Это 2-я часть из 4-х, в которой рассматривается внутренняя работа Chrome. В предыдущей части мы рассмотрели, как различные процессы и потоки работают с разными частями браузера. В этом посте мы подробнее рассмотрим, как каждый процесс и поток взаимодействуют, чтобы отобразить веб-сайт.
Перевод первой части
- в ходе перевода, я старался вычленять из статьи ПОНЯТИЯ, т.е. текстовые единицы которые несут специальный (технический) смысл. В переводе эти понятия выделены по особенному — во первых понятия предваряются символом звёздочки, во-вторых в них вместо пробела используется тире. Например: *браузер-процесс, *сайто-изоляция. При переводе понятий, приоритет отдавался не красоте перевода, а желанию выделить, акцентировать, то что мы имеем дело с ПОНЯТИЕМ, а не с фигурой речи.
- также, некоторые слова переведены неверно с точки зрения русского языка, в жаргонном стиле, например пайплайн, продакшен. У "технарей" такой перевод не вызовет затруднений, у остальных читателей прошу прощения.
Рассмотрим простой пример использования веб-браузера: вы вводите URL в браузере, затем браузер извлекает данные из интернета и отображает страницу. В этой заметке мы остановимся на той части, где пользователь запрашивает сайт, а браузер готовится к отображению страницы — также известной как навигация.
Начнём с *браузер-процесса
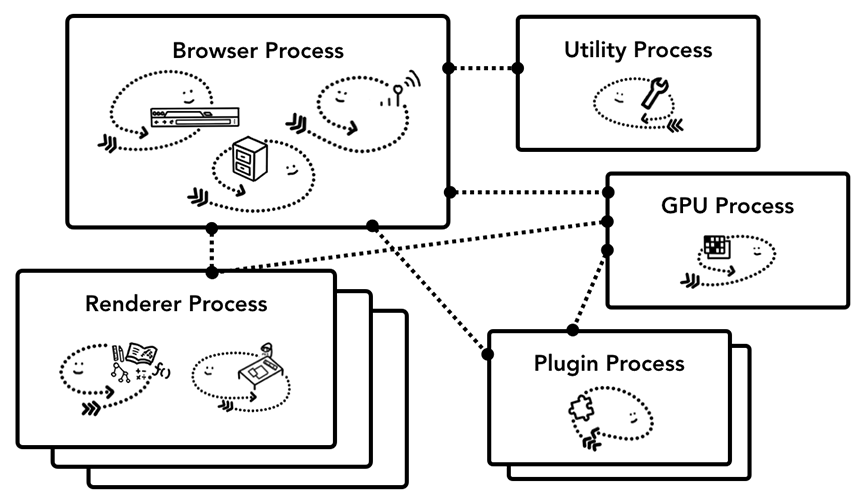
Как мы описывали в первой части, все, что находится вне вкладки, обрабатывается *браузер-процессом. *Браузер-процесс имеет такие потоки, как *UI-поток, который рисует кнопки и поля ввода браузера, *сетевой-поток, который имеет дело с сетевым стеком для получения данных из Интернета, *поток-хранения, который контролирует доступ к файлам и многие другие. Когда вы вводите URL в адресную строку, ваш вход обрабатывается *UI-потоком *браузер-процесса.

Рисунок 1: Интерфейс браузера вверху, схема *браузер-процесса с *UI-потоком, *сетевым-потокм и *потоком-хранения внутри внизу
Простая навигация
= Шаг 1. Обработка ввода
Когда пользователь начинает печатать в адресной строке, первое, что интересует *UI-поток "Это поисковый запрос или URL?". В Chrome адресная строка также является полем ввода поискового запроса, поэтому *UI-поток должен разобраться и решить, отправить ли вас в поисковую систему, или на сайт, который вы запросили.
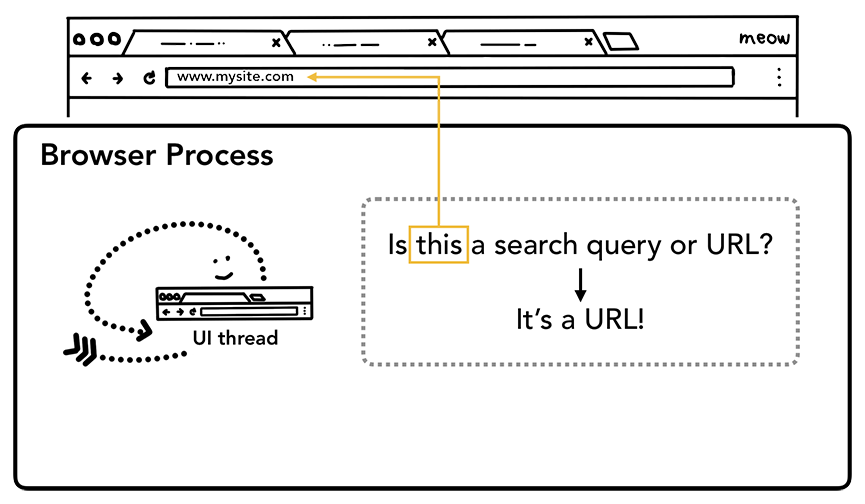
Рисунок 1-bis: *UI-поток спрашивает, является ли входной запрос поисковым или URL-адресом
= Шаг 2. Старт навигации
Когда пользователь нажимает Enter, *UI-поток инициирует сетевой вызов для получения контента сайта. В углу вкладки отображается анимация загрузки, и *сетевой-поток проходит через соответствующие протоколы, такие как DNS поиск и создание TLS соединения для запроса.
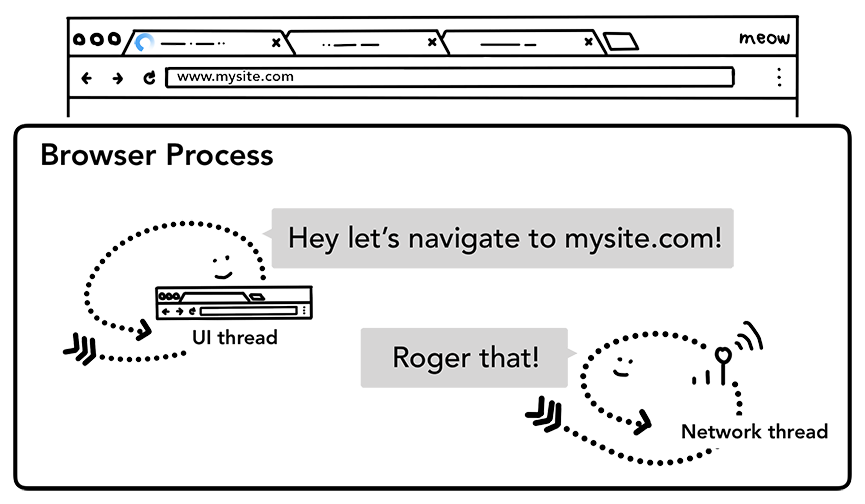
Рисунок 2: *UI-поток разговаривающий с *сетевым-потоком для перехода на mysite.com
В этом месте *сетевой-поток может получить заголовок перенаправления сервера, например, HTTP 301. В этом случае *сетевой-поток взаимодействует с *UI-потоком, для которого сервер выполняет редирект. Затем будет инициирован еще один запрос URL-адреса.
= Шаг 3. Чтение ответа
Как только тело ответа (payload, полезная нагрузка) начинает поступать, *сетевой-поток при необходимости смотрит на первые несколько байт данных. В заголовке ответа 'Content-Type' должно быть указано, какой это тип данных, но так как он может отсутствовать или быть неправильным, то в данном случае выполняется прослушивание MIME-типа. Это "сложное дело", прокомментировано в исходном коде. Вы можете прочитать комментарий, чтобы посмотреть, как разные браузеры обращаются с парами 'content-type/payload'

Рисунок 3: Заголовок ответа, содержащий Content-Type и полезную нагрузку, которая является фактическими данными
Если ответ является HTML-файлом, то следующим шагом будет передача данных в *рендер-процесс, но если это zip-файл или какой-либо другой файл, то это означает, что это запрос на загрузку, поэтому он будет передан в менеджер загрузок.

Рисунок 4: *Сетевой-поток спрашивает, являются ли данные ответа HTML данными с безопасного сайта
Здесь также выполняется проверка SafeBrowsing. Если домен и ответные данные, похоже совпадают с известным вредоносным сайтом, то *сетевой-поток предупреждает показом предупреждающей страницы. Кроме того, выполняется проверка Cross Origin Read Blocking (CORB), чтобы убедиться, что конфиденциальные межсайтовые данные не попадают в *рендер-процесс.
= Шаг 3. Поиск *рендер-процесса
После того, как все проверки завершены и *сетевой-поток уверен, что браузер может перейти к запрашиваемому сайту, *сетевой-поток сообщает *UI-потоку, что данные готовы. Затем *UI-поток ищет *рендер-процесс для продолжения рендеринга веб-страницы.

Рисунок 5: *Сетевой-поток, просящий *UI-поток предоставить *рендер-процесс
Поскольку сетевой запрос на получение обратного ответа может занять несколько сотен миллисекунд, применяется оптимизация для ускорения этого процесса. Когда *UI-поток посылает URL запрос в *сетевой-поток на шаге 2, он уже знает, к какому сайту он обращается. *UI-поток пытается проактивно найти или запустить *рендер-процесс параллельно с сетевым запросом. Таким образом, если все пойдет как ожидалось, *рендер-процесс уже будет находится в режиме ожидания, к моменту когда *сетевой-поток получил данные. Этот резервный процесс может быть не использован, если навигация будет перенаправлена на другой сайт, в этом случае может потребоваться другой процесс.
= Шаг 4. Реализация перехода
Теперь, когда данные и *рендер-процесс готовы, выполняется IPC запрос из *браузер-процесса в *рендер-процесс для реализации перехода. Также передается стрим данных, для того чтобы *рендер-процесс мог продолжать получать HTML-данные. Как только *браузер-процесс получает подтверждение того, что в *рендер-процессе всё выполнено, навигация завершается и начинается фаза загрузки документа.
На этом этапе адресная строка обновляется, а индикатор безопасности и пользовательский интерфейс сайта отражают информацию о сайте на новой странице. История сеансов для вкладки будет обновлена, поэтому кнопки "Назад" и "Вперед" позволят перемещаться с сайта, на который только что была осуществлена навигация. Для облегчения восстановления вкладки/сессии при закрытии вкладки или окна, история сеанса хранится на диске.
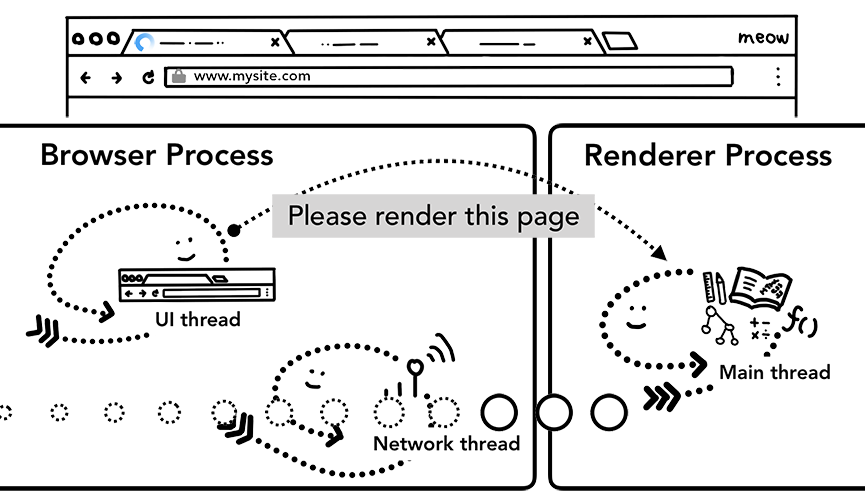
Рисунок 6: IPC между *браузер-процессом и *рендер-процессом, запрос на рендеринг страницы
= Дополнительный шаг. Завершение начальной загрузки
После реализации навигации *рендер-процесс продолжает загрузку ресурсов и рендеринг страницы. Подробнее о том, что происходит на этом этапе, мы расскажем в следующем посте. Как только *рендер-процесс "финиширует" рендеринг, он посылает IPC запрос обратно в *браузер-процесс (это происходит после того, как все события загрузки сработали на всех фреймах страницы и закончили своё выполнение). На этом этапе *UI-поток останавливает анимацию индикатора загрузки страницы.
Я пишу "финиширует" в кавычках, потому что JavaScript на стороне клиента все равно может загрузить дополнительные ресурсы и вывести новые представления после этого момента.
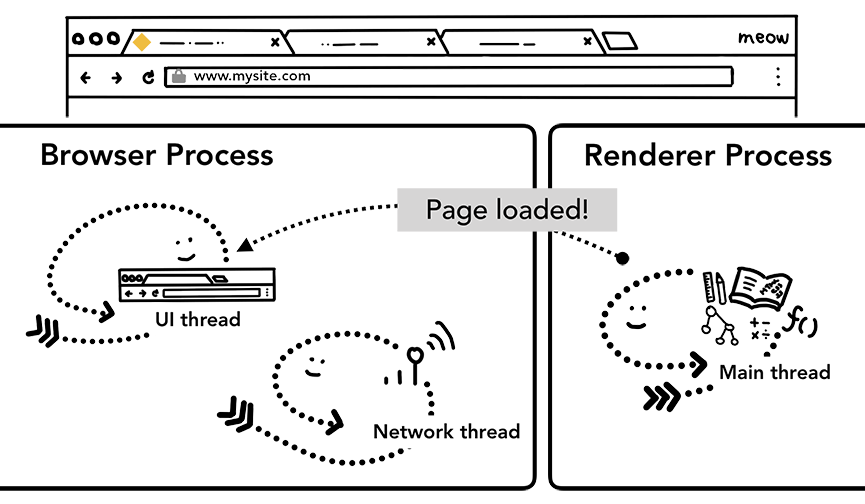
Рисунок 7: IPC-запрос от *рендер-процесса к *браузер-процессу для уведомления о том, что страница "загружена".
Навигация к другому сайту
Простая навигация была завершена! Но что случится, если пользователь снова поместит другой URL в адресную строку? Что ж, процесс браузера пройдет те же самые этапы, что и при переходе на другой сайт. Но перед тем, как это сделать, ему нужно проверить для текущего отрисованного сайта, волнует ли его событие beforeunload.
beforeunload может создавать высплыавющее предупреждение "Leave this site?" при попытке навигации наружу или закрытии вкладки. Все внутренние вкладки, включая ваш JavaScript код, обрабатывается *рендер-процессом, поэтому *браузер-процесс должен свериться с текущим *рендер-процессом, когда приходит новый навигационный запрос.
Внимание: Не добавляйте без необходмости обработчики beforeupload. Это создает больше задержек, так как обработчик должен быть выполнен еще до того, как навигация может быть запущена. Этот обработчик событий должен добавляться только при необходимости, например, если необходимо предупредить пользователей о том, что они могут потерять данные, введенные на странице.
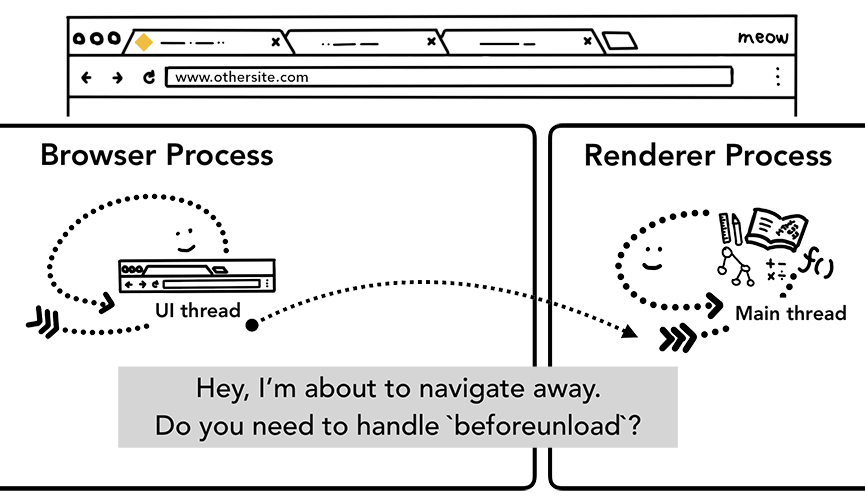
Рисунок 8: IPC-запрос от *браузер-процесса к *рендер-процессу, говорящий ему, что он собирается перейти на другой сайт
Если навигация была инициирована из *рендер-процесса (например, пользователь нажал на ссылку или JavaScript на стороне клиента запустил window.location = "https://newsite.com"), то *рендер-процесс сначала проверяет обработчики beforeupload. Затем он проходит через тот же процесс, что и процесс запуска навигации. Единственное отличие состоит в том, что запрос на навигацию запускается от *рендер-процесса к *браузер-процессу.
Когда новая навигация осуществляется на сайт, отличный от текущего, вызывается отдельный *рендер-процесс для обработки новой навигации, в то время как текущий *рендер-процесс продолжается для обработки таких событий, как выгрузка. Для получения более подробной информации смотрите обзор состояния жизненного цикла страницы и то, как вы можете подключаться к событиям с помощью Page Lifecycle API.
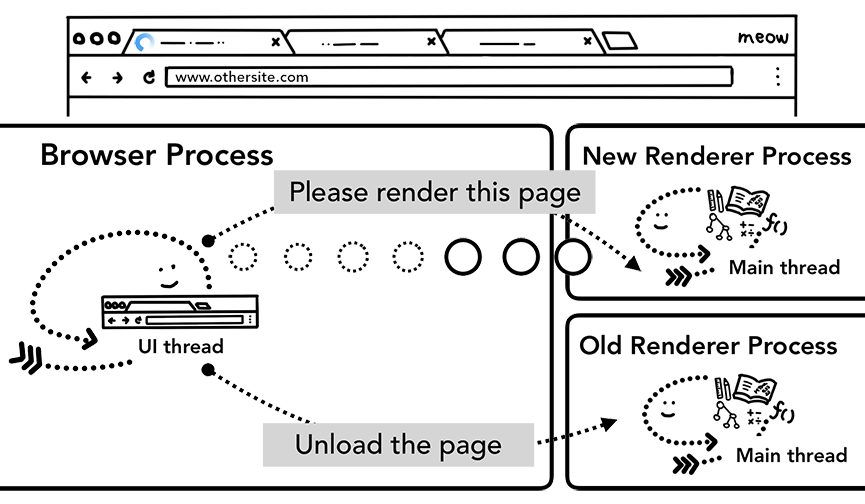
Рисунок 9: 2 IPC-запроса от *браузер-процесса к новому *рендер-процессу, говорящему отрисовать страницу и говорящему старому *рендер-процессу выгрузить страницу
При использовании Service Worker
Одним из недавних изменений в процессе навигации является введение service worker. Service worker (*сервис-воркер) — это способ написания сетевого прокси в коде вашего приложения; позволяющий веб-разработчикам иметь больше контроля над тем, что кэшировать локально а когда получать новые данные из сети. Если *сервис-воркер настроен на загрузку страницы из кэша, то нет необходимости запрашивать данные из сети.
Важно помнить, что *сервис-воркер — это JavaScript-код, который запускается в *рендер-процессе. Но когда приходит запрос на навигацию, откуда *браузер-процессу знать, что у сайта есть *сервис-воркер?
Когда *сервис-воркер зарегистрирован, скоуп *сервис-воркера сохраняется как ссылка (вы можете прочитать более подробную информацию об этом скоупе в статье The Service Worker Lifecycle). Когда происходит навигация, *сетевой-поток сравнивает домен со скоупами *сервис-воркера, если *сервис-воркер зарегистрирован для этого URL, то *UI-поток ищет *рендер-процесс, чтобы выполнить код *сервис-воркера. *Сервис-воркер может загружать данные из кэша, исключая необходимость запрашивать данные из сети, или может запрашивать новые ресурсы из сети.

Рисунок 10: сетевой поток в процессе просмотра браузером скоупа *сервис-воркера
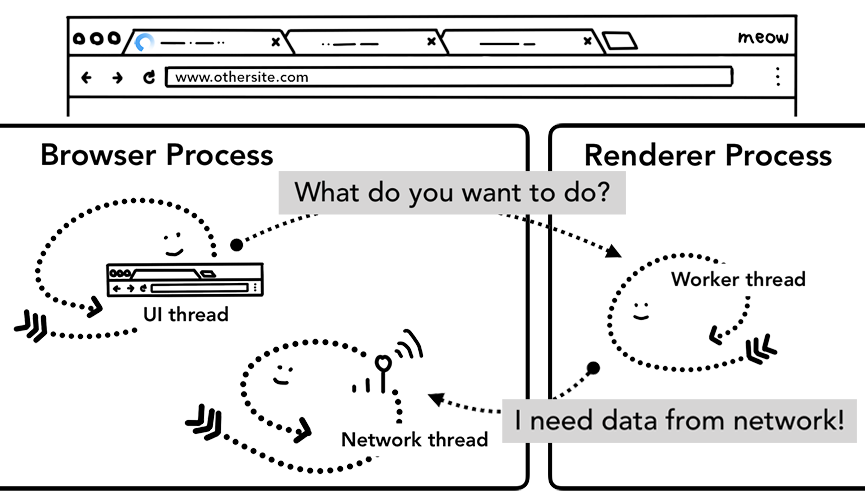
Рисунок 11: *UI-поток в *браузер-процессе запускает *рендер-процесс для работы с *сервис-воркерами; поток *сервис-воркера в *рендер-процессе затем запрашивает данные из сети
Предзагрузка при навигации (Navigation Preload)
Вы можете видеть, что цикл общения между *браузер-процессом и *рендер-процессом может приводить к задержкам, если *сервис-воркер в конце концов решит запросить данные из сети. Navigation Preload — это механизм ускорения этого процесса путем загрузки ресурсов параллельно с запуском *сервис-воркера. Он помечает эти запросы заголовком, позволяя серверам решить отправить ли различное содержимое для этих запросов; например, просто обновленные данные вместо полного документа.
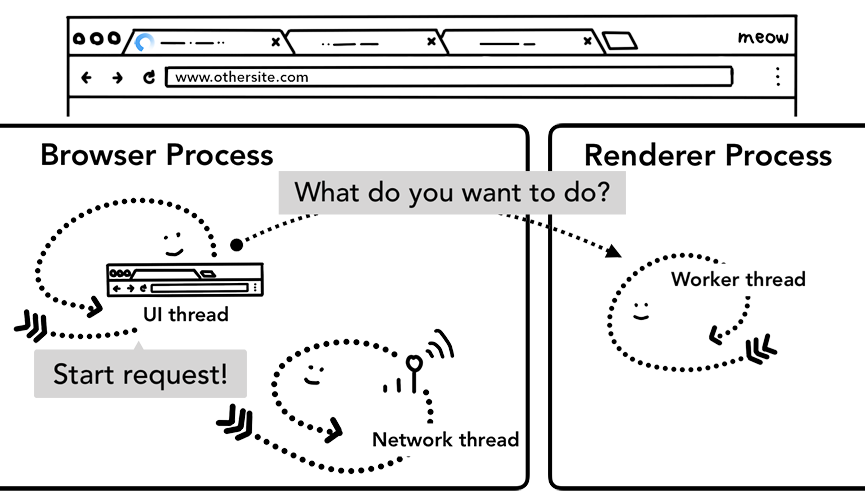
Рисунок 12: *UI-поток в *браузер-процессе, запускающий *рендер-процесс для обработки *сервис-воркера с параллельным запуском сетевого запроса
Краткие итоги
В этом посте мы рассмотрели, что происходит во время навигации и как код вашего веб-приложения, такой как заголовки ответов и JavaScript на стороне клиента, взаимодействует с браузером. Знание шагов, через которые проходит браузер для получения данных из сети, облегчает понимание того, зачем были разработаны API, такие как Navigation Preload. В следующем посте мы погрузимся в то, как браузер обрабатывает HTML/CSS/JavaScript для отображения страниц.
Предыдущая часть
 с CRM Битрикс24")

")

