

Прогресс в области машинного обучения для обработки естественного языка существенно ускорился за последние несколько лет. Модели покинули исследовательские лаборатории и стали основой ведущих цифровых продуктов. Хорошей иллюстрацией этому служит недавнее заявление о том, что основным компонентом, стоящим за поиском Google, стала модель BERT. Google верит, что этот шаг (т.е. внедрение передовой модели понимания естественного языка в поисковую систему) представляет собой «величайший прорыв за последние пять лет и один из знаменательнейших во всей истории поисковых систем».
Данная статья – это простое руководство по использованию одной из версий BERT'а для классификации предложений. Пример, рассмотренный нами, одновременно и достаточно простой для первого знакомства с моделью, и достаточно продвинутый для того, чтобы продемонстрировать ключевые концепты.
Помимо этой статьи был подготовлен ноутбук, который можно посмотреть в репозитории или запустить в Colab.
Данные: SST2
В нашем примере мы будем использовать набор данных SST2, содержащий предложения из отзывов о фильмах, каждое из которых имеет либо положительную метку (значение 1), либо отрицательную (значение 0):

Модели: классификация тональности предложений
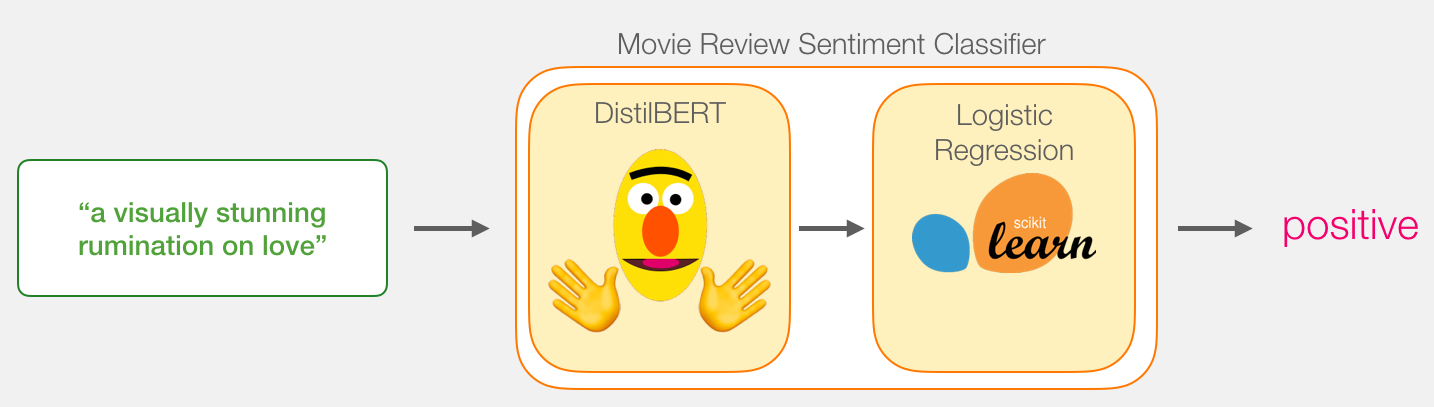
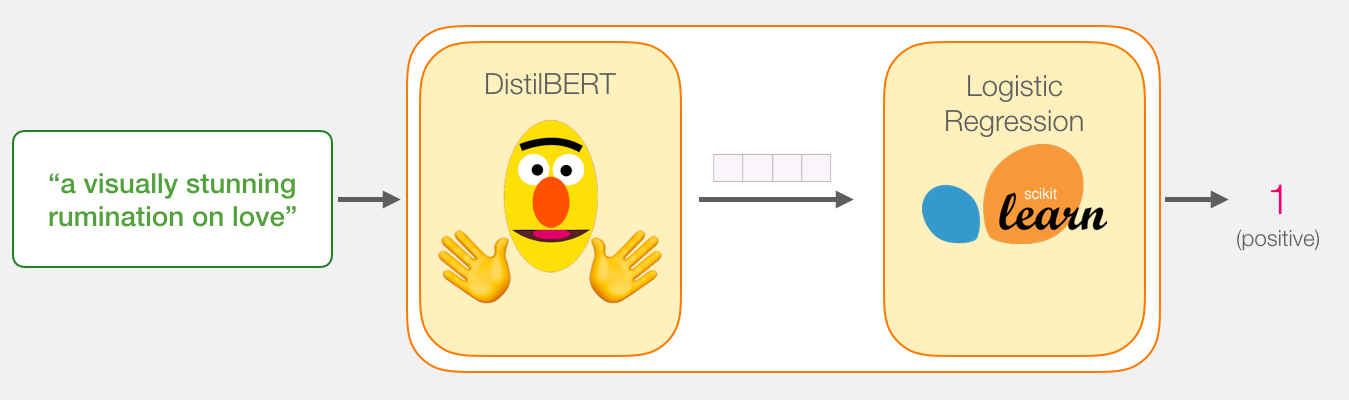
Наша цель – создать модель, которая берет одно предложение (вроде тех, что в нашем наборе данных) и выдает или 1 (что будет указывать на положительную тональность предложения), или 0 (отрицательная тональность). Мы можем схематично изобразить это так:

Под капотом же модель будет содержать целых две модели:
- DistilBERT обрабатывает предложения и передает извлеченную им информацию в следующую модель. DistilBERT представляет собой уменьшенную версию BERT'а, разработанную и выложенную в отрытый доступ группой разработчиков HuggingFace. Она быстрее и легче своего старшего собрата, но при этом вполне сравнима в результативности.
- Следующая модель – базовая логистическая регрессия из библиотеки scikit learn, которая берет результат обработки DistilBERT'ом и классифицирует предложение как положительное или отрицательное (1 или 0 соответственно).
Данные, которые мы передаем между двумя моделями, представляют собой вектор размерности 768. Можно считать этот вектор эмбеддингом предложения, который мы используем для классификации.
Для тех, кто читал предыдущую статью BERT, ELMO и Ко в картинках (как в NLP пришло трансферное обучение): этот вектор является результатом первой позиции (которая получает на вход токен [CLS]).
Обучение модели
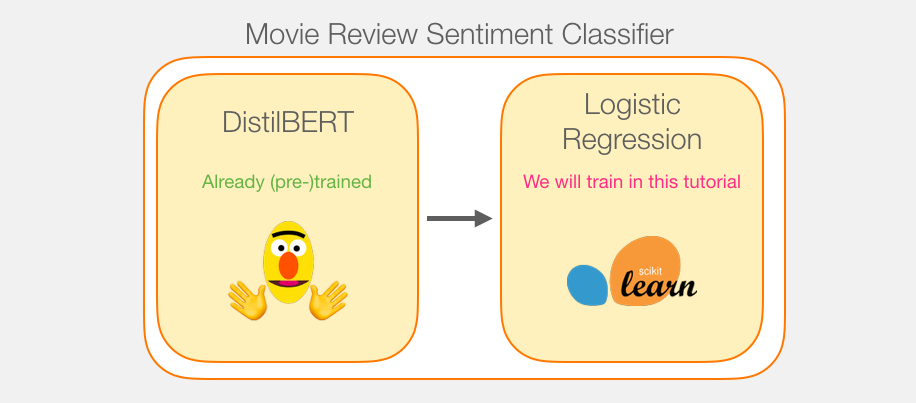
Несмотря на то, что мы используем две модели, обучать мы будем лишь логистическую регрессию. Что касается DistilBERT'а, то мы воспользуемся уже предобученной моделью для английского языка. И хотя она не была ни обучена, ни настроена для задачи классификации, мы можем воспользоваться некоторыми «навыками» BERT'а, которыми он обладает для решения общих задач. В первую очередь, имеется в виду тот факт, что BERT подает на выход вычисления по первой позиции, связанной с [CLS] токеном. Вероятно, этот навык он приобрел в связи с такой задачей, как классификация следующего предложения. Для ее выполнения, судя по всему, BERT и обучается включать смысл всего предложения в вывод по первой позиции.
В библиотеке transformers содержатся реализации DistilBERT'а, а также предобученные версии модели.
Обзор руководства
Итак, вот план нашей игры. Сначала мы воспользуемся обученным DistilBERT'ом для создания эмбеддингов для 2 тысяч предложений.

После этого мы больше не будем касаться DistilBERT'а. Далее вся работа будет проходить со Scikit Learn. Мы, как обычно, разбиваем наш набор данных на обучающую и тестовую выборки:
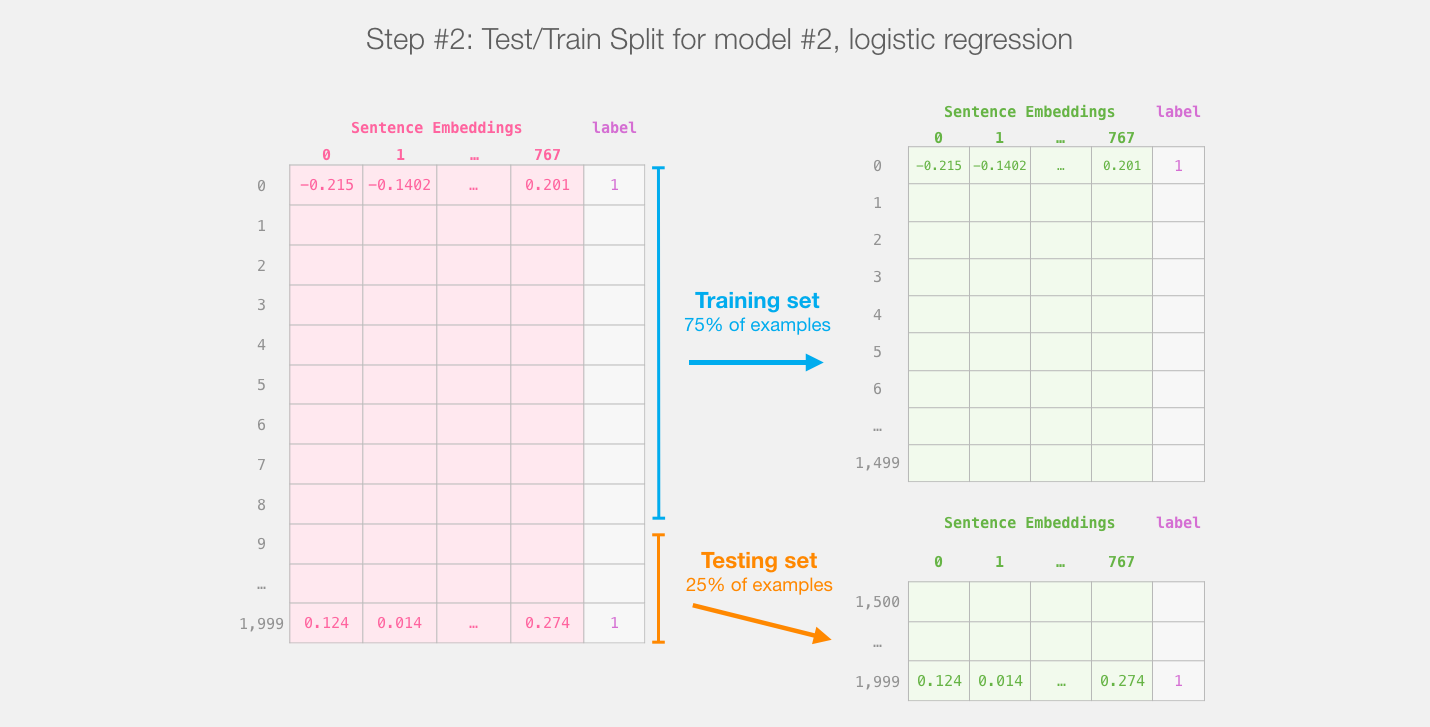
Разделение на обучающую и тестовую выборки для выхода distilBERT'а (модель #1) создает наборы данных, на которых мы будем обучать и оценивать модель логистической регрессии (модель #2). Имейте в виду, что в реальности sklearn перемешивает примеры перед тем, как разделять на выборки, а не просто берет первые 75% примеров так, как они хранятся в исходном наборе данных
Далее мы обучаем логистическую регрессию на обучающей выборке:

Как вычисляется предсказанное значение
Прежде чем мы углубимся в код и объясним, как обучать модель, давайте посмотрим на то, как обученная модель подсчитывает предсказанное значение.
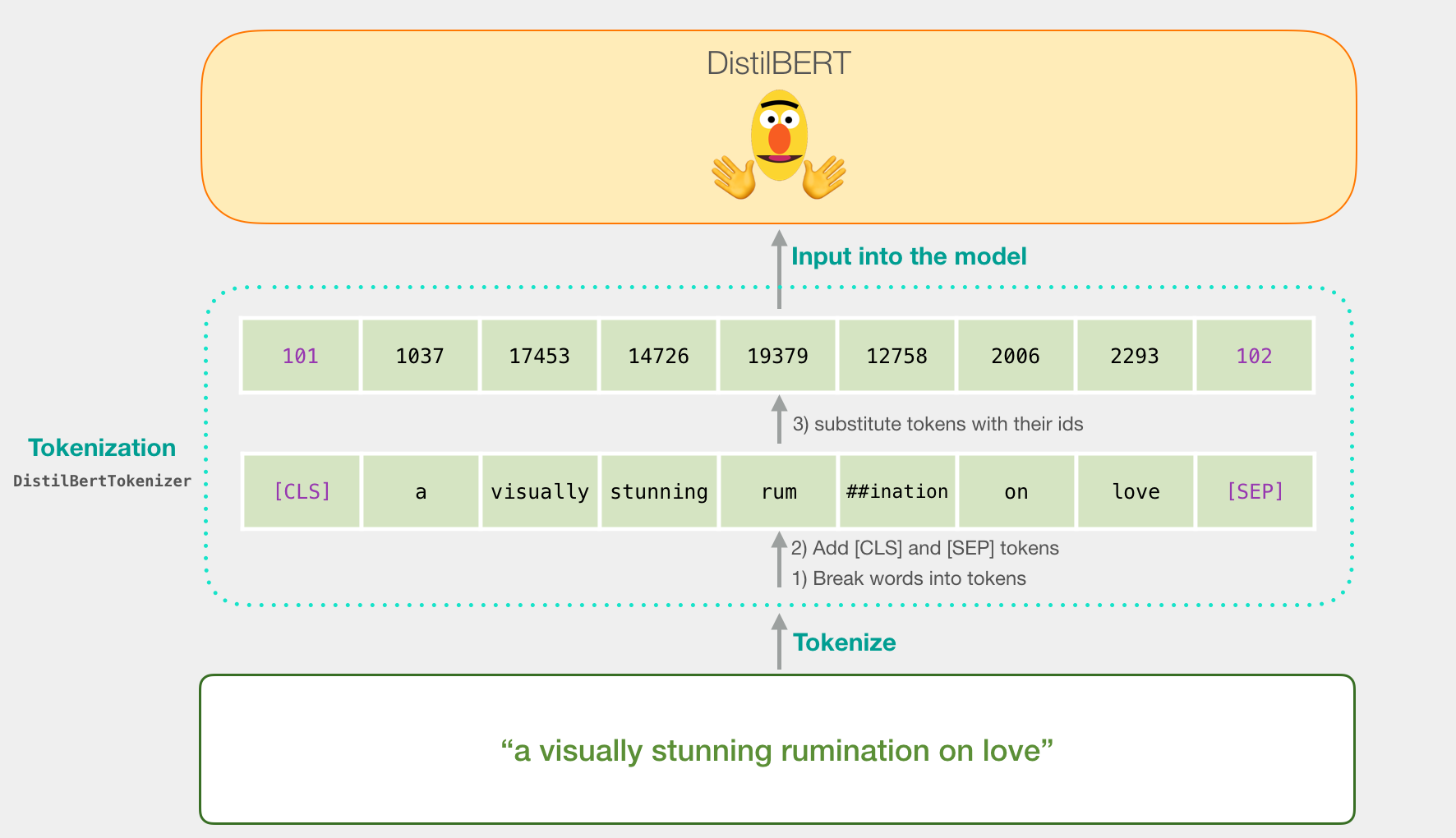
Давайте попробуем классифицировать предложение «a visually stunning rumination on love». Первым делом используем токенизатор BERT'а для того, чтобы разбить предложение на токены. Далее добавим специальные токены, которые нужны для классификации предложения (а именно токен [CLS] на первой позиции и [SEP] в конце предложения).

Третьим шагом будет замена каждого токена его идентификатором из таблицы эмбеддингов, которую мы получаем вместе с обученной моделью. Подробнее об эмбеддингах слов можно посмотреть в статье Word2vec в картинках.

Все эти три действия токенизатор делает одной строчкой кода:
tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)Наше входное предложение теперь имеет подходящую форму для обработки в DistilBERT'е.
Если вы читали статью BERT, ELMO и Ко в картинках (как в NLP пришло трансферное обучение), то вам будет понятна следующая иллюстрация:
Проходя через DistilBERT
Порядок обработки входного вектора в DistilBERT'е точно такой же, как и в обычном BERT'е. На выходе будет вектор для каждого входного токена, состоящий из 768 чисел с плавающей точкой.
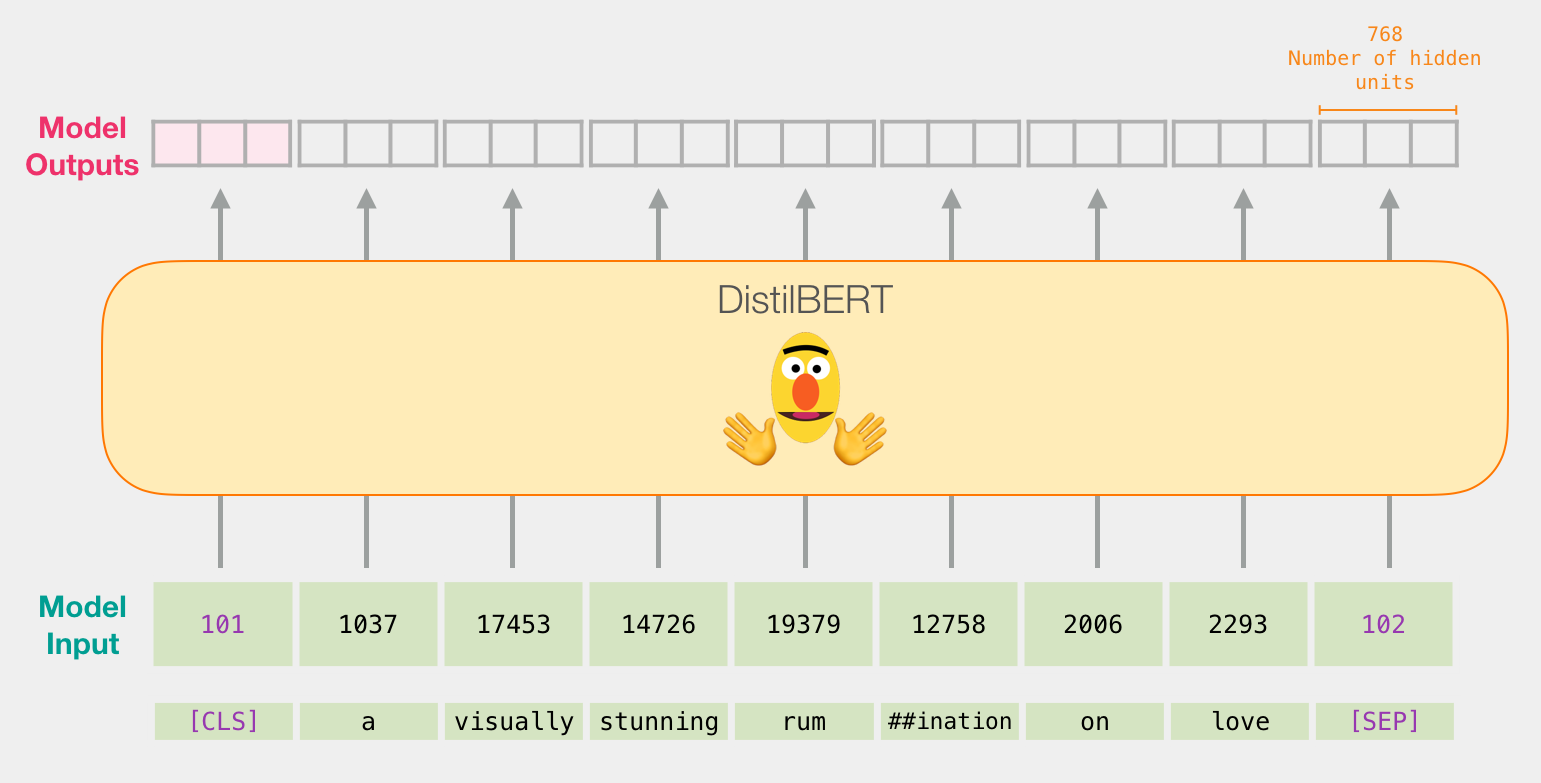
Поскольку перед нами стоит задача классификации предложений, мы игнорируем все, кроме первого вектора (связанного с [CLS] токеном). Этот вектор мы передаем в качестве входного в модель логистической регрессии.
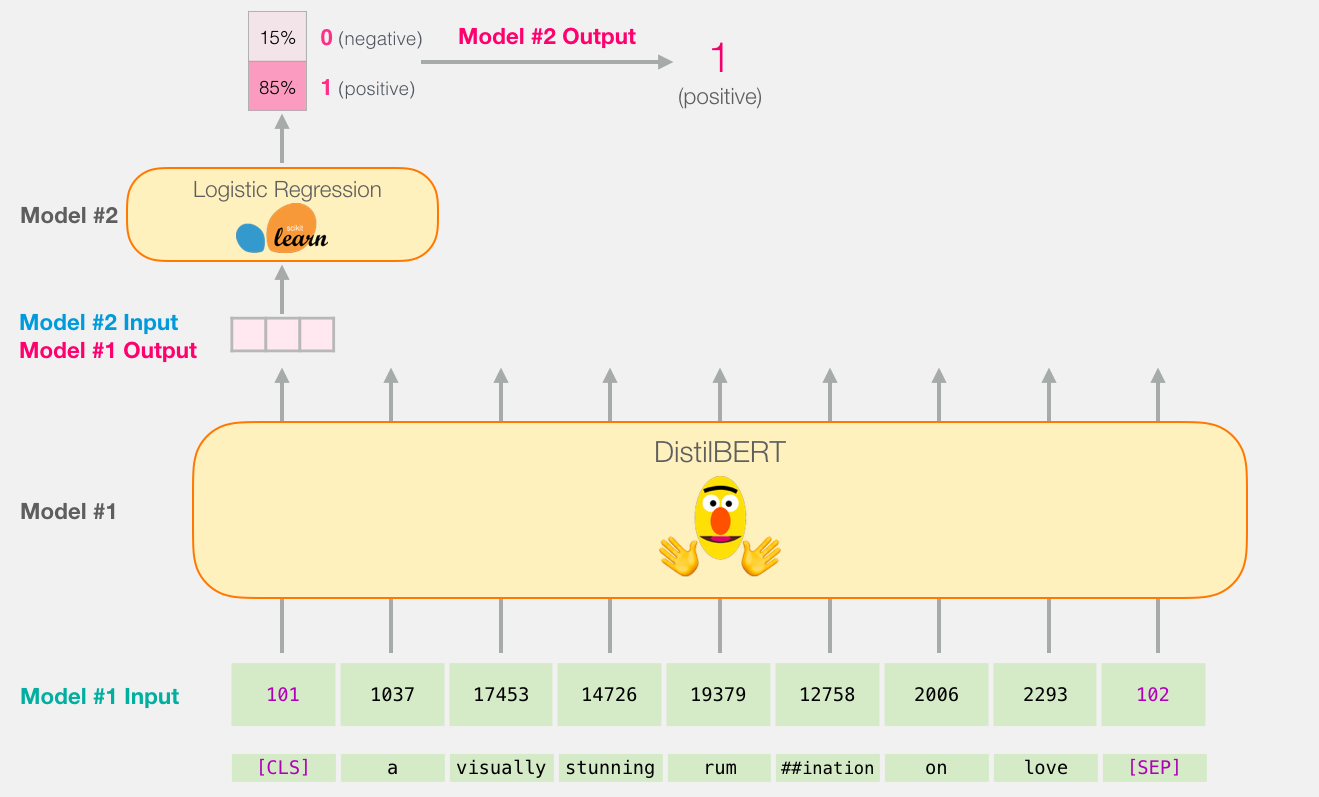
С этого момента эстафета переходит к модели логистической регрессии, которая должна классифицировать этот вектор на основании того, чему она научилась на этапе обучения. Можно схематично представить процесс подсчета предсказанного значения следующим образом:
Обучение мы обсудим в следующей части, где также рассмотрим код для всего этого процесса.
Код
В этой части мы приведем код для обучения модели классификации предложений. Ноутбук со всем этим кодом доступен в Colab и на github.
Начнем с загрузки необходимых библиотек:
import numpy as np
import pandas as pd
import torch
import transformers as ppb # pytorch transformers
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_splitНабор данных доступен отдельным файлом на github, так что мы просто импортируем его напрямую в датафрейм pandas:
df = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv', delimiter='\t', header=None)Можно использовать df.head() для того, чтобы отобразить первые 5 строк датафрейма и посмотреть, что из себя представляют данные:
df.head()
Загрузка предобученной модели DistilBERT и токенизатора
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer, 'distilbert-base-uncased')
## Хотите BERT вместо distilBERT? Раскомментируйте следующую строку:
#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
# Загрузка предобученной модели/токенизатора
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
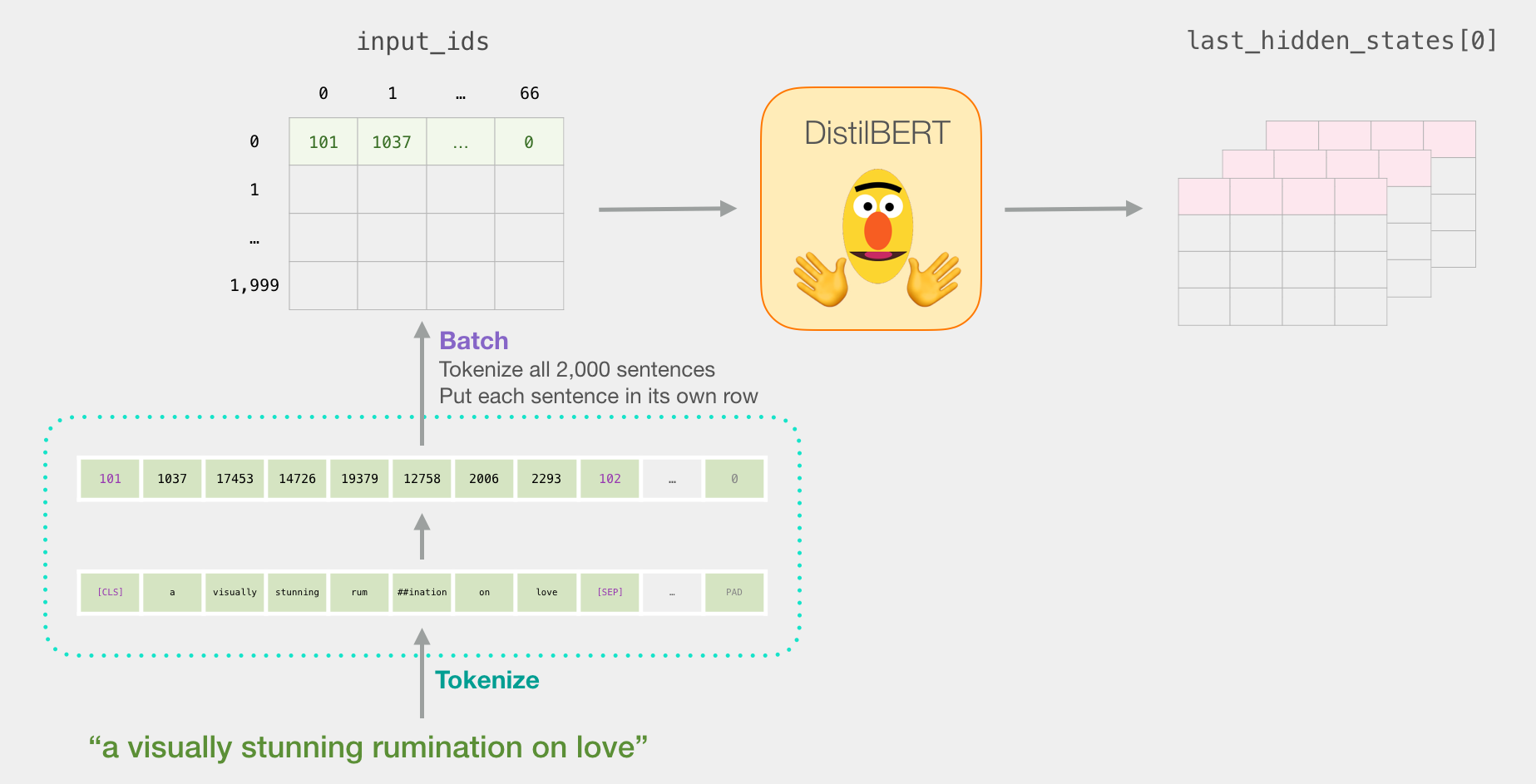
model = model_class.from_pretrained(pretrained_weights)Теперь мы можем токенизировать набор данных. Обратите внимание, что мы будет делать все немного не так, как написано в примере выше. Там токенизируется только одно предложение. Здесь же мы токенизируем и обрабатываем все предложения вместе в одном пакете (в демонстрационном ноутбуке из соображений экономии ресурсов обрабатывается небольшая группа примеров, около 2000).
Токенизация
tokenized = df[0].apply((lambda x: tokenizer.encode(x, add_special_tokens=True)))Этот код преобразует каждое предложение в список идентификаторов.

Набор данных теперь представляет собой список (или объект Series/DataFrame из pandas) списков. Прежде чем DistilBERT обработает его на входе, мы должны привести векторы к одному размеру путем прибавления к более коротким векторам идентификатора 0 (padding). Вы можете посмотреть, как это реализовано в ноутбуке (по сути, все сводится к простым манипуляциям с базовыми строками и массивами в Python).
Таким образом, мы получаем матрицу/тензор, который можно передавать BERT'у:

Обработка в DistilBERT'е
Теперь создадим входной вектор из матрицы токенов и передадим его в DistilBERT.
input_ids = torch.tensor(np.array(padded))
with torch.no_grad():
last_hidden_states = model(input_ids)После запуска этого кода переменная last_hidden_states будет содержать вывод DistilBERT'а, который представляет собой кортеж формы (число примеров, максимальное число токенов в предложении, число скрытых нейронов в модели DistilBERT). В нашем случае, это будет 2000 (т.к. мы ограничили себя 2000 примеров), 66 (что представляет собой число токенов в самом длинном предложении из 2000 примеров), 278 (число скрытых нейронов в модели DistilBERT).

Распаковка выходного тензора BERT'а
Давайте распакуем этот 3-d выходной тензор. Мы можем для начала поисследовать его измерения:
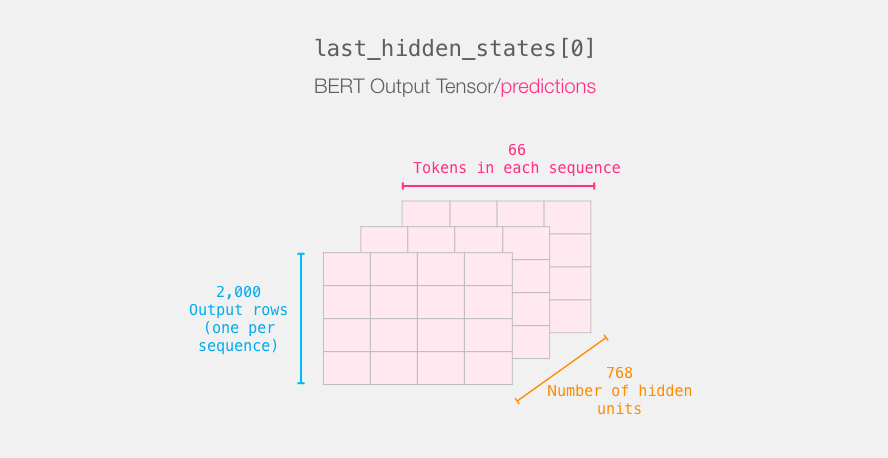
Путешествие подходит к концу
Каждая строка соответствует предложению из нашего набора данных. Завершение обработки первого предложения можно изобразить следующим образом:
Получение самой важной части
Для классификации предложений нас интересует только выход BERT'а для токена [CLS]. Поэтому мы выбираем эту часть куба и отбрасываем все остальное.

Таким образом, мы разрезаем этот 3d тензор для того, чтобы получить нужный нам 2d тензор:
# Разрежьте выход для первой позиции во всех последовательностях, возьмите все выходы скрытых нейронок
features = last_hidden_states[0][:,0,:].numpy()Теперь в переменной features содержится 2d массив numpy, который состоит из эмбеддингов всех предложений нашего набора данных.

Тензор, который мы вырезали из выхода BERT'а
Набор данных для логистической регрессии
Теперь, когда у нас есть выход из BERT'а, мы получили набор данных, который нам нужен для обучения модели логистической регрессии. Признаками являются 768 столбцов, а метки мы получили из нашего изначального набора данных.

Размеченный набор данных, на котором мы тренируем логистическую регрессию. Параметрами являются выходные векторы BERT'а для токена [CLS] (позиция #0), которые мы вырезали (см. предыдущую картинку). Каждая строка соответствует предложению в нашем наборе данных, а каждый столбец – выходу скрытых нейронов из сети прямого распространения, находящейся над блоком Трансформера в модели BERT/DistilBERT
После того, как было произведено традиционное для машинного обучения разделение на обучающую и тестовую выборки, мы можем создать модель логистической регрессии и обучить ее на нашем наборе данных.
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)Код выше разделяет набор данных на обучающую и тестовую выборки:
Далее мы обучаем модель логистической регрессии на обучающей выборке.
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)Модель обучена, и мы можем подсчитать метрики на тестовой выборке.
lr_clf.score(test_features, test_labels)Выполнив этот код, получим показатель точности (accuracy) модели – 81%.
Бенчмарки
Для сравнения: наибольший показатель точности для этого набора данных – 96.8. DistilBERT может быть дообучен для того, чтобы улучшить результат решения этой задачи – процесс, называемый тонкой настройкой. В ходе него BERT обновляет свои веса для того, чтобы лучше справляться с классификацией предложений (что мы можем назвать downstream task). Тонкая настройка DistilBERT'а позволяет достичь показателя точности в 90.7. Полноразмерная модель BERT'а достигает 94.9.
Ноутбук
Перейдите прямо в нотбук или запустите его в Colab.
Вот и все! Хорошее первое знакомство получилось. Следующим шагом будет обратиться к документации и попробовать провести тонкую настройку своими руками. Вы также можете вернуться немного назад и перейти от distilBERT'а к BERT'у и посмотреть, как это сработает.
Благодарности Clément Delangue, Victor Sanh, а также команде Huggingface, которая предоставила отзыв о ранних версиях этого руководства.
Авторы
- Автор оригинала – Jay Alammar
- Перевод – Смирнова Екатерина
- Редактирование и вёрстка – Шкарин Сергей



 абсолютного новичка")
