
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Наверное, когда появились первые дашборды, это выглядело как магия. Не нужно больше ждать, пока кто-то подготовит отчёт, можно просто интерактивно работать с данными, хоть и в определенных рамках. А какой следующий шаг?
Представьте, что у вас есть контакт в телеграме, которому можно просто отправить голосовое сообщение типа: "Что у нас там с планом продаж в Казани?" или "Сколько мы потратили на смузи транспорт в прошлом месяце?" и он сразу пришлет ответ. Круто?
В этом посте мы расскажем, как мы создавали виртуального аналитика ViTalk, с какими проблемами столкнулись и как их решали, а еще про то, что у него находится под капотом.

Итак, зачем, все-таки, нужен виртуальный аналитик?
Аналитики Gartner, например, считают1, что уже в ближайшие годы половина запросов к Business Intelligence системам будет сформулирована на естественном языке. Идея в том, что, если такая возможность будет, к анализу данных получат доступ кратно больше людей, чем сейчас. Я думаю, что по срокам они тут слишком оптимистичны, но за этим точно будущее и со временем NLQ (Natural Language Query) станет одним из основных интерфейсов исследования данных. Особенно, когда виртуальный аналитик сможет не только отвечать на вопрос "Что произошло?", но и наш любимый "Что делать?". Ну или, хотя бы, давать полезные советы.
У меня идея создания такого виртуального аналитика появилась давно, но получилось сделать рабочий вариант далеко не с первого раза. С момента создания компании в 2015 году примерно раз в год мы делали "подход к станку". Первые два подхода закончились плохо — прототипы хорошо работали на заготовленных вопросах, но как только вопрос задавал неподготовленный человек, все сразу ломалось. В третий раз произошло что-то, похожее на волшебство — не на все вопросы, не идеально, но прототип выдавал людям то, что им было нужно.
После этого мы решили, что мы верим, что за этим будущее, и решили вложить силы в создание уже полноценного продукта. Выяснилось, что разработка аналитика, которым действительно удобно пользоваться — долгий и сложный путь, на котором нужно решать массу как ожидаемых, так и неожиданных проблем.


Задача виртуального ассистента — чётко и предсказуемо переводить запросы с естественного языка в структурированные запросы. Мы начали пробовать разные подходы и идеи, начиная с самых очевидных, и в результате пришли к достаточно сложному и развитому инструменту. Но расскажем обо всём по порядку.
Таблица соответствия
Первая идея для ViTalk была достаточно простой. Чтобы запустить виртуального ассистента, можно просто сохранить конкретные фразы в таблице, чтобы в будущем передать на движок ViQube правильные запросы. Решение очевидное… но и с очевидными недостатками.

Во-первых, баз данных может быть много даже у одного пользователя, что уж говорить об использовании системы разными клиентами? Неужели надо каждый раз перевбивать эти запросы? К тому же, как правило, человек не ограничивается одним запросом про прибыль. У руководителя может быть большой словарный запас, поэтому заранее внести все фразы в систему не получится.
Вторая проблема заключается в том, что один и тот же вопрос можно задать по-разному. Пользователь не будет запоминать, как именно сформулированы запросы, которые хранятся в базе. Даже такой простой вопрос как «Прибыль сегодня» можно задать, назвав конкретную дату или день недели. Очень часто пользователи (мы видим это при анализе логов) прибавляют к запросу «наша компания», «у нас», другие притяжательные местоимения. Слово «прибыль» можно вообще заменить на «доходы», либо сформулировать вопрос в глагольной форме — это естественно для человека, но создает кучу сложностей для “таблицы”, в которую будут записаны сопоставления.
Ключевые слова
Второй подход — узнавать запросы по ключевым словам. Можно создать базу таких слов и сразу же искать внутри запроса ключевики, которые есть в нашей базе.
Но и этот подход чреват проблемами. Во-первых, для слов существуют синонимы: вместо KPI можно спросить про производительность, а рабочие дни - назвать буднями. Вариантов таких замен очень много, и прописать все возможные синонимы в базе не получается.
Ищем смыслы
Раз не получается искать по словам, мы будем искать по смыслам! В 2013 году была предложена успешная и очень эффективная реализация представления слов (words embeddings). Если вкратце, то каждому слову мы сопоставляем некоторый набор чисел. Если представить этот набор, как координаты, то слово оказывается точкой в n-мерном пространстве (часто используется 300-мерное). Сопоставление чисел происходит таким образом, чтобы между словами была связь: чем вероятнее соответствующим словам встретиться в одном контексте, тем ближе будут точки в пространстве. Например, «король» и «Луи» должны быть рядом друг с другом, хотя бы из-за песни про Луи II. А слова «барбекю» или «автоматизация», естественно, должны быть подальше, потому что встретить их в одном контексте маловероятно.

С тех пор как word2vec (эффективную модель для получения таких представлений) была предложена чешским аспирантом Томашем Миколовым, эмбеддинги получили широкое распространение и начали создаваться не только для английского, но и для других языков и их сочетаний.
Самое замечательное, что некоторые операции с полученными наборами чисел имеют смысл с точки зрения смысла слов!
Например, что будет, если мы от “Лондона” отнимем “Англию” и прибавим “Россию”? Этот пример почти всегда приводят на лекциях по NLP. “Лондон” относится к “Англии” в отношении «столица — страна». Логично, что после выполнения действий получится «Страна, столица страны Россия». Как мы помним, это Москва. Если мы проделаем те же самые операции с векторами, соответствующим словам, у нас действительно получится что-то похожее на Москву — это точка, ближе всего к которой находится именно “Москва”.

К счастью, существуют такие проекты как «RusVectōrēs», с помощью которых в свободном доступе находится широкий выбор предпосчитанных эмбеддингов. Воспользоваться ими при разработке ViTalk показалось логичным, ведь вектора в многомерном пространстве позволяют сравнивать не просто звучание и написание слов, а их смыслы.
Не только смысл, но и вид
А что, если в базе есть похожие сущности? Например, слова «рабочий» и «день» — весьма распространённые, они могут встречаться в разных сущностях. Как нам их отличить? В этом случае эмбеддинги никак не спасают, и появляется идея рассматривать слова не только по смыслам, но и смотреть по виду. Но тут возникает проблема приведения фраз естественного языка в начальную форму. Ведь мы говорим «по рабочим дням» — в дательном падеже. В базе, естественно, все хранится в именительном падеже. Как минимум, нужно приводить слово к именительному падежу, единственному числу и так далее. А приведение — задача непростая, даже если пользоваться уже готовыми решениями. В этом процессе могут возникать всякие казусы. Например, мы долго боролись с тем, что слово “филиал” различные движки воспринимают как глагол в прошедшем времени и преобразуют в «филиасть». В этом случае вместо результатов поиска по филиалу система выдает непонятно что. Это, конечно, не панацея, но для устранения подобных проблем было решено работать одновременно и со смыслом, и с формой слов.

Кроме этого, есть такие сущности, которые просто не могут быть в одном запросе. Например, там, где есть рабочие дни, у нас нет отдельного показателя KPI, то есть для рабочих дней KPI не определен. Но есть KPI для “рабочих цеха”. Что делать при неправильном запросе? Возможно, пользователь ошибся, и логично предложить ему ответ про “рабочих цеха”? Эти факторы должны быть учтены при поиске значений.
Вероятности
В итоге в качестве первого решения мы выбрали простую вероятностную модель, которая сопоставляла каждому из вариантов запроса некоторую вероятность, что пользователь имел в виду “именно это”. На вероятность влияло очень много факторов — находятся ли эти термины в одной группе? Пересекаются ли сущности в предложении по своим частям или нет? Однако, выбирать тот вариант, который наиболее вероятен, — тоже не оказалось идеальным решением..

Вот замечательный пример, который убил много сил и нервов: “План по прибыли и обороту”.
В базе данных, с которой мы работали в тот момент, были такие сущности, как «план по прибыли», «план по обороту», а также «прибыль» и «оборот» по отдельности. Понятно, что любой разумный человек может однозначно сказать, что имеется в виду в фразе «план по прибыли и обороту» — просто пользователь для лаконичности свернул два запроса в одно выражение. Но как объяснить это ViTalk, который реально пытается на такой запрос ответить?
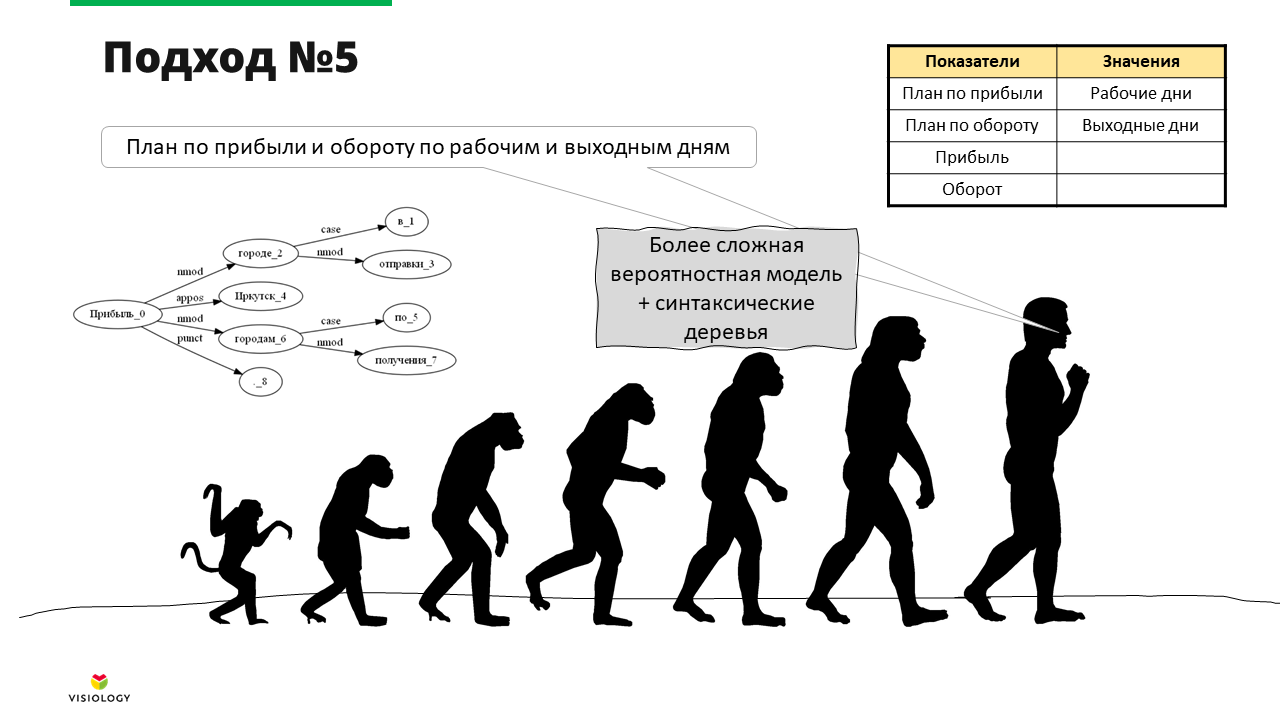
Мы усложнили вероятностную модель и использовали построение синтаксического дерева для анализа того, что именно пользователь имел в виду. Это тоже не идеально работающее решение, потому что даже топовые платформы по построению синтаксических деревьев для русского языка достаточно часто ошибаются. А раз и вероятностная модель, и сторонние решения могут быть неверны, общая степень точности оказывается недостаточной.
Свой метод перевода
В итоге, после множества усложнений, у нас получилась достаточно сложная модель для работы с запросами на естественном языке. Нас часто спрашивают: “Почему мы не пользуемся готовыми решениями?” Ведь задача перевода с естественного языка на язык структурированных запросов достаточно стандартна.

Взять, например, GPT-3 от OpenAI, которая шокирует всех своими потрясающими сгенерированными текстами. Почему не воспользоваться чем-то похожим? Дело в том, что подход GPT-3 требует много ресурсов, а пользователю хочется быстро получить ответ на свой вопрос (не имея, как правило, больших вычислительных мощностей). К тому же, пока качество работы решений для русского языка не очень высокое (сначала все обкатывается на английском, и только потом очередь доходит до других языков).
Есть и третья проблема использования GPT-3 и подобных решений. Она заключается в том, что для дообучения системы требуется большая выборка. Но базы наших клиентов разнообразны, их много, а история обращения — не такая большая. К тому же всё это может не учитывать потребности клиентов, которые в своем лексиконе используют много жаргонизмов, характерных для конкретной компании. Часто какой-то термин используется именно здесь и именно так. Соответственно, распознавание запросов требует дообучения, а выполнить мы его не можем из-за отсутствия достаточной выборки. Так что вероятностная модель — своя и, тем более, уже адаптированная, оказывается лучше.
Адаптация под клиента
Помимо самой модели, которая обеспечивает базис, умеет выделять сущности и задавать правильные запросы, полезно бывает провести настройку под конкретную базу данных, чтобы учитывать термины, которые используются на конкретном производстве.
У нас, например, есть специальный инструмент, который позволяет конфигурировать и вписывать синонимы в простом и удобном формате. Это происходит при первичной настройке ViTalk.
Кроме этого, поиск по смыслам не всегда оказывается оптимальным. Например, если в вашей базе данных содержится несколько миллионов или сотен миллионов значений для какого-то параметра, такой поиск по смыслам будет очень долгим. Для таких случаев мы выбираем полнотекстовый поиск, который работает значительно быстрее.
Прелесть в том, что полнотекстовый поиск включается автоматически, когда система обнаруживает очень большие сущности. Но при необходимости можно отказаться от этого переключения. Также для оптимизации работы в настройках можно отключать отдельные элементы. Например, это могут быть дублирующиеся группы показателей, которые заведены в базе для удобства, или данные, которые в принципе никогда не потребуется показывать при работе с виртуальным ассистентом.
Неопределенности и относительные даты
Ещё один момент, отработка которого отняла много времени, — это относительные даты. Очень часто пользователю BI-системы не хочется конкретно указывать диапазон времени. Он может сказать: «прошлый квартал», или “3 месяца назад”. Перевести такой запрос в нормальный формат оказалось не так-то просто. Конечно, есть готовые решения, которые позволяют преобразовать относительные даты. Но поизучав немного, мы решили ими не пользоваться, потому что нам нужно было обеспечить одновременно и скорость отработки и точность распознавания. В результате было создано собственное решение, которое выделяет из запроса именно такие сущности, как время и дата.
Но даже при всем этом в запросах по-прежнему остается масса неопределенностей. Например, пользователь может и не помнить, что у него в базе есть несколько сущностей с одинаковыми названиями. В таком случае ассистент не может корректно ответить на запрос в принципе. Часто встречается ситуация, когда календарь хранится в разных понятиях: дата доставки, дата продажи, дата производства. И когда человек спрашивает: “покажи нам прибыль в 2018 году”, нужно, чтобы ViTalk задал уточняющий вопрос. Выделить те ситуации, когда мы должны не просто отсечь одну сущность, а задать вопрос, было непросто.
На практике часто бывает так, что сущности оказываются составными. Например, крупная категория «Бакалея, сахар, соль» может сопровождаться подкатегориями «Бакалея», «Сахар», «Соль», которые существуют по отдельности. В таких случаях мы начали уточнять, что именно хочет узнать пользователь — данные по всей категории или получить информацию по подкатегориям? Сейчас ViTalk уже стал достаточно умным, чтобы не проявлять лишнюю самодеятельность и задавать вопросы в неопределенных ситуациях.
Выбор метода визуализации
На вебинаре, посвященном ViTalk, мы показывали, что ассистент может по-разному показывать результаты своей работы. Иногда он выдаёт ответ текстом, бывают диаграммы и линейные графики. И в каждом случае есть свои предпочтения. Например, в запросе «динамика по прибыли по месяцам», все, конечно, хотят увидеть не столбчатую диаграмму, а линейный график — ведь на нем как раз видно динамику. Поэтому в ViTalk мы зашили некоторые паттерны представлений разных категорий данных.
Например, проанализировав стандартные аналитические паттерны, посмотрев логи, мы пришли к выводу, что чаще всего наших пользователей интересует сравнение, сопоставление или “топ” каких-то показателей. Часто хотят увидеть ТОП лучших сотрудников, ТОП продаваемых товаров, а также динамику этих изменений.

Чтобы удовлетворить эти запросы, нам пришлось реализовать подсветку дополнительных параметров. При отработке запросов на сравнение он показывает несколько столбцов, явно подчёркивая разницу, а при демонстрации ТОПов выделяет самые-самые результаты. Для динамики у нас всегда — линейный график. А когда мы делаем запрос “кто у нас самый эффективный сотрудник”, результат будет в виде текста и числа с KPI.
Самое сложное при разработке инструмента конфигурации было выдержать баланс. С одной стороны, нужно было, чтобы пользователь мог гибко настроить решение под себя, с другой стороны — чтобы это не превращалось в какую-то сложную работу, которую все захотят пропустить.
И в заключение...

Интересно, что многие серьезные зарубежные конкуренты, тоже сделавшие своих виртуальных ассистентов, например, Qlik Insights Bot, Power BI Q&A, Tableau AskData, выбрали принципиально другой подход. В их решениях пользователь получает подсказки по мере ввода запроса, то есть система помогает ему (и принуждает) писать что-то похожее на SQL-запрос, но на естественном языке. Это делает процесс более предсказуемым, но зато не позволяет обрабатывать честные плохо сформулированные "человеческие" запросы и, по очевидным причинам, голосовые сообщения. Какой подход окажется лучше, покажет время.
Виртуальным аналитикам еще многому нужно научиться, чтобы создать серьезную конкуренцию аналитику-человеку. Конечно, не все из тех, кто занимается BI системами, согласны, что за виртуальными аналитиками будущее. С другой стороны, ведь и компьютер, побеждающий сегодня в шахматах и го, когда-то казался фантастикой, как и управление голосом магнитолой и навигатором в машине.
Ну а мы предпочитаем не сомневаться, а прилагать все усилия, чтобы виртуальные аналитики все больше освобождали аналитиков-людей от рутинных задач и позволяли им сосредоточиться на действительно сложных и важных задачах (например, на ответах на вопросы пользователей "а у меня с Excel не сходится!!!" продвинутой аналитике).
Ну а пообщаться с ViTalk можно в публичном демо-боте в Telegram - @vitalk_public_bot. Будем благодарны за любую обратную связь, критику и предложения!
P.S. Хочу выразить огромный респект нашей команде Data Science в лице Екатерины Дмитриевой, Борислава Полякова и Ивана Лазаревского, которые подготовили контент для технической части этой статьи и являются её соавторами.
Ссылки:
Gartner Magic Quadrant for Analytics and Business Intelligence Platforms




