобные оптимизации могут повысить производительность более чем на порядок в многоядерных системах, поскольку они обеспечивают лучшее масштабирование.
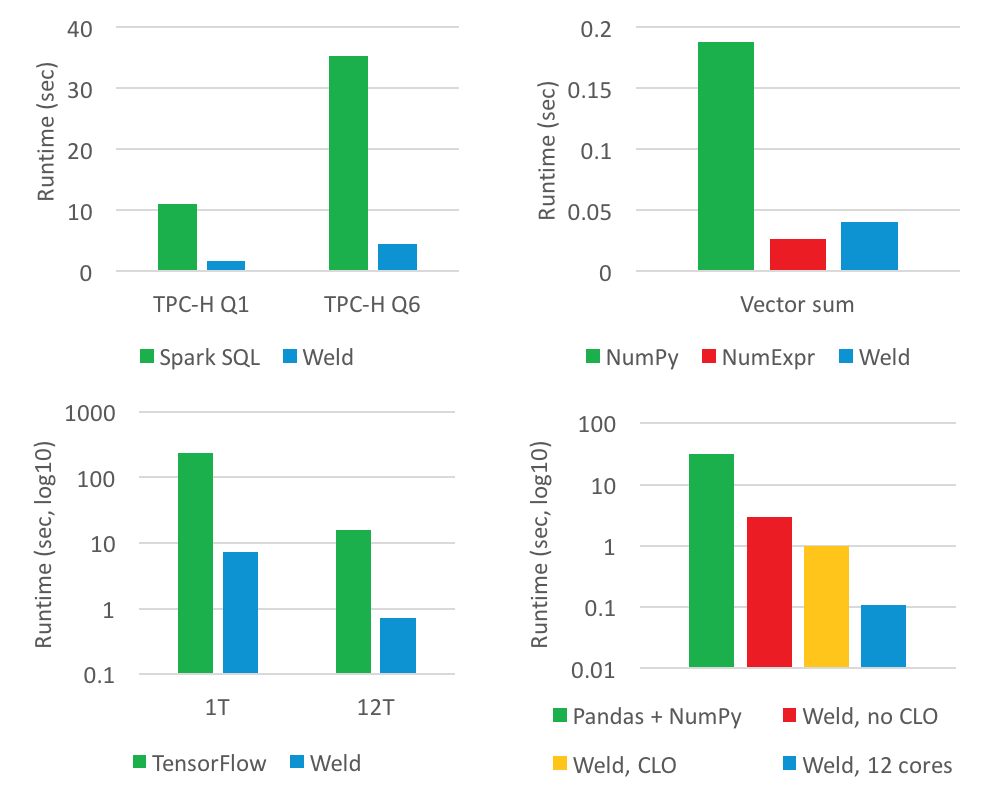
Интеграции прототипов Weld со Spark (вверху слева), NumPy (вверху справа) и TensorFlow (внизу слева) демонстрируют до 30-кратного улучшения по сравнению с реализациями собственной инфраструктуры без изменений в коде приложения пользователя. Кросс-библиотечная оптимизация Pandas и NumPy (внизу справа) может повысить производительность на два порядка.
Baloo — это библиотека, которая реализует подмножество Pandas API с использованием Weld. Она была разработана Раду Джикой (Radu Jica), магистром из CWI (Centrum Wiskunde & Informatica, Амстердам). Цель Baloo состоит в том, чтобы применить описанные выше виды оптимизации в Pandas для улучшения однопоточной производительности, уменьшения использования памяти и обеспечения параллелизма.
Weld и Baloo в настоящее время не поддерживают внешние операции (out-of-core, external memory), хотя мы будем рады получить opensource-разработки в этом направлении!
Мы выбрали Rust, потому что:
Мы выбрали LLVM, потому что это фреймворк компиляции с открытым исходным кодом, который широко используется и поддерживается. Мы генерируем LLVM напрямую вместо C/C++, поэтому нам не требуется наличие компилятора C. Также это сокращает время компиляции, так как мы не парсим код C/C++.
Rust не был первым языком, на котором был реализован Weld. Первая реализация была на Scala, которая была выбрана из-за ее алгебраических типов данных и наличия такой мощной фичи как сопоставление с образцом. Это упростило написание оптимизатора, который является основной частью компилятора. Наш оригинальный оптимизатор был выполнен наподобие Catalyst, расширяемого оптимизатора в Spark SQL.
Мы отошли от Scala, потому что было слишком сложно встроить язык на основе JVM в другие среды выполнения и языки.
Основным отличием Weld от систем, таких как RAPIDS, является то, что он направлен на оптимизацию приложений, содержащих разные kernel (функции в терминах CUDA), путем компиляции на лету, а не на оптимизацию реализаций отдельных функций. Например, GPU-бэкенд Weld скомпилирует один единственный kernel CUDA, оптимизированный для конечного приложения, вместо того, чтобы вызывать отдельные kernel.
Кроме того, Weld IR не зависит от аппаратного обеспечения, что позволяет использовать его как для GPU, так и для CPU, а также нестандартного оборудования навроде векторных процессоров.
Конечно, Weld существенно пересекается с другими проектами в той же области, включая RAPIDS, и создается под их влиянием.
Такие среды выполнения, как Bohrium (реализует ленивые вычисления в NumPy) и Numba (библиотека Python, JIT-компилятор числового кода) разделяют высокоуровневые цели Weld. А системы оптимизаторов вроде Spark SQL непосредственно влияют на дизайн Weld.
Одним из наиболее захватывающих аспектов Weld IR является то, что он нативно поддерживает параллелизм данных. Это означает, что распареллеливание циклов в Weld IR всегда выполняется безопасно. Это делает Weld IR привлекательным для использования новых видов оборудования.
Например, сотрудники NEC использовали Weld для запуска рабочих нагрузок Python на кастомном векторном процессоре с высокой пропускной способностью памяти, просто добавив новый бэкэнд в существующий Weld IR.
IR также может быть использован для реализации слоя физических операций в БД. И еще мы планируем добавить функции, которые позволят также компилировать подмножество Python в код Weld.
Многие примеры и бенчмарки, на которых мы тестировали эти библиотеки, взяты из реальной рабочей нагрузки. Поэтому нам бы очень хотелось, чтобы пользователи опробовали текущую версию в своих приложений, и оставили свои отзывы. И, что лучше всего, предложили собственные патчи.
В общем, на текущий момент нельзя сказать, что в реальных приложениях все будет работать «из коробки».
Наши следующие релизы в течение следующих нескольких месяцев будут посвящены исключительно удобству использования и надежности библиотек Python. Наша цель состоит в том, чтобы сделать библиотеки достаточно хорошими для включения в реальные проекты. А также в возможности использовать версии библиотек, не относящиеся к Weld, в тех местах, где поддержка еще не добавлена.
Как я уже отметил в первом вопросе, проект Split annotations (исходный код и академическая статья) должен упростить этот переход.
Split annotations — это система, которая позволяет добавить аннотации в существующий код, чтобы определить как разделить, преобразовать и распараллелить его. Она обеспечивает оптимизацию, которую мы считаем наиболее эффективной в Weld (хранение чанков данных в кэшах CPU между вызовами функций, вместо сканирования всего набора данных). Но Split annotations значительно проще интегрировать чем Weld, поскольку она используют существующий библиотечный код, не опираясь на IR компилятора. Это также облегчает ее обслуживание и отладку, что, в свою очередь, повышает надежность.
Библиотеки, пока не имеющие полной поддержки Weld, могут использовать Split annotations. Это позволит нам постепенно добавлять поддержку Weld, основываясь на отзывах пользователей, и при этом включать новые оптимизации.
Проработав несколько недель с data science инструментарием в Python и R, я начал задаваться вопросом, а нет ли какого промежуточного представления (Intermediate representation, IR) наподобие CUDA, которое можно использовать в разных языках. Должно же быть что-то получше, чем реимплементация и оптимизация одних и тех же методов в каждом языке. В дополнение к этому было бы неплохо иметь общую среду выполнения (common runtime), чтобы оптимизировать всю программу целиком, а не каждую функцию в отдельности.
После нескольких дней исследования и тестирования различных проектов я нашел Weld (можете ознакомиться с академической статьей).
К моему удивлению одним из автором Weld является Матей Захария (Matei Zaharia), создатель Spark.
Итак, я связался с Шоумиком Палкаром (Shoumik Palkar), основным контрибьютором Weld, и взял интервью у него. Шоумик — аспирант факультета компьютерных наук в Стэнфордском университете, куда поступил по совету Матея Захарии.
Weld еще не готова к промышленному использованию, но весьма перспективна. Если вам интересно будущее data science и Rust в частности, вам понравится это интервью.
Реклама автора оригинала статьи
Присоединяйтесь к группе и каналу «Not a Monad Tutorial», чтобы обсудить Weld и программирование в целом. Увидимся там!
Если вы ищете хороших инженеров, отправьте мне письмо на mail@fcarrone.com или вы также можете связаться со мной через твиттер на @unbalancedparen.
Присоединяйтесь к группе и каналу «Not a Monad Tutorial», чтобы обсудить Weld и программирование в целом. Увидимся там!
Если вы ищете хороших инженеров, отправьте мне письмо на mail@fcarrone.com или вы также можете связаться со мной через твиттер на @unbalancedparen.
Для чего разрабатывался Weld, какие проблемы он решает?
Цель создания Weld состоит в том, чтобы увеличить производительность для приложений, использующих высокоуровневые API, такие как NumPy и Pandas. Основная проблема, которую он решает — это кросс-функциональные и кросс-библиотечные оптимизации, не предоставляемые сегодня другими библиотеками. В частности, многие широко используемые библиотеки имеют современные реализации алгоритмов для отдельных функций (например, алгоритм быстрого соединения (join), реализованный в Pandas на C, или быстрое умножение матриц в NumPy), но не обеспечивают возможности оптимизации сочетания этих функций. Например, предотвращение ненужных сканирований памяти при выполнении умножения матрицы с последующим агрегированием.
Weld же предоставляет общую среду исполнения, которая позволяет библиотекам выражать вычисления в общем промежуточном представлении (IR). Этот IR можно затем оптимизировать с помощью оптимизатора компилятора, а затем скомпилировать «на лету» (JIT) в параллельный машинный код с такими оптимизациями, как слияние циклов, векторизация и т.д. IR в Weld изначально параллелен, поэтому программы, выраженные в нем, всегда могут быть тривиально распараллелены.
Также у нас есть новый проект Split annotations, который будет интегрирован с Weld и призван снизить барьер для включения подобных оптимизаций в существующих библиотеках.
Не будет ли проще оптимизировать numpy, pandas и scikit? Насколько получается быстрее?
Weld обеспечивает оптимизацию сочетания функций в этих библиотеках, тогда как оптимизация библиотек может ускорить вызовы только отдельных функций. Фактически, многие из этих библиотек уже очень хорошо оптимизированы для каждой отдельной функции, но обеспечивают производительность ниже пределов современного оборудования, поскольку они не используют параллелизм или не эффективно используют иерархию памяти.
Например, многие функции NumPy для многомерных массивов (ndarray) реализованы на низкоуровневом языке C, но для вызова каждой функции требуется полное сканирование входных данных. Если эти массивы не помещаются в кэши ЦП, большая часть времени выполнения может идти на загрузку данных из основной памяти, а не на выполнение вычислений. Weld может просматривать отдельные вызовы функций и выполнять оптимизации, такие как объединение циклов, которые будут хранить данные в кэшах или регистрах ЦП. Подобные оптимизации могут повысить производительность более чем на порядок в многоядерных системах, поскольку они обеспечивают лучшее масштабирование.
Интеграции прототипов Weld со Spark (вверху слева), NumPy (вверху справа) и TensorFlow (внизу слева) демонстрируют до 30-кратного улучшения по сравнению с реализациями собственной инфраструктуры без изменений в коде приложения пользователя. Кросс-библиотечная оптимизация Pandas и NumPy (внизу справа) может повысить производительность на два порядка.
Что такое Baloo?
Baloo — это библиотека, которая реализует подмножество Pandas API с использованием Weld. Она была разработана Раду Джикой (Radu Jica), магистром из CWI (Centrum Wiskunde & Informatica, Амстердам). Цель Baloo состоит в том, чтобы применить описанные выше виды оптимизации в Pandas для улучшения однопоточной производительности, уменьшения использования памяти и обеспечения параллелизма.
Поддерживает ли Weld/Baloo внешние операции (как, скажем, Dask) для обработки данных, которые не помещаются в памяти?
Weld и Baloo в настоящее время не поддерживают внешние операции (out-of-core, external memory), хотя мы будем рады получить opensource-разработки в этом направлении!
Почему вы выбрали Rust и LLVM для реализации Weld? Сразу ли пришли к Rust?
Мы выбрали Rust, потому что:
- Он имеет минимальный рантайм (по сути, просто проверяет границы массивов) и его легко встраивать в другие языки, такие как Java и Python
- Он содержит парадигмы функционального программирования, такие как сопоставление с образцом (pattern matching), которые облегчают написание кода, например, для оптимизации компилятора сопоставления с образцом
- У него прекрасное сообщество и высококачественные пакеты (в Rust они называются crates), которые облегчили разработку нашей системы.
Мы выбрали LLVM, потому что это фреймворк компиляции с открытым исходным кодом, который широко используется и поддерживается. Мы генерируем LLVM напрямую вместо C/C++, поэтому нам не требуется наличие компилятора C. Также это сокращает время компиляции, так как мы не парсим код C/C++.
Rust не был первым языком, на котором был реализован Weld. Первая реализация была на Scala, которая была выбрана из-за ее алгебраических типов данных и наличия такой мощной фичи как сопоставление с образцом. Это упростило написание оптимизатора, который является основной частью компилятора. Наш оригинальный оптимизатор был выполнен наподобие Catalyst, расширяемого оптимизатора в Spark SQL.
Мы отошли от Scala, потому что было слишком сложно встроить язык на основе JVM в другие среды выполнения и языки.
Если Weld нацелен на CPU и GPU, как его можно сравнить с такими проектами как RAPIDS, которые реализуют data science библиотеки Python для GPU?
Основным отличием Weld от систем, таких как RAPIDS, является то, что он направлен на оптимизацию приложений, содержащих разные kernel (функции в терминах CUDA), путем компиляции на лету, а не на оптимизацию реализаций отдельных функций. Например, GPU-бэкенд Weld скомпилирует один единственный kernel CUDA, оптимизированный для конечного приложения, вместо того, чтобы вызывать отдельные kernel.
Кроме того, Weld IR не зависит от аппаратного обеспечения, что позволяет использовать его как для GPU, так и для CPU, а также нестандартного оборудования навроде векторных процессоров.
Конечно, Weld существенно пересекается с другими проектами в той же области, включая RAPIDS, и создается под их влиянием.
Такие среды выполнения, как Bohrium (реализует ленивые вычисления в NumPy) и Numba (библиотека Python, JIT-компилятор числового кода) разделяют высокоуровневые цели Weld. А системы оптимизаторов вроде Spark SQL непосредственно влияют на дизайн Weld.
Есть ли у Weld другие применения кроме оптимизаций data science библиотек?
Одним из наиболее захватывающих аспектов Weld IR является то, что он нативно поддерживает параллелизм данных. Это означает, что распареллеливание циклов в Weld IR всегда выполняется безопасно. Это делает Weld IR привлекательным для использования новых видов оборудования.
Например, сотрудники NEC использовали Weld для запуска рабочих нагрузок Python на кастомном векторном процессоре с высокой пропускной способностью памяти, просто добавив новый бэкэнд в существующий Weld IR.
IR также может быть использован для реализации слоя физических операций в БД. И еще мы планируем добавить функции, которые позволят также компилировать подмножество Python в код Weld.
Готовы ли библиотеки для использования в реальных проектах? И если нет, то когда можно ожидать готовый результат?
Многие примеры и бенчмарки, на которых мы тестировали эти библиотеки, взяты из реальной рабочей нагрузки. Поэтому нам бы очень хотелось, чтобы пользователи опробовали текущую версию в своих приложений, и оставили свои отзывы. И, что лучше всего, предложили собственные патчи.
В общем, на текущий момент нельзя сказать, что в реальных приложениях все будет работать «из коробки».
Наши следующие релизы в течение следующих нескольких месяцев будут посвящены исключительно удобству использования и надежности библиотек Python. Наша цель состоит в том, чтобы сделать библиотеки достаточно хорошими для включения в реальные проекты. А также в возможности использовать версии библиотек, не относящиеся к Weld, в тех местах, где поддержка еще не добавлена.
Как я уже отметил в первом вопросе, проект Split annotations (исходный код и академическая статья) должен упростить этот переход.
Split annotations — это система, которая позволяет добавить аннотации в существующий код, чтобы определить как разделить, преобразовать и распараллелить его. Она обеспечивает оптимизацию, которую мы считаем наиболее эффективной в Weld (хранение чанков данных в кэшах CPU между вызовами функций, вместо сканирования всего набора данных). Но Split annotations значительно проще интегрировать чем Weld, поскольку она используют существующий библиотечный код, не опираясь на IR компилятора. Это также облегчает ее обслуживание и отладку, что, в свою очередь, повышает надежность.
Библиотеки, пока не имеющие полной поддержки Weld, могут использовать Split annotations. Это позволит нам постепенно добавлять поддержку Weld, основываясь на отзывах пользователей, и при этом включать новые оптимизации.


