
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

В предыдущих частях серии статей мы рассмотрели принципы работы преимущественно с точки зрения приложения. В этой заключительной части мы сфокусируемся на инфраструктуре.
Серия статей состоит из следующих связанных частей:
Часть 1: Сообщение producer’а;
Часть 2: Подъем consumer’ов;
Часть 3: Смещения и как с ними справляться;
Часть 4: Мой кластер потерян! — Принятие неудачи.
Обычно предприятия используют Kafka в качестве основы для своей платформы обработки данных. Дело в том, что она справляется с широким спектром критически важных для бизнеса рабочих нагрузок. Но рано или поздно все может быть обречено на провал. Вот почему важно учитывать неудачи при проектировании (да, ошибки реальны) вашей общей архитектуры и мыслить терминами резервного копирования и аварийного восстановления.
В предыдущих частях упоминался и применялся Айвен для Кафки. Aiven — это полноценная платформа передачи данных, ориентированная на будущее. Что действительно интересно — насколько легко настраивать решения для аварийного восстановления, независимо от того, используется ли она одним или несколькими облачными провайдерами.

Давайте предположим, что вы хотите внедрить многооблачное решение для аварийного восстановления с помощью Aiven для Kafka. Здесь следует выделить две вещи:
1. Поскольку Aiven не предлагает привязки к поставщику облачных услуг, это позволяет легко развертывать кластеры в разных облаках.
2. Для репликации данных при разработке решений для аварийного восстановления используется Mirror Maker 2.
Две основные схемы аварийного восстановления:
Active / Passive Pattern: использует вторичный кластер, который действует, как резервная копия.
Active / Active Pattern: использует два кластера, реплицируя данные между ними.
Некоторые шаблоны синхронизации или репликации данных также могут приводить к сбою, поскольку данные также реплицируются.
Fan-out Pattern: данные реплицируются из одного кластера в несколько кластеров.
Use Case: реплицируйте данные в разные облака и/или в области.Aggregation Pattern: пограничные кластеры отправляют данные в централизованный кластер, который действует, как агрегатор.
Use Case: агрегируйте данные в централизованное хранилище; например, для хранилища данных или операционной.Full-Mesh Pattern: кластеры отправляют данные друг другу.
Use Case: разные кластеры работают в разных регионах/странах, и данные должны быть доступны в целом в каждом регионе / стране, например, для удовлетворения оперативных потребностей.
Распространенный шаблон — Active/Passive, то есть наличие одного активного кластера, который синхронизирует свои данные со вторичным кластером, который станет активным в том случае, если текущий активный кластер станет недоступен (failover).

Важная вещь, на которую следует обратить внимание в отношении сервисов Aiven, заключается в том, что общая связь между различными облаками осуществляется с использованием туннеля IPSec для обеспечения безопасной сети.

Mirror Maker 2 использует платформу Connect для репликации данных между кластерами Kafka. Можно развернуть MirrorMaker2 либо на AWS, либо на GCP.
MM2 включает в себя несколько новых функций, таких как:
репликация данных темы и группы консьюмеров;
конфигурация темы и репликация ACL;
синхронизация кросс-кластерных смещений (оффсетов);
сохранение партиций.
При благоприятном исходе у вас есть приложения консьюмеров и продюсеров, работающие в активном кластере, в данном случае на AWS, а затем, бум, обнаруживается неудача.
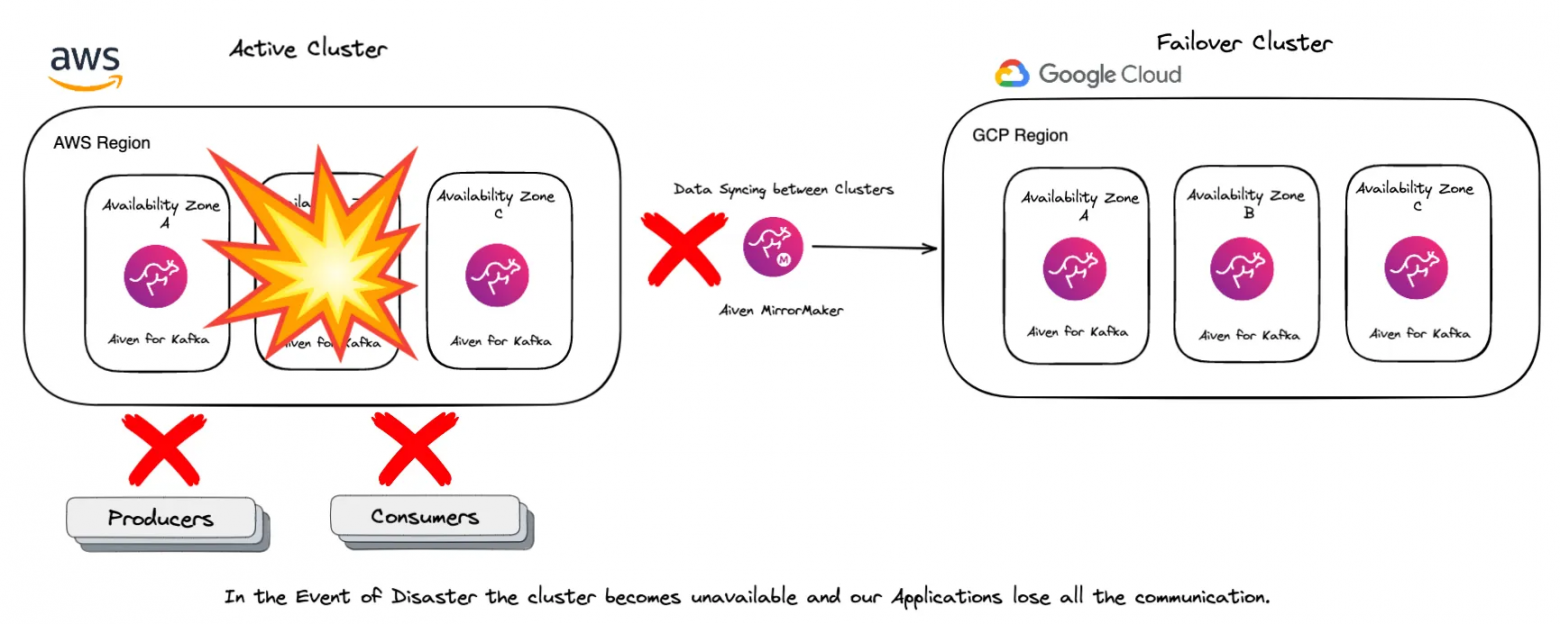
Весь кластер выходит из строя, приложения становятся недоступными.
При работе с распределёнными системами и при планировании аварийных ситуаций вам и вашей команде необходимо ответить на один важный вопрос: что для вас значит катастрофа?
Например, ваш кластер может временно стать недоступным из-за какой-либо временной проблемы с сетью, но через несколько минут все снова заработает. Приемлем ли такой сценарий для вашего бизнеса? Можете ли вы мириться с этим или вашему приложению необходимо переключиться, как только кластер оказывается потерянным? Нужно ли вам немедленно переключить все ваши приложения?
Ответы на такого рода вопросы помогут вам занять наиболее выгодное положение при разработке вашего решения. Последний недостающий элемент — это то, как на самом деле будет выглядеть отработка отказа на практике.
Один из подходов к этой проблеме — свести логику вашего приложения с логикой повторных попыток.
Существует много хороших библиотек, которые обеспечивают отказоустойчивость и жизнеспособность, такие как Resilience4j для Java, Arrow Fx для Kotlin и ZIO для Scala. Обратите внимание, что все они — функциональные функциональными библиотеки.

Как показано в приведенном выше фрагменте, здесь следующая цель: как только приложения потеряют подключение к кластеру, зафиксируйте это, запустите логику повторных попыток и, в конце концов, при необходимости, вернитесь к исправному кластеру.
Примечание: Возможно, у вас уже запущены сотни приложений в продакшене или у вас много разных команд, каждая из которых создает свои собственные приложения. Добавление жизнеспособности к логике вашего приложения может быть затруднено на этапе внедрения и координации. Альтернативами могут быть добавление LoadBalancer для обработки трафика или использование технологий Service Mesh.
Подведение итогов
Неудача — это то, что рано или поздно произойдёт, и вы должны иметь это в виду. При разработке решений для аварийного восстановления вам, возможно, потребуется спросить:
Каким должно быть определение — мой кластер потерян — в контексте нашего бизнеса?
Как быстро приложения должны переключиться на работоспособный кластер и начать функционировать?
Каков наилучший подход к реализации отработки отказа приложения?

Мы рекомендуем прокачивать свои навыки разработчика вместе с Apache Kafka!
В 2023 инженерам инфраструктуры и программистам необходимо знание Apache Kafka. Углублённый курс с практикой на Java или Golang и платформой Spring+Docker+Postgres переведёт вас на новый уровень владения инструментом.
На курсе «Apache Kafka для разработчиков» мы обсудим:
неправильное использование Кафка и отсутствие коммитов в ней;
ваши кейсы о проблемах при работе с Apache Kafka;
опыт создания Data Lake на ~80 ТБ с помощью Apache Kafka;
особенности эксплуатации kafka с retention в 99999999.
Стартуем уже 12 мая 2023! Вас ждут встречи, живые трансляции, ответы на вопросы от спикеров, обсуждение Kafka с другими участниками интенсива, много практики на стендах и закрепление материала.
Присоединяйтесь и покоряйте вершины Kafka
Интересные статьи
Интересные статьи
")


