
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Все началось в 2001 году, когда интернет только начинал свое победное шествие, и появился неограниченный доступ к огромной библиотеке знаний. Мы жадно скачивали электронные версии книг и статей. Всё! Всё, что что могло быть полезным в самообразовании. В первую очередь нас, конечно, интересовало программирование, электроника и механика, но биологией, медициной, химией и прочим мы тоже не брезговали. Таким образом, у каждого стала формироваться персональная электронная библиотека.
Но мы быстро столкнулись с проблемой систематизации знаний. Выяснилось, что файловая система не очень подходит для этих целей. Первым признаком стал процесс дублирования каталогов.

Затем папка ‘Разобрать’ превратилась в подобие черной дыры. В нее стали попадать все документы, которые было сложно отнести к какой-либо категории.

Первое, что пришло в голову – помещать копии документа одновременно в несколько каталогов. Но и это тоже оказалось не особо удобно: структура каталогов становилась все запутаннее и запутаннее.
Дело в том, что работа с древовидными системами подразумевает осуществление постоянного выбора каталога или папки на основе классификации содержимого сохраняемого или искомого документа. Мы так не любим “разгребать” файлы потому, что классификация - сложная высокоуровневая функция мозга.
Гораздо проще перечислить категории или указать теги, ассоциируемые с содержанием документа/файла, тем более что этот процесс можно автоматизировать. И это круто, т.к. позволяет задействовать ассоциативное мышление, которое гораздо проще классификации. Но абсолютно не понятно, как визуализировать список тегов и производить поиск по документам.
В 2014 году (эту дату имеют первые эскизы) были предложены две гипотезы:
если один документ относится к двум и более тегам (категориям), значит эти теги связаны
если сохранить несколько документов, то используя меру сходства можно вычислить связи между тегами и построить карту тегов (граф)
Прорабатывая эти идеи, мы поняли, что получается что-то очень интересное: персонализированная графовая база данных, в которой решена проблема описания связей. Используя эти концепции можно построить систему хранения информации, работающую на новых принципах. Для проверки работоспособности идеи были нарисованы скетчи интерфейса и начата разработка прототипа.
Изначально мы делали Desktop-приложение на C++, но потом отказались от него и разработали web-сервис. Online-приложение проще распространять, обновлять и поддерживать силами небольшой команды в условиях ограниченного финансирования. К сожалению, мы поняли это достаточно поздно, поэтому на разработку работающего прототипа ушло несколько лет. Теперь мы можем дать совет “web application is the first” или всегда делайте сначала web-приложение.
Тем не менее, мы получили неоценимый опыт, а также существенный задел, который пригодится в будущем. Ведь мы не отказались от desktop-приложения и обязательно его выпустим в случае успеха нашего проекта.
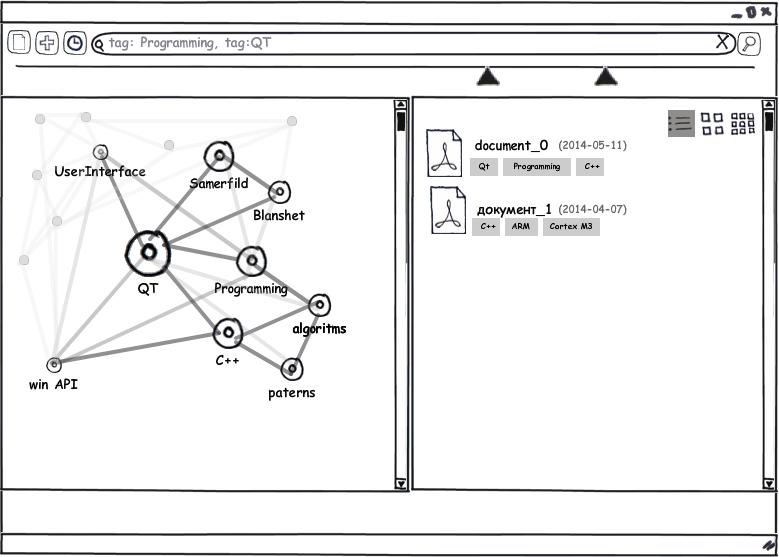
Как сейчас это работает?
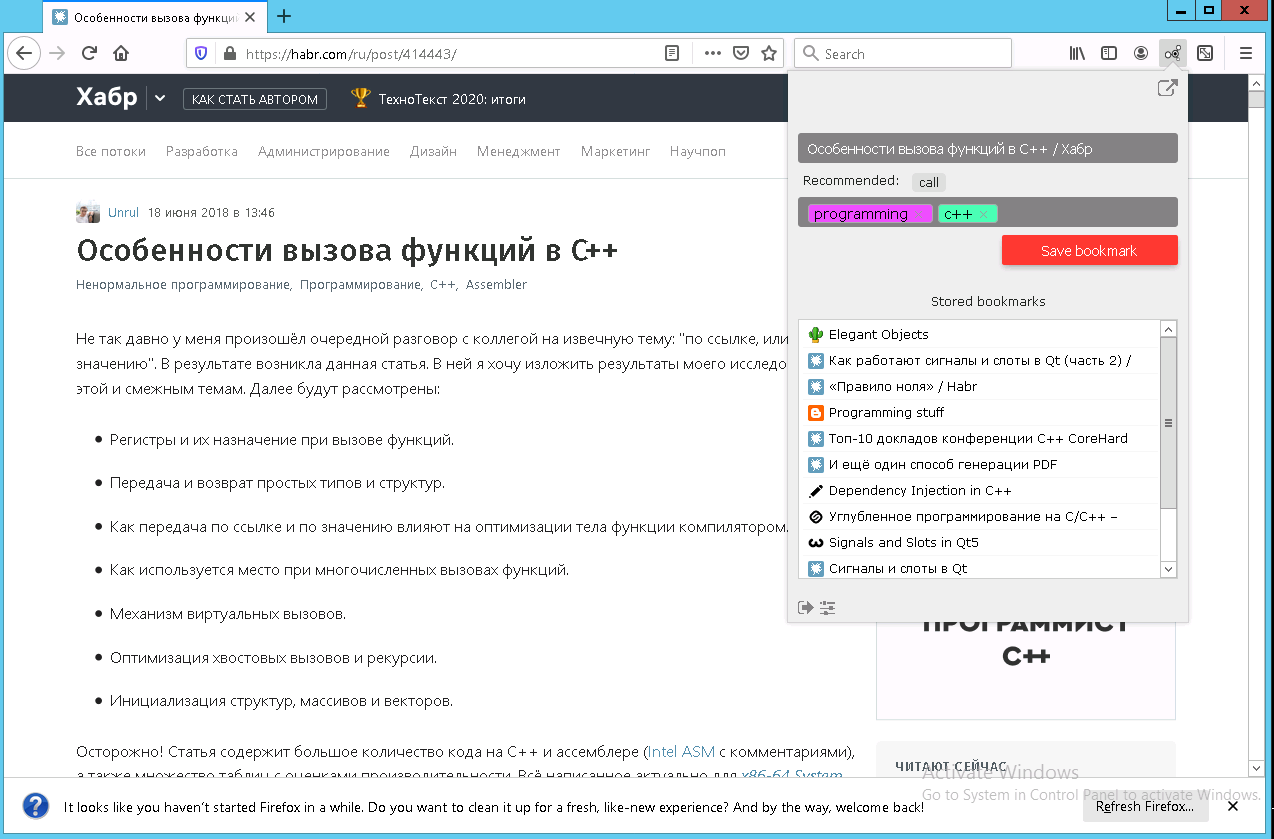
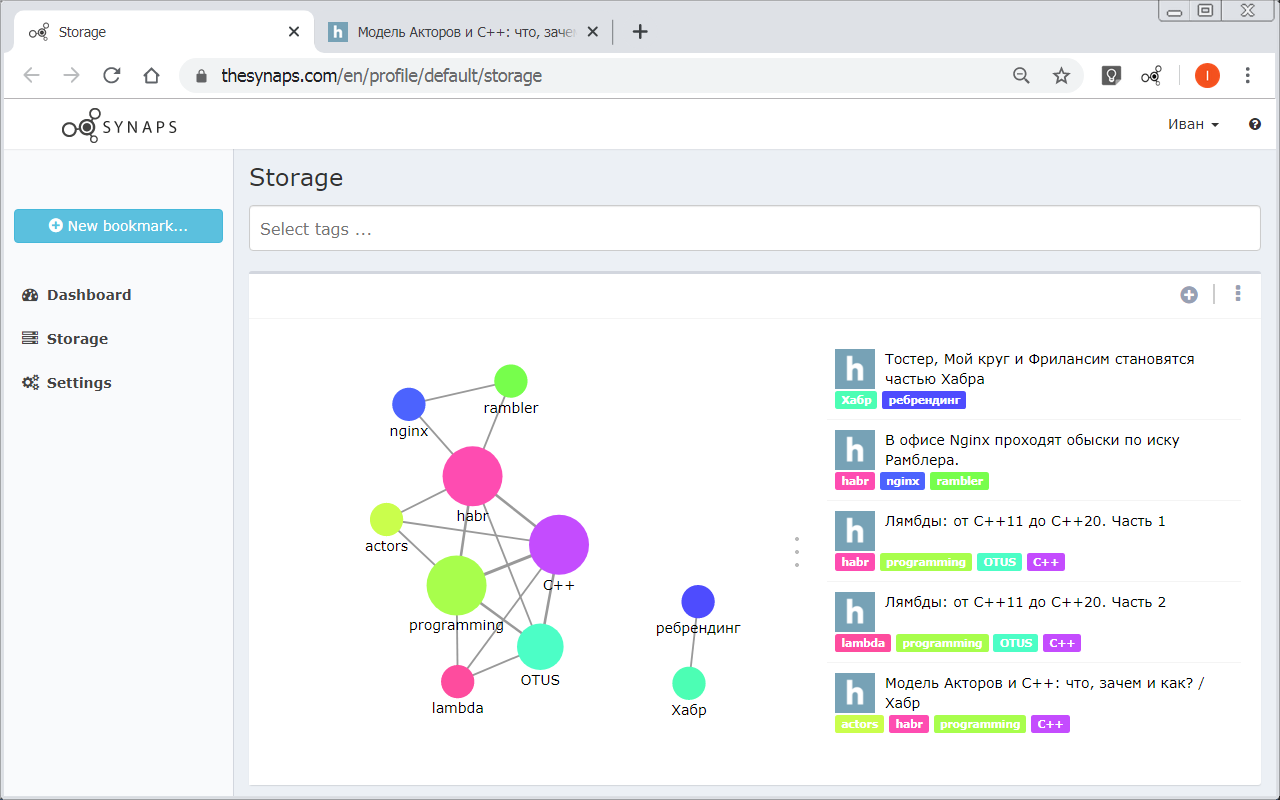
Каждому сохраняемому документу автоматически предлагается последовательность тегов, которая ассоциируется с содержимым документа. Пользователь может редактировать эту последовательность добавлять и удалять свои теги. На рисунке ниже приведен пример сохранения веб-странички при помощи плагина для браузера.
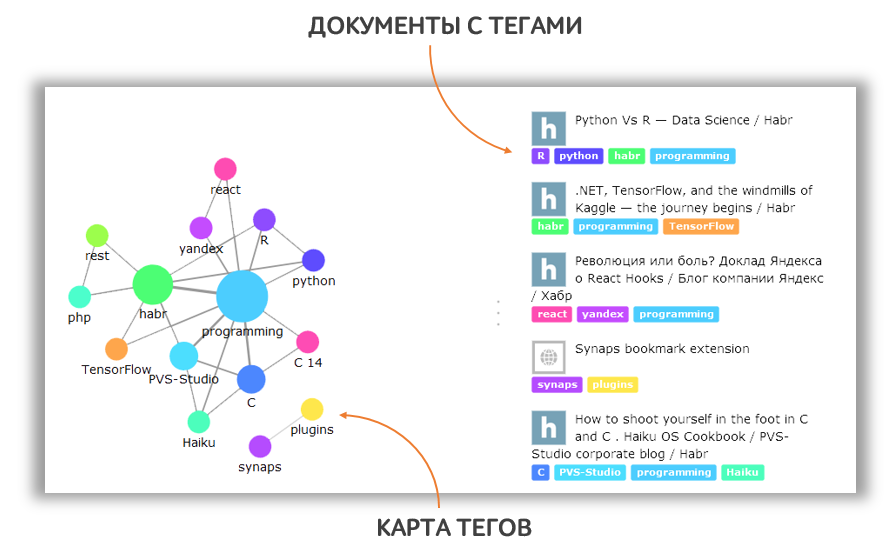
Затем мы вычисляем расстояние связи между тегами и представляем результаты в виде карты тегов, которая по сути является графическим отображением ваших знаний.
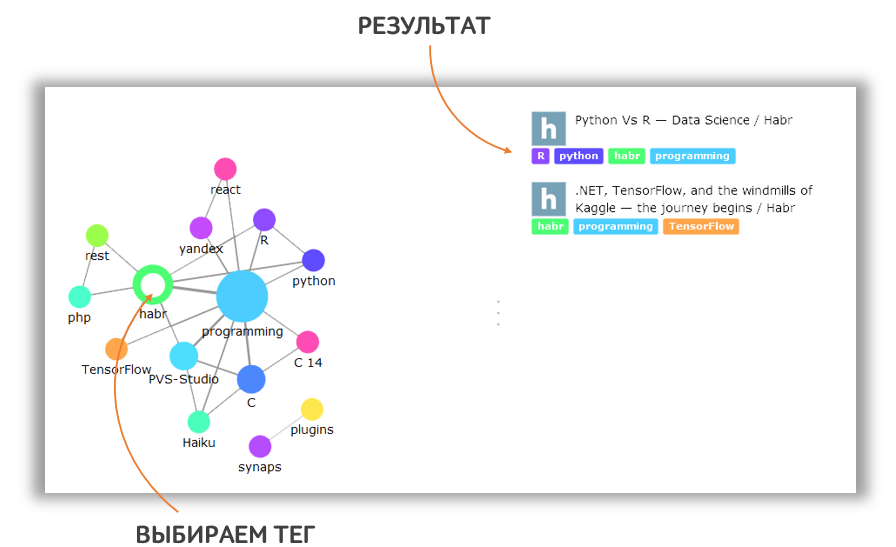
При выборе тега на карте происходит фильтрация списка документов, обеспечивая поиск необходимой информации.
Все просто!
Мы сами пользуемся нашим приложением. Причем чем больше документов сохраняешь, тем более интересную информацию можно получить из карты тегов. Думаю, что это может стать отличной темой для следующей статьи.
Техническая часть
Несмотря на кажущуюся простоту наш проект технологически достаточно сложен. Основная инфраструктура (IaaS) “крутится” в собственном облаке, построенном на базе OpenStack, развернутом на 3-х серверах Intel.
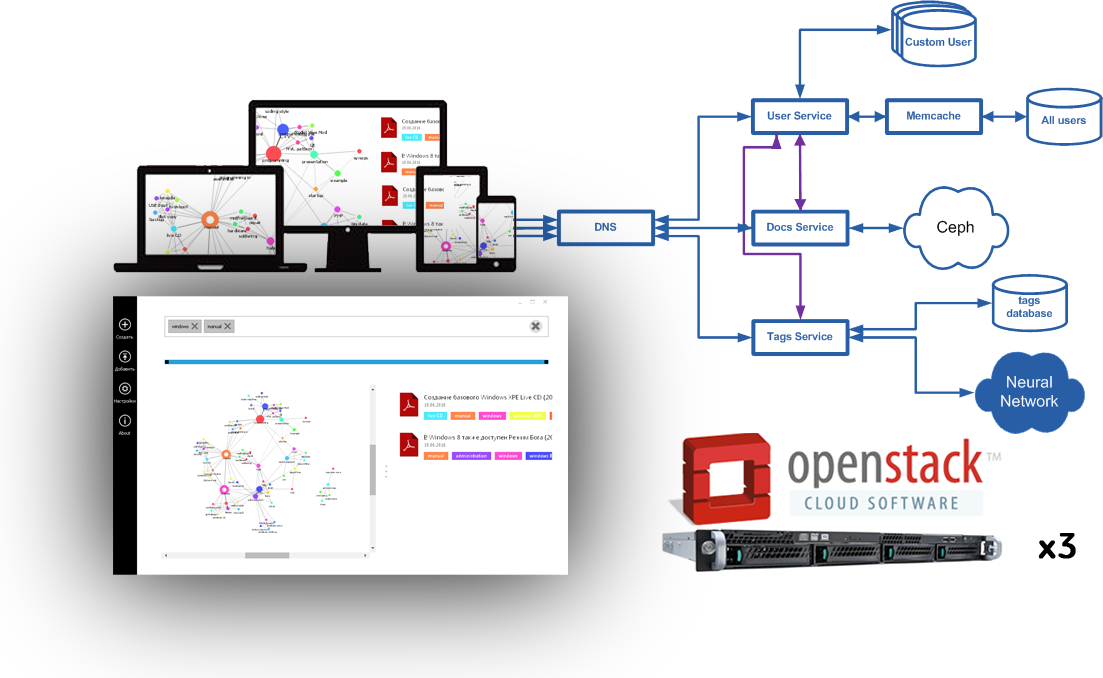
Для стартапа, конечно, логичнее использовать готовое облако, а не тратить ресурсы на разворачивание своего. Однако, на момент начала проекта у нас уже было свое железо и опыт развертывания подобных систем. Мы придерживались правила: используй технологии с которыми хорошо знаком. К тому же собственное облако в нашем случае имело ряд преимуществ:
соответствие требованиям 152-ФЗ;
данные принадлежат нам, а не 3-й стороне
оперативное взаимодействие с командой, занимающейся инфраструктурой (кто работал с Amazon поймут)
дешевле (в нашем случае)
возможность использования инфраструктуры в других проектах.
Стоит отметить, что часть инфраструктуры, все же работает в облаках Amazon и российского провайдера SprintHost. Там “крутятся” вторичный DNS, почта, мониторинг и другие вспомогательные сервисы, делая нашу систему более распределенной и надежной.
На следующем уровне (PaaS) работают web-сервера и базы данных. Мы еще занимаемся строительством этого уровня: не решена задача автоматического масштабирования, шардирования и т.д. Но мы работаем над этим. Если бы мы использовали Amazon, большая часть задач была бы решена, но за это пришлось бы заплатить технологической зависимостью от сервис-провайдера в будущем. В общем, это достаточно холиварная тема даже среди нашей команды.
На третьем уровне (SaaS) работает уже сам сервис Synaps, построенный по принципу микро-сервисов, где каждую задачу решает маленькое приложение. Эти приложения общаются между собой через API, решая единую задачу. Такой подход позволяет независимо менять модули, сохраняя работоспособность всей системы. Выбор конкретных технологий в этом случае был так же обусловлен имеющимися компетенциями в команде, поэтому большая часть сервисов написана на языке php и python.
Часть сервисов предоставляют публичный REST API, посредством которого осуществляется взаимодействие с клиентским ПО. Например, сайт с пользовательским интерфейсом thesynaps.com является клиентом и не содержит никаких данных. Второй клиент – это плагины для браузеров. Их задача упростить процесс сохранения web-страниц в хранилище Synaps.
Внедрение и перспективы
На данный момент у нас полноценно работает прототип (MVC), позволяющий работать с ссылками на web-ресурсы (закладки). Он показал не только возможность реализации системы ассоциативного хранения данных, но и позволил получить первых пользователей, полностью отказавшихся от альтернативных инструментов работы с web-закладками.
Сейчас мы реализуем наиболее востребованный пользователями функционал в сервисе работы с web-закладками. Так недавно был добавлен механизм импорта/экспорта, на основе ElasticSearch реализовано автоматическое распознавание тегов при добавлении нового документа и т.д.
Мы планируем расширять нашу аудиторию, предоставляя самый удобный бесплатный сервис работы с web-закладками. Надеемся, что приложение будет востребовано среди продвинутых пользователей и разработчиков. Мы оцениваем российский рынок не менее чем в 500 тыс. человек с потенциалом роста 3-5% в год.
Но настоящее будущее нашего продукта мы все же видим в работе с файлами и документами. Работы в этом направлении ведутся уже давно. Основой должно стать кроссплатформенное приложение, с которого начинался наш проект. Это приложение будет синхронизироваться с сервисом посредством REST API и способно работать offline.
Вместо заключения.
Если вы дочитали до этого места, значит тема статьи для вас актуальна. Потратье еще 30 секунд и попробуйте наш сервис (пока только online и только закладки): https://thesynaps.com.
Будем признательны дельным коментариям. Нам крайне важно мнение хабровчан стоит ли дальше развивать этот проект?
Спасибо




